Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Ad-DS Paper Circle #8
Search
Yusuke Kaneko
March 30, 2025
3.3k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Ad-DS Paper Circle #8
広告輪読会第八回スライド
Yusuke Kaneko
March 30, 2025
More Decks by Yusuke Kaneko
See All by Yusuke Kaneko
Ad-DS Paper Circle #1
ykaneko1992
0
7.3k
Ad-DS Paper Circle #2
ykaneko1992
0
4.5k
Ad-DS Paper Circle #3
ykaneko1992
0
4.2k
Ad-DS Paper Circle #4
ykaneko1992
0
4.1k
Ad-DS Paper Circle #5
ykaneko1992
0
3.8k
Ad-DS Paper Circle #6
ykaneko1992
0
3.5k
Ad-DS Paper Circle #7
ykaneko1992
0
3.4k
Ad-DS Paper Circle #9
ykaneko1992
0
3.2k
Ad-DS Paper Circle Intro
ykaneko1992
0
7.6k
Featured
See All Featured
SEO for Brand Visibility & Recognition
aleyda
0
4.6k
From Legacy to Launchpad: Building Startup-Ready Communities
dugsong
0
260
How Fast Is Fast Enough? [PerfNow 2025]
tammyeverts
3
660
Being A Developer After 40
akosma
91
590k
Save Time (by Creating Custom Rails Generators)
garrettdimon
PRO
32
3.8k
Product Roadmaps are Hard
iamctodd
55
12k
JAMstack: Web Apps at Ludicrous Speed - All Things Open 2022
reverentgeek
1
500
Jamie Indigo - Trashchat’s Guide to Black Boxes: Technical SEO Tactics for LLMs
techseoconnect
PRO
0
370
From π to Pie charts
rasagy
0
240
Evolving SEO for Evolving Search Engines
ryanjones
0
240
Conquering PDFs: document understanding beyond plain text
inesmontani
PRO
4
2.9k
Building Experiences: Design Systems, User Experience, and Full Site Editing
marktimemedia
0
550
Transcript
A/B Testing Intuition Busters Common Misunderstandings in Online Controlled Experiments
AI事業本部 協業リテールメディアディビジョン プリズムパートナーカンパニー 桂川 大輝 1
桂川 大輝 •所属 AI事業本部 協業リテールメディアディビジョン プリズムパートナーカンパニー •職種 機械学習エンジニア •入社 2023年7月中途入社
•業務 DSPの開発 2
1.概要 2.導入 3.動機 4.意外な結果には強力な証拠が必要 5.検出力の低い実験は信頼性が低い 6.事後検出力の計算は不安定 7.実験環境での自由度を最小限に 8.不均等なバリアントに注意 9.まとめ 3
概要 • 今回の論文:「A/B Testing Intuition Busters: Common Misunderstandings in Online
Controlled Experiments(Kohavi et al., 2022)」 • 「A/Bテスト実践ガイド 真のデータドリブンへ至る信用で る実験とは」の著者 4
概要 •A/Bテストは企業の意思決定に広 活用 れている 、多 の誤解 存在 特に「直感的に正し 思える 実は誤った統計解釈(直感的誤解)」
問題 •統計の誤用は長年批判 れて た 依然として蔓延 誤解により、誤った結論 導 れ、実験の信頼性 損なわれる •A/Bテストに る代表的な誤解を整理 直感的誤解の背景を説明し、それらを打破する方法を解説 誤解を防 ための実験プラットフォームの設計指針も提案 A/Bテストの誤解を減らし、より正確な意思決定を支援 ※内容の共有を重視するため数式による証明の多 は省略 5
導入 •A/Bテスト(オンライン制御実験)は新しいアイデアを評価するために広 活用 大手企業では100件/営業日以上の実験処理を実施 •統計理論は十分に文書化 れて り、一部の落とし穴についても共有 •し し、統計の誤った適用や誤解 依然として多発
書籍、論文、ソフトウェアに いても散見 特に「直感的に正し 思える 実は誤った統計解釈(直感的誤解)」 問題 •そのため、「直感的誤解」を事例に基づいて解説 6
動機 •業界に るA/Bテスト実践事例の共有 GuessTheTest:「A/Bテスト事例」を紹介するウェブサイト うした取り組みは有益である一方で誤解を生む可能性もある 7 https://guessthetest.com/
動機 •事例:CVR 337%向上したA/Bテスト(GuessTheTest) • の結果は本当に信頼で るの ? うした直感的な誤解を分析し、統計的推論を用いて問題点を明確化 業界のA/Bテスト実践を改善するためのベストプラクティスを提案 8
実験概要 2つのLPを比較 サンプル 50%/50% 結論 • p値が0.05を下回るため有意 • 検出力97%で問題なし
意外な結果には強力な証拠が必要 • 意外な結果は注目を集めやすい 、誤解を招 ストーリー性 強 、誤り 発覚しても広まりやすい 心理学の有名な研究の多 再現に失敗(誤解の可能性
ある) 9
意外な結果には強力な証拠が必要 • p値の誤解(ベルヌーイの誤謬) p値 0.05=5%の確率で誤検出 信頼度=(1-p値)×100% Optimizelyのドキュメントではp値0.10を「10%のエラー率」と誤解 A/Bテスト関連の書籍や専門家でも誤解 広まっている 謝罪をする事例も
• p値の正しい理解 帰無仮説 正しいと仮定した場合、観測 れた結果以上に極端な統計量 得られる確率 設定した有意水準よりもp値 低い場合に、帰無仮説 棄却 れ有意差 あると判断 10
意外な結果には強力な証拠が必要 • FPRとは? p値 ら有意な差 ある と わ っても、それ 誤検出(偽陽性)である確率(リスク)
統計的有意性≠本当に効果 ある と 特に成功率 低いとFPR 増加 • 誤検出への対策 p値だ でな 、FPRも表示 意外な結果(新たな発見)には 必ず再現実験を実施 有意水準として0.01や0.005(厳しい値)を設定 11
意外な結果には強力な証拠が必要 • Twymanの法則「極端な数字は(たいてい)間違っている」 事例:極端なCV数の増加 Airbnb、Booking、Amazon、Microsoftでの数万回のA/Bテストの経験上、「CVの300%の増加」は(ほぼ)ありえない p値 極端に低い場合のみ受 入れるべ 12 結果
良す る と ら、まずは疑うべ (あるいは有意水準を低 設定する)
意外な結果には強力な証拠が必要 • 結論と推奨 A/Bテストの適切な運用のために意外な結果には慎重に 実験プラットフォームはFPRを表示し、意外な結果(低いp値)を検知可能に 意外な結果に対して、FPRを考慮し、p値0.01または0.005を推奨(FPRを下 る) Twymanの法則を適用し、意外な結果は再実験 13
検出力の低い実験は信頼性が低い •検出力とは? 本当に効果差(δ) 存在する場合にそれを検出で る確率 (帰無仮説を棄却で る確率) •適切な検出力の確保 A/Bテストでは十分な検出力を確保するために、適切なサンプル数 必要
業界標準 検出力:80%(1-β=0.8) 有意水準(p値の閾値):0.05(α=0.05) サンプル数の計算式: •検出力 低いと… 有意な結果 出に い(効果 あっても見逃す) 有意な結果 出ても誤検出の可能性 高まる 14
検出力の低い実験は信頼性が低い • GuessTheTestの例 • (実務で扱う題材に いて) 統計的に意味のある結果を得るには数千~数万のサンプル 必要 15 検出率は業界標準の80%に対して低い
CVR 3.7% 検出すべき最小変化( δ) 10% 必要なサンプル数 ? 実際のサンプル数 82人(75人) 必要な検出力 80% 実際の検出力 3%(97%ではない) 必要なサンプル数:41,642人
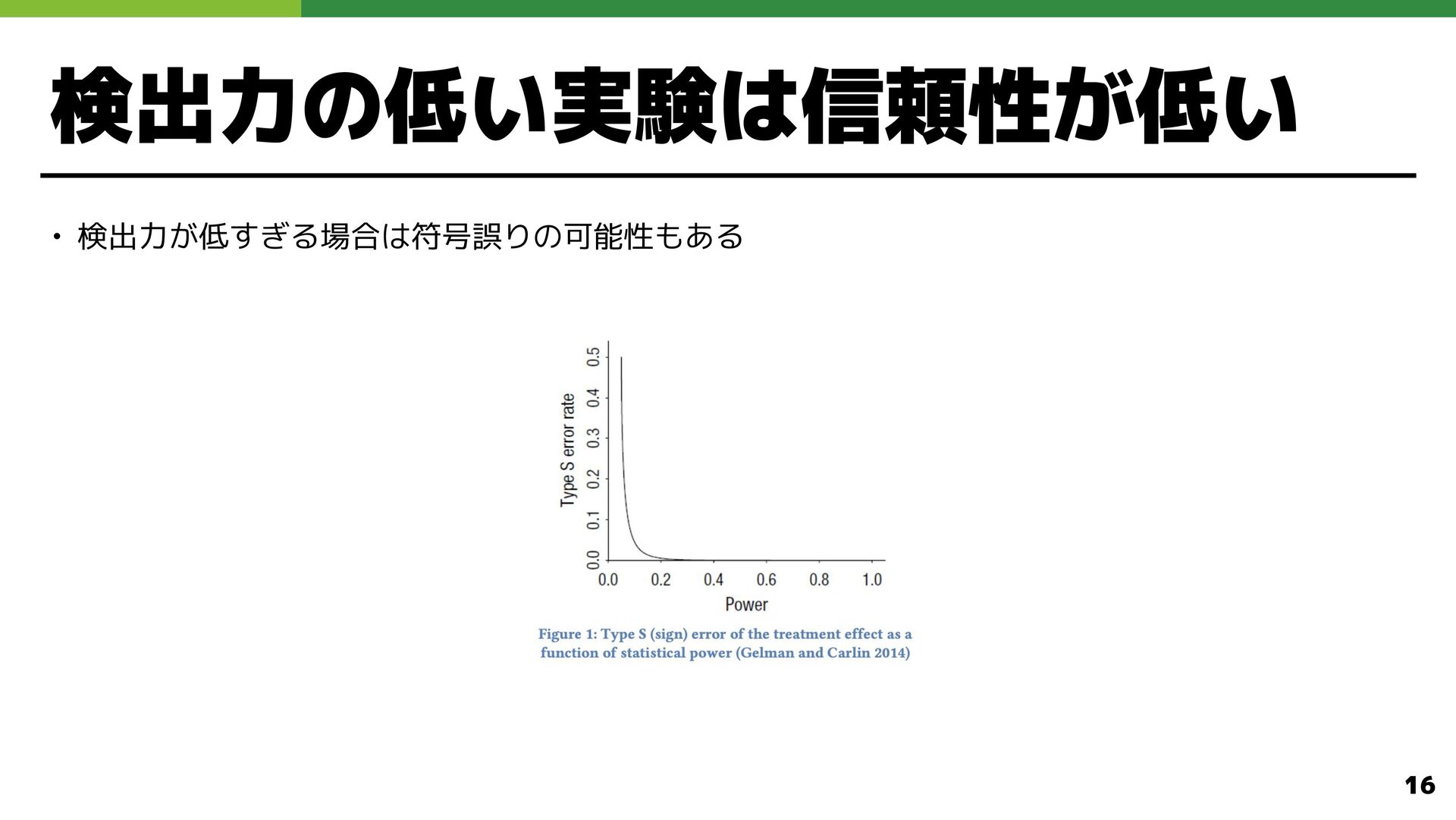
検出力の低い実験は信頼性が低い • 検出力 低す る場合は符号誤りの可能性もある 16
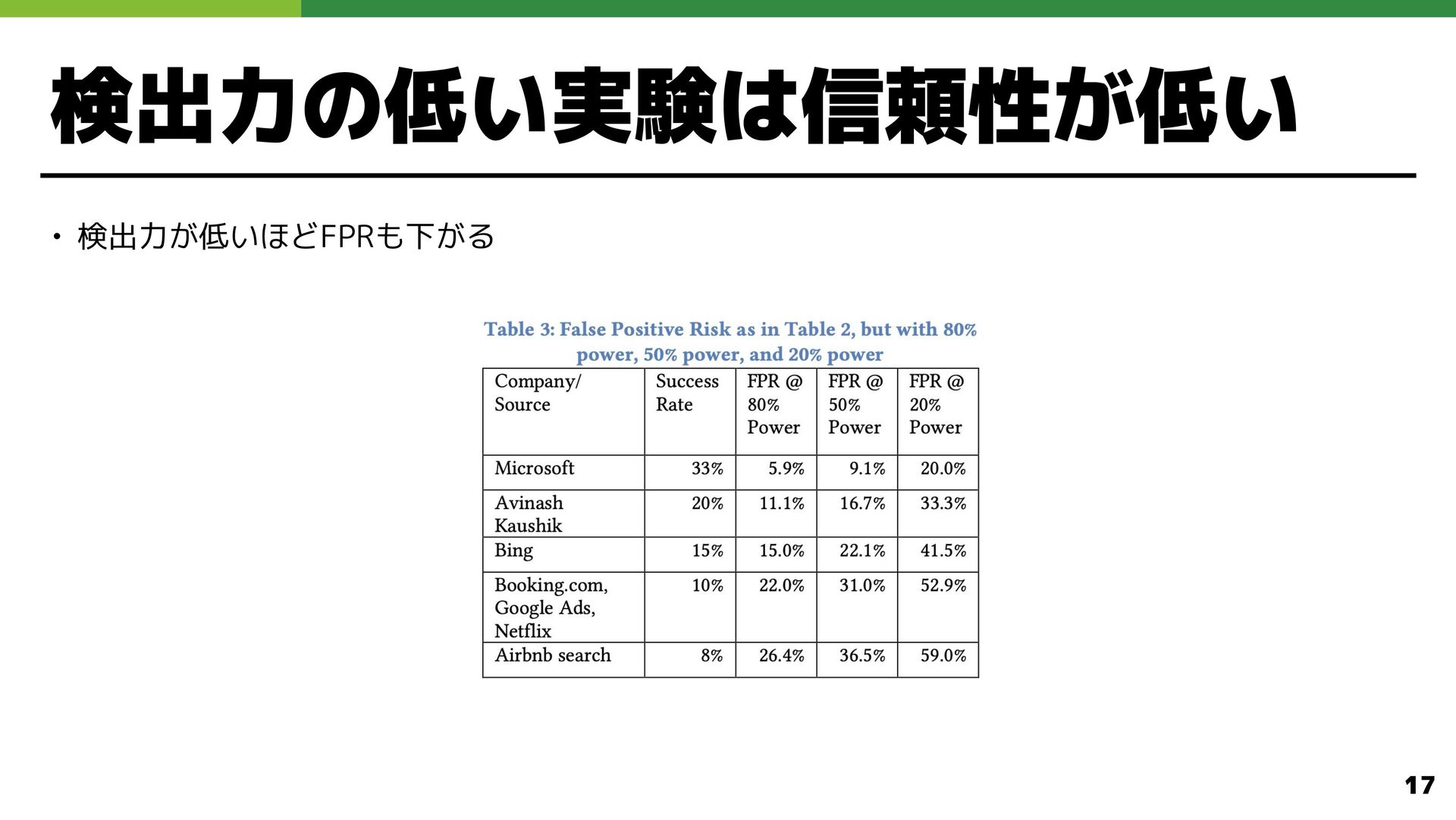
検出力の低い実験は信頼性が低い • 検出力 低いほどFPRも下 る 17
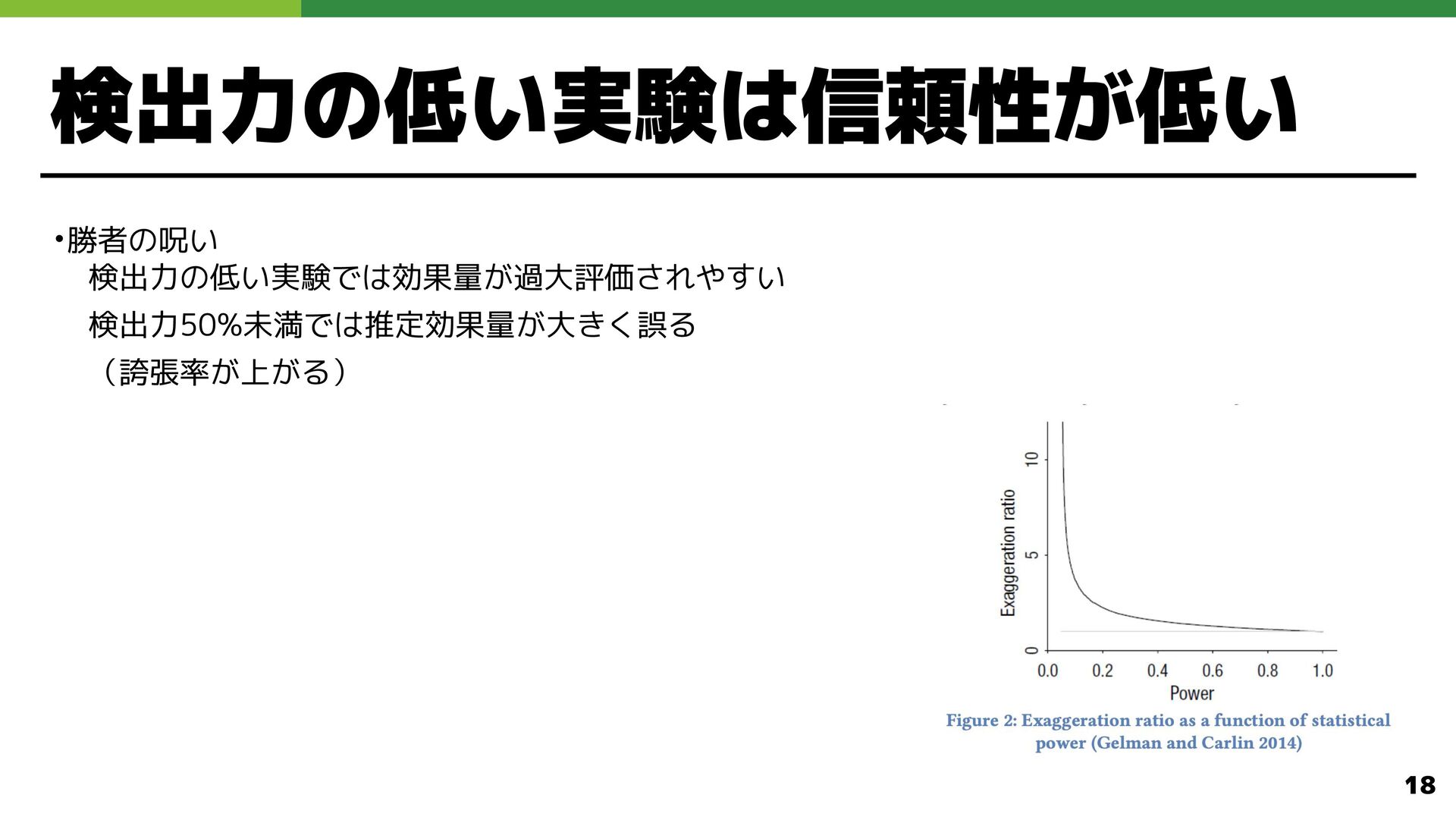
検出力の低い実験は信頼性が低い •勝者の呪い 検出力の低い実験では効果量 過大評価 れやすい 検出力50%未満では推定効果量 大 誤る (誇張率 上
る) 18
検出力の低い実験は信頼性が低い •結論と推奨 検出力の低い実験は誤った結論を導 リスク 高い A/Bテストでは最低でも数千、理想的には数万のサンプル 必要 検出力80%以上を確保するため、事前のサンプル数計算を徹底 実験プラットフォームは検出力の低い実験を防 仕組みを導入すべ
適切な検出力を確保し、信頼で る実験を行う 19
事後検出力の計算は不安定 •事後検出力とは? A/Bテスト後に、観測 れた効果を基に検出力を推定する手法 (p値と有意水準αのみで決定 れる) •事後検出力≠実際の検出力 事後検出力の計算はノイズ 大 、
誤った結論を導 可能性 高い p値 0.05を超えると、 事後検出力は50%未満 (低す る) 20
事後検出力の計算は不安定 •なぜ問題 ? p値に大 依存し、変動 激しい p値はサンプル数やデータのばらつ によって大 変動するため、事後検出力も不安定 特に検出力
低い場合、p値のばらつ 激し 、事後検出力の計算は正確な指標にはならない(ほぼ意味をな ない) 「効果 本当にない」場合でも、低い事後検出力を「小 いサンプル数のせい」と誤解 実験結果 「有意でない」と 、「サンプル数 小 いせいで効果を検出で な った」と考える ともある 、 それは誤った推論で単に「効果 ない」可能性もある 検出力を事後的に計算するのではな (事後検出力を用いず)、事前に適切なサンプル数を設定すべ p値と有意水準αのみで決まる 検出力は本来、サンプル数、効果量、ばらつ によって決まる検出力とは異なる(事後検出力≠実際の検出力) 21
事後検出力の計算は不安定 •実験プラットフォームでの推奨事項 事後検出力の表示は不要 事前に「最小検出可能効果量(MDE)」を設定 観測効果ではな 、事前の基準で検出力を計算 例:Booking.comのExperiment Tool 新規実験時にMDEを入力 事後検出力は表示せず、事前計画を重視
22
事後検出力の計算は不安定 •結論と推奨 事後検出力は誤解を招 ため使用すべ でない A/Bテストでは事前の検出力の計算を重視 実験プラットフォームはMDEを入力 せるべ 事後検出力を採用せず、事前の検出力計算を重視 23
実験環境での自由度を最小限に • A/Bテストの結果はデータの処理方法によって大 変わる • 恣意的なデータの処理(外れ値除去やデータの切り分 ) 行われると、 統計的に有意に見える結果 得られてしまう
• 統計的有意性は事前に決めたルールに従って評価すべ 24
実験環境での自由度を最小限に •事例1:外れ値除去の落とし穴 あるA/Bテストで「統計的に有意」と報告 れた 、 実サンプルでの検定に いてp値は有意ではな った 実は極端な外れ値を除去するという操作 行われた
外れ値除去は仮説に依存せずに行うべ 特にバリアント とに独立した外れ値除去をすると、FPR 上昇する とも •事例2:リアルタイムA/Bテストの落とし穴 Optimizelyの初期のA/Bテストではリアルタイムのp値を確認で た 運用者はp値 有意になった瞬間に実験を停止するようになった の手法は第一種過誤を増大 せる 25
実験環境での自由度を最小限に •結論と推奨 事前の設定を推奨 実験システムではデータ処理を標準化する と 重要 データの処理(外れ値除去やデータの切り分 )のルールを事前に設定し、実験の構成として明示する データ処理の変更履歴を記録し、透明性を確保(例:Booking.com) A/Bテストの強みを活
す ソフトウェアに るA/Bテストは再実験のコスト 低い 興味深い結果を発見したら、新たな仮説を立てて再実験すべ 26
不均等なバリアントに注意 •A/Bテストではコントロールとトリートメントを均等に割り当てるの 一般的 •理論上は「コントロールを大 すると検出力 上 る」と考えられる 特に段階的導入ではトリートメントを小 設定する ともある
(例:10%→50%) し し、不均等なバリアントは技術的・統計的な問題を引 起 す可能性 ある 27
不均等なバリアントに注意 •不均等なバリアントの理論上のメリット コントロールを大 すると、トリートメントとの比較で分散 小 なる と ら、 検出力 向上(最大10%程度)
具体的に考えると、1つのコントロールを複数のトリートメントと共有すると検出力 向上 (例:コントロール:50%、トリートメント×5:各10%) 28
不均等なバリアントに注意 •不均等なバリアントの採用による実務的な環境での問題(技術的・運用的リスク) トリガー型実験(特定の条件を満たすユーザーのみ対象)での実現 大変(考慮 必要) 期待通りにするためにはど で制御 せないとい ない Cookie
Churnで不均等になる ユーザー粒度での分割に対して、再割り当て 発生する 特に大 いバリアントに再割り当て れてしまう確率 高い( らに不均等に) LRU(Least Recently Used)キャッシュの影響により、大 なバリアント 有利になる レスポンス 早 なるなど •実務的な環境では均等なバリアント 推奨 29
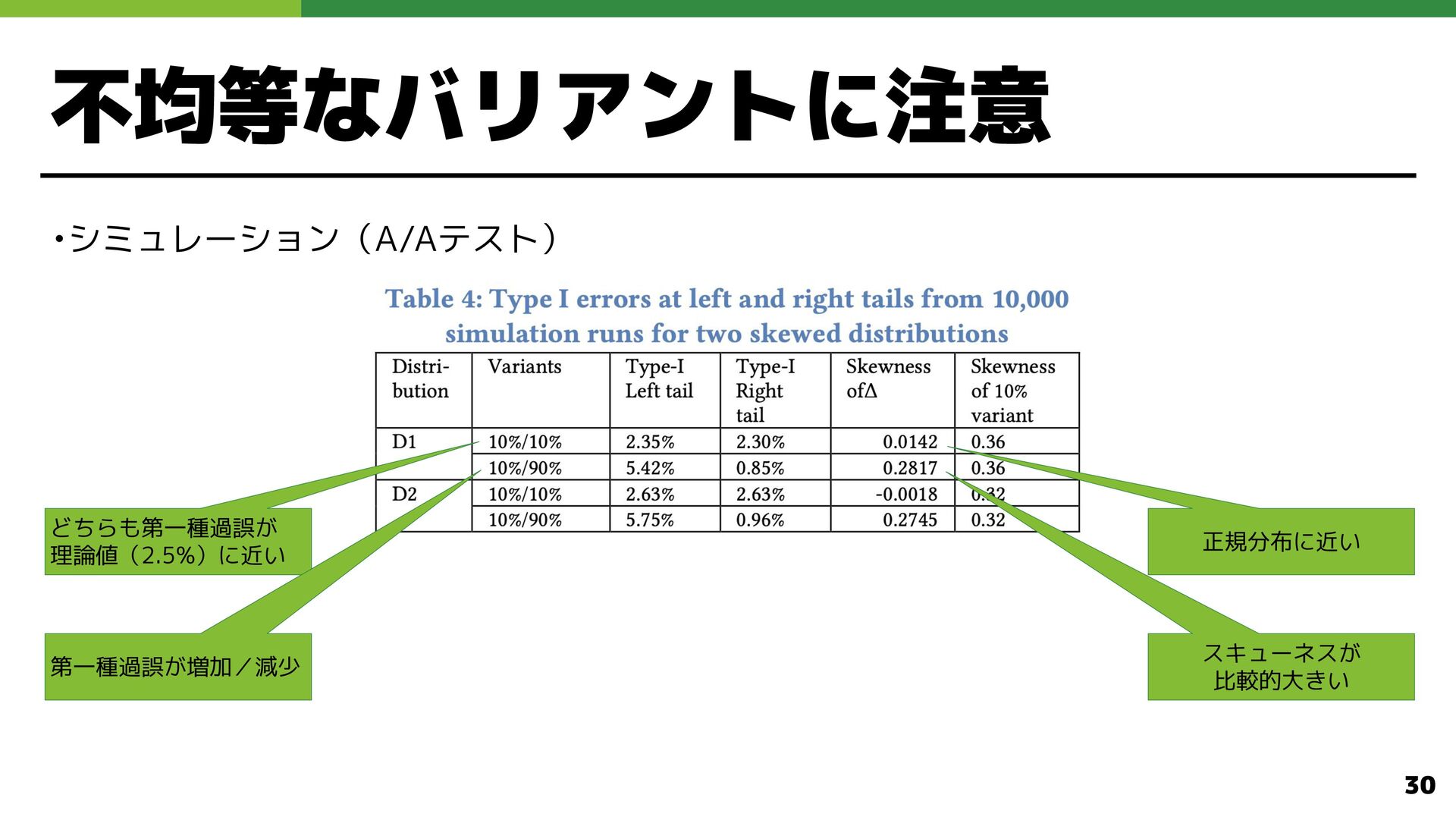
不均等なバリアントに注意 •シミュレーション(A/Aテスト) どちらも第一種過誤 理論値(2.5%)に近い スキューネス 比較的大 い 正規分布に近い 第一種過誤 増加/減少
30
不均等なバリアントに注意 •結論と推奨 不均等なバリアントは第一種過誤を増加 せる可能性 ある 検出力の向上だ でな 、誤検出のリスクも考慮する必要 ある 31
まとめ •A/Bテストに る5つの「直感的誤解」を解説 ①意外な結果には強力な証拠 必要 ②検出力の低い実験は信頼性 低い ③事後検出力の計算は不安定 ④実験環境での自由度を最小限に ⑤不均等なバリアントに注意
•実験者 誤解しに い実験プラットフォームの設計を提案 一部の推奨事項は著者ら 関わる実際のプラットフォームに導入済み 32
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}