ARE COMMON. OUR SYSTEMS AND COMPANIES SCALE RAPIDLY HOW DO YOU BUILD A RESILIENT SYSTEM WHILE YOU SCALE? WE USE CHAOS! WHY DO DISTRIBUTED SYSTEMS NEED CHAOS? 10
CAUSE OF A PROBLEM, BUT IT IS OFTEN A SERIOUS CONTRIBUTING FACTOR. AN EXAMPLE IS THE NORTHEAST BLACKOUT OF 2003. COMMON ISSUES INCLUDE: + HAVING THE WRONG TEAM DEBUG + NOT ESCALATING + NOT HAVING A BACKUP ON-CALL 18
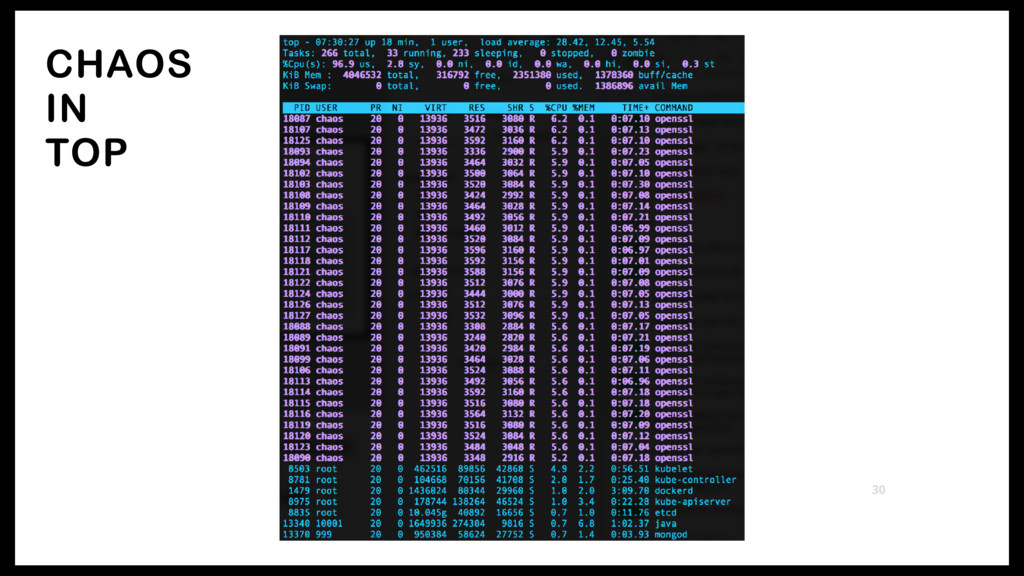
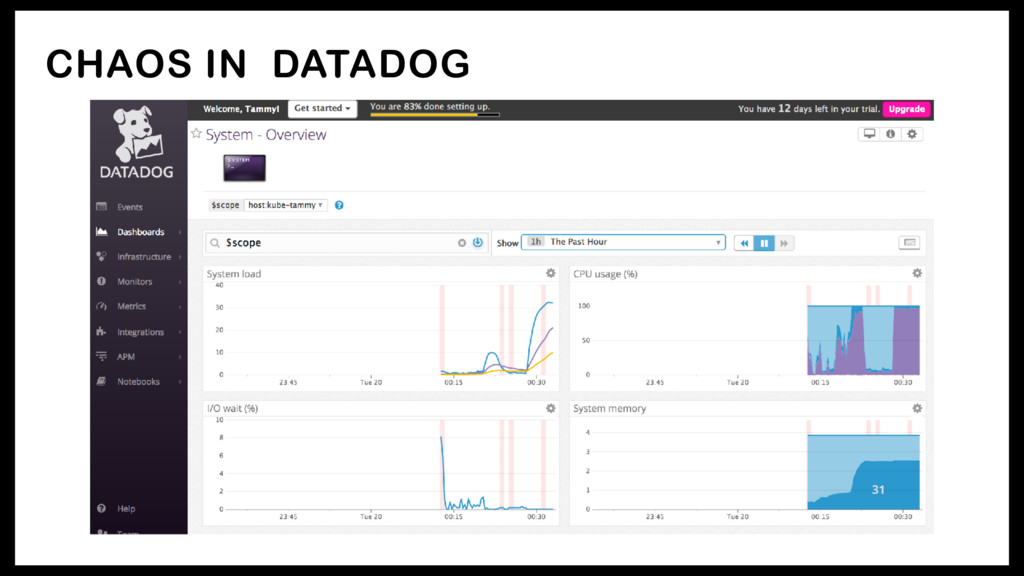
<< EOF > /tmp/infiniteburn.sh #!/bin/bash while true; do openssl speed; done EOF # 32 parallel 100% CPU tasks should hit even the biggest EC2 instances for i in {1..32} do nohup /bin/bash /tmp/infiniteburn.sh & done 28
I LEAD DATABASES AT DROPBOX & WE DO CHAOS. + FEAR WILL NOT HELP YOU SURVIVE “THE WORST OUTAGE”. + DO YOU TEST YOUR ALERTS & MONITORING? WE DO. + HOW VALUABLE IS A POSTMORTEM IF YOU DON’T HAVE ACTION ITEMS AND DO THEM? NOT VERY. QUICK THOUGHTS….. 48
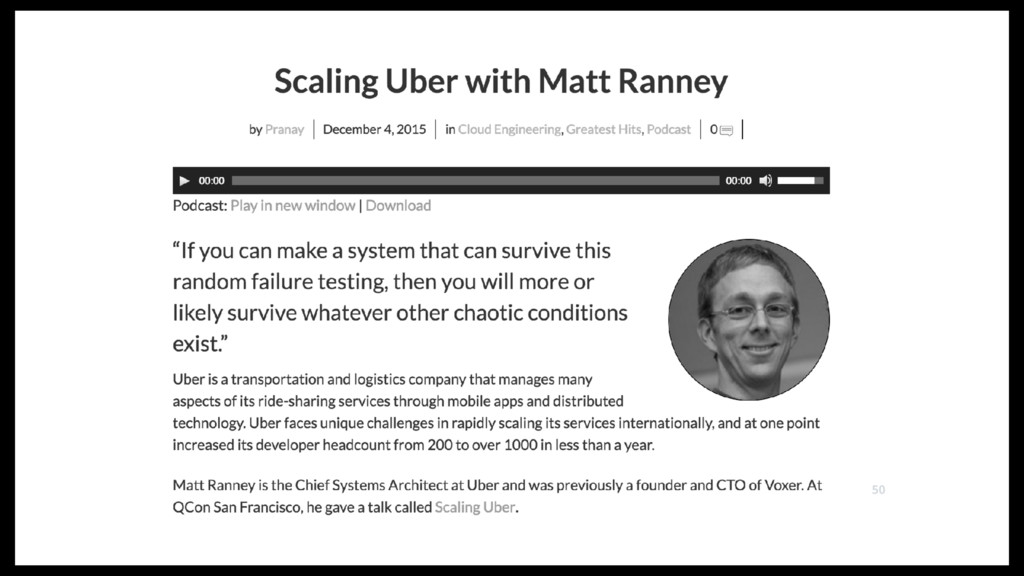
REPLICATION TO S3 FAILED 2. LOGS BACKED UP ON PRIMARY 3. ALERTS FIRE TO ENGINEER BUT THEY ARE IGNORED 4. DISK FILLS UP ON DATABASE PRIMARY 5. ENGINEER DELETES UNARCHIVED WAL FILES 6. ERROR IN CONFIG PREVENTS PROMOTION — Matt Ranney, UBER, YOW 2015 49
+ DIDN’T USE NETFLIX SIMIAN ARMY AS IT WAS AWS-CENTRIC. + ENGINEERS AT UBER DON’T LIKE FAILURE TESTING (ESP. DATABASES) ……THIS IS DUE TO THEIR WORST OUTAGE EVER: — Matt Ranney, UBER, YOW 2015 51
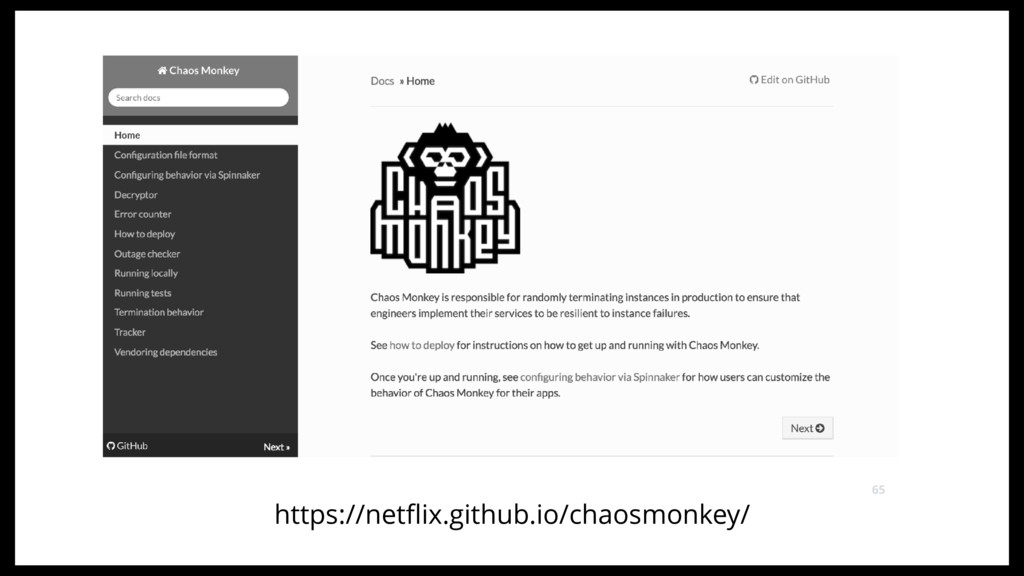
@ NETFLIX SIMIAN ARMY CONSISTS OF SERVICES (MONKEYS) IN THE CLOUD FOR GENERATING VARIOUS KINDS OF FAILURES, DETECTING ABNORMAL CONDITIONS, AND TESTING THE ABILITY TO SURVIVE THEM. THE GOAL IS THE KEEP THE CLOUD SAFE, SECURE AND HIGHLY AVAILABLE. 52
REMOVAL OF DATA FROM PRIMARY DATABASE 2.DATABASE OUTAGE DUE TO PROJECT_AUTHORIZATIONS HAVING TOO MUCH BLOAT 3.CI DISTRIBUTED HEAVY POLLING AND EXCESSIVE ROW LOCKING FOR SECONDS TAKES GITLAB.COM DOWN 4.SCARY DATABASE SPIKES https://about.gitlab.com/2017/02/10/postmortem-of-database-outage-of-january-31/ 53
NOT SOMETHING THAT HAPPENS AROUND A TABLE AS A SLEW OF EXCEPTIONAL ENGINEERS ARCHITECT THE PERFECT SYSTEM. PERFECTION COMES THROUGH REPEATEDLY TRYING TO BREAK THE SYSTEM” — VICTOR KLANG, TYPESAFE CHAOS @ TYPESAFE 57
DEGRADED AVAILABILITY FOR THE STRIPE API AND DASHBOARD. IN AGGREGATE, ABOUT TWO THIRDS OF ALL API OPERATIONS FAILED DURING THIS WINDOW.” CHAOS @ STRIPE https://support.stripe.com/questions/outage-postmortem-2015-10-08-utc 60
THAT CALLS CHAOS MONKEY ONCE A WEEKDAY TO CREATE A SCHEDULE OF TERMINATIONS. HAS BEEN AROUND FOR MANY YEARS! USED AT BANKS, E-COMMERCE STORES, TECH COMPANIES + MORE 63
IN TOP FORM. CHAOS MONKEY IS THE FIRST MEMBER. OTHER SIMIANS INCLUDE JANITOR MONKEY & CONFORMITY MONKEY. https://github.com/Netflix/SimianArmy SIMIAN ARMY 80
IN YOUR SYSTEM BEFORE THEY END UP IN THE NEWS. LIKE A VACCINATION, THEY SAFELY INJECT HARM INTO YOUR SYSTEM TO BUILD IMMUNITY TO FAILURE. GREMLIN INC 81 https://gremlininc.com/
INJECTION DURING GAME DAYS. GO CLIENT TO THE CHAOS MONKEY REST API 87 https://github.com/mlafeldt/chaosmonkey go get -u github.com/mlafeldt/chaosmonkey/lib
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}