Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
(Preprint) Diffusion Classifiers Understand Co...
Search
Shumpei Takezaki
May 29, 2025
650
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
(Preprint) Diffusion Classifiers Understand Compositionality, but Conditions Apply
https://arxiv.org/pdf/2505.17955
Shumpei Takezaki
May 29, 2025
More Decks by Shumpei Takezaki
See All by Shumpei Takezaki
(IJCNN2026) Cell Instance Segmentation via Multi-Task Image-to-Image Schrödinger Bridge
shumpei777
0
17
(IJCNN2026) SCoRe: Clean Image Generation from Diffusion Models Trained on Noisy Images
shumpei777
0
25
(CVPR2026) Back to Basics: Let Denoising Generative Models Denoise
shumpei777
0
210
(Preprint) Diffusion Transformers with Representation Autoencoders
shumpei777
1
1.3k
(Blog post) Diffusion is spectral autoregression
shumpei777
3
1.3k
(ICLR2021) Score-Based Generative Modeling through Stochastic Differential Equations
shumpei777
1
690
(ICLR2023) Improving Deep Regression with Ordinal Entropy
shumpei777
0
52
(NeurIPS2024) Guiding a Diffusion Model with a Bad Version of Itself
shumpei777
0
46
(ICML2023) I2SB: Image-to-Image Schrödinger Bridge
shumpei777
0
67
Featured
See All Featured
The Limits of Empathy - UXLibs8
cassininazir
1
500
Understanding Cognitive Biases in Performance Measurement
bluesmoon
32
3k
The untapped power of vector embeddings
frankvandijk
2
1.8k
Documentation Writing (for coders)
carmenintech
77
5.4k
Introduction to Domain-Driven Design and Collaborative software design
baasie
1
900
Leading Effective Engineering Teams in the AI Era
addyosmani
9
2.1k
Embracing the Ebb and Flow
colly
88
5.1k
Leadership Guide Workshop - DevTernity 2021
reverentgeek
1
320
Performance Is Good for Brains [We Love Speed 2024]
tammyeverts
12
1.7k
Optimising Largest Contentful Paint
csswizardry
37
3.8k
Building Experiences: Design Systems, User Experience, and Full Site Editing
marktimemedia
0
550
Faster Mobile Websites
deanohume
310
32k
Transcript
拡散モデルで認識してみた 2025/5/29@論文読み会 Shumpei Takezaki (D2, Uchida Lab.)
• Diffusion Classifiers Understand Compositionality, but Conditions Apply[Jeong+, arxiv preprint]
• “画像生成”拡散モデルによる“画像認識”能力を包括的に調査 紹介する論文 1
• 画像とテキストそれぞれの特徴ベクトルの類似度によって認識 • 苦手なタスクも存在 • 語順,空間的関係,カウント,構成認識など CLIPのZero-shot分類 2 [1] Radford+,ICML2021
Shortcut (表面的)な学習と表現 ベクトルの一致度による学習が原因? ① 画像とテキストの ベクトルを獲得 ② ベクトルの一致度 を計算 ③ 一致度が高いクラスに 認識 事後確率の推定 テキストでクラスを指定 例: A photo of a “dog”
• 条件付き推定ノイズの予測誤差を使って分類[1,2,3] • 拡散モデルを用いた事後確率の推定に当たる Diffusion Classifiers (DS): 拡散モデルZero-shot分類 3 [1]Li+,ICCV2023
[2]Clark+,NeurIPS2023 [3]Krojer+,NeurIPS2023 [1]より抜粋 ① 時刻tに応じた ノイズを付加 ② テキストで条件つけて ノイズを推定 ③ 推定ノイズと付与ノイズの 誤差を計算 ④ 誤差が小さいクラスに 認識 ※ 全時刻tで平均 (等間隔でサンプリング) 空間や構成の認識に優れる? ピクセルレベルの再構成学習により
• 仮説1: 拡散モデルの構成分類がCLIPより優れる • 包括的な構成分類タスクの検証 • 仮説2: 生成したものを(分類を通して)理解している • 新たなベンチマークであるSelfーBenchの提案
• 生成/認識モデルが同じモデルによるGenerative AI Paradoxの検証 • 仮説3: ドメイン差はタイムステップの重み付けで緩和可能 • Diffusion Classifiersで用いるタイムステップの影響を調査 検証する仮説 4
• 仮説1: 拡散モデルの構成分類がCLIPより優れる • 包括的な構成分類タスクの検証 • 仮説2: 生成したものを(分類を通して)理解している • 新たなベンチマークであるSelfーBenchの提案
• 生成/認識モデルが同じモデルによるGenerative AI Paradoxの検証 • 仮説3: ドメイン差はタイムステップの重み付けで緩和可能 • Diffusion Classifiersで用いるタイムステップの影響を調査 検証する仮説 5
• 構成分類 (Compositional classification)[1,2] • 複数の属性や関係性を組み合わせた情報をもとに判断する分類タスク • 構成分類タスクの拡散モデルでの検証は限られている[3,4] 拡散モデルによる分類は構成分類が得意 ?
6 [1]Jphnson+,CVPR2017 [2]Thrush+,CVPR2022 [3] Clark+,NeurIPS2023 [4]Krojer+,NeurIPS2023 CLEVR[1] [3]より抜粋 Winoground[2] [2]より抜粋
• 仮説1: 拡散モデルの構成分類がCLIPより優れる • 包括的な構成分類タスクの検証 • 仮説2: 生成したものを(分類を通して)理解している • 新たなベンチマークであるSelfーBenchの提案
• 生成/認識モデルが同じモデルによるGenerative AI Paradoxの検証 • 仮説3: ドメイン差はタイムステップの重み付けで緩和可能 • Diffusion Classifiersで用いるタイムステップの影響を調査 検証する仮説 7
• Generative AI Paradox[1] • モデルが生成できても理解 (認識)できない可能性を示唆 • 生成モデルと認識モデルが別々であるという問題が残る 「優れた生成能力」は「優れた認識能力」を意味するか?
8 [1]West+,ICLR2024 生成と認識でモデルが異なるため Paradoxの検証としては不十分
• 仮説1: 拡散モデルの構成分類がCLIPより優れる • 包括的な構成分類タスクの検証 • 仮説2: 生成したものを(認識を通して)理解している • 新たなベンチマークであるSelfーBenchの提案
• 生成/認識モデルが同じモデルによるGenerative AI Paradoxの検証 • 仮説3: ドメイン差はタイムステップの重み付けで緩和可能 • Diffusion Classifiersで用いるタイムステップの影響を調査 検証する仮説 9
• 仮説1: 拡散モデルの構成分類がCLIPより優れる • 包括的な構成分類タスクの検証 • 仮説2: 生成したものを(分類を通して)理解している • 新たなベンチマークであるSelfーBenchの提案
• 生成/認識モデルが同じモデルによるGenerative AI Paradoxの検証 • 仮説3: ドメイン差はタイムステップの重み付けで緩和可能 • Diffusion Classifiersで用いるタイムステップの影響を調査 検証する仮説 10
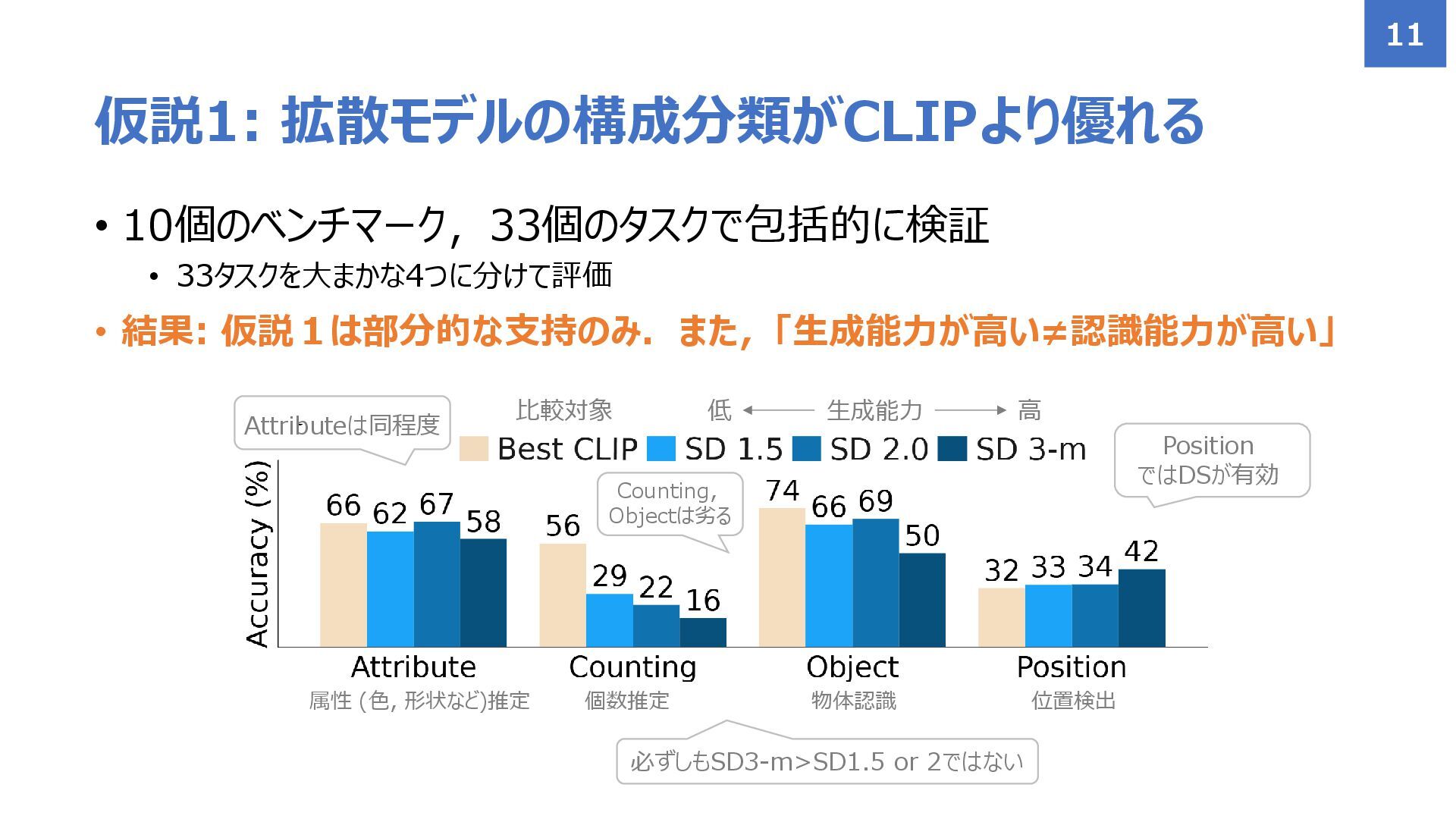
• 10個のベンチマーク,33個のタスクで包括的に検証 • 33タスクを大まかな4つに分けて評価 • 結果: 仮説1は部分的な支持のみ.また,「生成能力が高い≠認識能力が高い」 仮説1: 拡散モデルの構成分類がCLIPより優れる 11
個数推定 属性 (色, 形状など)推定 物体認識 位置検出 Position ではDSが有効 Attributeは同程度 Counting, Objectは劣る 必ずしもSD3-m>SD1.5 or 2ではない 比較対象 低 高 生成能力
• 仮説1: 拡散モデルの構成分類がCLIPより優れる • 包括的な構成分類タスクの検証 • 仮説2: 生成したものを(分類を通して)理解している • 新たなベンチマークであるSelfーBenchの提案
• 生成/認識モデルが同じモデルによるGenerative AI Paradoxの検証 • 仮説3: ドメインギャップはタイムステップの重み付けで緩和可能 • Diffusion Classifiersで用いるタイムステップの影響を調査 検証する仮説 12
• 正例と負例のテキストを与えてどちらを選択するかで評価 Self-Bench: 生成画像による構成分類評価のためのベンチマーク 13
• 作り方はとっても簡単 • 正例のPromptを作成 (GenEval[1] から拝借)し,画像生成 • Textとの整合性を考慮して生成画像に対して人手によるフィルタリング • NegativeなPromptを作成
• 正例: a parking meter left of a teddy bear, 負例: a parking meter right of a teddy bear Self-Bench: 生成画像による構成分類評価のためのベンチマーク 14 [1]Ghosh+,NeurIPS2023 Filterに関して (Textとの整合性を考慮) - F: Filterなし - C: 人手によるフィルタリング SD3-mはテキストとの 整合性が高い
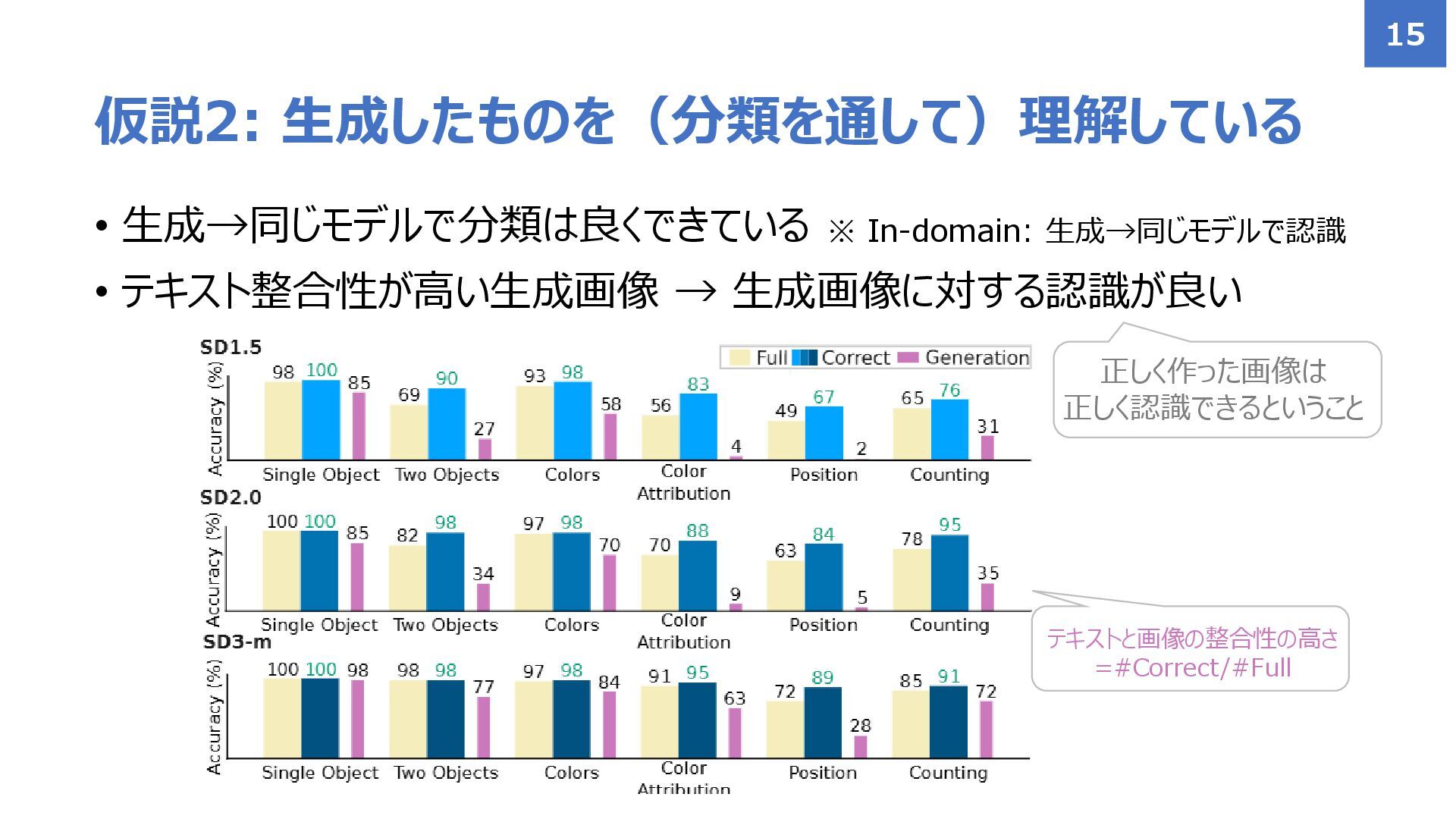
• 生成→同じモデルで分類は良くできている • テキスト整合性が高い生成画像 → 生成画像に対する認識が良い 仮説2: 生成したものを(分類を通して)理解している 15 正しく作った画像は
正しく認識できるということ テキストと画像の整合性の高さ =#Correct/#Full ※ In-domain: 生成→同じモデルで認識
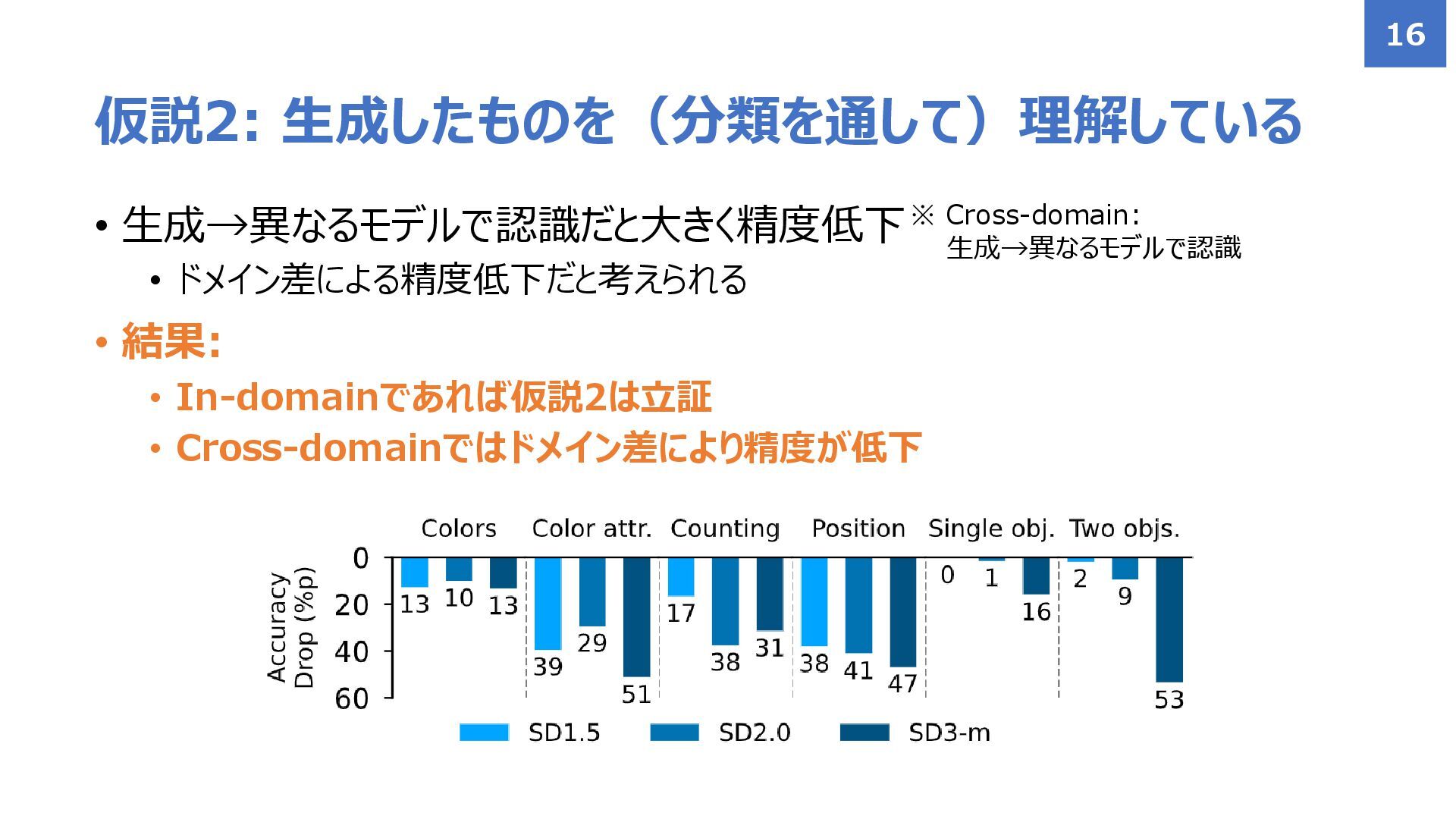
• 生成→異なるモデルで認識だと大きく精度低下 • ドメイン差による精度低下だと考えられる • 結果: • In-domainであれば仮説2は立証 • Cross-domainではドメイン差により精度が低下
仮説2: 生成したものを(分類を通して)理解している 16 ※ Cross-domain: 生成→異なるモデルで認識
• 仮説1: 拡散モデルの構成分類がCLIPより優れる • 包括的な構成分類タスクの検証 • 仮説2: 生成したものを(分類を通して)理解している • 新たなベンチマークであるSelfーBenchの提案
• 生成/認識モデルが同じモデルによるGenerative AI Paradoxの検証 • 仮説3: ドメインギャップはタイムステップの重み付けで緩和可能 • Diffusion Classifiersで用いるタイムステップの影響を調査 検証する仮説 17
• 時刻tに応じてノイズレベルが変化.それに応じて生成する粗さも変化[1,2] 拡散モデルは時刻(=ノイズレベル)に応じて粗い→細かい生成 18 時刻 小 時刻 大 粗い生成 細かい生成
[1]Li+, NeurIPSW2024 [2]Wang+, NeurIPSW2023 [1]より抜粋
• 時刻tのサンプリング方法を変化させることによる認識能力への影響を調査 • 等間隔ではなくより適した方法があるはず 時刻tのサンプリング方法を最適化することが重要か? 19 [1]Li+,ICCV2023 [2]Clark+,NeurIPS2023 [3]Krojer+,NeurIPS2023 [1]より抜粋
① 時刻tに応じた ノイズを付加 ② テキストで条件つけて ノイズを推定 ③ 推定ノイズと付与ノイズの 誤差を計算 ④ 誤差が小さいクラスに 認識 ※ 全時刻tで平均 (等間隔でサンプリング)
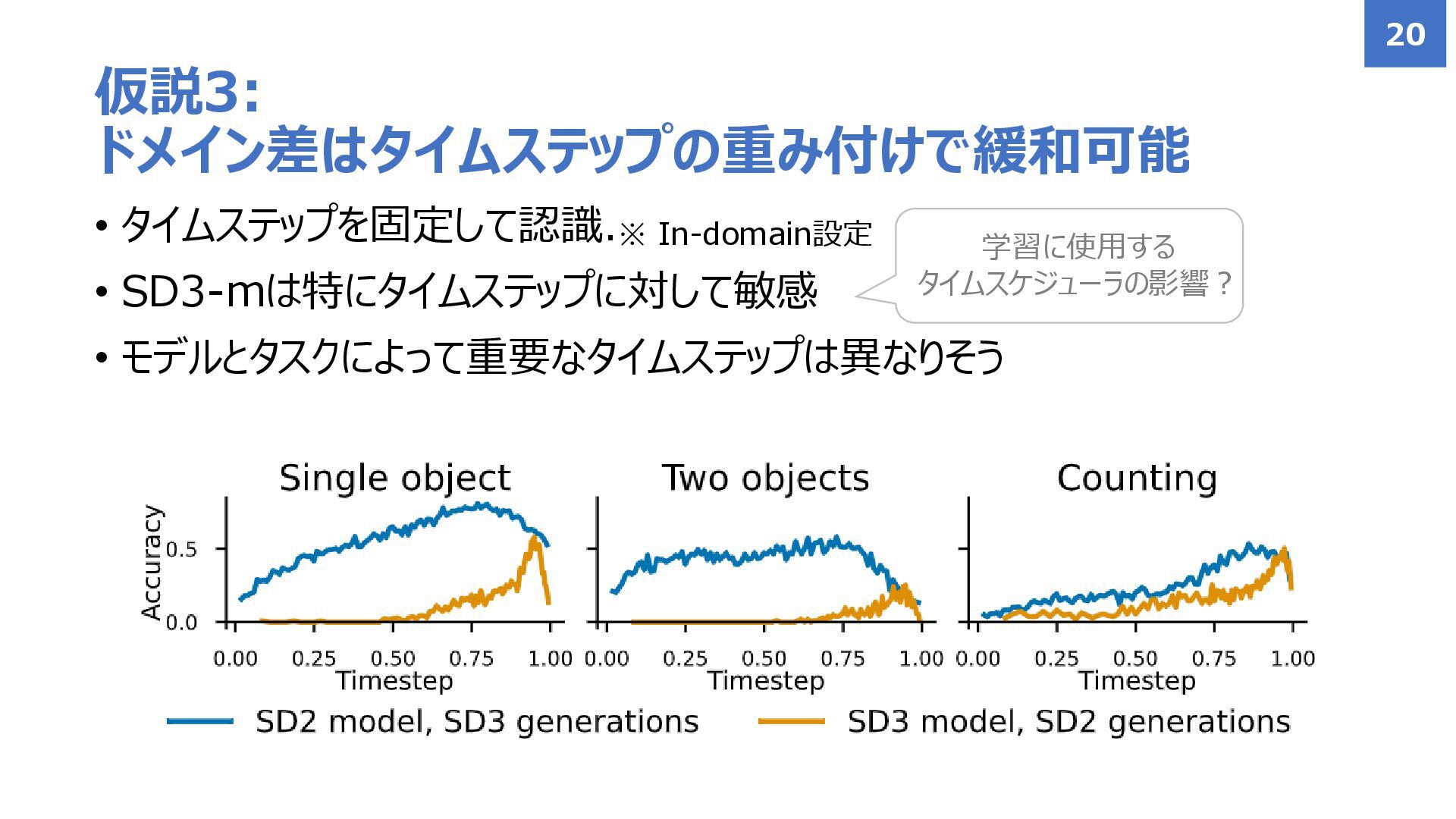
• タイムステップを固定して認識. • SD3-mは特にタイムステップに対して敏感 • モデルとタスクによって重要なタイムステップは異なりそう 仮説3: ドメイン差はタイムステップの重み付けで緩和可能 20 学習に使用する
タイムスケジューラの影響? ※ In-domain設定
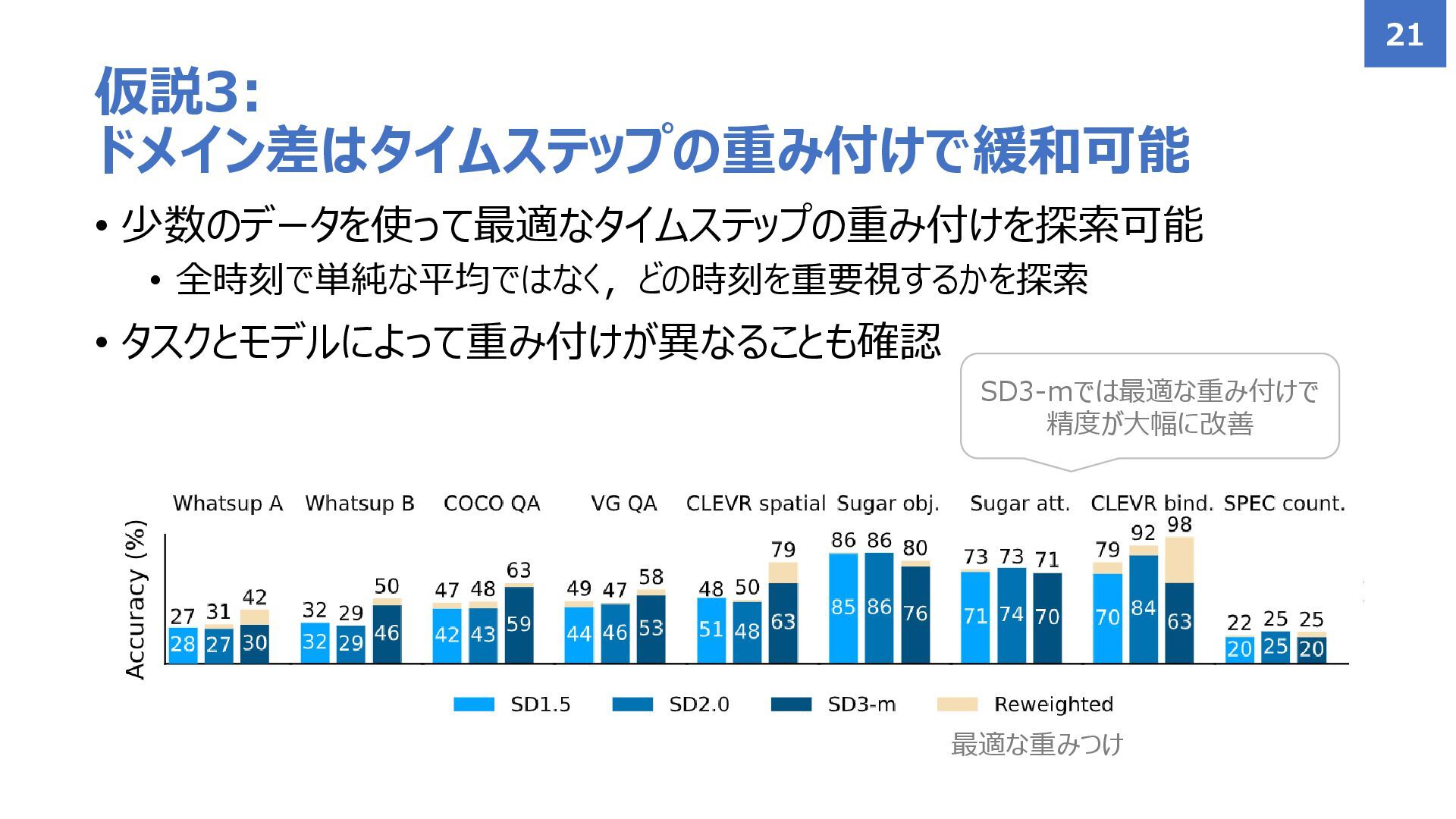
• 少数のデータを使って最適なタイムステップの重み付けを探索可能 • 全時刻で単純な平均ではなく,どの時刻を重要視するかを探索 • タスクとモデルによって重み付けが異なることも確認 仮説3: ドメイン差はタイムステップの重み付けで緩和可能 21 最適な重みつけ
SD3-mでは最適な重み付けで 精度が大幅に改善
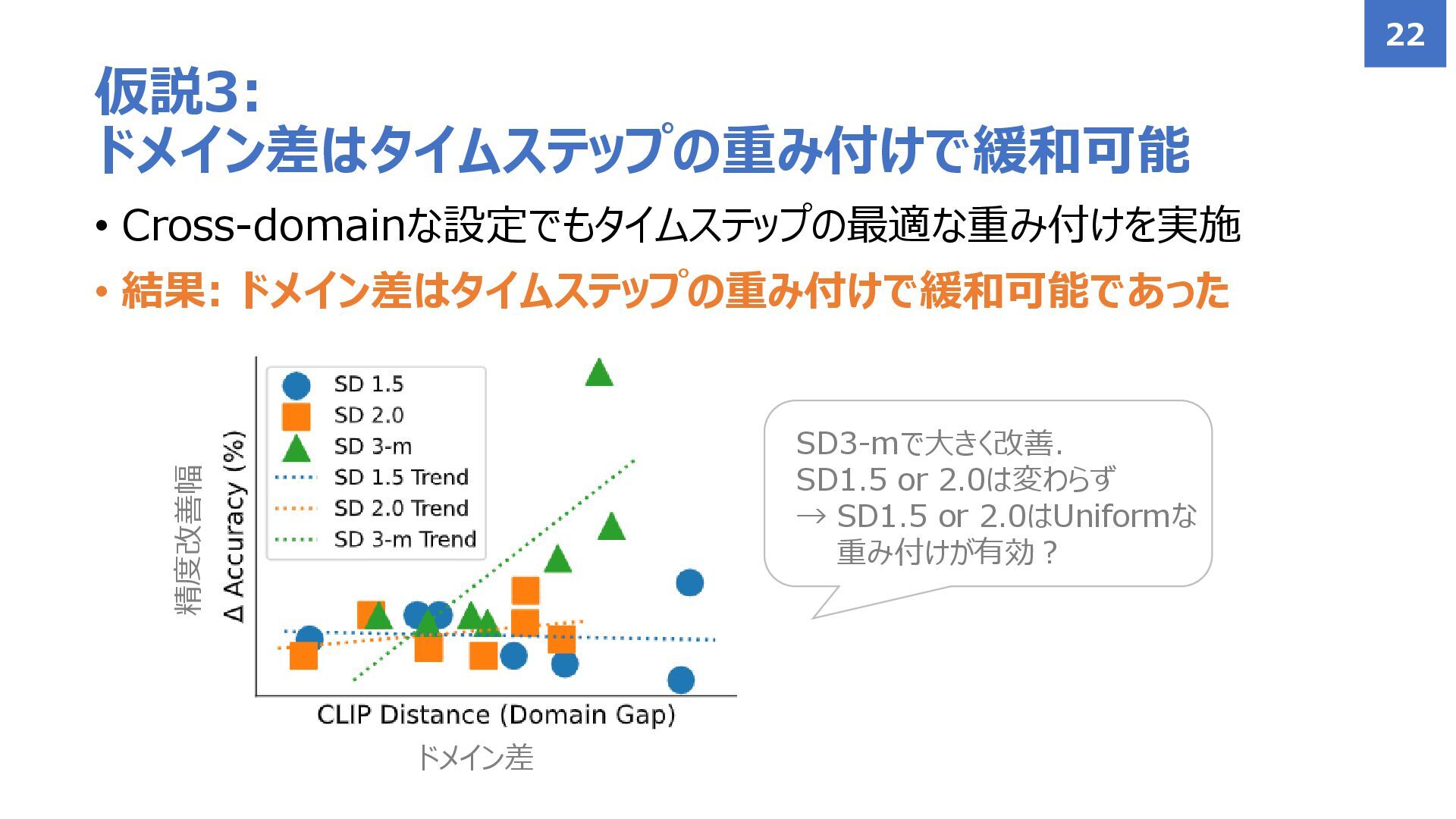
• Cross-domainな設定でもタイムステップの最適な重み付けを実施 • 結果: ドメイン差はタイムステップの重み付けで緩和可能であった 仮説3: ドメイン差はタイムステップの重み付けで緩和可能 22 精度改善幅 ドメイン差
SD3-mで大きく改善. SD1.5 or 2.0は変わらず → SD1.5 or 2.0はUniformな 重み付けが有効?
• ドメイン情報が消えていて,認識に必要な情報が残っているような タイムステップが重要であるとことが観察できた 仮説3: ドメイン差はタイムステップの重み付けで緩和可能 23
• 目的: 拡散モデルによるZero-shot分類の包括的な調査 • 結果: • 拡散モデルの構成分類がCLIPより優れているわけではない (位置検出は得意) • In-domainで生成画像を認識
(Cross-domainではドメイン差で精度が低下) • ドメイン差はタイムステップの重み付けで緩和可能 (ドメイン情報は適度に消す) • 感想 • 位置検出が得意なのはピクセルが保たれた学習をしているので納得 (CLIPでも空間情報を保存した学習が必要では?) • 時刻に応じて画像情報の「何が」「どれくらい」消えるのかを解析するのも面白そう Summary 24
{kind=link}
![• Diffusion Classifiers Understand Compositionality, but Conditions Apply[Jeong+, arxiv preprint]](https://files.speakerdeck.com/presentations/b31630408c4a46ac914fd559a1666268/slide_1.jpg){kind=link}
![• 画像とテキストそれぞれの特徴ベクトルの類似度によって認識 • 苦手なタスクも存在 • 語順,空間的関係,カウント,構成認識など CLIPのZero-shot分類 2 [1] Radford+,ICML2021](https://files.speakerdeck.com/presentations/b31630408c4a46ac914fd559a1666268/slide_2.jpg){kind=link}
![• 条件付き推定ノイズの予測誤差を使って分類[1,2,3] • 拡散モデルを用いた事後確率の推定に当たる Diffusion Classifiers (DS): 拡散モデルZero-shot分類 3 [1]Li+,ICCV2023](https://files.speakerdeck.com/presentations/b31630408c4a46ac914fd559a1666268/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
![• 構成分類 (Compositional classification)[1,2] • 複数の属性や関係性を組み合わせた情報をもとに判断する分類タスク • 構成分類タスクの拡散モデルでの検証は限られている[3,4] 拡散モデルによる分類は構成分類が得意 ?](https://files.speakerdeck.com/presentations/b31630408c4a46ac914fd559a1666268/slide_6.jpg){kind=link}
{kind=link}
![• Generative AI Paradox[1] • モデルが生成できても理解 (認識)できない可能性を示唆 • 生成モデルと認識モデルが別々であるという問題が残る 「優れた生成能力」は「優れた認識能力」を意味するか?](https://files.speakerdeck.com/presentations/b31630408c4a46ac914fd559a1666268/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![• 作り方はとっても簡単 • 正例のPromptを作成 (GenEval[1] から拝借)し,画像生成 • Textとの整合性を考慮して生成画像に対して人手によるフィルタリング • NegativeなPromptを作成](https://files.speakerdeck.com/presentations/b31630408c4a46ac914fd559a1666268/slide_14.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![• 時刻tに応じてノイズレベルが変化.それに応じて生成する粗さも変化[1,2] 拡散モデルは時刻(=ノイズレベル)に応じて粗い→細かい生成 18 時刻 小 時刻 大 粗い生成 細かい生成](https://files.speakerdeck.com/presentations/b31630408c4a46ac914fd559a1666268/slide_18.jpg){kind=link}
![• 時刻tのサンプリング方法を変化させることによる認識能力への影響を調査 • 等間隔ではなくより適した方法があるはず 時刻tのサンプリング方法を最適化することが重要か? 19 [1]Li+,ICCV2023 [2]Clark+,NeurIPS2023 [3]Krojer+,NeurIPS2023 [1]より抜粋](https://files.speakerdeck.com/presentations/b31630408c4a46ac914fd559a1666268/slide_19.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}