Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Don't try to tame your autoscalers, tame Tortoi...
Search
sanposhiho
December 13, 2023
840
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Don't try to tame your autoscalers, tame Tortoises!
Japan FinOps Meetup:
https://mercari.connpass.com/event/302744/
sanposhiho
December 13, 2023
More Decks by sanposhiho
See All by sanposhiho
Understanding the Kubernetes Scheduler: Internals, Roadmap, and Contributions
sanposhiho
1
160
kube-scheduler: from 101 to the frontier
sanposhiho
1
290
A Tale of Two Plugins: Safely Extending the Kubernetes Scheduler with WebAssembly
sanposhiho
0
260
人間によるKubernetesリソース最適化の”諦め” そこに見るリクガメの可能性
sanposhiho
2
2.2k
メルカリにおけるZone aware routing
sanposhiho
4
1.9k
A tale of two plugins: safely extending the Kubernetes Scheduler with WebAssembly
sanposhiho
1
630
メルカリにおけるプラットフォーム主導のKubernetesリソース最適化とそこに生まれた🐢の可能性
sanposhiho
1
1k
MercariにおけるKubernetesのリソース最適化のこれまでとこれから
sanposhiho
8
4.2k
The Kubernetes resource management and the behind systems in Mercari
sanposhiho
0
370
Featured
See All Featured
Getting science done with accelerated Python computing platforms
jacobtomlinson
2
360
Money Talks: Using Revenue to Get Sh*t Done
nikkihalliwell
0
420
[RailsConf 2023 Opening Keynote] The Magic of Rails
eileencodes
31
10k
Optimising Largest Contentful Paint
csswizardry
37
3.8k
Exploring anti-patterns in Rails
aemeredith
3
450
The Power of CSS Pseudo Elements
geoffreycrofte
82
6.5k
DevOps and Value Stream Thinking: Enabling flow, efficiency and business value
helenjbeal
1
270
AI: The stuff that nobody shows you
jnunemaker
PRO
9
850
Heart Work Chapter 1 - Part 1
lfama
PRO
8
36k
Docker and Python
trallard
47
4k
個人開発の失敗を避けるイケてる考え方 / tips for indie hackers
panda_program
123
22k
Public Speaking Without Barfing On Your Shoes - THAT 2023
reverentgeek
1
460
Transcript
1 Confidential Don't try to tame your autoscalers, tame Tortoises!
Kensei Nakada / @sanposhiho
2 Mercari JP Platform team / 2022卒新卒 Kubernetes approver (SIG-Scheduling)
Kubernetes Contributor award 2022/2023 winner Kensei Nakada / sanposhiho
3 Kubernetes Cluster Overview Workloads on cluster + FinOps
4 Kubernetesクラスター概要 - GKEを使用 (Standard mode) - 一つのClusterで、Mercari/Merpayほぼ全てのWorkloadが動いている - PlatformチームがCluster
adminとして運用
5 Workload について - ほとんどがGoで実装されたWorkload - Istioを一部namespaceで使用し、sidecarが存在
6 FinOps! - 直近メルカリでは全社的な目標としてFinOpsを掲げている - Platformチームでもインフラリソースの効率化を推進 - 殆どのサービスが乗っているのでインパクトが超絶大きい - あくまでも安全性を担保しつつ、リソースの効率化を行う必要がある
7 Autoscalers? Kubernetesには以下のオートスケーラーが存在 • HorizontalPodAutoscaler: Podの負荷があがればPodの数を増やす。 • VerticalPodAutoscaler: Podの負荷が上がればPodが使用できるリソース を増やす
8 HPAの例 このように、Containerに対して 閾値を設定すると、HPAが自動 でそれに近いリソース使用率に 維持してくれる minReplicas とよばれる、最低 Pod数を決めるパラメーター など
その他細かいものも多く存在
9 メルカリの Kubernetes リソース最適化の今 • Kubernetes リソース最適化にはKubernetesに関わる深い知識が必要 • アプリケーション開発チーム全員にその知識を求めるのは現実的ではない •
→ Platformがリソース最適化のためのツールやガイドラインの提供を行ってい る
10 Resource Recommender Resource Recommenderと呼ばれるSlack botが動作している → リソース最適化を簡略化することを目標としている Hoge deployment
appcontainer XXX XXX
11 HPA最適化? • 前述のようにCPUはHPAに管理されている →HPAを最適化しない限り、CPU利用率は上がらない • HPAの最適化 = 閾値を上げれば良い? →実際は閾値を上げるだけでリソース使用率が上がるとは限らない
• Resource recommenderはHPAの最適化には対応しておらず、未だにユー ザーが自身の判断で最適化を行う必要がある
12 HPA最適化における考慮点
13 クラスター上のすべてのサービスにHPAを作成すれば、クラスターのリソース使用率 も上がる? ↓ 現実はそれほど簡単ではない • HPAの各種パラメーターの調整 • リソースのRequestの調整 をしないとHPAがパワーを発揮できない
HPAの難しさ
14 1) Incident時のHPAのScale in問題 - UpstreamのサービスがIncidentで落ちる - Downstreamのサービスに通信が行かなくなる - DownstreamのサービスのCPU使用量が下がる
この場合にDownstreamのサービスではHPAによるScale inが発生する
15 1) Incident時のHPAのScale in問題 - UpstreamのサービスがIncidentで落ちる - Downstreamのサービスに通信が行かなくなる - DownstreamのサービスのCPU使用量が下がる
この場合にDownstreamのサービスではHPAによるScale inが発生する ↓ Upstreamのサービスが復活した時に、一気にトラフィックが流れてDownstream のサービスが死ぬというインシデントが稀に発生
16 高めにminReplicasを設定すればよくね? minReplicasを高めに設定しておけば、 確かに解決になるがHPAの機能性を損なうし💸💸💸につながるので❌ 例: Pods数が通常のオフピーク時に3個/ピーク時に20個、targetUtilizationが70%の場合、ピーク 時に障害という最悪のケースを考慮すると、minReplicasを14に設定する必要がある
17 dynamic MinReplicasの実装 1週間前の同じ時間のレプリカ数の1/2のレプリカ数をsuggestする DatadogMetricsを全てのHPAに導入 ↓ HPAは複数の指標のレプリカ数の提案から一番大きいものを採用するため、 Incidentの時など通常に比べて異常にレプリカ数が減少している時にのみ動作す る
18 2) HPAがレプリカ増やしすぎる問題 Deploymentのresource requestが小さすぎると、ピーク時のレプリカ数がとても 多くなる。
19 2) HPAがレプリカ増やしすぎる問題 Deploymentのresource requestが小さすぎると、ピーク時のレプリカ数がとても 多くなる。 この際、Podのサイズを大きくし、レプリカ数を小さく抑えた方が、省エネになる場合 がある。 とあるサービスでは、この最適化を行うことで、リソースコストが40%減少 (ピーク時のレプリカ数は200->30に変化)
20 3) HPAがレプリカ全然増やさない問題 Deploymentのresource requestが大きすぎると、HPAを設定していても 「レプリカ数がずっとminReplicasで制限されてる」みたいなケースが起こりうる この場合、HPAが機能していないに等しいためCPU使用率も低くなる
21 3) HPAがレプリカ全然増やさない問題 この場合、 - Podのサイズを十分に小さくしてHPAが動作するようにする - VPAにCPUも任せる 等を考える必要がある
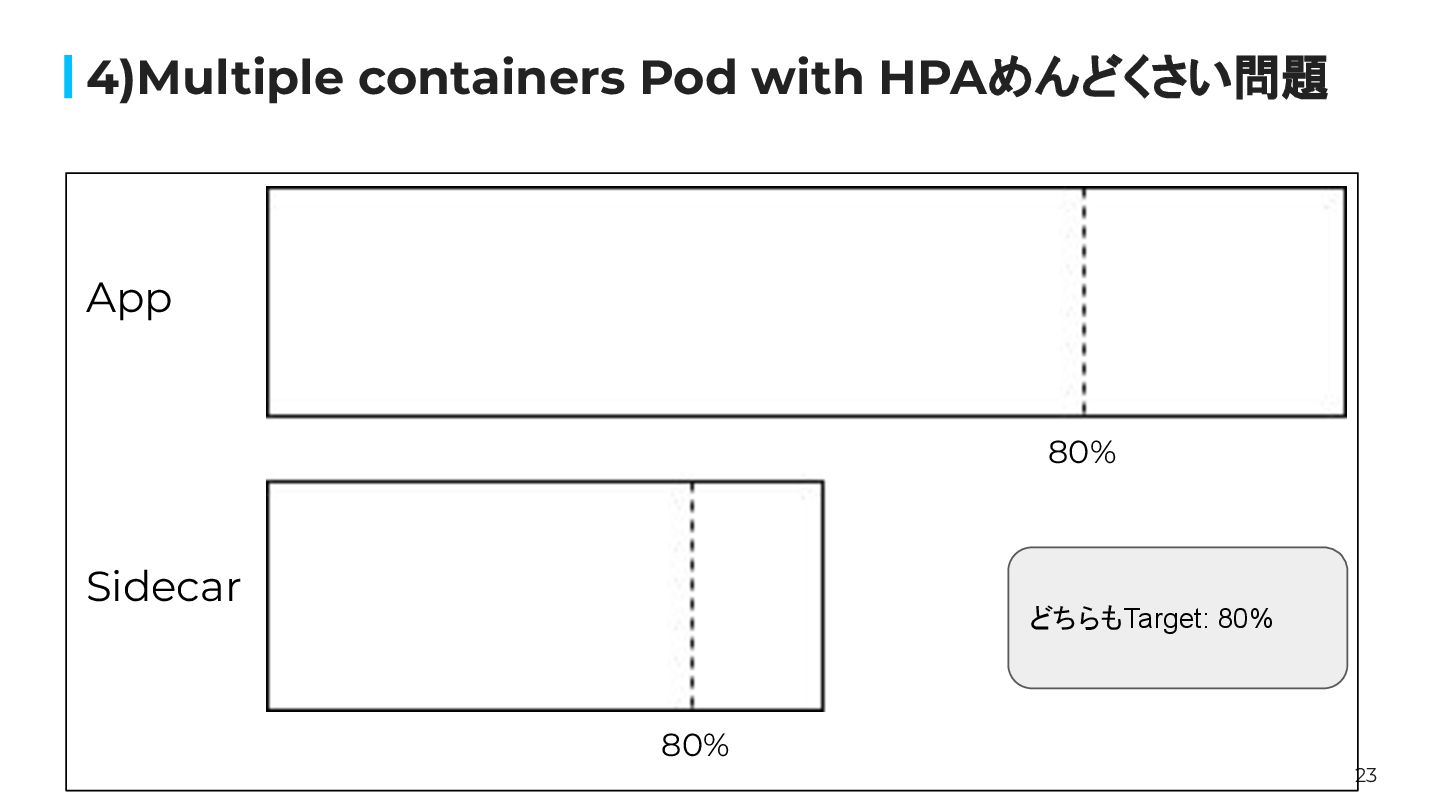
22 4) Multiple containers Pod with HPAめんどくさい問題 例: HPAのtarget utilization:
sidecar: 80%/app container: 80% この場合、HPAはどちらかのcontainerのresource utilizationが80%を 大きく超えた時にスケールアウトを行う。 ↓ これによって、sidecar or app のどちらかのリソースが常に余っているということに なり得る。
23 4)Multiple containers Pod with HPAめんどくさい問題 80% 80% App Sidecar
どちらもTarget: 80%
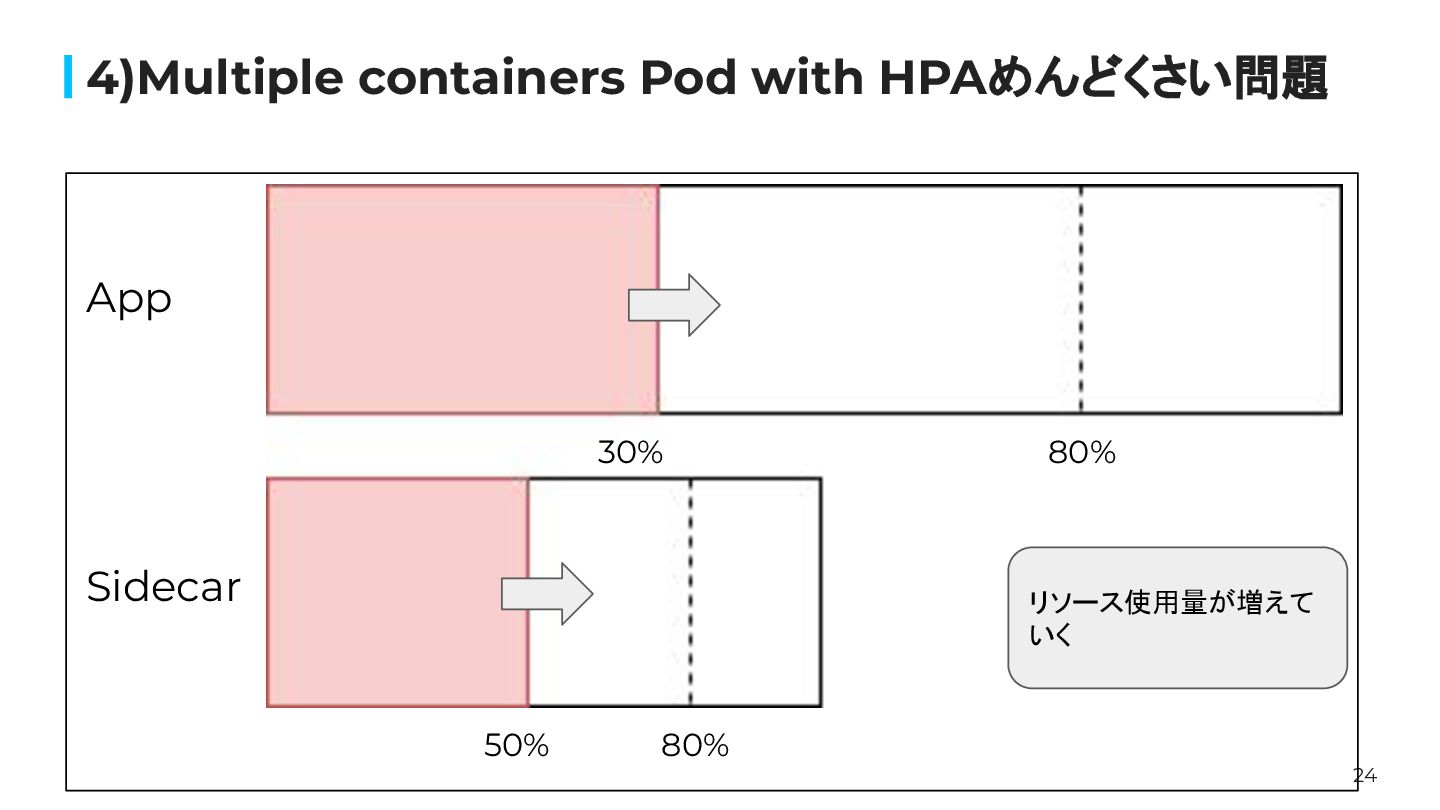
24 4)Multiple containers Pod with HPAめんどくさい問題 80% 80% App Sidecar
リソース使用量が増えて いく 50% 30%
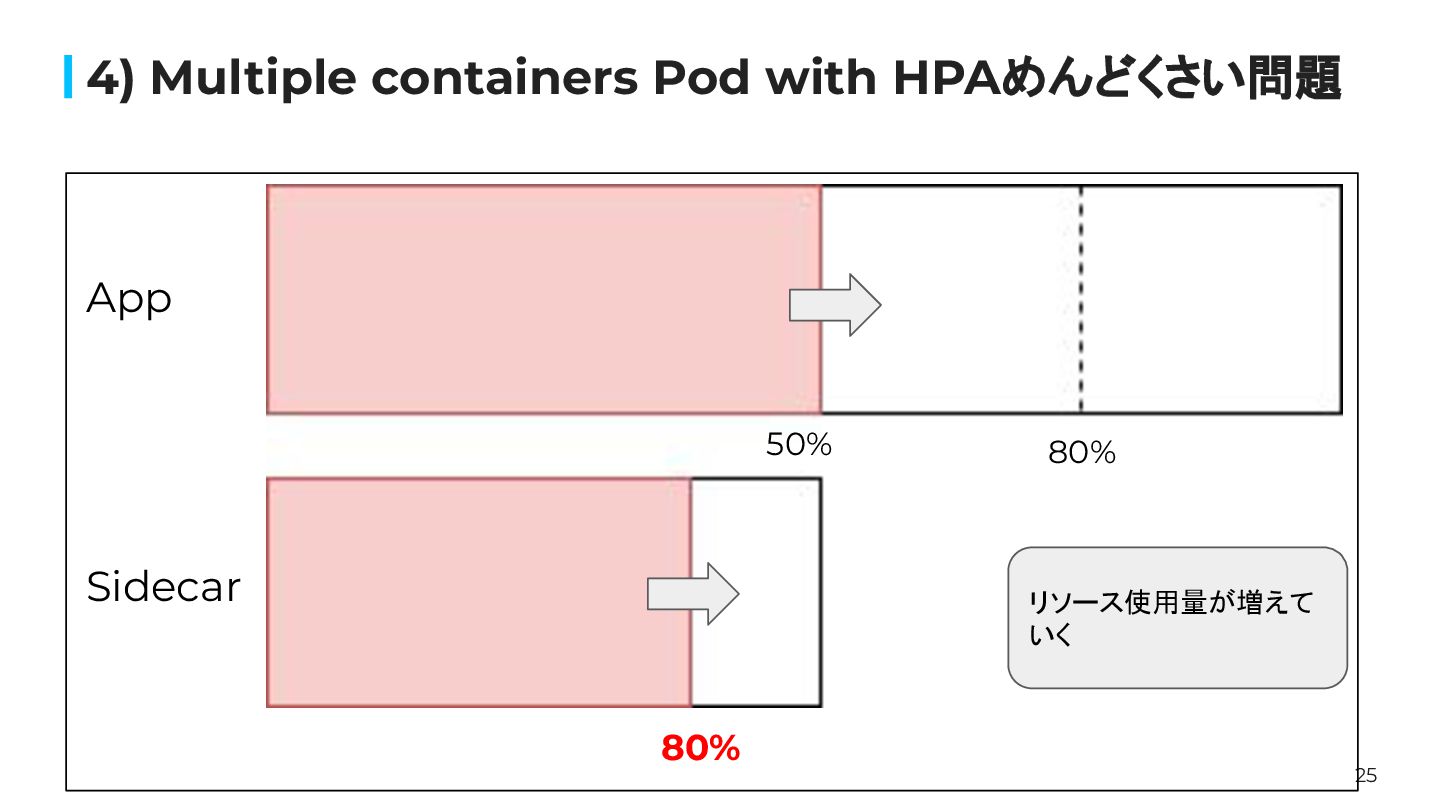
25 4) Multiple containers Pod with HPAめんどくさい問題 80% 80% App
Sidecar リソース使用量が増えて いく 50%
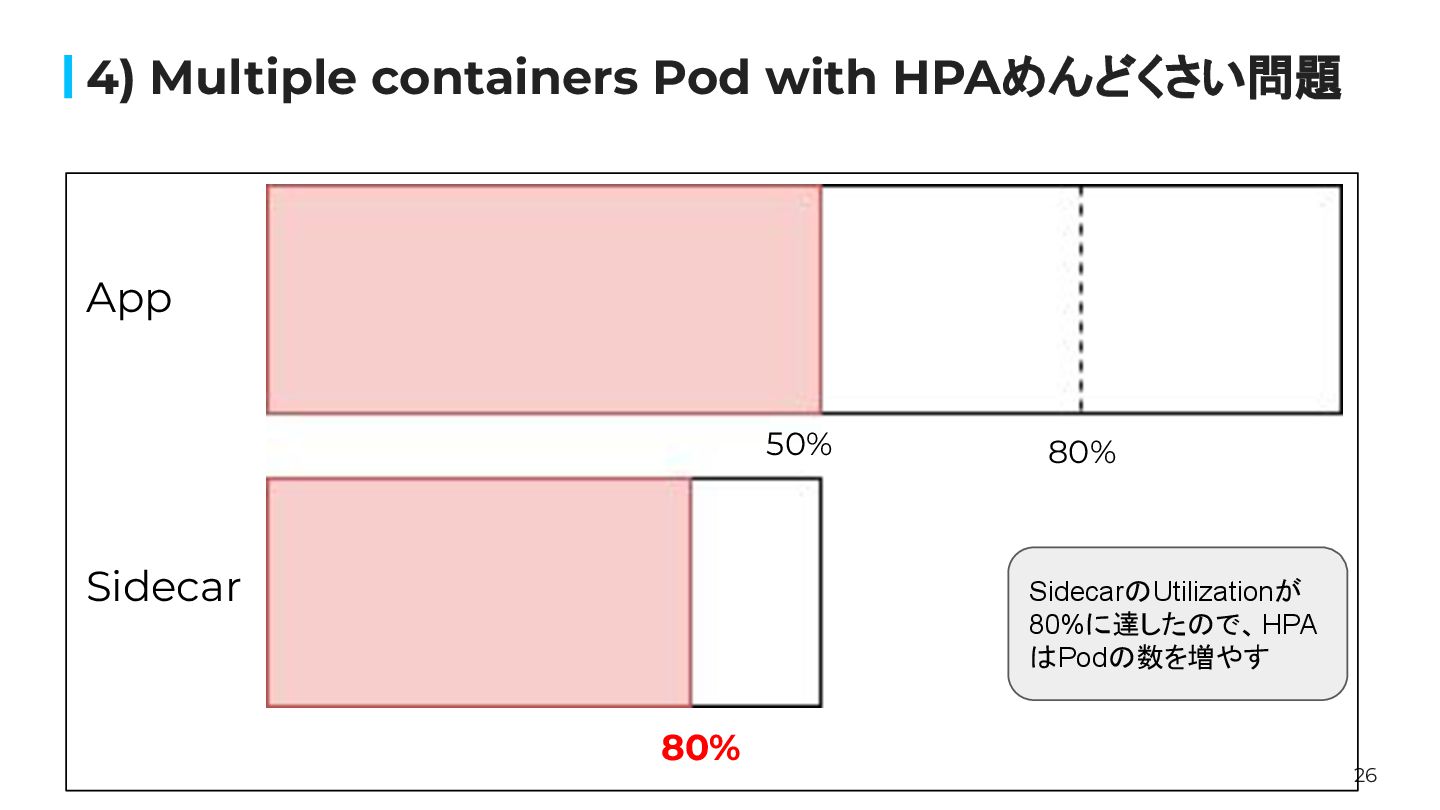
26 4) Multiple containers Pod with HPAめんどくさい問題 80% 80% App
Sidecar SidecarのUtilizationが 80%に達したので、HPA はPodの数を増やす 50%
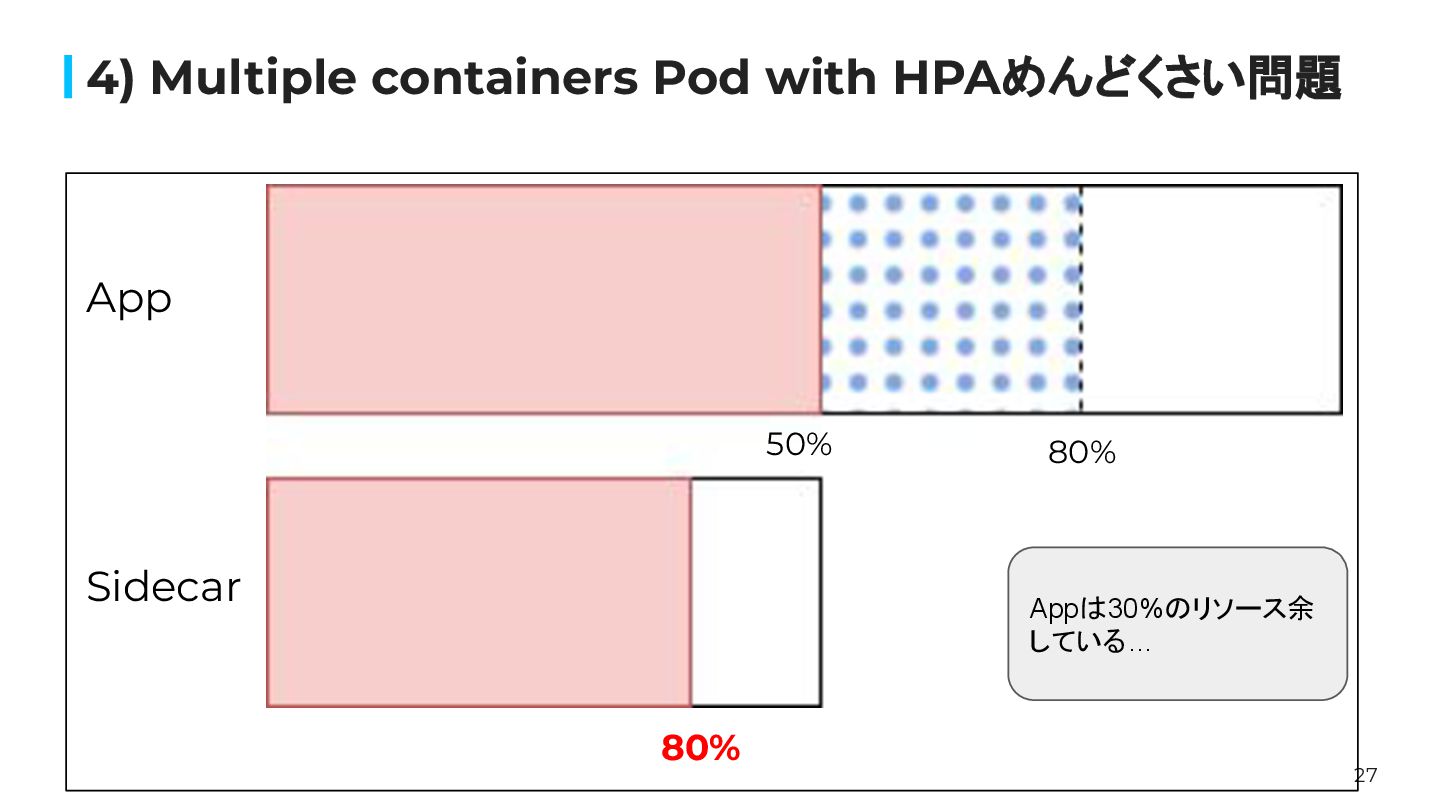
27 4) Multiple containers Pod with HPAめんどくさい問題 80% 80% App
Sidecar 50% Appは30%のリソース余 している…
28 4) Multiple containers Pod with HPAめんどくさい問題 HPAを設定していても、CPU 使用量を確認しつつ、片方のcontainerの使用量が 常に低い場合、contianerのsizeを調整する必要がある。
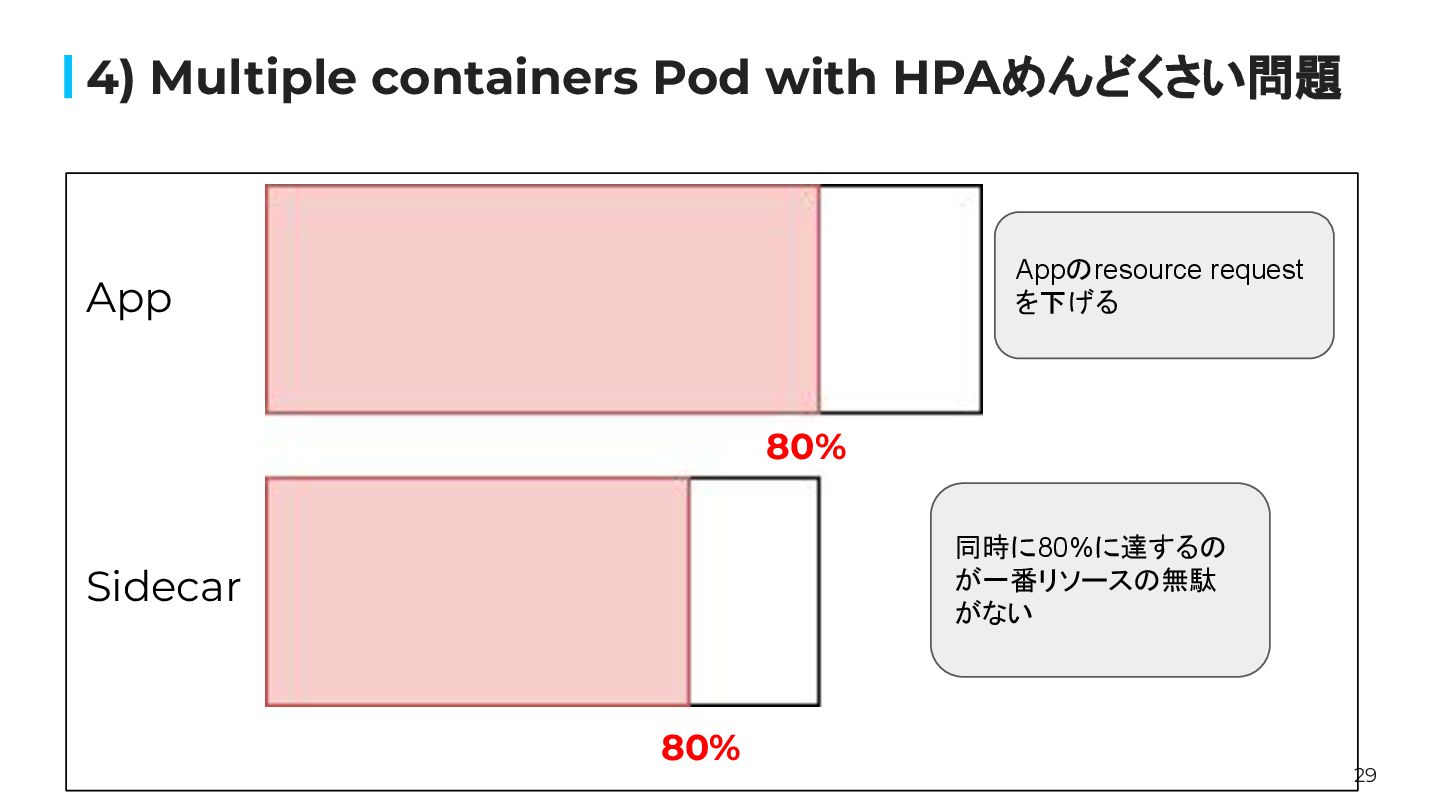
29 4) Multiple containers Pod with HPAめんどくさい問題 80% 80% App
Sidecar 80% Appのresource request を下げる 同時に80%に達するの が一番リソースの無駄 がない
30 5) HPAのtarget utilization決めるの難しすぎ問題 メルカリでは、HPAのtarget utilizationは70%-80%に設定されていることが多 い。 ↓ なぜ20%-30%の余分なCPUを与えておく必要があるのか?
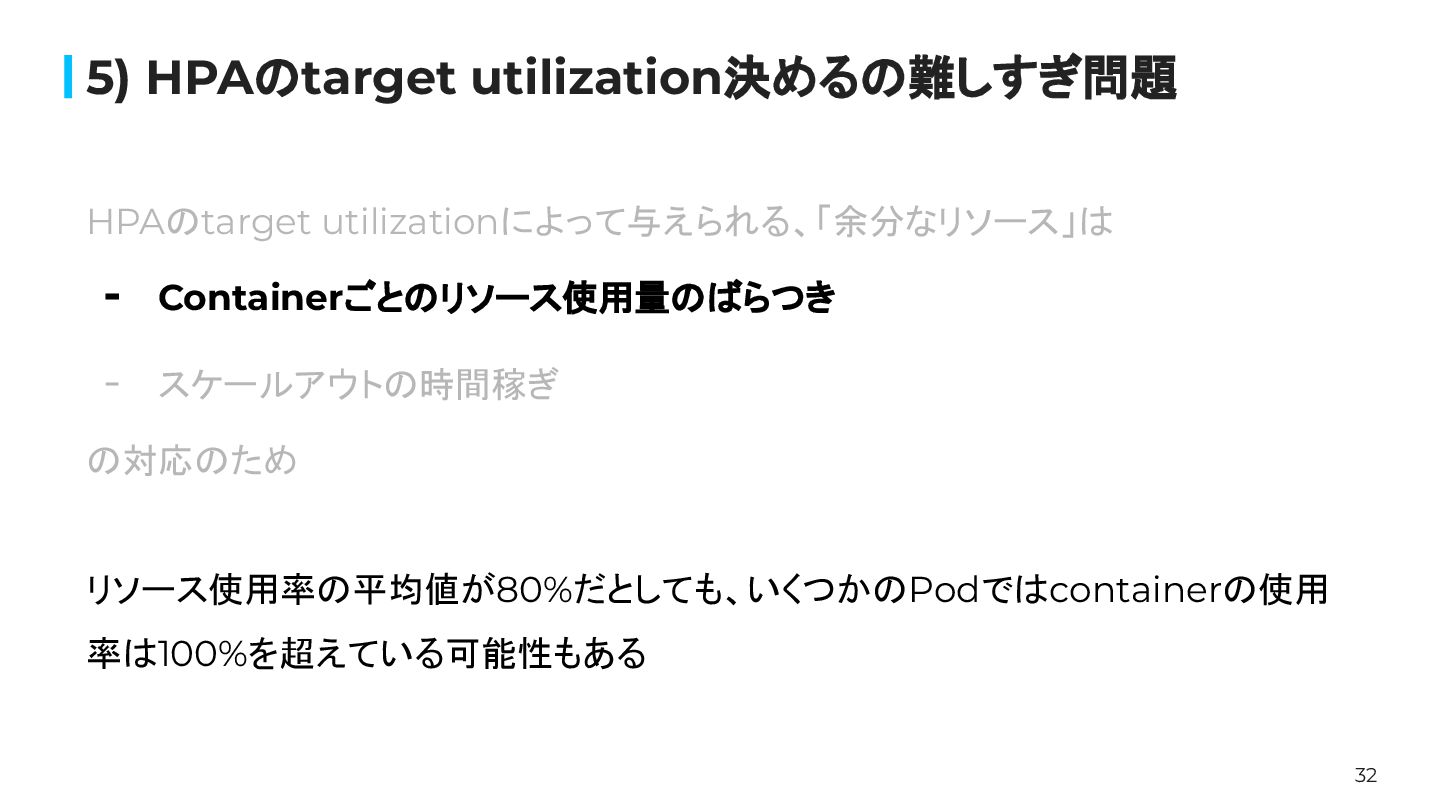
31 5) HPAのtarget utilization決めるの難しすぎ問題 HPAのtarget utilizationによって与えられる、「余分なリソース」は - Containerごとのリソース使用量のばらつき - スケールアウトの時間稼ぎ
の対応のため
32 5) HPAのtarget utilization決めるの難しすぎ問題 HPAのtarget utilizationによって与えられる、「余分なリソース」は - Containerごとのリソース使用量のばらつき - スケールアウトの時間稼ぎ
の対応のため リソース使用率の平均値が80%だとしても、いくつかのPodではcontainerの使用 率は100%を超えている可能性もある
33 5) HPAのtarget utilization決めるの難しすぎ問題 HPAのtarget utilizationによって与えられる、「余分なリソース」は - Containerごとのリソース使用量のばらつき - スケールアウトの時間稼ぎ
の対応のため → (次スライド)
34 5) HPAのtarget utilization決めるの難しすぎ問題 0. トラフィックが増えるにつれて、リソース使用量が増えていく 1. リソース使用率が閾値に達する 2. HPAが気がついてスケールアウトを実行する
3. (Cluster AutoscalerがNodeを増やす) 4. 新しいPodが作られ実際に動き出し、READYになる (1) → (4)にかかる時間の間もリソース使用量が増えているため、 この間の時間稼ぎの必要性
35 5) HPAのtarget utilization決めるの難しすぎ問題 - Containerごとのリソース使用率のばらつき - トラフィックの増加のスピード - HPA
controllerのリコンサイルの間隔 - (Nodeに空きができるまでの時間 (via Cluster Autoscaler) - Podが動き出すまでにかかる時間 これらを踏まえて、適切な「余分リソース」をtarget utilizationを通してPodに与え る必要がある
36 5) HPAのtarget utilization決めるの難しすぎ問題 - Containerごとのリソース使用率のばらつき - トラフィックの増加のスピード - HPA
controllerのリコンサイルの間隔 - (Nodeに空きができるまでの時間 (via CA or overprovisioning Pods)) - Podが動き出すまでにかかる時間 これらを踏まえて、適切な「余分リソース」をtarget utilizationを通してPodに与え る必要がある 無理じゃね…?
37 ここまでの話 1. Incident時のHPAのScale in問題 2. HPAがレプリカ増やしすぎる問題 3. HPAがレプリカ全然増やさない問題 4.
Multiple containers Pod with HPAめんどくさい問題 5. HPAのtarget utilization決めるの難しすぎ問題
38 ここまでの話 1. Incident時のHPAのScale in問題 2. HPAがレプリカ増やしすぎる問題 3. HPAがレプリカ全然増やさない問題 4.
Multiple containers Pod with HPAめんどくさい問題 5. HPAのtarget utilization決めるの難しすぎ問題 無理じゃね…?
39 🐢を使用したWorkload Autoscaling
40 mercari/tortoise
41 これからはリクガメに任せる時代です。 過去のWorkloadの振る舞いを記 録し、HPA, VPA, Pod resource request/limitの全てをいい感じに 調節してくれる Kubernetes
controller https://github.com/mercari/to rtoise
42 mercari/tortoiseのモチベ - 人間の手で先ほどの最適化を全て行うのは厳しい - 最適化後もアプリケーションの変化に伴い、定期的な見直しが必要 - 最適化の責務をアプリケーション開発チームからプラットフォームチームに移す → Tortoiseをセットアップさえしてくれれば、その先アプリケーション開発チー
ムはリソース最適化について考える必要がない - Datadog metricを含む外部サービスにautoscalingを依存させたくない → 外部サービスの障害の間、HPAが正しく動かず眠れぬ夜を過ごすことにな る
43 Simplified configuration apiVersion: autoscaling.mercari.com/v1alpha1 kind: Tortoise metadata: name: nginx-tortoise
namespace: tortoise-poc spec: updateMode: Auto targetRefs: deploymentName: nginx-deployment Deployment name ONLY!
44 mercari/tortoiseの機能 - HPA optimization: 前章で「無理じゃね…?」と言ってたやつを全部自動で行う - VPA optimization: HPAとVPAがうまいこと同時に動けるように調整
- Emergency mode: 緊急時のスケールアップを担当
45 Horizontal Scaling 過去の振る舞いを元にHPAを調整し続ける - minReplicas: ½ * {過去数週間の同 時刻の最大レプリカ数}
- maxReplicas: 2 * {過去数週間の同時 刻の最大レプリカ数} - HPA target utilization: 推奨の値を計 算し、設定
46 Horizontal Scaling 過去の振る舞いを元にHPAを調整し続ける - minReplicas: ½ * {過去数週間の同 時刻の最大レプリカ数}
- maxReplicas: 2 * {過去数週間の同時 刻の最大レプリカ数} - HPA target utilization: 推奨の値を計 算し、設定 前述のdynamic minReplicasと 同様の振る舞い
47 [復習] Incident時のHPAのScale in問題 - UpstreamのサービスがIncidentで落ちる - Downstreamのサービスに通信が行かなくなる - DownstreamのサービスのCPU使用量が下がる
この場合にDownstreamのサービスではHPAによるScale inが発生する
48 Horizontal Scaling 過去の振る舞いを元にHPAを調整し続ける - minReplicas: ½ * {過去数週間の同 時刻の最大レプリカ数}
- maxReplicas: 2 * {過去数週間の同 時刻の最大レプリカ数} - HPA target utilization: 推奨の値を計 算し、設定 Bug等の想定外ケースの際に、 無制限にscale upするのを防ぐ
49 Horizontal Scaling 過去の振る舞いを元にHPAを調整し続ける - minReplicas: ½ * {過去数週間の同 時刻の最大レプリカ数}
- maxReplicas: 2 * {過去数週間の同時 刻の最大レプリカ数} - HPA target utilization: 推奨の値を 計算し、設定 How?
50 [復習] HPAのtarget utilization決めるの難しすぎ問題 HPAのtarget utilizationによって与えられる、「余分なリソース」は - Containerごとのリソース使用量のばらつき - スケールアウトの時間稼ぎ
の対応のため
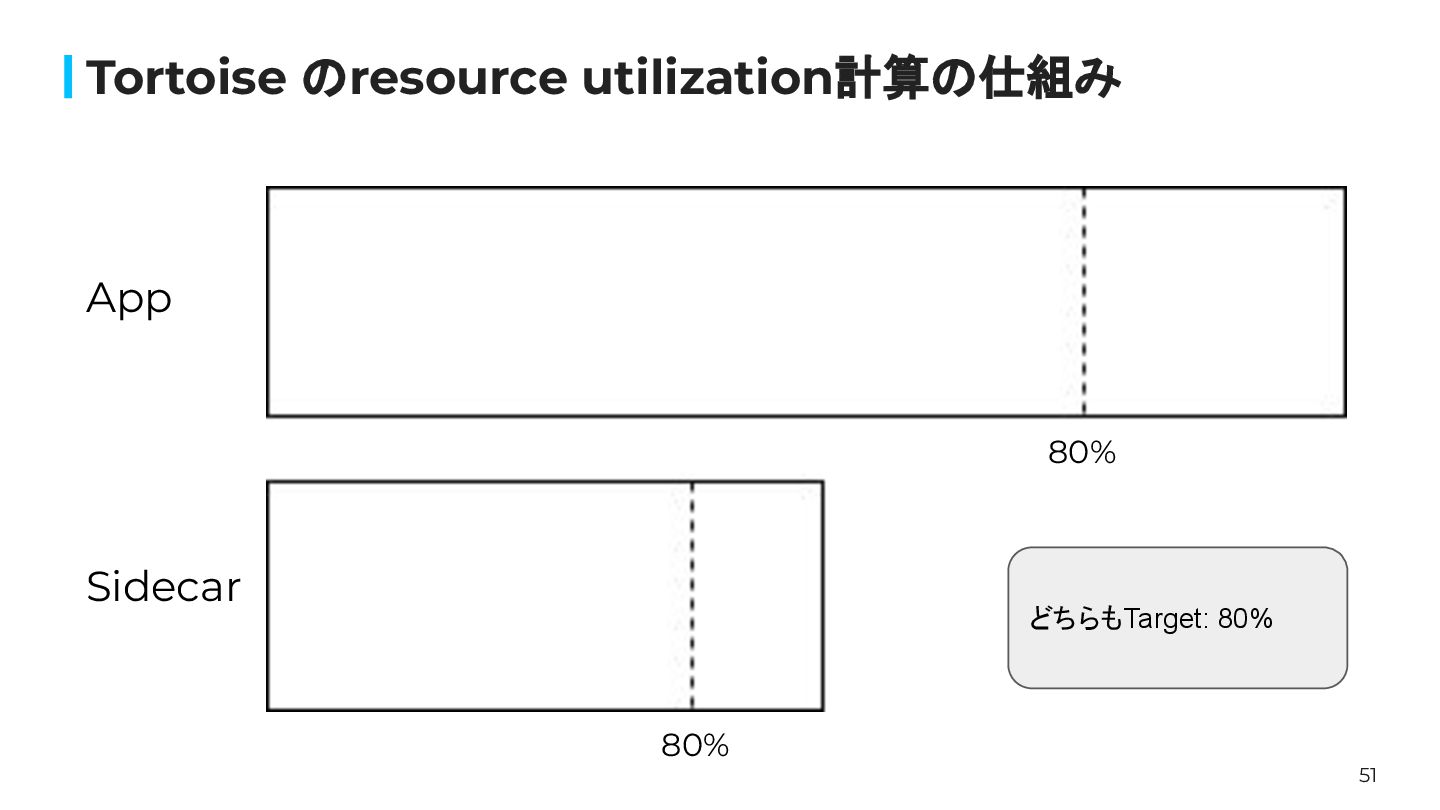
51 Tortoise のresource utilization計算の仕組み 80% 80% App Sidecar どちらもTarget: 80%
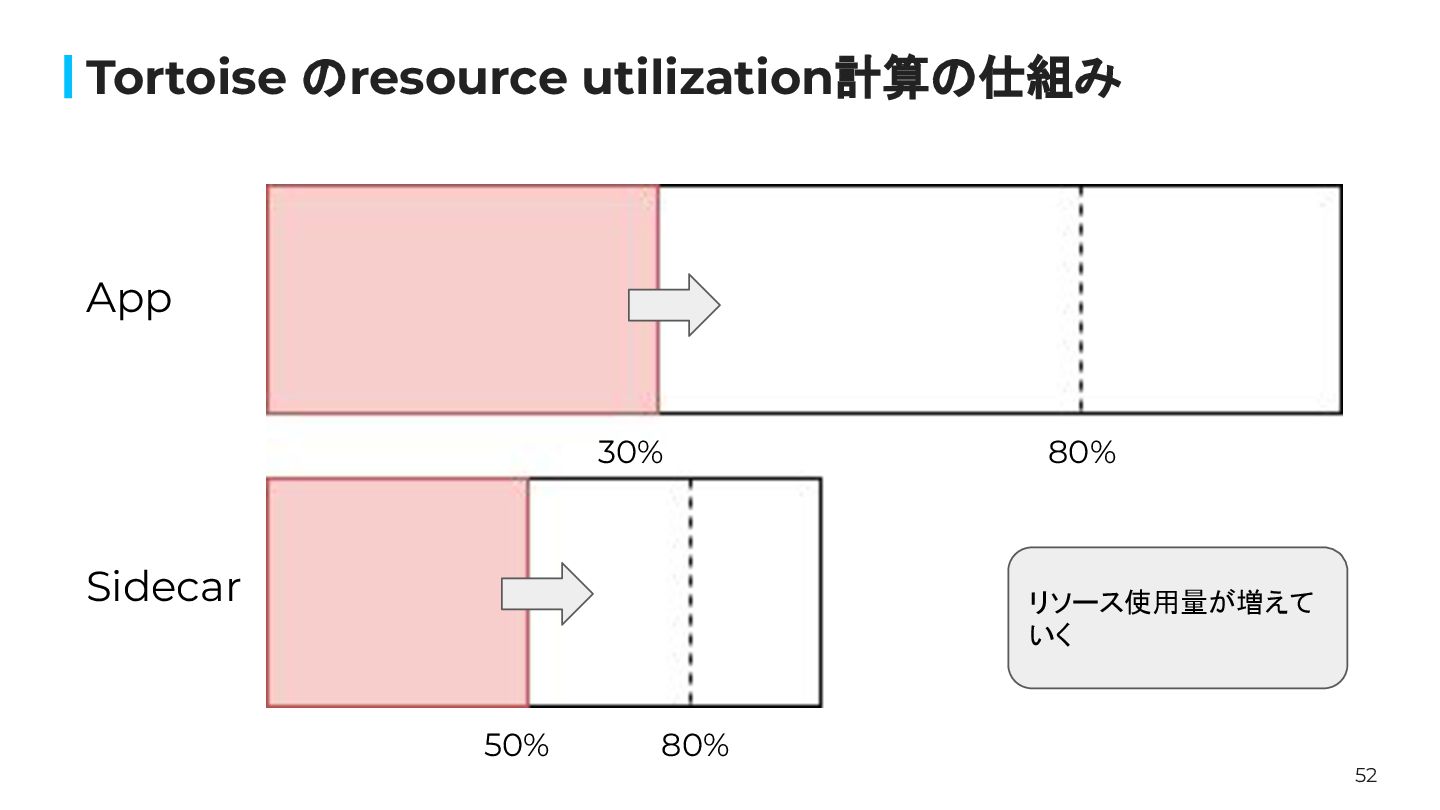
52 Tortoise のresource utilization計算の仕組み 80% 80% App Sidecar リソース使用量が増えて いく
50% 30%
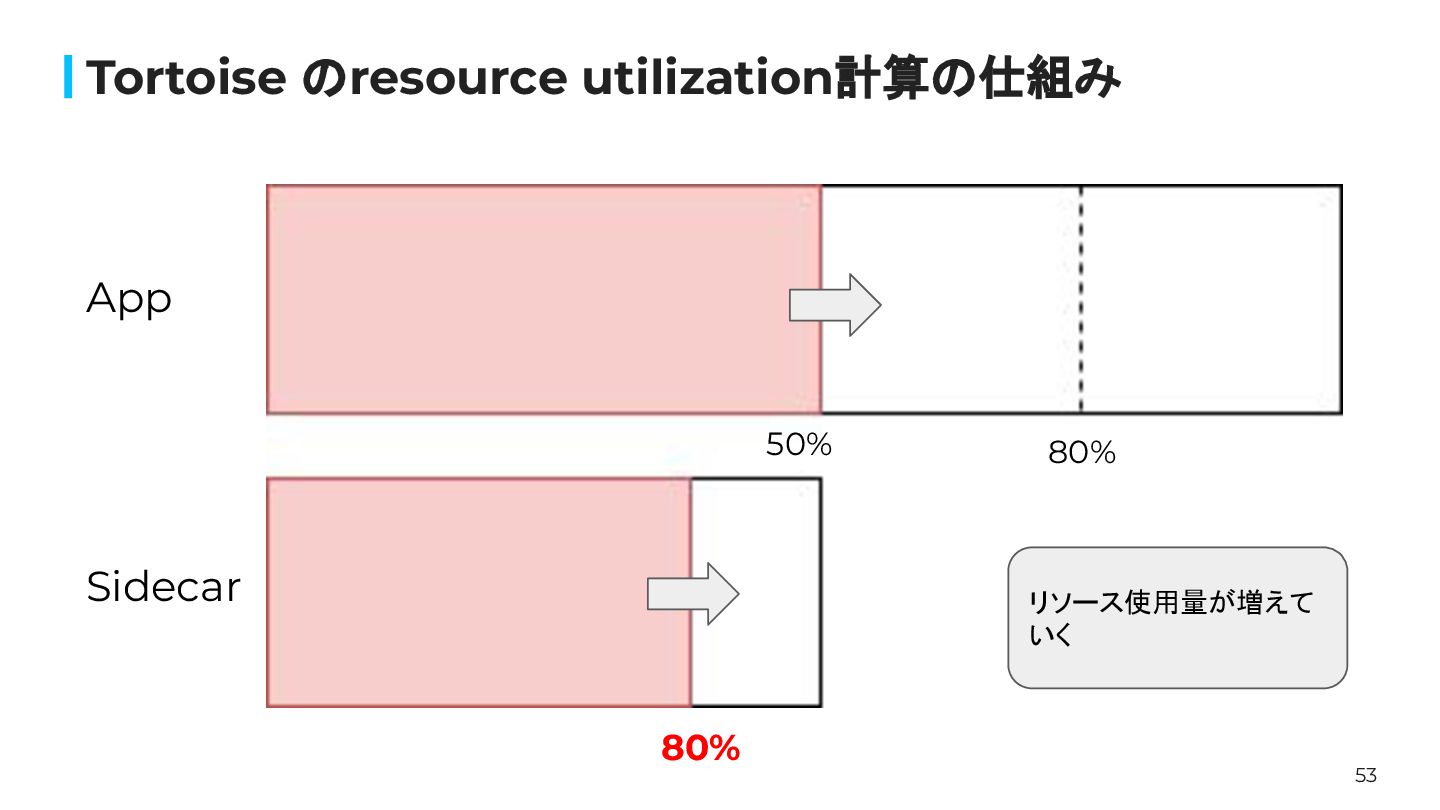
53 Tortoise のresource utilization計算の仕組み 80% 80% App Sidecar リソース使用量が増えて いく
50%
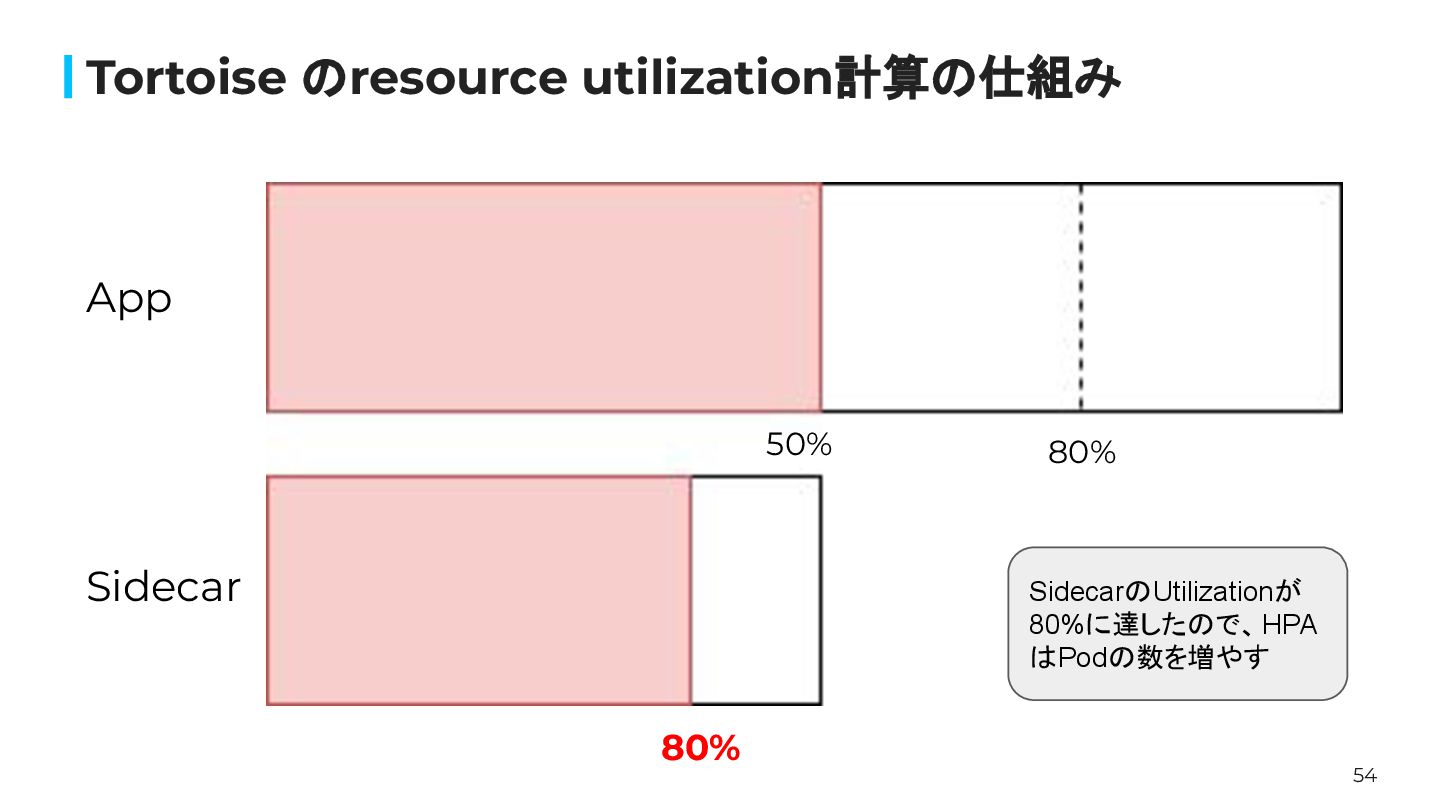
54 Tortoise のresource utilization計算の仕組み 80% 80% App Sidecar SidecarのUtilizationが 80%に達したので、HPA
はPodの数を増やす 50%
55 [復習] HPAのtarget utilization決めるの難しすぎ問題 HPAのtarget utilizationによって与えられる、「余分なリソース」は - Containerごとのリソース使用量のばらつき - スケールアウトの時間稼ぎ
の対応のため
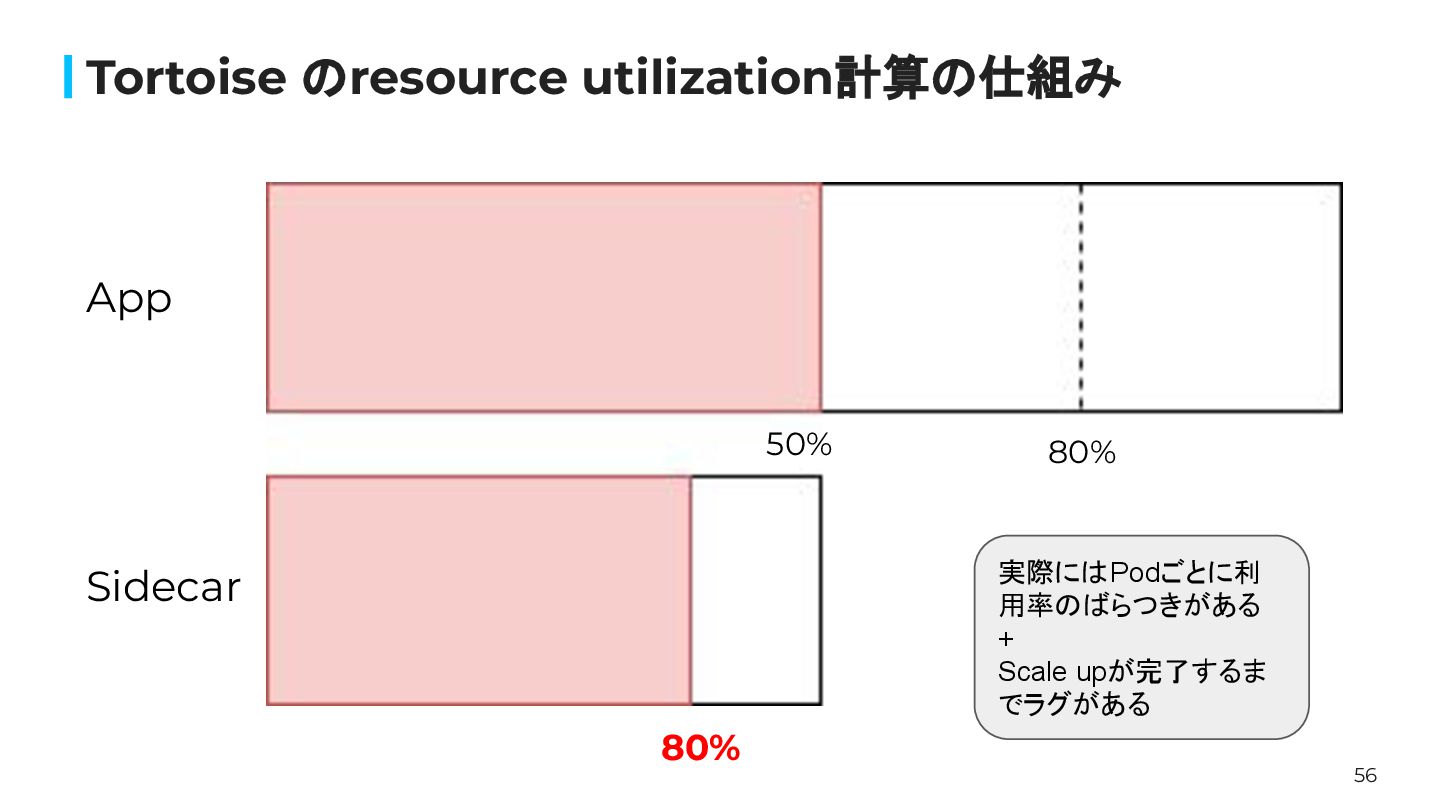
56 Tortoise のresource utilization計算の仕組み 80% 80% App Sidecar 50% 実際にはPodごとに利
用率のばらつきがある + Scale upが完了するま でラグがある
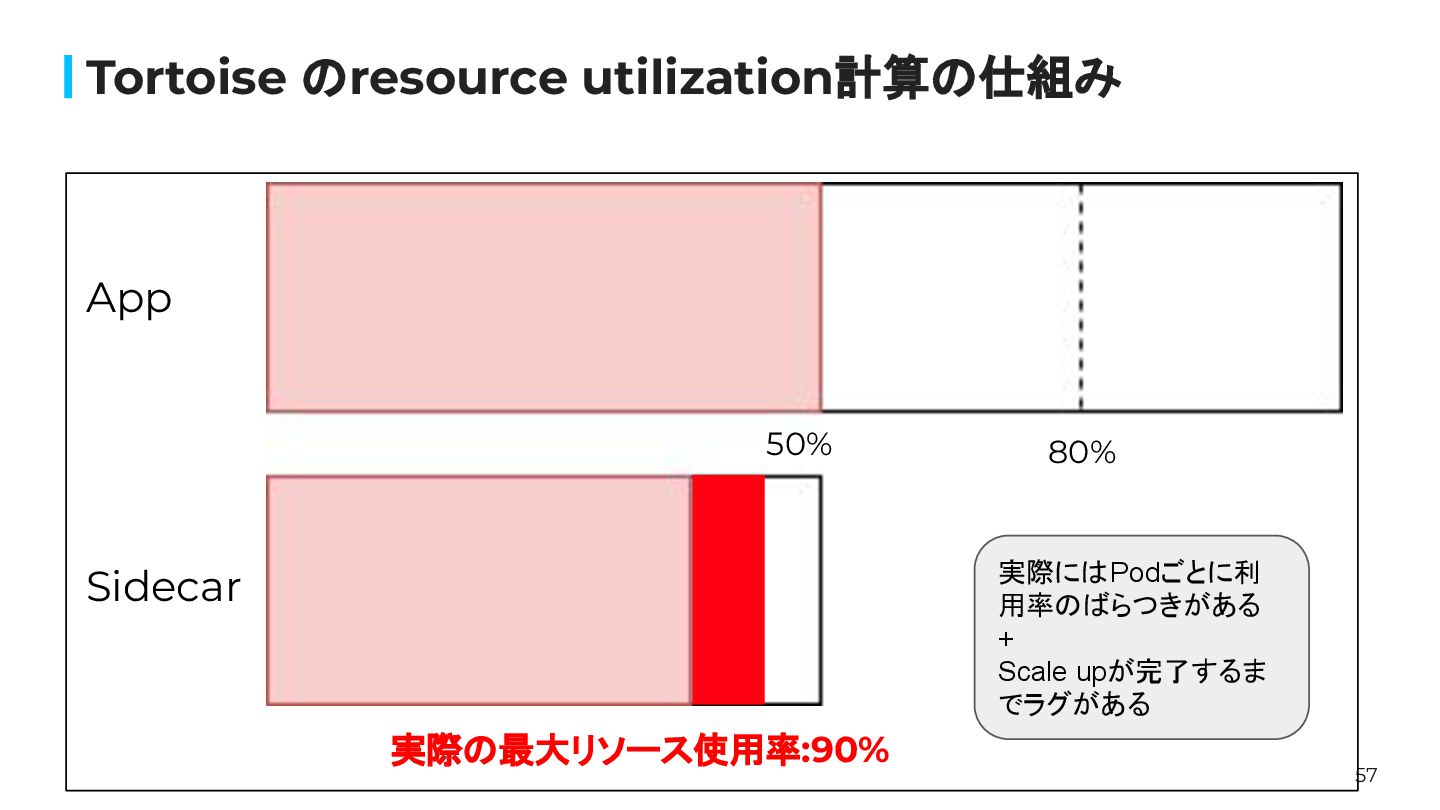
57 Tortoise のresource utilization計算の仕組み 80% 実際の最大リソース使用率:90% App Sidecar 50% 実際にはPodごとに利
用率のばらつきがある + Scale upが完了するま でラグがある
58 VPAがどのように推奨値を計算しているか 過去のリソースの使用量を記録 ↓ p90 - p95 (+ OOMKilledを考慮) の値を「十分なリソースの量」としてResource
requestに適応
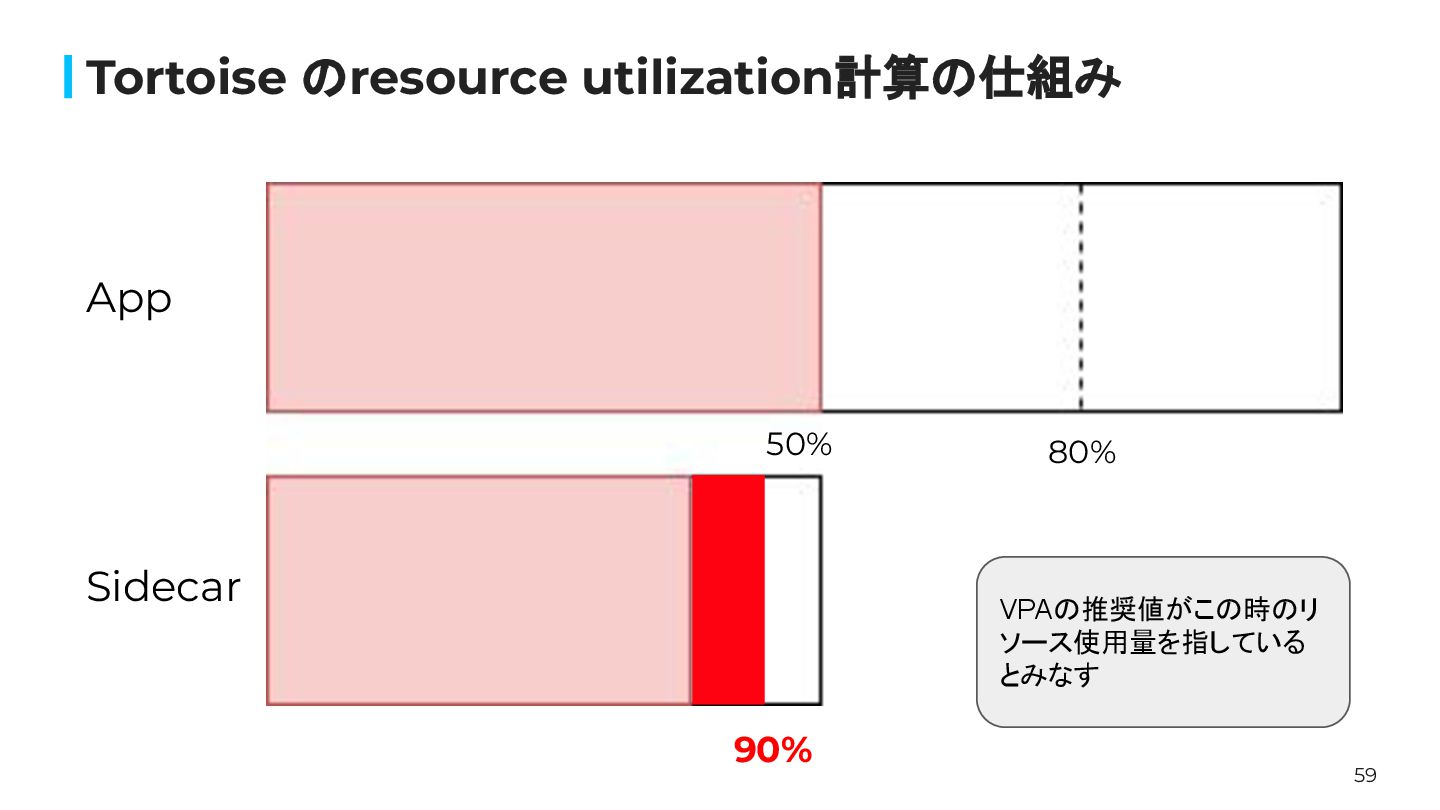
59 Tortoise のresource utilization計算の仕組み 80% 90% App Sidecar VPAの推奨値がこの時のリ ソース使用量を指している
とみなす 50%
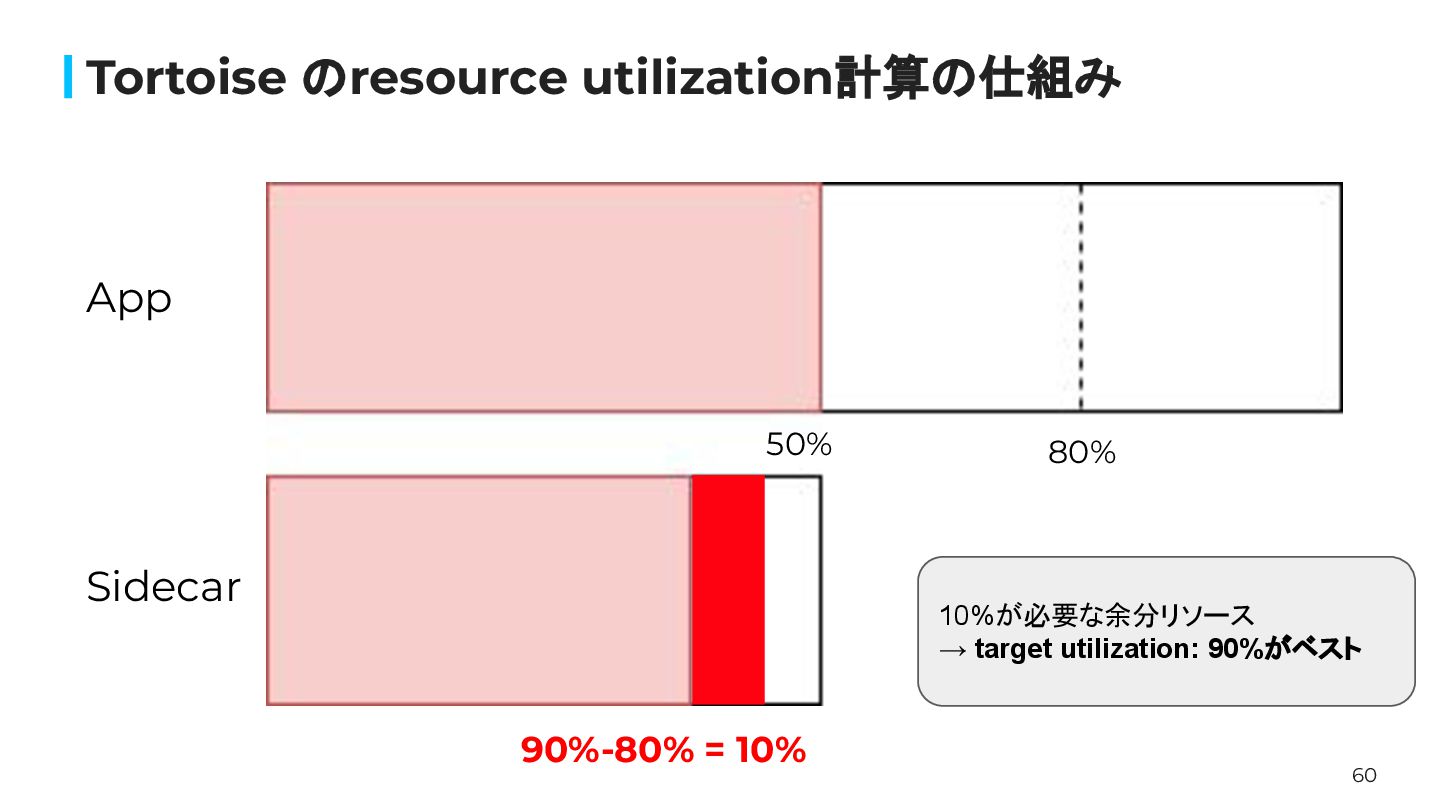
60 Tortoise のresource utilization計算の仕組み 80% 90%-80% = 10% App Sidecar
10%が必要な余分リソース → target utilization: 90%がベスト 50%
61 Horizontal Scaling 過去の振る舞いからコンテナサイズも調整: - ほぼ常にレプリカ数が3で、リソース使用率 が小さい時、一時的にVerticalに切り替 え、HPAが動作するようにする - 現在のコンテナサイズが小さく、かつピーク
時にレプリカ数が多すぎる傾向にあると、コ ンテナサイズを大きくする - 片方のコンテナのリソース使用率が常に小 さい時、そのコンテナサイズを小さくする
62 Horizontal Scaling 過去の振る舞いからコンテナサイズも調整: - ほぼ常にレプリカ数が3で、リソース使用率 が小さい時、一時的にVerticalに切り替 え、HPAが動作するようにする - 現在のコンテナサイズが小さく、かつピーク
時にレプリカ数が多すぎる傾向にあると、コ ンテナサイズを大きくする - 片方のコンテナのリソース使用率が常に小 さい時、そのコンテナサイズを小さくする
63 [復習] HPAがレプリカ全然増やさない問題 Deploymentのresource requestが大きすぎると、HPAを設定していても 「レプリカ数がずっとminReplicasで制限されてる」みたいなケースが起こりうる この場合、HPAが機能していないに等しいためCPU使用率も低くなる
64 Horizontal Scaling 過去の振る舞いからコンテナサイズも調整: - ほぼ常にレプリカ数が3で、リソース使用率 が小さい時、一時的にVerticalに切り替 え、HPAが動作するようにする - 現在のコンテナサイズが小さく、かつピーク
時にレプリカ数が多すぎる傾向にあると、コ ンテナサイズを大きくする - 片方のコンテナのリソース使用率が常に小 さい時、そのコンテナサイズを小さくする
65 [復習] HPAがレプリカ増やしすぎる問題 Deploymentのresource requestが小さすぎると、ピーク時のレプリカ数がとても 多くなる。 この際、Podのサイズを大きくし、レプリカ数を小さく抑えた方が、省エネになる場合 がある。 とあるサービスでは、この最適化を行うことで、GKEコストが40%減少 (ピーク時のレプリカ数は200->30に変化)
66 Horizontal Scaling 過去の振る舞いからコンテナサイズも調整: - ほぼ常にレプリカ数が3で、リソース使用率 が小さい時、一時的にVerticalに切り替 え、HPAが動作するようにする - 現在のコンテナサイズが小さく、かつピーク
時にレプリカ数が多すぎる傾向にあると、コ ンテナサイズを大きくする - 片方のコンテナのリソース使用率が常に小 さい時、そのコンテナサイズを小さくする
67 [復習] Multiple containers Pod with HPAめんどくさい問題 例: HPAのtarget utilization:
sidecar: 80%/app container: 80% この場合、HPAはどちらかのcontainerのresource utilizationが80%を大きく超 えた時にスケールアウトを行う。 ↓ これによって、sidecar or app のどちらかのリソースが常に余っているということに なり得る。
68 [復習] Multiple containers Pod with HPAめんどくさい問題 80% 80% App
Sidecar 50% Appは30%のリソース余 している…
69 [復習] Multiple containers Pod with HPAめんどくさい問題 80% 80% App
Sidecar 80% Appのresource request を下げる 同時に80%に達するの が一番リソースの無駄 がない
70 Emergency mode 緊急時に一時的にレプリカ数を十分に 大きく変更してくれる - minReplicasをmaxReplicasと 同じ値に一時的に変更 - OFFにした際に、安全のため適切
にゆっくりスケールダウンを行う
71 Emergency mode apiVersion: autoscaling.mercari.com/v1alpha1 kind: Tortoise metadata: name: nginx-tortoise
namespace: tortoise-poc spec: updateMode: Emergency targetRefs: deploymentName: nginx-deployment ←
72 Emergency mode 緊急で十分にスケールアウトしたい時に使用する - 通常にはないようなトラフィックの増加を観測している場合 (テレビ, bot等) - インフラサイドのincidentが発生し、念の為あげておきたい場合
(datadog, GCP 等)
73 mercari/tortoiseの現状 - Platformで開発しており、検証段階 - まだ実際に本番で使用はしていない
74 Thanks for listening!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![47 [復習] Incident時のHPAのScale in問題 - UpstreamのサービスがIncidentで落ちる - Downstreamのサービスに通信が行かなくなる - DownstreamのサービスのCPU使用量が下がる](https://files.speakerdeck.com/presentations/f69404738c6e4be1a9c0806199e4f85e/slide_46_1742167440.jpg){kind=link}
{kind=link}
{kind=link}
![50 [復習] HPAのtarget utilization決めるの難しすぎ問題 HPAのtarget utilizationによって与えられる、「余分なリソース」は - Containerごとのリソース使用量のばらつき - スケールアウトの時間稼ぎ](https://files.speakerdeck.com/presentations/f69404738c6e4be1a9c0806199e4f85e/slide_49_1742167446.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![55 [復習] HPAのtarget utilization決めるの難しすぎ問題 HPAのtarget utilizationによって与えられる、「余分なリソース」は - Containerごとのリソース使用量のばらつき - スケールアウトの時間稼ぎ](https://files.speakerdeck.com/presentations/f69404738c6e4be1a9c0806199e4f85e/slide_54_1742167447.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![63 [復習] HPAがレプリカ全然増やさない問題 Deploymentのresource requestが大きすぎると、HPAを設定していても 「レプリカ数がずっとminReplicasで制限されてる」みたいなケースが起こりうる この場合、HPAが機能していないに等しいためCPU使用率も低くなる](https://files.speakerdeck.com/presentations/f69404738c6e4be1a9c0806199e4f85e/slide_62_1742167448.jpg){kind=link}
{kind=link}
![65 [復習] HPAがレプリカ増やしすぎる問題 Deploymentのresource requestが小さすぎると、ピーク時のレプリカ数がとても 多くなる。 この際、Podのサイズを大きくし、レプリカ数を小さく抑えた方が、省エネになる場合 がある。 とあるサービスでは、この最適化を行うことで、GKEコストが40%減少 (ピーク時のレプリカ数は200->30に変化)](https://files.speakerdeck.com/presentations/f69404738c6e4be1a9c0806199e4f85e/slide_64_1742167448.jpg){kind=link}
{kind=link}
![67 [復習] Multiple containers Pod with HPAめんどくさい問題 例: HPAのtarget utilization:](https://files.speakerdeck.com/presentations/f69404738c6e4be1a9c0806199e4f85e/slide_66_1742167449.jpg){kind=link}
![68 [復習] Multiple containers Pod with HPAめんどくさい問題 80% 80% App](https://files.speakerdeck.com/presentations/f69404738c6e4be1a9c0806199e4f85e/slide_67_1742167449.jpg){kind=link}
![69 [復習] Multiple containers Pod with HPAめんどくさい問題 80% 80% App](https://files.speakerdeck.com/presentations/f69404738c6e4be1a9c0806199e4f85e/slide_68_1742167449.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}