Share
白金鉱業 Meetup Vol.24 で発表したLT資料です!
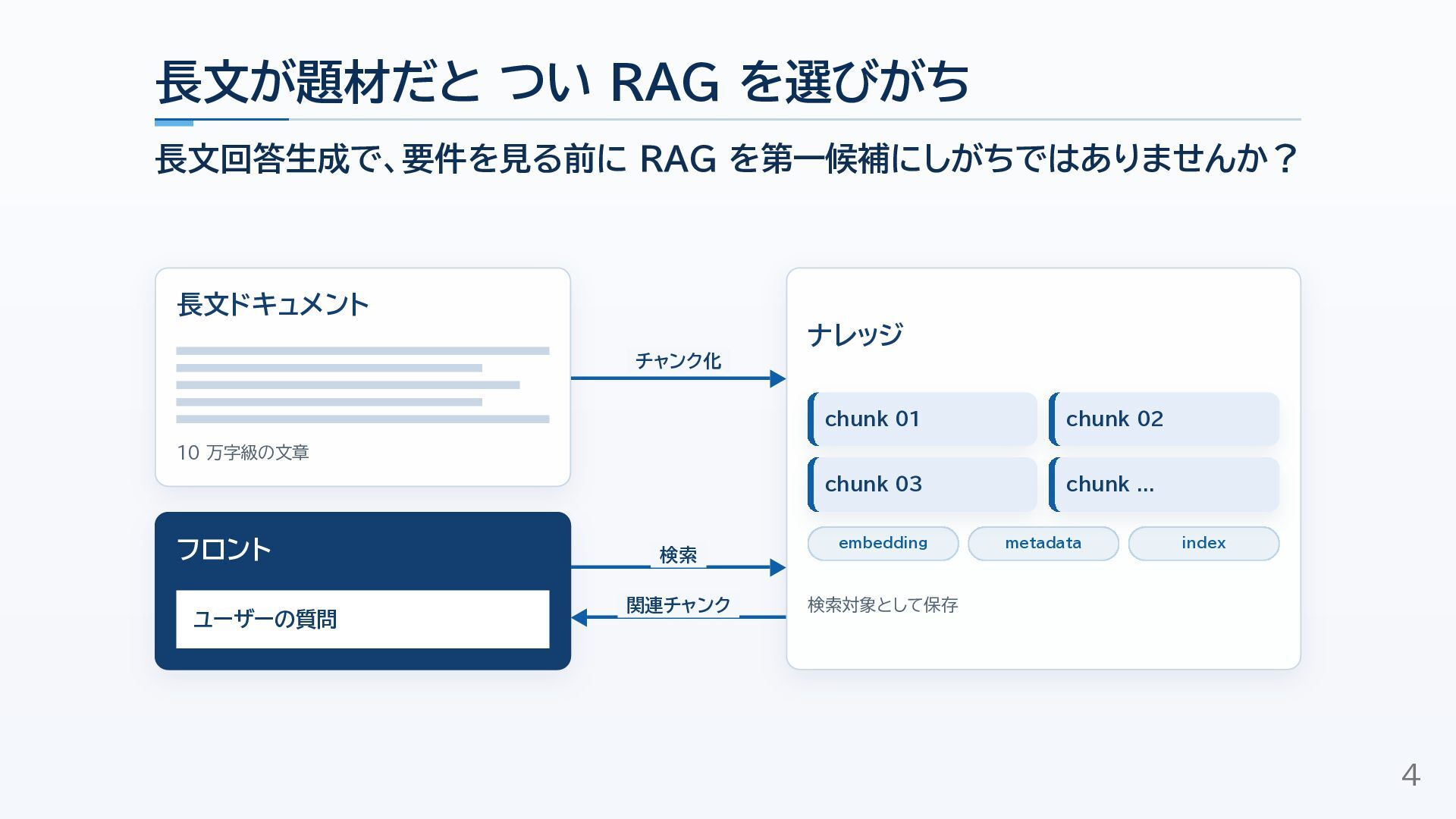
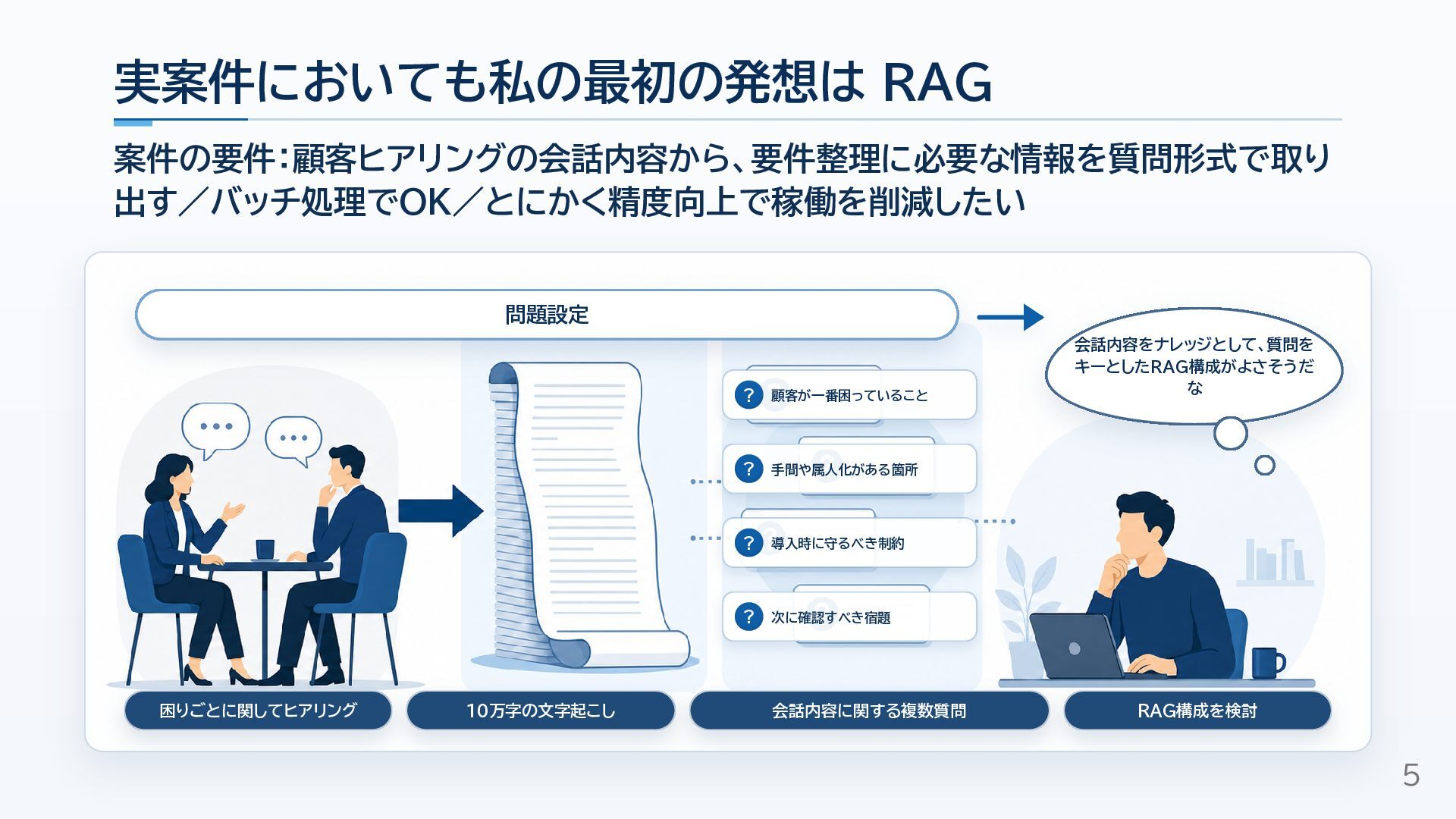
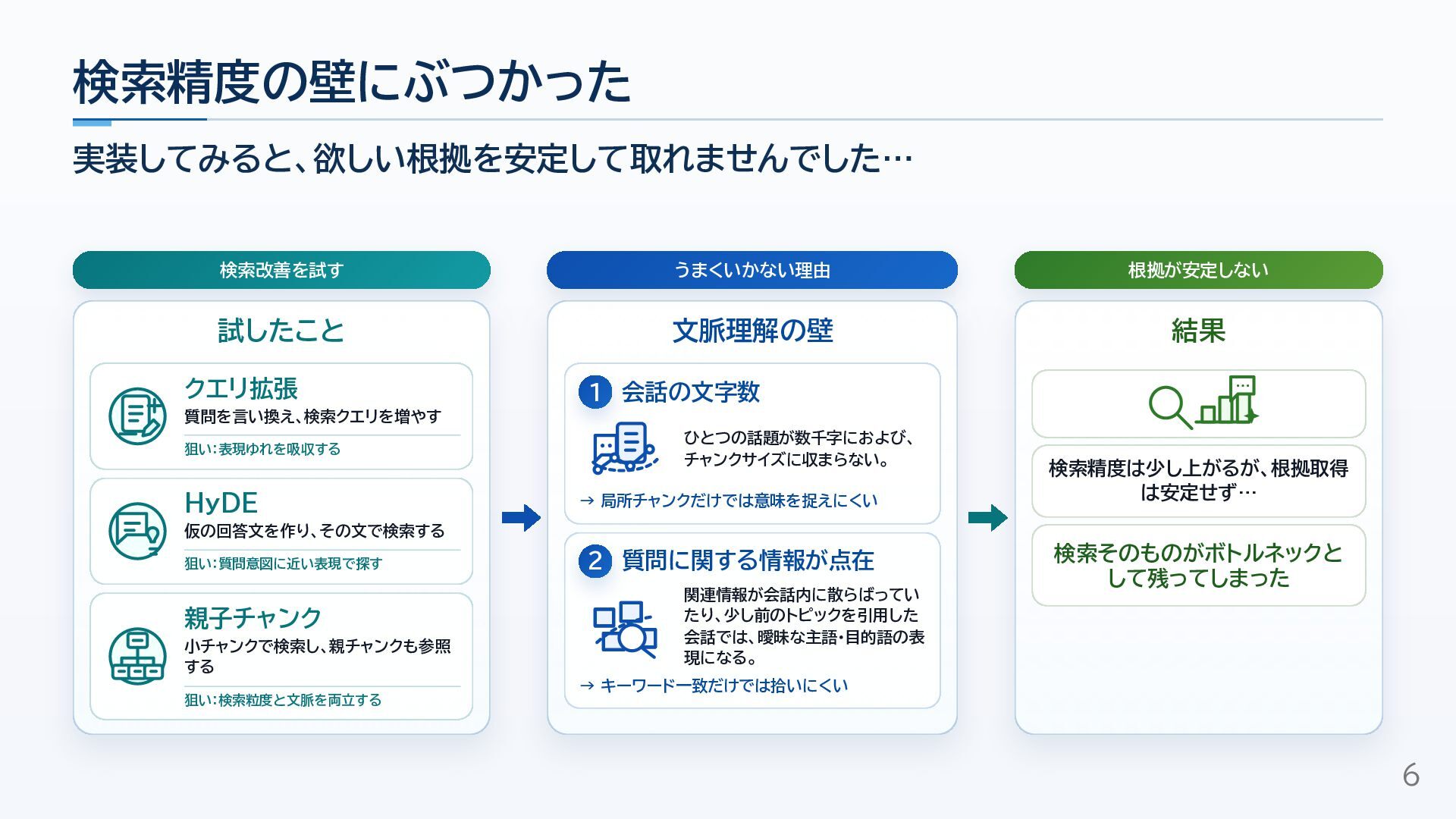
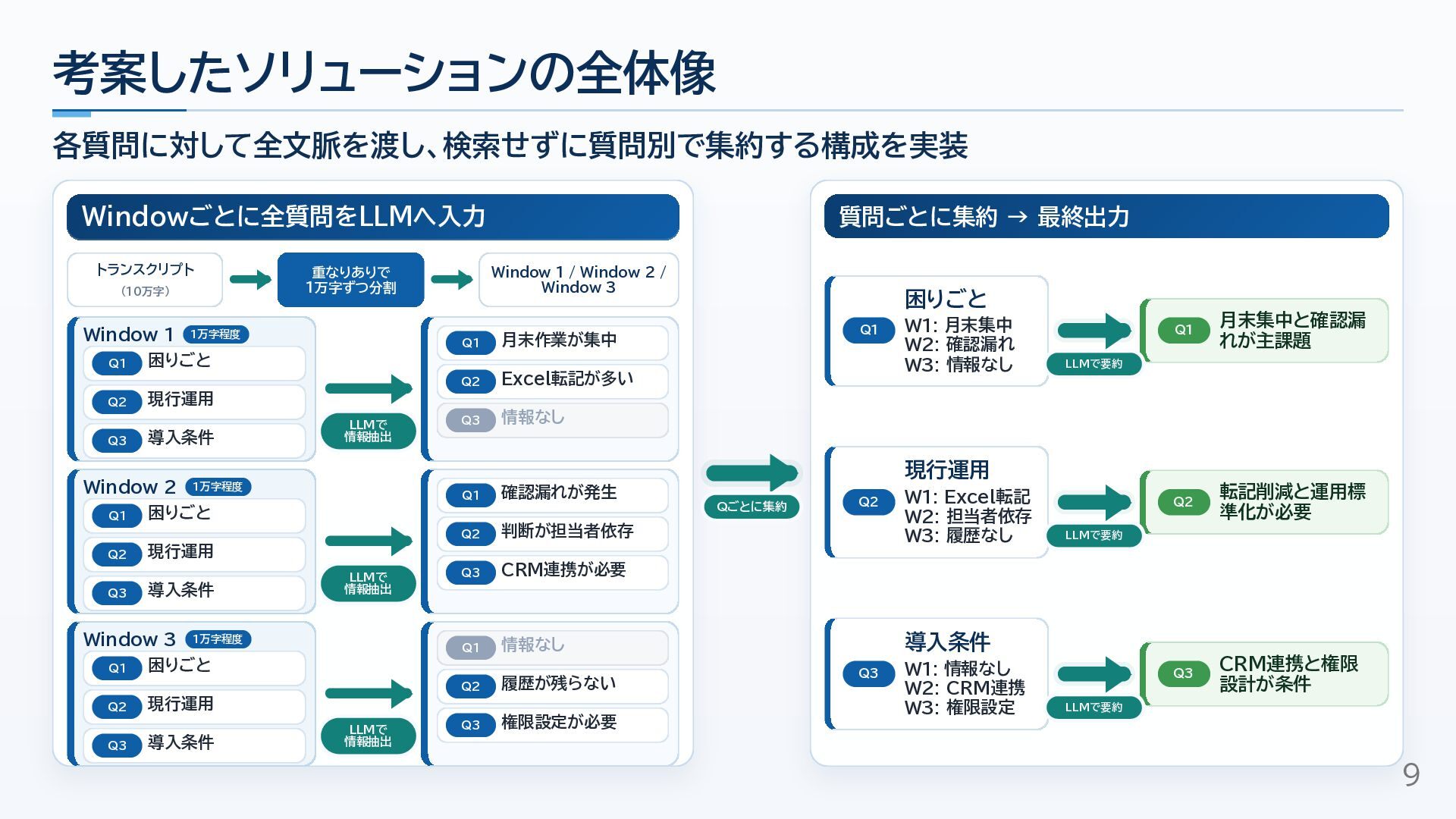
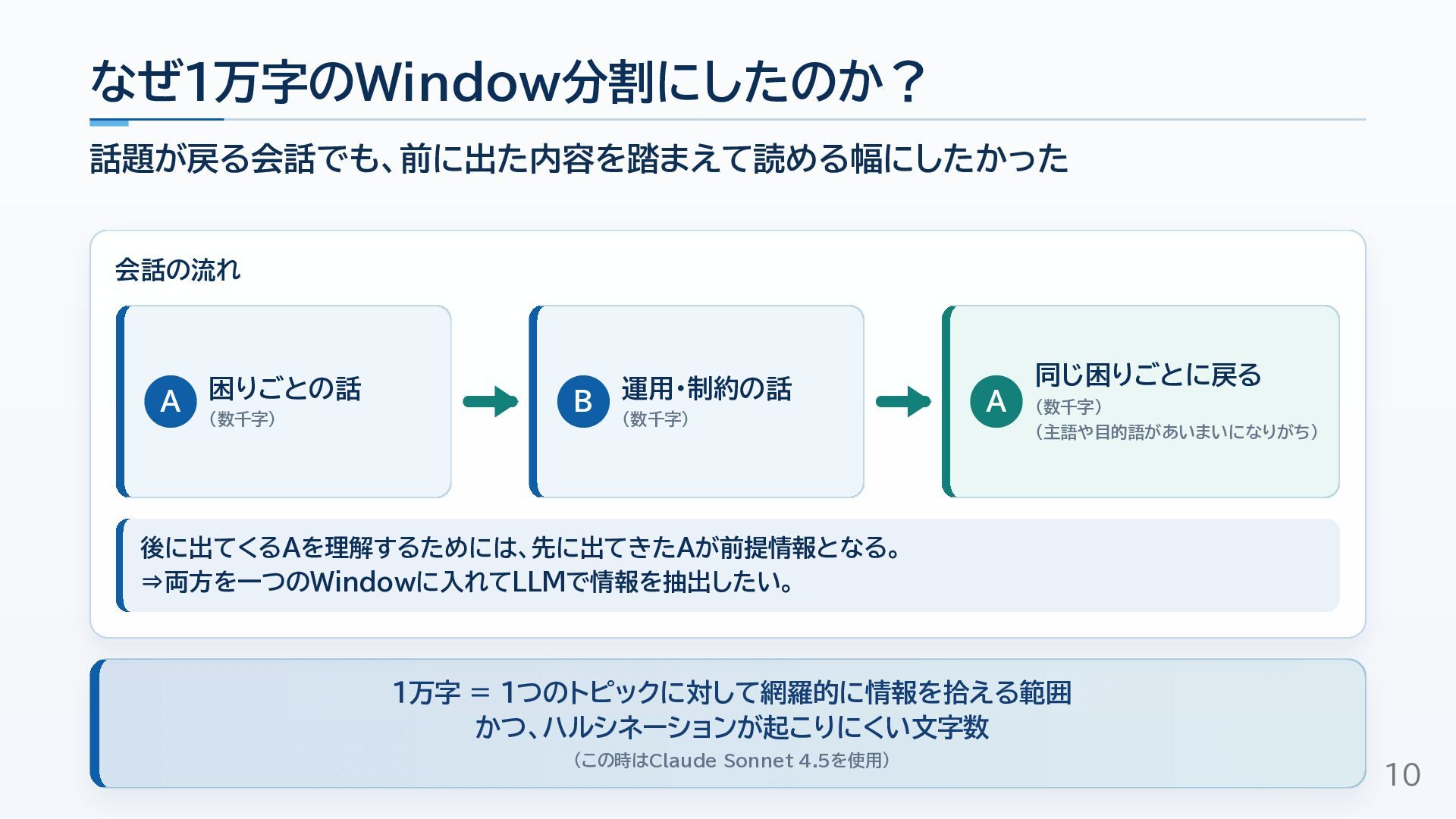
10万字級のインタビュー文字起こしをもとに回答生成する実案件で、最初はRAG構成を検討しつつも、検索精度・情報の点在・文脈幅の課題から、Window走査と質問別集約の構成へ切り替えた経験をまとめました。
RAGを否定する話ではなく、速度・コスト・検索の難しさ・必要な文脈幅を見ながら、長文回答生成の構成をどう選ぶかを考えるための資料です!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}