and business needs – to find the sweet spot that aligns with your risk tolerance and budget. Remember, frugality is about maximizing value, not just minimizing spend. And to do that, you need to determine what you’re willing to pay for.
and expertise •Installation and configuration of OSS •Scaling and performance tuning •Security configuration •Patching – updates and security fixes •Upstream contributions and fixes •Support of open source technology •Infrastructure patching – security and functional •Compute orchestration, provisioning •Cluster scaling •Physical hardware, host OS/kernel, networking, and facilities •Physical data centre capabilities Self host •Use open source technology Customer Manages
# List the bucket contents 1000 times (excessive API calls) for _ in range(1000): objects = s3.list_objects_v2(Bucket=bucket_name) # Download the same files over and over instead of caching for obj in objects.get("Contents", []): key = obj["Key"] s3.download_file(bucket_name, key, f"/tmp/{key}") # Re-downloading every time # Uploading large file in small chunks without using multipart upload with open("large_file.dat", "rb") as f: while chunk := f.read(1024): # Reading in tiny 1KB chunks s3.put_object(Bucket=bucket_name, Key="uploads/large_file.dat", Body=chunk)
entire table instead of querying specific records response = dynamodb.scan(TableName=table_name) # Process items (even if we only need a few) for item in response.get("Items", []): print(item)
our source of truth Apache Cassandra databases as well as our performance sensitive Memcached tiers. ACCP is successfully reducing crypto overhead by up to 90% in various workloads primarily TLS and message digests. For example, ACCP accelerates our internode communication, quorum data reads, anti-entropy repair, and continuous S3 backups. We were pleased with how easy it was to integrate ACCP with both off-the-shelf and in-house Java software.” Joey Lynch Netflix Cloud Data Engineering Team Up to 90% crypto overhead reduction
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
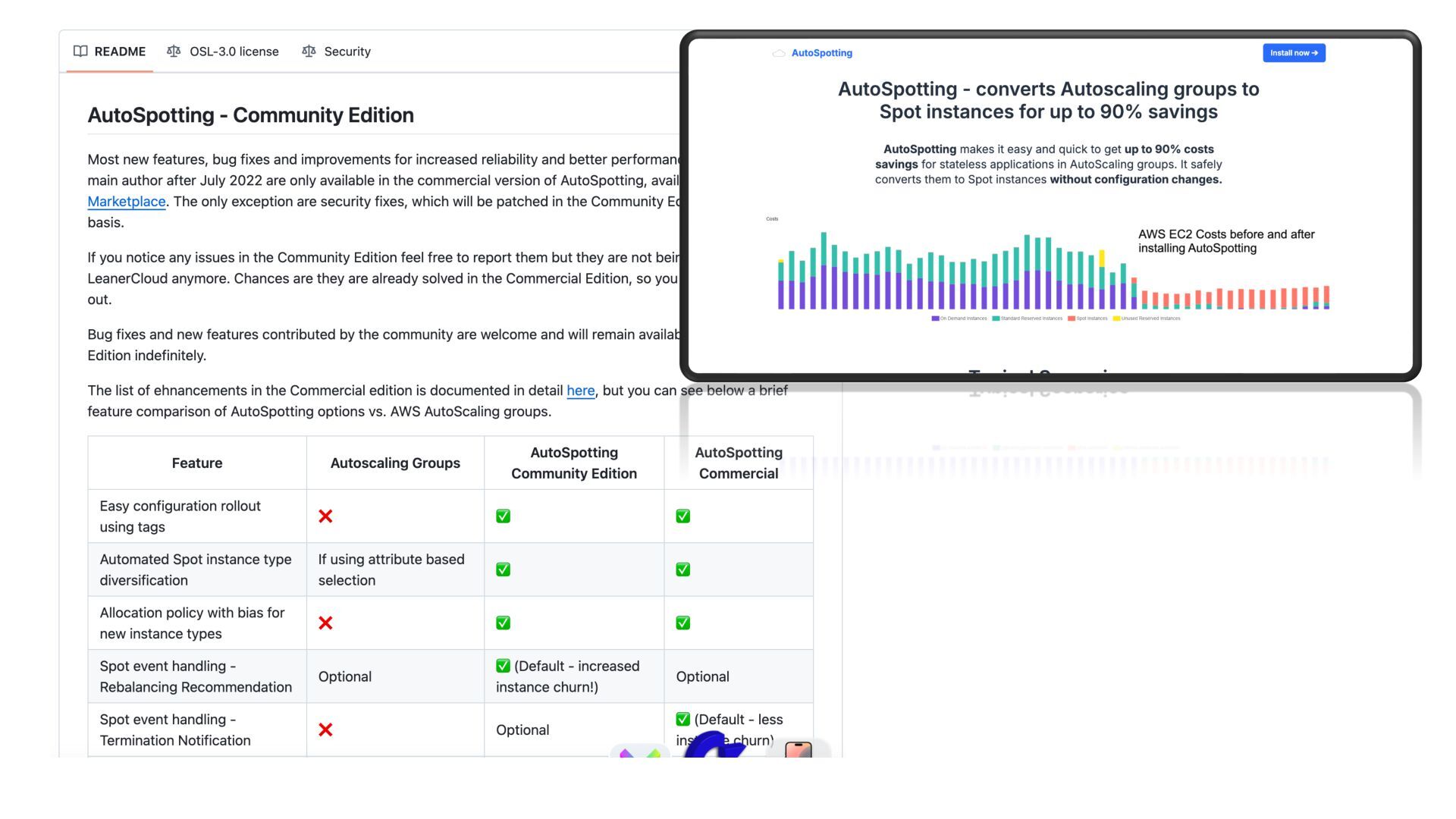{kind=link}
{kind=link}
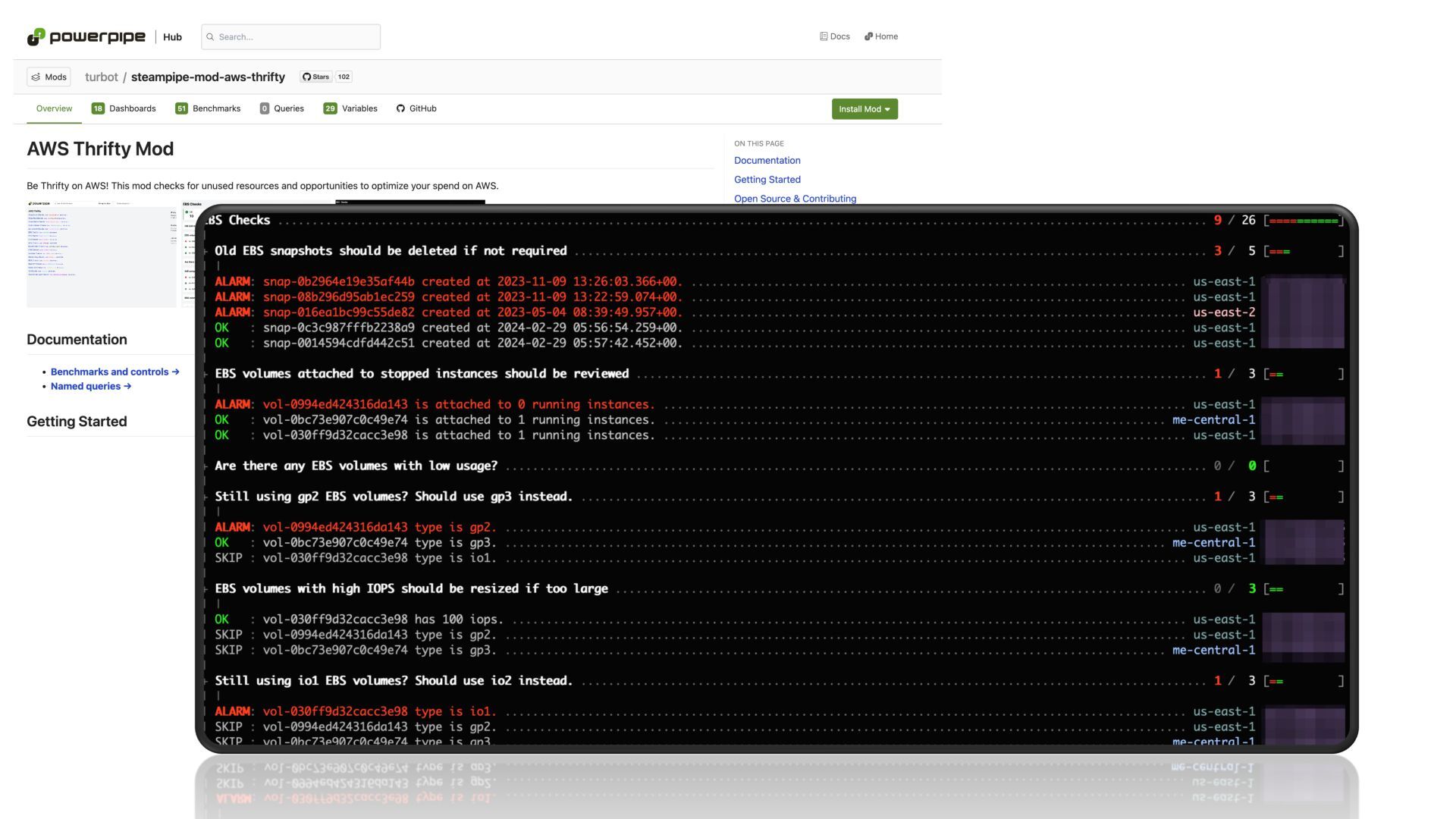{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you_ @[email protected] https://www.linkedin.com/in/ricardosueiras 094459.bsky.social https://github.com/094459](https://files.speakerdeck.com/presentations/0dc6d179735d4dd085f281f0acb2638c/slide_62.jpg){kind=link}