Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
アーキテクチャ選定から実装Tipsまで! AgentCore / Strands Agents...
Search
Yudai Jinno
March 19, 2026
1k
4
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
アーキテクチャ選定から実装Tipsまで! AgentCore / Strands AgentsでAIエージェントを実際に作ってわかったことN選
Yudai Jinno
March 19, 2026
More Decks by Yudai Jinno
See All by Yudai Jinno
はじめてのre:Inventを120%充実させよう! 〜初参加の経験を添えて〜
yuu551
1
210
AgentCoreの機能、全部要る? ユースケース別にAWSサービスとの組み合わせ方を一緒に整理しよう
yuu551
5
2.4k
Amazon Bedrock AgentCore Managed Harness 座学資料
yuu551
1
2.4k
AWS Agent Registryへの期待
yuu551
1
110
Amazon Bedrockで始めるRAG入門
yuu551
1
1k
個人的によく知らなかった AgentCore Memoryの機能を中心に深掘りしてみた
yuu551
2
850
Bedrock PolicyでAmazon Bedrock Guardrails利用を強制してみた
yuu551
1
770
Amazon Bedrock AgentCore EvaluationsでAIエージェントを評価してみよう!
yuu551
1
710
2025年 Amazon Bedrock AgentCoreまとめ
yuu551
31
22k
Featured
See All Featured
Information Architects: The Missing Link in Design Systems
soysaucechin
0
1k
Getting science done with accelerated Python computing platforms
jacobtomlinson
2
340
The Pragmatic Product Professional
lauravandoore
37
7.4k
WENDY [Excerpt]
tessaabrams
11
38k
The Success of Rails: Ensuring Growth for the Next 100 Years
eileencodes
47
8.2k
Building a A Zero-Code AI SEO Workflow
portentint
PRO
0
640
HTML-Aware ERB: The Path to Reactive Rendering @ RubyCon 2026, Rimini, Italy
marcoroth
3
360
Code Review Best Practice
trishagee
74
20k
RailsConf 2023
tenderlove
30
1.5k
Discover your Explorer Soul
emna__ayadi
2
1.2k
SEO for Brand Visibility & Recognition
aleyda
0
4.6k
The AI Revolution Will Not Be Monopolized: How open-source beats economies of scale, even for LLMs
inesmontani
PRO
3
3.6k
Transcript
アーキテクチャ選定から実装Tipsまで! AgentCore / Strands AgentsでAIエージェントを実 際に作ってわかったことN選 Hello! AgentCore Lunch オンライン
〜本格アプリ開発ノウハウ編!〜 神野 雄大(Jinno Yudai/@yjinn448208)
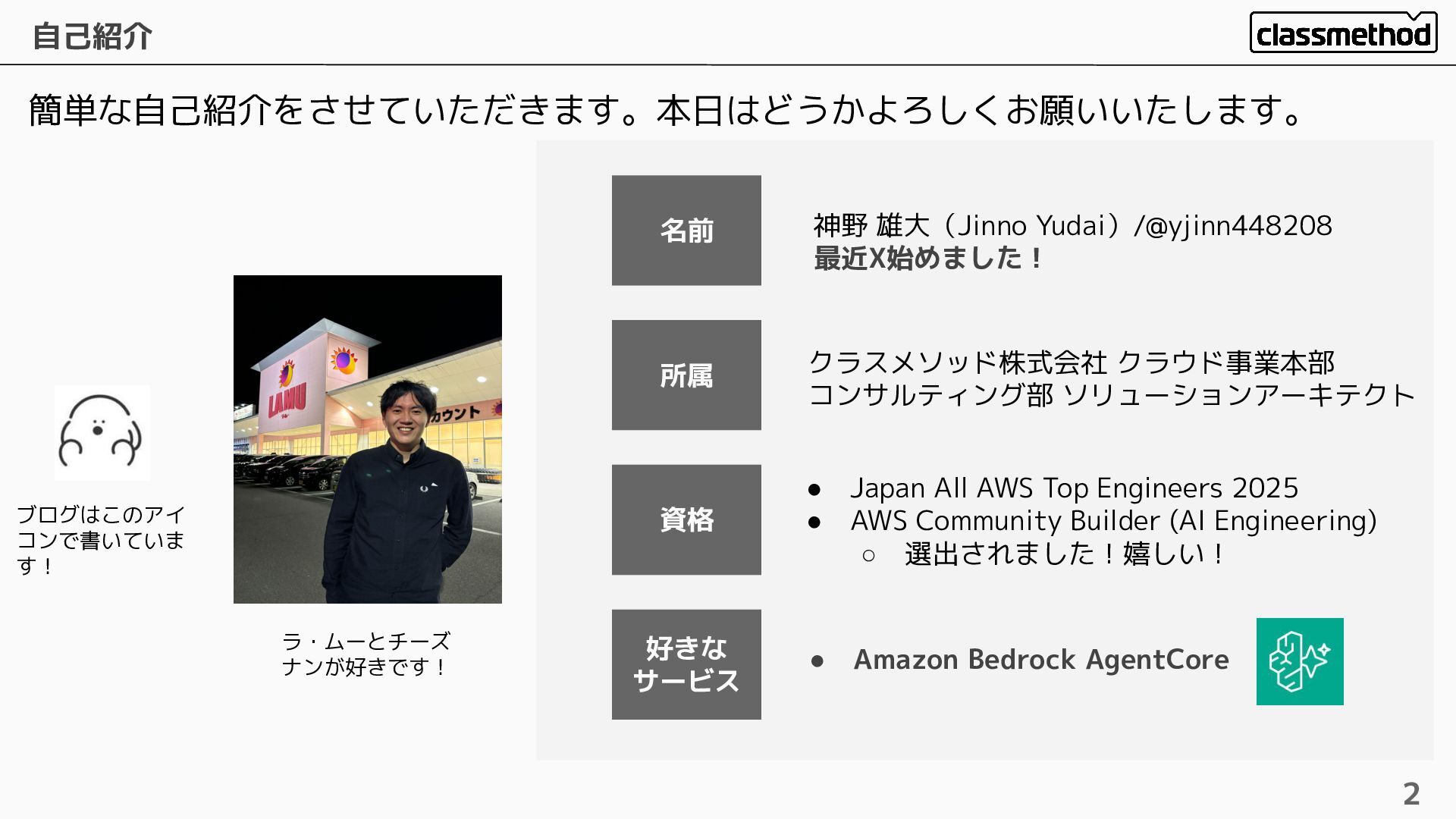
自己紹介 2 簡単な自己紹介をさせていただきます。本日はどうかよろしくお願いいたします。 名前 神野 雄大(Jinno Yudai)/@yjinn448208 最近X始めました! 所属 クラスメソッド株式会社
クラウド事業本部 コンサルティング部 ソリューションアーキテクト • Japan All AWS Top Engineers 2025 • AWS Community Builder (AI Engineering) ◦ 選出されました!嬉しい! 資格 好きな サービス ブログはこのアイ コンで書いていま す! ラ・ムーとチーズ ナンが好きです! • Amazon Bedrock AgentCore
対象と目的 3 本日はAmazon Bedrock AgentCoreをアプリケーションに組み込もうと思っている方に 対して実際に作った知見を少しでも共有できればと思っております。 対象 対象と目的 • Amazon
Bedrock AgentCoreを触ったことはあるがお試しレベル で、アプリケーションに組み込む際のTipsを知りたい 目的 • Amazon Bedrock AgentCoreやStrands Agentsを使ったアプリケーショ ンの実装Tipsを理解して活用できるようになる
お断り 4 大変申し訳ないですが、本日の内容はAgentCoreを少し触ったことがある、何ができる かざっくりと理解していることを前提としています。もし触りの箇所から知りたい場合 は手前味噌で恐縮ですが私のブログで解説しているのでみていただけると嬉しいです。 【2025年版】 Amazon Bedrock AgentCoreま とめ資料を公開します!
著者ページ Sorry・・・
5 内容 今日は本番導入時に重要なポイントになりそうなTipsに絞ってお伝えさせていただきま す。実際に作った感想なので一部当たり前じゃん・・・?みたいなものもあるかもしれ ませんがご了承ください。今回ご紹介する話はあくまで一案ですので正解ではない点も ご了承ください。 • 実際に作っていたAIエージェントのデモ • Tips集
作ったAIエージェント:情報体系化AIエージェント Info Organizer 6
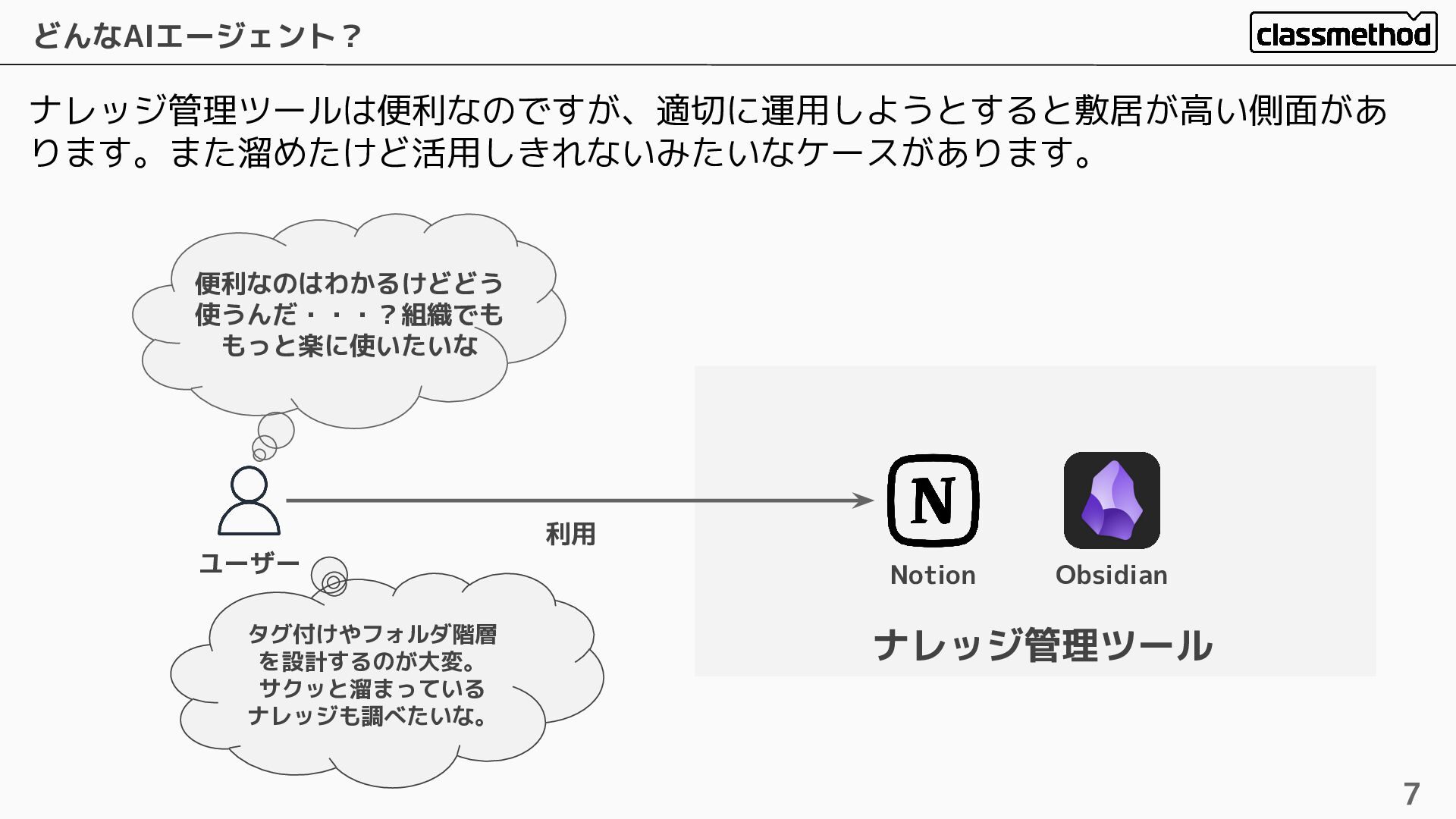
ナレッジ管理ツールは便利なのですが、適切に運用しようとすると敷居が高い側面があ ります。また溜めたけど活用しきれないみたいなケースがあります。 どんなAIエージェント? 7 ユーザー Notion Obsidian 利用 ナレッジ管理ツール 便利なのはわかるけどどう
使うんだ・・・?組織でも もっと楽に使いたいな タグ付けやフォルダ階層 を設計するのが大変。 サクッと溜まっている ナレッジも調べたいな。
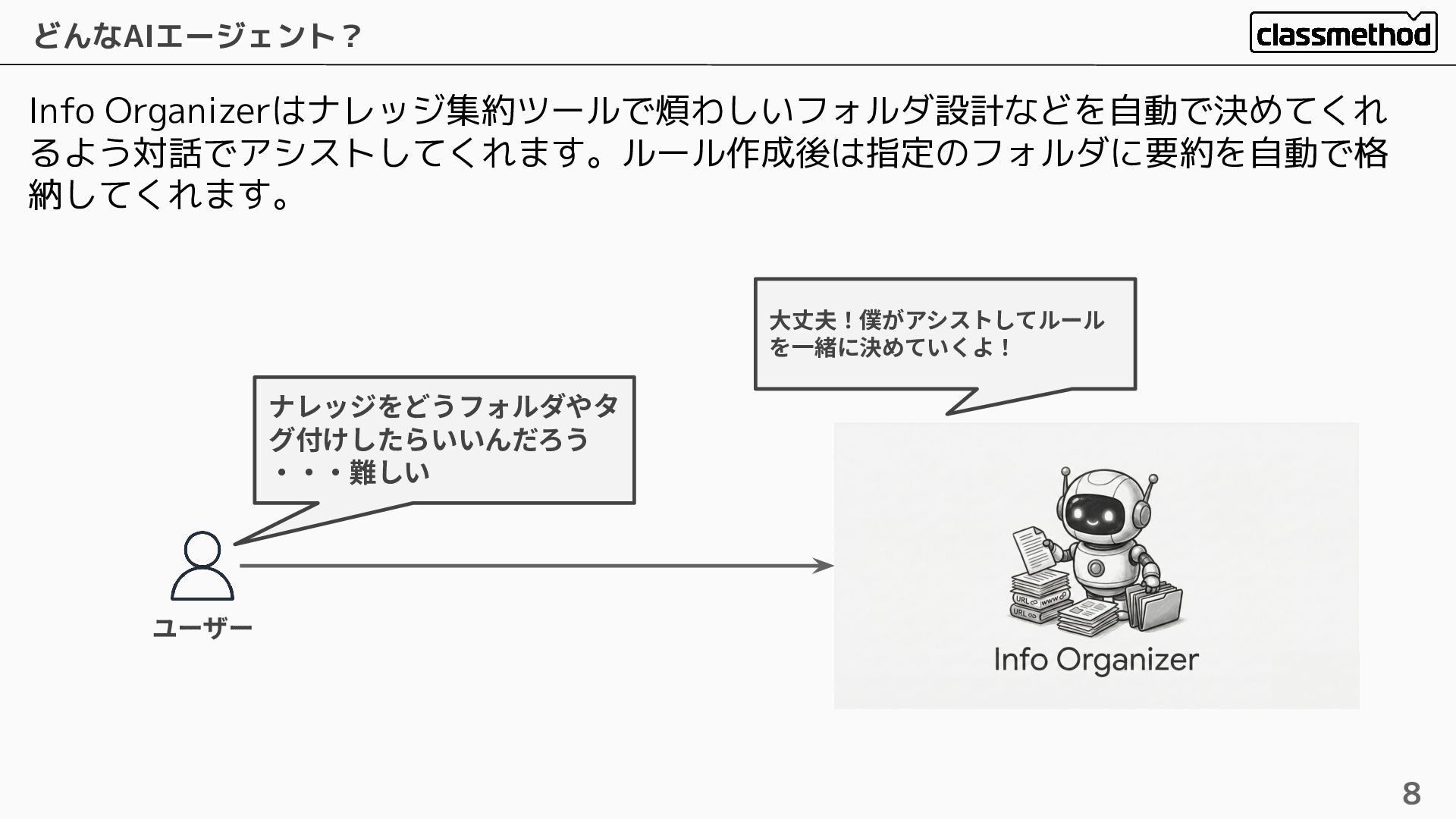
Info Organizerはナレッジ集約ツールで煩わしいフォルダ設計などを自動で決めてくれ るよう対話でアシストしてくれます。ルール作成後は指定のフォルダに要約を自動で格 納してくれます。 どんなAIエージェント? 8 ユーザー ナレッジをどうフォルダやタ グ付けしたらいいんだろう ‧‧‧難しい
⼤丈夫!僕がアシストしてルール を⼀緒に決めていくよ!
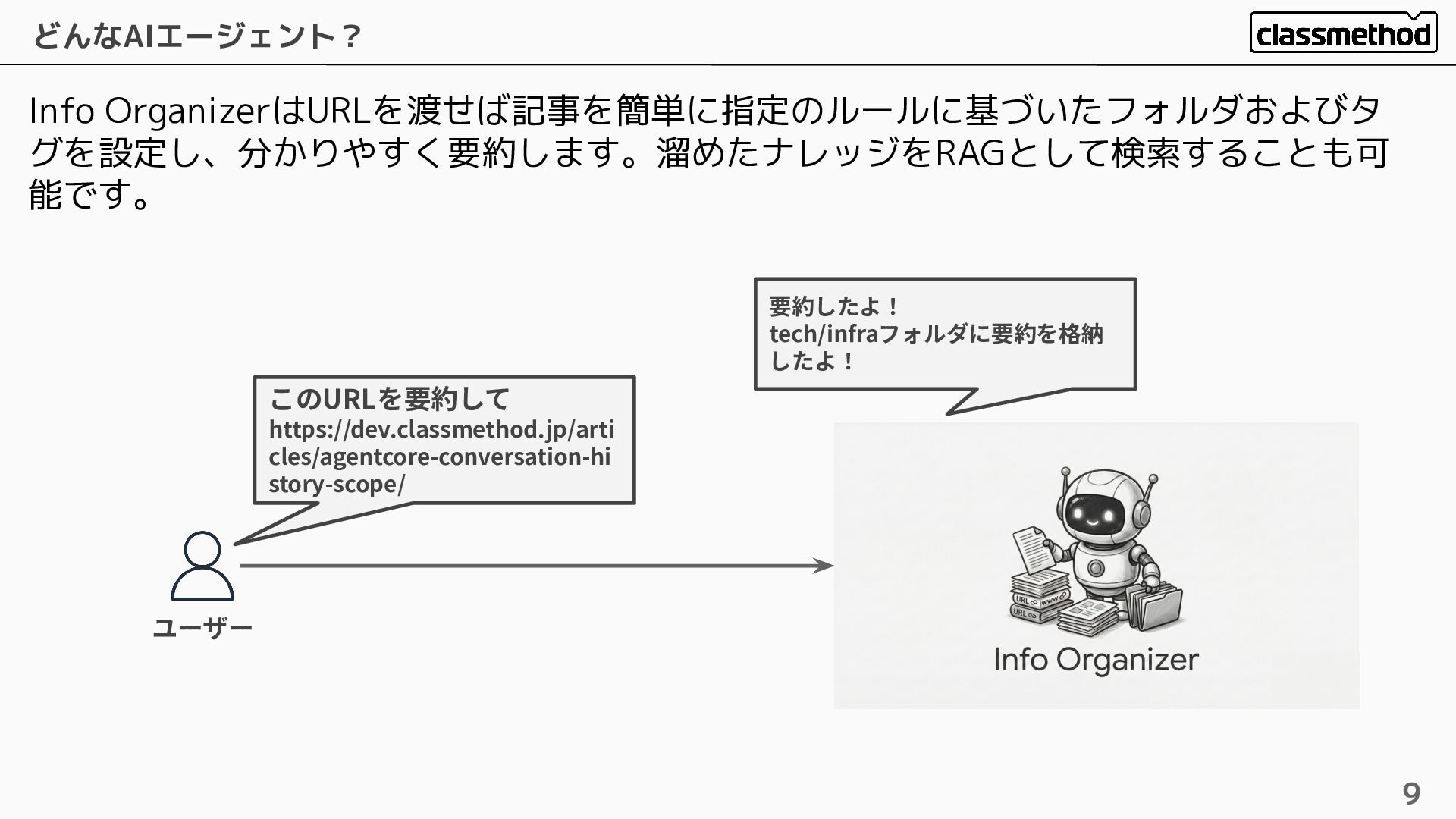
Info OrganizerはURLを渡せば記事を簡単に指定のルールに基づいたフォルダおよびタ グを設定し、分かりやすく要約します。溜めたナレッジをRAGとして検索することも可 能です。 どんなAIエージェント? 9 ユーザー このURLを要約して https://dev.classmethod.jp/arti cles/agentcore-conversation-hi
story-scope/ 要約したよ! tech/infraフォルダに要約を格納 したよ!
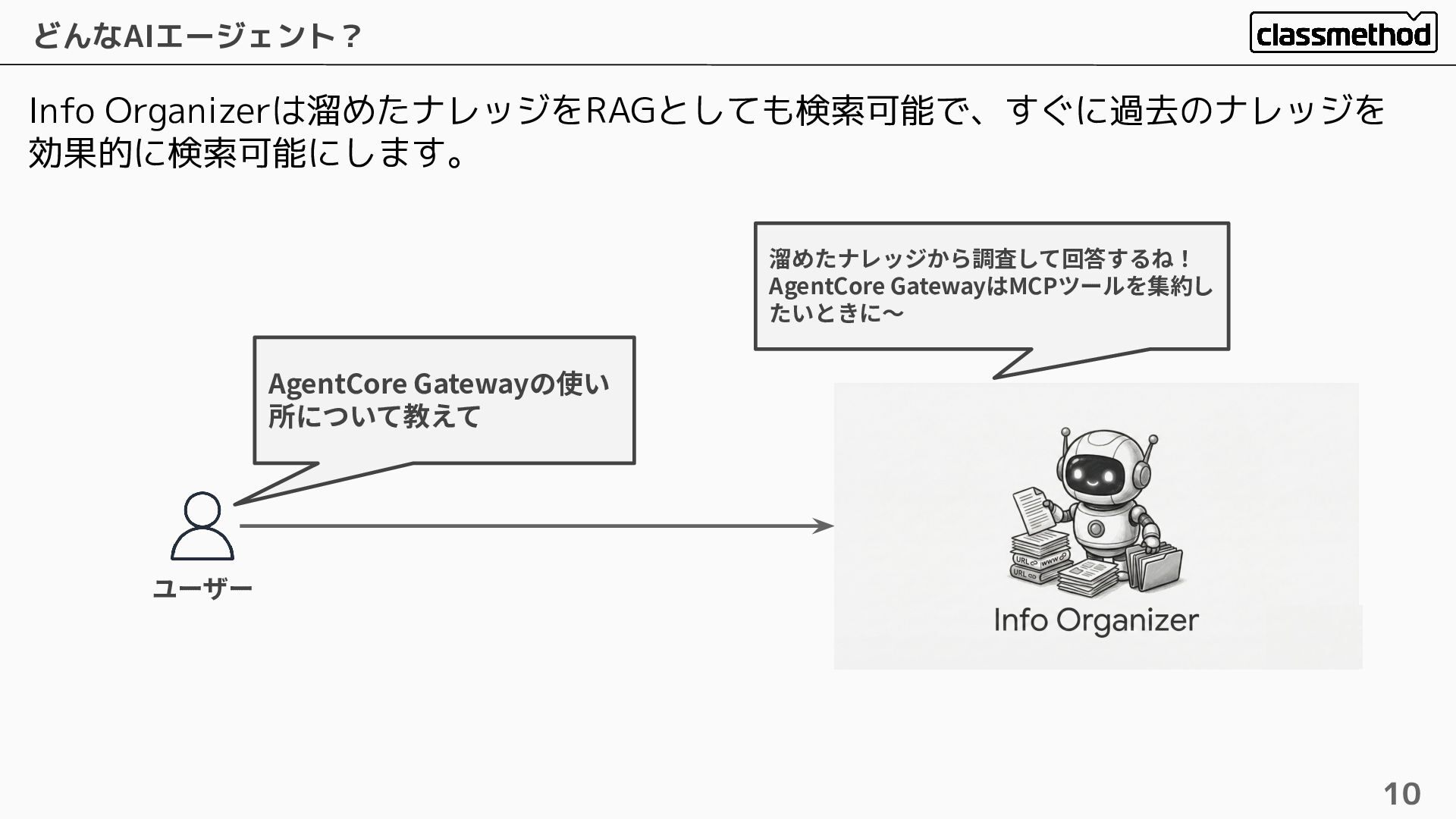
Info Organizerは溜めたナレッジをRAGとしても検索可能で、すぐに過去のナレッジを 効果的に検索可能にします。 どんなAIエージェント? 10 ユーザー AgentCore Gatewayの使い 所について教えて 溜めたナレッジから調査して回答するね!
AgentCore GatewayはMCPツールを集約し たいときに〜
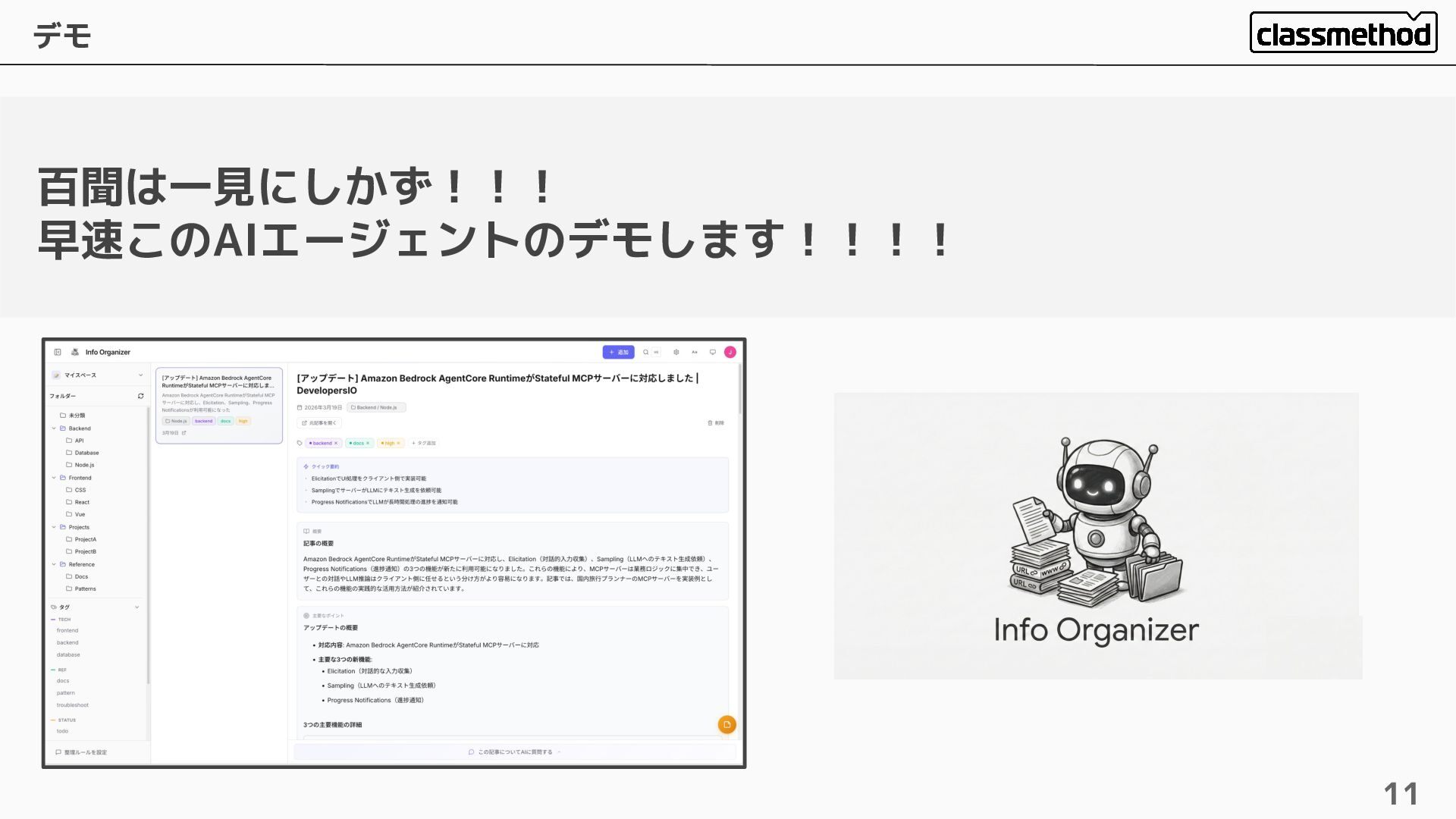
デモ 11 百聞は一見にしかず!!! 早速このAIエージェントのデモします!!!!
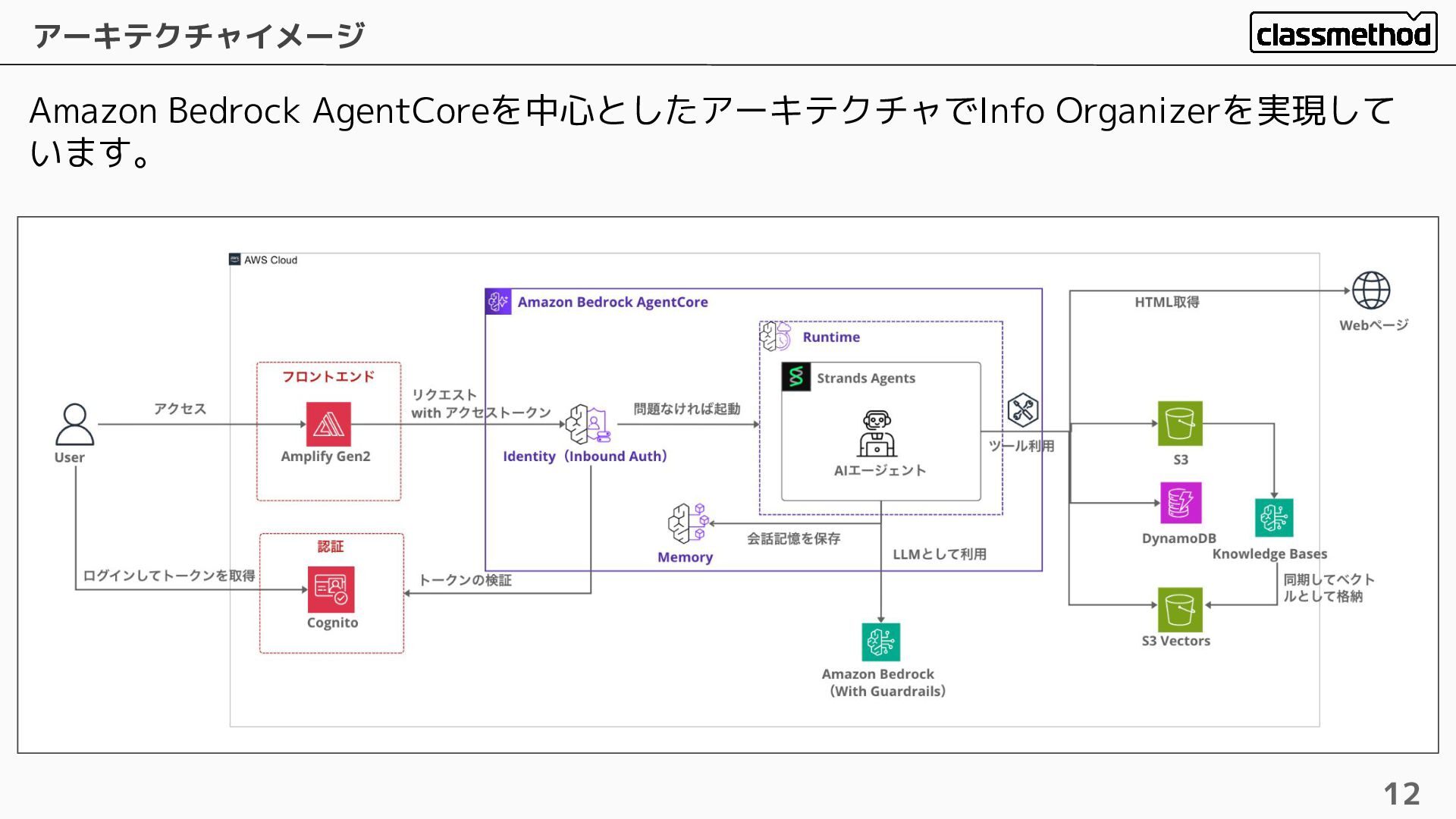
Amazon Bedrock AgentCoreを中心としたアーキテクチャでInfo Organizerを実現して います。 アーキテクチャイメージ 12
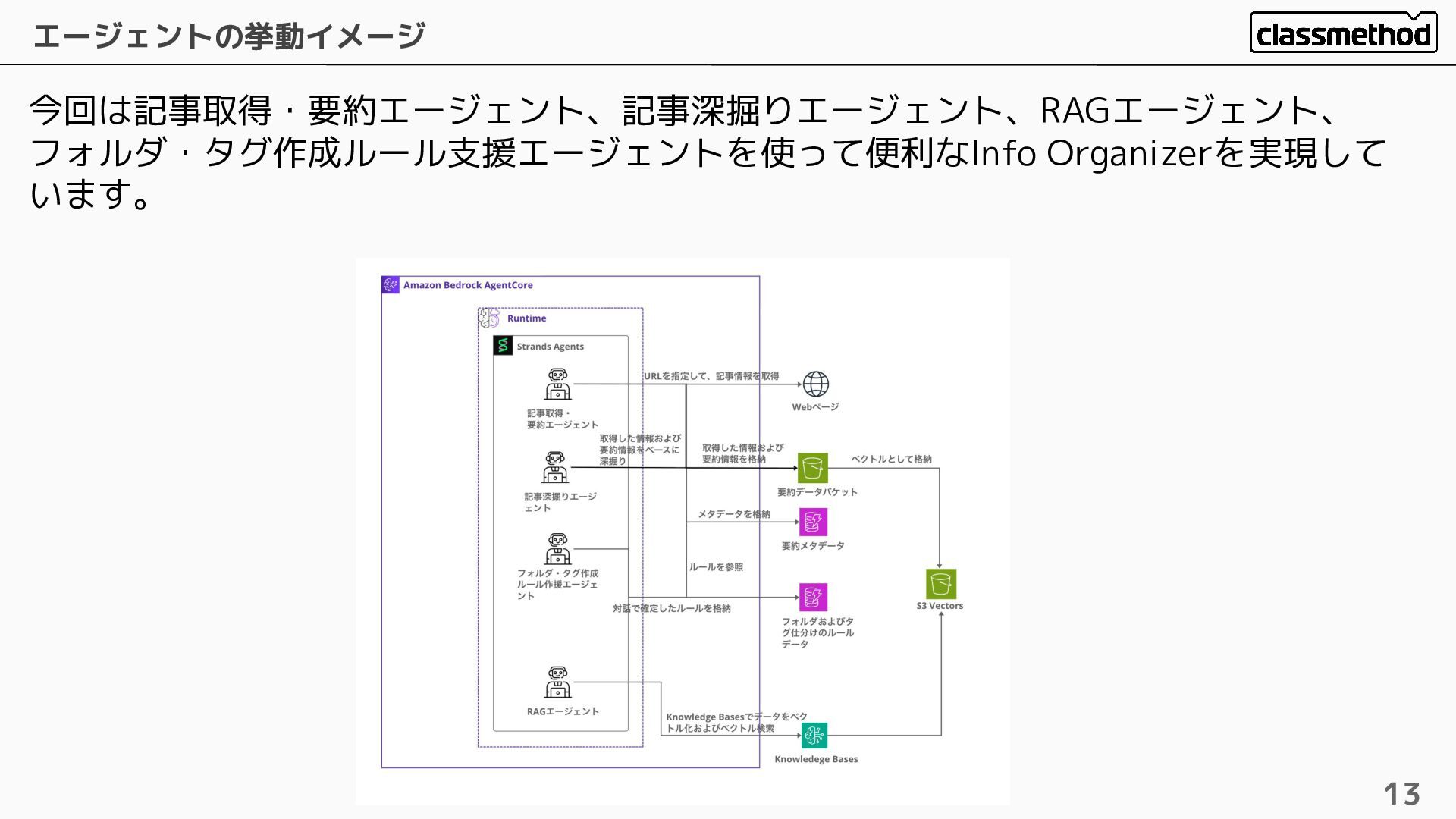
今回は記事取得・要約エージェント、記事深掘りエージェント、RAGエージェント、 フォルダ・タグ作成ルール支援エージェントを使って便利なInfo Organizerを実現して います。 エージェントの挙動イメージ 13
今日はこのInfo Organizerや今まで実装してきた経験からTipsを共有 したいと思います! 14
Tips1:無闇にAIエージェントに飛びつかない 15
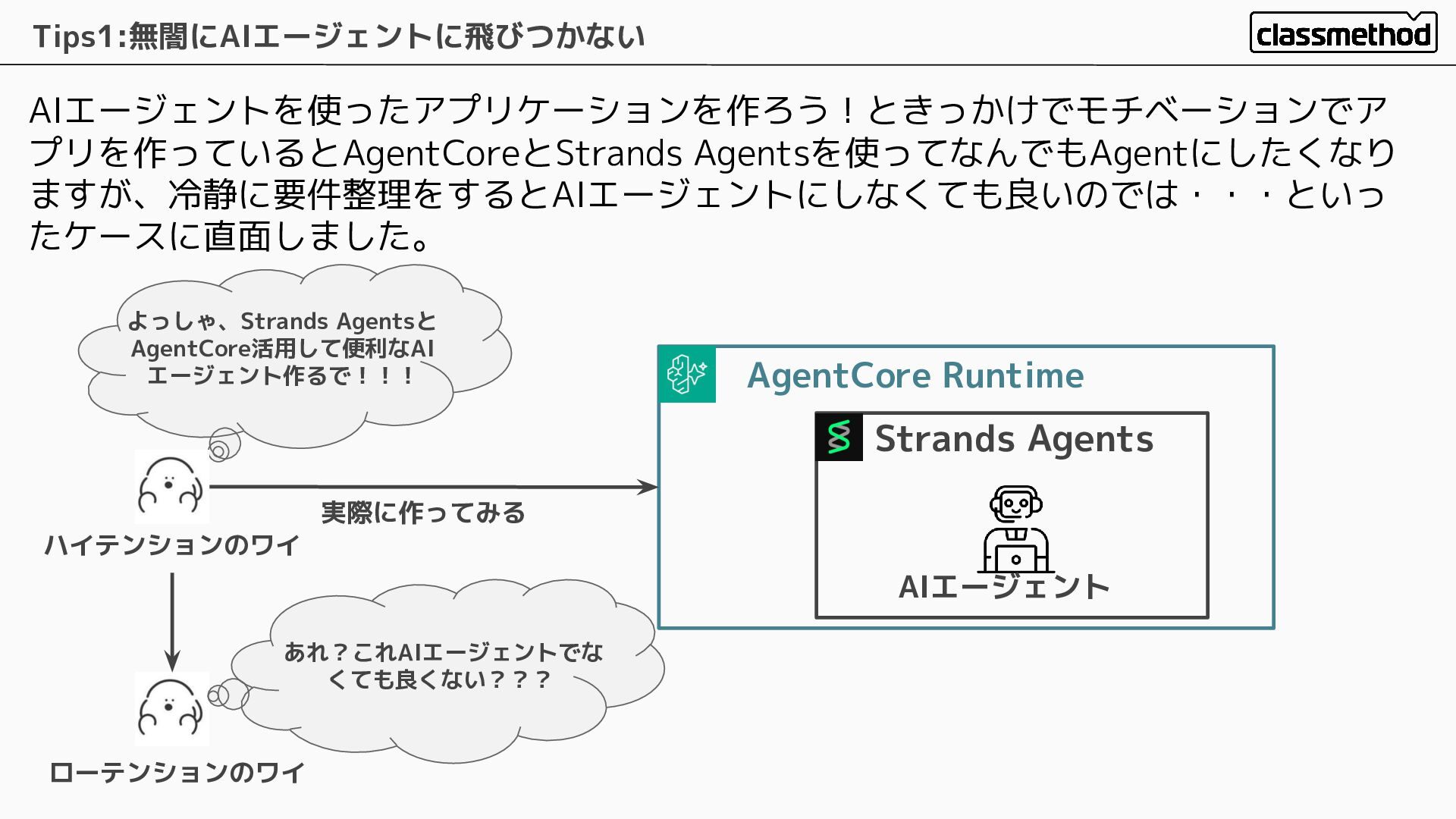
AIエージェントを使ったアプリケーションを作ろう!ときっかけでモチベーションでア プリを作っているとAgentCoreとStrands Agentsを使ってなんでもAgentにしたくなり ますが、冷静に要件整理をするとAIエージェントにしなくても良いのでは・・・といっ たケースに直面しました。 Tips1:無闇にAIエージェントに飛びつかない ハイテンションのワイ よっしゃ、Strands Agentsと AgentCore活用して便利なAI
エージェント作るで!!! AgentCore Runtime Strands Agents AIエージェント 実際に作ってみる ローテンションのワイ あれ?これAIエージェントでな くても良くない???
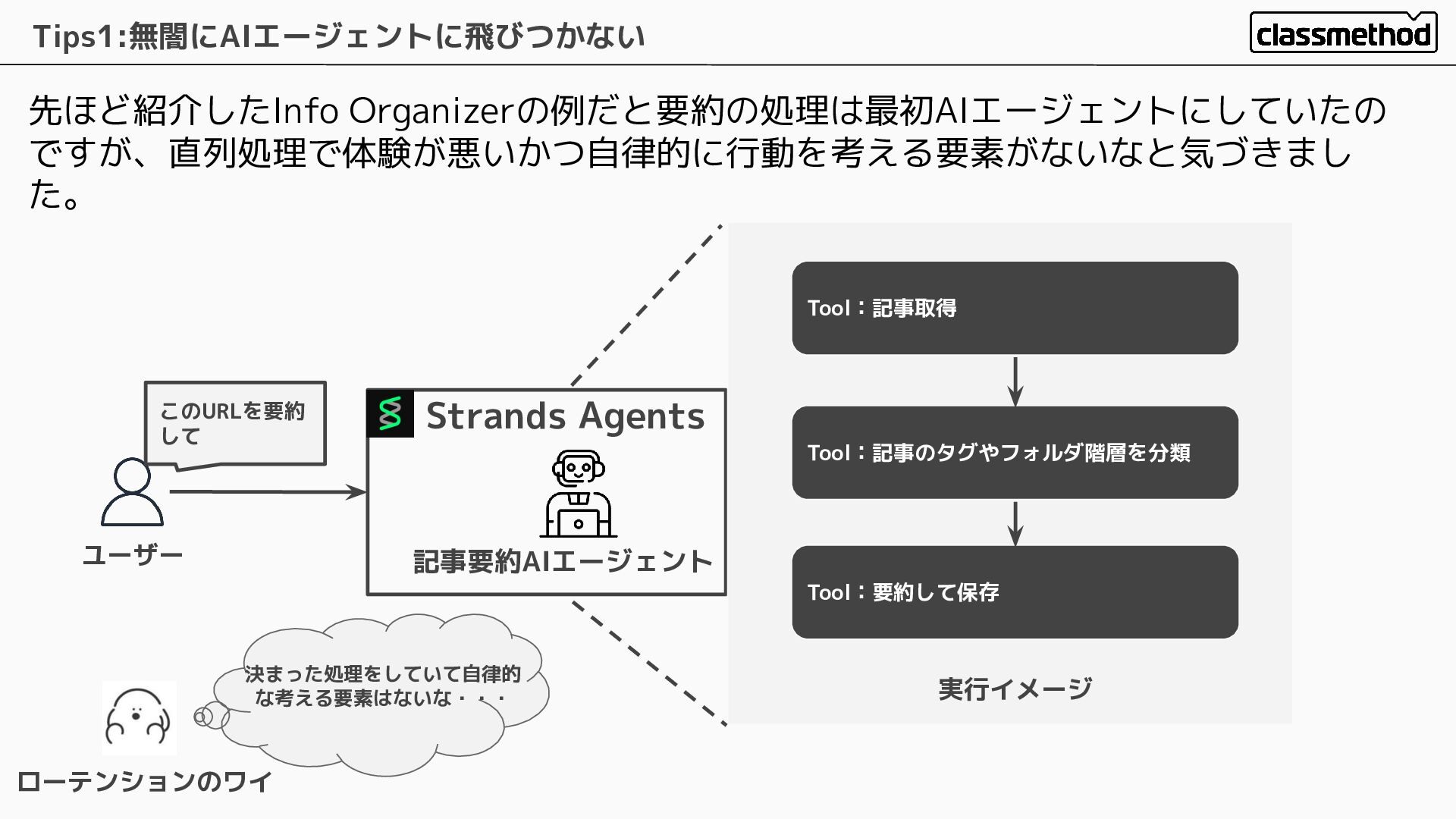
先ほど紹介したInfo Organizerの例だと要約の処理は最初AIエージェントにしていたの ですが、直列処理で体験が悪いかつ自律的に行動を考える要素がないなと気づきまし た。 Tips1:無闇にAIエージェントに飛びつかない ユーザー このURLを要約 して 記事要約AIエージェント Tool:記事取得
Tool:記事のタグやフォルダ階層を分類 Tool:要約して保存 実行イメージ ローテンションのワイ 決まった処理をしていて自律的 な考える要素はないな・・・ Strands Agents
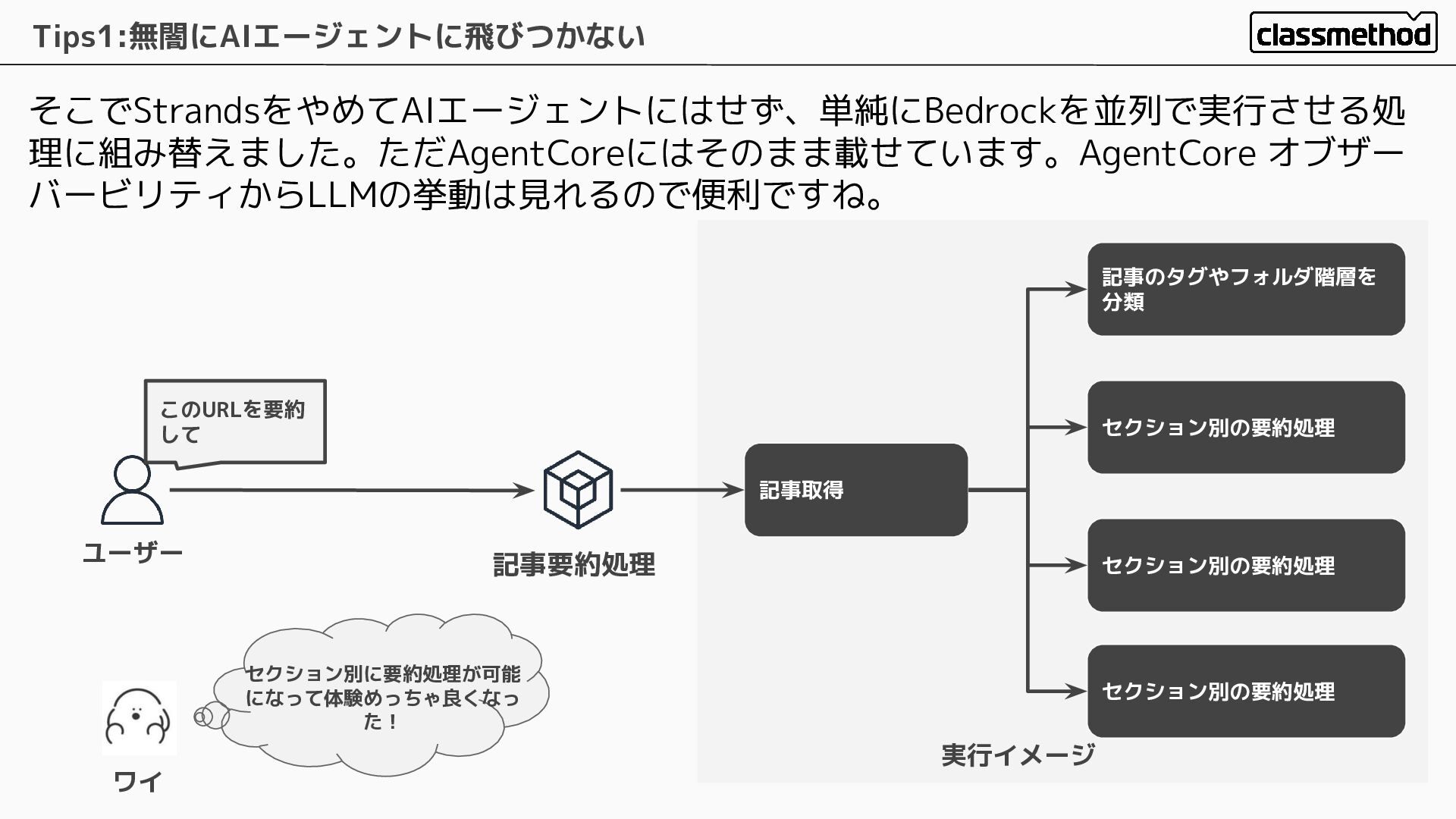
そこでStrandsをやめてAIエージェントにはせず、単純にBedrockを並列で実行させる処 理に組み替えました。ただAgentCoreにはそのまま載せています。AgentCore オブザー バービリティからLLMの挙動は見れるので便利ですね。 Tips1:無闇にAIエージェントに飛びつかない ユーザー このURLを要約 して 記事要約処理 記事取得
記事のタグやフォルダ階層を 分類 セクション別の要約処理 セクション別の要約処理 セクション別の要約処理 セクション別に要約処理が可能 になって体験めっちゃ良くなっ た! ワイ 実行イメージ
ポイント:AIエージェントを作ろうといった気持ちで開発を進めると、 どうしてもAIエージェントでどうソリューションを生み出すか考えが ちになるので、改めて要件に立ち返ってシンプルに実現できる方を選 びたい。 19 無理にエージェントにしなくても良いよね! どうしても技術駆動で考えてしまう・・・ 個人的にはユーザービリティを高めるための自律性が求められたり、人間のオペレーション を部分的に代替していくなどがユースケースとしてハマりやすいのかなと感じていました。 ワイ
Tips2:エージェントの設計単位について考える 20
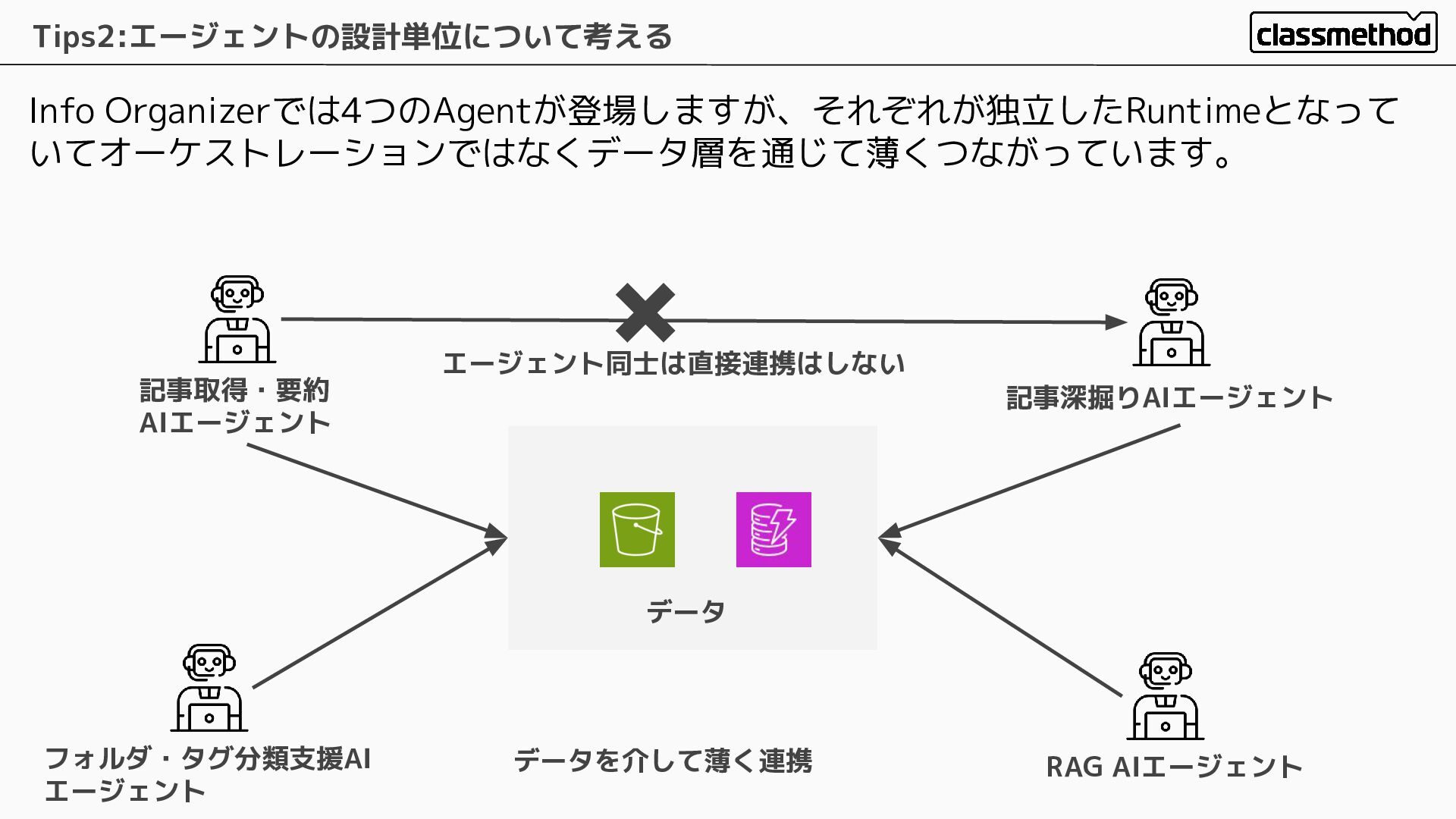
Info Organizerでは4つのAgentが登場しますが、それぞれが独立したRuntimeとなって いてオーケストレーションではなくデータ層を通じて薄くつながっています。 Tips2:エージェントの設計単位について考える 記事取得・要約 AIエージェント 記事深掘りAIエージェント フォルダ・タグ分類支援AI エージェント RAG
AIエージェント データ データを介して薄く連携 エージェント同士は直接連携はしない ✖
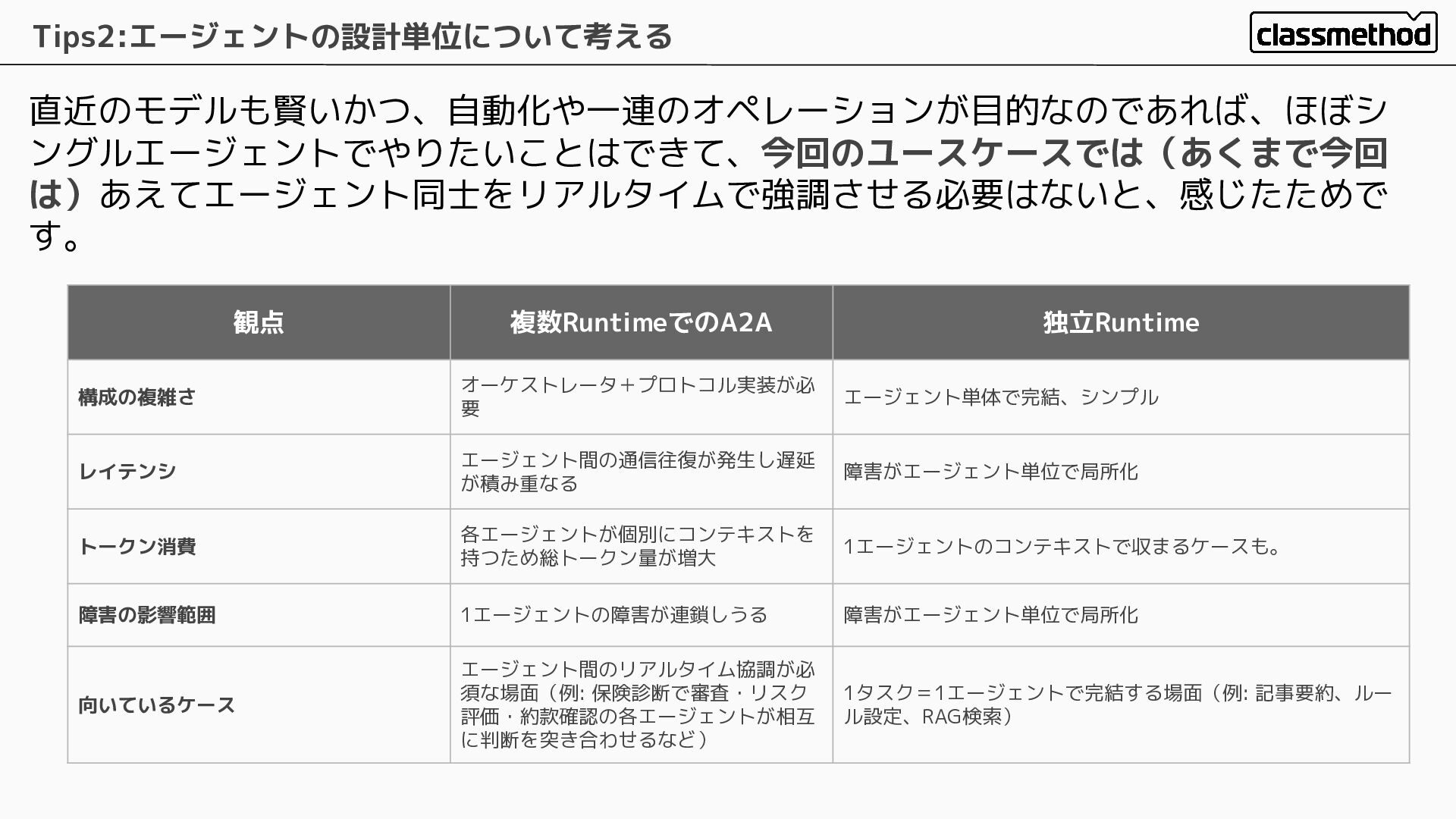
直近のモデルも賢いかつ、自動化や一連のオペレーションが目的なのであれば、ほぼシ ングルエージェントでやりたいことはできて、今回のユースケースでは(あくまで今回 は)あえてエージェント同士をリアルタイムで強調させる必要はないと、感じたためで す。 Tips2:エージェントの設計単位について考える 観点 複数RuntimeでのA2A 独立Runtime 構成の複雑さ オーケストレータ+プロトコル実装が必
要 エージェント単体で完結、シンプル レイテンシ エージェント間の通信往復が発生し遅延 が積み重なる 障害がエージェント単位で局所化 トークン消費 各エージェントが個別にコンテキストを 持つため総トークン量が増大 1エージェントのコンテキストで収まるケースも。 障害の影響範囲 1エージェントの障害が連鎖しうる 障害がエージェント単位で局所化 向いているケース エージェント間のリアルタイム協調が必 須な場面(例: 保険診断で審査・リスク 評価・約款確認の各エージェントが相互 に判断を突き合わせるなど) 1タスク=1エージェントで完結する場面(例: 記事要約、ルー ル設定、RAG検索)
ポイント:ポイント: 無理にマルチエージェントを意識していないか。 要件によってはAWSではシンプルにシングルエージェント、もしくは1Runtime内で、 Agent As ToolsやSwarmなどの方がまだ収まりが良いかと思う。A2Aはレイテンシ・ トークン消費・障害連鎖のコストを考慮した上でリアルタイム協調が必要なケースに採用 したい。 23 できるだけシンプルに考えたいですね!
本当にエージェント同士が会話する必要がある か?を最初に問いたいところですね。 A2Aって近未来的なロマンはありますが・・・ ワイ
Tips3:Knowledege Bases Direct Ingestion 24
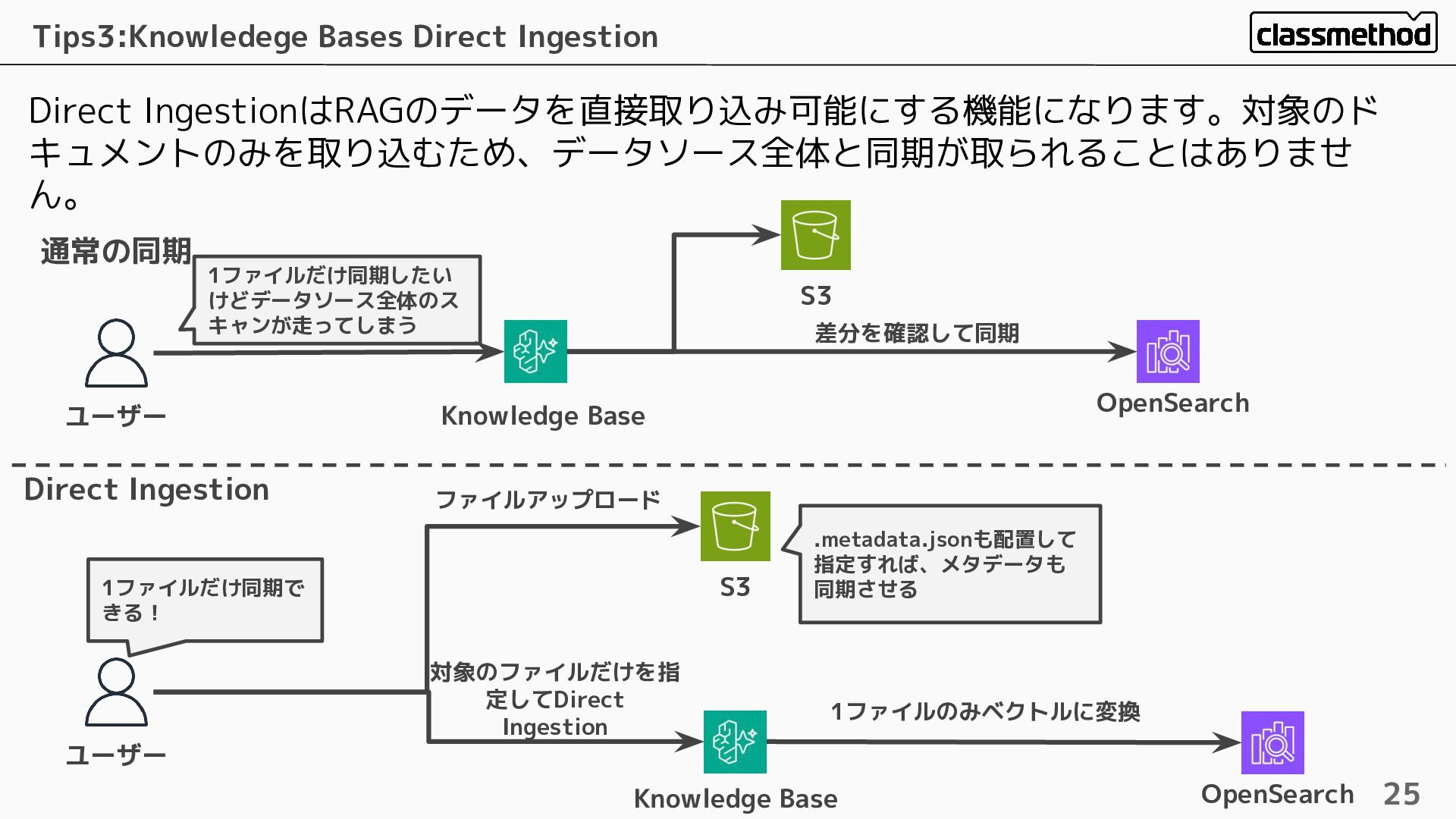
Direct IngestionはRAGのデータを直接取り込み可能にする機能になります。対象のド キュメントのみを取り込むため、データソース全体と同期が取られることはありませ ん。 Tips3:Knowledege Bases Direct Ingestion 25 ユーザー
1ファイルだけ同期で きる! S3 Knowledge Base OpenSearch ファイルアップロード 対象のファイルだけを指 定してDirect Ingestion 1ファイルのみベクトルに変換 Direct Ingestion 通常の同期 ユーザー 1ファイルだけ同期したい けどデータソース全体のス キャンが走ってしまう Knowledge Base S3 OpenSearch 差分を確認して同期 .metadata.jsonも配置して 指定すれば、メタデータも 同期させる
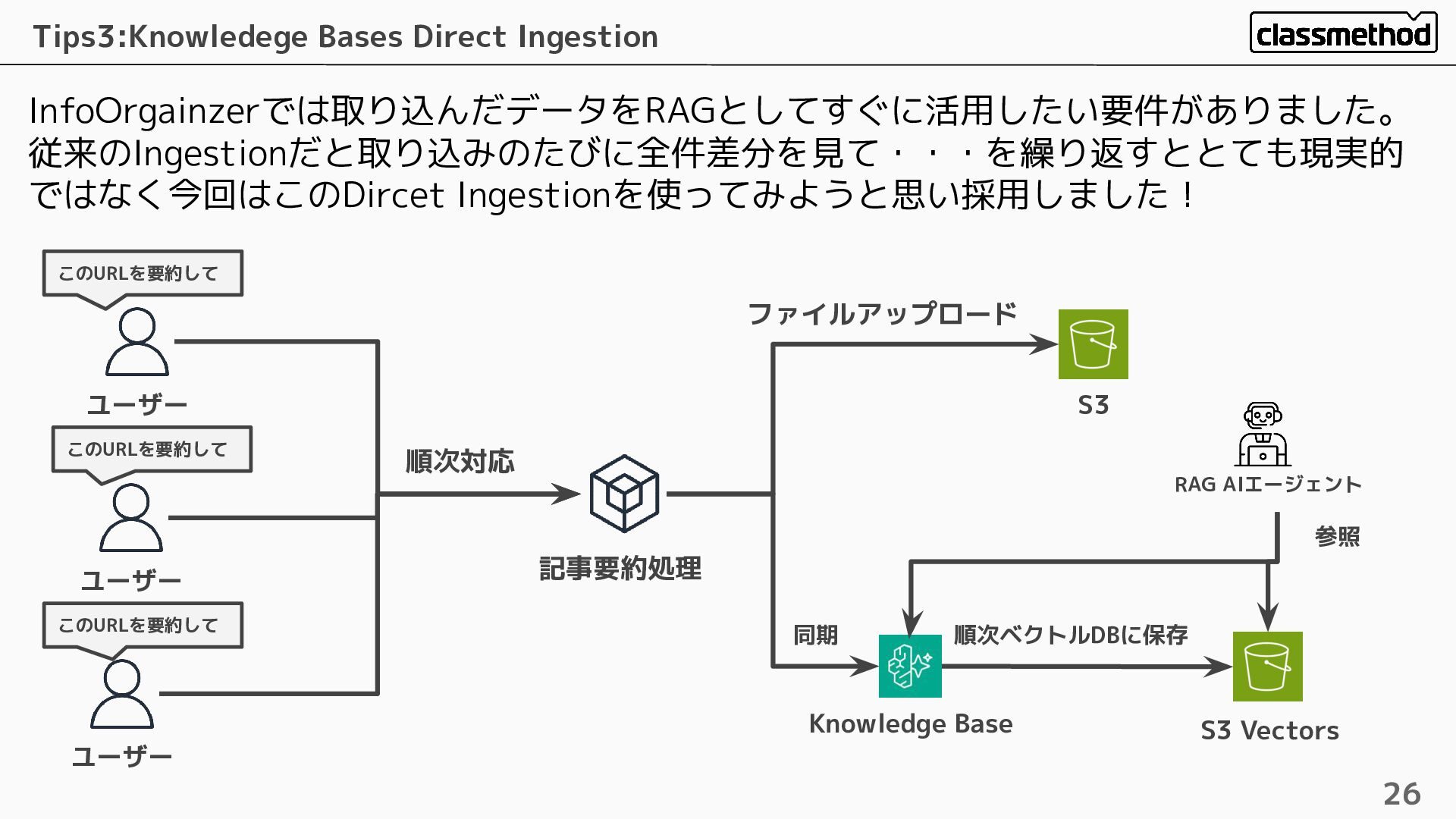
InfoOrgainzerでは取り込んだデータをRAGとしてすぐに活用したい要件がありました。 従来のIngestionだと取り込みのたびに全件差分を見て・・・を繰り返すととても現実的 ではなく今回はこのDircet Ingestionを使ってみようと思い採用しました! Tips3:Knowledege Bases Direct Ingestion 26 ユーザー
記事要約処理 ユーザー このURLを要約して このURLを要約して ユーザー このURLを要約して Knowledge Base S3 S3 Vectors 順次対応 ファイルアップロード 順次ベクトルDBに保存 同期 RAG AIエージェント 参照
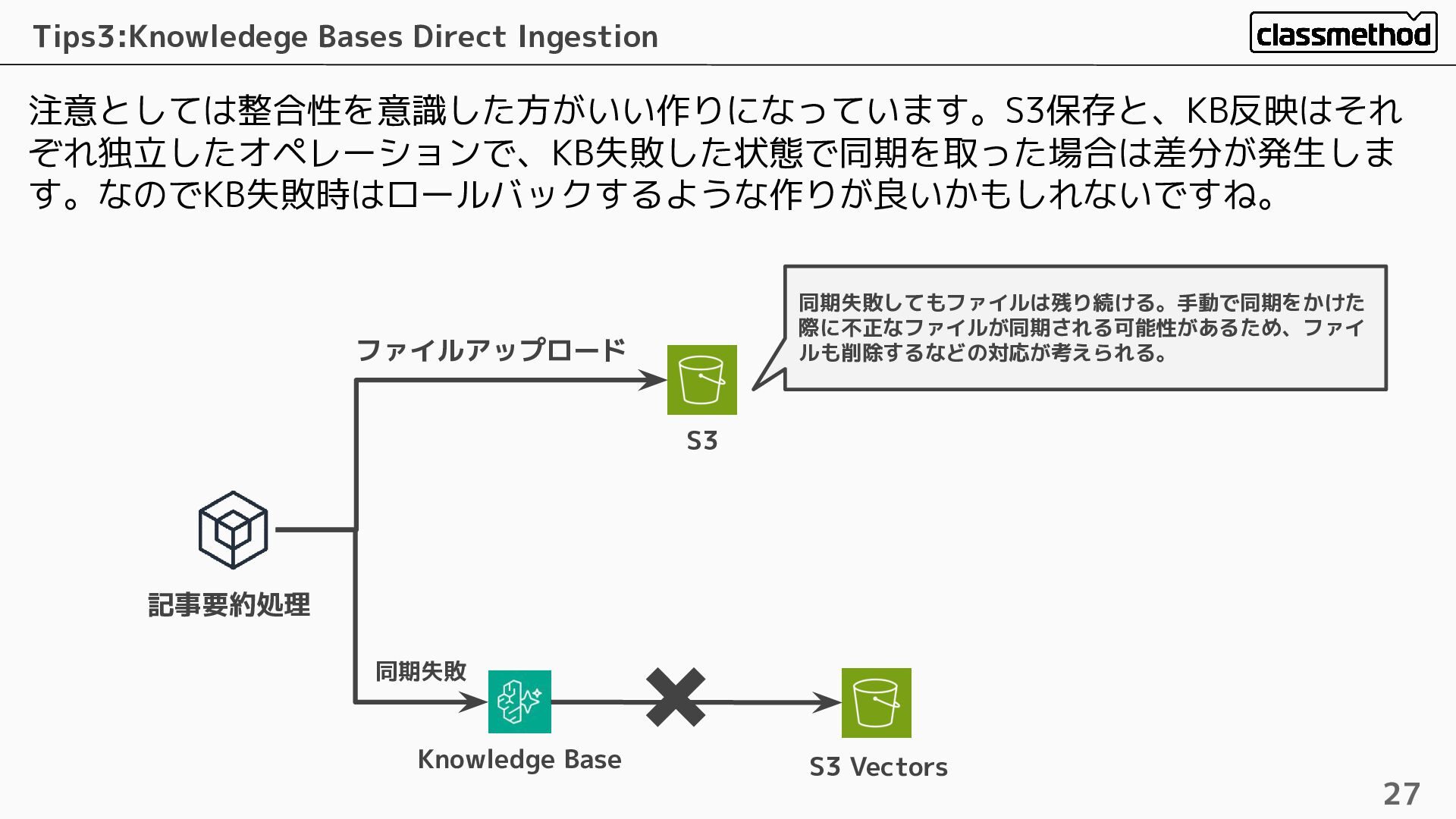
注意としては整合性を意識した方がいい作りになっています。S3保存と、KB反映はそれ ぞれ独立したオペレーションで、KB失敗した状態で同期を取った場合は差分が発生しま す。なのでKB失敗時はロールバックするような作りが良いかもしれないですね。 Tips3:Knowledege Bases Direct Ingestion 27 記事要約処理 Knowledge
Base S3 S3 Vectors ファイルアップロード 同期失敗 ✖ 同期失敗してもファイルは残り続ける。手動で同期をかけた 際に不正なファイルが同期される可能性があるため、ファイ ルも削除するなどの対応が考えられる。
ポイント:ファイルを絶えず更新するようなシナリオだとDirect Ingestionが良さそうですね!!エラー時は整合性が崩れないよう意識 するのも大事ですね。 28 最初どうやって同期(オンラインバッチとかを考 えていた)しようかと思ったけど、Direct Ingestion機能があってよかったよ・・・ ワイ
Tips4:AgentCore Memoryの長期記憶の話 29
皆様はAgentCore Memoryの長期記憶をどのように呼び出していますでしょうか。一番 簡単に実装できるのはStrands AgentsのSession Managerかと思います。 Tips4:AgentCore Memoryの長期記憶の話 30 • MemoryID、SessionID、ActorIDの設
定をしてセッションマネージャーを作成 し、Agentの引数に設定すればMemory と連携可能
どういった実装になっているのかもう少し深掘りしてみます。Strands Agentsの Session Managerで自動で取得した長期記憶はユーザープロンプトに埋め込まれます。 下記のようなイメージです。 Tips4:AgentCore Memoryの長期記憶の話 31 <user_context>タグで初回に取得した長 期記憶がユーザープロンプトとして設定さ
れている
先述したように機械的にユーザープロンプトに埋め込まれるので、処理を実装しなくて 良いので便利な反面、たまに変に長期記憶が最初から記憶されて悪さするケースもあっ たので、シチュエーションによって長期記憶を活用したいケースは、そのシチュエー ションになって初めて取得するようなツールとして活用するのも手かなと感じました。 Tips4:AgentCore Memoryの長期記憶の話 32 ユーザーの好みが必要であると判 断された場合のみ長期記憶を取得
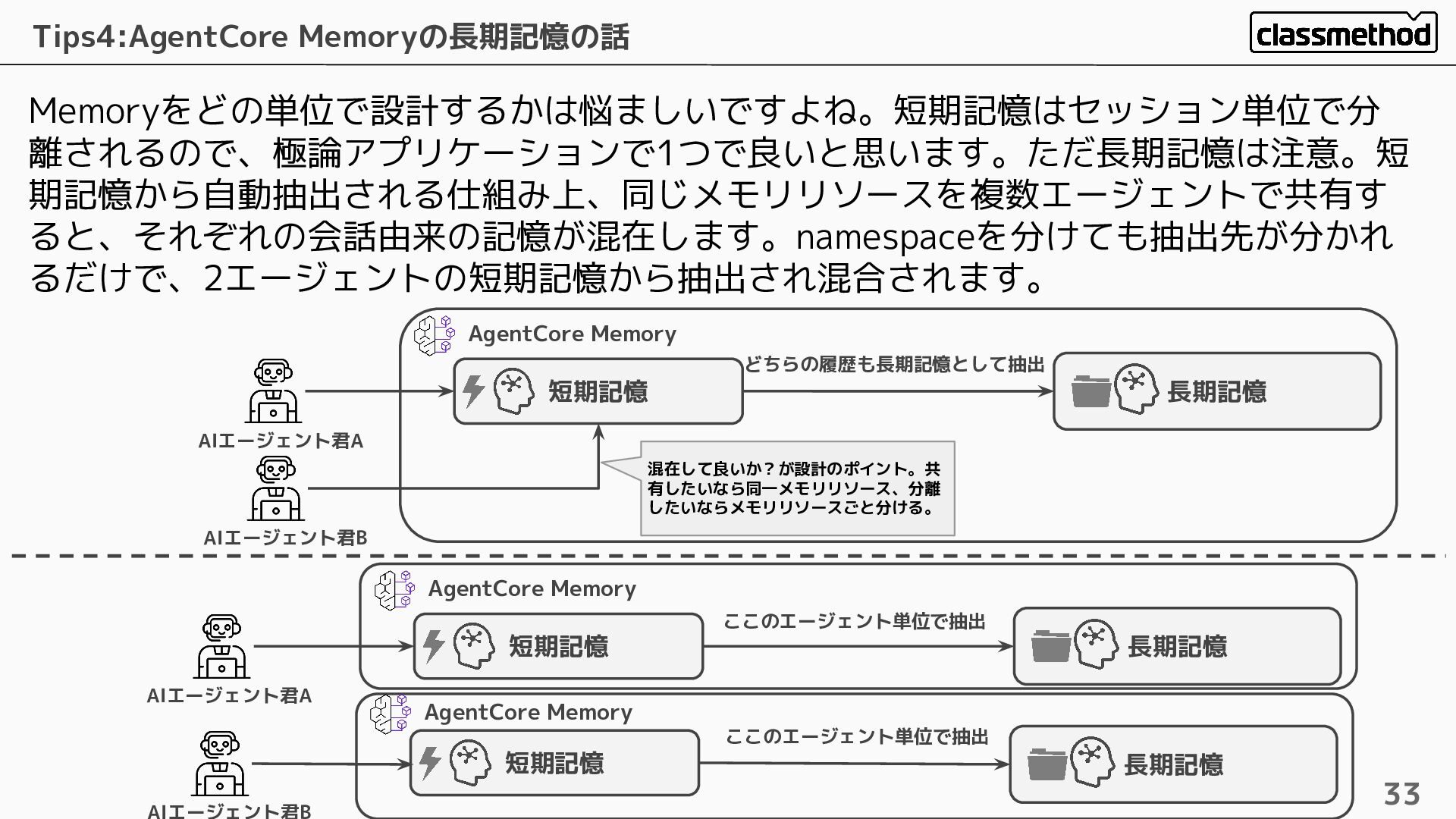
Memoryをどの単位で設計するかは悩ましいですよね。短期記憶はセッション単位で分 離されるので、極論アプリケーションで1つで良いと思います。ただ長期記憶は注意。短 期記憶から自動抽出される仕組み上、同じメモリリソースを複数エージェントで共有す ると、それぞれの会話由来の記憶が混在します。namespaceを分けても抽出先が分かれ るだけで、2エージェントの短期記憶から抽出され混合されます。 Tips4:AgentCore Memoryの長期記憶の話 33 長期記憶 短期記憶
AIエージェント君A AIエージェント君B 混在して良いか?が設計のポイント。共 有したいなら同一メモリリソース、分離 したいならメモリリソースごと分ける。 どちらの履歴も長期記憶として抽出 AgentCore Memory 長期記憶 短期記憶 AIエージェント君A AIエージェント君B ここのエージェント単位で抽出 AgentCore Memory 長期記憶 短期記憶 AgentCore Memory ここのエージェント単位で抽出
ポイント:Session Managerの自動埋め込みは手軽だが、長期記憶が意 図せぬタイミングで入ってきてノイズになる可能性もある。ユース ケースに応じて使い分けを意識したい。 34 良かれと思って実装した、Session Managerで取得した長期記憶が たまーによくない方向に・・・ユースケースに応じて取得方法は考 えたいですね。使うモデルによっては取得しているのにうまく解釈 してくれないこともあったよ。
ワイ
Tips5:Guardrailsの小ネタ 35
Amazon Bedrock Guardrailsをアプリケーションに組み込んでインプット・アウトプッ トをコントロールしたいケースはあると思います。 Tips5:Guardrailsの小ネタ 36 Amazon Bedrock with Guardrails
ユーザー/ アプリケーション !$?!@!@#@@ (不適切なコンテンツ) ガードレールによってブ ロックされました • コンテンツフィルター ◦ ヘイト、侮辱、性的、暴力、不正行為、プロンプトアタック などの有害コンテンツをテキスト・画像の両方で検出・ブ ロック • 拒否トピック ◦ 特定のトピック(話題)を定義してブロック • ワードフィルター ◦ カスタムの単語やフレーズを定義してブロック • 機密情報フィルター ◦ PII(個人識別情報)などの機密情報をブロックまたはマスク • コンテキストグラウンディングチェック ◦ ソース情報に基づかないハルシネーションを検出・フィルタ リング • 自動推論チェック(プレビュー) ◦ 論理ルールに基づいてモデル応答の正確性を検証し、事実誤 認を防止 Guardrailsの主な機能
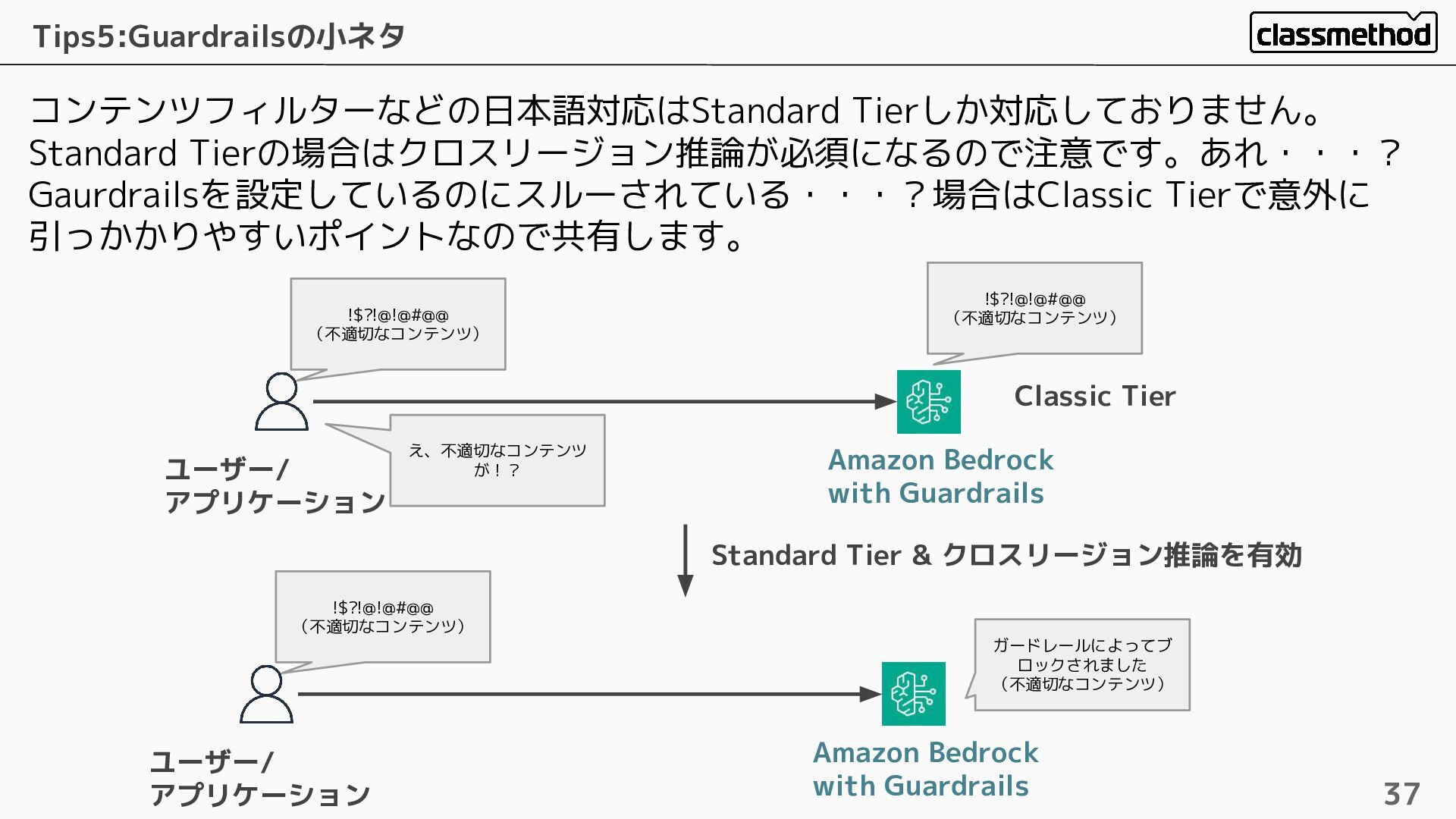
コンテンツフィルターなどの日本語対応はStandard Tierしか対応しておりません。 Standard Tierの場合はクロスリージョン推論が必須になるので注意です。あれ・・・? Gaurdrailsを設定しているのにスルーされている・・・?場合はClassic Tierで意外に 引っかかりやすいポイントなので共有します。 Tips5:Guardrailsの小ネタ 37 Amazon
Bedrock with Guardrails ユーザー/ アプリケーション !$?!@!@#@@ (不適切なコンテンツ) !$?!@!@#@@ (不適切なコンテンツ) え、不適切なコンテンツ が!? Standard Tier & クロスリージョン推論を有効 Amazon Bedrock with Guardrails ユーザー/ アプリケーション !$?!@!@#@@ (不適切なコンテンツ) ガードレールによってブ ロックされました (不適切なコンテンツ) Classic Tier
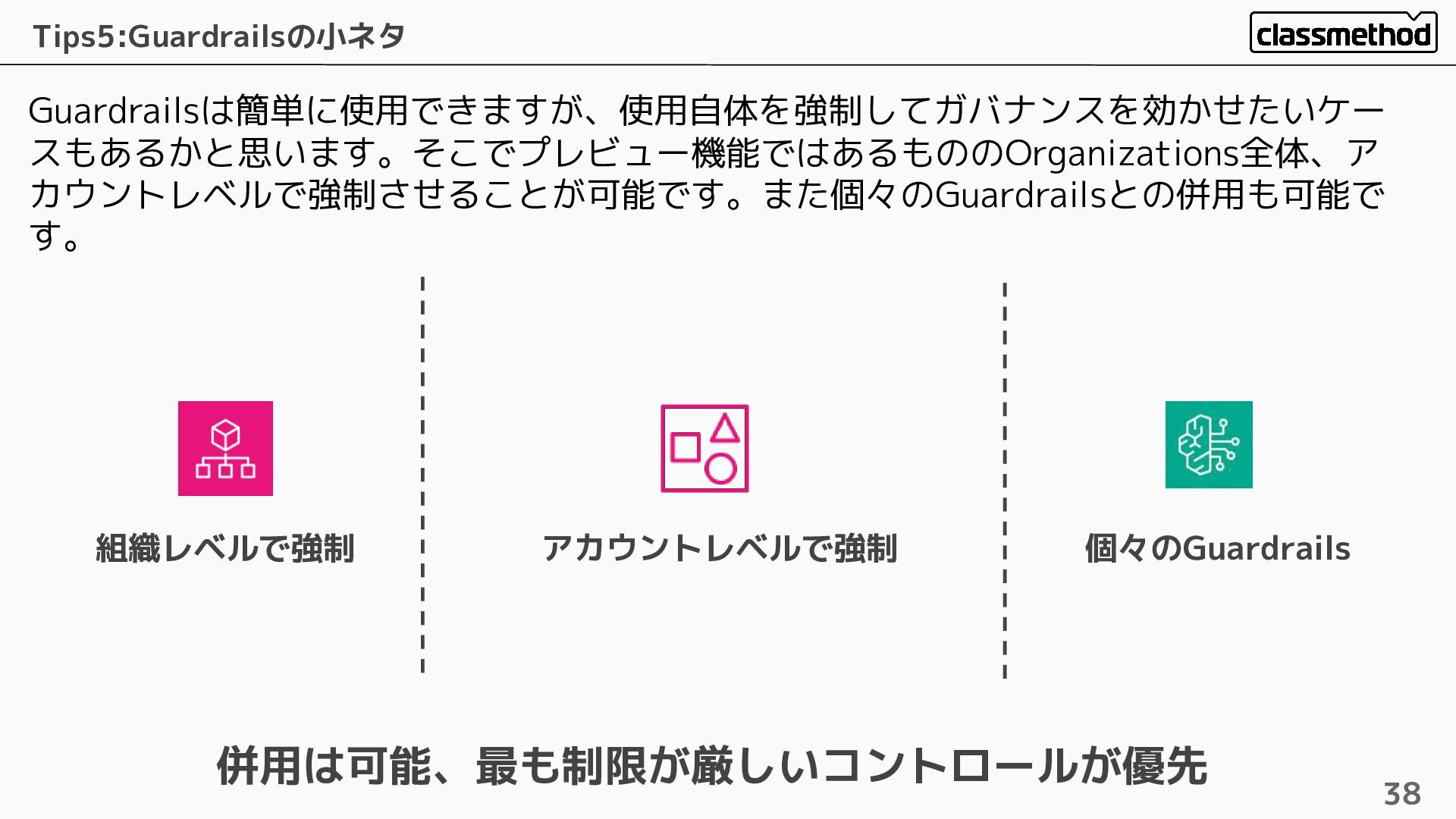
Guardrailsは簡単に使用できますが、使用自体を強制してガバナンスを効かせたいケー スもあるかと思います。そこでプレビュー機能ではあるもののOrganizations全体、ア カウントレベルで強制させることが可能です。また個々のGuardrailsとの併用も可能で す。 Tips5:Guardrailsの小ネタ 38 組織レベルで強制 アカウントレベルで強制 個々のGuardrails 併用は可能、最も制限が厳しいコントロールが優先
Tips6:体験について 39
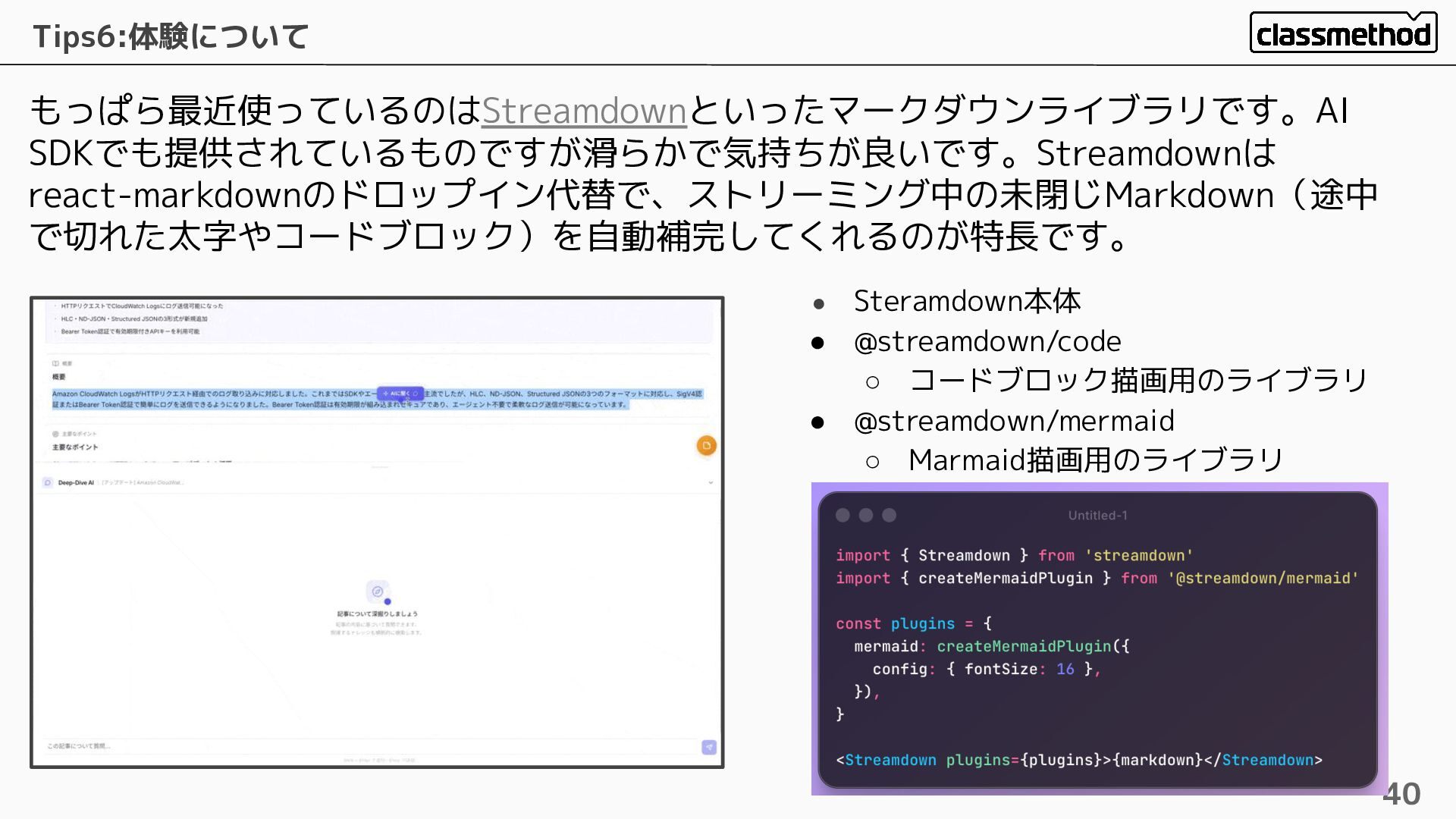
もっぱら最近使っているのはStreamdownといったマークダウンライブラリです。AI SDKでも提供されているものですが滑らかで気持ちが良いです。Streamdownは react-markdownのドロップイン代替で、ストリーミング中の未閉じMarkdown(途中 で切れた太字やコードブロック)を自動補完してくれるのが特長です。 Tips6:体験について 40 • Steramdown本体 • @streamdown/code
◦ コードブロック描画用のライブラリ • @streamdown/mermaid ◦ Marmaid描画用のライブラリ
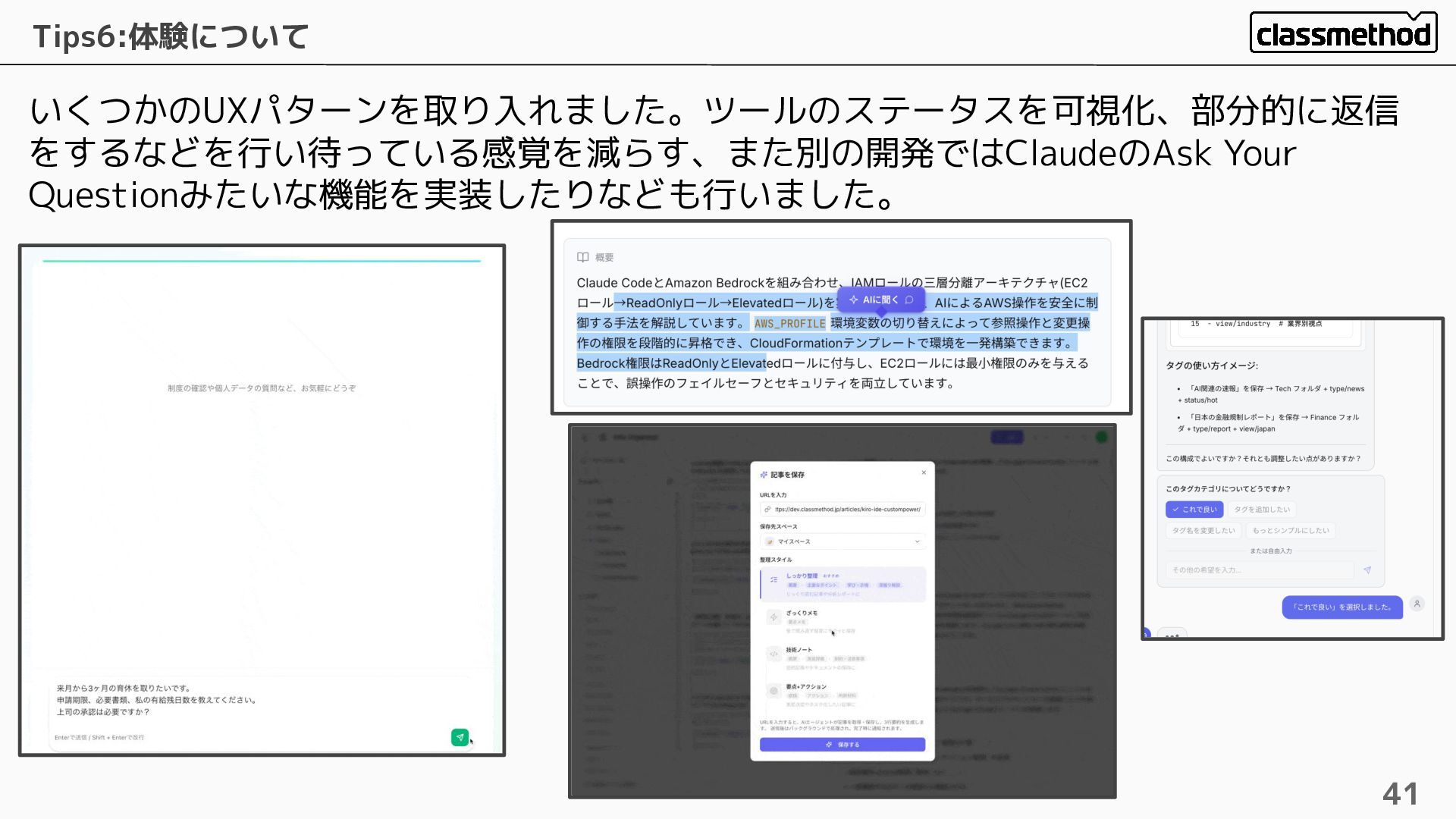
いくつかのUXパターンを取り入れました。ツールのステータスを可視化、部分的に返信 をするなどを行い待っている感覚を減らす、また別の開発ではClaudeのAsk Your Questionみたいな機能を実装したりなども行いました。 Tips6:体験について 41
ポイント: AIエージェントのUI/UXは単純なテキスト生成だけではな い。ストリーミング表示(Streamdown)、ツール実行中のステップ可 視化、 選択式UIなど工夫する余地がたくさんある。触ることが癖になる のを目標とし、要約するのが楽しい!と思わせたい・・・!ただロジッ クの複雑さとのトレードオフなのでどこまでを工夫するかは考える必要 がある。 42 体験やデザインって難しいですよね。できるだけ満足してもらえるように作り
込んでいますが、客観的に判断するのは難しいので色々な人に触ってもらって FBもらうようにしています。またロジックの複雑さとのトレードオフでもあ るので本当に悩ましい・・・ ワイ
終わりに 43
ご清聴ありがとうございました!!! 今回お話しした内容は実際に開発する中での一部気づきをまとめたものです。 もしかすると簡単な話だったかもしれません。 もっとこういったやり方があるよとか、この辺の工夫はどうしたらいいのかなどあれば ぜひお気軽に教えてください!!皆さんでAIエージェントを”構築”する知見を広めてい きましょう!! ありがとうございましたー!! ありがとうございました 44
Thank you!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}