COLMAP Background 01 Related works 02 Analyze the necessary conditions for successful reconstruction 03 Identify a suitable feature matching method 04 Future work 05 Conclusion 06
reconstruction from images for generating 2D floor maps. Baseline method: • We use the COLMAP for execution on a low computational resource environment. What we did: • Found the conditions required for successful reconstruction • Found the best performing feature extraction and matching methods that can satisfy the conditions for successful reconstruction • Improved the robustness of COLMAP reconstruction What we achieved: • Robustly reconstruct point cloud from the actual cleaner robot images
are experimenting automatic image collection in an actual grocery store called EZOHUB TOKYO. • Mount a camera on a cleaner robot and automatically collect grocery store images. • Much lower cost than installing a specific robot for data collection because it utilizes a cleaner robot already operating in a grocery store. A smartphone camera is mounted on a cleaner robot.
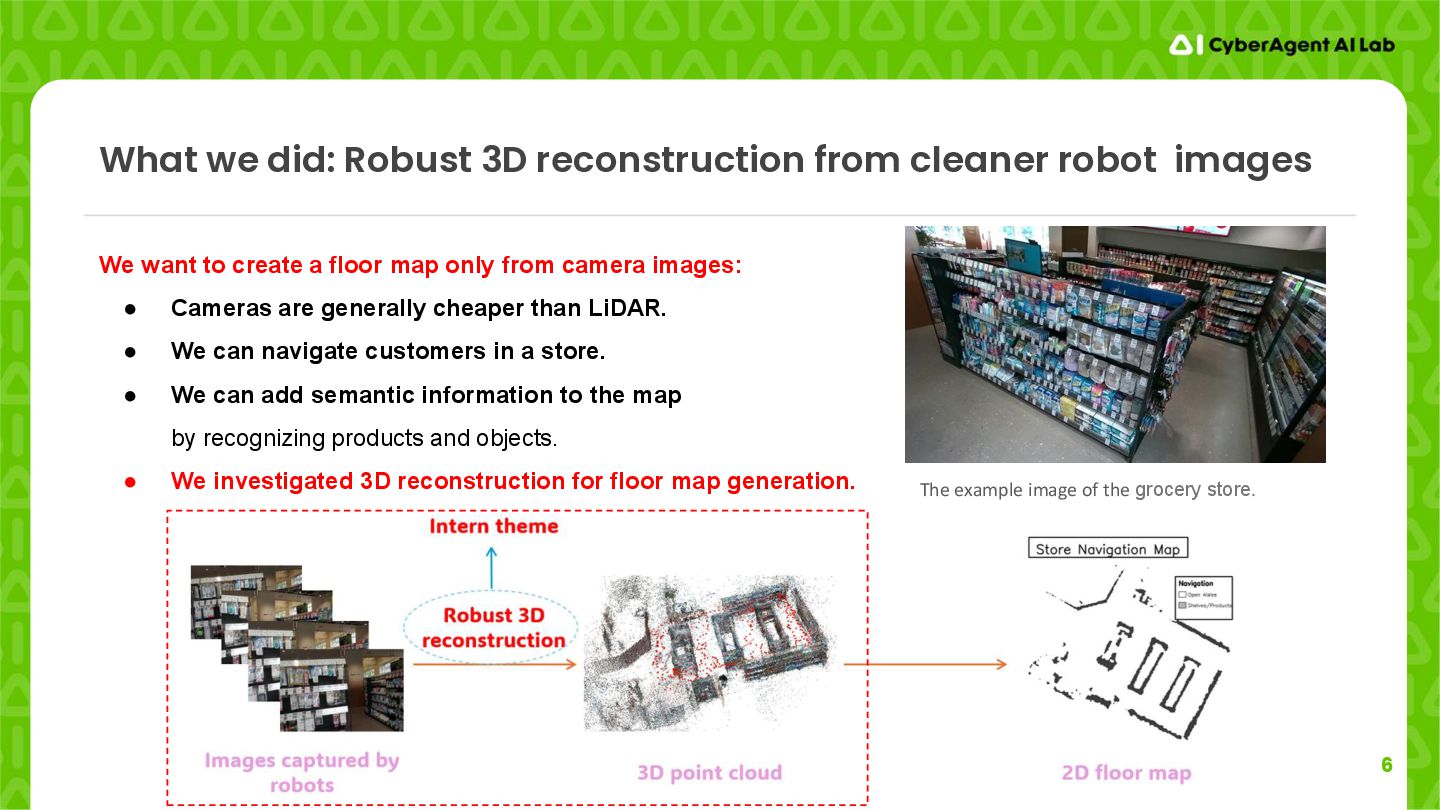
camera images: • Cameras are generally cheaper than LiDAR. • We can navigate customers in a store. • We can add semantic information to the map by recognizing products and objects. • We investigated 3D reconstruction for floor map generation. What we did: Robust 3D reconstruction from cleaner robot images The example image of the grocery store.
the cleaner robot images by improving the feature matching performance Reconstruction with DISK + LightGlue The best performing feature matching method we found Reconstruction with classic SIFT image features
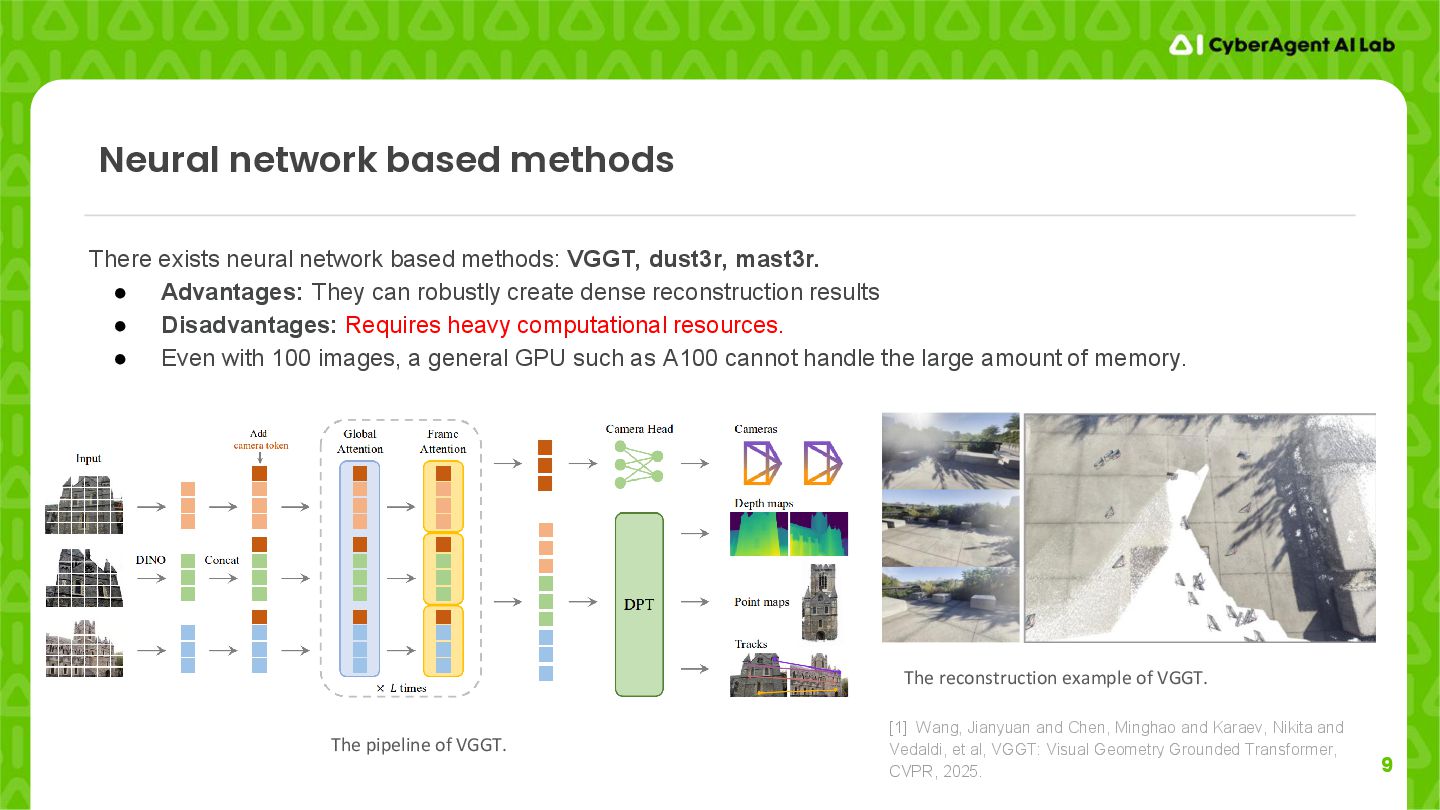
exists neural network based methods: VGGT, dust3r, mast3r. • Advantages: They can robustly create dense reconstruction results • Disadvantages: Requires heavy computational resources. • Even with 100 images, a general GPU such as A100 cannot handle the large amount of memory. [1] Wang, Jianyuan and Chen, Minghao and Karaev, Nikita and Vedaldi, et al, VGGT: Visual Geometry Grounded Transformer, CVPR, 2025. The reconstruction example of VGGT.
matching in COLMAP. COLMAP is a de facto standard software for 3D reconstruction. [2] Schonberger, Johannes Lutz and Frahm, Jan-Michael, Structure-from-Motion Revisited, CVPR, 2016. Flaws of COLMAP • Lacks the feature extraction and matching performance ◦ COLMAP uses the classic SIFT feature • We needed to improve the feature matching performance for robust grocery store reconstruction
Sarlin, Cesar Cadena, Roland Siegwart, Marcin Dymczyk, From Coarse to Fine: Robust Hierarchical Localization at Large Scale, CVPR, 2019. We use HLoC as a feature extraction & matching library for improving feature extraction and matching robustness. • HLoC contains several feature extraction and matching methods. • We can easily switch them and find the best performing one. → HLoC simplifies debugging and performance analysis
two parts: correspondence search, and incremental reconstruction. What we did to improve the performance: • Investigated the key conditions for successful reconstruction. • Investigated the best performing feature extraction & matching methods that satisfy the key conditions. [2] Schonberger, Johannes Lutz and Frahm, Jan-Michael, Structure-from-Motion Revisited, CVPR, 2016. Improved robustness of feature matching with HLoC Analyzed the reconstruction pipeline and found the key conditions for successful reconstruction
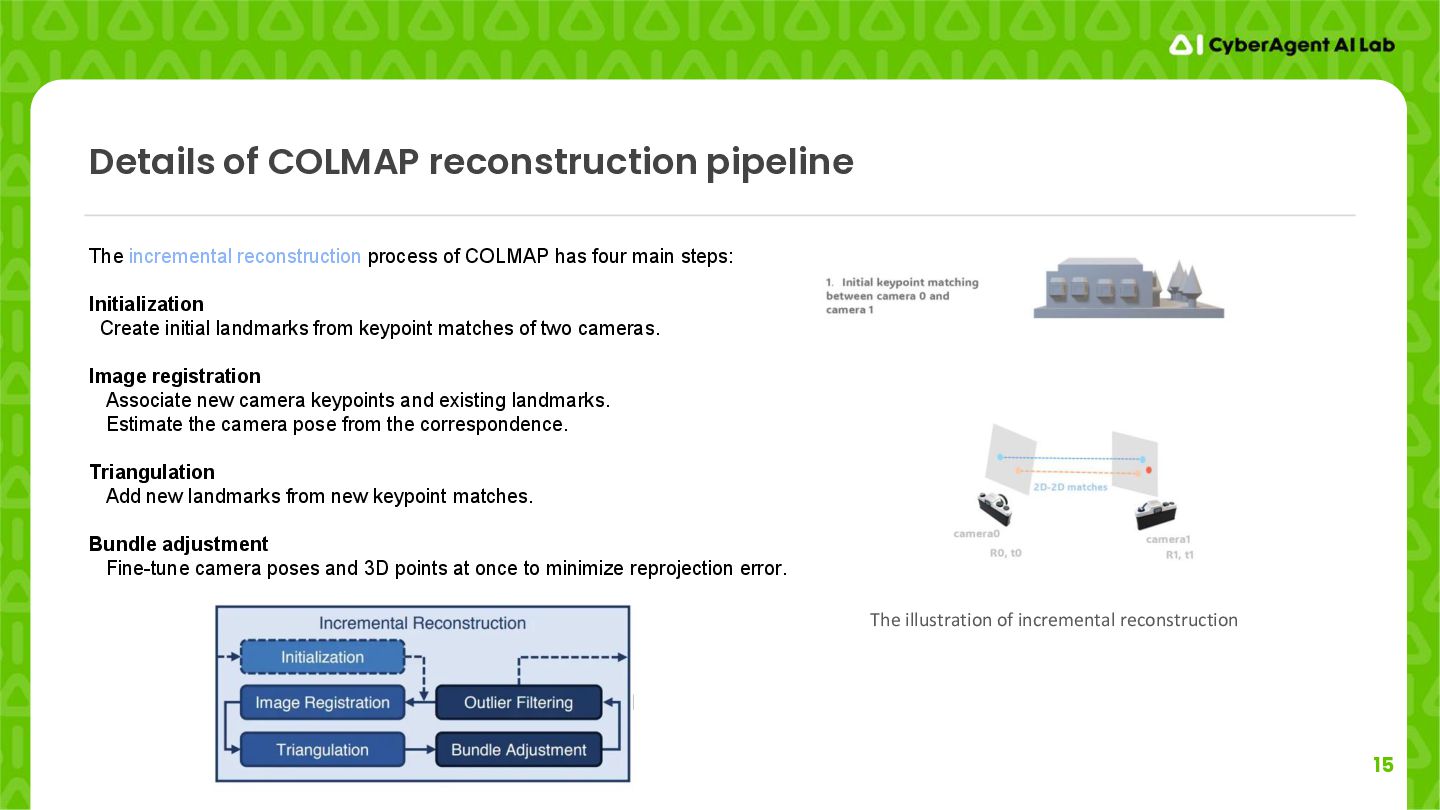
reconstruction The incremental reconstruction process of COLMAP has four main steps: Initialization Create initial landmarks from keypoint matches of two cameras. Image registration Associate new camera keypoints and existing landmarks. Estimate the camera pose from the correspondence. Triangulation Add new landmarks from new keypoint matches. Bundle adjustment Fine-tune camera poses and 3D points at once to minimize reprojection error.
key conditions for successful reconstruction Method 1. Conduct two extremely challenging datasets. 2. Analyze the reconstruction results of these two challenging datasets. We found four key conditions for successful reconstruction 1. Sufficient 2D-2D inlier matches 2. Sufficient triangulation angles 3. Sufficient number of 3D landmarks 4. Geometrically accurate, sufficient 2D-3D correspondences
failed because it could not find the initial image pair. Through the reconstruction experiment of dataset 1, we found two conditions for successful initial image selection: • Sufficient 2D-2D inlier matches • Sufficient triangulation angles If COLMAP couldn’t find the good initial image pair, overall reconstruction will fail.
because of image registration failure. We found two conditions for successful reconstruction • Sufficient number of 3D landmarks • Geometrically accurate, sufficient 2D-3D correspondences
2D-2D inlier matches • Sufficient triangulation angles • Sufficient number of 3D landmarks • Geometrically accurate, sufficient 2D-3D correspondences To satisfy these conditions above, we need • Input images with large overlaps with sufficiently large viewpoint angles → Almost uncontrollable, because we cannot control the cleaner robot • Geometrically accurate many keypoint matches → Controllable. We can replace the feature extraction and matching algorithm. → We tried to identify feature extraction and matching method that can generate accurate, large number of matches.
robust feature extraction and matching method • Ran experiments on various grocery store dataset to find the best method ◦ Handheld camera dataset ◦ Actual cleaner robot dataset We replaced the feature extraction and matching method in the experiment
in EZOHUB TOKYO • Handheld captured RGB images from RealSense D455i • Created 10 small image sets ◦ Each contains 100 images • Contains both easy and difficult cases ◦ Difficult cases have little texture Easy Difficult Viewpoint variation Less texture
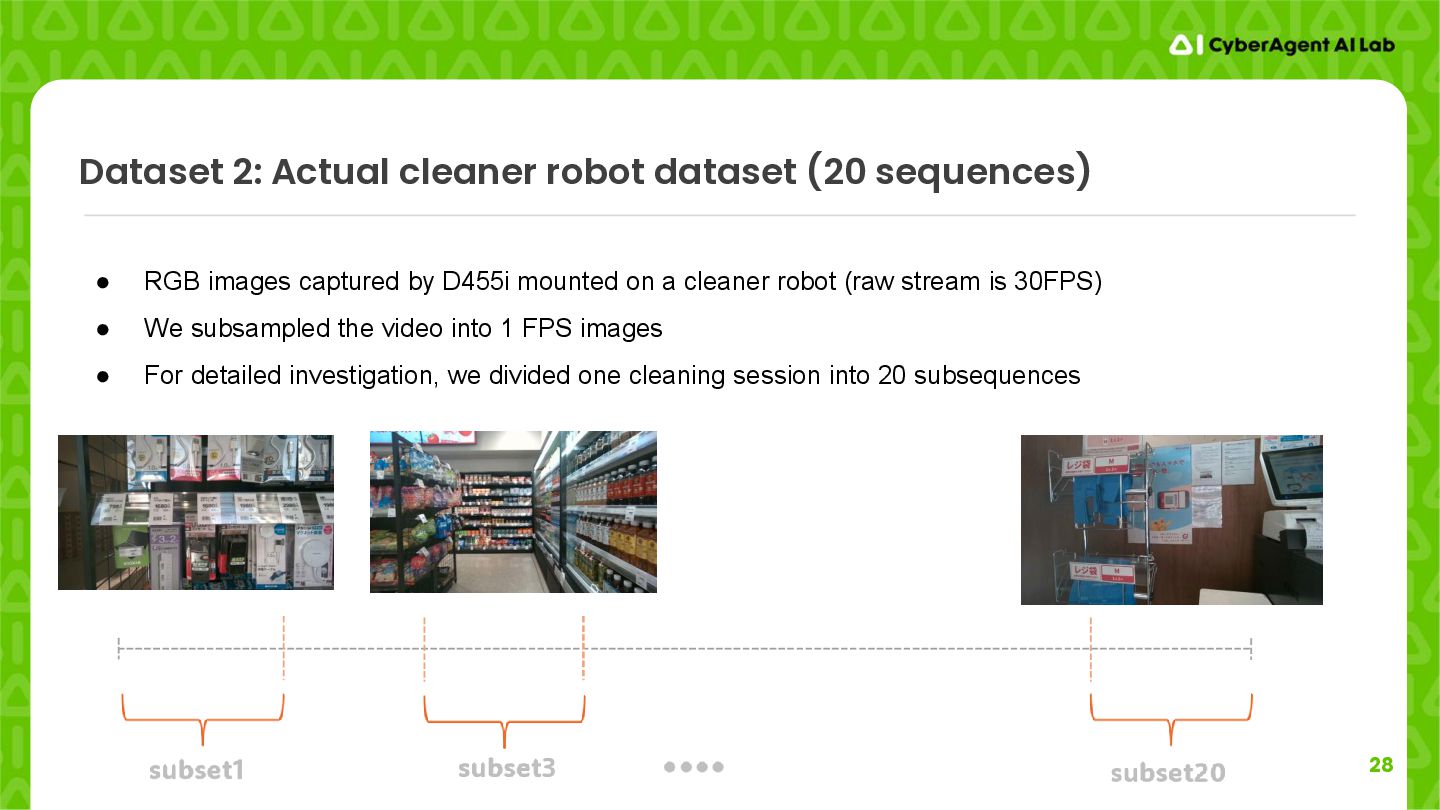
RGB images captured by D455i mounted on a cleaner robot (raw stream is 30FPS) • We subsampled the video into 1 FPS images • For detailed investigation, we divided one cleaning session into 20 subsequences
We applied feature extractors and matchers contained in HLoC • Used available 21 combinations of extractors and matchers • Ignored incompatible extractor & matcher combinations • Ignored superglue because it’s computationally demanding Explanation of NN-family (nearest neighbor search) • NN-mutual: mutual nearest neighbor matching • NN-ratio: nearest neighbor matching with ratio filtering
Good metric for success / failure of reconstruction. • Number of correctly registered images to the number of input images. The number of reconstructed 3D points → Important for robust image registration • The more 3D landmarks the point cloud has, the more robust the pose estimation will be. Track length → Indicates strength of image descriptor and matcher • A higher mean track length indicates that the same 3D points are tracked across more camera views, which generally suggests a more robust reconstruction with better triangulation. Reprojection error → Geometric accuracy of the reconstruction result. • It is a geometric error corresponding to the image distance between a projected point and a measured one. The smaller reprojection error denotes the more robust reconstruction.
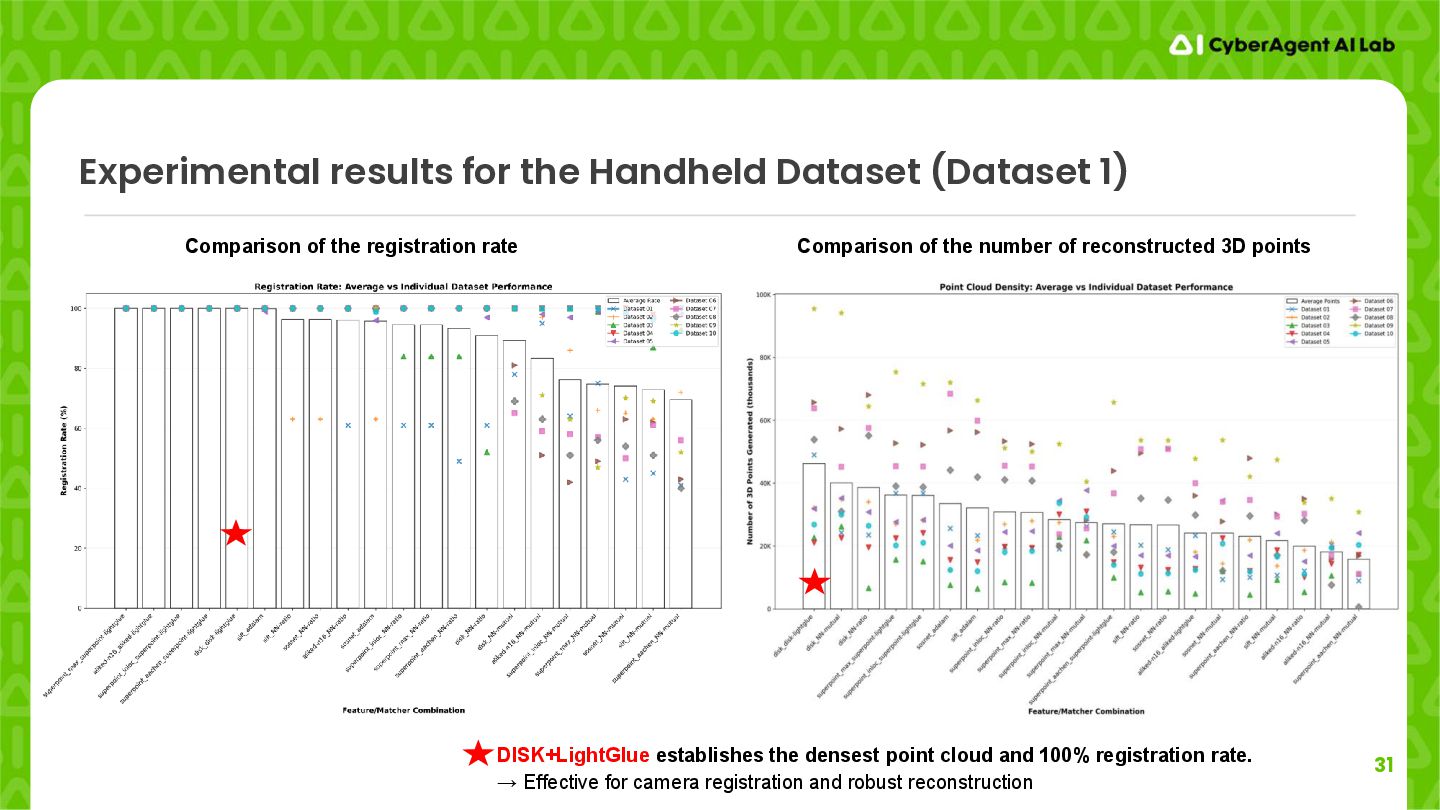
of the registration rate Comparison of the number of reconstructed 3D points DISK+LightGlue establishes the densest point cloud and 100% registration rate. → Effective for camera registration and robust reconstruction
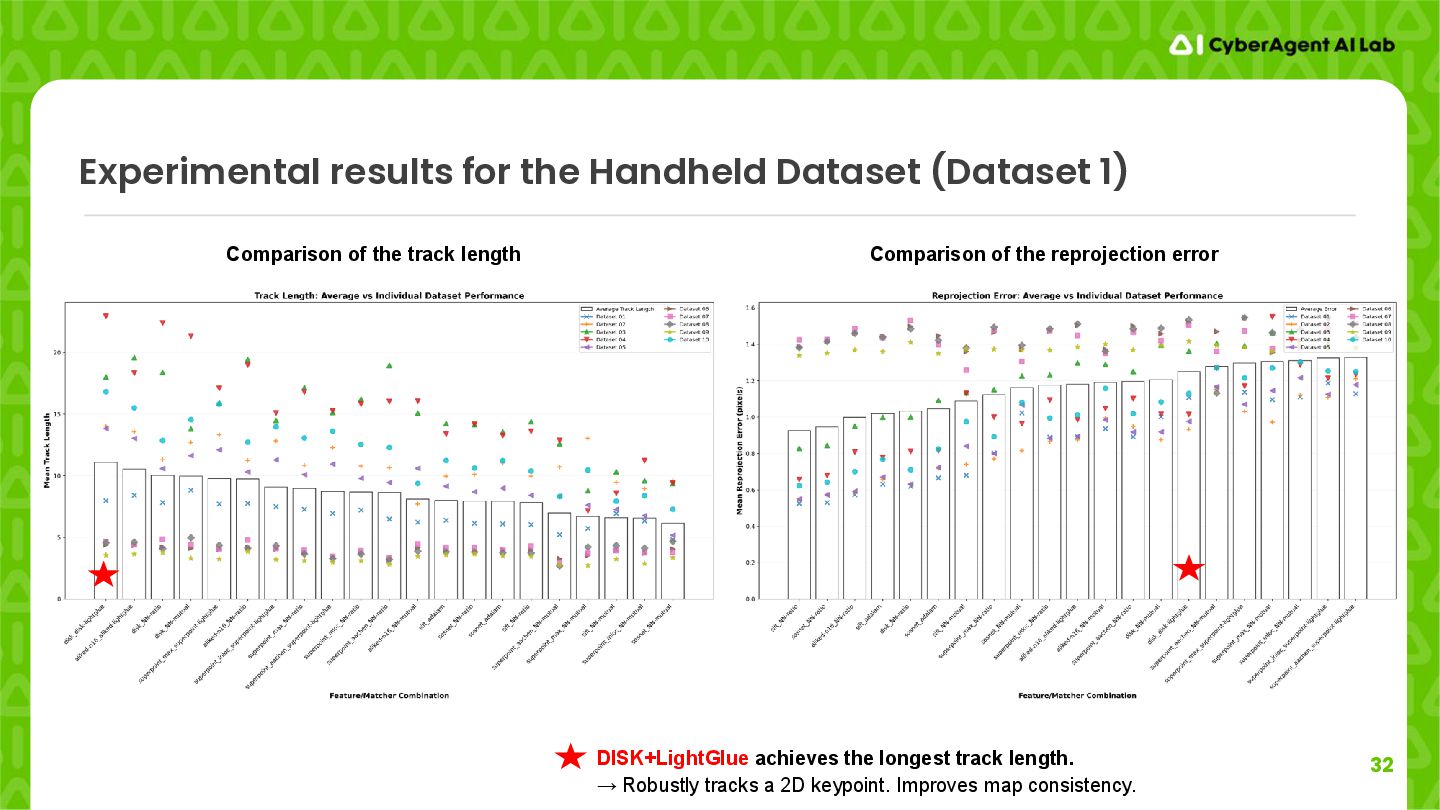
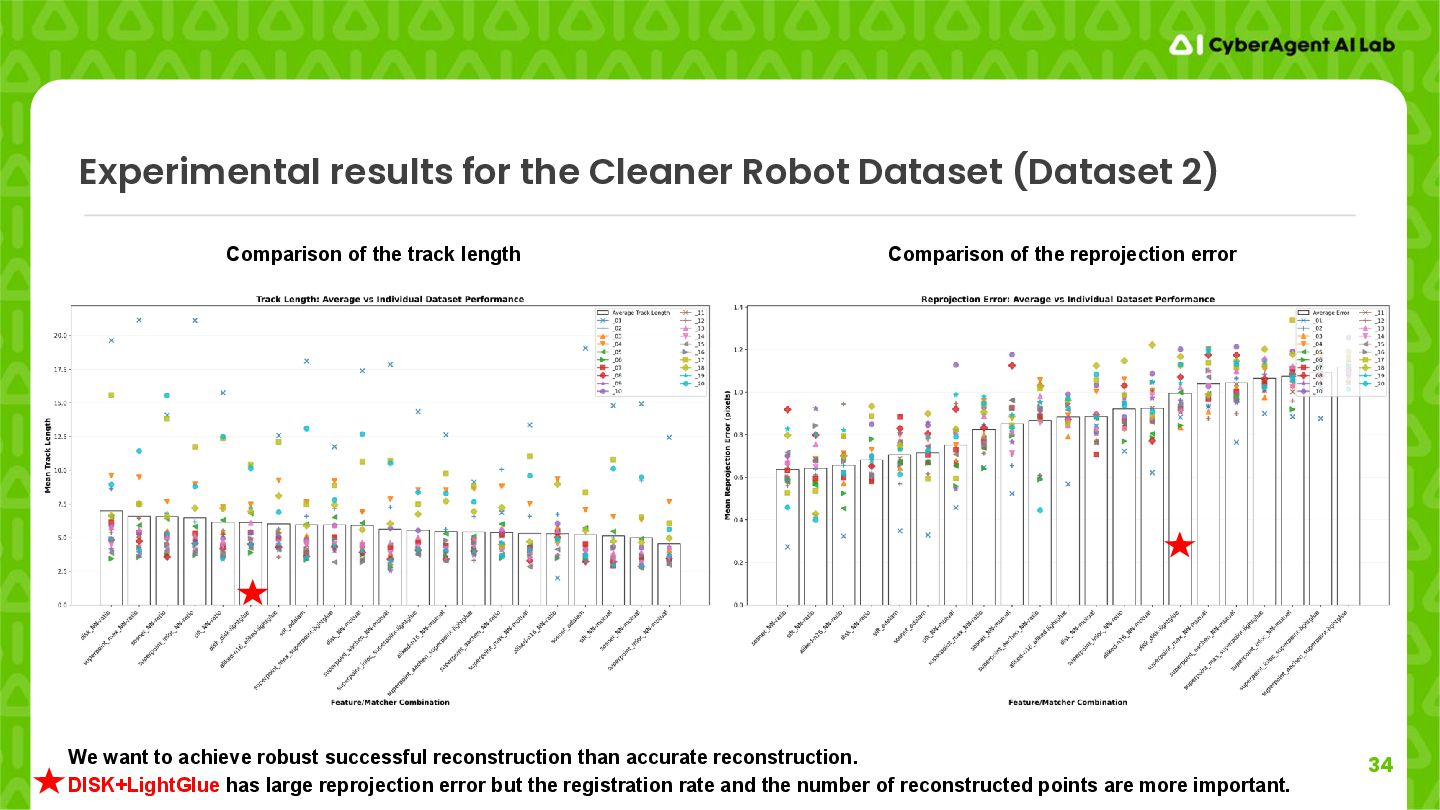
of the track length Comparison of the reprojection error DISK+LightGlue achieves the longest track length. → Robustly tracks a 2D keypoint. Improves map consistency.
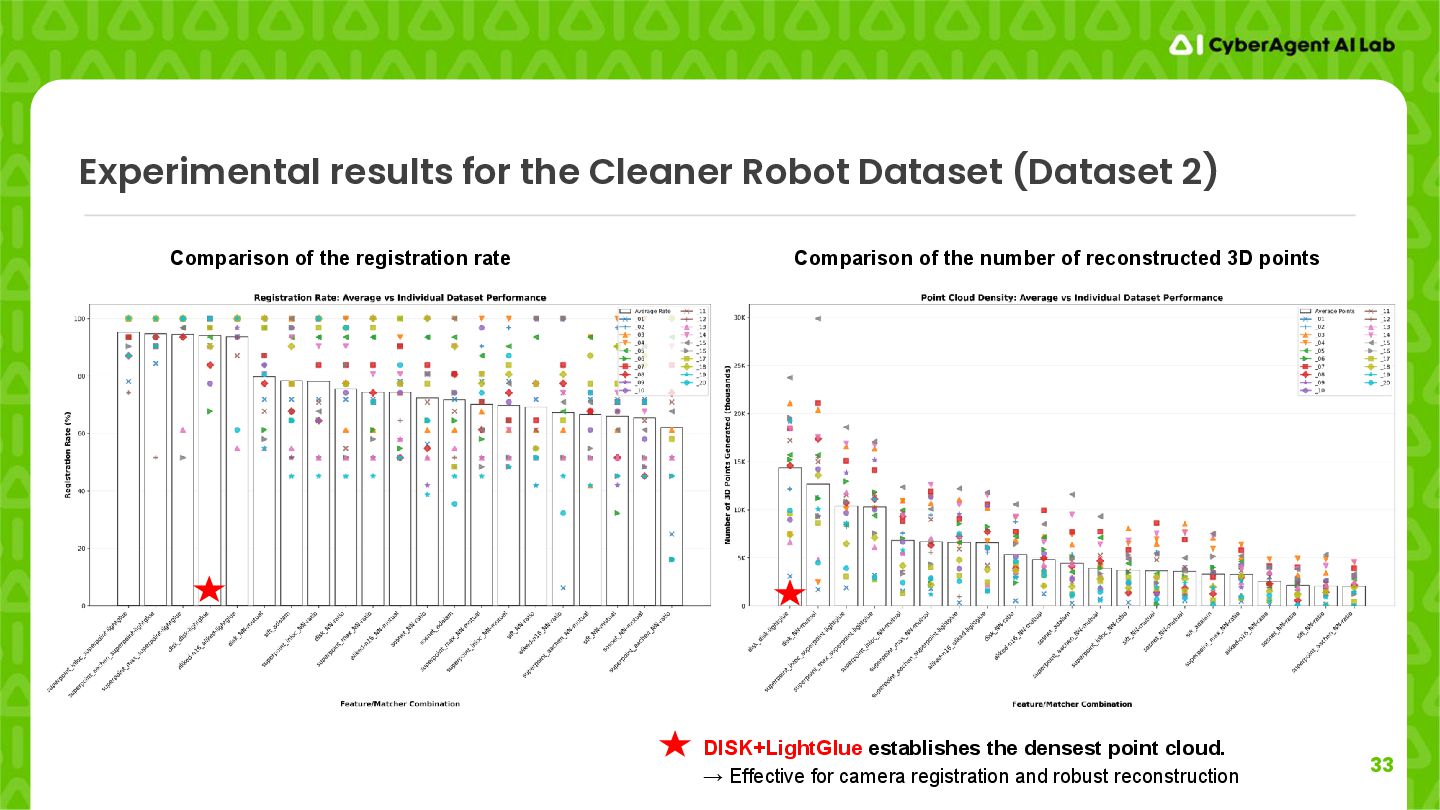
DISK+LightGlue establishes the densest point cloud. → Effective for camera registration and robust reconstruction Comparison of the registration rate Comparison of the number of reconstructed 3D points
We want to achieve robust successful reconstruction than accurate reconstruction. DISK+LightGlue has large reprojection error but the registration rate and the number of reconstructed points are more important. Comparison of the track length Comparison of the reprojection error
LightGlue → DISK+LightGlue had the best performance in terms of dense keypoint extraction and matching About LightGlue feature matcher: Compared to classic feature descriptors like SIFT, LightGlue has two main advantages. 1. LightGlue can get more global-aware features while classic SIFT feature captures very local context in the descriptor. Therefore the LightGlue’s descriptors have strong discriminativeness for distinguishing each other. 2. Classic descriptors that only use the information in one single image. LightGlue extracts descriptive information at the feature extraction stage by cross-image interaction. About DISK feature extractor: The DISK feature detector is designed to obtain many keypoints from images, allowing for dense reconstruction results. 1. DISK formulated local feature matching as a Reinforcement Learning problem, where the objective is to maximize the number of correct matches.
for successful reconstruction from the COLMAP source code and reconstruction behavior. ◦ Sufficient 2D-2D inlier matches ◦ Sufficient triangulation angles ◦ Sufficient number of 3D landmarks ◦ Geometrically accurate, sufficient 2D-3D correspondences • Found the best performing feature extraction and matching method that satisfies the conditions above through the experiment. • Succeeded robust reconstruction from the actual cleaner robot images for floor map generation.
SIFT + Nearest Neighbor vs DISK + LightGlue. We can robustly reconstruct the point cloud for the scenes that the ordinary SIFT feature fails. DISK + LightGlue SIFT + NN-mutual
with fast speed. • Try to employ the reconstruction process only using low computational resources, such as CPUs. • Expected to create a floor map with low-cost sensor observations, such as web camera.
Sufficient 2D-2D inlier matches ◦ Sufficient triangulation angles ◦ Sufficient number of 3D landmarks ◦ Geometrically accurate, sufficient 2D-3D correspondences • DISK+LightGlue was identified as the most robust combination after testing 21 different feature and matcher types. • When applied to a real-world cleaner robot dataset, the DISK+LightGlue method could ensure the successful reconstruction.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![10 COLMAP [2] The example of the feature extraction and](https://files.speakerdeck.com/presentations/42f708ab43954d9b8910dea7bbe18a78/slide_9.jpg){kind=link}
![11 We use HLoC [4] for efficient experiment [4] Paul-Edouard](https://files.speakerdeck.com/presentations/42f708ab43954d9b8910dea7bbe18a78/slide_10.jpg){kind=link}
![12 How we improved COLMAP [2] COLMAP basically consists of](https://files.speakerdeck.com/presentations/42f708ab43954d9b8910dea7bbe18a78/slide_11.jpg){kind=link}
{kind=link}
![14 Investigation of required conditions for successful reconstruction [2] Schonberger,](https://files.speakerdeck.com/presentations/42f708ab43954d9b8910dea7bbe18a78/slide_13.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![25 Improve robustness of feature matching [2] Schonberger, Johannes Lutz](https://files.speakerdeck.com/presentations/42f708ab43954d9b8910dea7bbe18a78/slide_24.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}