policy gradientを採用 a i = μ i (s) : actor μ を導入する ここで、bidding actionがナッシュ均衡となる場合を考える。 上記の制約のもとで最適なμ (actor) を求める。 これを、alternative gradient descentアプローチで解いた。 14
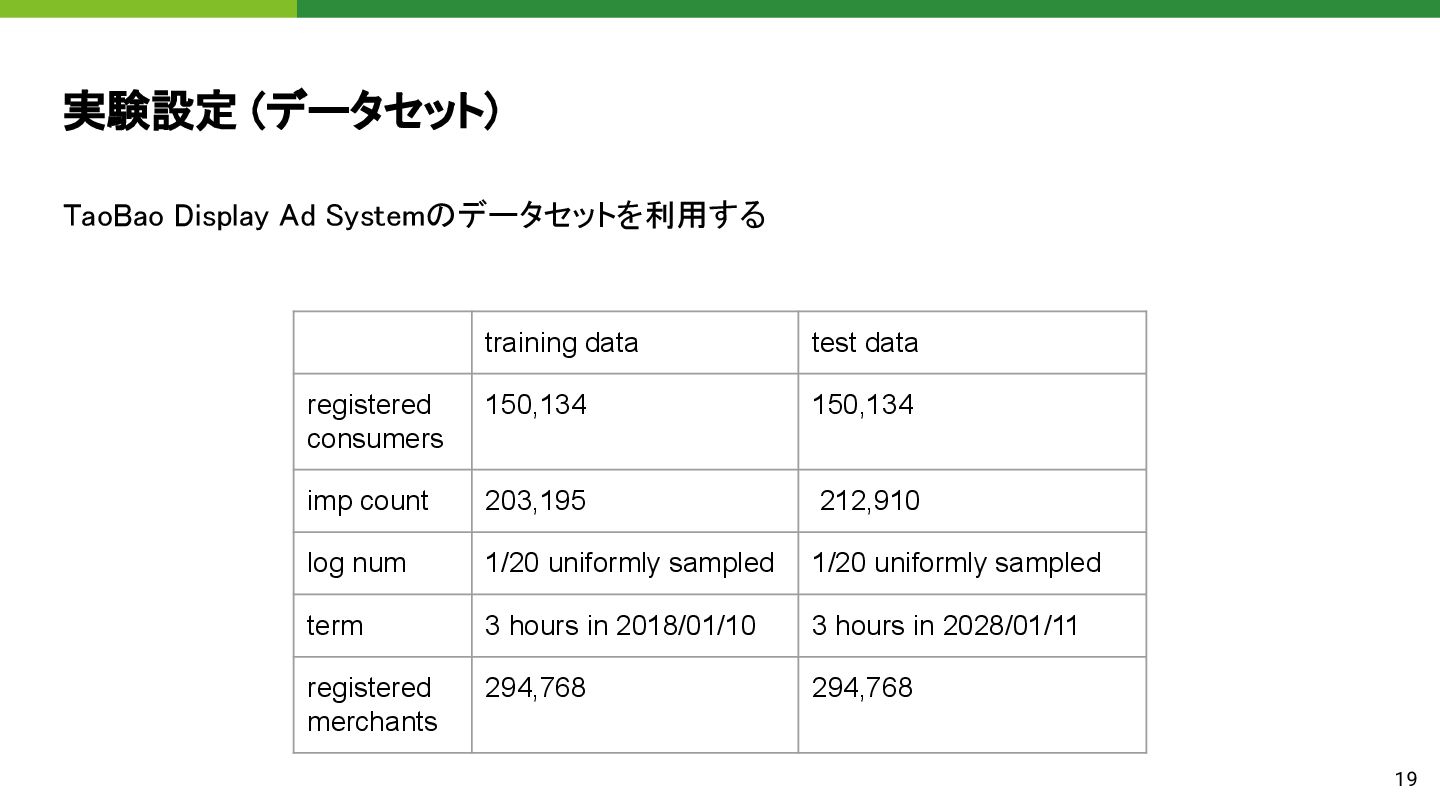
19 training data test data registered consumers 150,134 150,134 imp count 203,195 212,910 log num 1/20 uniformly sampled 1/20 uniformly sampled term 3 hours in 2018/01/10 3 hours in 2028/01/11 registered merchants 294,768 294,768
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}