Einzelinstanz kann jederzeit vom Cluster verschoben werden • PVC für File-/Blobstorage • Konfiguration als Statefulset denkbar • skaliert nicht • zweifelhafte Verfügbarkeit • ZEO • Clients skalierbar (Deployment) • ZEO im Cluster denkbar • nicht HA (keine Replikation) Plone auf Kubernetes betreiben
PostgreSQL • Clients skalierbar (Deployment) • DB extern • Replikation • HA: PAF, Patroni • DB in Kubernetes • Replikation • HA: CloudNativePG https://cloudnative-pg.io • präferierte Lösung für aktuelles Plone • clientseitige Blobcaches als PVCs • schnellere Verfügbarkeit nach Restarts • bessere Kontrolle über Speicherbedarf der Clients (Blobs nicht im Hauptspeicher) • Restarts infolge Überschreitung von Resource Limits können vermieden werden Plone auf Kubernetes betreiben
Checks sind pro Pod, nicht pro Service • für Plone (zumindest Backend): • nicht durch Checks Last erzeugen • unnötige Restarts vermeiden Plone auf Kubernetes betreiben
(official, eigene) verwendbar • Konfiguration in Umgebungsvariablen und ConfigMaps • ZODB Backend: nur RelStorage auf PostgreSQL unterstützt • CronJob für DB-Wartung • DB optional im Cluster • optionales shared Blobcache auf PVC (Filesystem muss File Locks unterstützen wie z.B. CephFS) • Nginx als Reverse Proxy optional zusätzlich zu Ingress • Varnish optional Plone auf Kubernetes betreiben
Nginx) in einem eigenen Chart • verschiedene Konfigurationen durch Kombination der Subcharts • Plone Volto • Plone Classic • Konfiguration in Subcharts kann überschrieben werden Plone auf Kubernetes betreiben
![Plone auf Kubernetes betreiben Thomas Schorr [email protected] Plone Tagung Gießen](https://files.speakerdeck.com/presentations/0446f47a85d841e4b8e155d78088cbb3/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
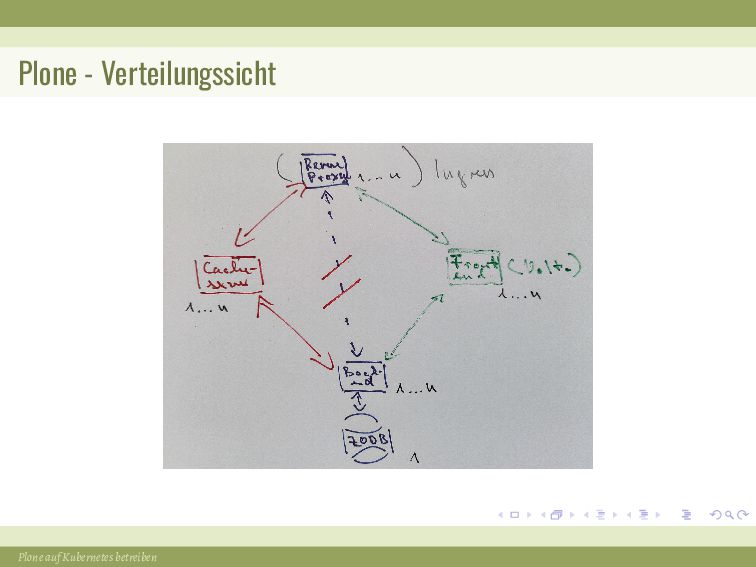{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
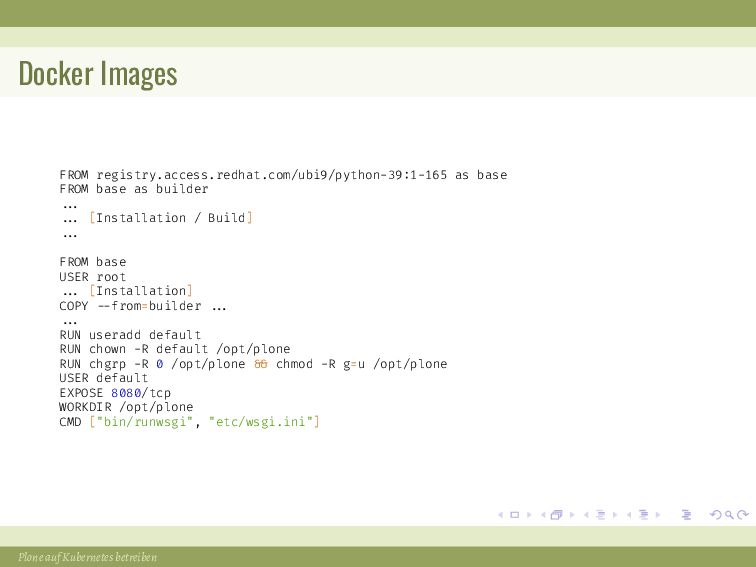{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Vielen Dank für Eure Aufmerksamkeit • Thomas Schorr • [email protected]](https://files.speakerdeck.com/presentations/0446f47a85d841e4b8e155d78088cbb3/slide_24.jpg){kind=link}