in data and when to use them • Understand key parameters useful across different packages • Develop an approach to reviewing and knowing how to import data
from working directory function output saved into If you are working on a PC, remember to change file path backslashes (“\”) to forward slashes (“/”) or use an escape first (“\\”).
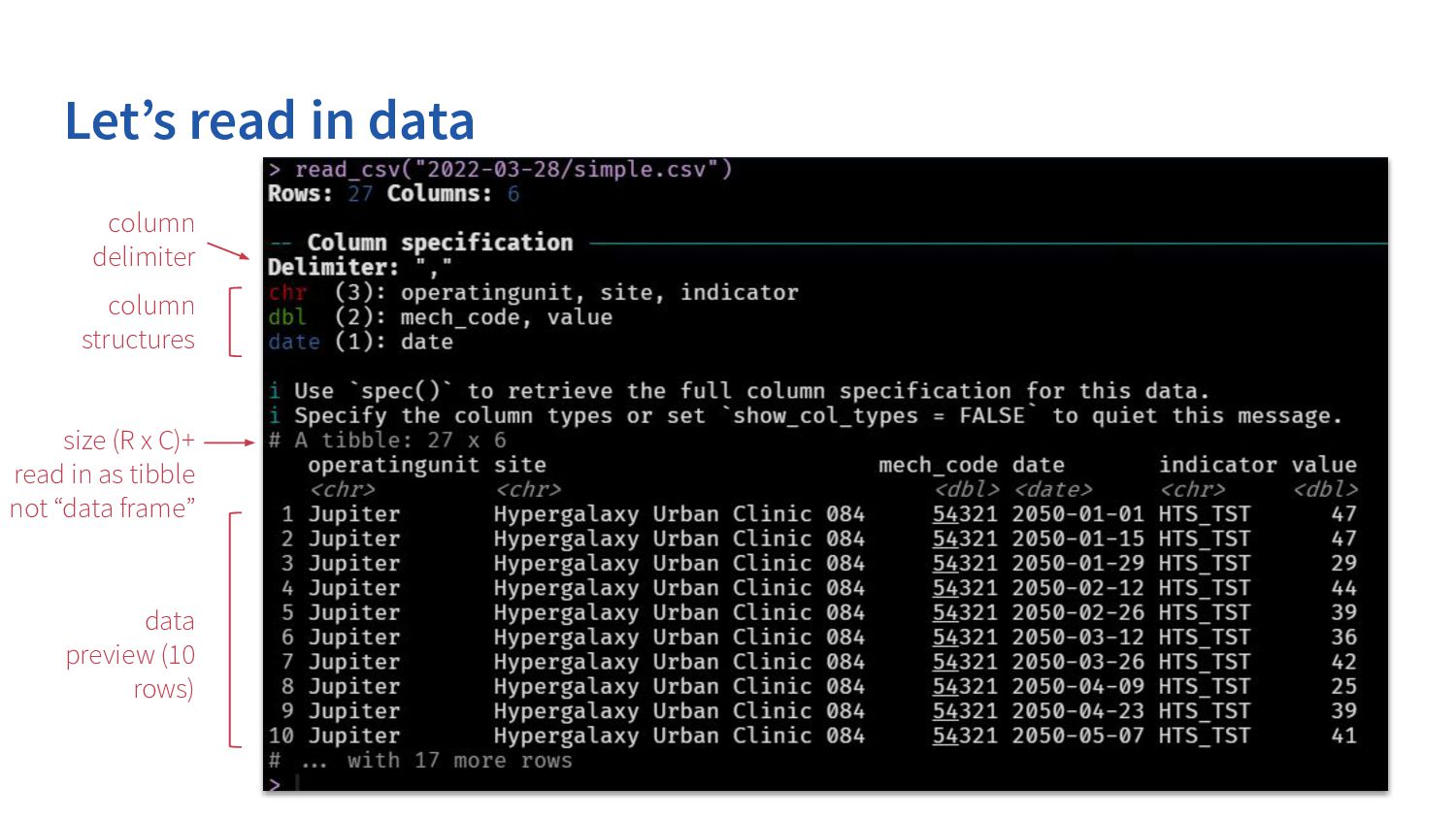
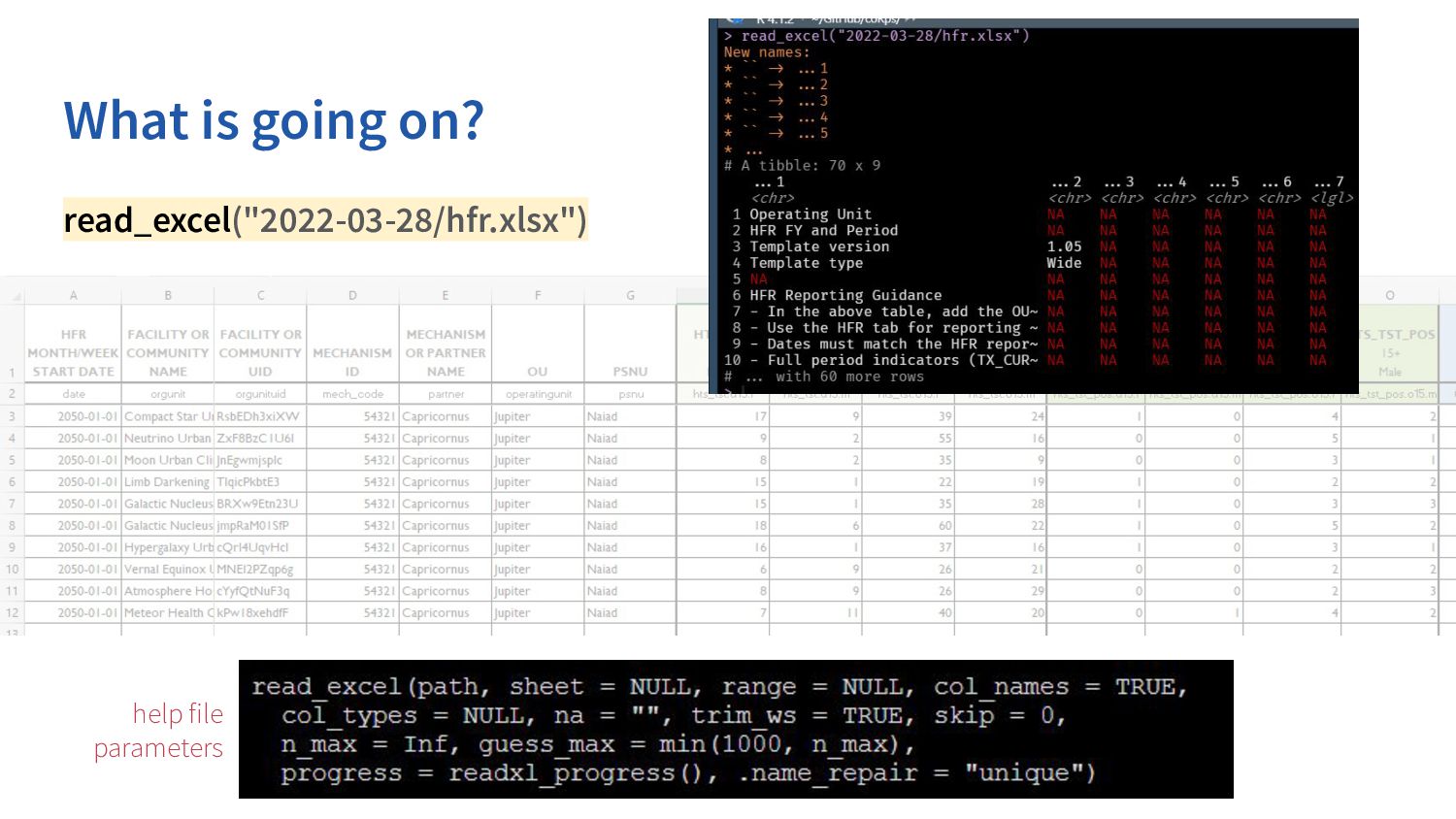
col_types = NULL, col_select = NULL, id = NULL, locale = default_locale(), na = c("", "NA"), quoted_na = TRUE, quote = "\"", comment = "", trim_ws = TRUE, skip = 0, n_max = Inf, guess_max = min(1000, n_max), name_repair = "unique", num_threads = readr_threads(), progress = show_progress(), show_col_types = should_show_types(), skip_empty_rows = TRUE, lazy = should_read_lazy() ) file to import specify column types specify source file number of lines to skip from top non-unique column names handling structure type guess range The other import functions all have a very similar set of parameters. If you understand read_csv, you can understand the structure of the rest. define missing values
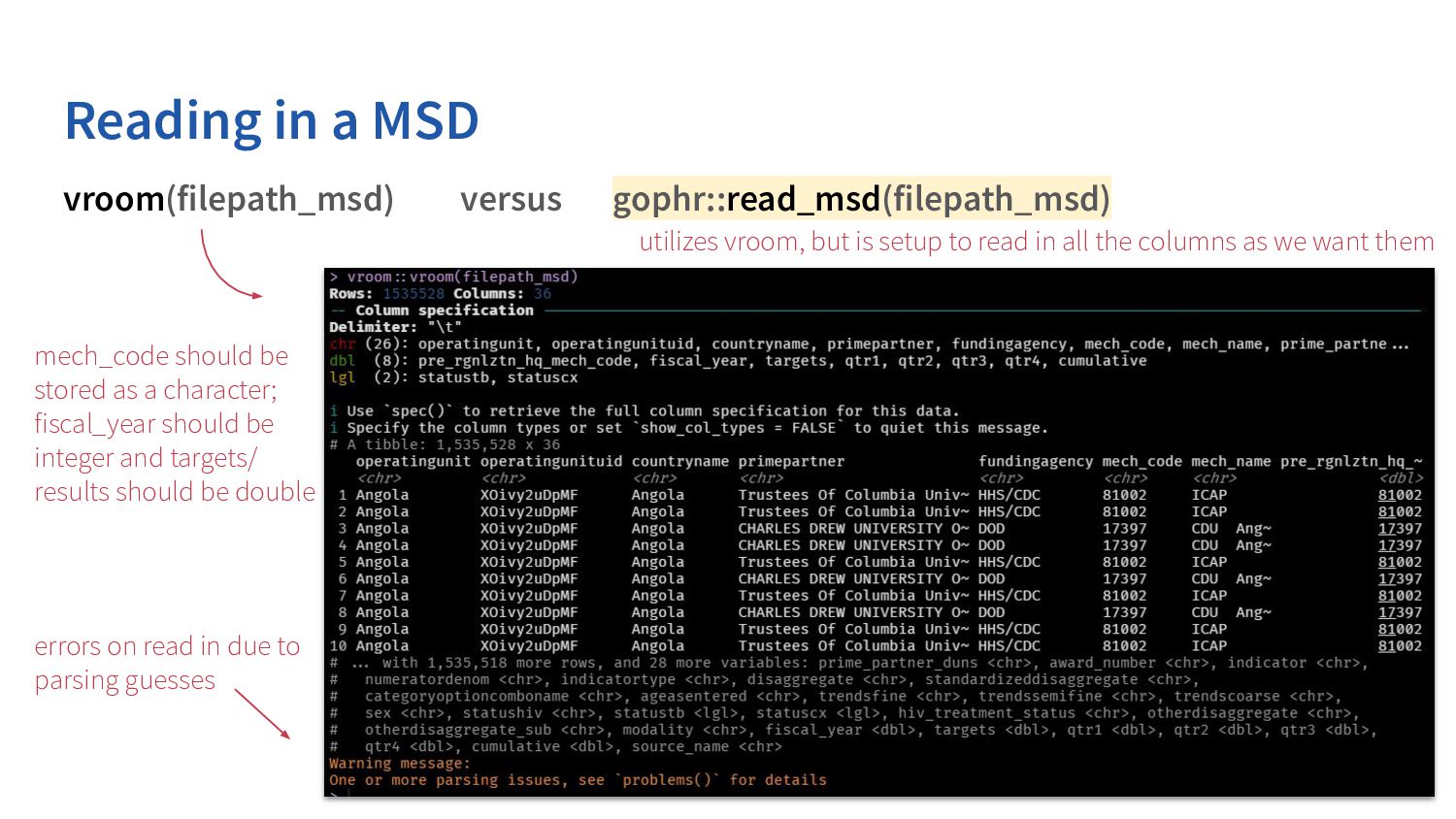
vroom::vroom() readxl::read_excel() haven::read_dta() googlesheets4::read_sheet() gophr::read_msd() googlesheets4::range_speedread() tameDP::tame_dp() read in small/medium sized csv read in small/medium sized tsv read in an Excel file read small Google Sheet read large Google Sheet read in large csv very fast “doesnʼt fit quite so well into the tidyverse” read in large csv fast read in SAS/Stata/SPSS file read in MER Structured Dataset applies necessary structure read in PEPFAR Data Pack tidies format
.f = ~read_excel("2022-03-28/hfr.xlsx", sheet = .x, skip = 1)) OR excel_sheets("2022-03-28/hfr.xlsx") %>% stringr::str_subset("HFR") %>% purrr::map_dfr(.f = ~read_excel("2022-03-28/hfr.xlsx", sheet = .x, skip = 1)) identify sheets in workbook limit vector to those that match HFR iterate read function over multiple sheets and combine into a tibble iterate read function over multiple sheets and combine into a tibble
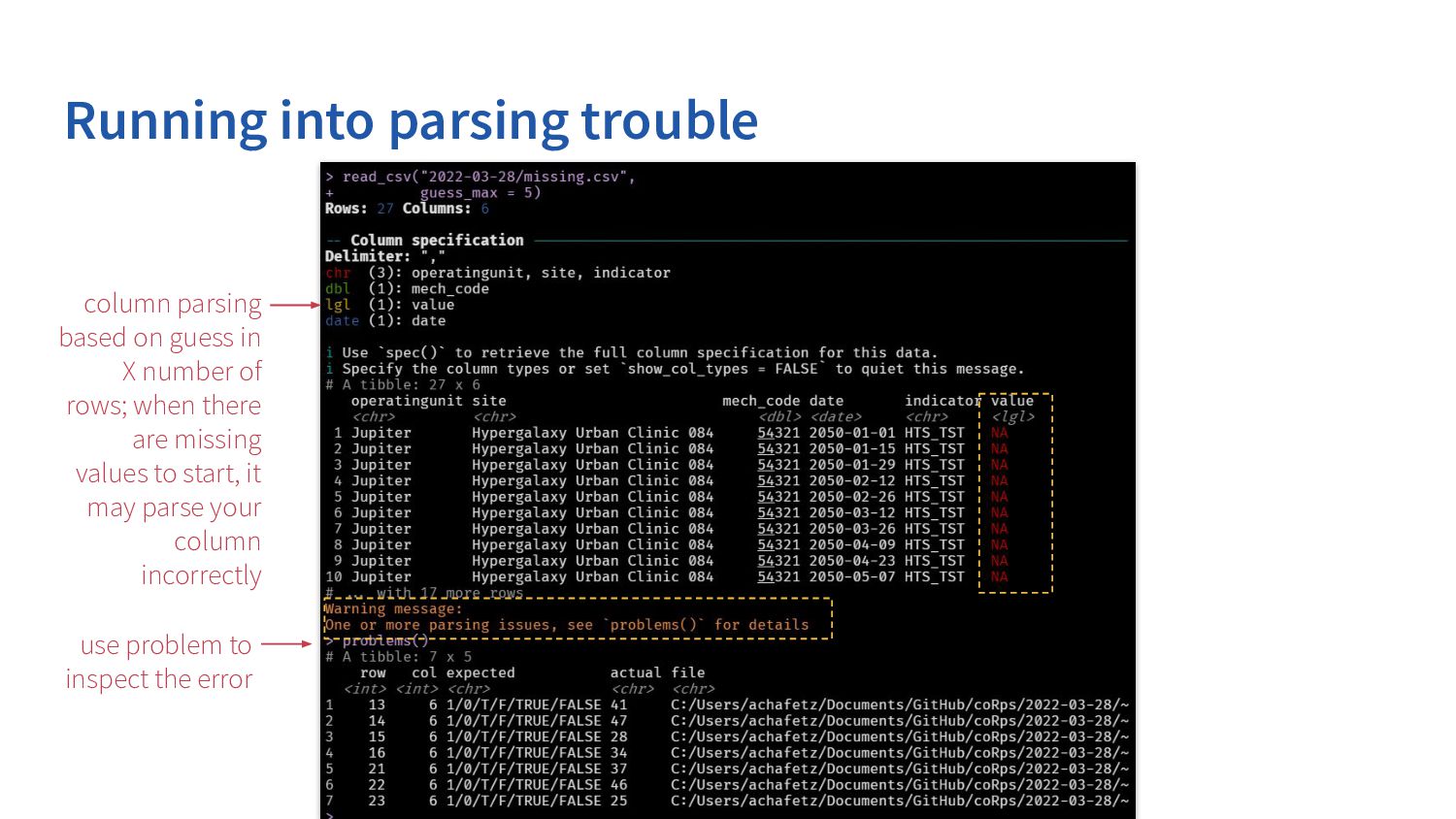
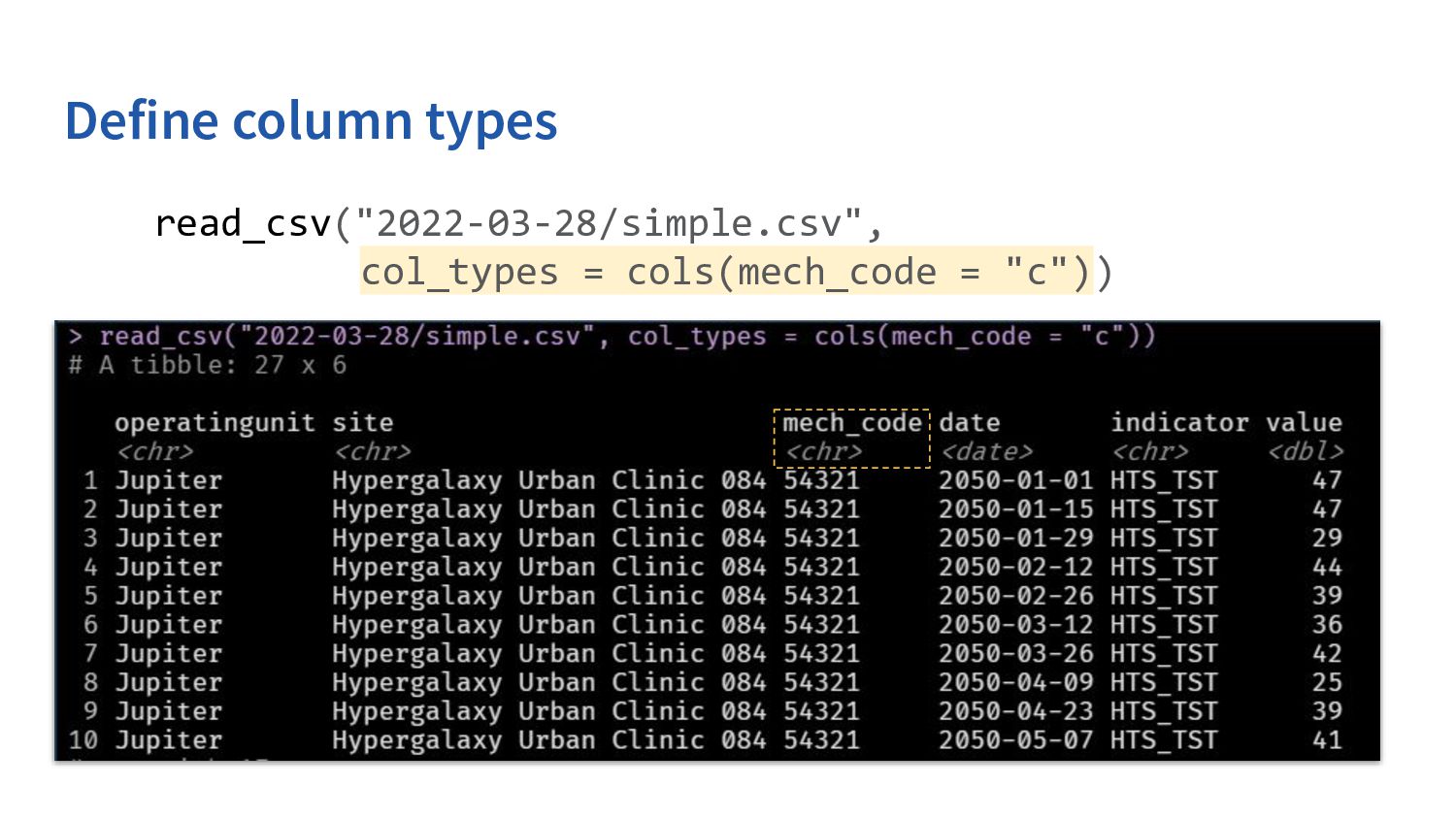
in due to parsing guesses mech_code should be stored as a character; fiscal_year should be integer and targets/ results should be double utilizes vroom, but is setup to read in all the columns as we want them
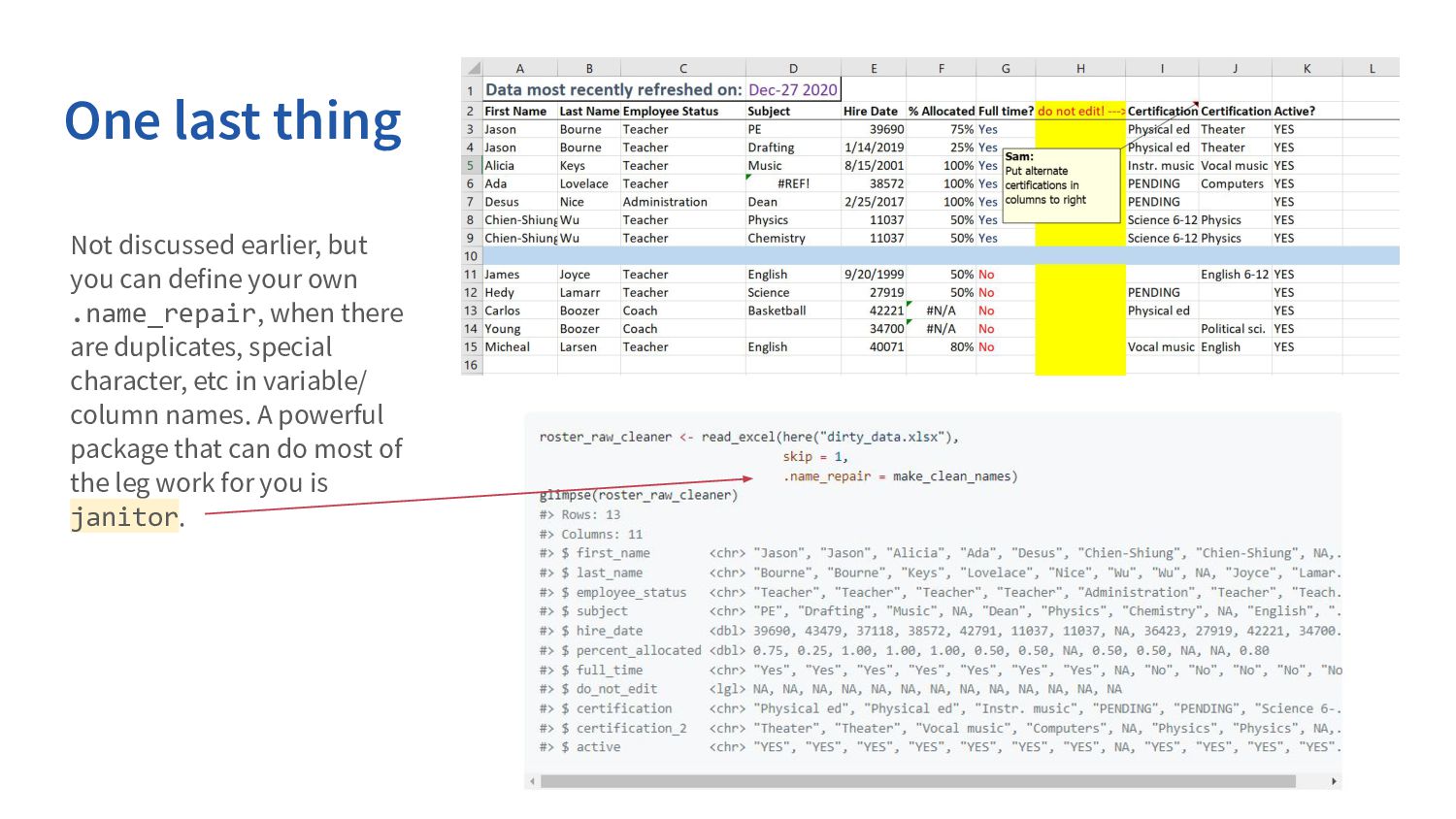
your own .name_repair, when there are duplicates, special character, etc in variable/ column names. A powerful package that can do most of the leg work for you is janitor.
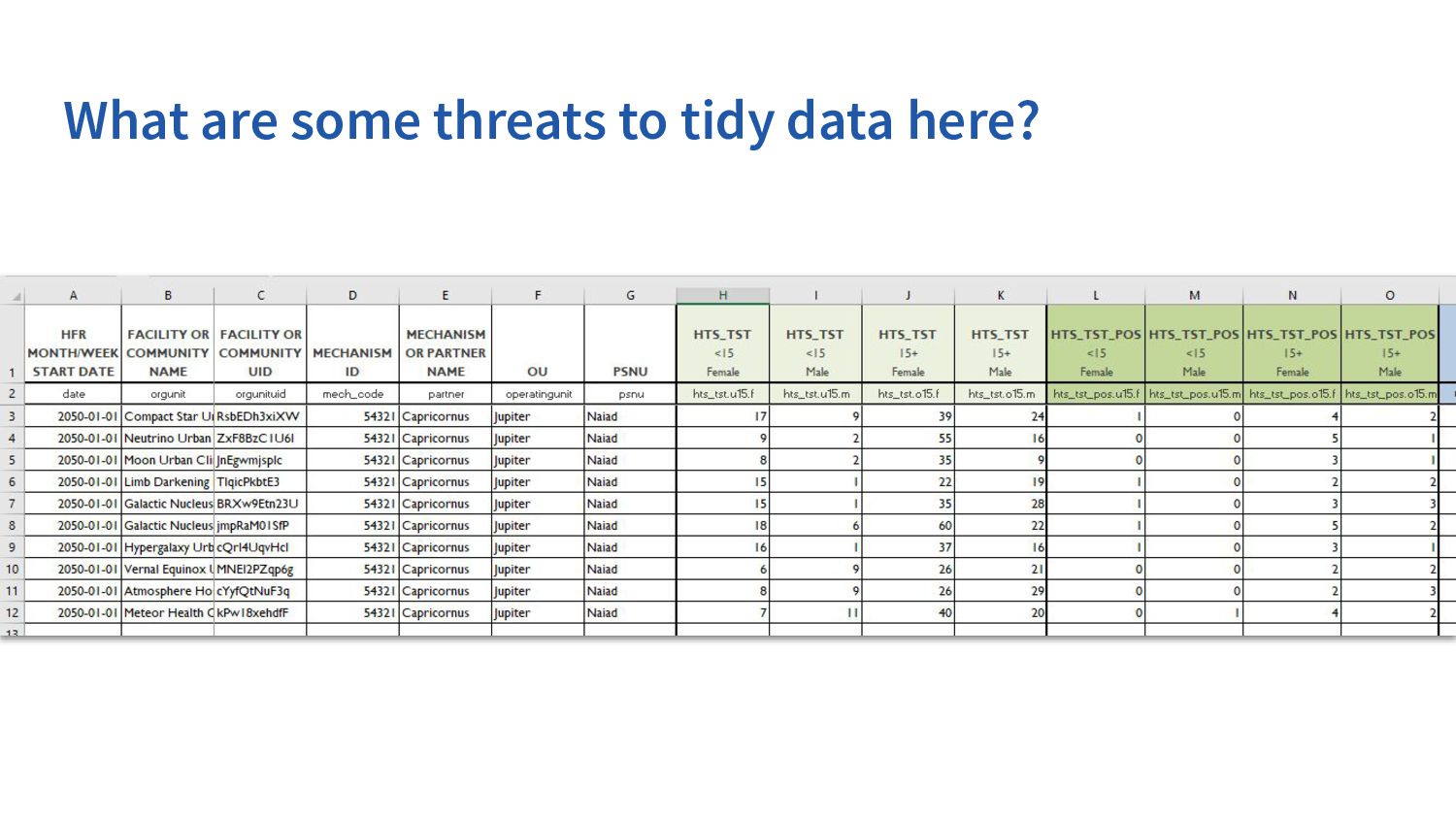
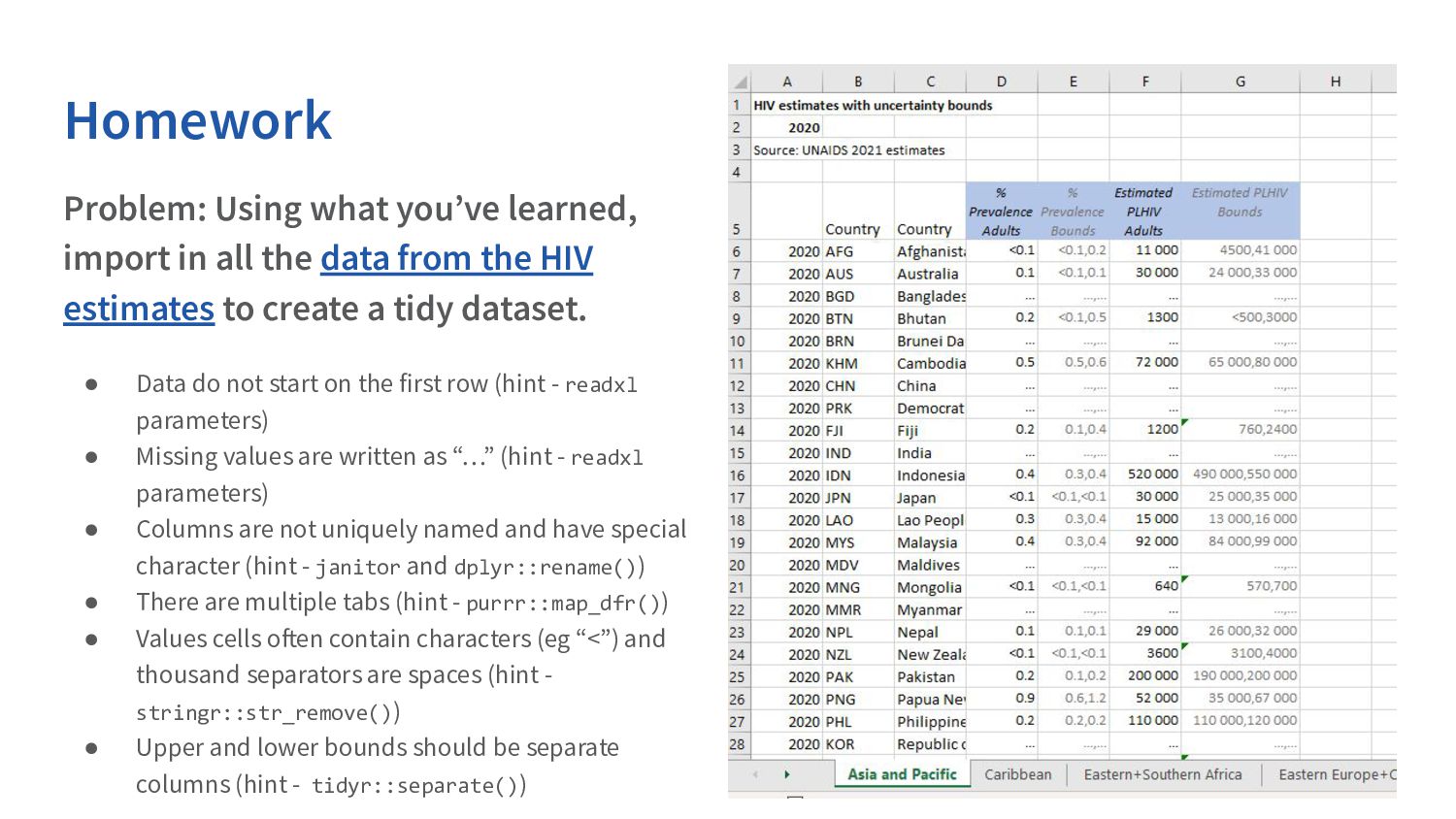
data from the HIV estimates to create a tidy dataset. • Data do not start on the first row (hint - readxl parameters) • Missing values are written as “…” (hint - readxl parameters) • Columns are not uniquely named and have special character (hint - janitor and dplyr::rename()) • There are multiple tabs (hint - purrr::map_dfr()) • Values cells often contain characters (eg “<”) and thousand separators are spaces (hint - stringr::str_remove()) • Upper and lower bounds should be separate columns (hint - tidyr::separate())
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}