for writing tasks are accurate and robust detectors of AI-generated text Jenna Russell, Marzena Karpinska, Mohit Iyyer ACL 2025 main long paper ※スライド中の図表は指定がない限りは上記の論文からの引用になります。
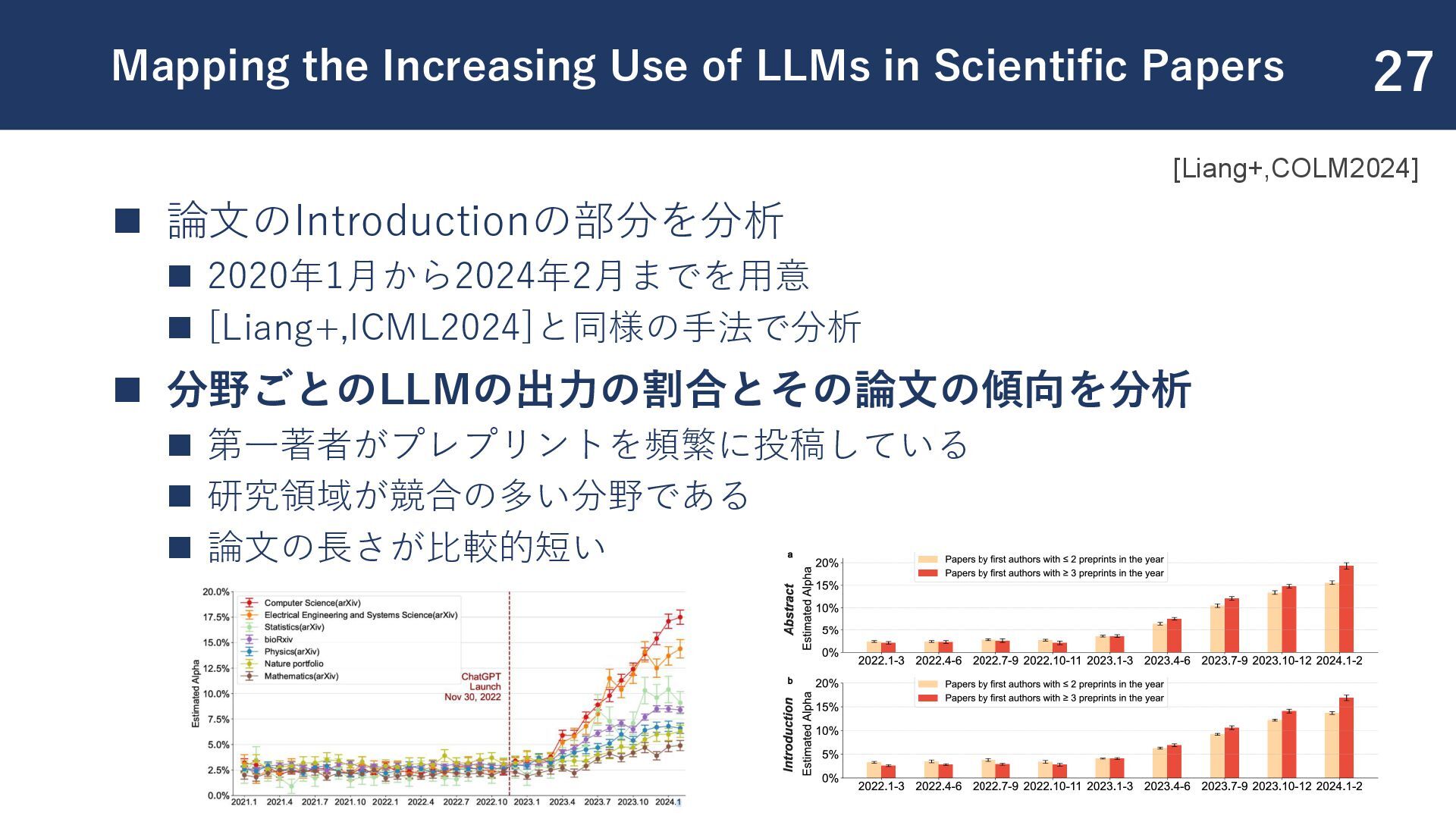
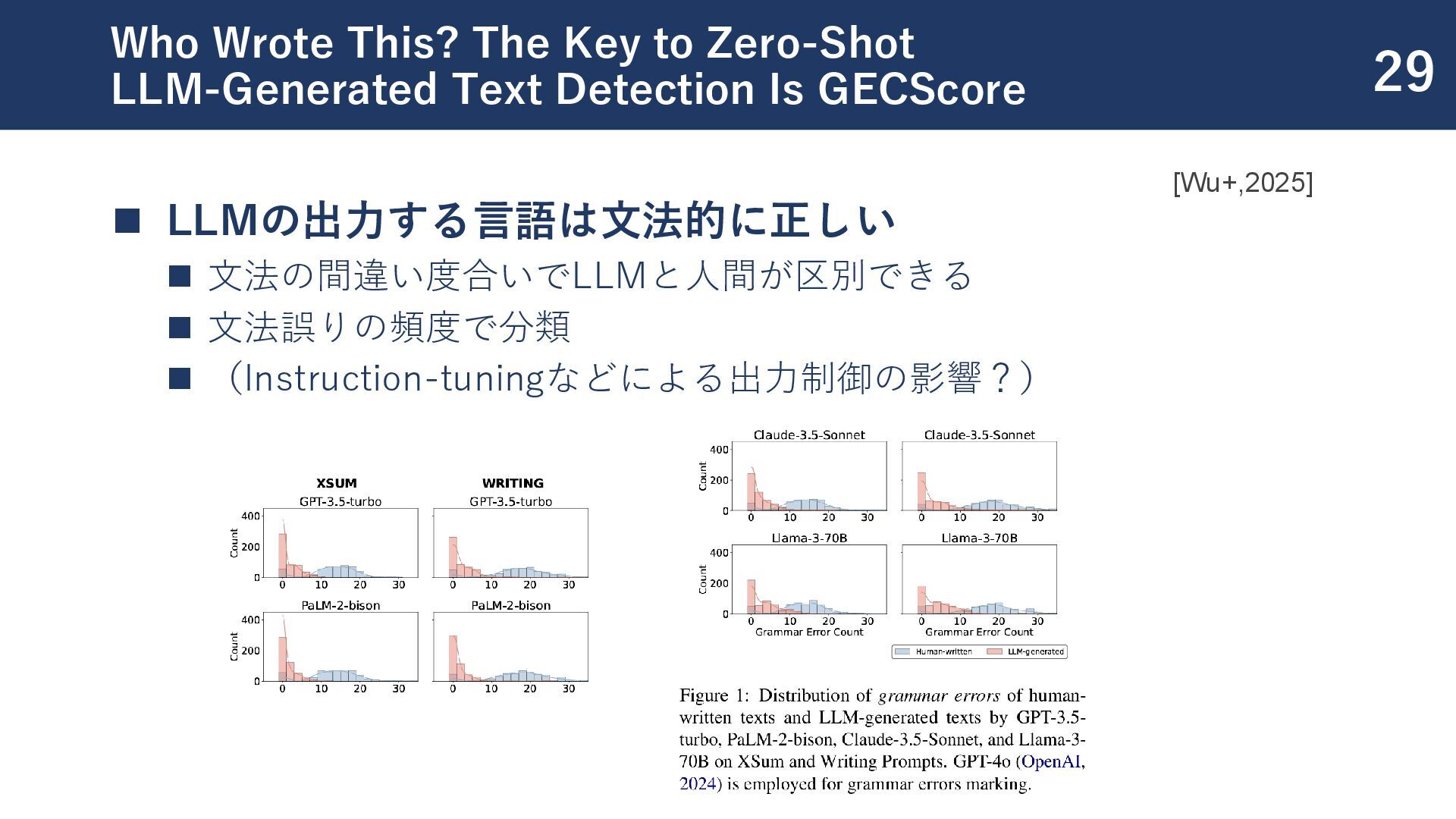
Case Study on the Impact of ChatGPT on AI Conference Peer Reviews ◼ [Liang+, COLM2024] Mapping the Increasing Use of LLMs in Scientific Papers ◼ [Wu+, 2025] Who Wrote This? The Key to Zero-Shot LLM-Generated Text Detection Is GECScore ◼ [Sun+, 2025] Idiosyncrasies in Large Language Models ◼ [Chang+, 2024] PostMark: A Robust Blackbox Watermark for Large Language Models ◼ [Yakura+, 2025] Empirical evidence of Large Language Model's influence on human spoken communication 25
{kind=link}
{kind=link}
![なぜこの論文を選んだのか? ◼ 人間とLLMの文の差異は何なのかを知りたい ◼ LLMの登場により言語は変化している ◼ 特定の単語の頻度が多くなる [Liang+, ICML2024] [Liang+,](https://files.speakerdeck.com/presentations/153886e409f64d7dba3dcbfc4f18e386/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
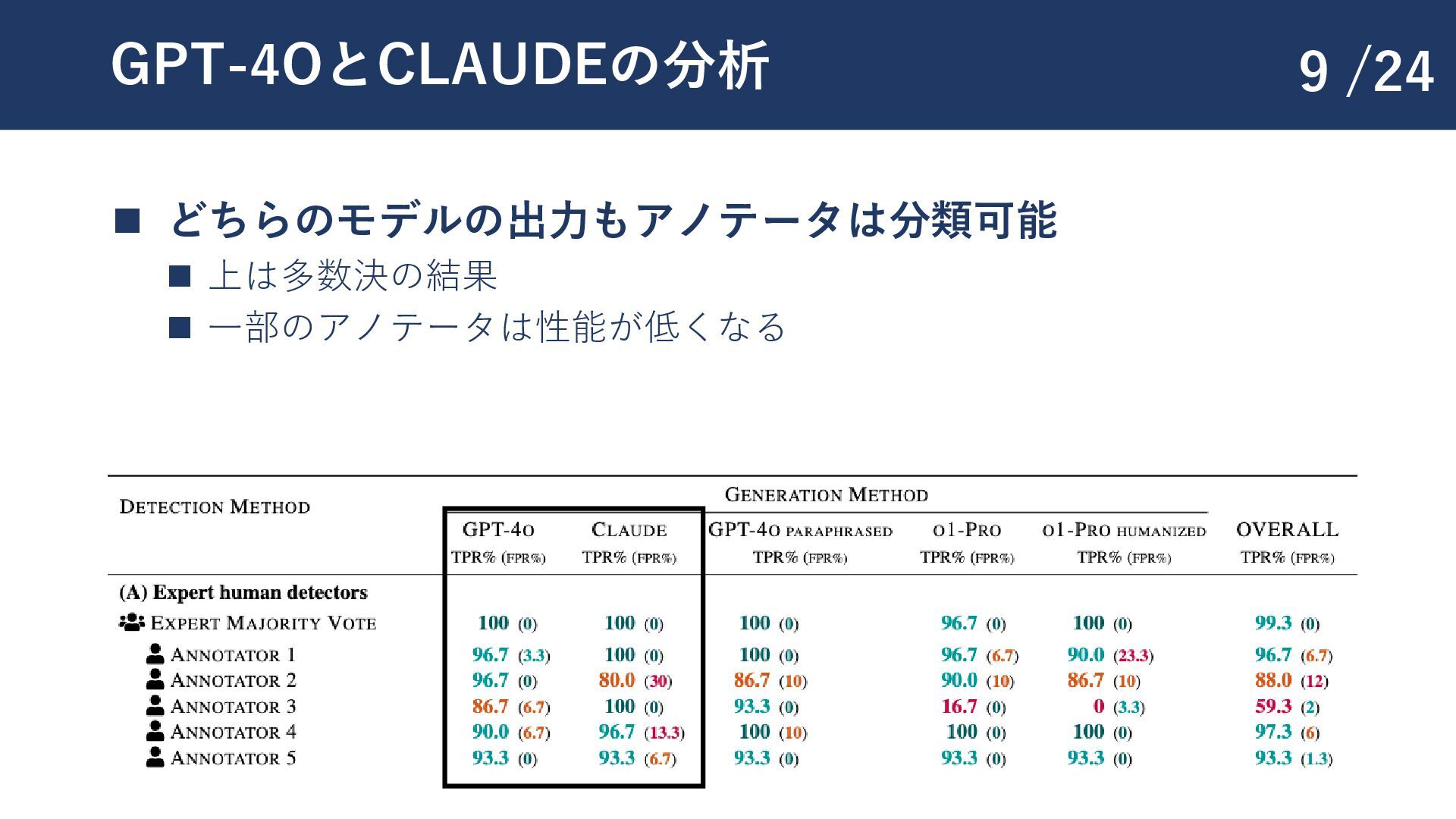{kind=link}
![GPT-4O+言い換えの分析 10 /24 ◼ LLMに人間が書いたように言い換えさせる ◼ Promptベースの手法 [Chang+, EMNLP2024] ◼](https://files.speakerdeck.com/presentations/153886e409f64d7dba3dcbfc4f18e386/slide_10.jpg){kind=link}
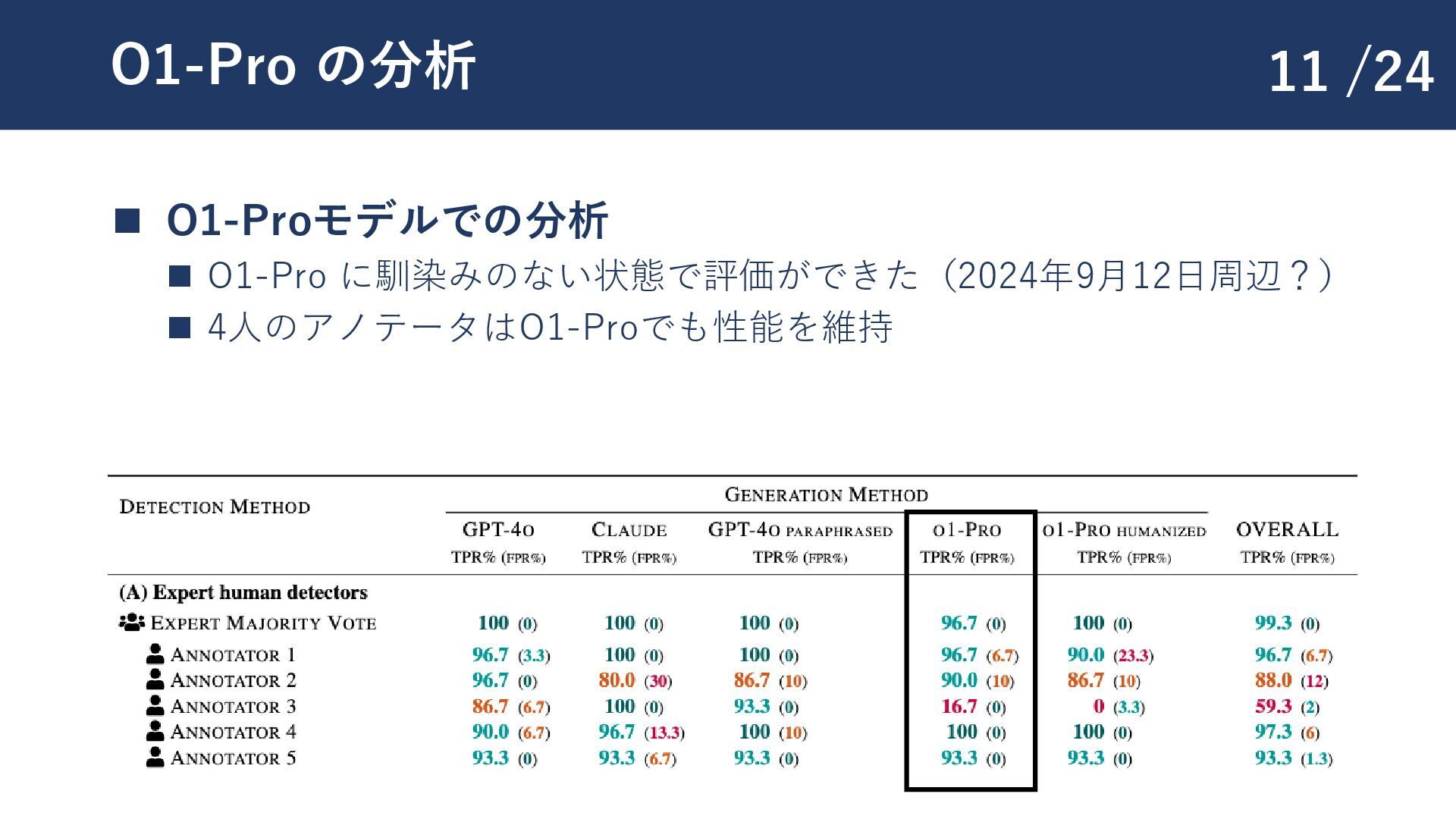{kind=link}
{kind=link}
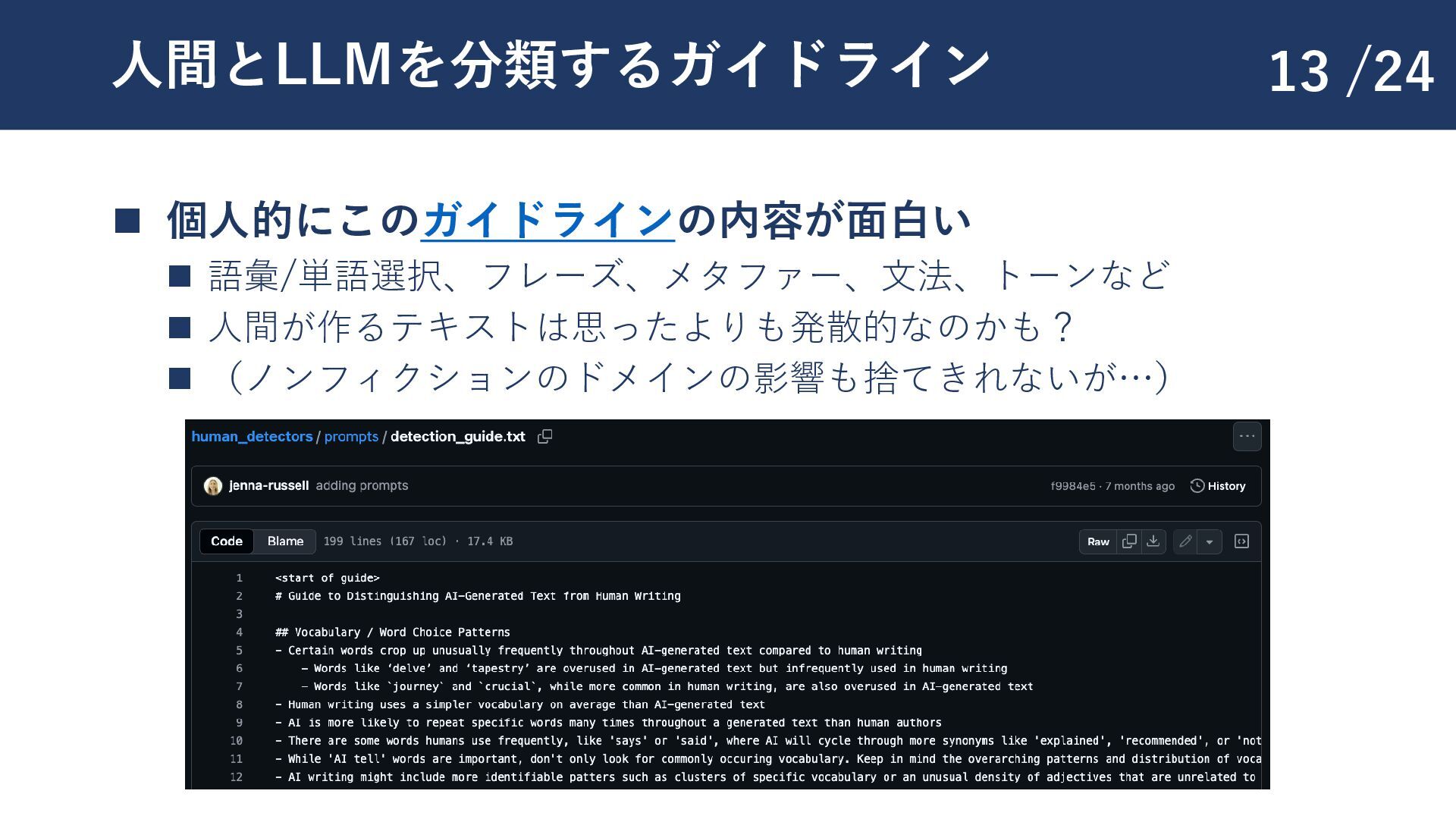{kind=link}
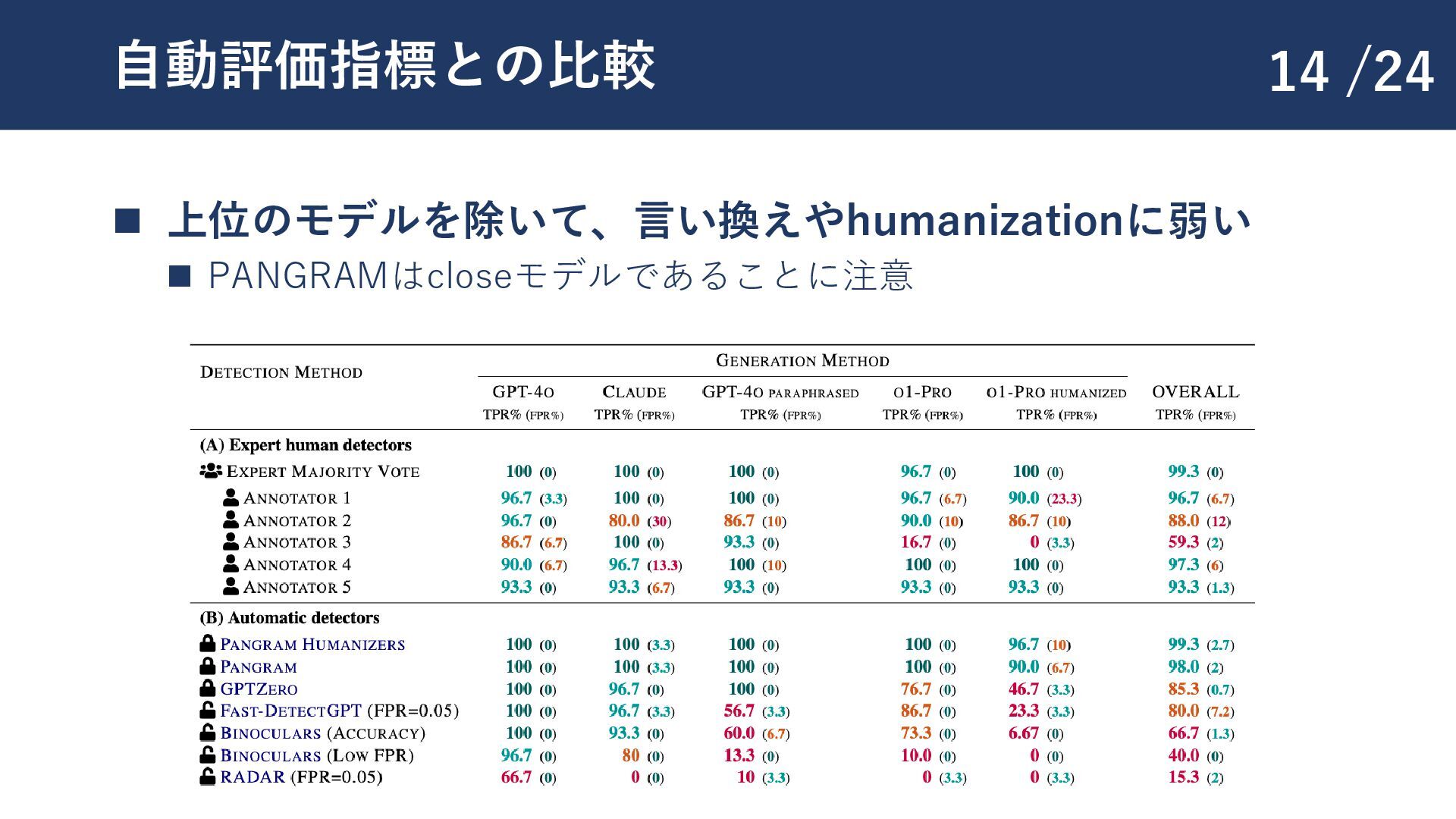{kind=link}
{kind=link}
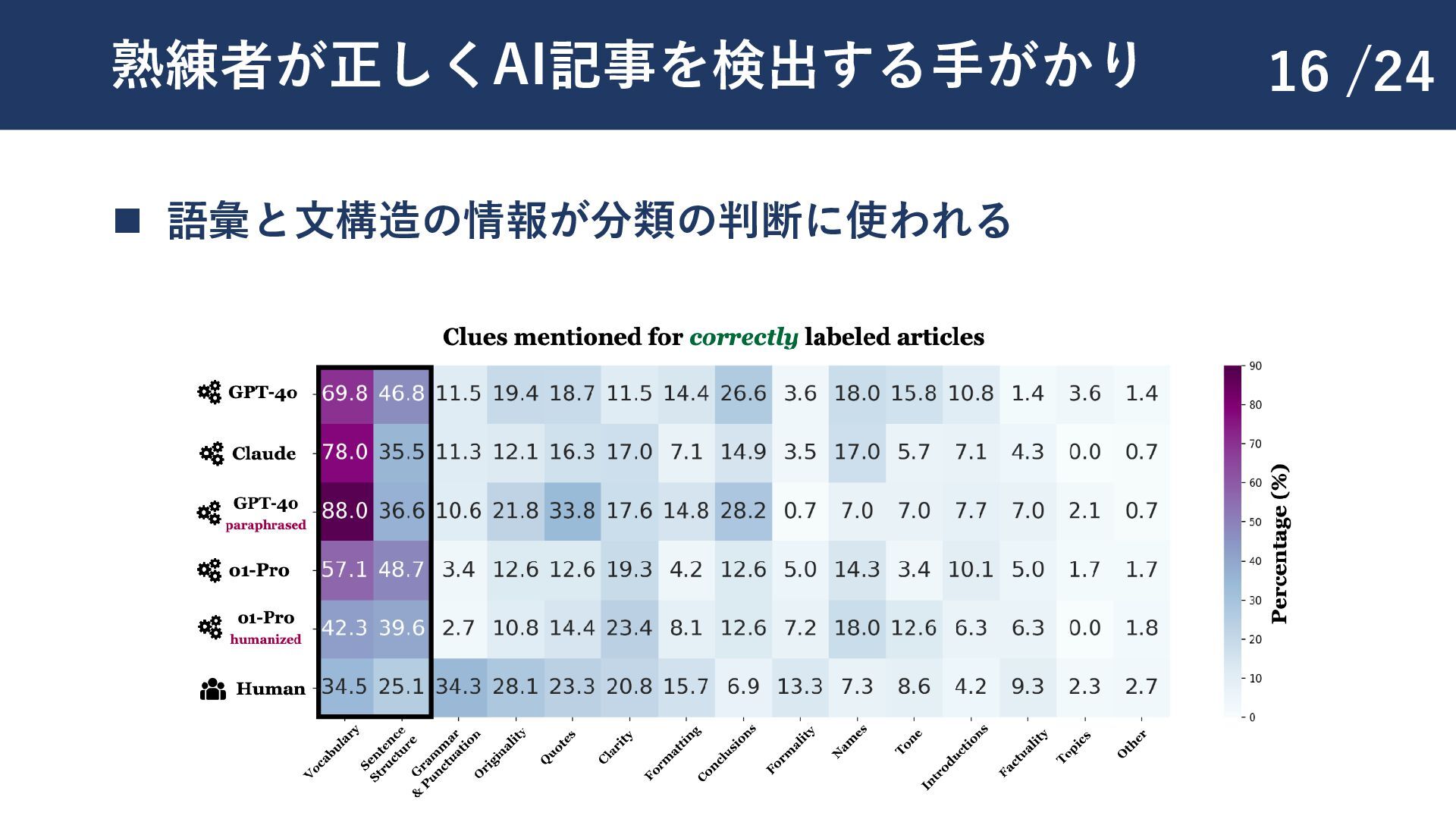{kind=link}
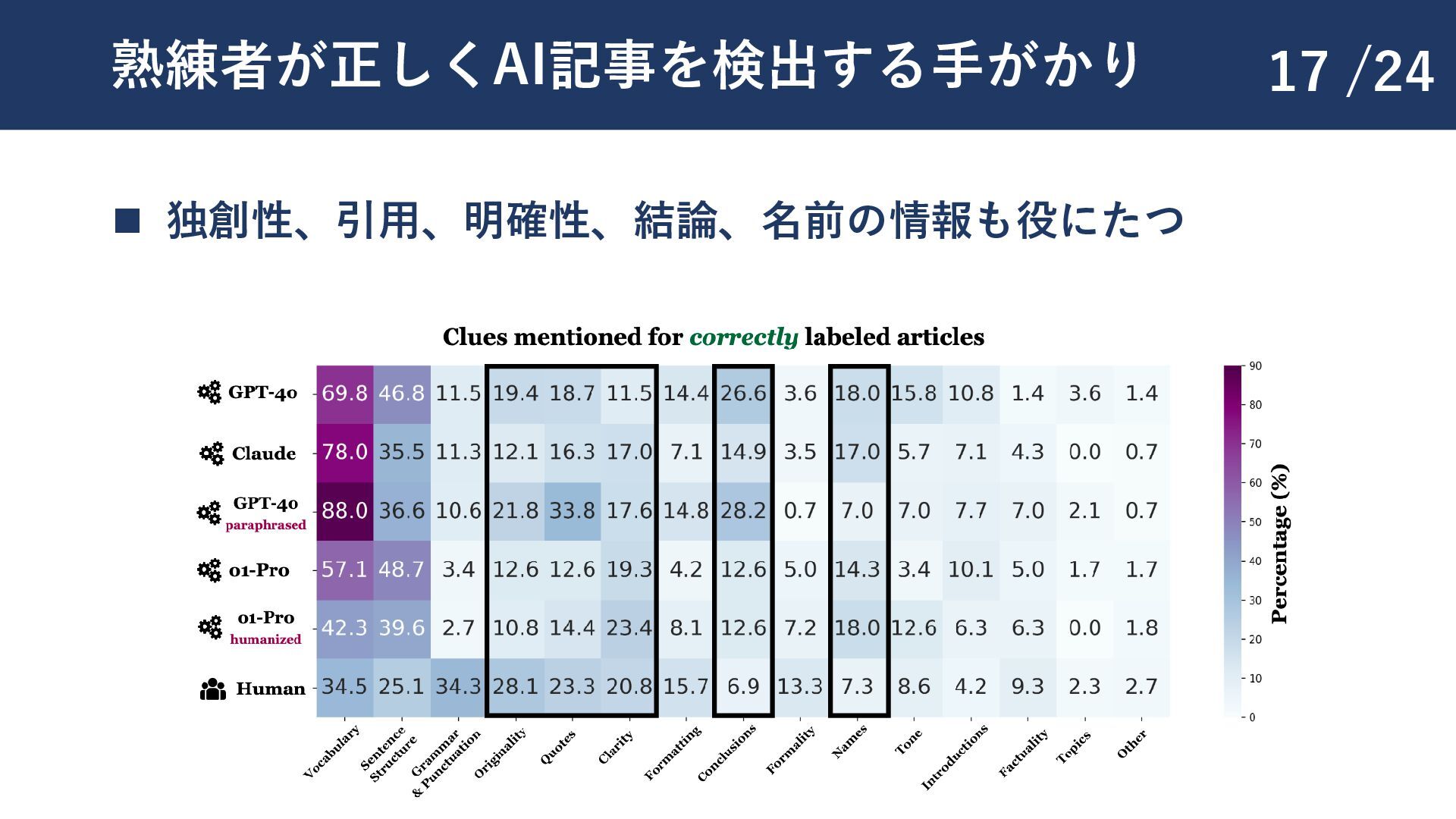{kind=link}
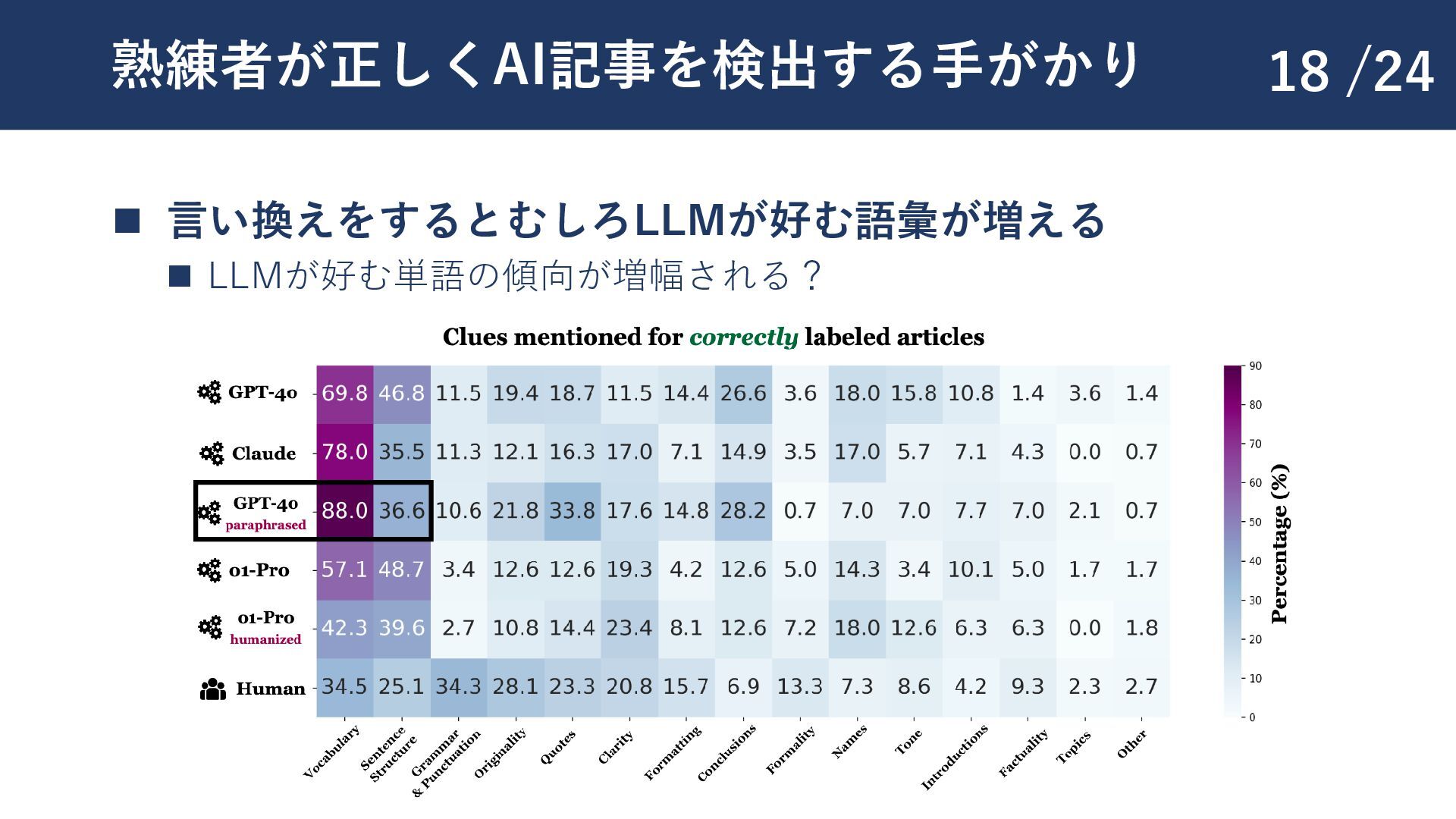{kind=link}
{kind=link}
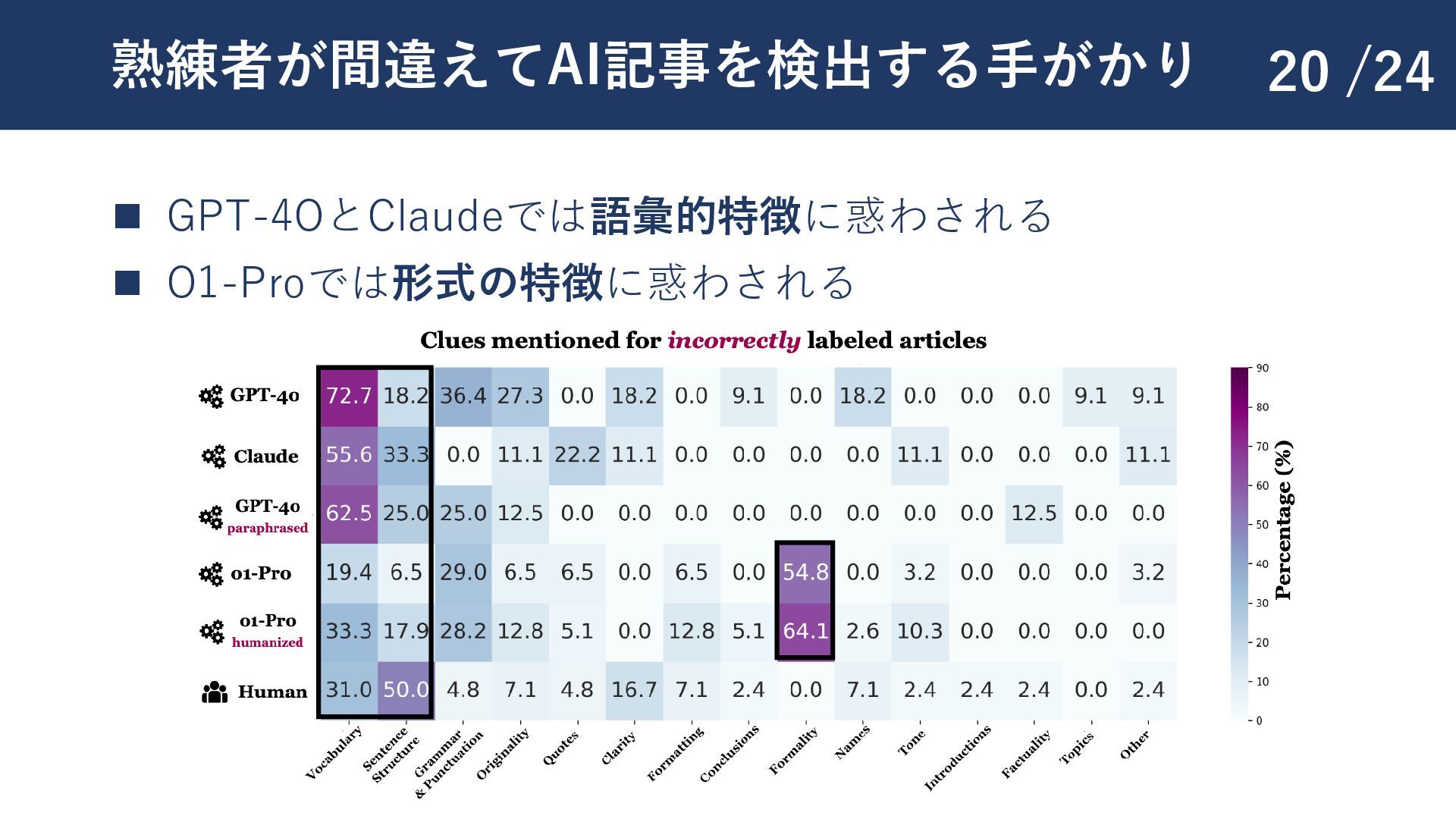{kind=link}
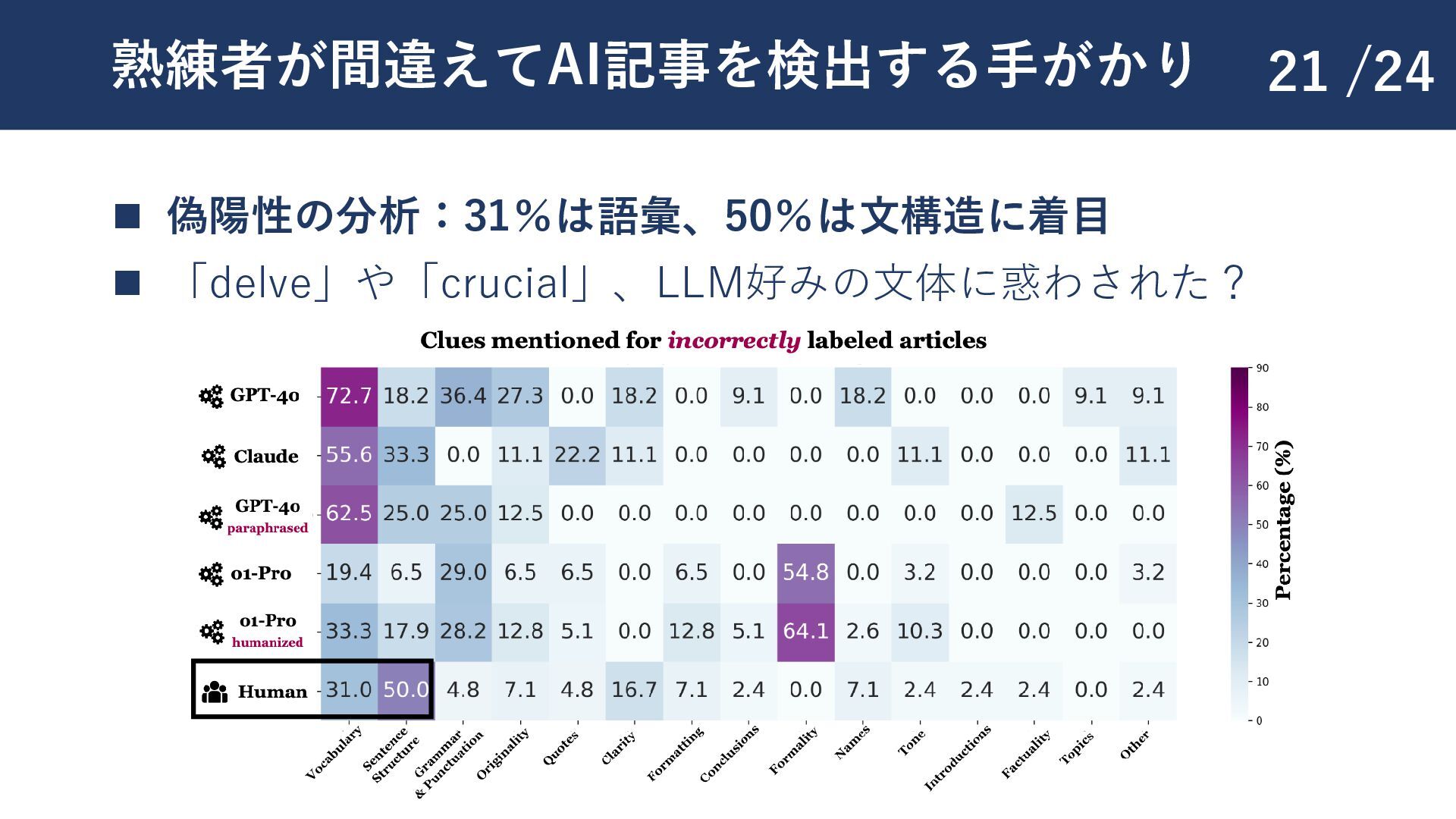{kind=link}
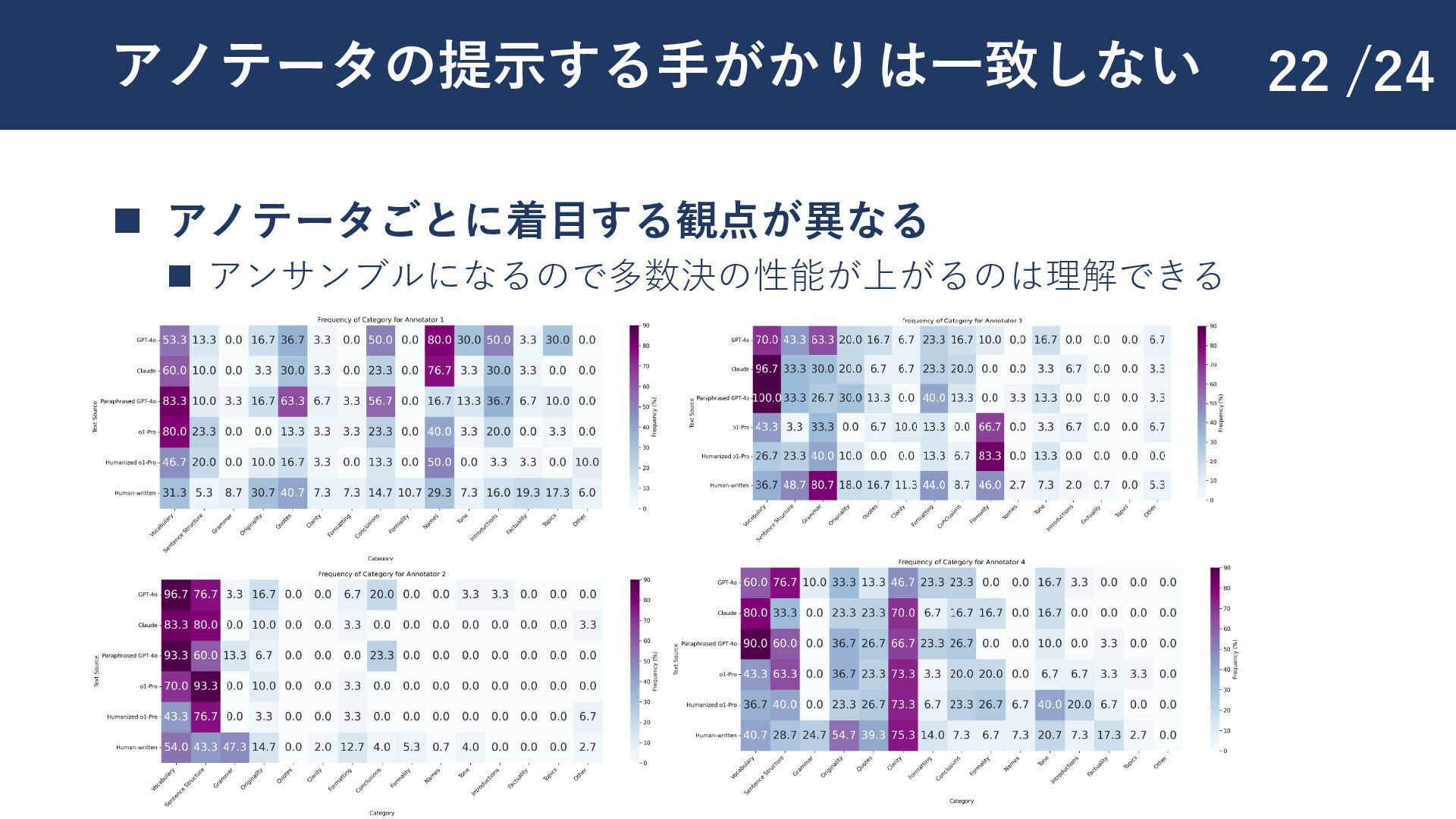{kind=link}
{kind=link}
{kind=link}
![参考文献 ◼ [Liang+, ICML2024] Monitoring AI-Modified Content at Scale: A](https://files.speakerdeck.com/presentations/153886e409f64d7dba3dcbfc4f18e386/slide_25.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
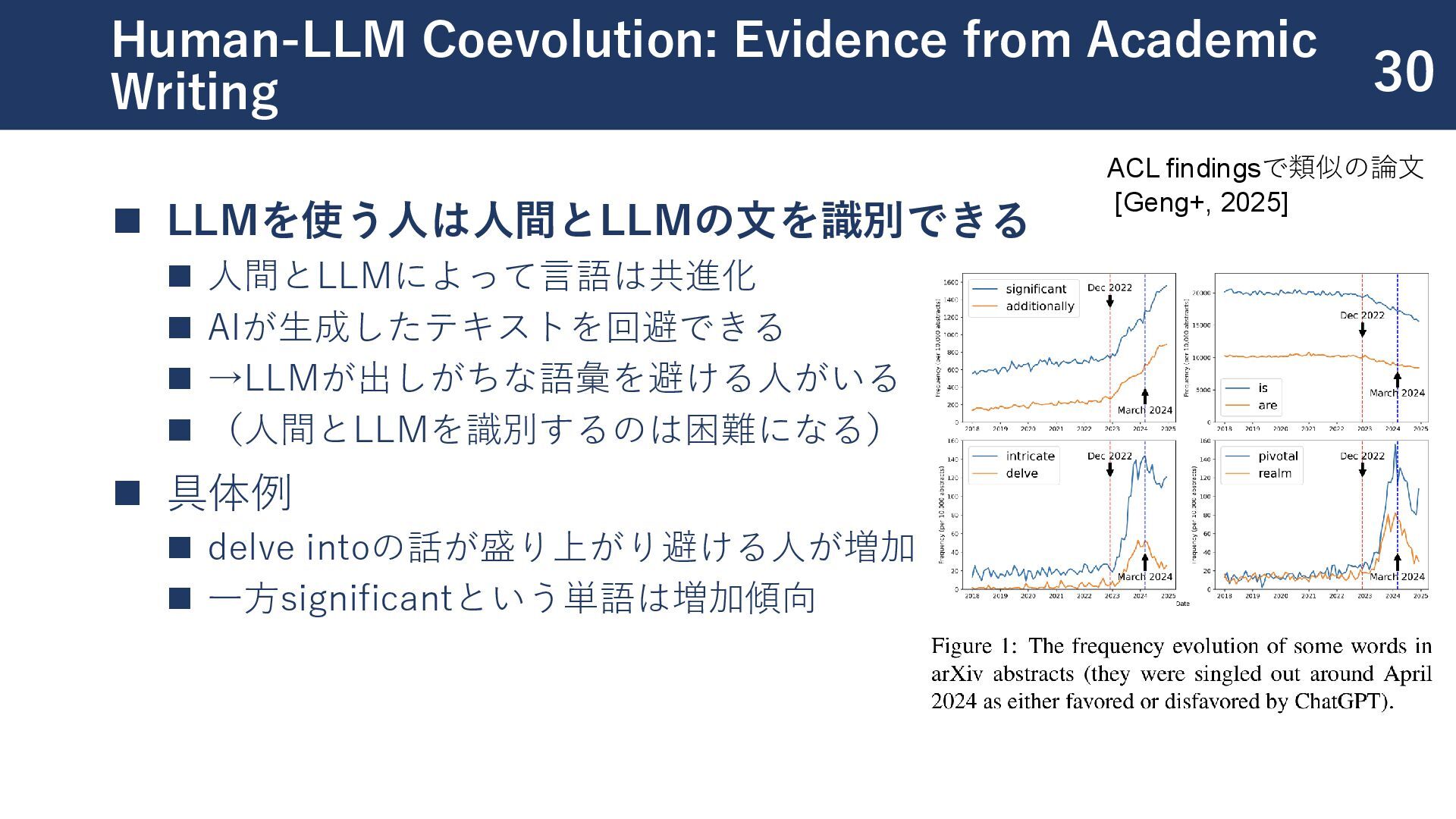{kind=link}
{kind=link}