Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
databricks,dbt,AWS S3を使ったデータパイプラインレシピ
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
RyutoYoda
March 18, 2025
110
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
databricks,dbt,AWS S3を使ったデータパイプラインレシピ
RyutoYoda
March 18, 2025
More Decks by RyutoYoda
See All by RyutoYoda
Streamlitで構築する マルチデータ プラットフォーム対応の アドホック分析環境
ryutoyoda
0
620
AIエージェント多すぎて迷子になっていませんか
ryutoyoda
0
42
dbtで作るデータ分析基盤
ryutoyoda
0
93
EmoEcho
ryutoyoda
0
70
Featured
See All Featured
Leo the Paperboy
mayatellez
8
1.9k
State of Search Keynote: SEO is Dead Long Live SEO
ryanjones
0
220
Done Done
chrislema
186
16k
AI Search: Where Are We & What Can We Do About It?
aleyda
0
7.7k
Performance Is Good for Brains [We Love Speed 2024]
tammyeverts
12
1.7k
Statistics for Hackers
jakevdp
799
230k
Impact Scores and Hybrid Strategies: The future of link building
tamaranovitovic
0
330
We Have a Design System, Now What?
morganepeng
55
8.2k
My Coaching Mixtape
mlcsv
0
170
The Cost Of JavaScript in 2023
addyosmani
55
10k
RailsConf 2023
tenderlove
30
1.5k
How to Ace a Technical Interview
jacobian
281
24k
Transcript
databricks,dbt,AWS S3 を使った データパイプラインレシピ Ryuto Yoda
1. 概要 AWS S3をUnity Catalogに接続する 2. データ取り込み設計 3. データパイプラインの構築 4.
CONTENTS 質問タイム 5.
概要 01
AWS S3、Databricks、dbtを使ってデータパイプラインの概要 AWS S3をデータレイクとして利用し、データの保存を行 います。 Databricksでは Sparkを活用して、大規模データのETL 処理や解析を高速に実行します。 dbtはSQLベースでデータの変換・モデリングを行い、ク リーンで高品質なデータを提供します。
この組み合わせにより、効率的なデータ処理と再現性の あるパイプラインが実現できます。
AWS S3をUnity Catalog に接続する 02
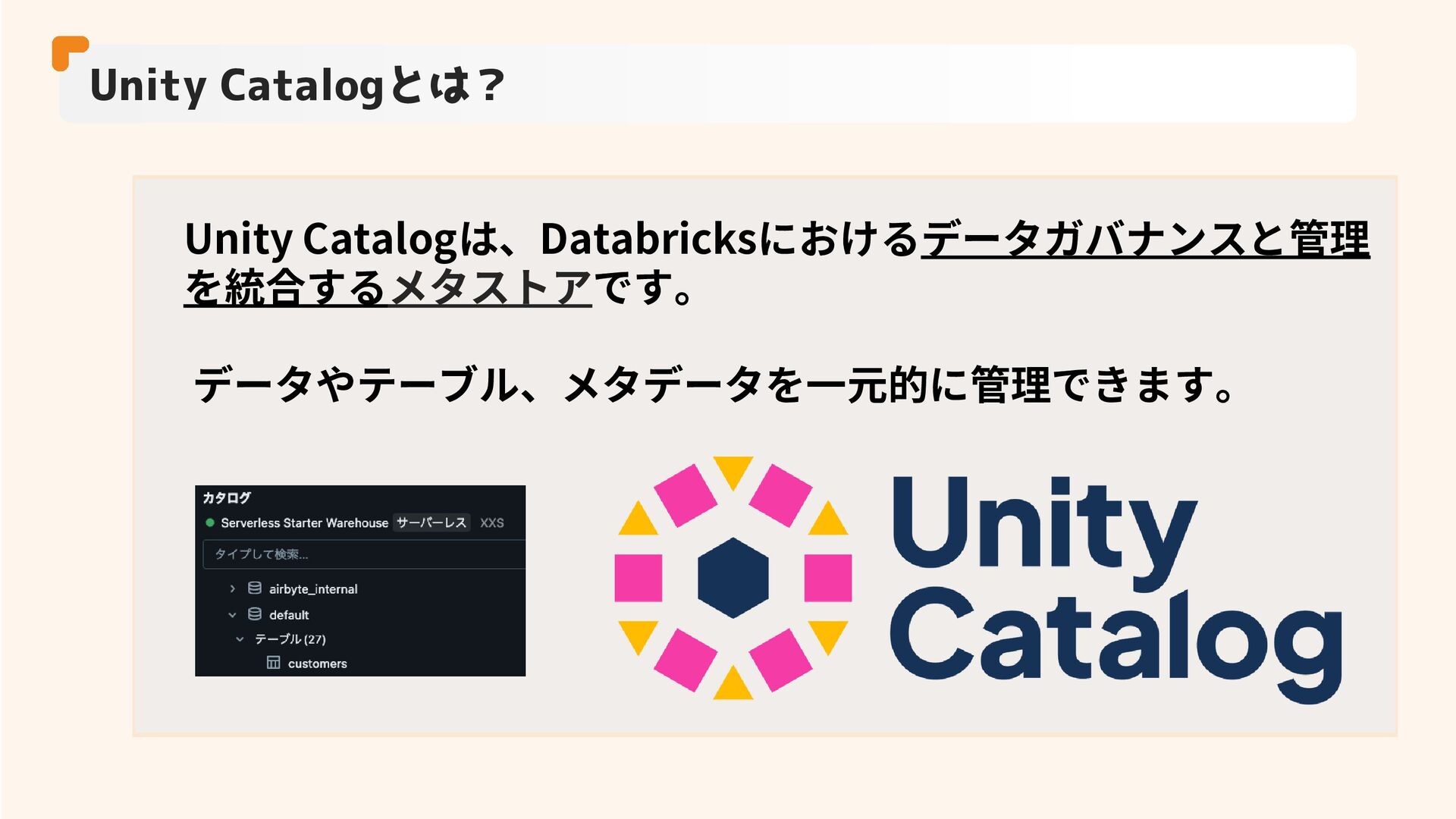
Unity Catalogとは? Unity Catalogは、Databricksにおけるデータガバナンスと管理 を統合するメタストアです。 データやテーブル、メタデータを一元的に管理できます。
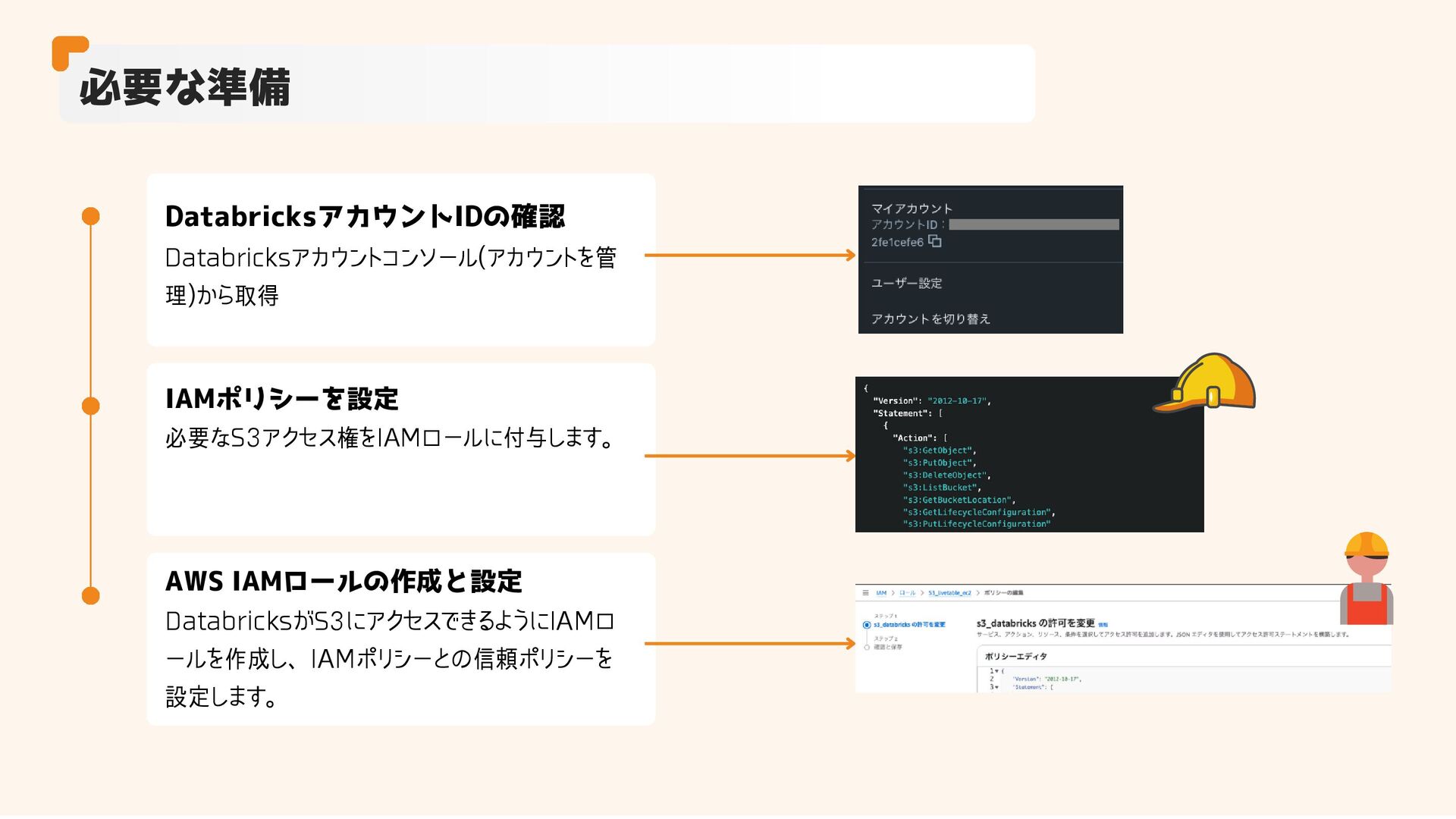
必要な準備 DatabricksアカウントIDの確認 Databricksアカウントコンソール(アカウントを管 理)から取得 AWS IAMロールの作成と設定 DatabricksがS3にアクセスできるようにIAMロ ールを作成し、IAMポリシーとの信頼ポリシーを 設定します。 IAMポリシーを設定
必要なS3アクセス権をIAMロールに付与します。
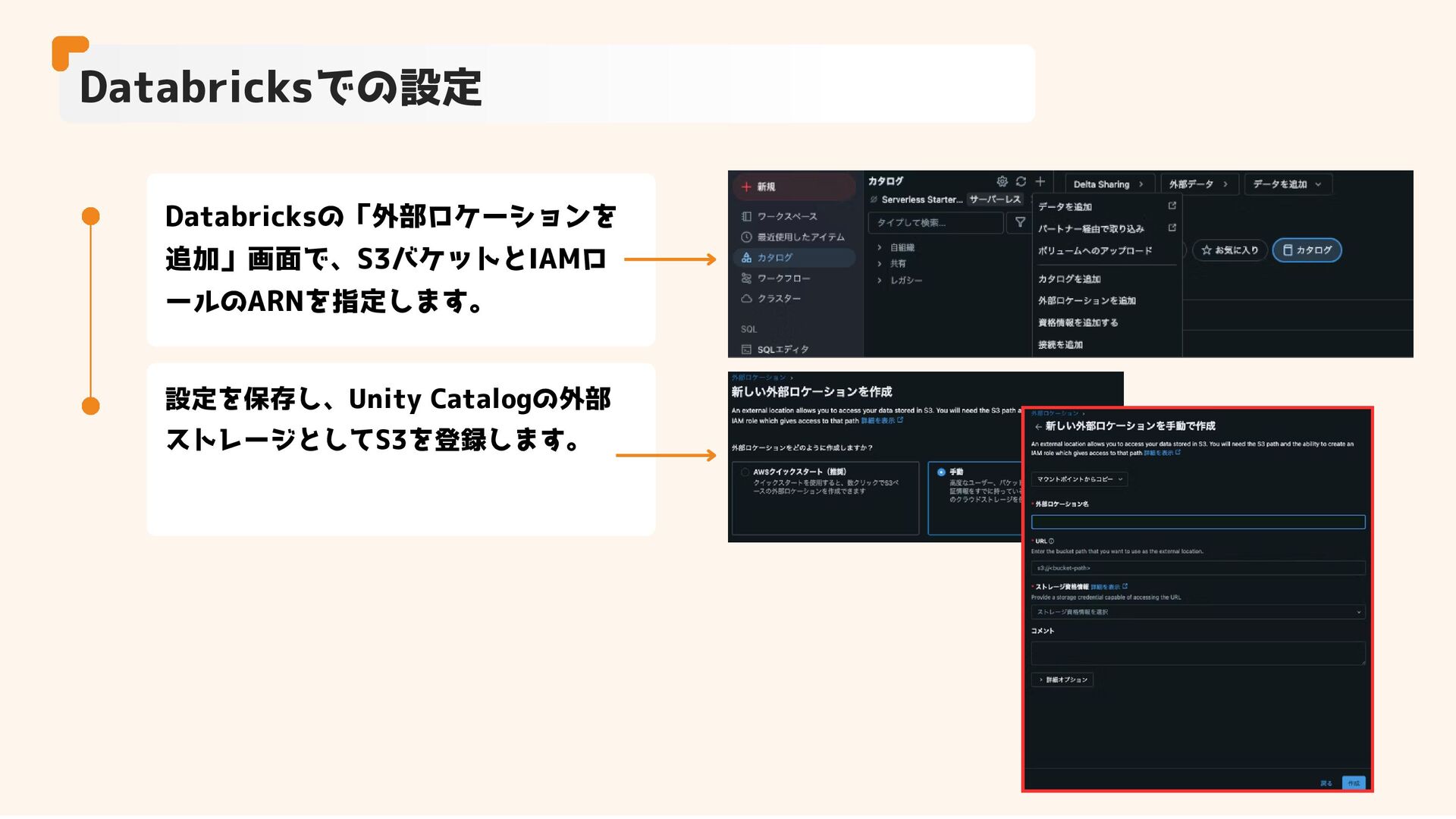
Databricksでの設定 Databricksの「外部ロケーションを 追加」画面で、S3バケットとIAMロ ールのARNを指定します。 設定を保存し、Unity Catalogの外部 ストレージとしてS3を登録します。
データ取り込み設計 03
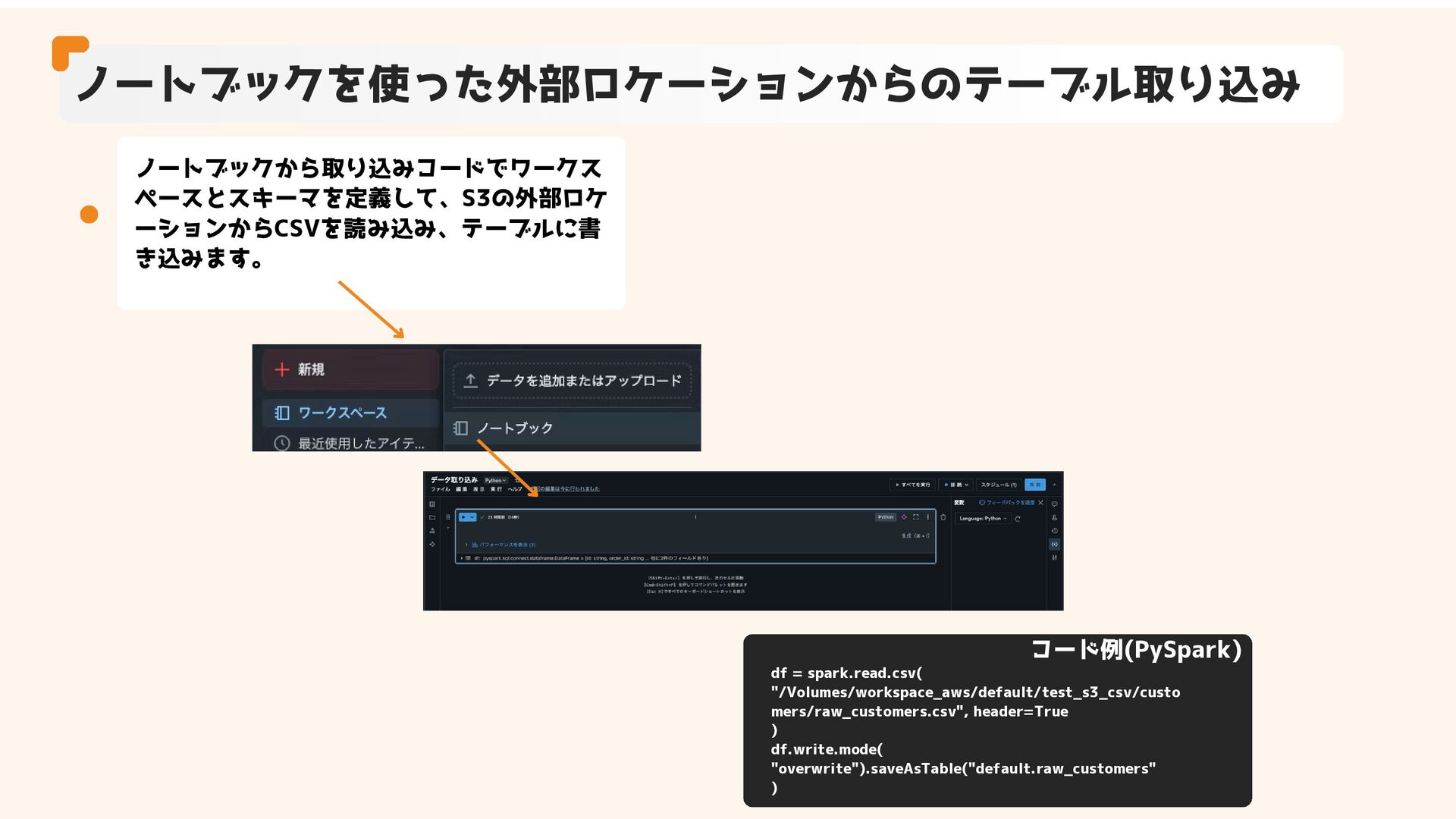
ノートブックを使った外部ロケーションからのテーブル取り込み ノートブックから取り込みコードでワークス ペースとスキーマを定義して、S3の外部ロケ ーションからCSVを読み込み、テーブルに書 き込みます。 df = spark.read.csv( "/Volumes/workspace_aws/default/test_s3_csv/custo mers/raw_customers.csv",
header=True ) df.write.mode( "overwrite").saveAsTable("default.raw_customers" ) コード例(PySpark)
データパイプラインの構築 (Databricks + dbt) 04
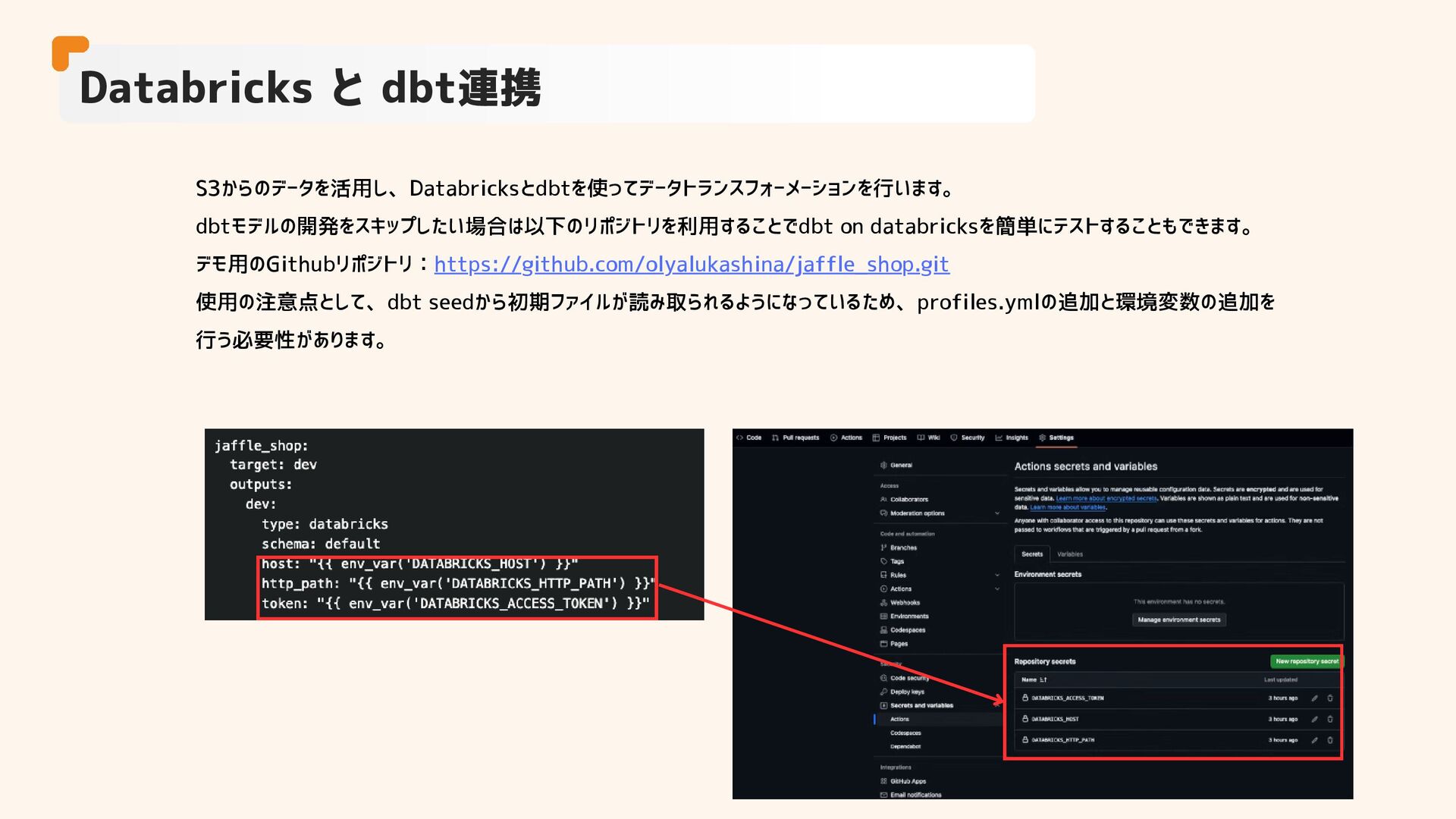
S3からのデータを活用し、Databricksとdbtを使ってデータトランスフォーメーションを行います。 dbtモデルの開発をスキップしたい場合は以下のリポジトリを利用することでdbt on databricksを簡単にテストすることもできます。 デモ用のGithubリポジトリ:https://github.com/olyalukashina/jaffle_shop.git 使用の注意点として、dbt seedから初期ファイルが読み取られるようになっているため、profiles.ymlの追加と環境変数の追加を 行う必要性があります。 Databricks と
dbt連携
Databricksジョブで自動化 Databricksジョブの作成 Databricksの「ワークフロー」セクションで 新しいジョブを作成して保存します ノートブックをフローに追加 これによりS3の外部ロケーションから databricksのテーブルへのロードも自動化さ れます。またこの処理が終わった後にdbtが 走るようになります。 トリガーの設定
スケジュールとトリガーのタブで、S3の到着 をトリガーに設定します。
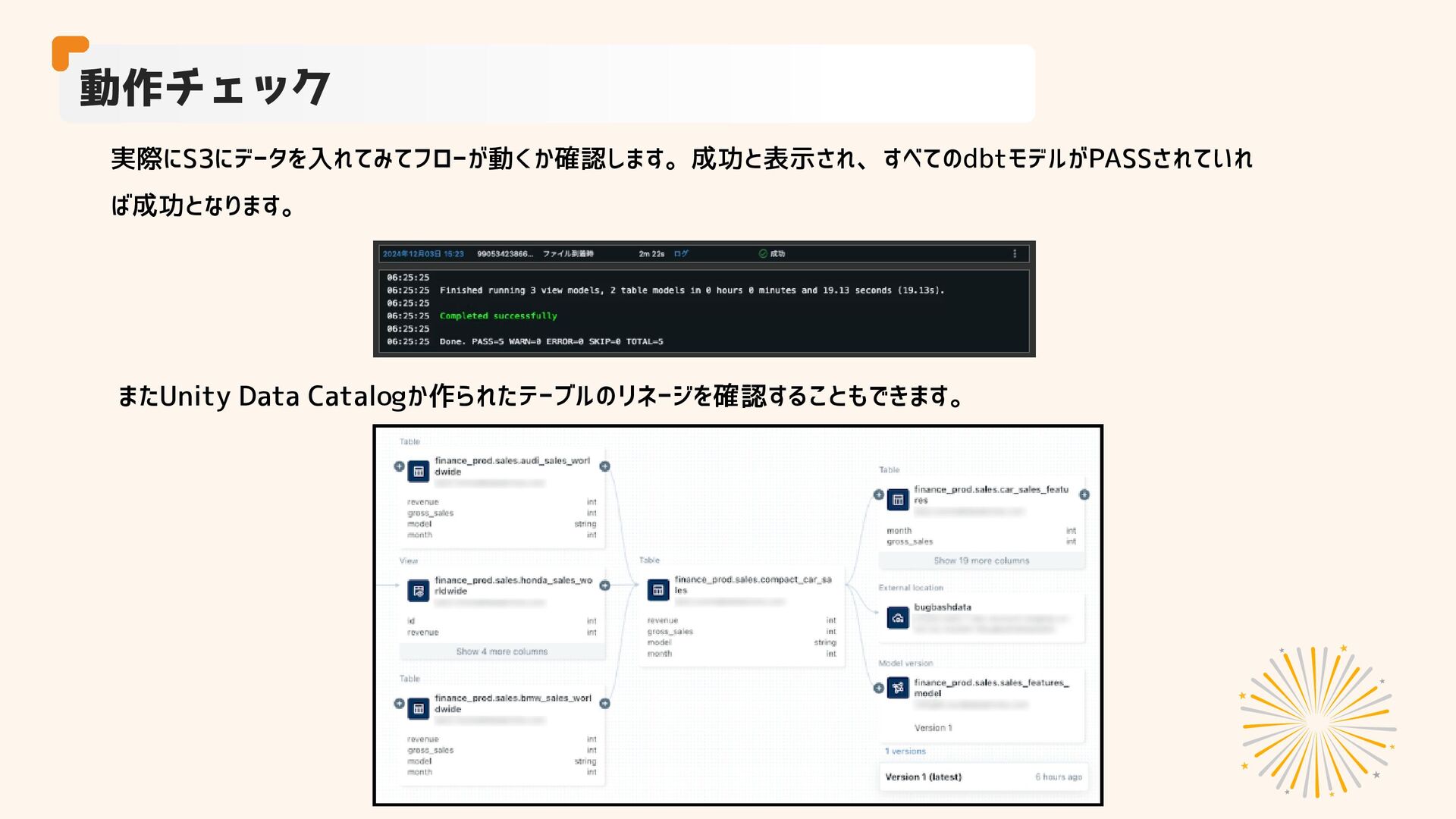
実際にS3にデータを入れてみてフローが動くか確認します。成功と表示され、すべてのdbtモデルがPASSされていれ ば成功となります。 動作チェック またUnity Data Catalogか作られたテーブルのリネージを確認することもできます。
質問タイム 05
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}