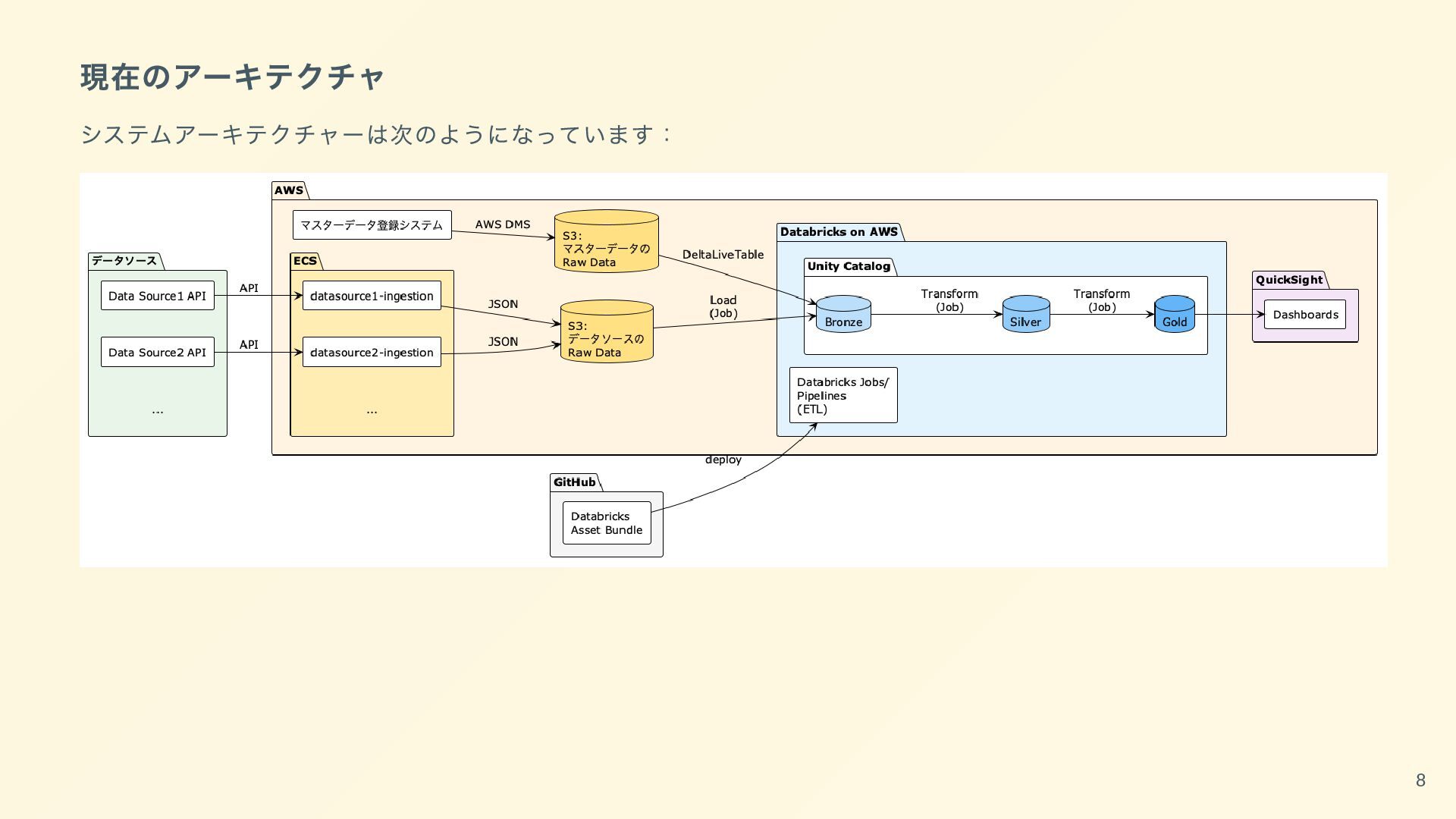
Catalog QuickSight Data Source1 API Data Source2 API ... Databricks Asset Bundle マスターデータ登録システム S3: データソースの Raw Data S3: マスターデータの Raw Data datasource1-ingestion datasource2-ingestion ... Databricks Jobs/ Pipelines (ETL) Bronze Silver Gold Dashboards API API JSON JSON AWS DMS Load (Job) DeltaLiveTable Transform (Job) Transform (Job) deploy 8
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
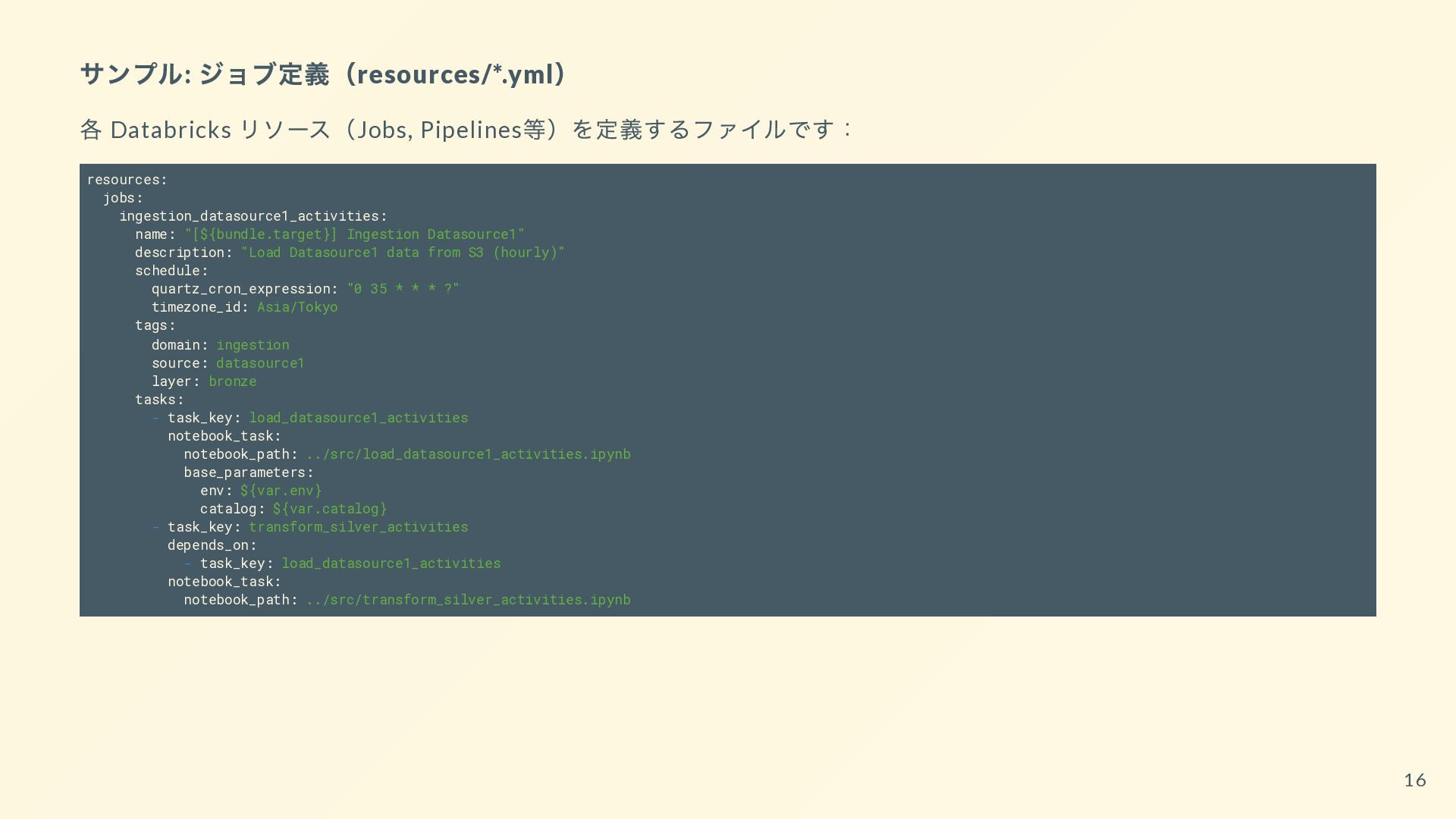{kind=link}
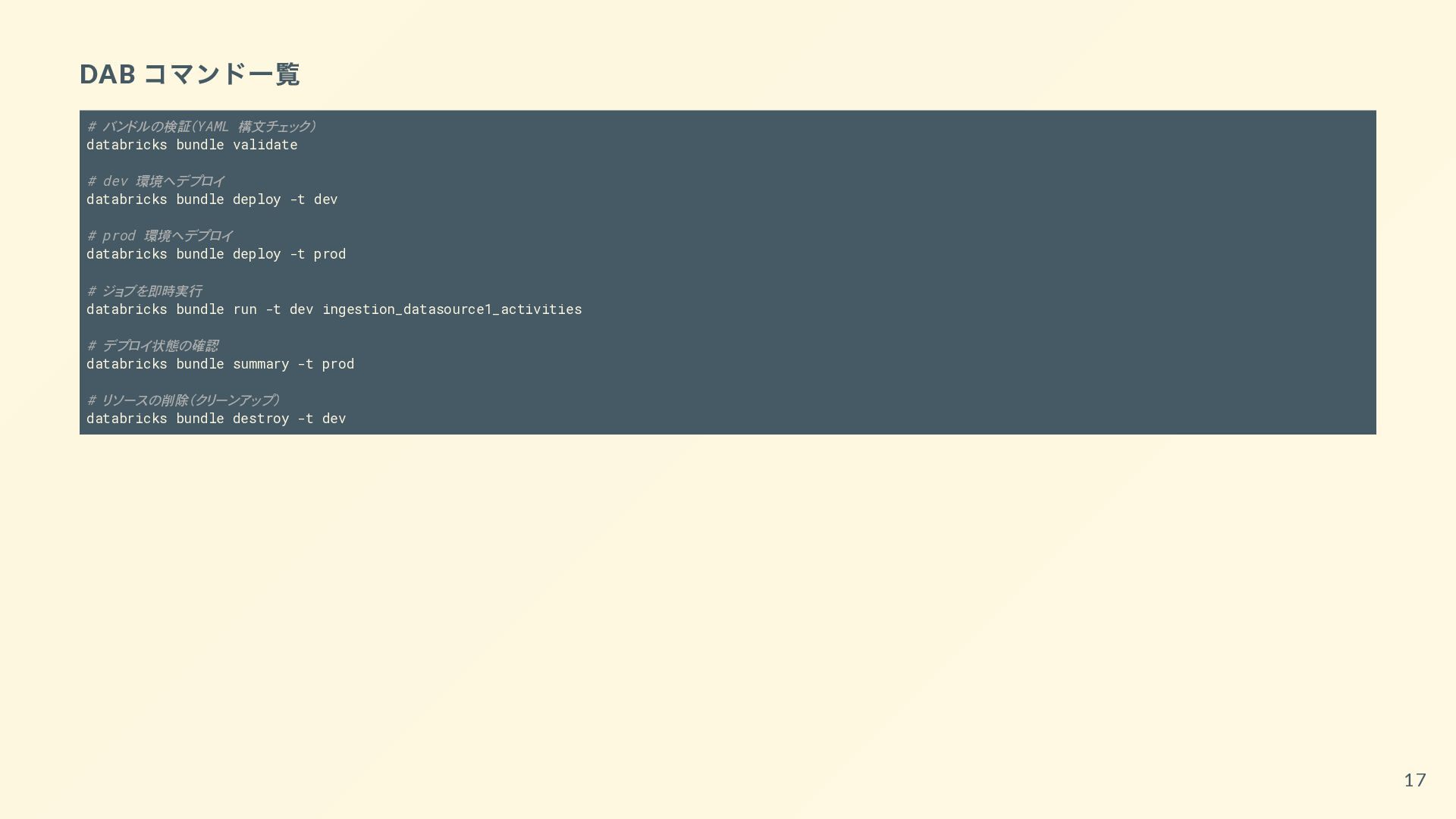{kind=link}
{kind=link}
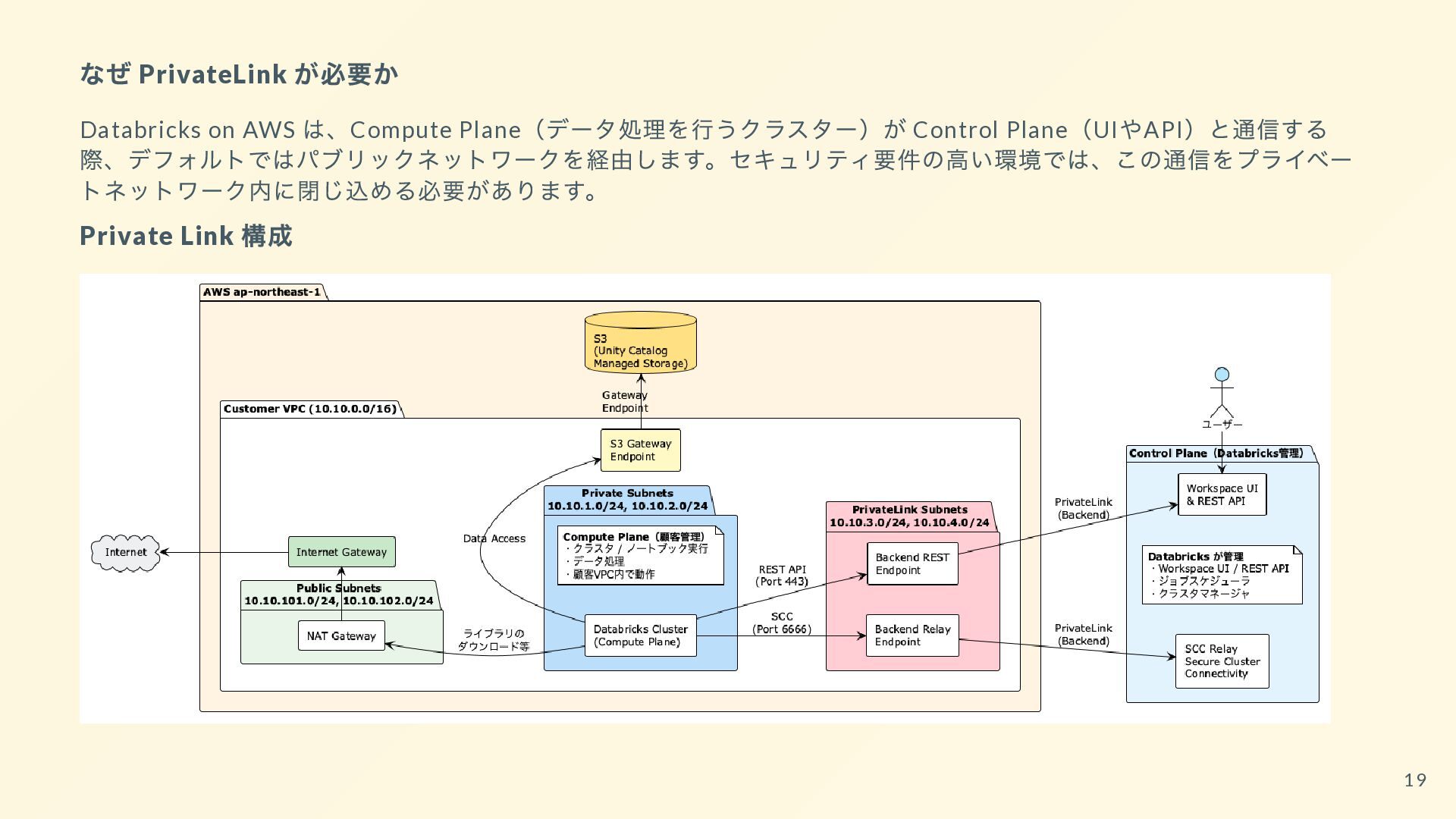{kind=link}
{kind=link}
{kind=link}
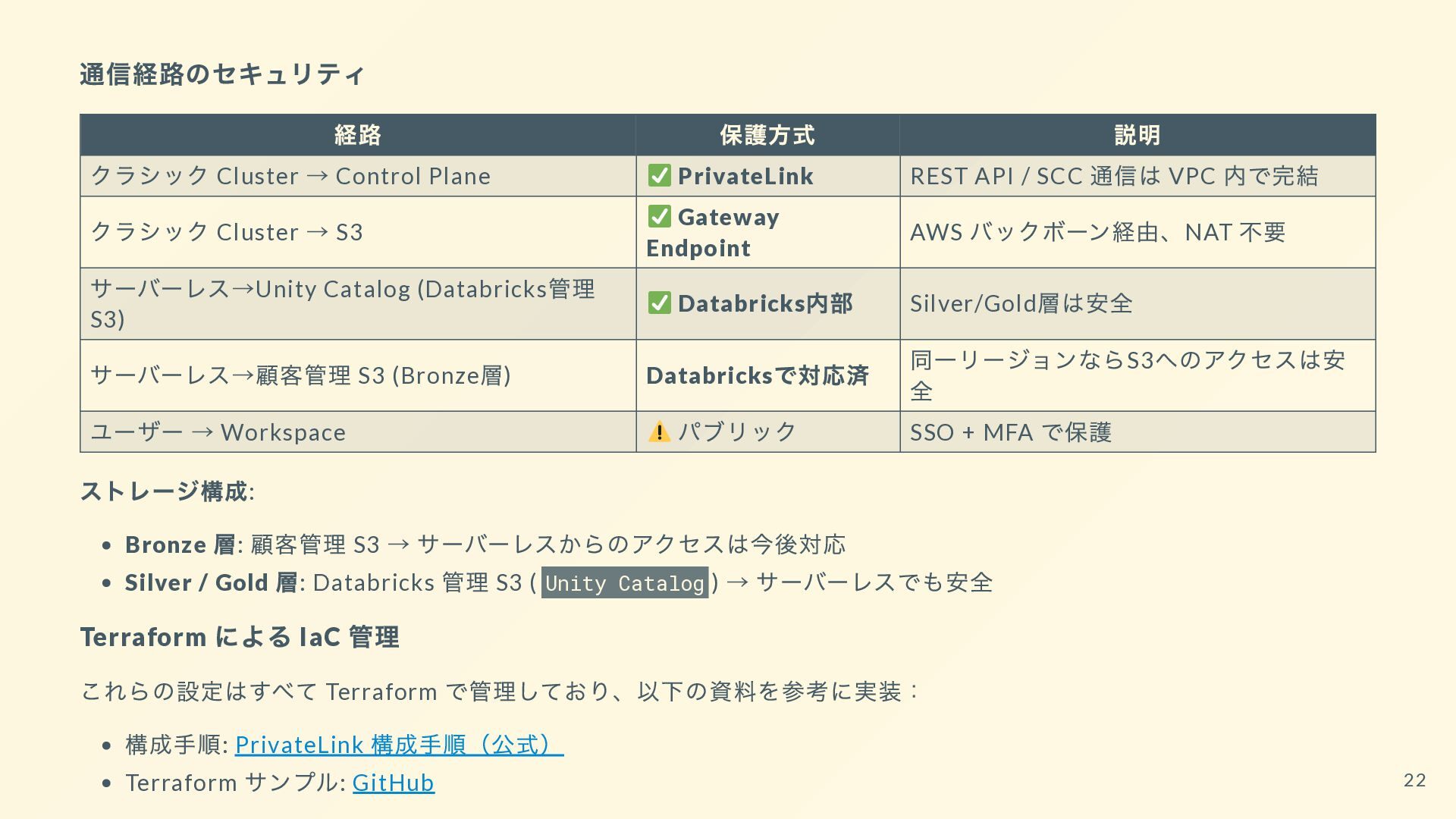{kind=link}
{kind=link}
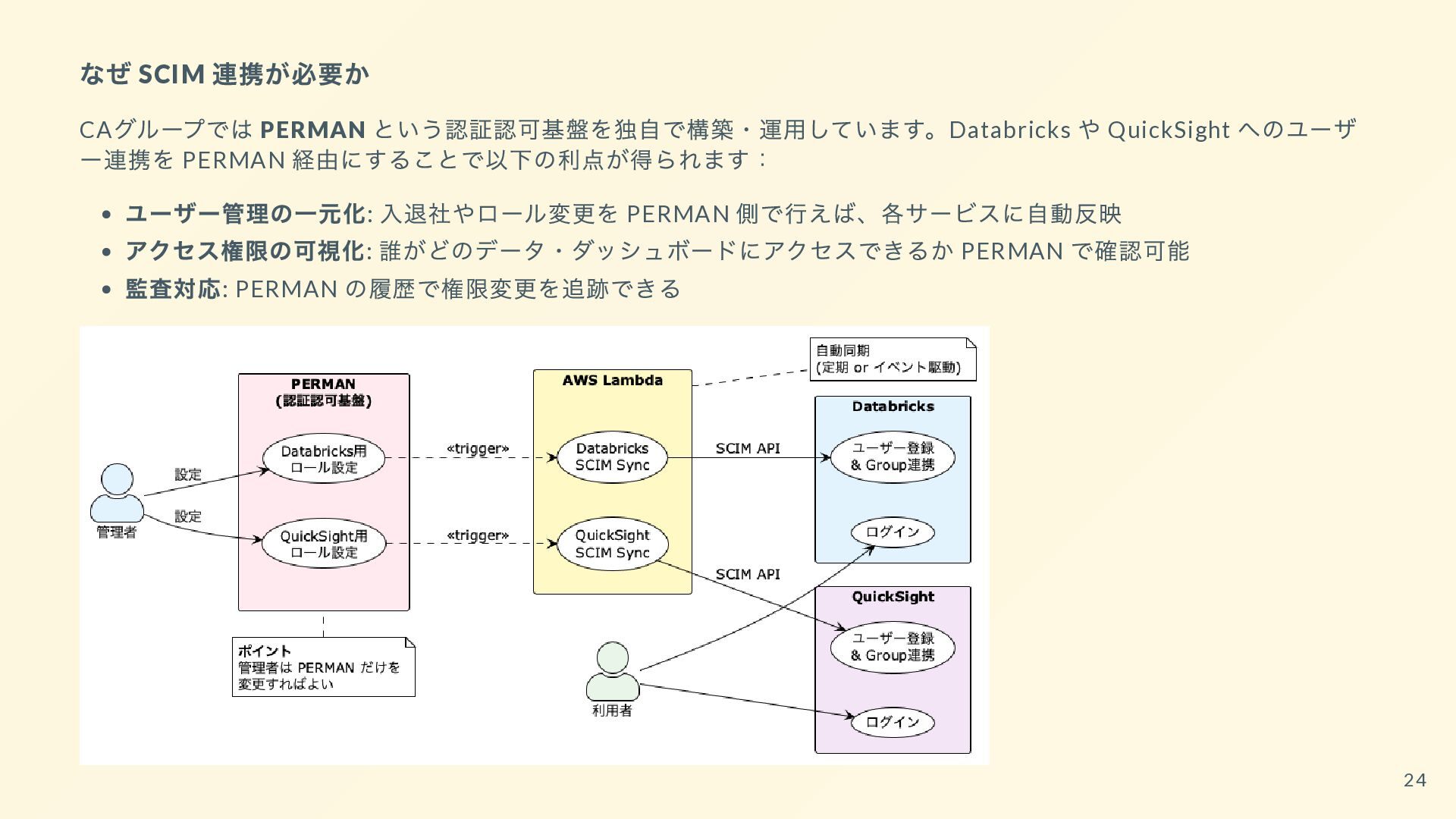{kind=link}
{kind=link}
{kind=link}
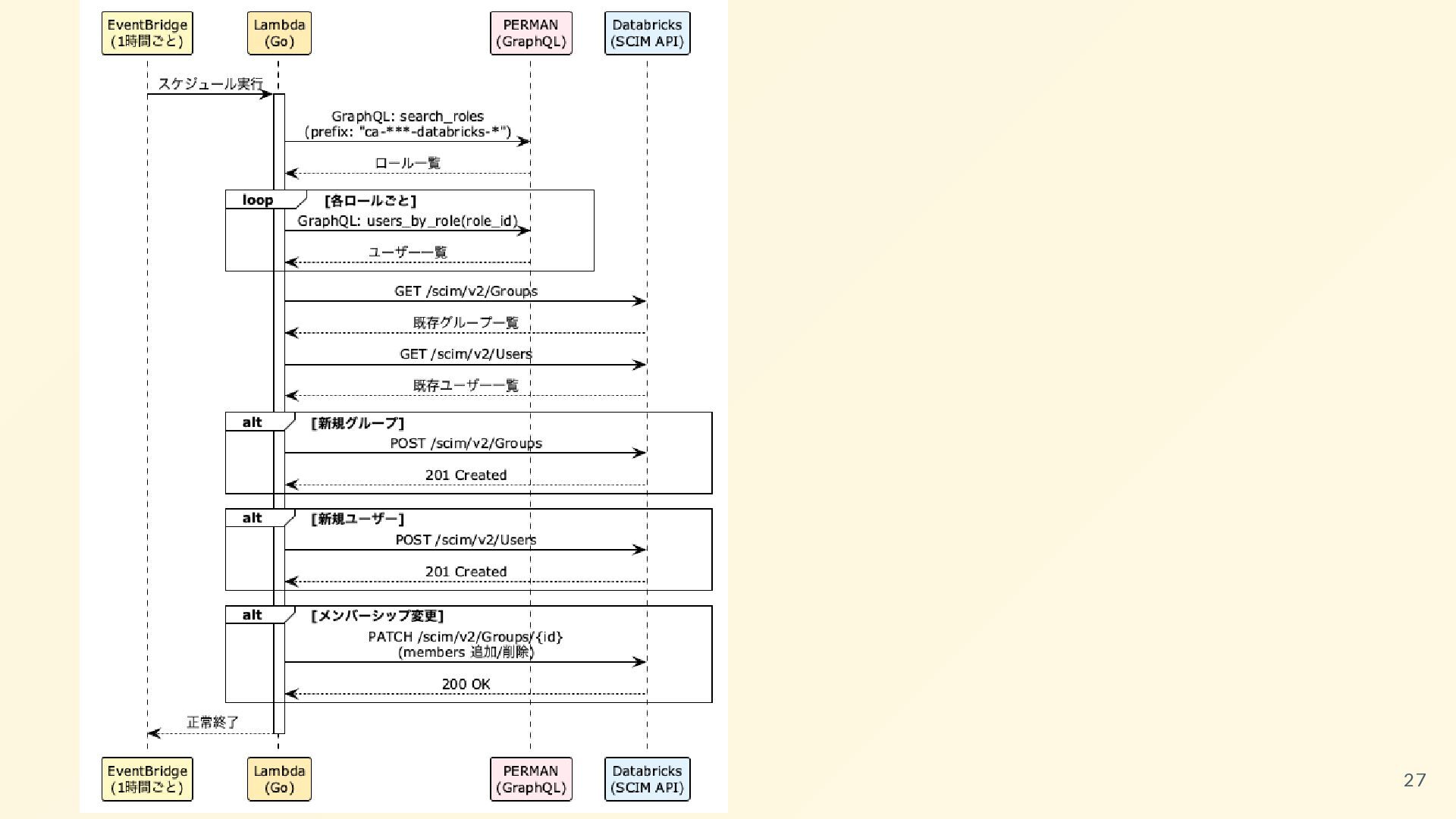{kind=link}
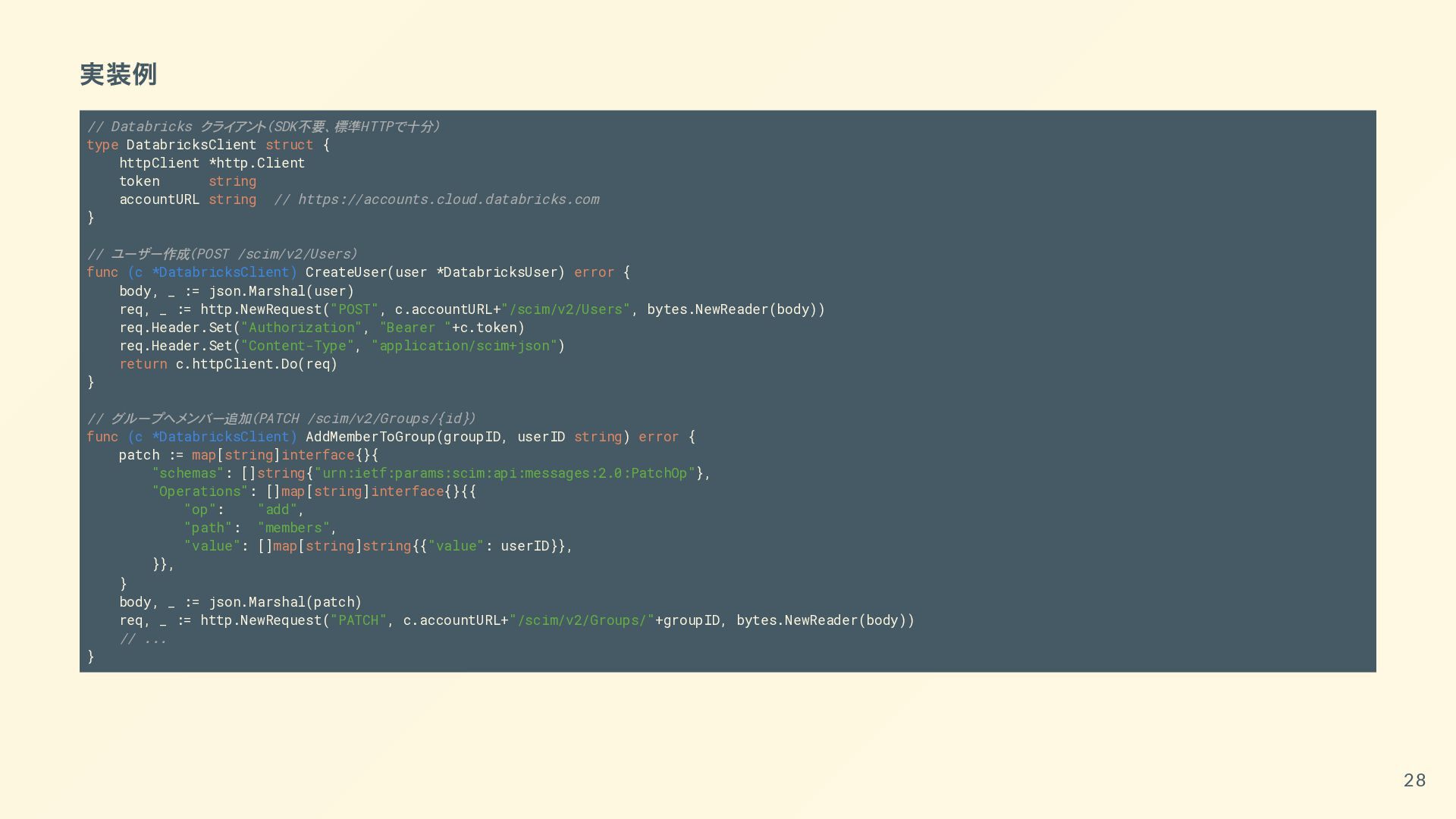{kind=link}
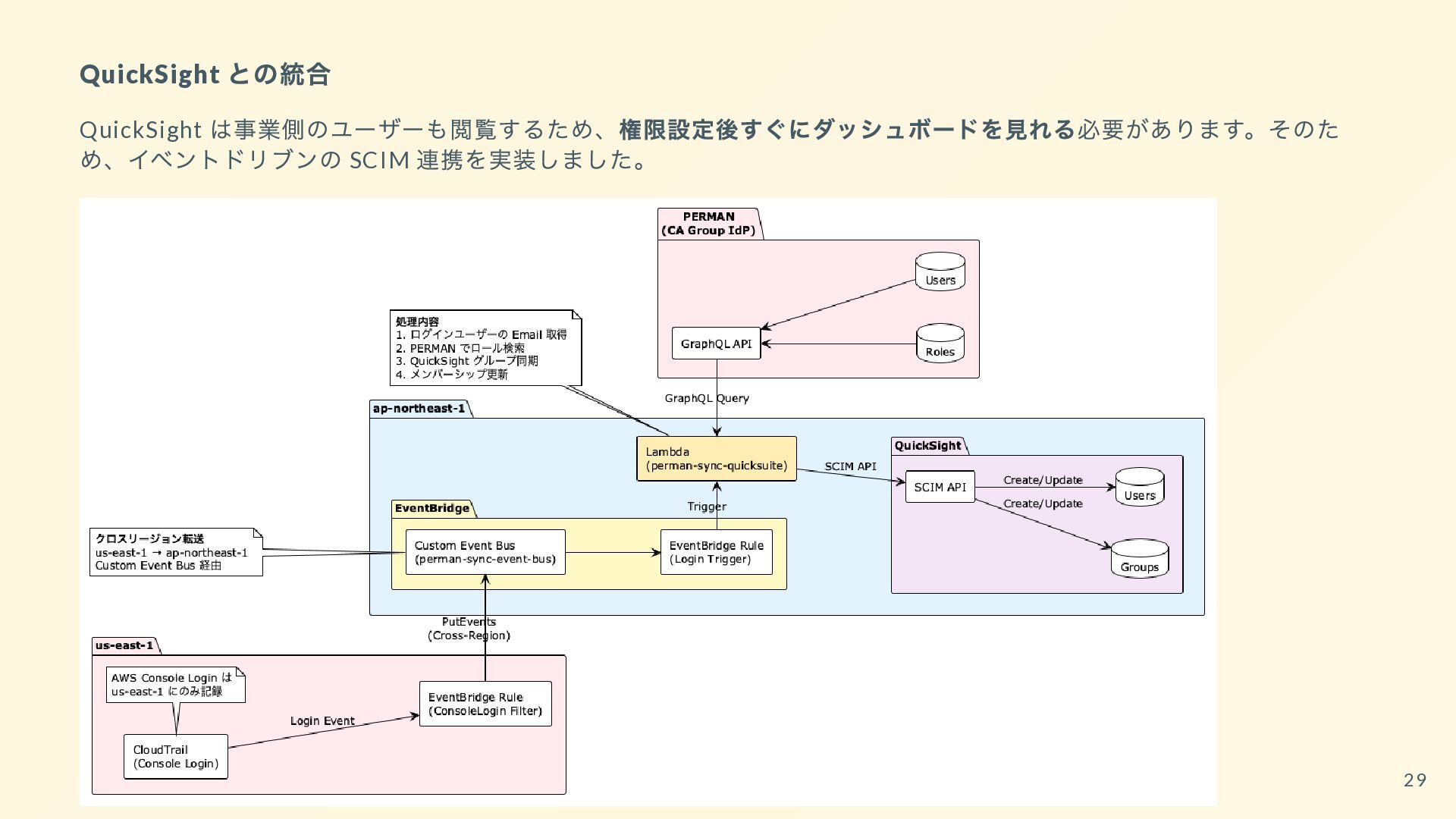{kind=link}
{kind=link}
{kind=link}
{kind=link}
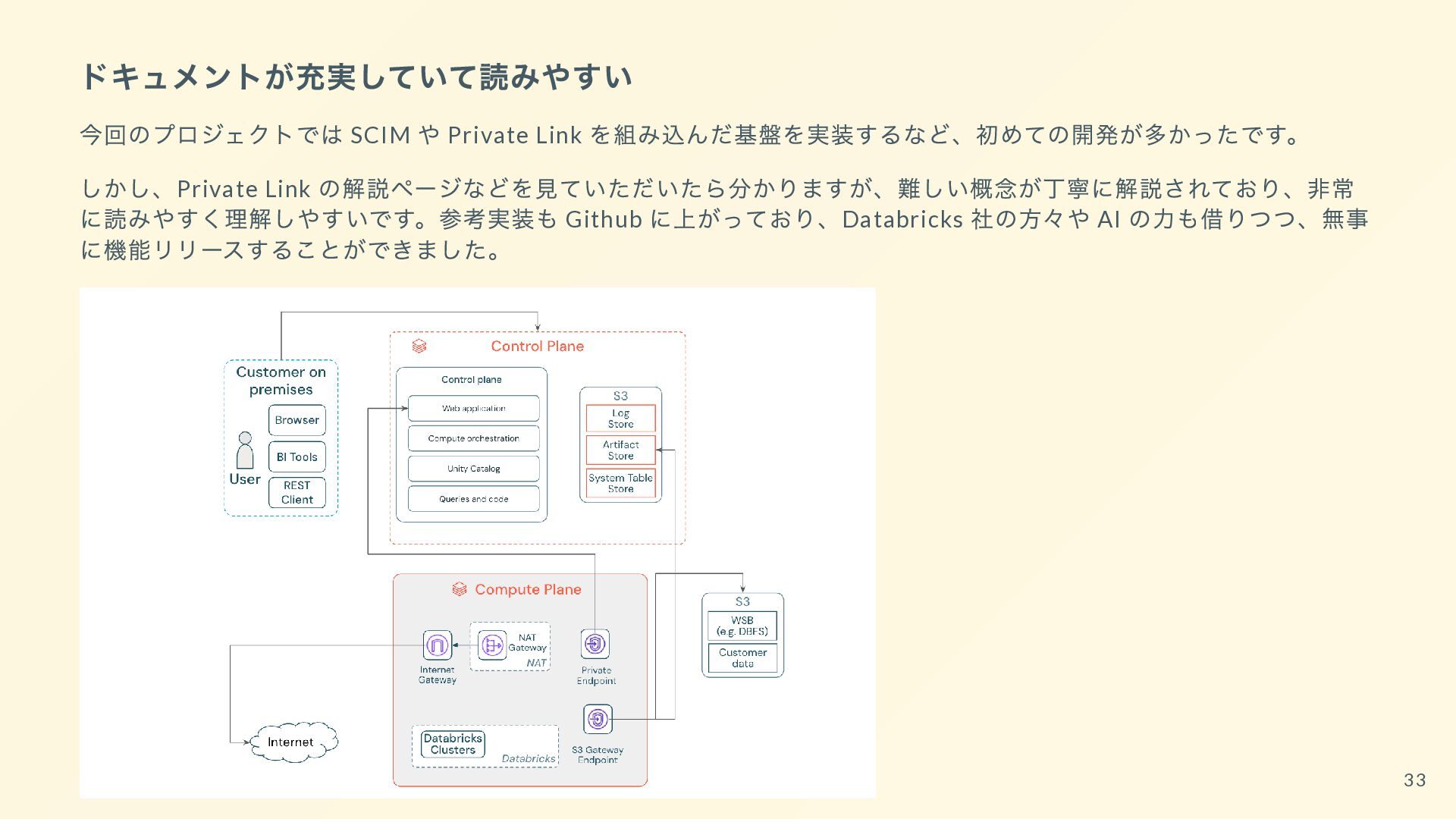{kind=link}
{kind=link}
{kind=link}