Vision Language Modelと自動運転AIの最前線
VLMは視覚と言語を統合学習した生成AIで、物理世界の状況把握を支え、自動運転やロボティクスなどの応用の要となりつつあります。このランチョンセミナーでは、VLMの学習、現実世界へのアクションとの融合、世界モデルを含む自動運転に関連した最新研究をわかりやすく紹介します。
2025/7/30 12:25~ のスポンサーセッションの投影資料です
https://cvim.ipsj.or.jp/MIRU2025/sponsor-events.html
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![DAVE-2 [Bojarski+ 2016] NVIDIAが⾃動⾞⽤SoCを開発、CNNを30fpsで動かし⾃動運転を実現 72時間のデータを収集し、10マイルを⼿放しで運転することに成功 データ収集システムの概要 (NVIDIA DrivePXは24TOPS) www.youtube.com/watch?v=NJU9ULQUwng 10](https://files.speakerdeck.com/presentations/11d39472465b46d1a18cb94c610b0772/slide_9.jpg){kind=link}
![UniAD [Hu+ 2023] カメラのみから車の制御までを End-to-Endで学習するフレームワーク。 PerceptionやPredictionで個別の機能やマルチタスクにするのではなく、各モジュー ルを同時に最適化する。CVPR2023 Best Paperに選出。 11](https://files.speakerdeck.com/presentations/11d39472465b46d1a18cb94c610b0772/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![第3世代の⾃動運転タスク (2023~) 深層学習ベースの自動運転の学習データは、大規模生成 AIをターゲットとした 自然言語による状況理解 に移行しつつある [Li+ 2024] 第1世代 (CNN,](https://files.speakerdeck.com/presentations/11d39472465b46d1a18cb94c610b0772/slide_16.jpg){kind=link}
{kind=link}
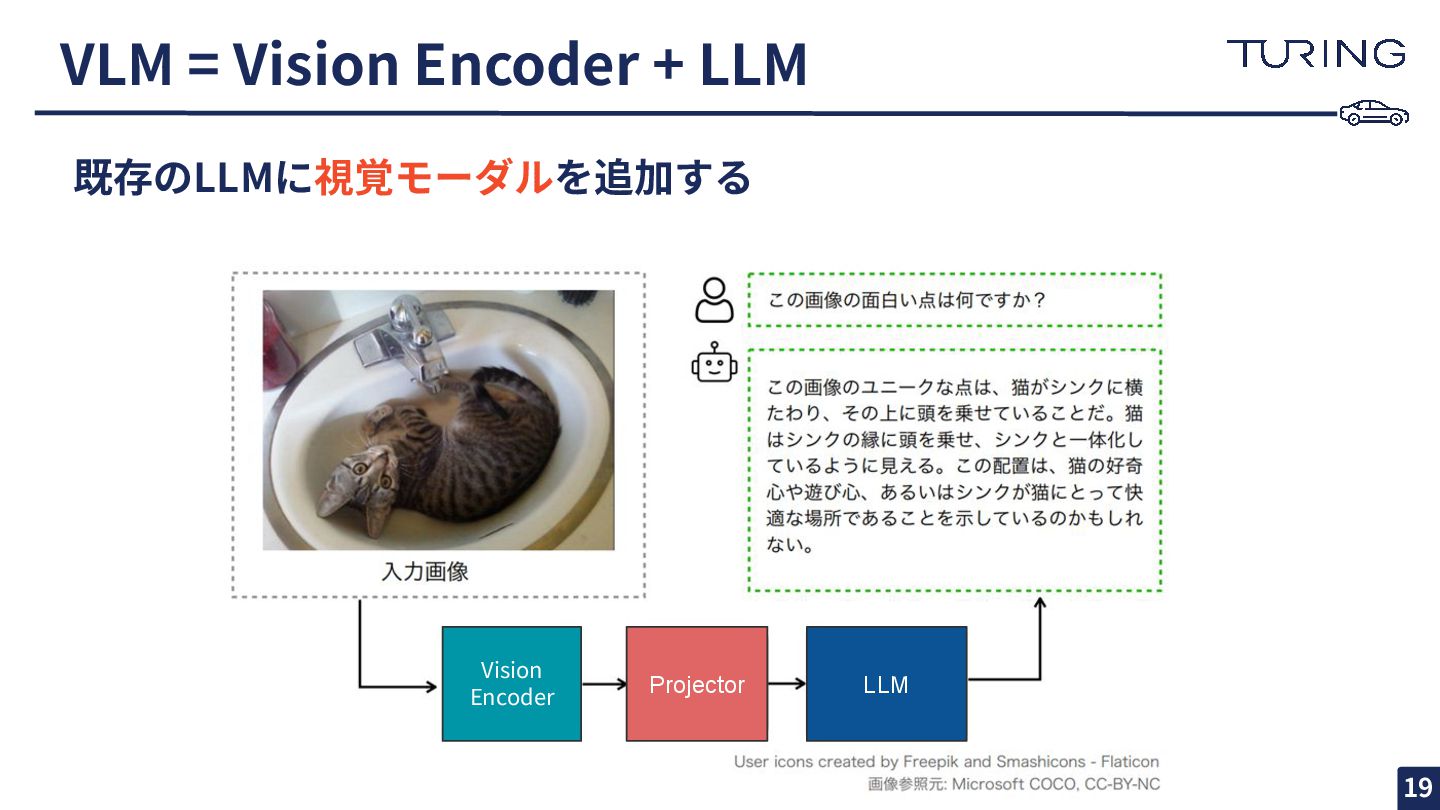{kind=link}
![Flamingo [Alayac+ 2022] 画像‧動画とテキストが⾃由に混在した シーケンスをそのまま⼊⼒でき、 few-shotだけで多様なマルチモーダル課題 に適応 • Image encoder](https://files.speakerdeck.com/presentations/11d39472465b46d1a18cb94c610b0772/slide_19.jpg){kind=link}
![LLaVA [Liu+ 2023] ⾼品質の指⽰チューニングデータを画像- ⾔語タスクに適⽤することで⾼い性能を 達成 • 指⽰チューニングデータ ◦ COCO](https://files.speakerdeck.com/presentations/11d39472465b46d1a18cb94c610b0772/slide_20.jpg){kind=link}
![インターリーブされた画像-テキストの⽣成が可能 画像‧テキストが混在したデータに対して、⼀貫した理解が可能 Chameleon [C Team+ 2024] Team, Chameleon. "Chameleon: Mixed-modal](https://files.speakerdeck.com/presentations/11d39472465b46d1a18cb94c610b0772/slide_21.jpg){kind=link}
![LingoQA [Marcu+ 2023] 質疑応答フレームワークを使ったVLMによる交通環境における理解と意思決定 Marcu, Ana-Maria, et al. "Lingoqa: Video](https://files.speakerdeck.com/presentations/11d39472465b46d1a18cb94c610b0772/slide_22.jpg){kind=link}
![RT-2 [Brohan+ 2023] 事前学習されたVLMをロボットアームのアクションデータでFT Zitkovich, Brianna, et al. "Rt-2: Vision-language-action](https://files.speakerdeck.com/presentations/11d39472465b46d1a18cb94c610b0772/slide_23.jpg){kind=link}
![LMDrive [Shao+ 2023] 25 ⾔語モデルを使ったEnd-to-End⾃動運転を実現 CARLAシミュレータ上で⾛⾏可能 Shao, Hao, et al. “LMDrive: Closed‑Loop End‑to‑End Driving with Large Language Models.” arXiv preprint arXiv:2312.07488 (2023).](https://files.speakerdeck.com/presentations/11d39472465b46d1a18cb94c610b0772/slide_24.jpg){kind=link}
![DriveVLM [Tian+ 2024] VLMによる⻑期計画をもとに経路を補正する 従来の⾃動運転パイプラインを⾼頻度で動かし、リアルタイム性を確保 26 Tian, Xiaoyu, et al. “DriveVLM: The Convergence of Autonomous Driving and Large Vision‑L anguage Models.” arXiv preprint arXiv:2402.12289 (2024).](https://files.speakerdeck.com/presentations/11d39472465b46d1a18cb94c610b0772/slide_25.jpg){kind=link}
![SimLingo [Renz+ 2025] 視覚-⾔語-⾏動モデルをシミュレータ特化で学習 CARLA Leaderboard 2.0‧Bench2Driveで SOTA、CARLA Challenge 2024 優勝 27 Renz, Katrin, et al. “SimLingo: Vision‑Only Closed‑Loop Autonomous Driving with Language‑Action Alignment.” arXiv preprint arXiv:2503.09594 (2025).](https://files.speakerdeck.com/presentations/11d39472465b46d1a18cb94c610b0772/slide_26.jpg){kind=link}
{kind=link}
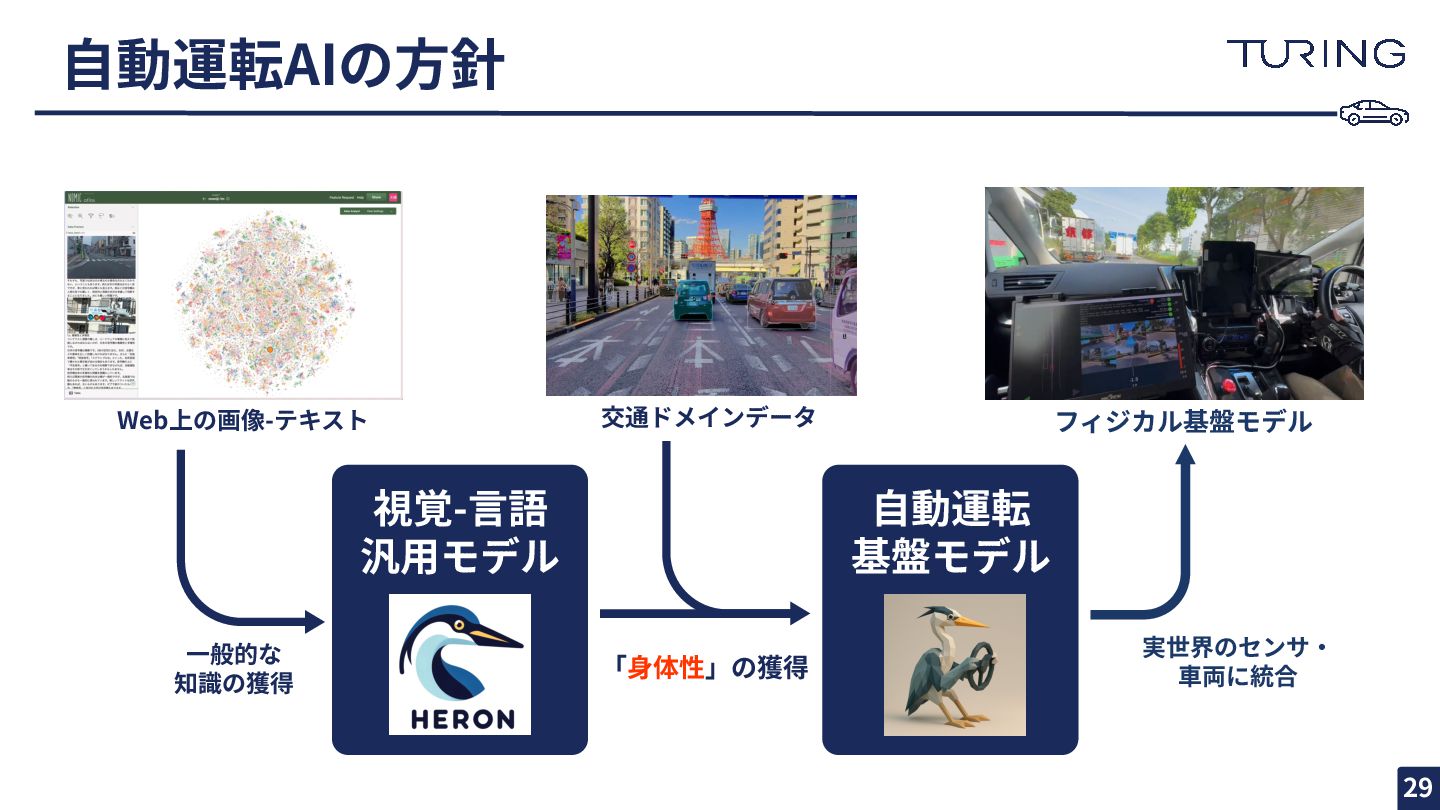{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
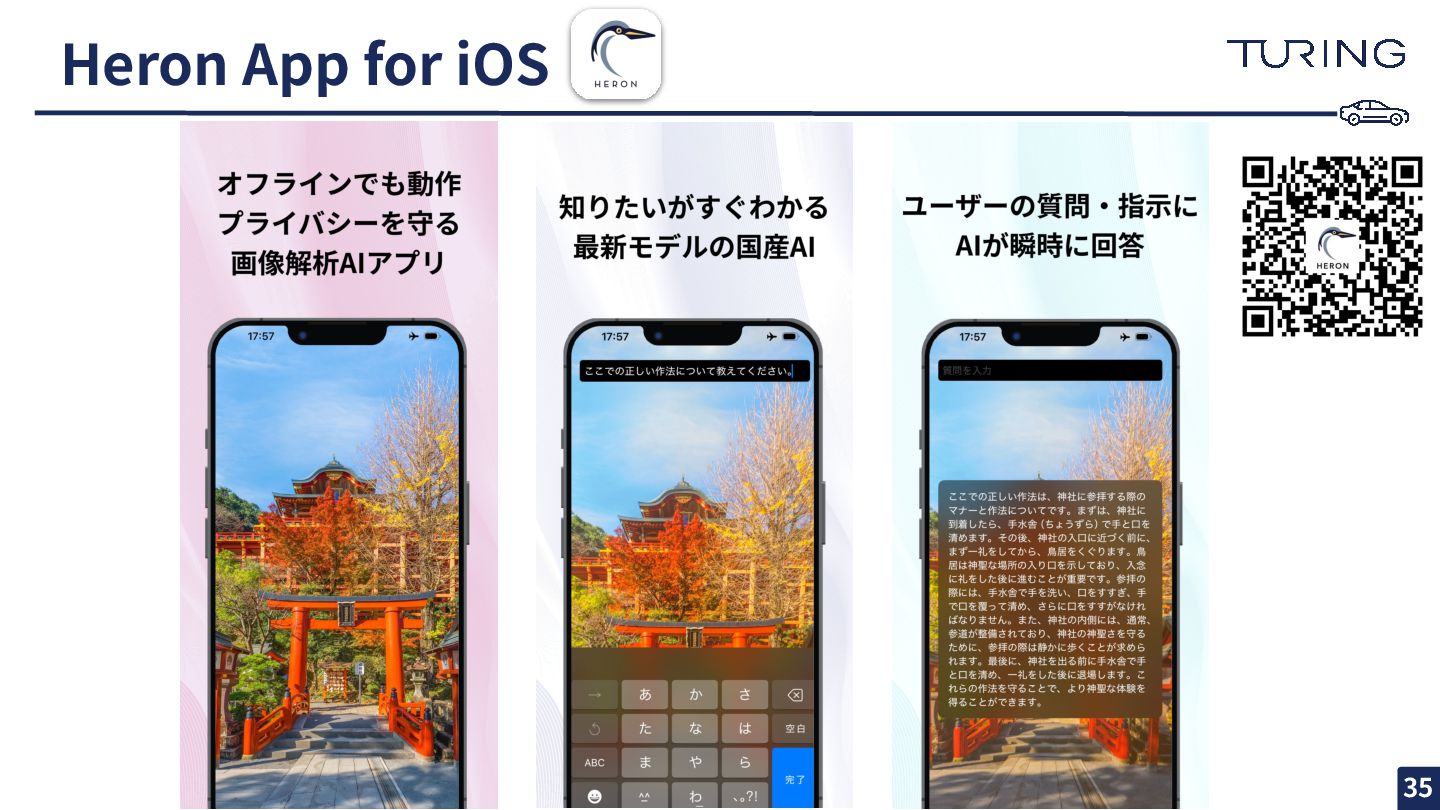{kind=link}
{kind=link}
{kind=link}
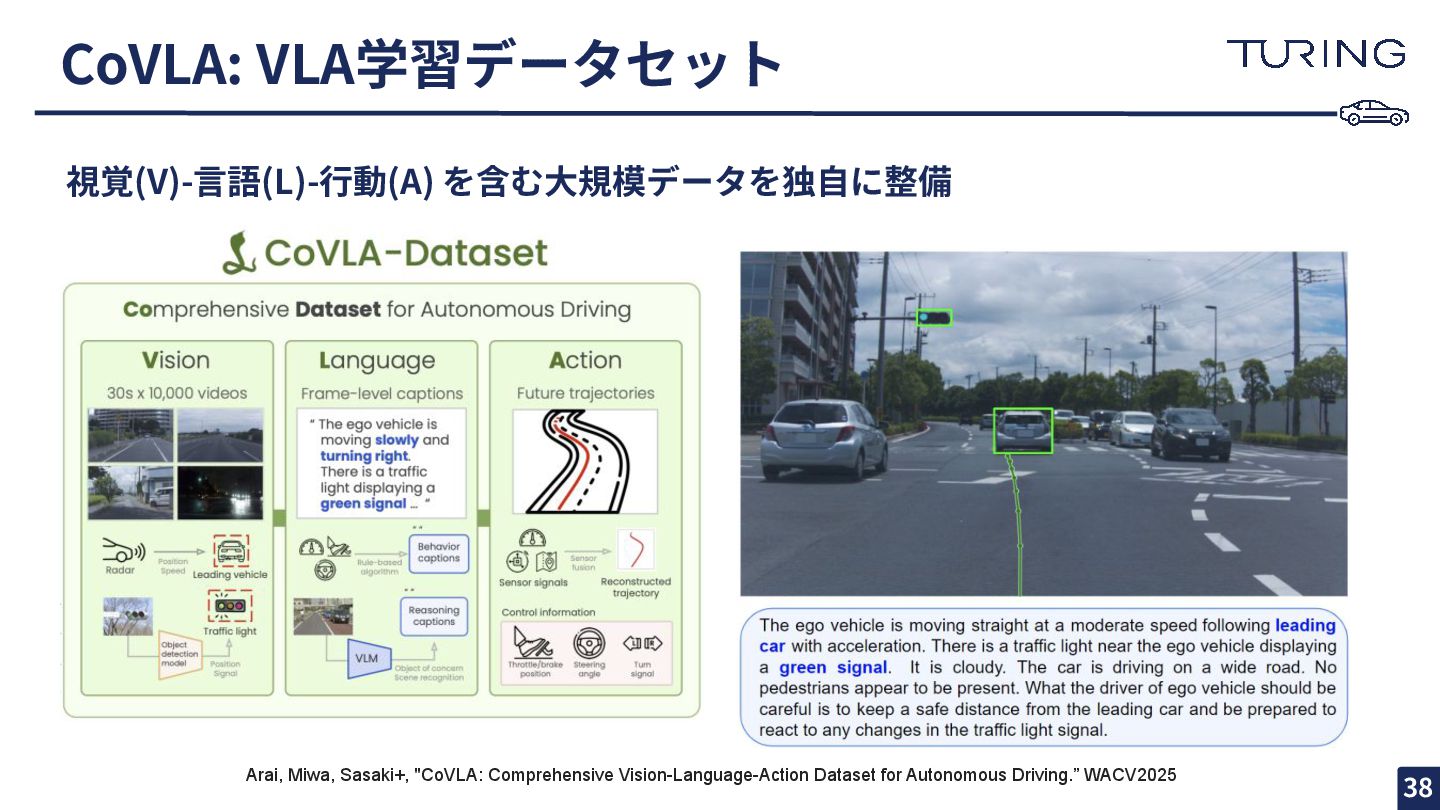{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}