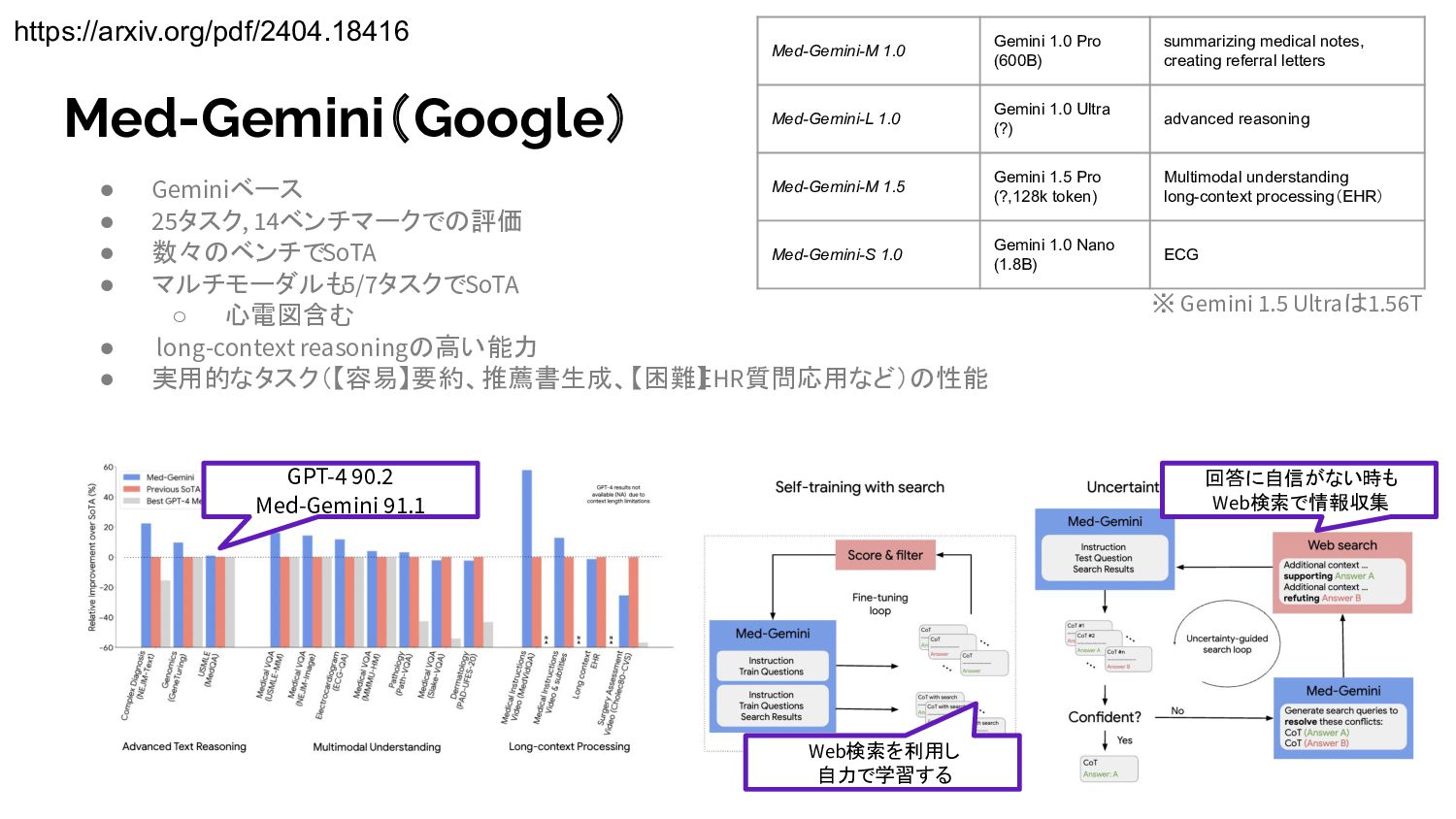
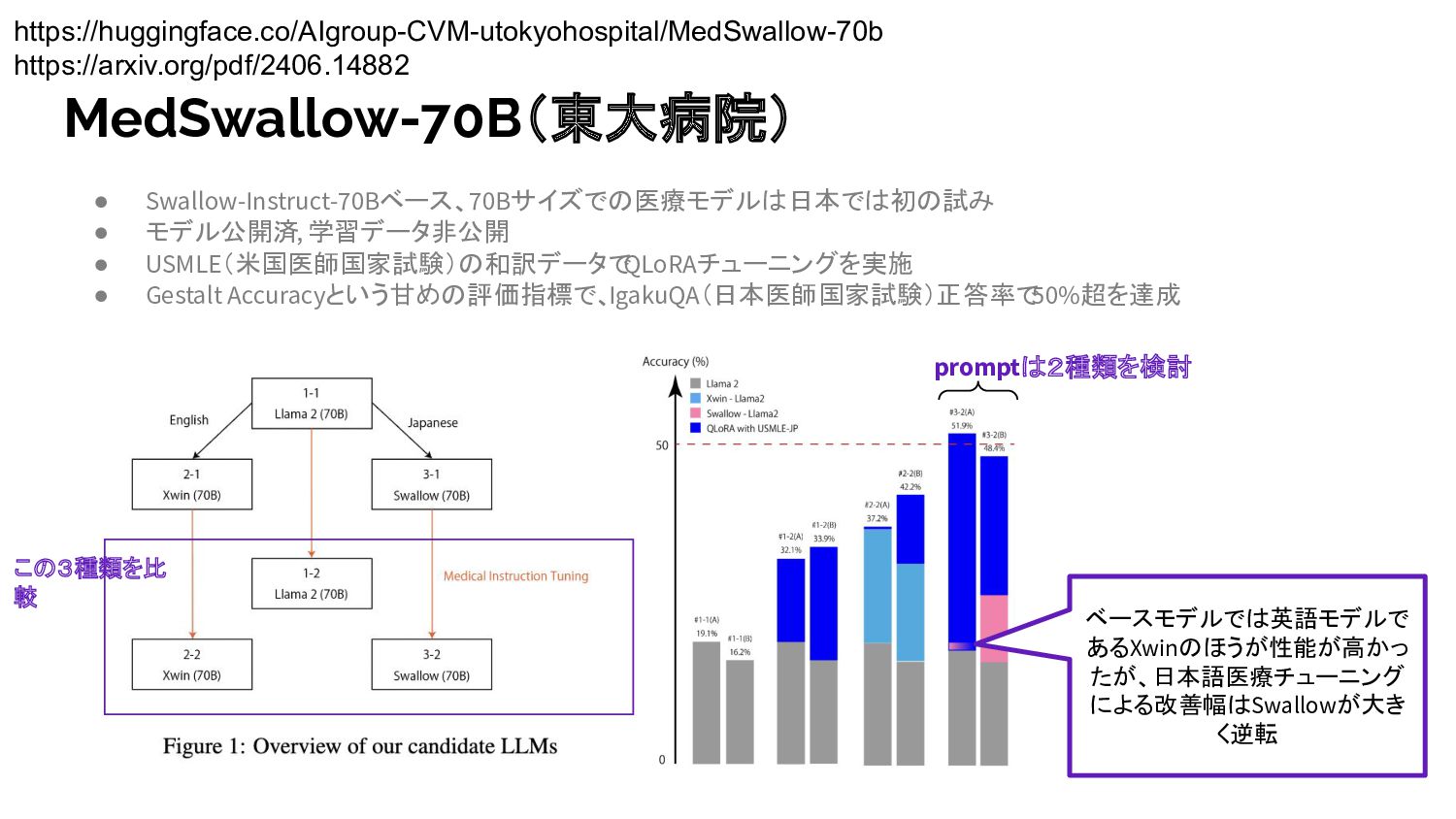
心電図含む • long-context reasoningの高い能力 • 実用的なタスク(【容易】要約、推薦書生成、【困難】 EHR質問応用など)の性能 Med-Gemini(Google) https://arxiv.org/pdf/2404.18416 GPT-4 90.2 Med-Gemini 91.1 Web検索を利用し 自力で学習する 回答に自信がない時も Web検索で情報収集 Med-Gemini-M 1.0 Gemini 1.0 Pro (600B) summarizing medical notes, creating referral letters Med-Gemini-L 1.0 Gemini 1.0 Ultra (?) advanced reasoning Med-Gemini-M 1.5 Gemini 1.5 Pro (?,128k token) Multimodal understanding long-context processing(EHR) Med-Gemini-S 1.0 Gemini 1.0 Nano (1.8B) ECG ※ Gemini 1.5 Ultraは1.56T
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}