Karpenter。複雑化しがちなKubernetes(K8s)クラスタの運用負荷を軽減し、コスト効率を考えたノードのスケールを自動的に制御するベンダニュートラルで強力なツールです。
AWS EKSではAuto Modeにおける標準実装になるなどオートスケーラとしての確固たる地位を築きつつあり、K8s運用担当者にとって気になる存在ではないでしょうか。 私はそんなKarpenterをクラスタ構築時点の導入、運用中クラスタのCluster Autoscalerからの移行、ベータ版からのアップグレードといったひと通りの導入を行い、運用してきました。
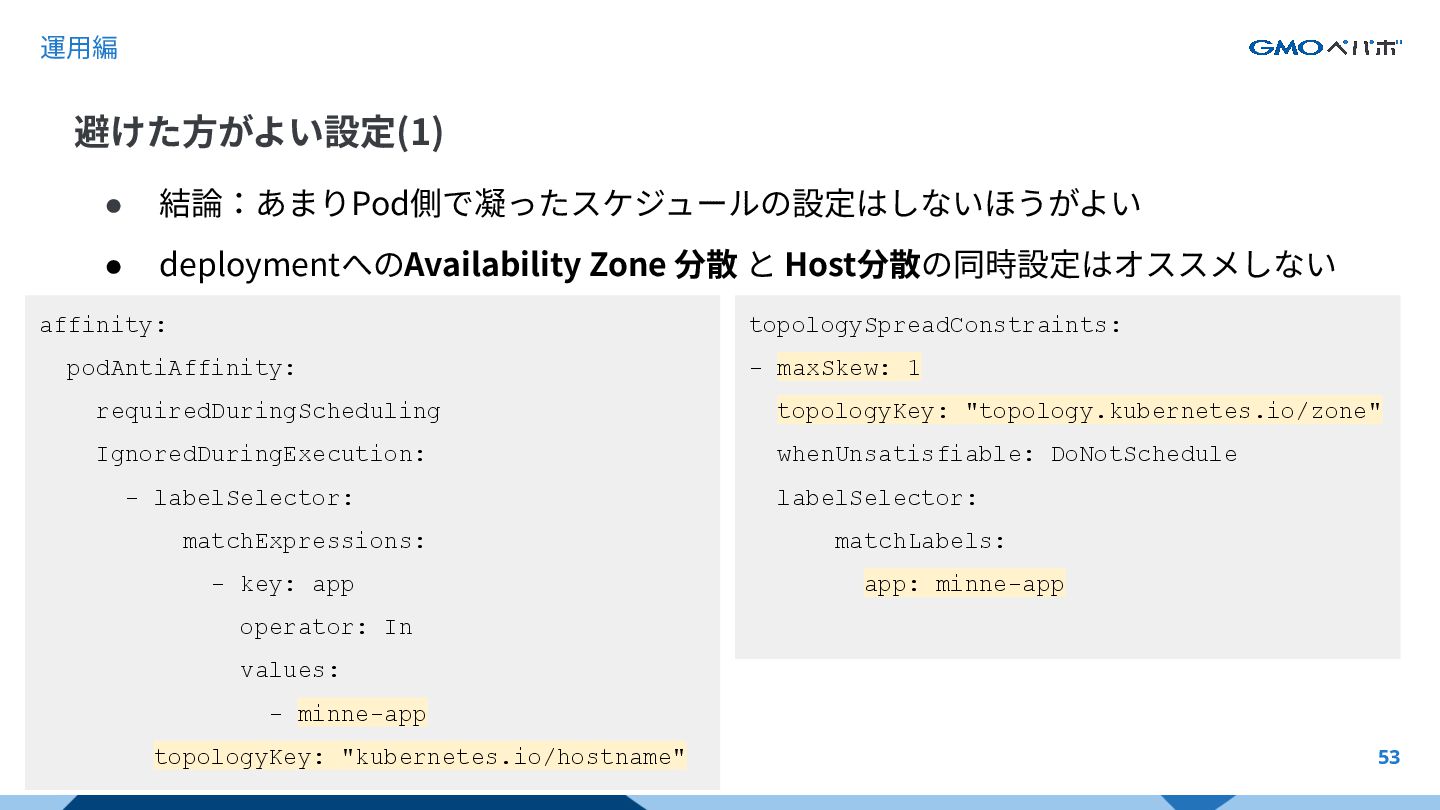
このセッションではKarpenterの導入と運用の勘所をすべてお伝えし、みなさまのK8s運用負荷軽減のお役に立つことを目的としています。KarpenterはインスタンスがPodに合わせてスケールする性格上、避けたほうがよい構成や、逆に積極的に活用したい設定が存在します。
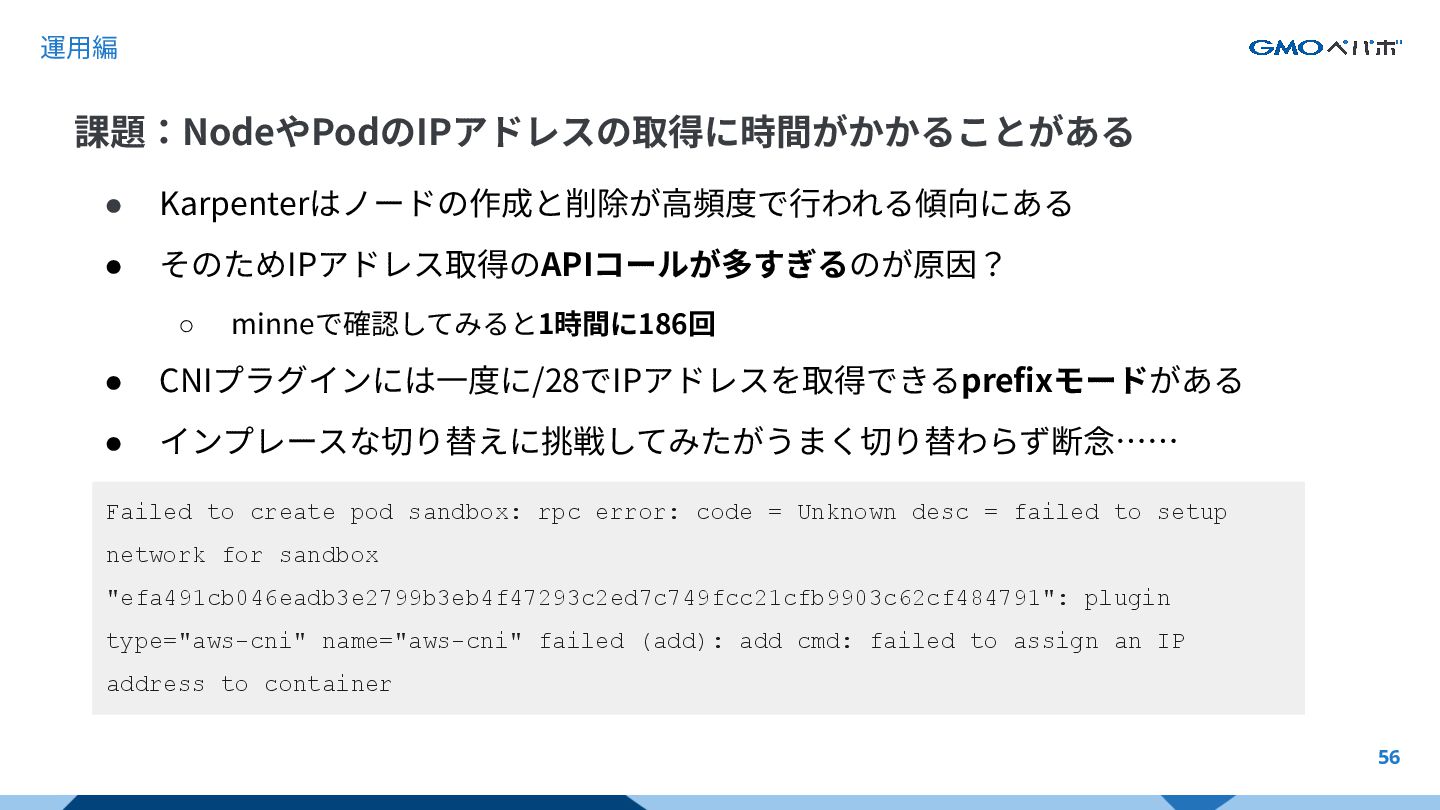
また、具体的かつ実践的な導入方法、ドキュメントではわかりにくかった点や、運用上の苦労話といった知見も余すことなく共有します。きっとみなさまのお役に立つセッションになると確信しています。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
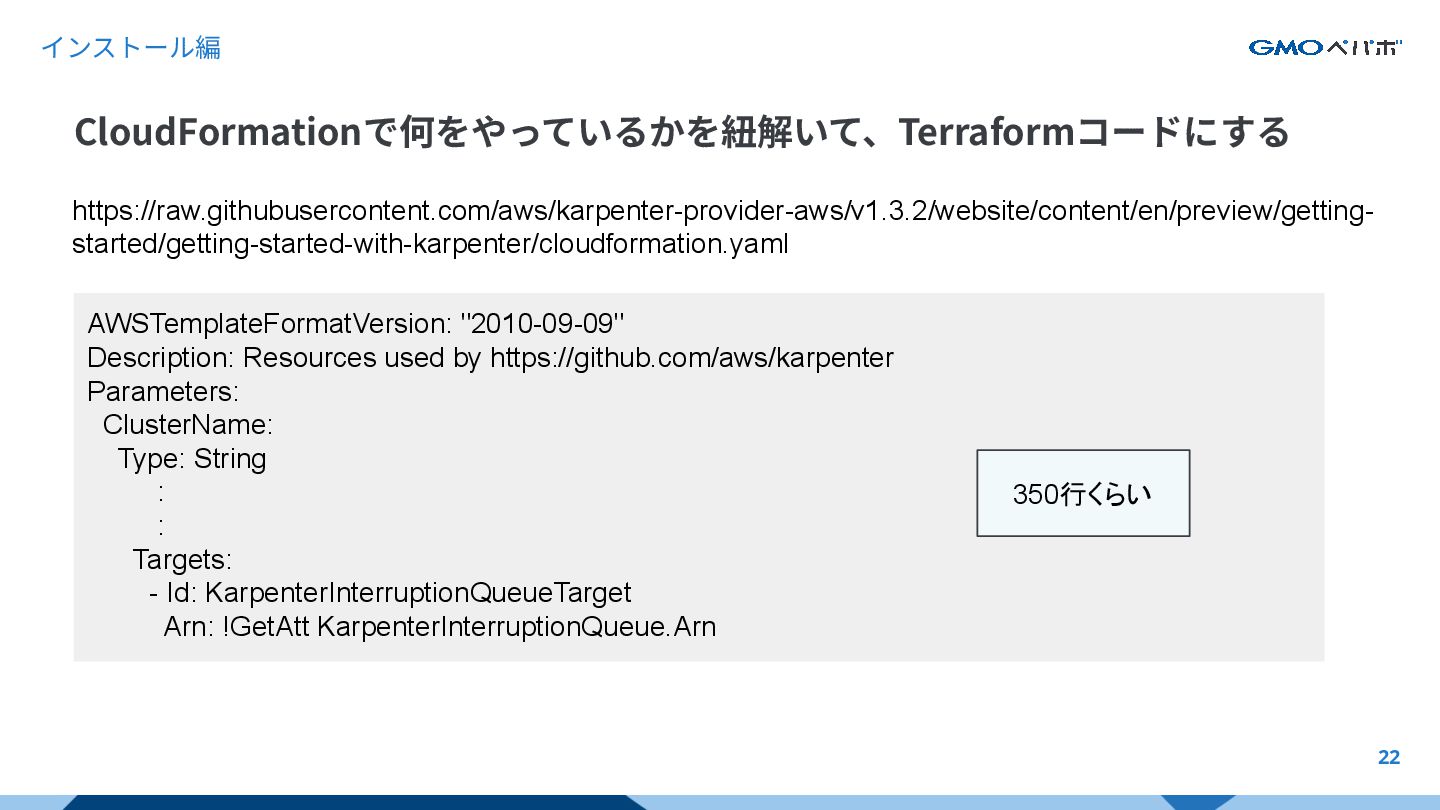{kind=link}
{kind=link}
{kind=link}
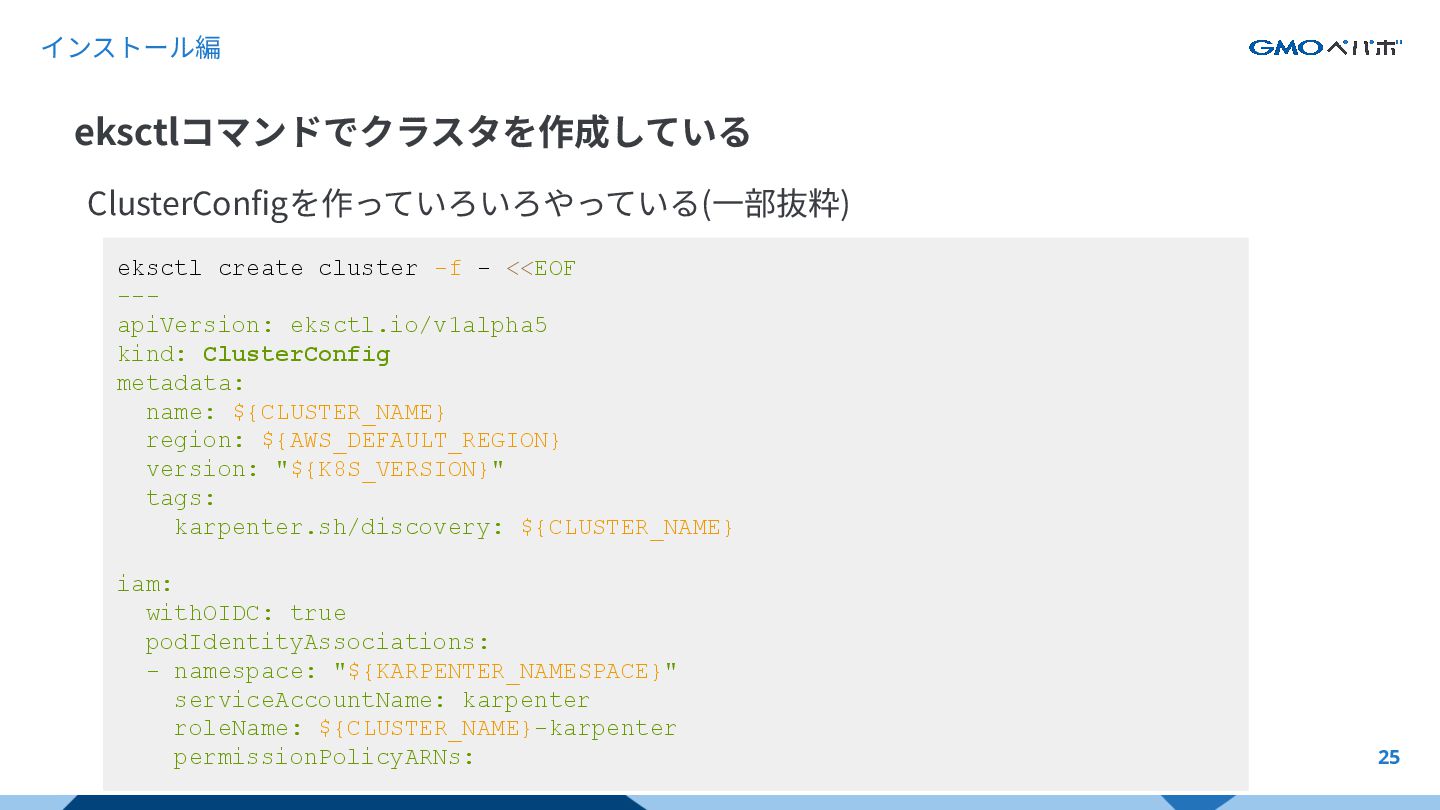{kind=link}
{kind=link}
{kind=link}
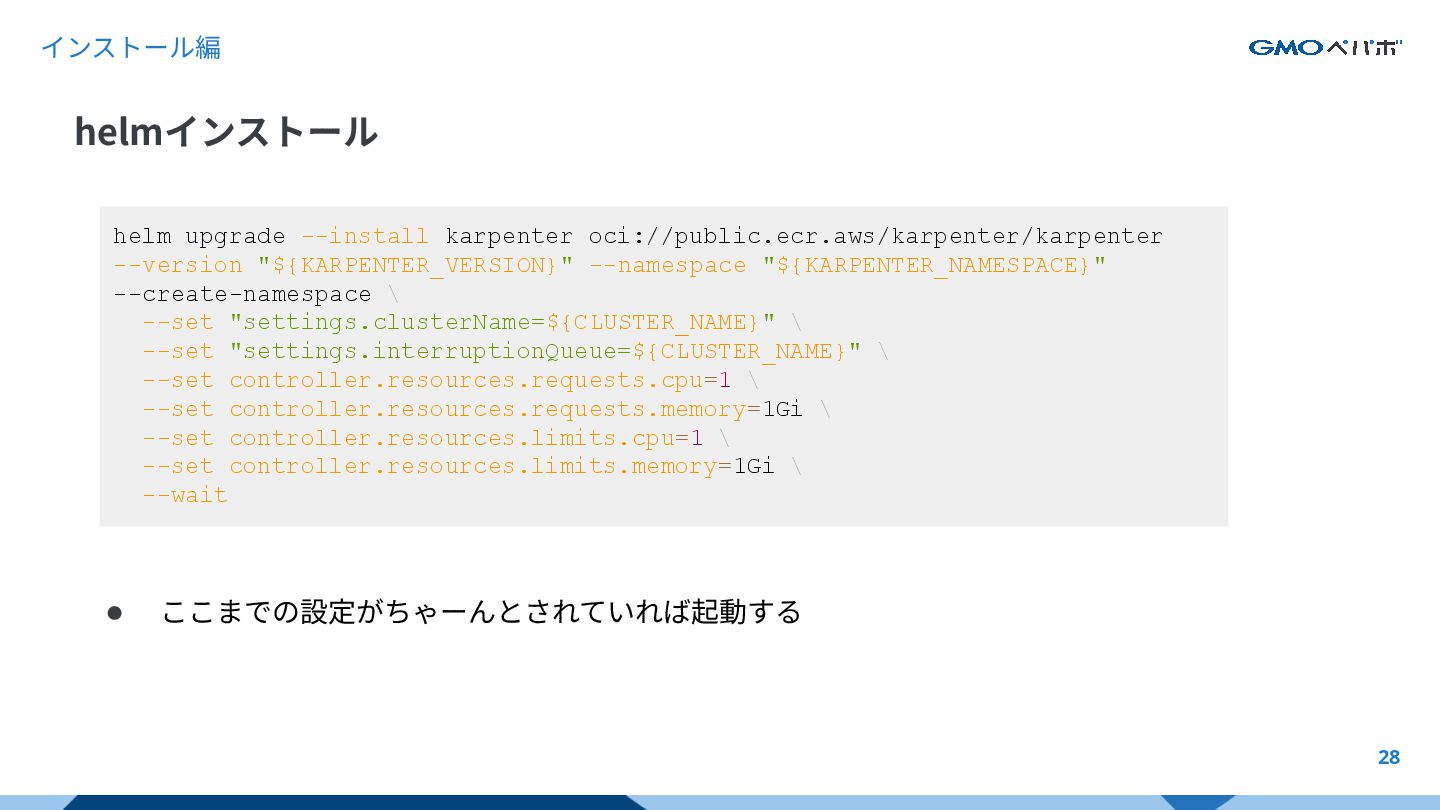{kind=link}
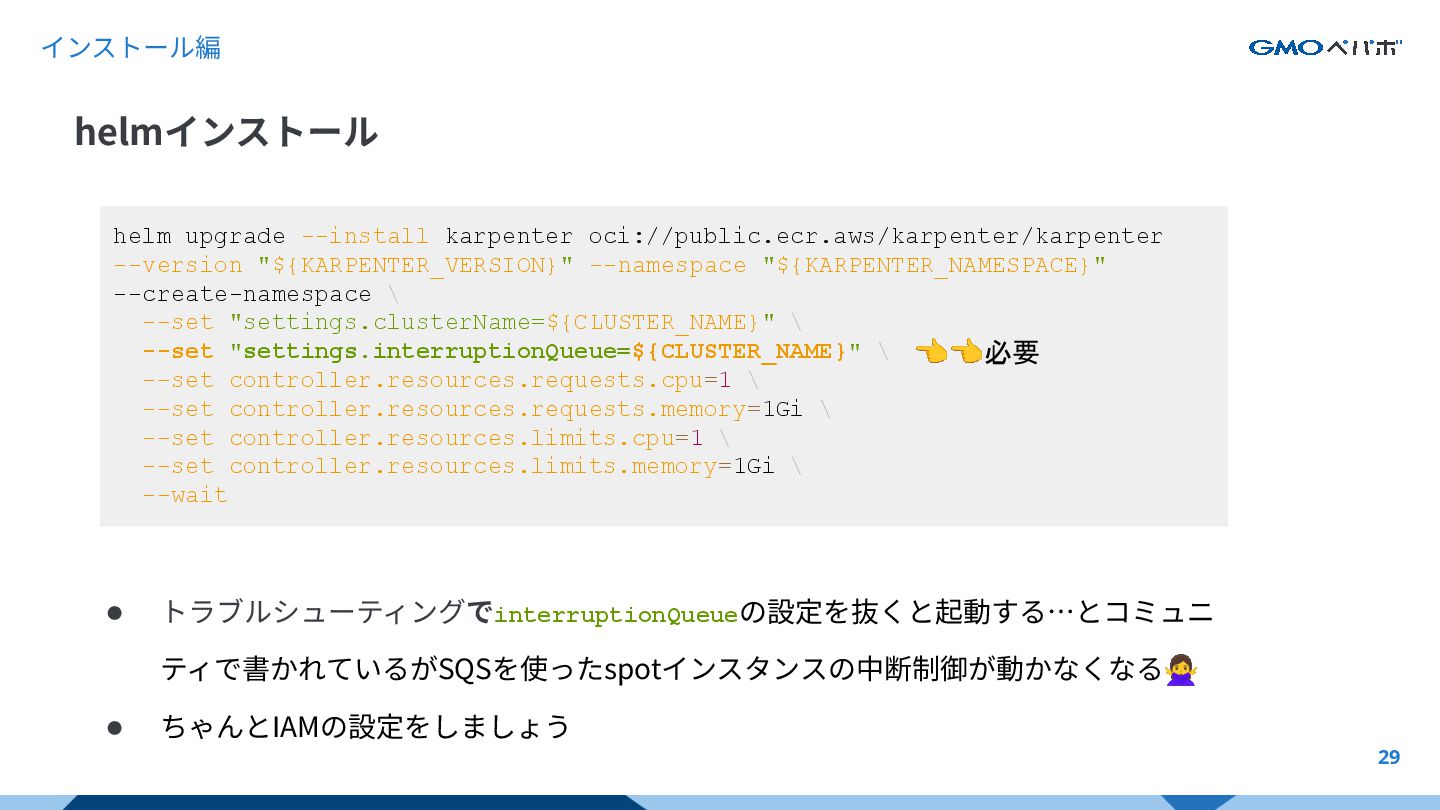{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
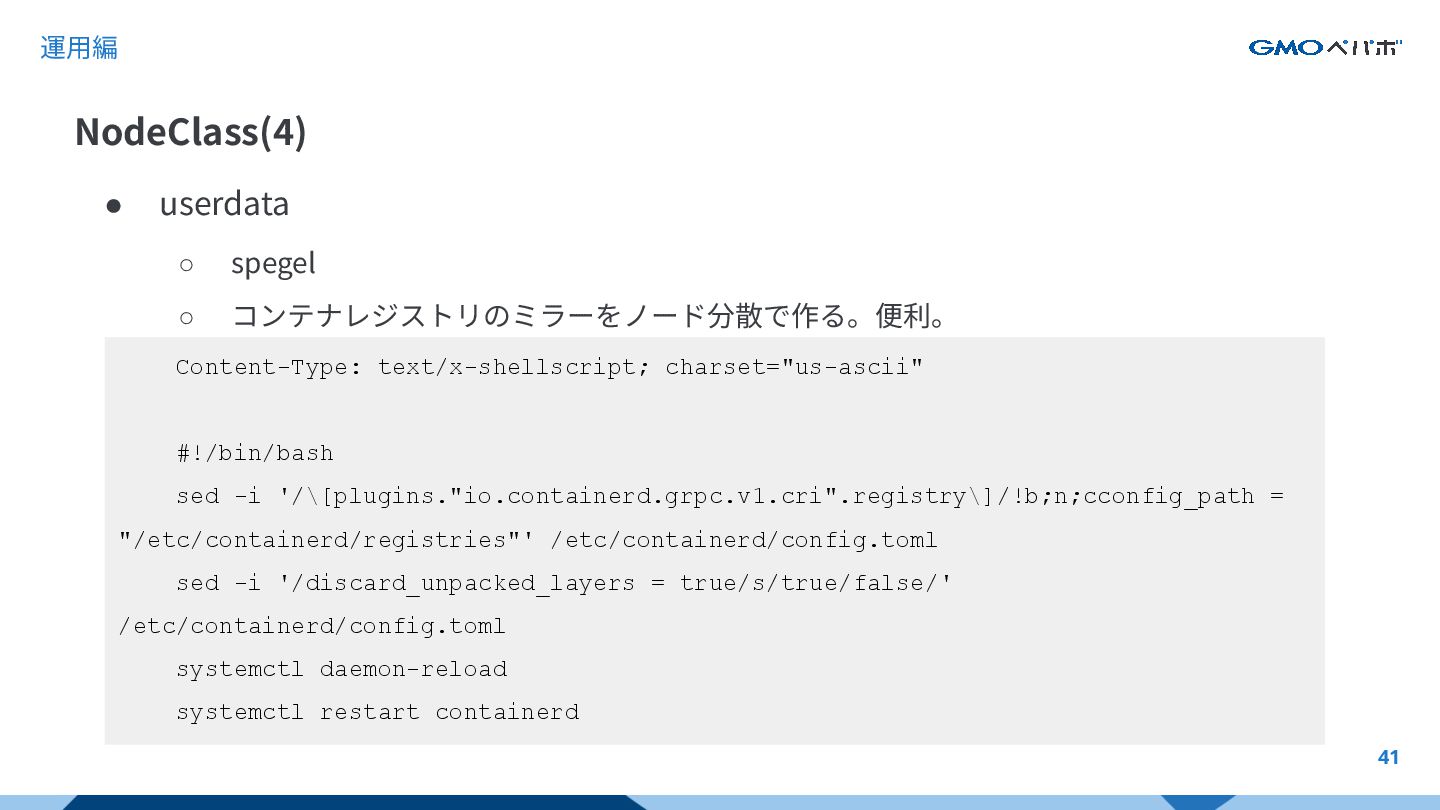{kind=link}
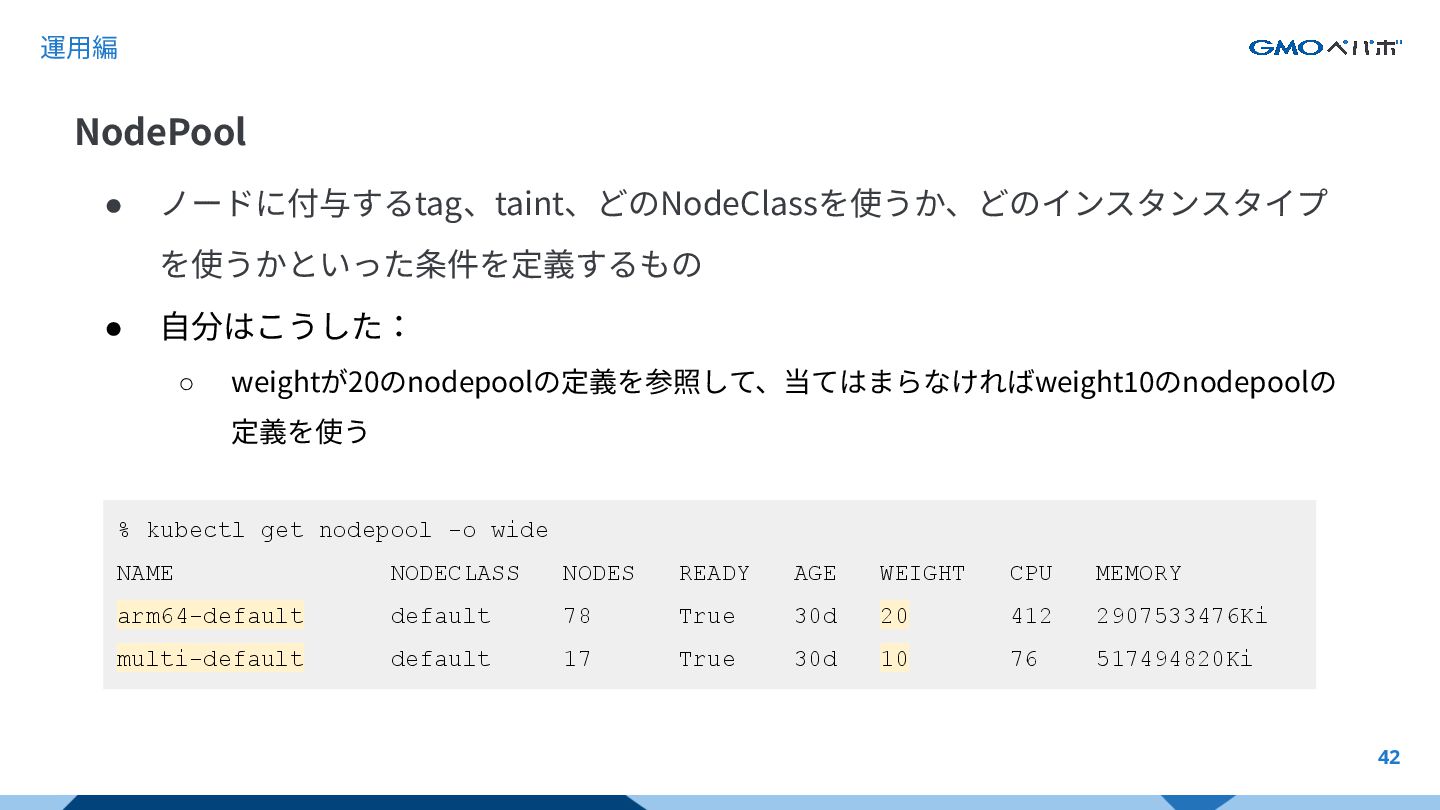{kind=link}
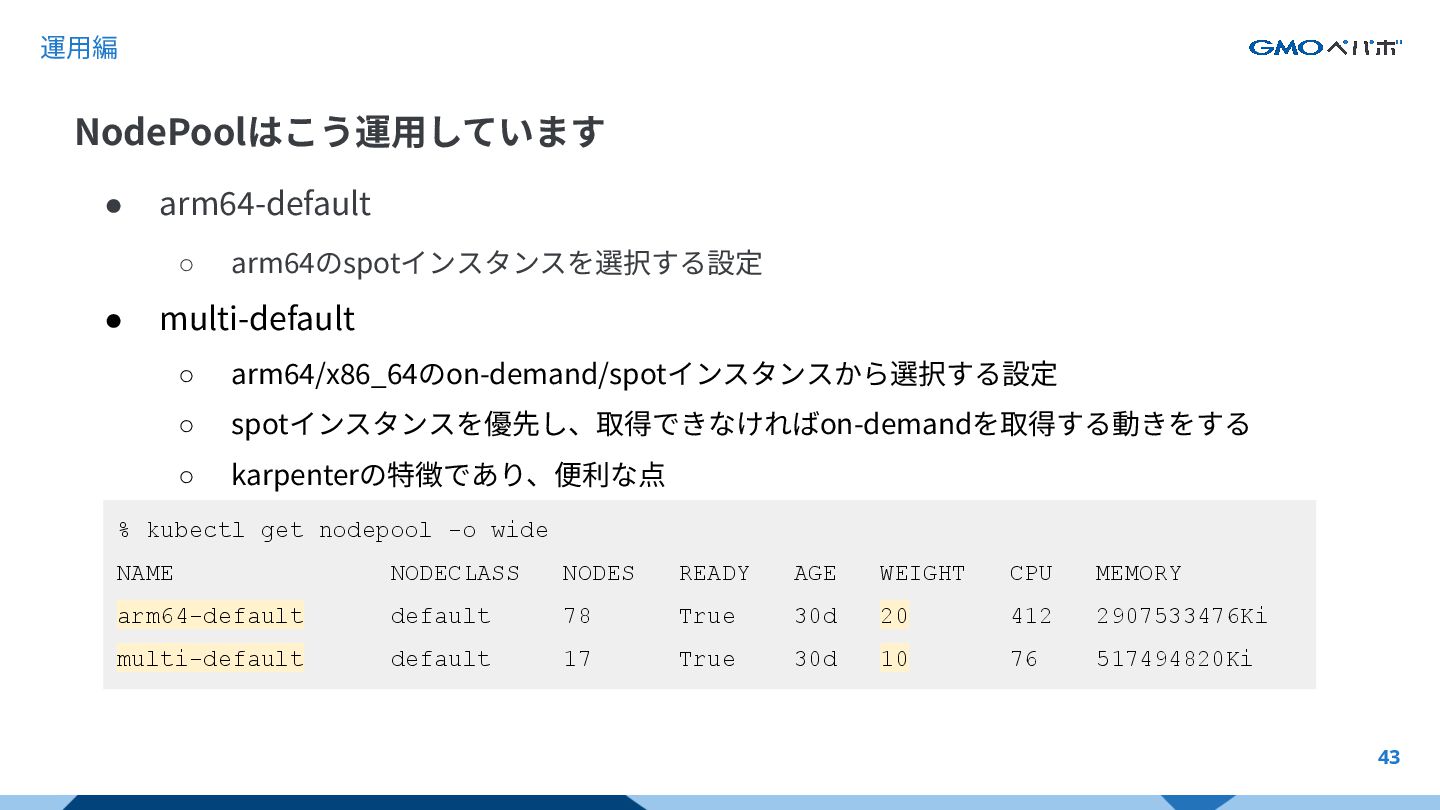{kind=link}
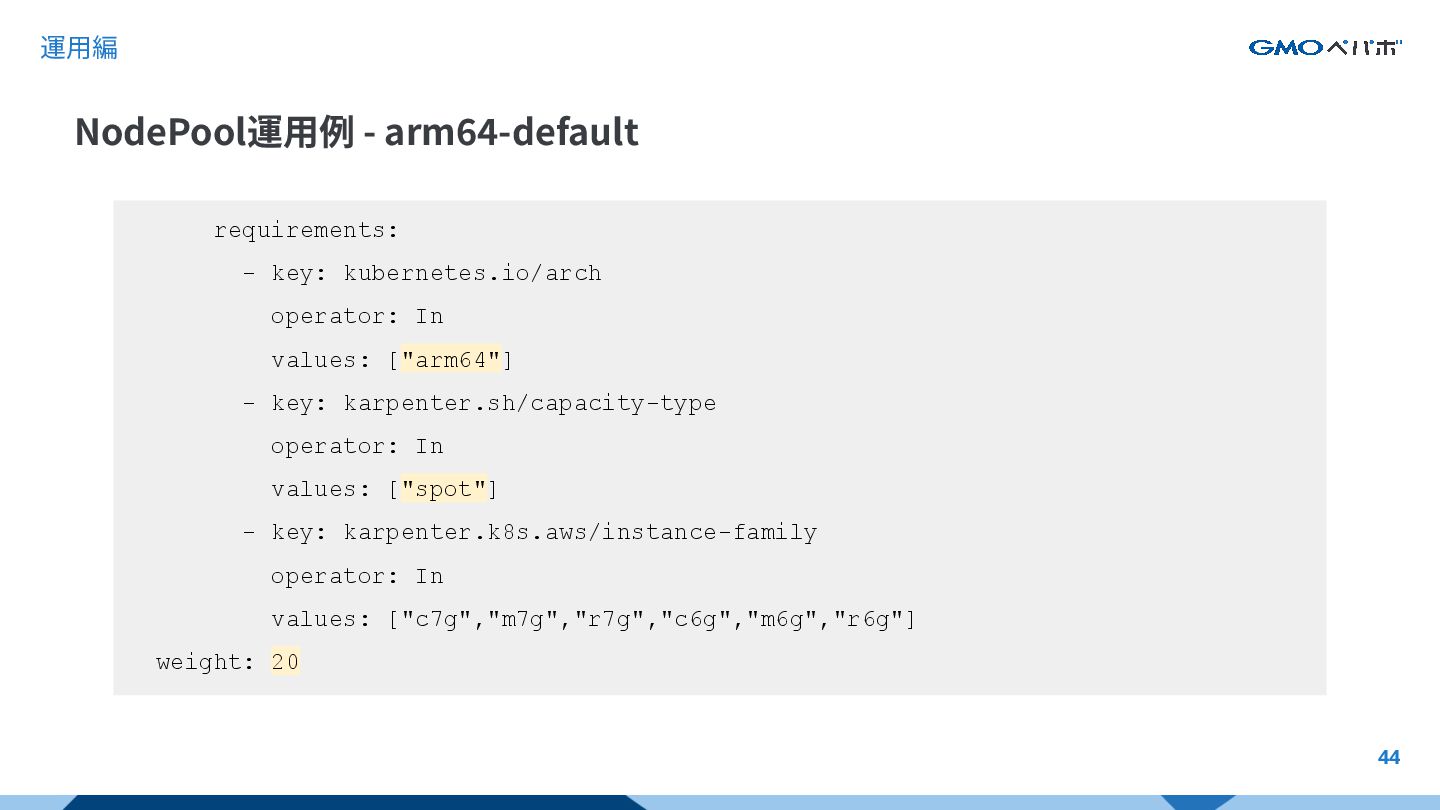{kind=link}
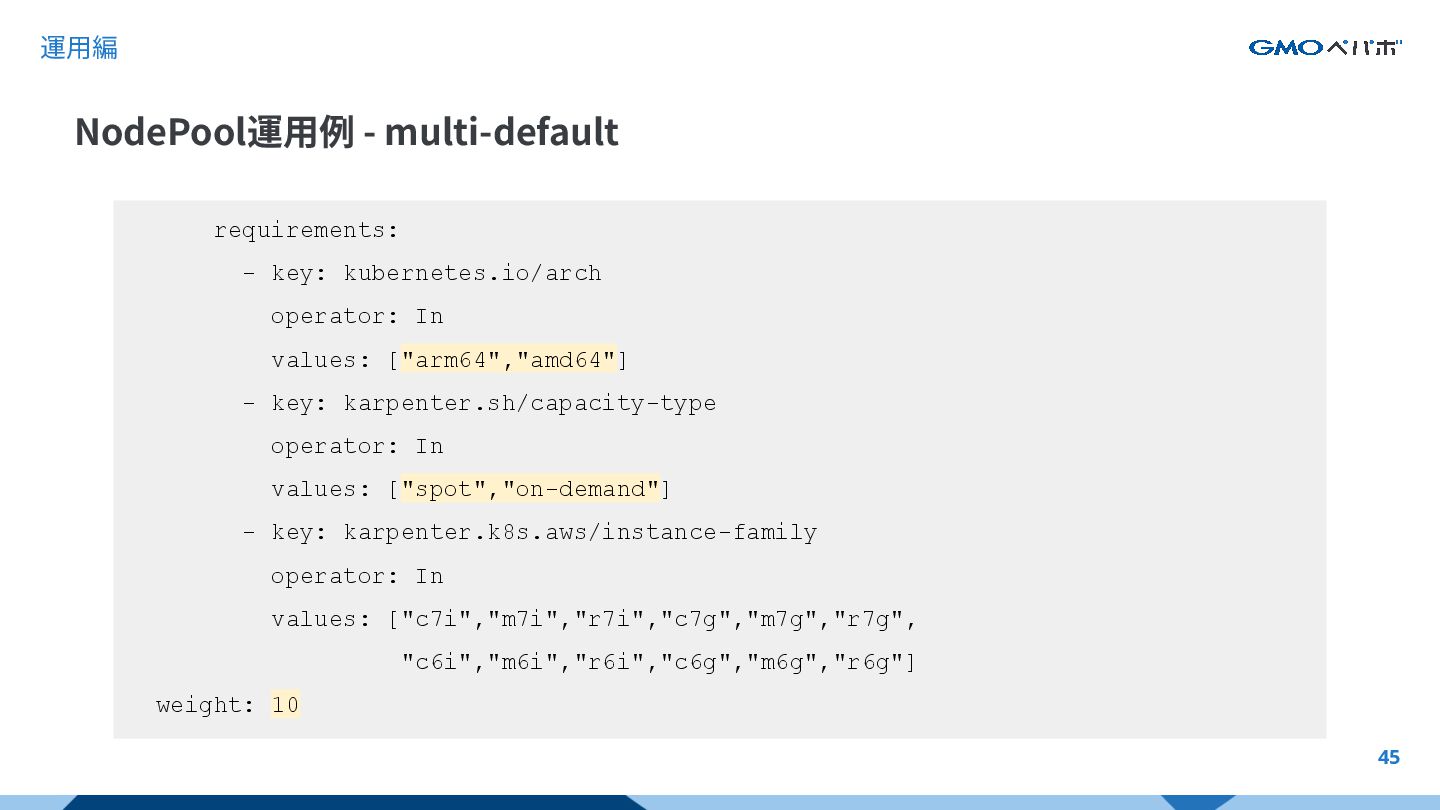{kind=link}
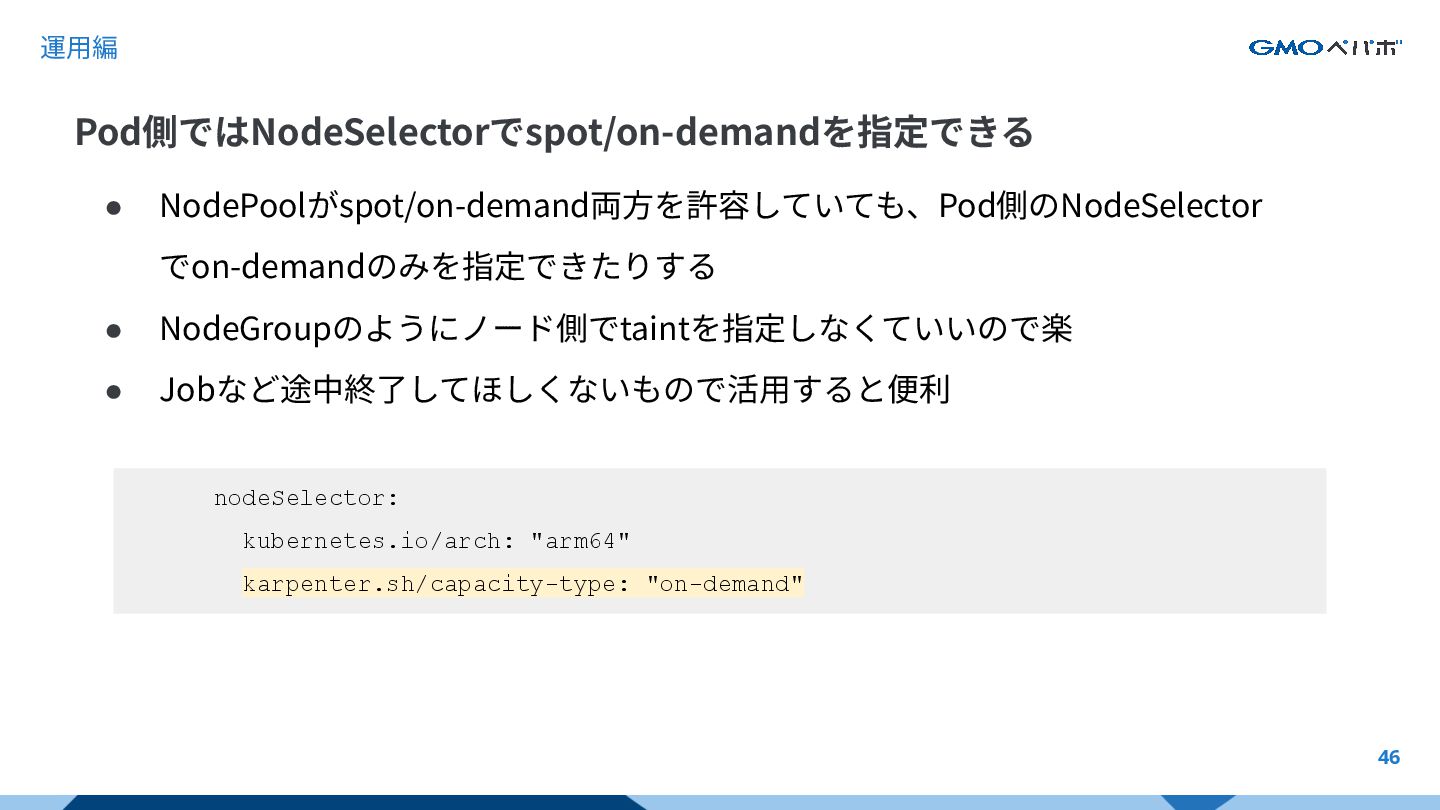{kind=link}
{kind=link}
{kind=link}
{kind=link}
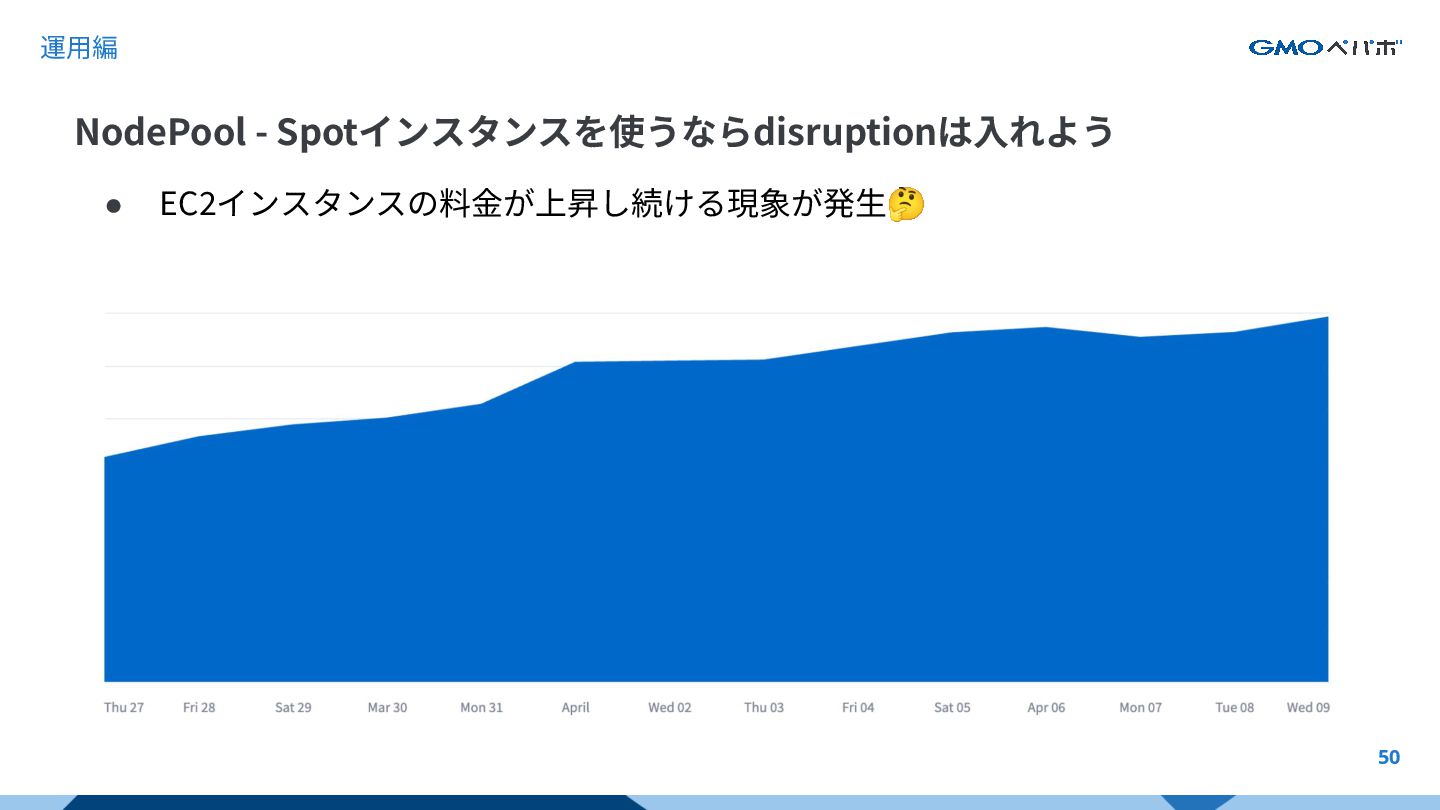{kind=link}
{kind=link}
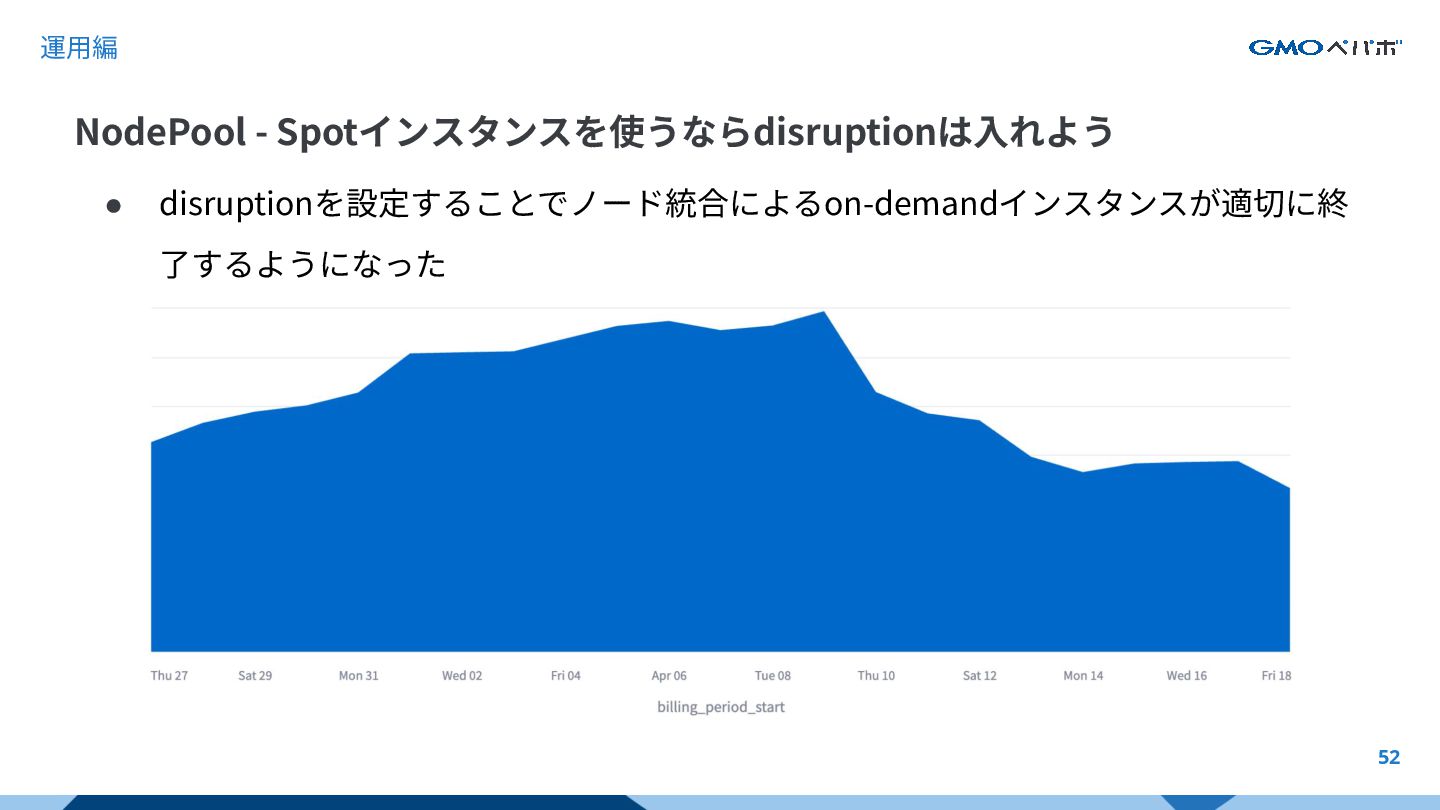{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}