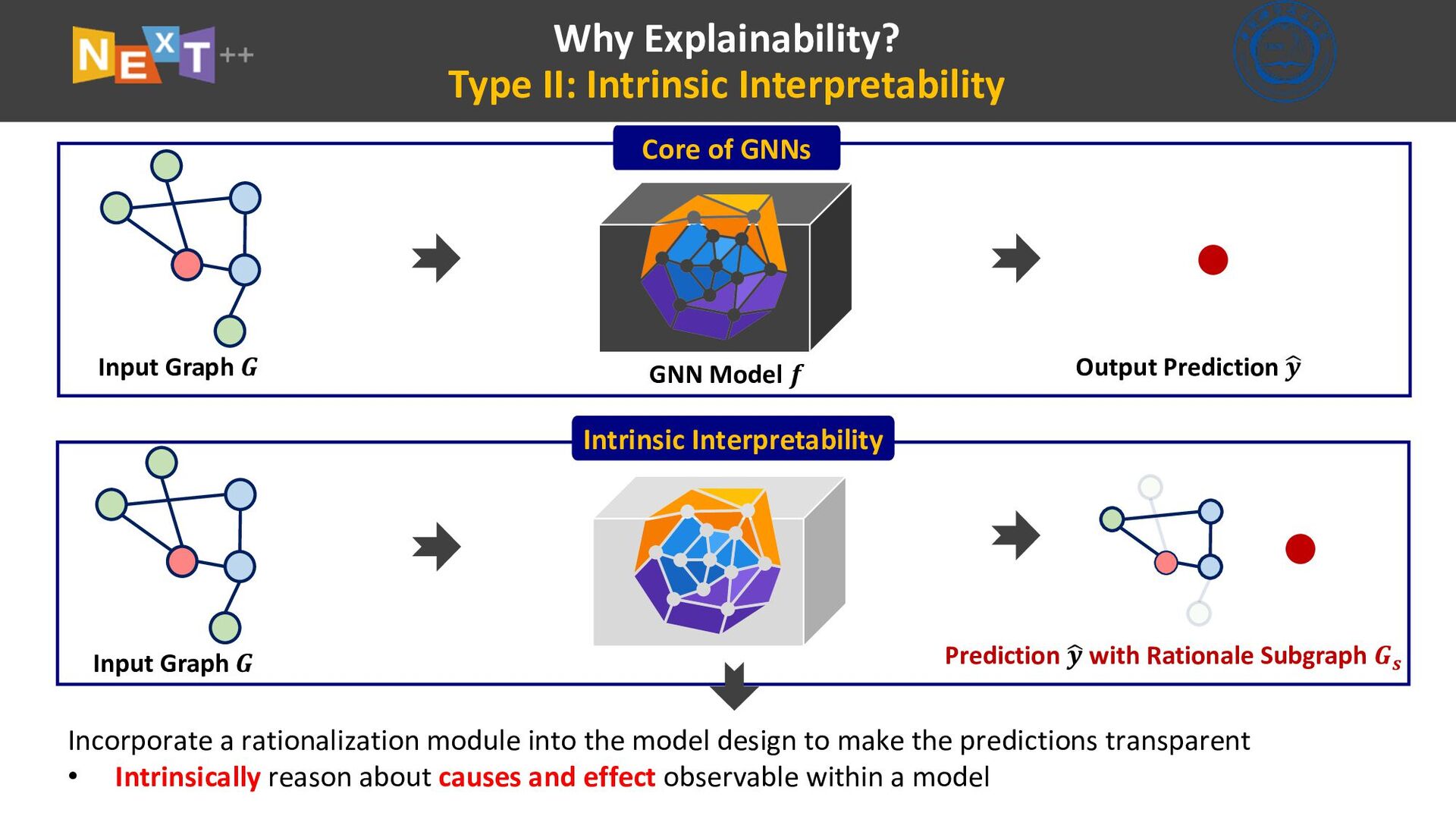
Graph Neural Networks (GNNs) are powerful models to exploit the high-order relationship between entities on graphs. Despite the superior performance, we have little knowledge about the explainability of GNNs. In this talk, we will introduce two themes of explainability, (1) Post-hoc explainability: Using an additional explainer method to explain a black-box model post hoc, but explanations could be unfaithful to the decision-making process of a model; (2) Intrinsic Interpretability: Incorporating a rationalization module into the model design, so as to transform a black-box to a white-box. We find causal theory is one promising solution and we will discuss interpretability and generalization.
Speaker's bio: Dr. Wang Xiang is a Professor in University of Science and Technology of China, where he is a member of Lab of Data Science. With his colleagues, students, and collaborators, he strives to develop trustworthy deep learning and artificial intelligence algorithms with better interpretability, generalization, and robustness. His research is motivated by, and contributes to, graph-structured applications in information retrieval (e.g., personalized recommendation), data mining (e.g., graph pre-training), security (e.g., fraud detection in fintech, information security in system), and multimedia (e.g., video question answering). His work has over 50 publications in top-tier conferences and journals. Over 10 papers have been featured in the most cited and influential list (e.g., KDD 2019, SIGIR 2019, SIGIR 2020, SIGIR 2021) and best paper finalist (e.g., WWW 2021, CVPR 2022). Moreover, He has served as the PC member for top-tier conferences including NeurIPS, ICLR, SIGIR and KDD, and the invited reviewer for prestigious journals including JMLR, TKDE, and TOIS.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}