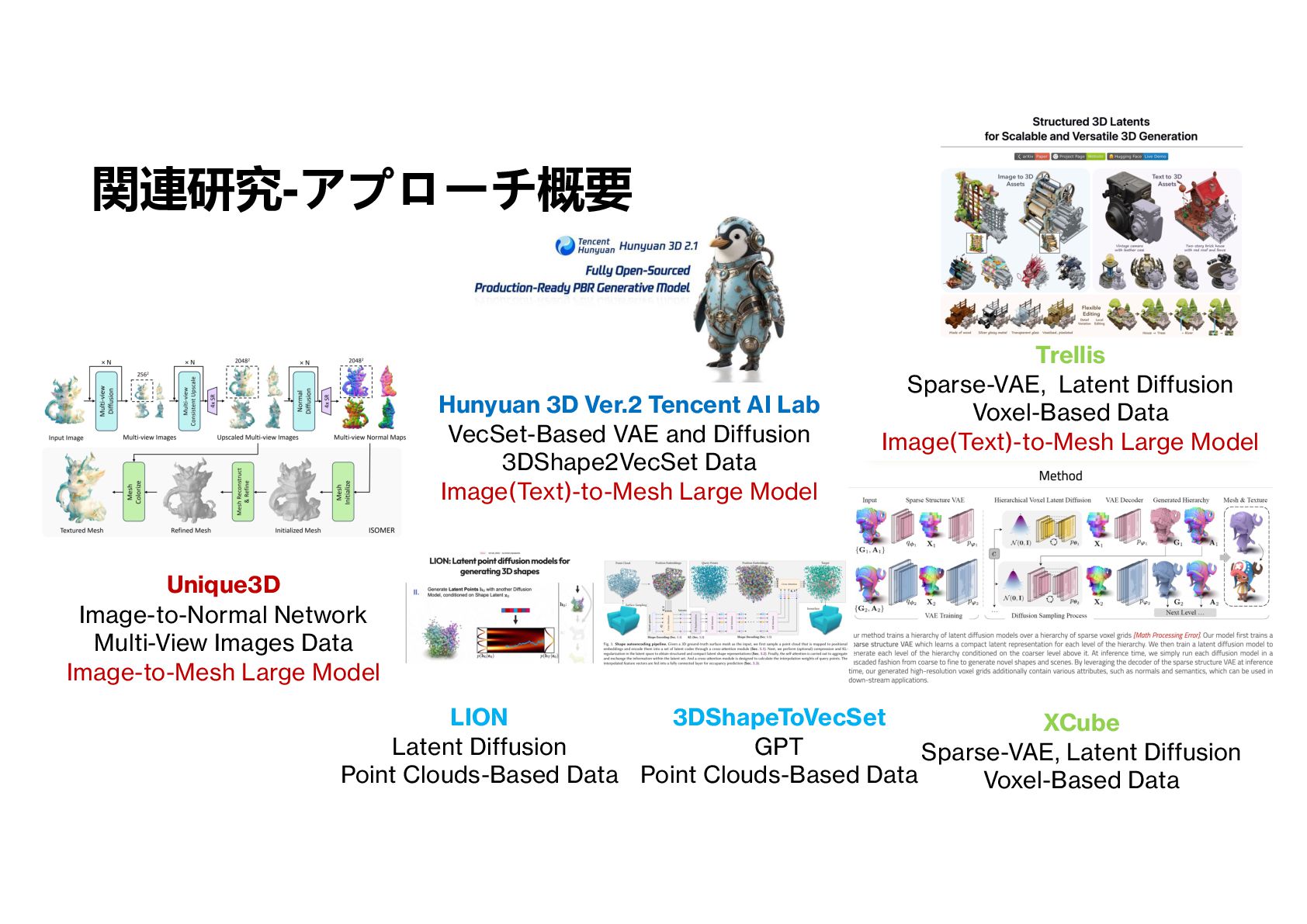
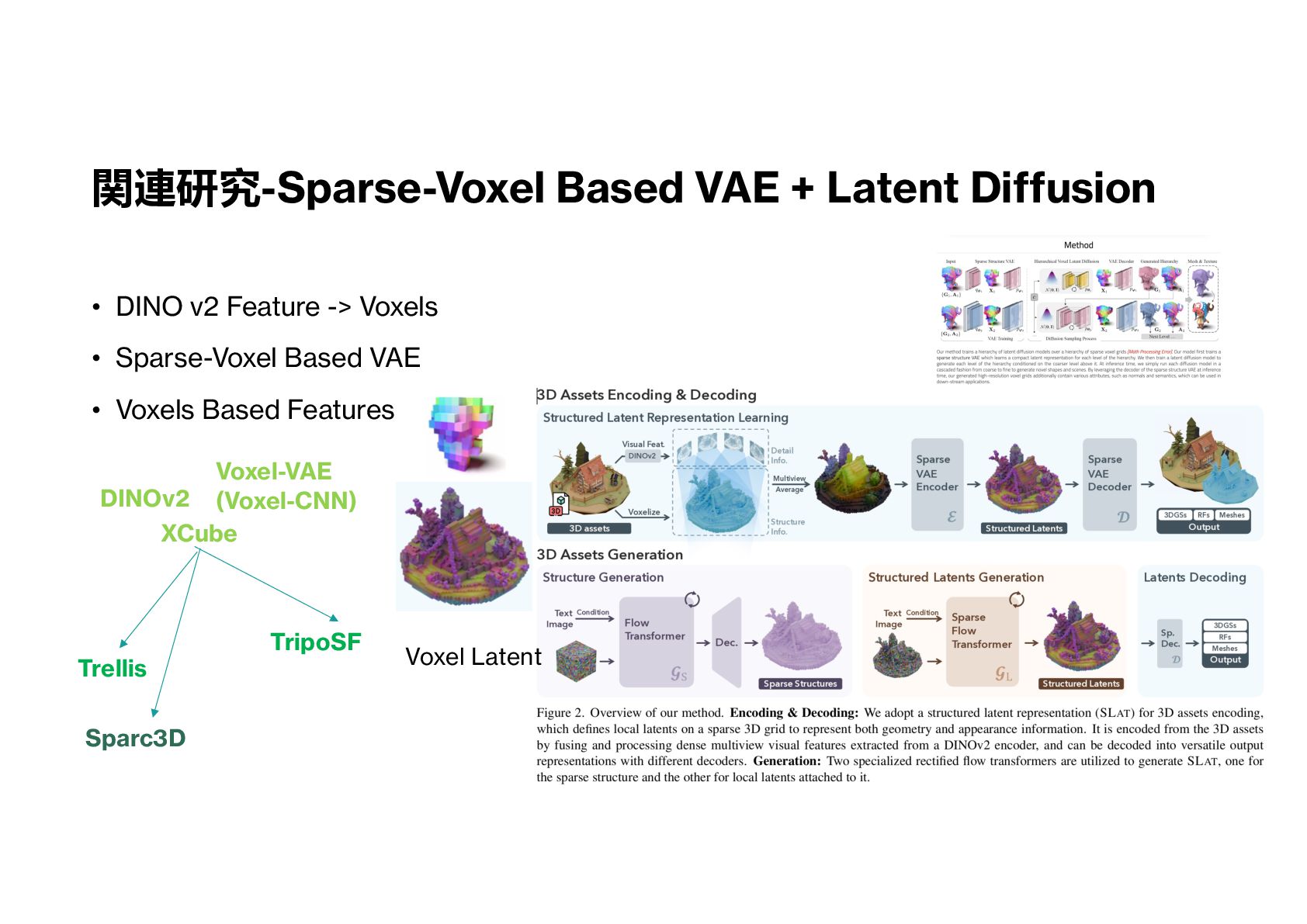
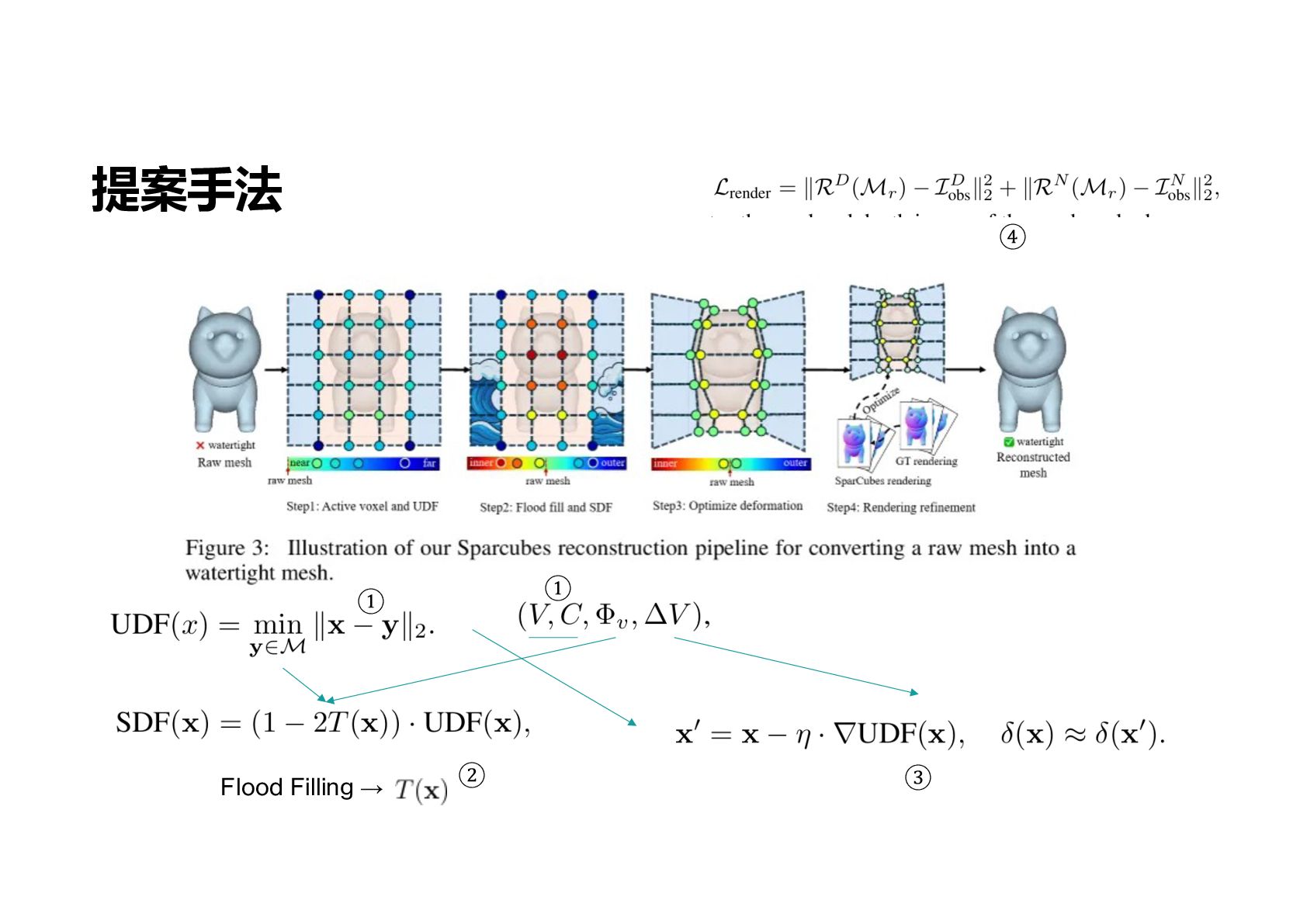
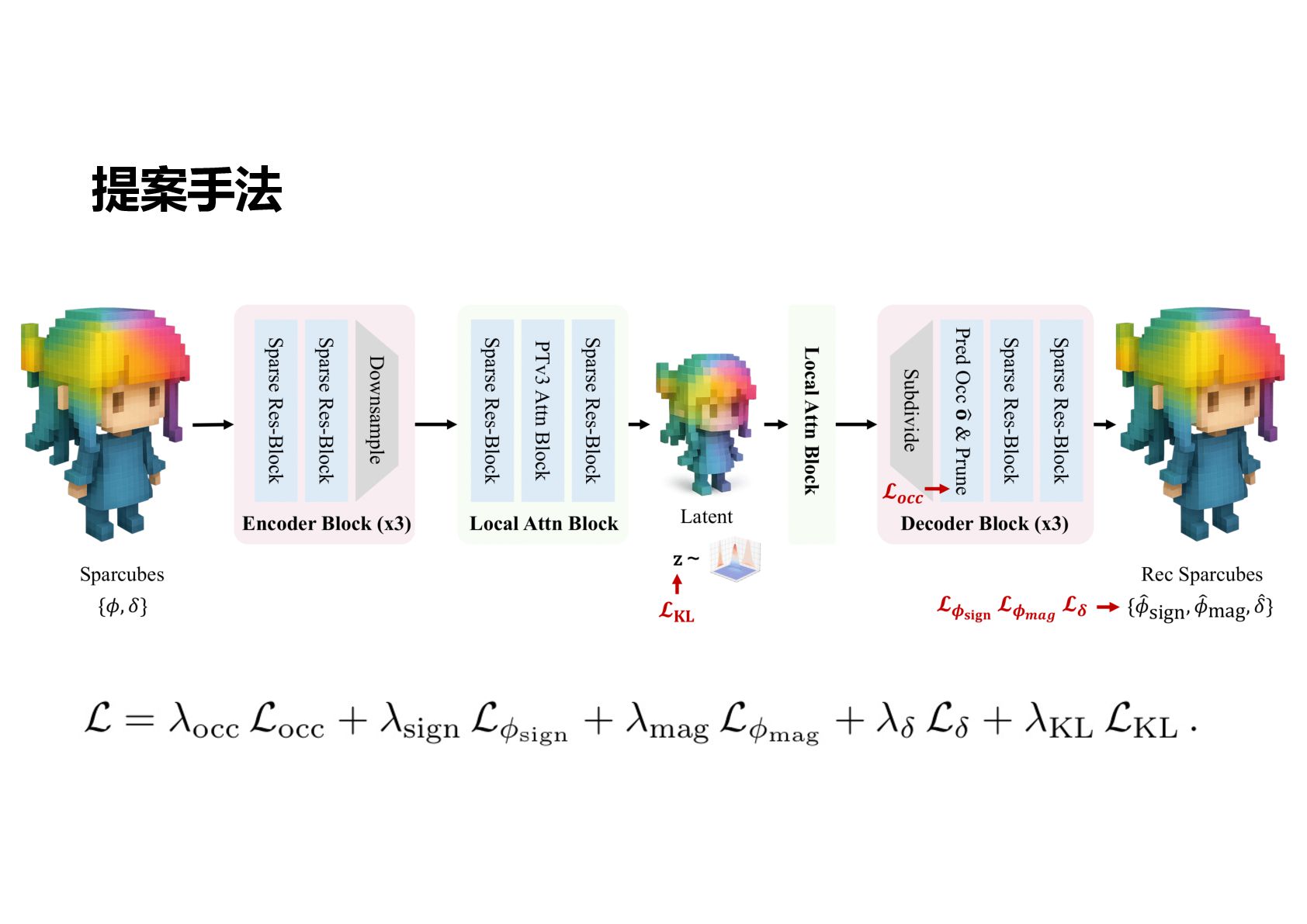
再現性 破壊における 3D 分割形状表現 Sparc3D Sparse-VAE, Latent Diffusion Voxel-Based Data Image-to-Mesh Large Model Fine-Tuned from Trellis Trellis Sparse-VAE, Latent Diffusion Voxel-Based Data Image(Text)-to-Mesh Large Model
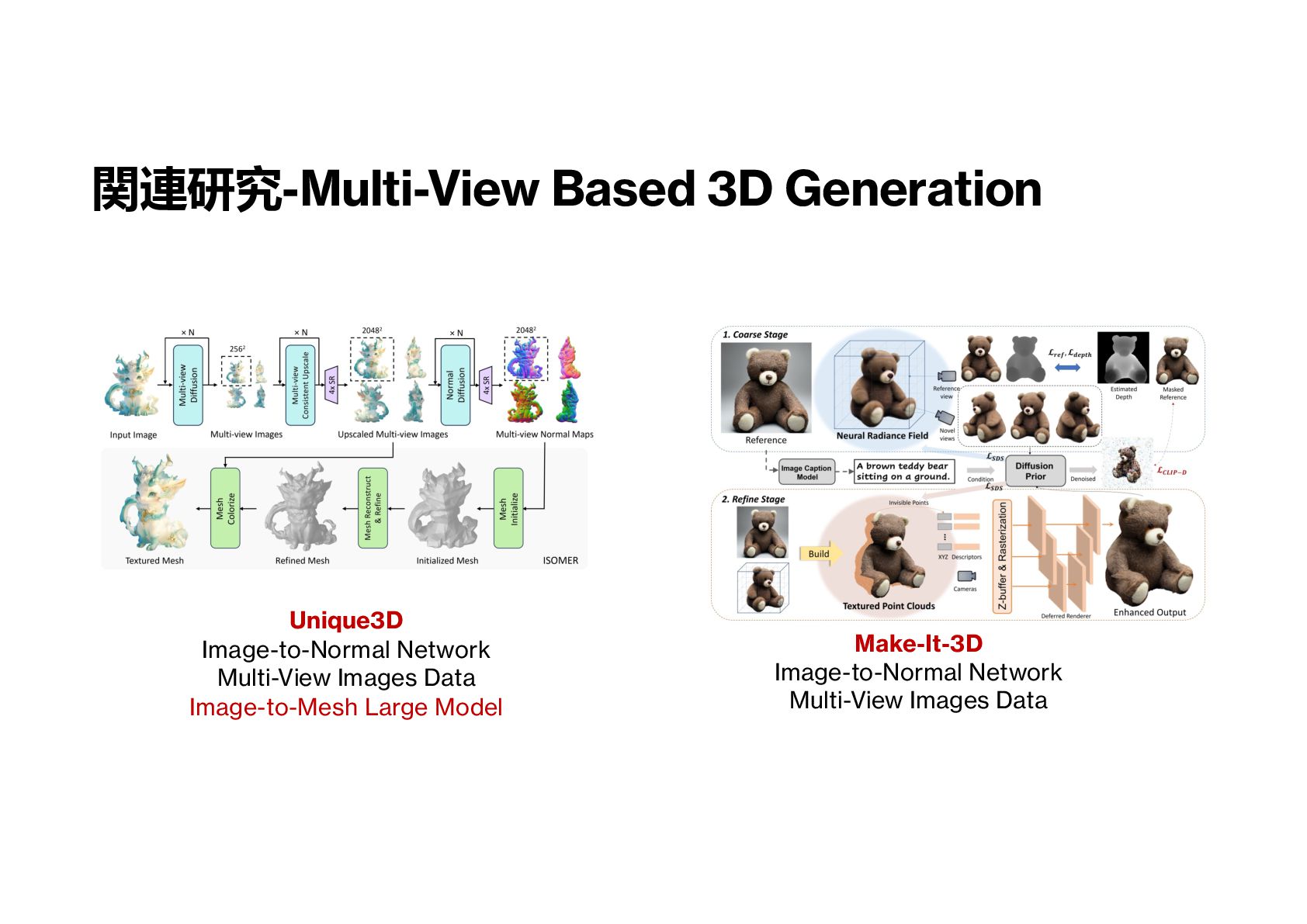
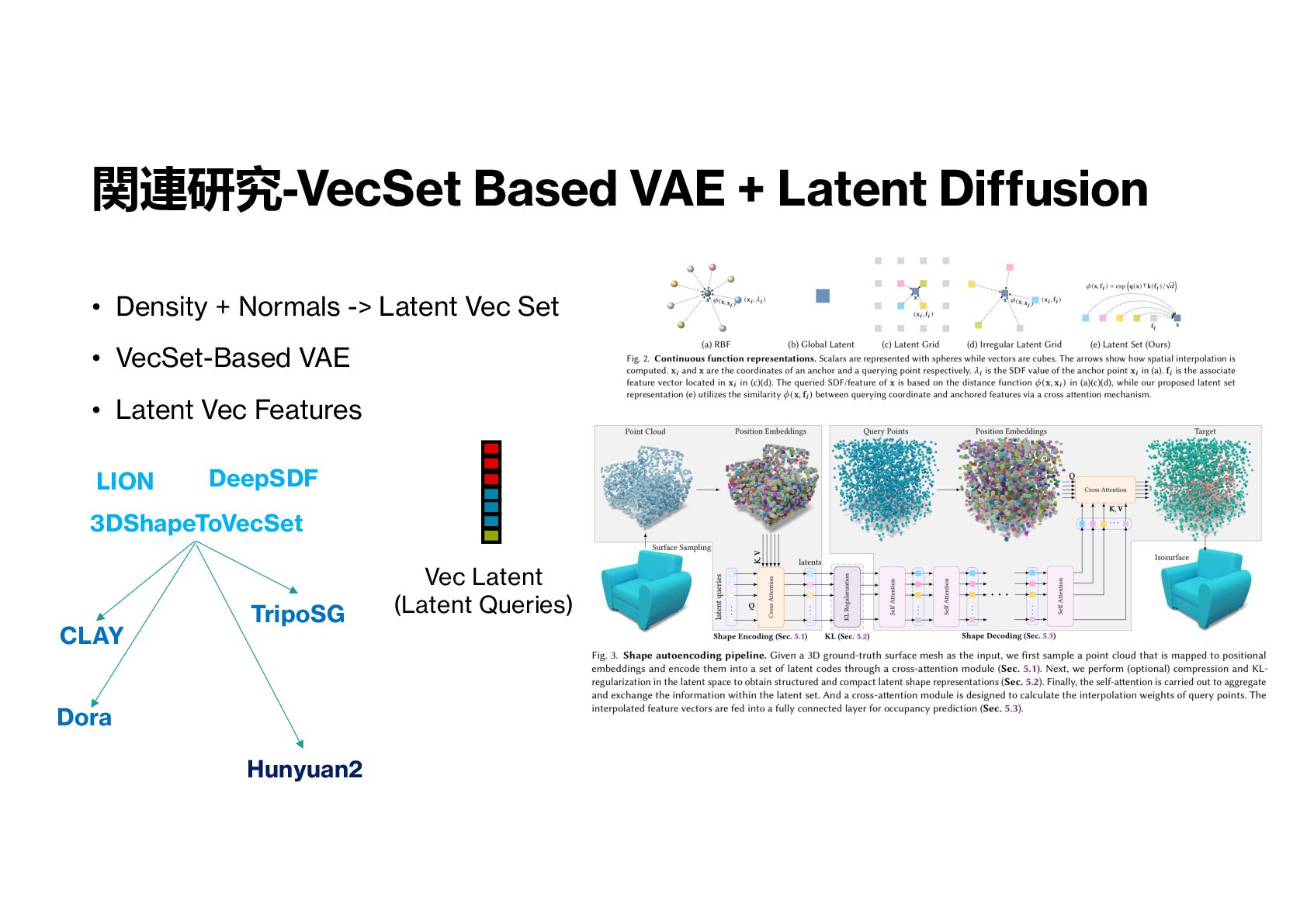
3DShape2VecSet Data Image(Text)-to-Mesh Large Model 関連研究-アプローチ概要 LION Latent Diffusion Point Clouds-Based Data XCube Sparse-VAE, Latent Diffusion Voxel-Based Data Trellis Sparse-VAE, Latent Diffusion Voxel-Based Data Image(Text)-to-Mesh Large Model Unique3D Image-to-Normal Network Multi-View Images Data Image-to-Mesh Large Model 3DShapeToVecSet GPT Point Clouds-Based Data
3D Ver.2 VecSet-Based VAE and Diffusion 3DShape2VecSet Data Image(Text)-to-Mesh Large Model Trellis Sparse-VAE, Latent Diffusion Voxel-Based Data Image(Text)-to-Mesh Large Model
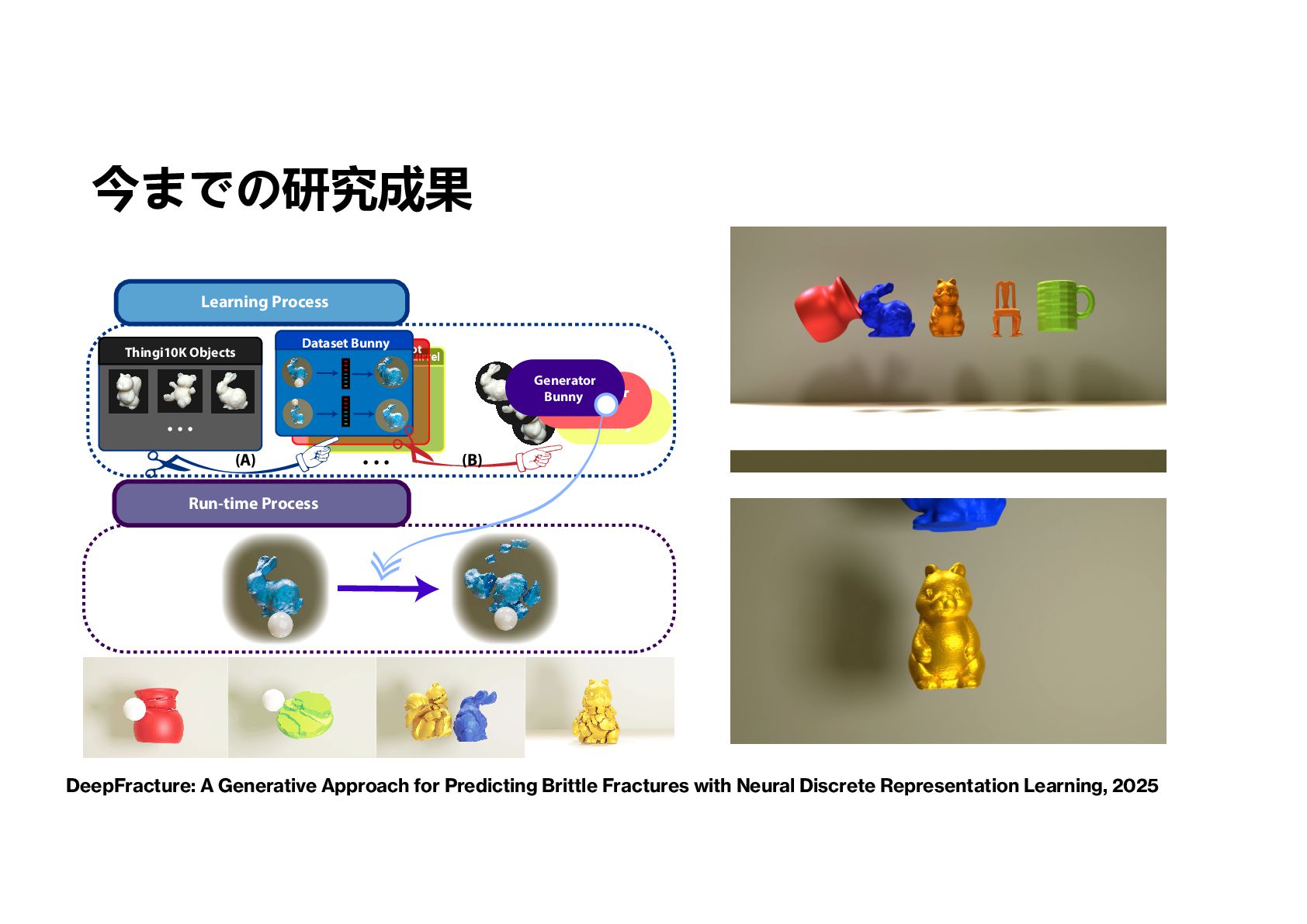
Trellis と Hunyuan よりいい目視一致性 • 3D Shape Single View Generation そろそろ解かれている • Large 3D Shape Model の大規模商業利用 • Fine-Tune で物理アニメーション • 上記だと,Image-based 表現ではなく,3DGS,NeRF などの表現も Large Model • VecSet Features より Voxel Fields は推せる. • Physical-Aware Video Generation vs 3D Animation Generation はしばらく併存 • Video-Based Generation の物理法則・編集可能 (CV) ーー 3DGSなど表現の開発 (CG)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}