◦ GPGPUのための並列計算プラット フォーム/プログラミングモデル ◦ C/C++拡張として書く ◦ GPUを数千~数万スレッド単位で 同時実⾏できる ◦ nvccでコンパイルして実⾏ ⼈類の99%はバージョン確認にしか使っていないが、 nvccは本来はCUDAコンパイラ → 1.894 ms (x186000 倍) ※ L4x4で⾮同期&最適化 #include <cuda_runtime.h> … __global__ void mandelbrot_kernel_u16( uint16_t* __restrict__ out, int width, int hSeg, int yOffset, float xmin, float ymin, float dx, float dy, int max_iter ) { const int x = blockDim.x * blockIdx.x + threadIdx.x; const int yLocal = blockDim.y * blockIdx.y + threadIdx.y; const bool inBounds = (x < width) & (yLocal < hSeg); const int y = yOffset + yLocal; // 画素の複素数 c = (cx, cy) float cx = xmin + x * dx; float cy = ymin + y * dy; … // kernel実行とhostへの非同期コピー CK(cudaEventRecord(g[i].evStart, g[i].stream)); mandelbrot_kernel_u16<<<grid, block, 0, g[i].stream>>>( g[i].d_out, width, g[i].hSeg, g[i].yOffset, xmin, ymin, dx, dy, max_iter ); CK(cudaEventRecord(g[i].evStop, g[i].stream)); CK(cudaMemcpyAsync( h_out + static_cast<size_t>(g[i].yOffset) * width, g[i].d_out, sizeof(uint16_t) * width * g[i].hSeg, cudaMemcpyDeviceToHost, g[i].stream ));
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
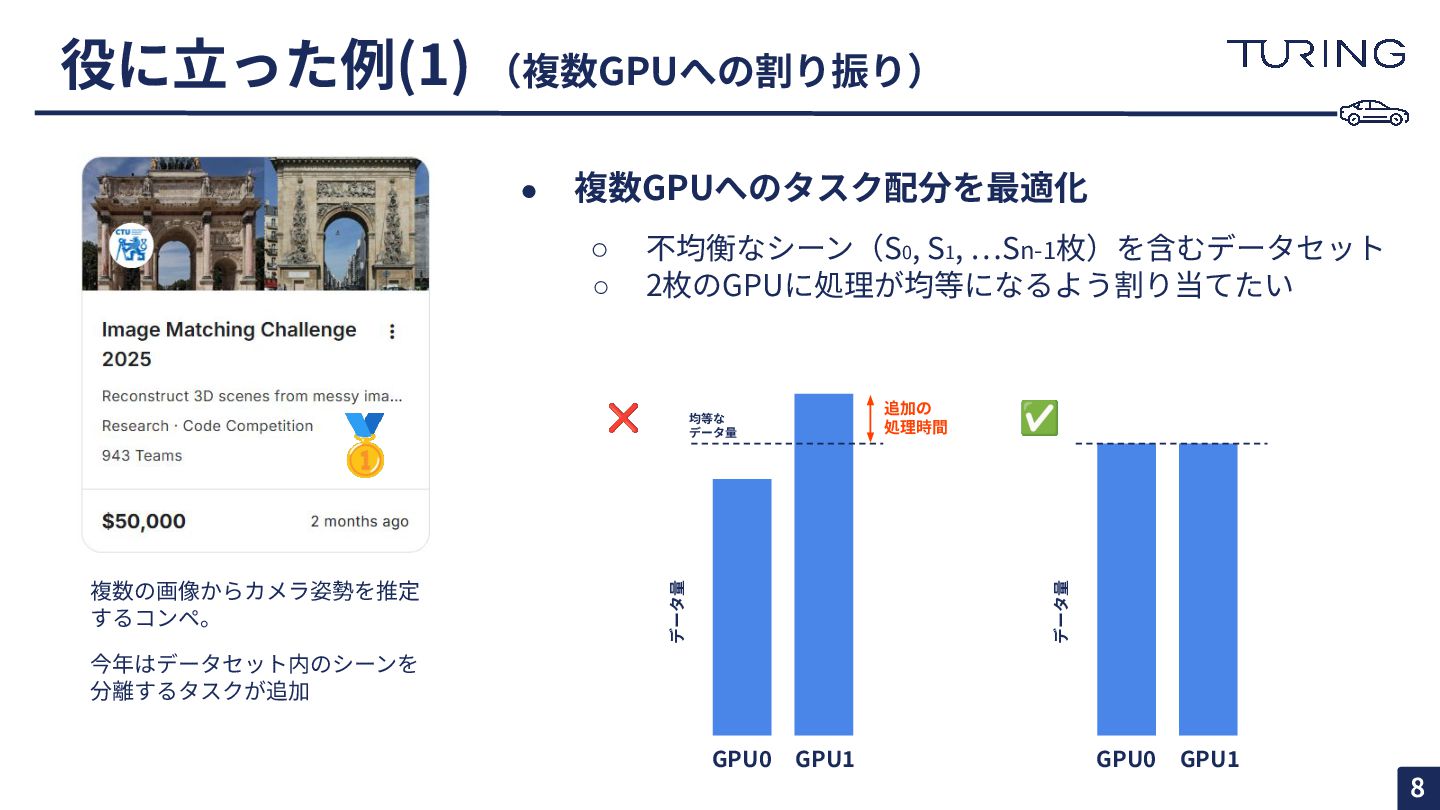{kind=link}
{kind=link}
{kind=link}
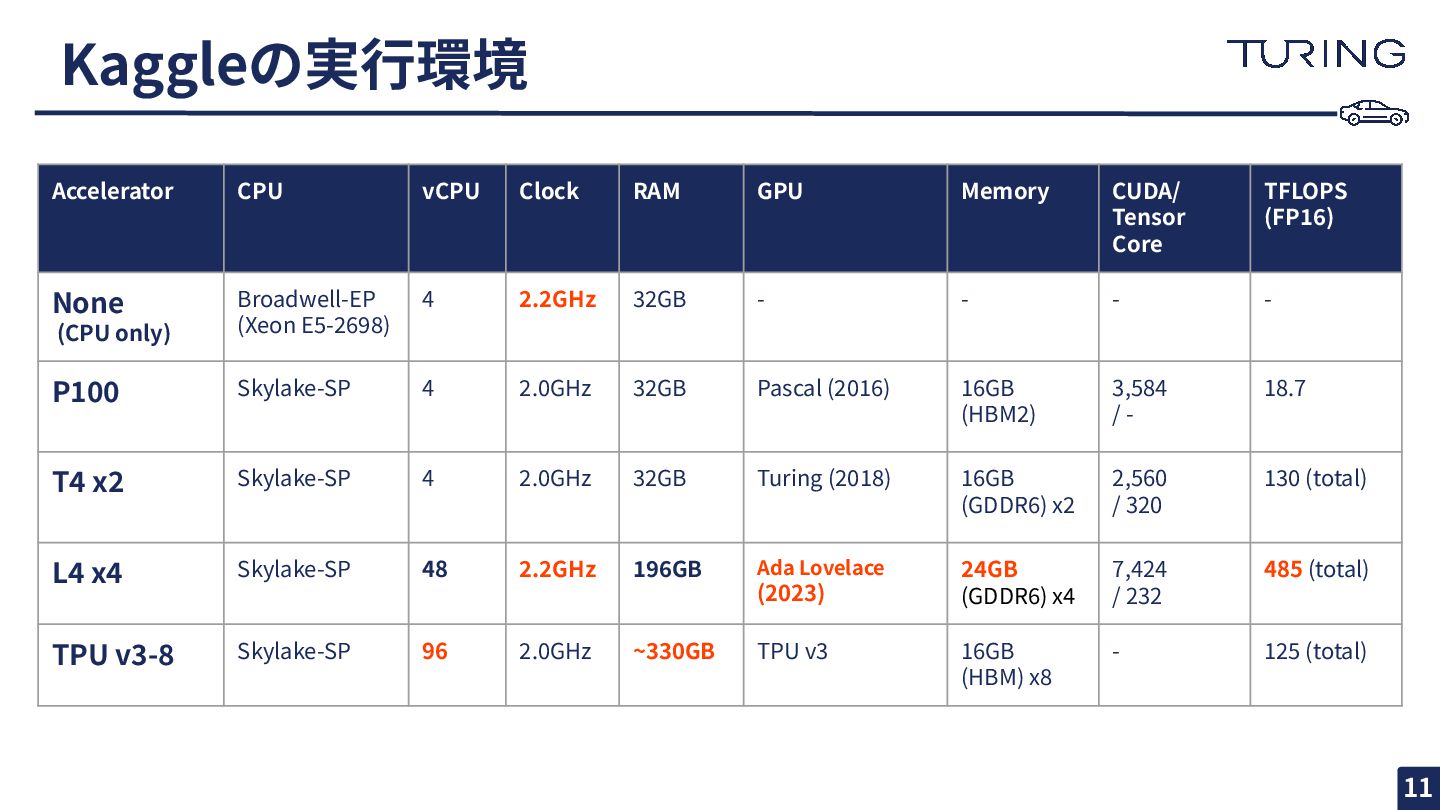{kind=link}
{kind=link}
{kind=link}
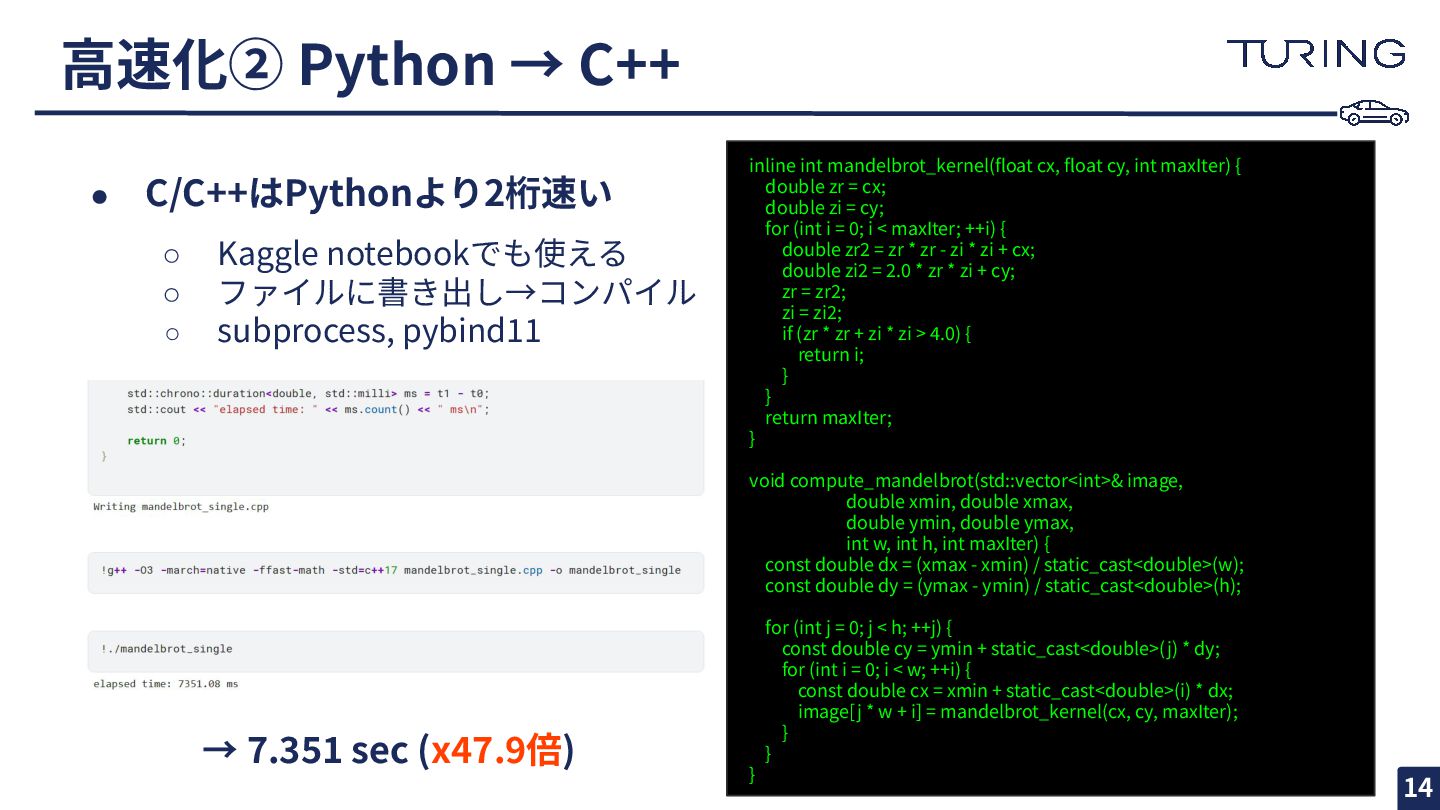{kind=link}
{kind=link}
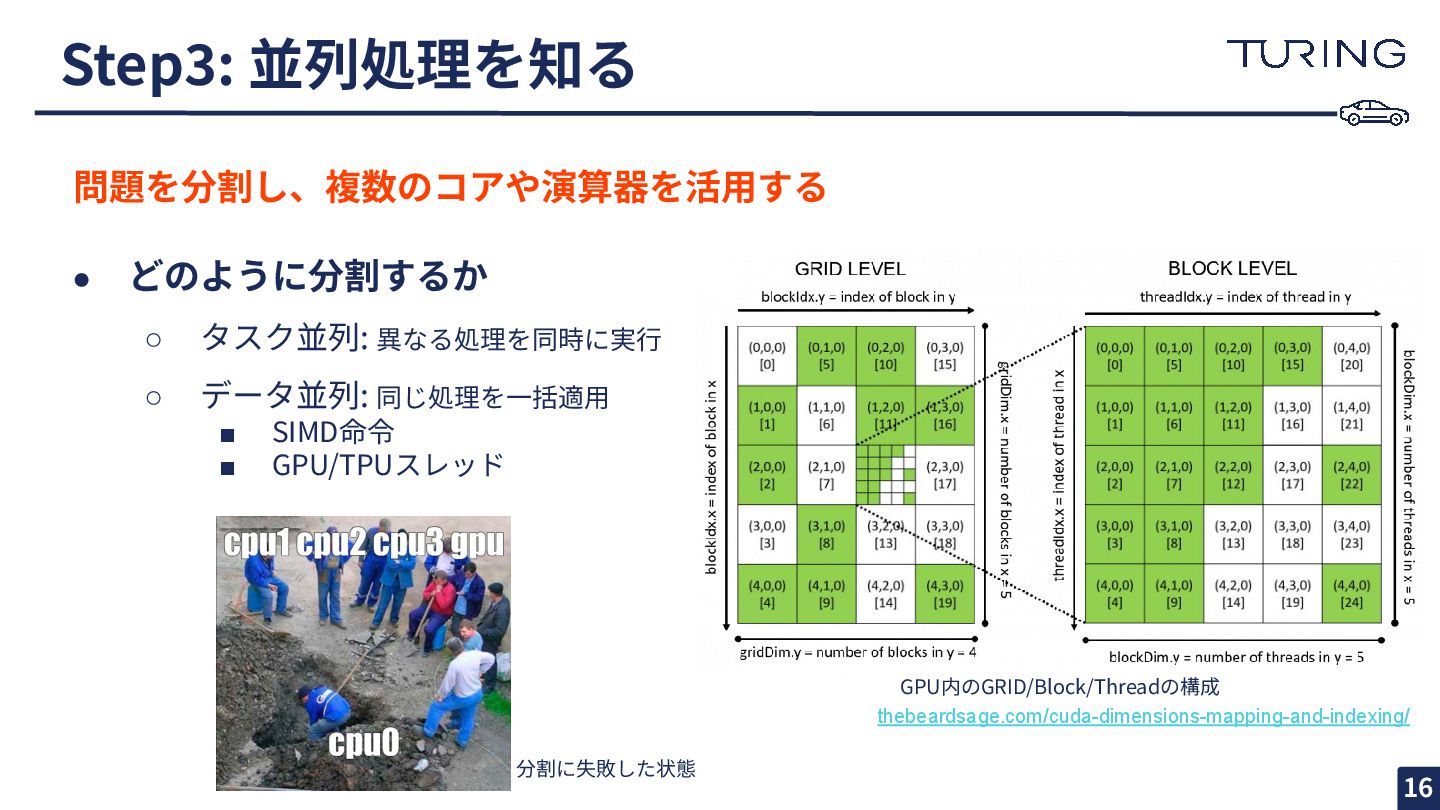{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
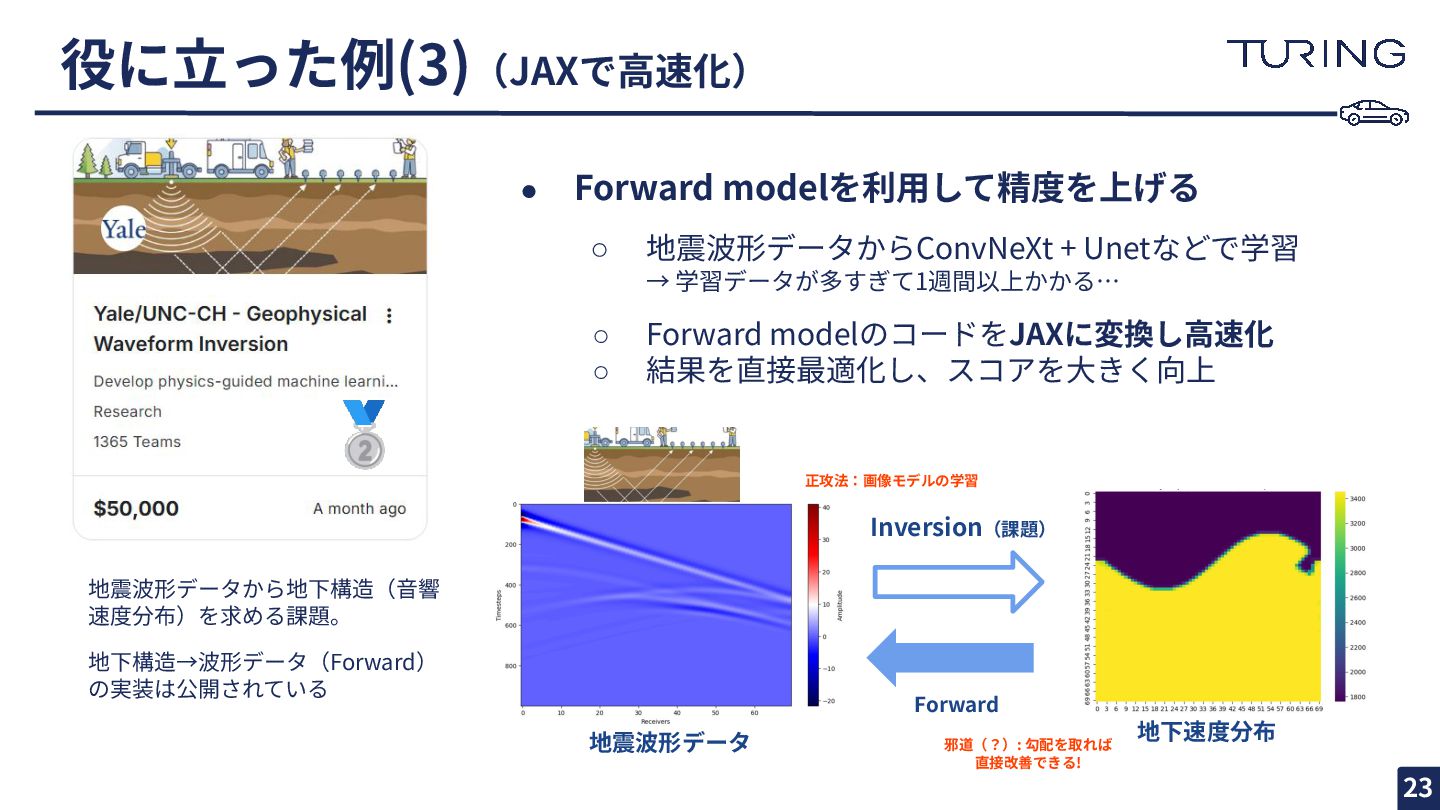{kind=link}
{kind=link}
{kind=link}
{kind=link}