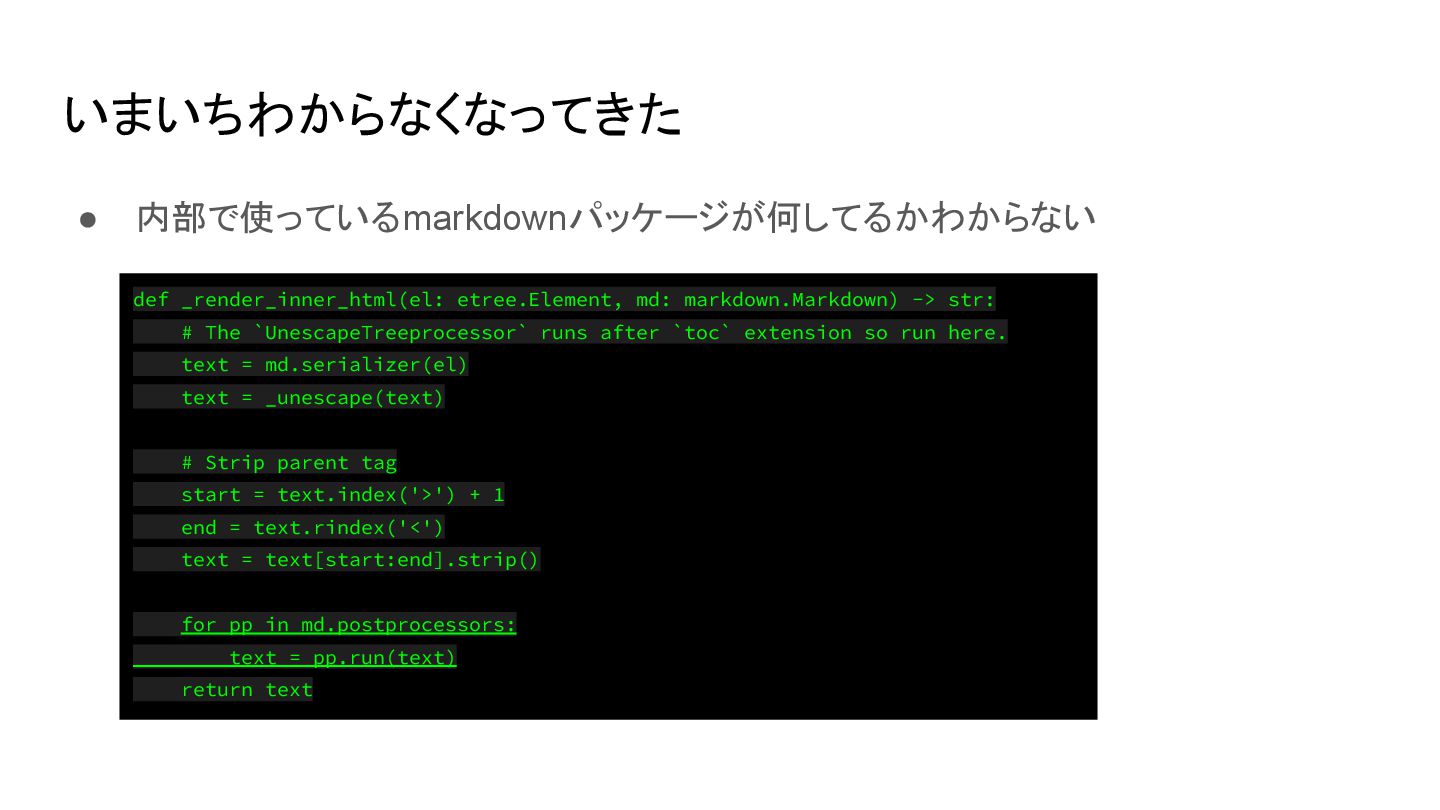
# The `UnescapeTreeprocessor` runs after `toc` extension so run here. text = md.serializer(el) text = _unescape(text) # Strip parent tag start = text.index('>') + 1 end = text.rindex('<') text = text[start:end].strip() for pp in md.postprocessors: text = pp.run(text) return text
{kind=link}
{kind=link}
{kind=link}
{kind=link}
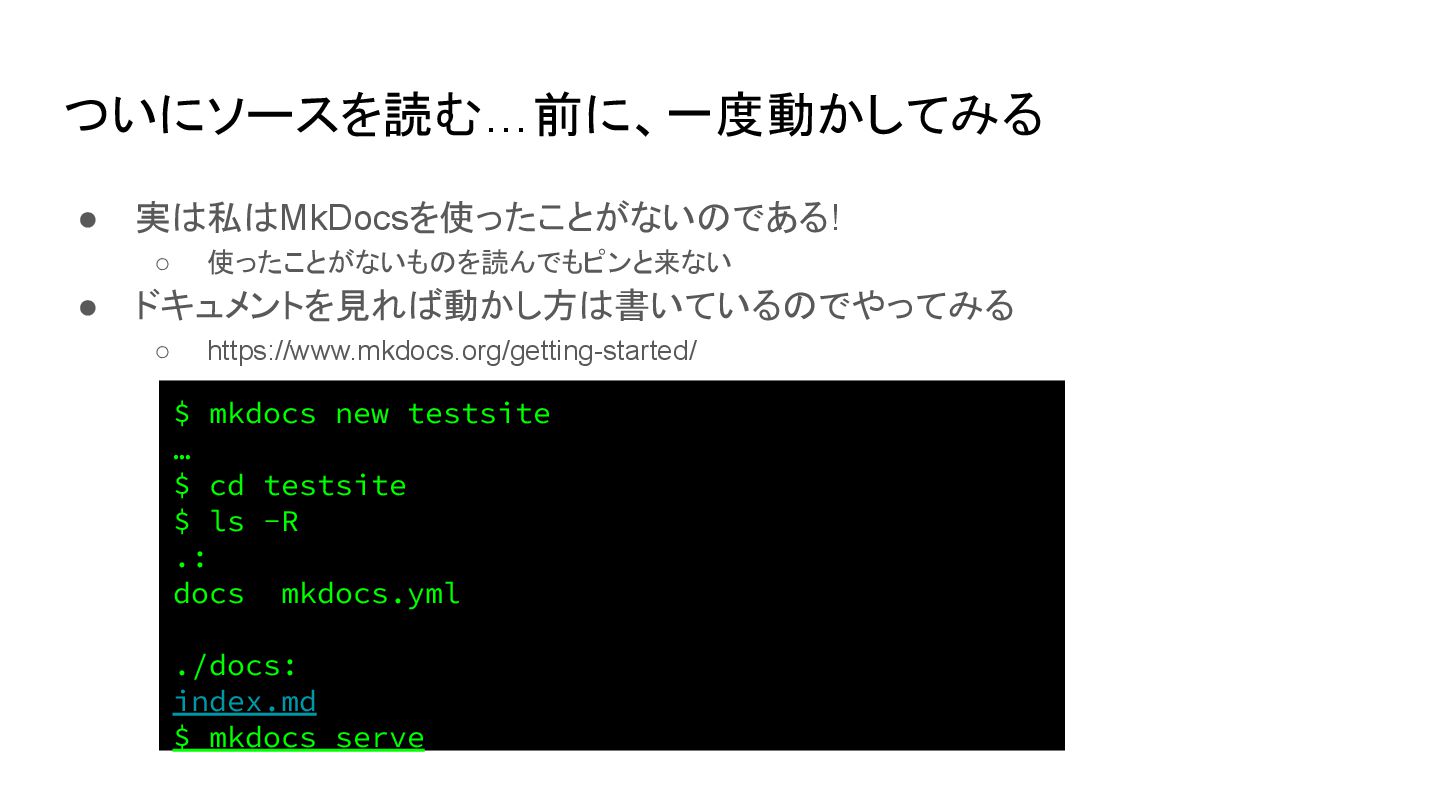{kind=link}
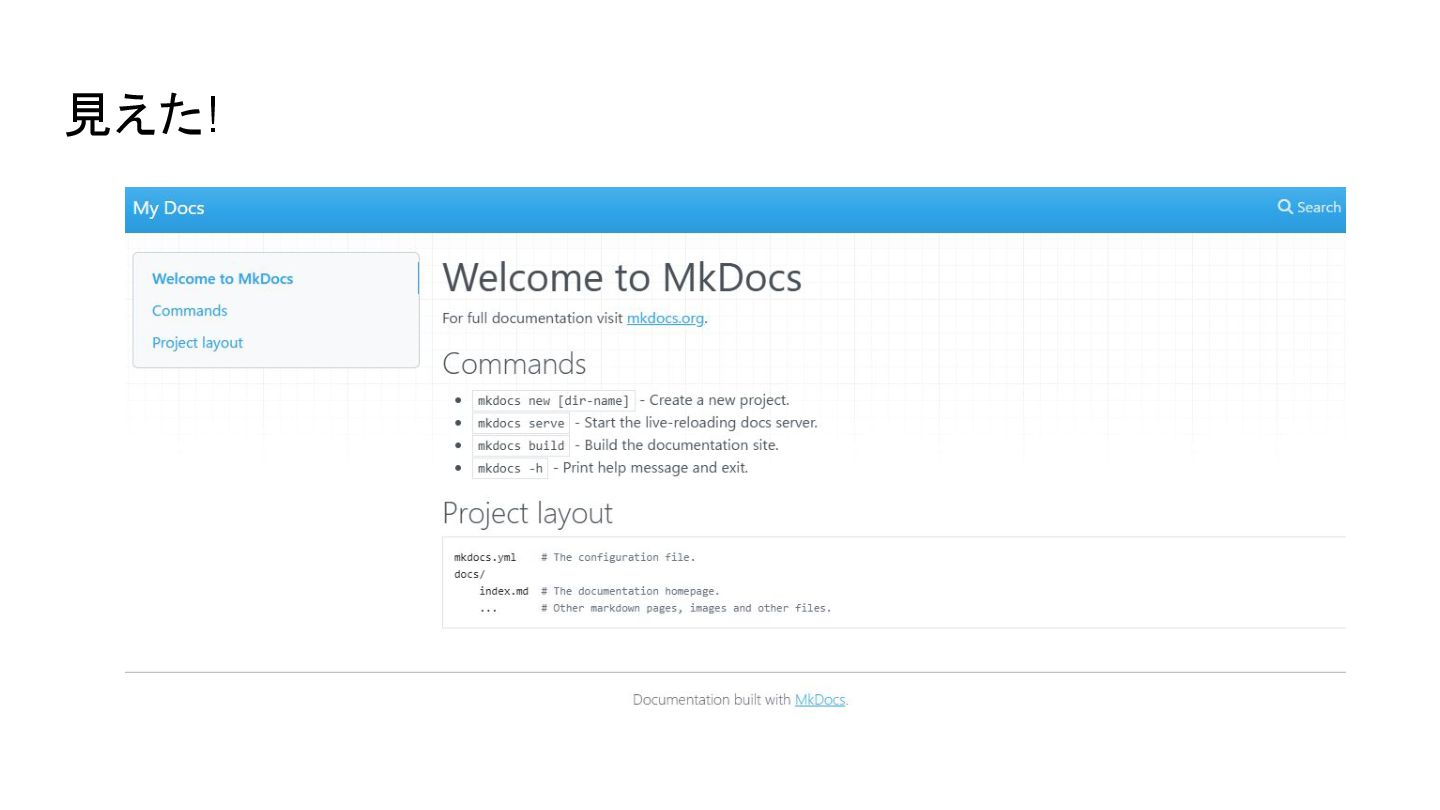{kind=link}
{kind=link}
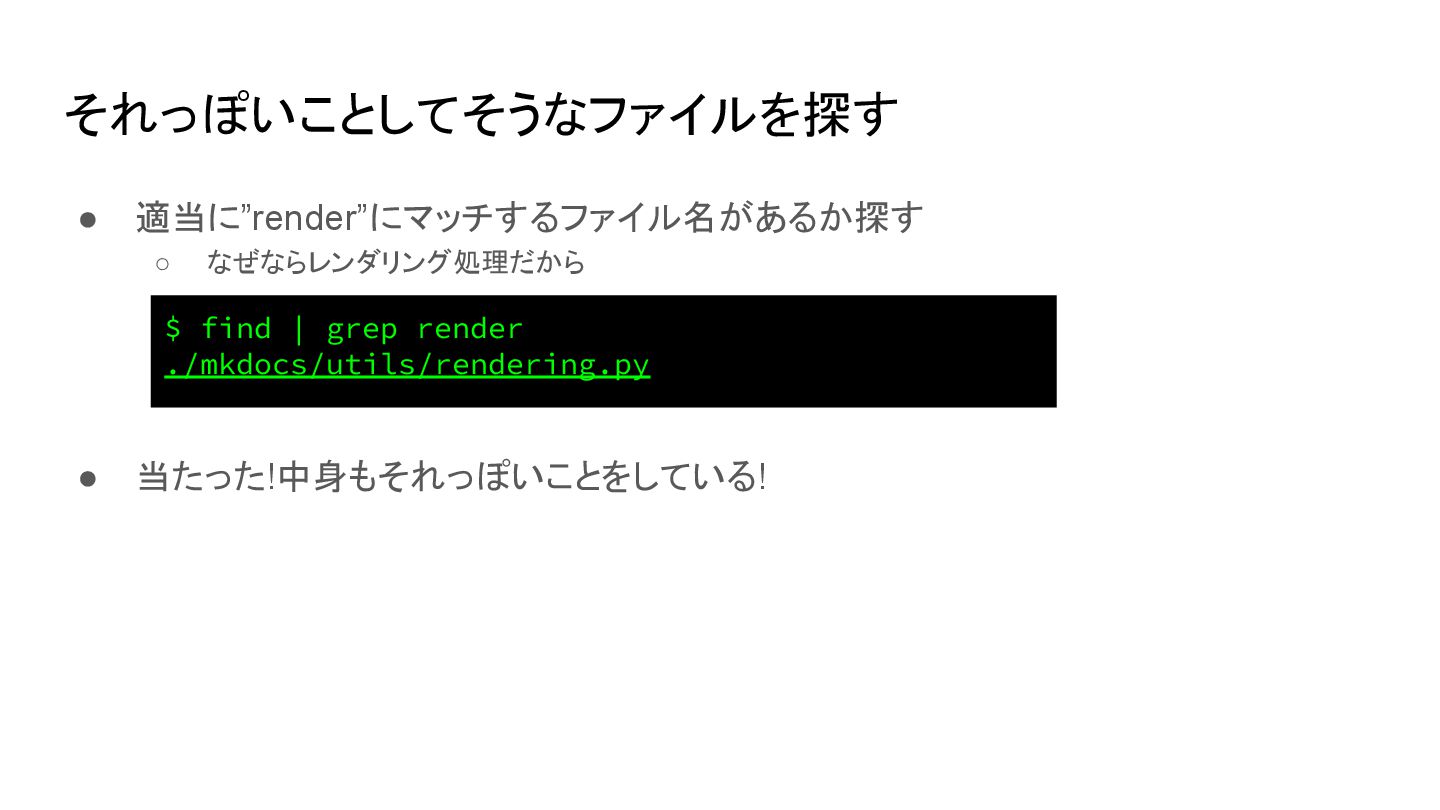{kind=link}
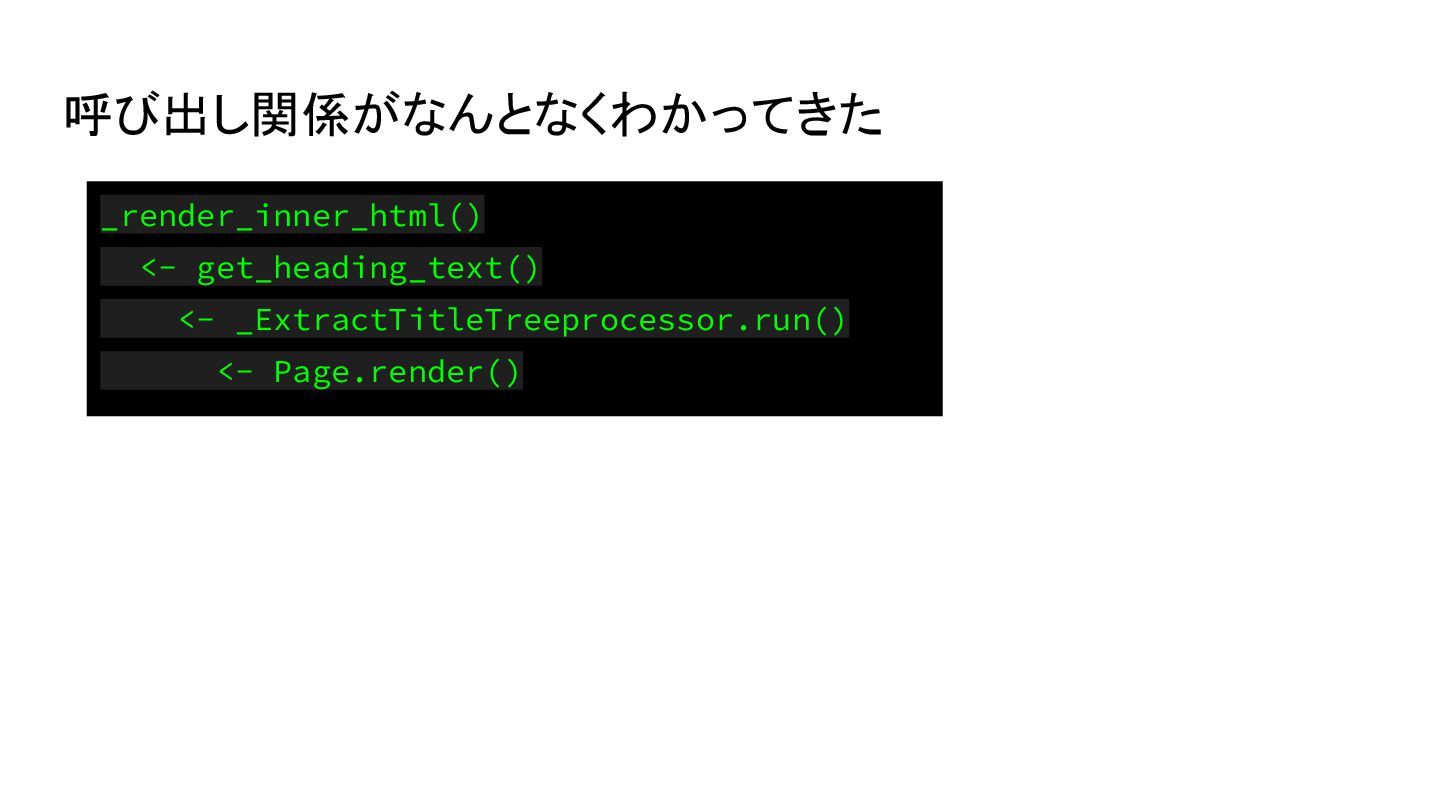{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}