Share
私たちのチームでは、生成AIを活用した技術に積極的に投資しています。AIエージェントが効率的に機能するには、検索基盤の整備が不可欠です。Amazon OpenSearch Service上に構築したテキスト埋め込みの検索基盤をご紹介します。また、文章の意味を理解できる言語モデルをテキストコンテンツの分類に応用する検証もおこなっています。その品質を継続的に改善するためのMLOpsパイプラインの構築までお話しします。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
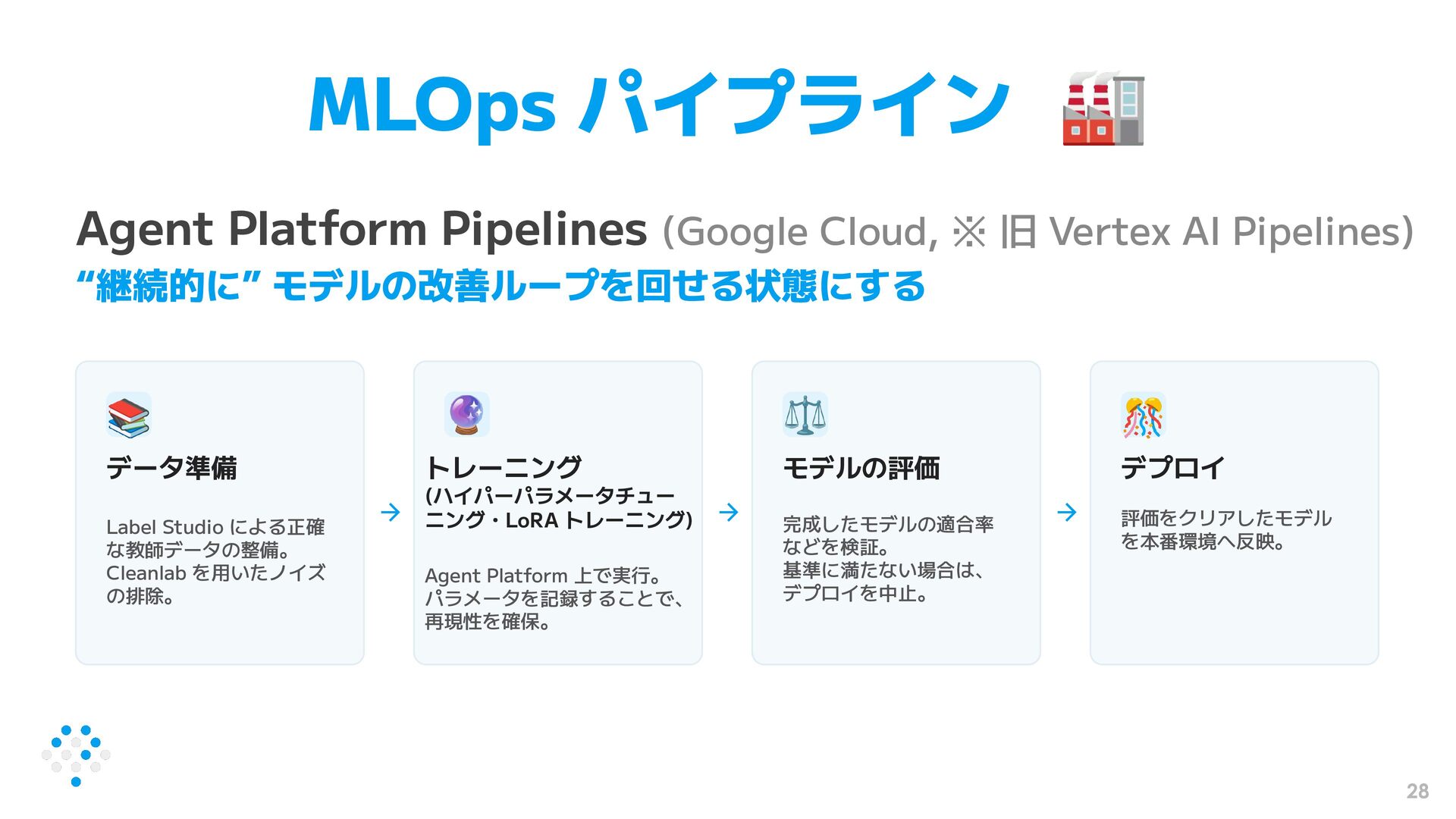{kind=link}
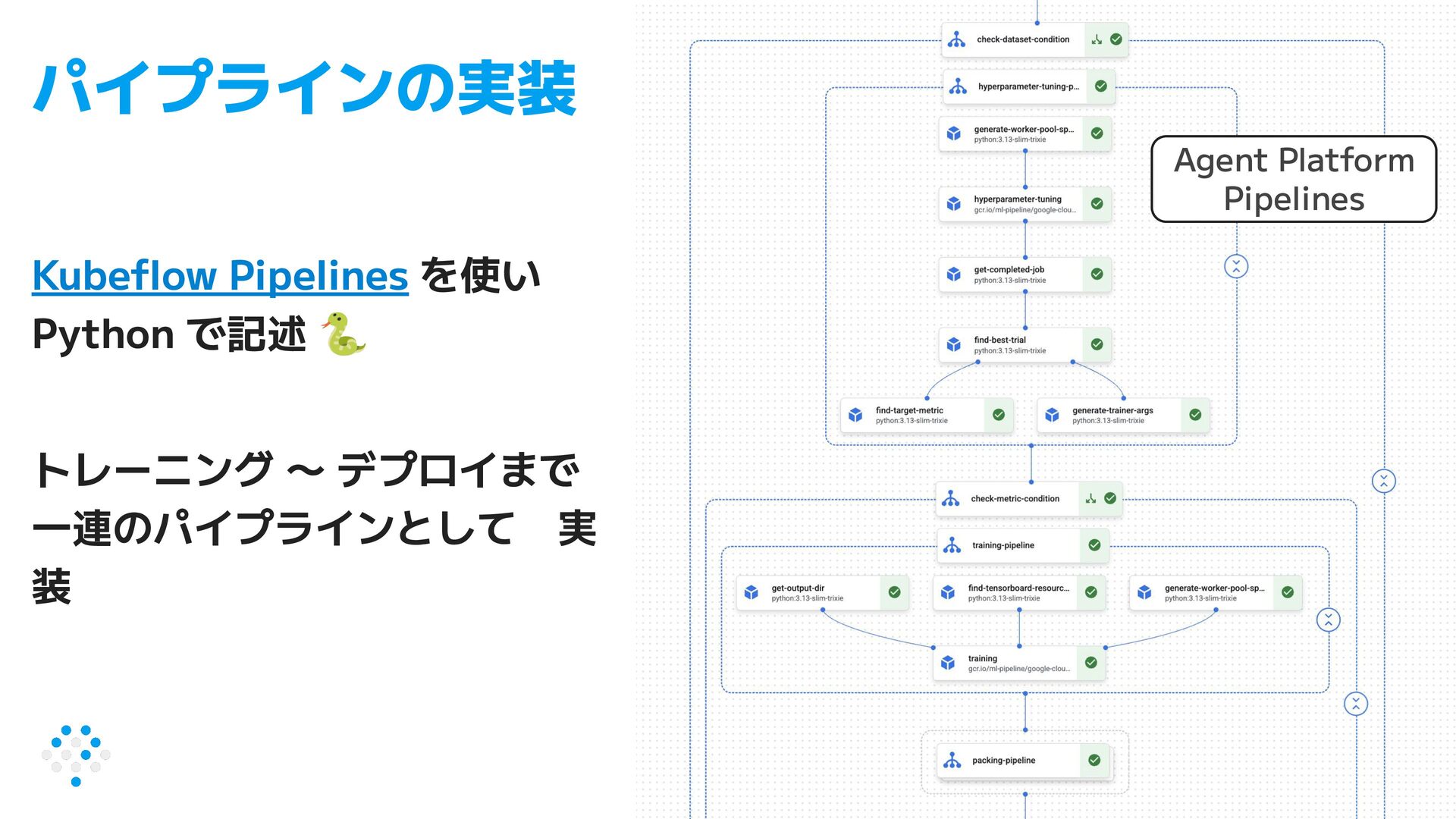{kind=link}
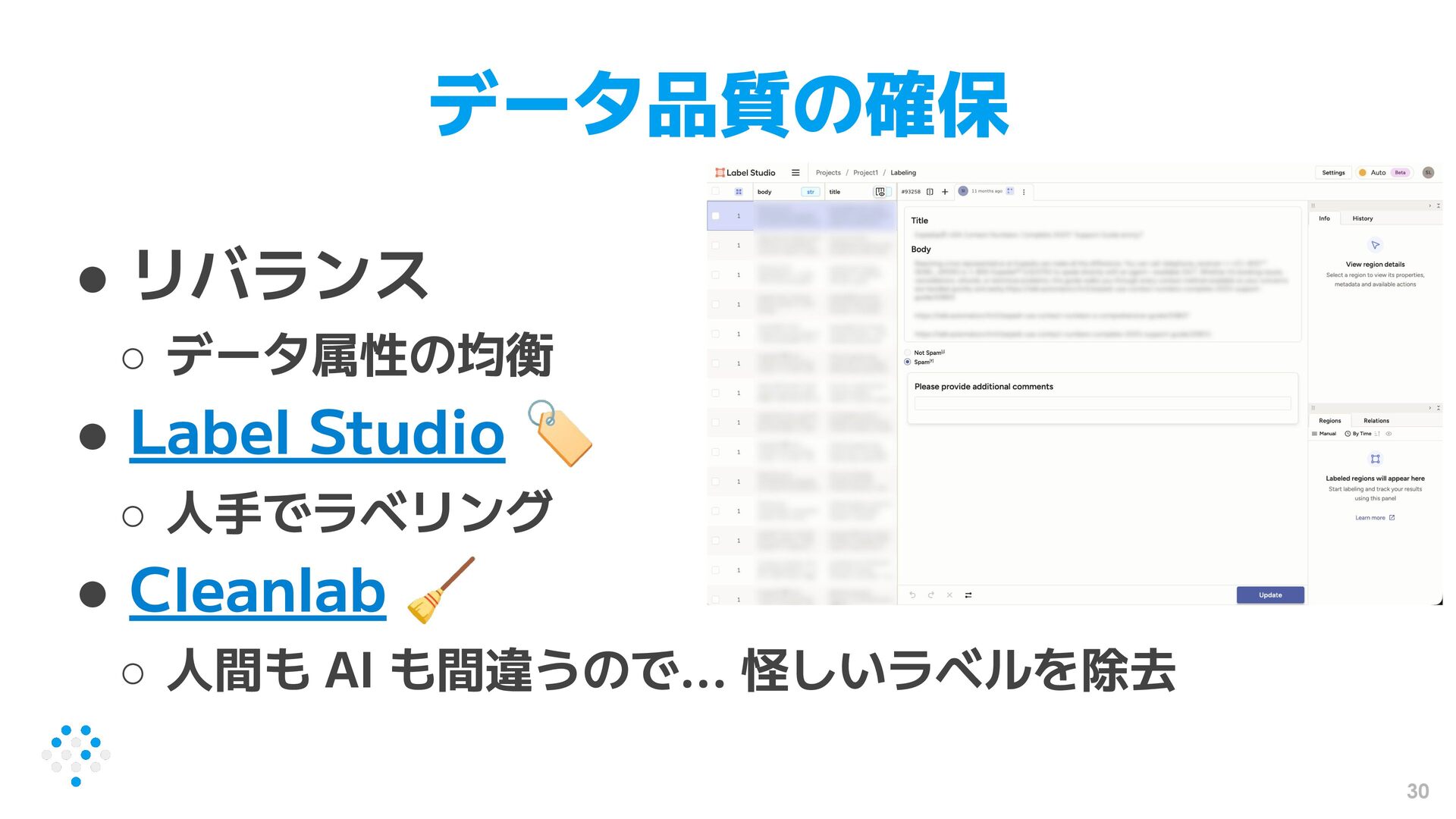{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}