Norway • Worked with search at FAST (now Microsoft) for 10 years • 5 years in R&D building FAST Enterprise Search Platform in Oslo, Norway • 5 years in Services doing solution delivery, technical sales, etc. in Tokyo, Japan • Founded ΞςΟϦΧגࣜձࣾ in October, 2009 • We help companies innovate using new technologies and good ideas • We do information retrieval, natural language processing and big data • We are based in Tokyo, but we have clients everywhere • We are a small company, but our customers are typically very big companies • Newbie Lucene & Solr Committer • Mostly been working on Japanese language support (Kuromoji) so far • Working on Korean support from a code donation (LUCENE-4956) • Please write me on [email protected] or [email protected]
with natural language • Basic measurements for search quality • Linguistics in Apache Lucene • Linguistics in ElasticSearch (quick intro) • Linguistics in Apache Solr • Linguistics in the NLP eco-system • Summary and practical advice
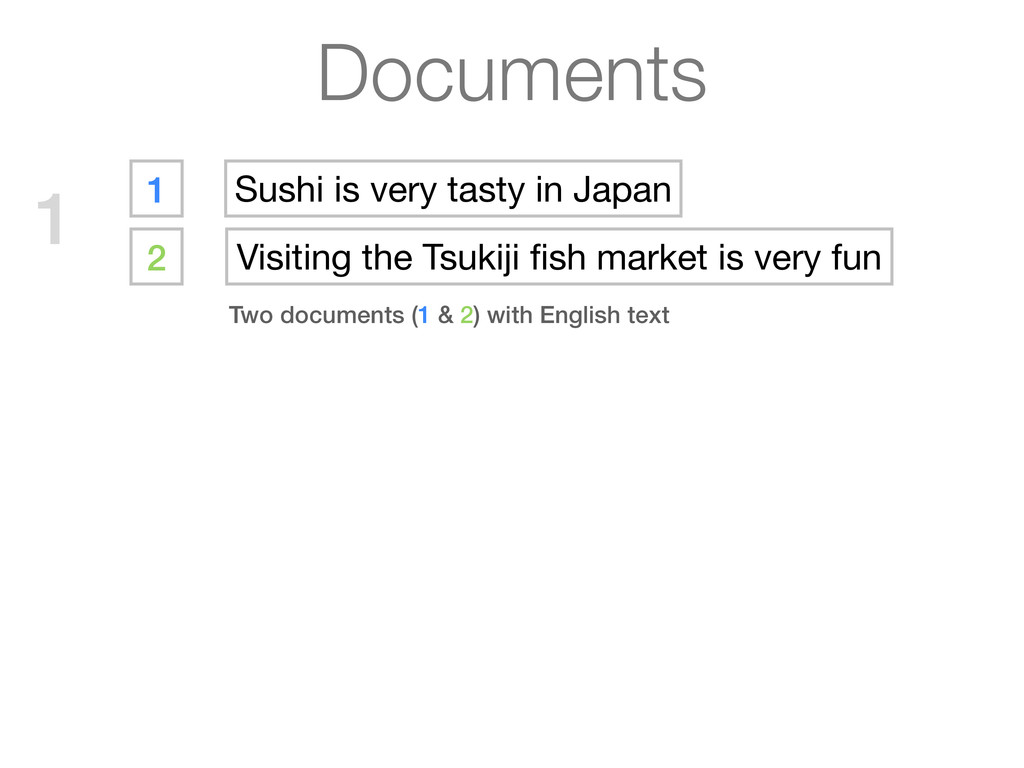
Visiting the Tsukiji fish market is very fun 1 Sushi is very tasty in Japan 2 Visiting the Tsukiji fish market is very fun Documents are turned into searchable terms (tokenization) Two documents (1 & 2) with English text 1 2
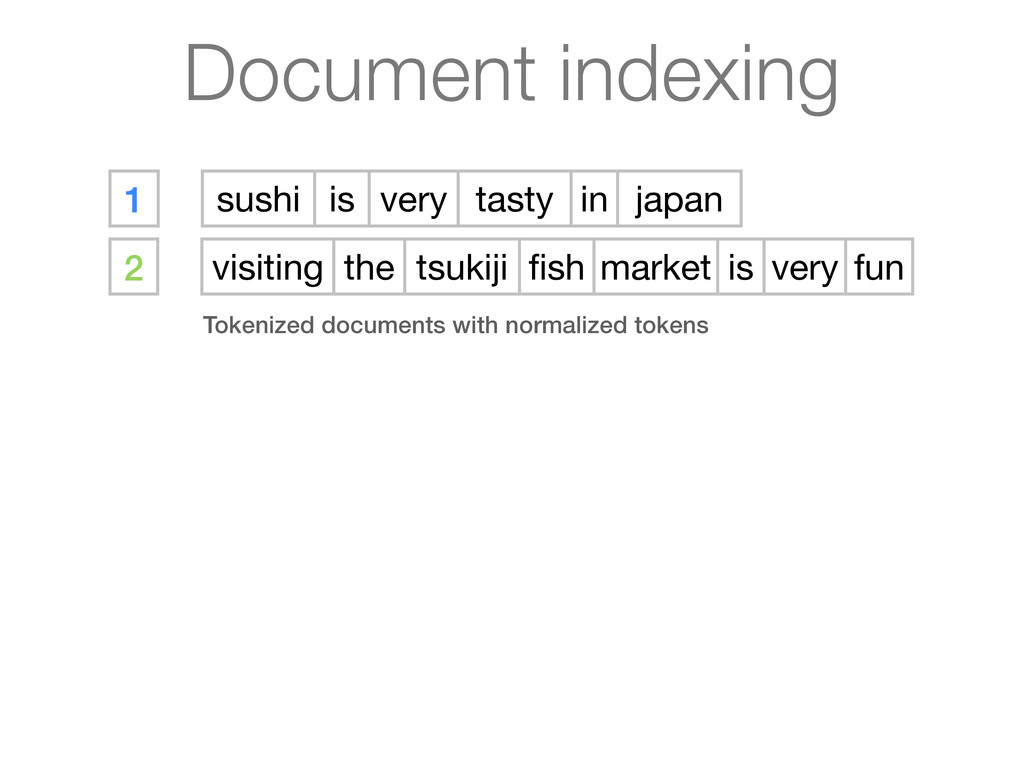
Visiting the Tsukiji fish market is very fun 1 Sushi is very tasty in Japan 2 Visiting the Tsukiji fish market is very fun 1 sushi is very tasty in japan 2 visiting the tsukiji fish market is very fun Documents are turned into searchable terms (tokenization) Two documents (1 & 2) with English text Terms/tokens are converted to lowercase form (normalization) 1 2 3
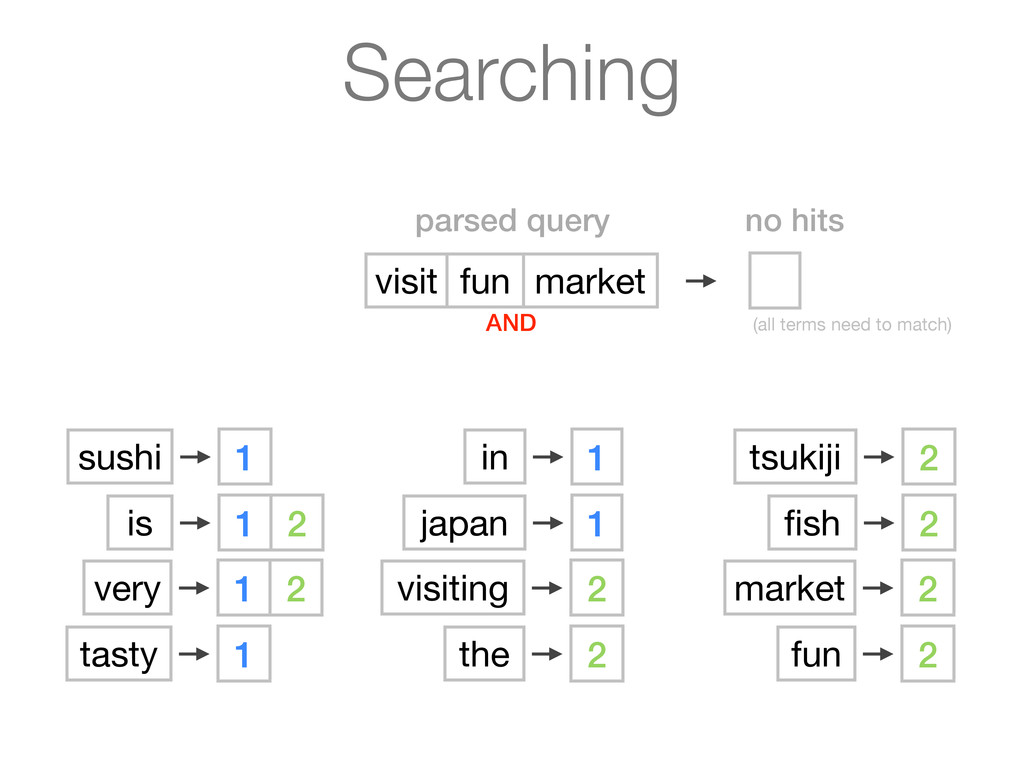
tasty 1 in 1 japan 1 visiting 2 the 2 tsukiji 2 fish 2 market 2 fun 2 1 sushi is very tasty in japan 2 visiting the tsukiji fish market is very fun Tokenized documents with normalized tokens Inverted index - tokens are mapped to the document ids that contain them
a search for style match styles? And should ferment match fermentation? ? Pale ale is a beer made through warm fermentation using pale malt and is one of the world's major beer styles.
es findet in der bayerischen Landeshauptstadt München. The Oktoberfest is the world’s largest festival and it takes place in the Bavarian capital Munich.
es findet in der bayerischen Landeshauptstadt München. The Oktoberfest is the world’s largest festival and it takes place in the Bavarian capital Munich. How do we want to search ü, ö and ß? ?
es findet in der bayerischen Landeshauptstadt München. The Oktoberfest is the world’s largest festival and it takes place in the Bavarian capital Munich. How do we want to search ü, ö and ß? ? Do we want a search for hauptstadt to match Landeshauptstadt? ?
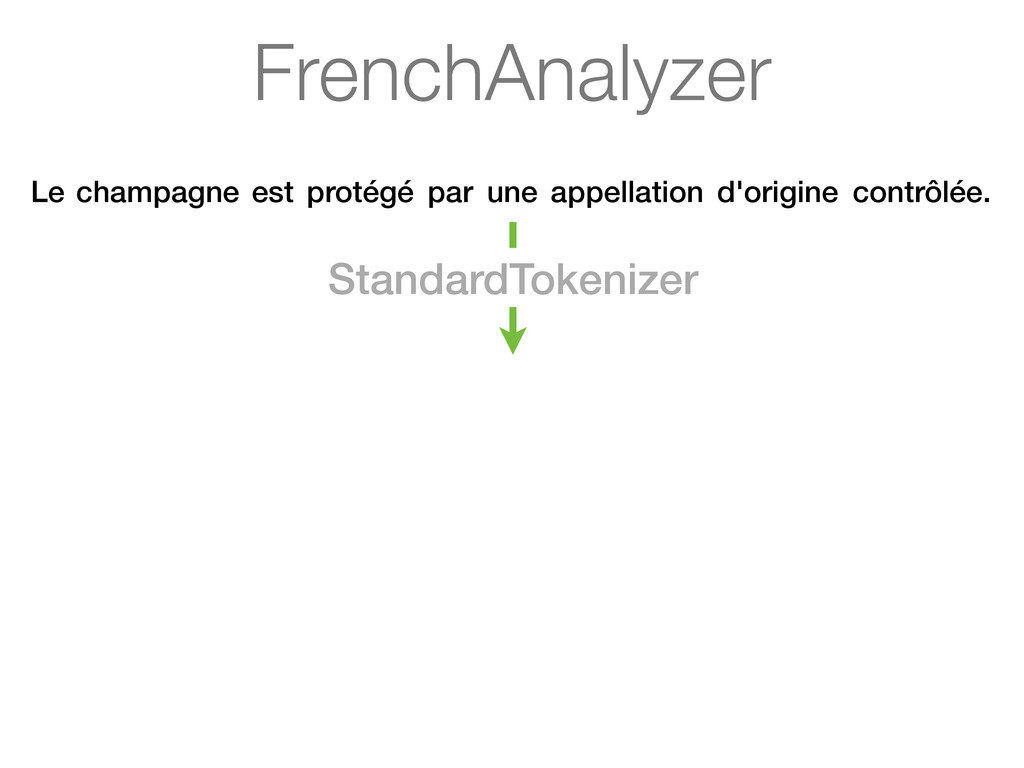
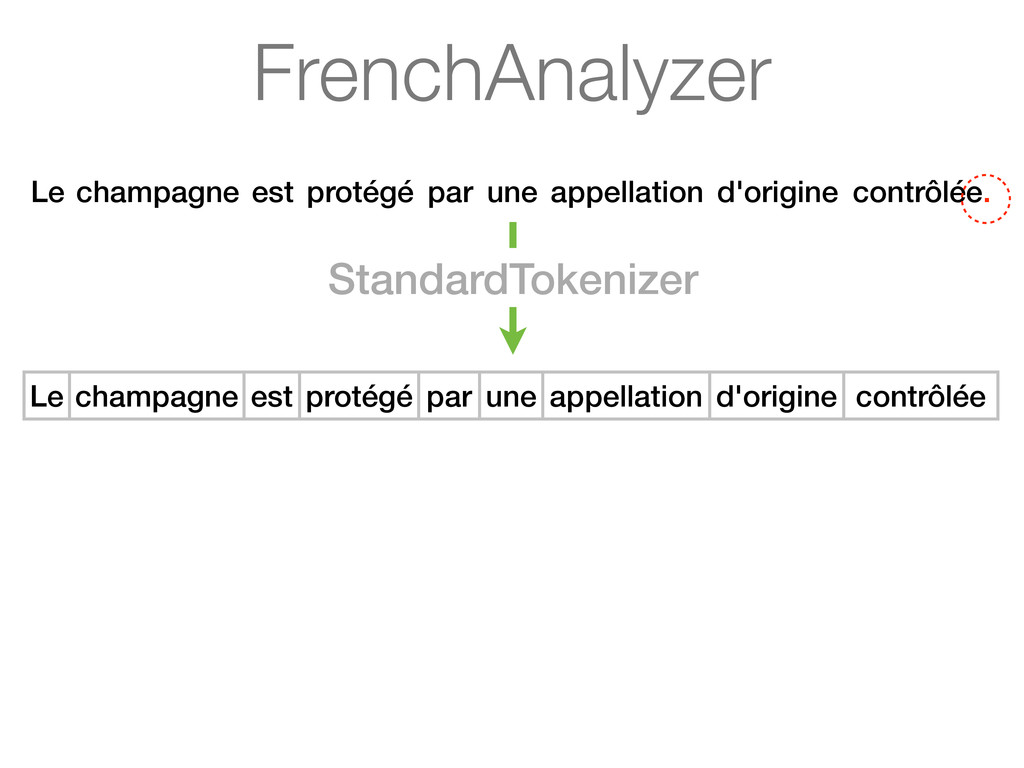
une appellation d'origine contrôlée. How do we want to search é, ç and ô? ? Champagne is a French sparkling wine with a protected designation of origin.
une appellation d'origine contrôlée. How do we want to search é, ç and ô? ? Do we want a search for aoc to match appellation d'origine contrôlée? ? Champagne is a French sparkling wine with a protected designation of origin.
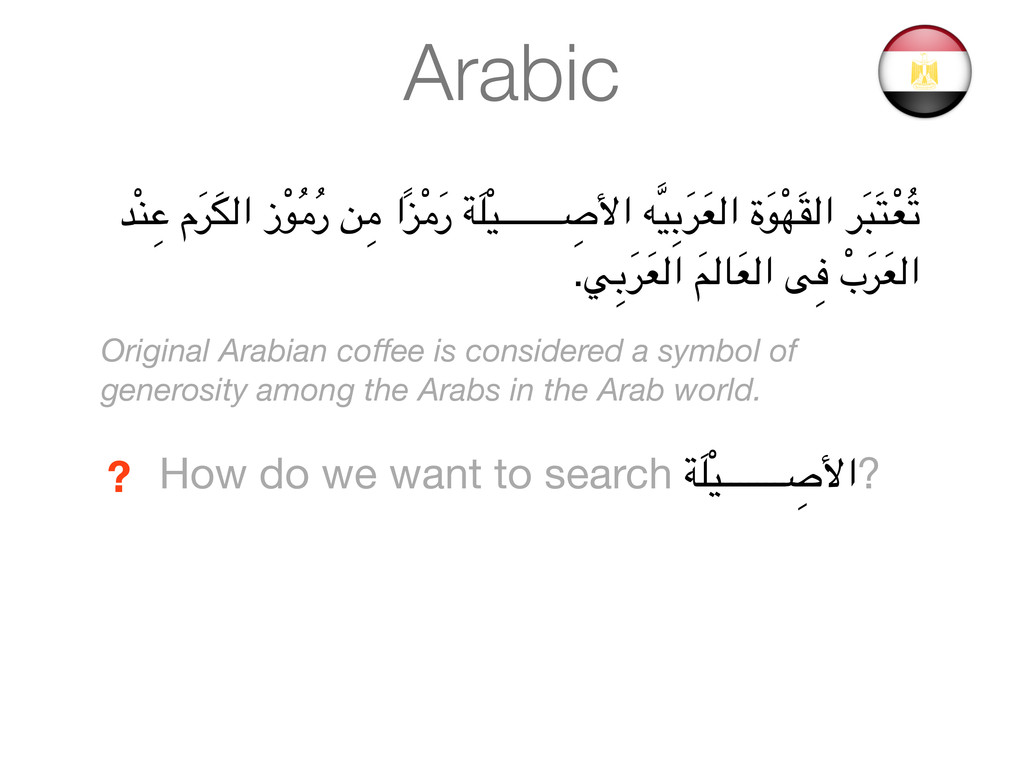
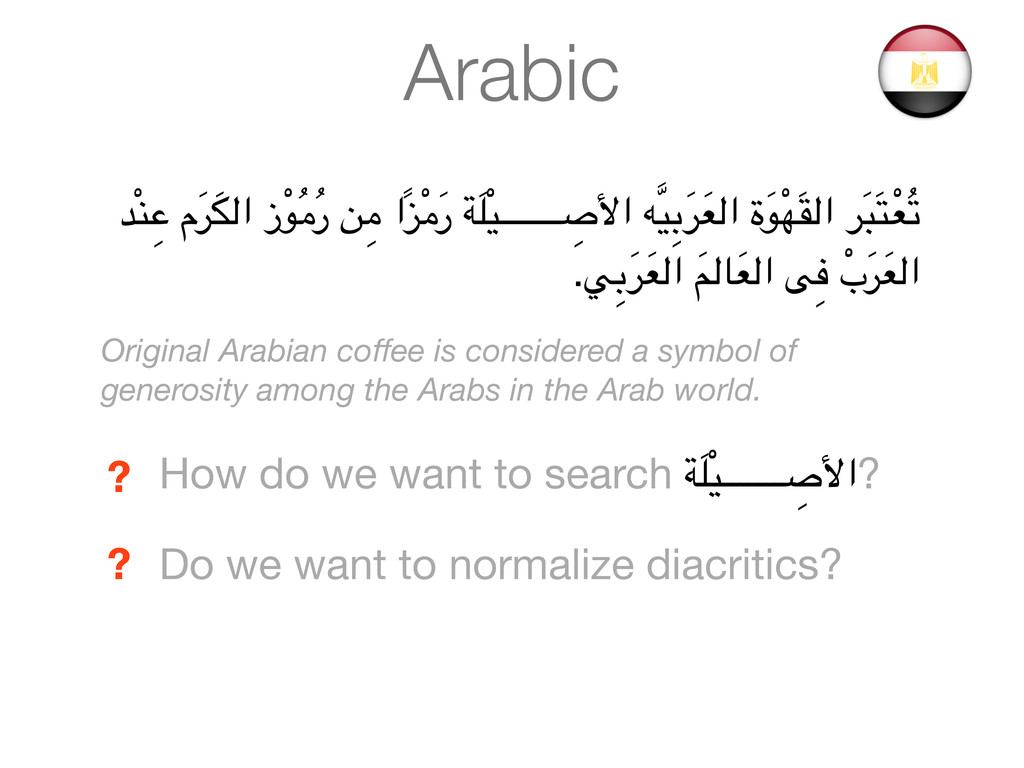
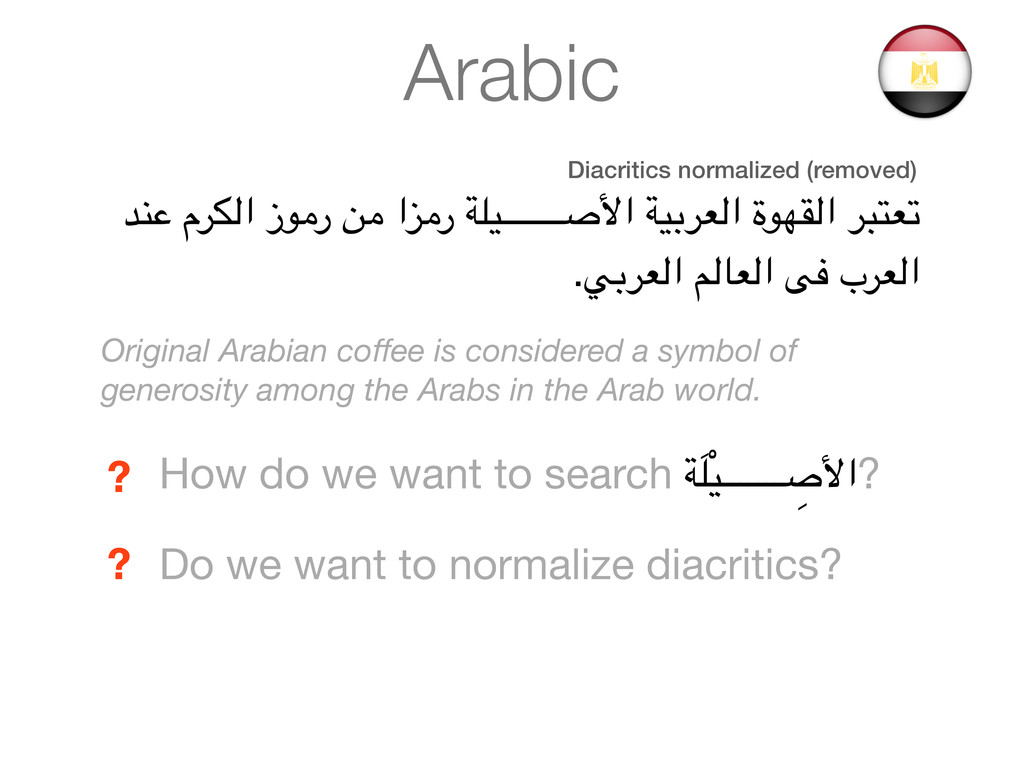
ةَ3ْAَB'ا %َC,َD,ْ&ُE .Fِ$َ%َ&'ا َG'Hَ&'ا IِJ ْبَ%َ&'ا Original Arabian coffee is considered a symbol of generosity among the Arabs in the Arab world. How do we want to search "َ:ْ#ـــــــ ِ <=ا? ?
ةَ3ْAَB'ا %َC,َD,ْ&ُE .Fِ$َ%َ&'ا َG'Hَ&'ا IِJ ْبَ%َ&'ا Original Arabian coffee is considered a symbol of generosity among the Arabs in the Arab world. How do we want to search "َ:ْ#ـــــــ ِ <=ا? ? Do we want to normalize diacritics? ?
.F$%&'ا G'H&'ا IJ ب%&'ا Original Arabian coffee is considered a symbol of generosity among the Arabs in the Arab world. How do we want to search "َ:ْ#ـــــــ ِ <=ا? ? Do we want to normalize diacritics? ? Diacritics normalized (removed)
ةَ3ْAَB'ا %َC,َD,ْ&ُE .Fِ$َ%َ&'ا َG'Hَ&'ا IِJ ْبَ%َ&'ا Original Arabian coffee is considered a symbol of generosity among the Arabs in the Arab world. How do we want to search "َ:ْ#ـــــــ ِ <=ا? ? Do we want to correct the common spelling mistake for IِJ and ه? ? Do we want to normalize diacritics? ?
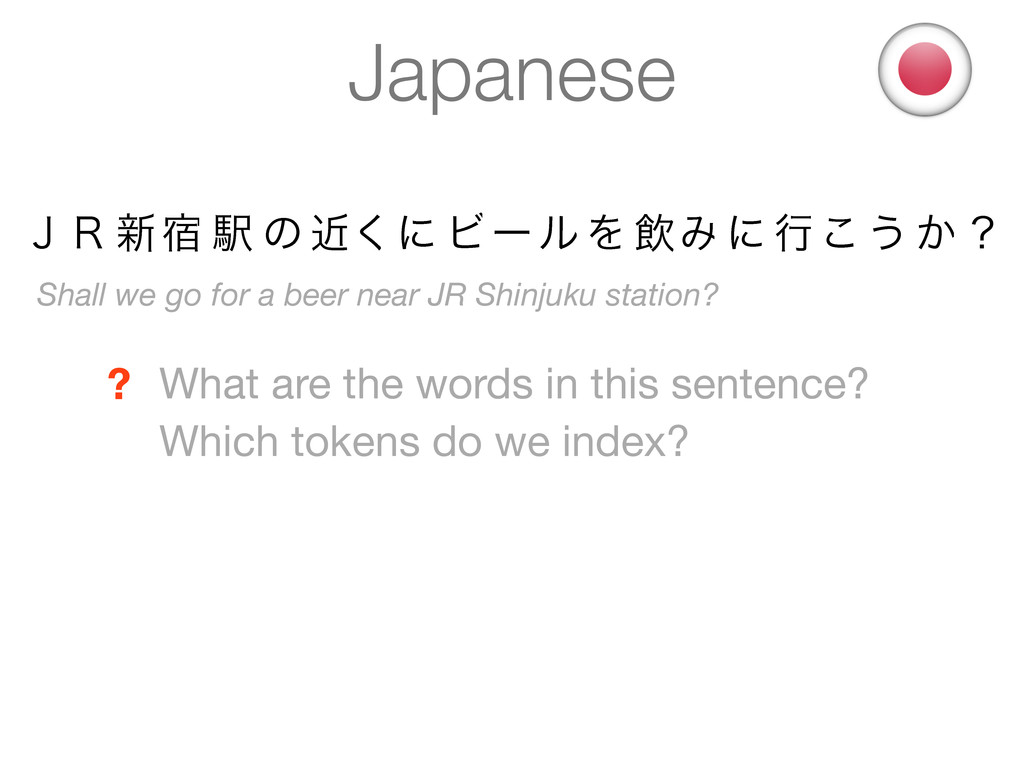
station? What are the words in this sentence? ? Words are implicit in Japanese - there is no white space that separates them ! What are the words in this sentence? Which tokens do we index? ̧̟ ৽॓ Ӻ ͷ ۙ͘ʹ ϏʔϧΛҿΈʹߦ͜͏ ͔ʁ
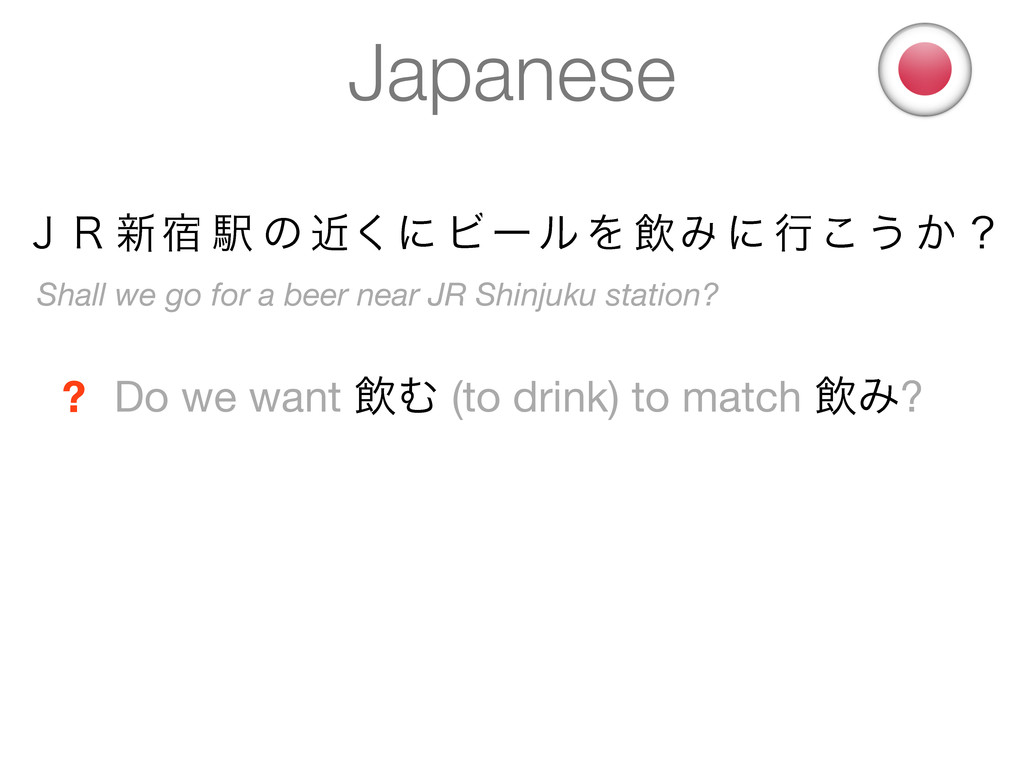
the words in this sentence? ? Words are implicit in Japanese - there is no white space that separates them ! What are the words in this sentence? Which tokens do we index? Shall we go for a beer near JR Shinjuku station? But how do we find the tokens? ? ̧̟ ৽॓ Ӻ ͷ ۙ͘ʹ ϏʔϧΛҿΈʹߦ͜͏ ͔ʁ
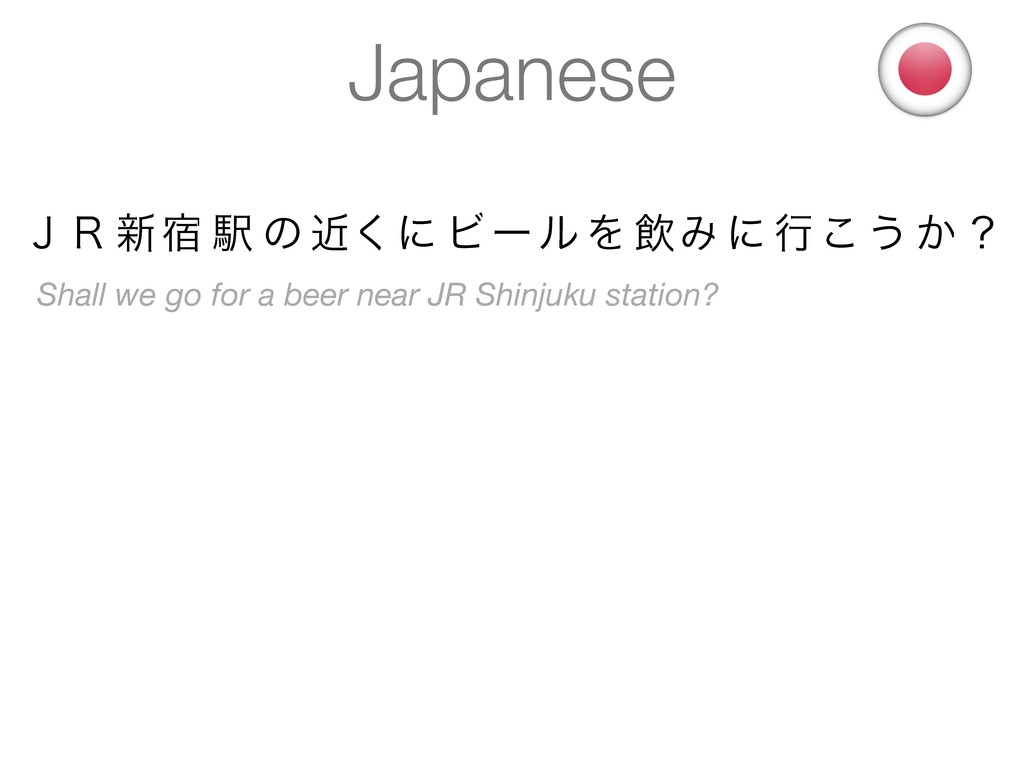
the words in this sentence? ? Words are implicit in Japanese - there is no white space that separates them ! What are the words in this sentence? Which tokens do we index? Shall we go for a beer near JR Shinjuku station? But how do we find the tokens? ?
? Do we want űƄŖſ to match Ϗʔϧ? ? Do we want (emoji) to match? ? Shall we go for a beer near JR Shinjuku station? Does half-width match full-width? ̧̟ ৽॓ Ӻ ͷ ۙ͘ʹ ϏʔϧΛҿΈʹߦ͜͏ ͔ʁ
non-space separated languages • Handling punctuation in space separated languages • Segmenting compounds into their parts • Apply relevant linguistic normalizations • Character normalization • Morphological (or grammatical) normalizations • Spelling variations • Synonyms and stopwords
language is different with its own set of complexities • We have had a high level look at languages • But there is also... • Search needs per-language processing • Many considerations to be made (often application-specific) Greek Hebrew Chinese Korean Russian Thai Spanish and many more ... Japanese English German French Arabic
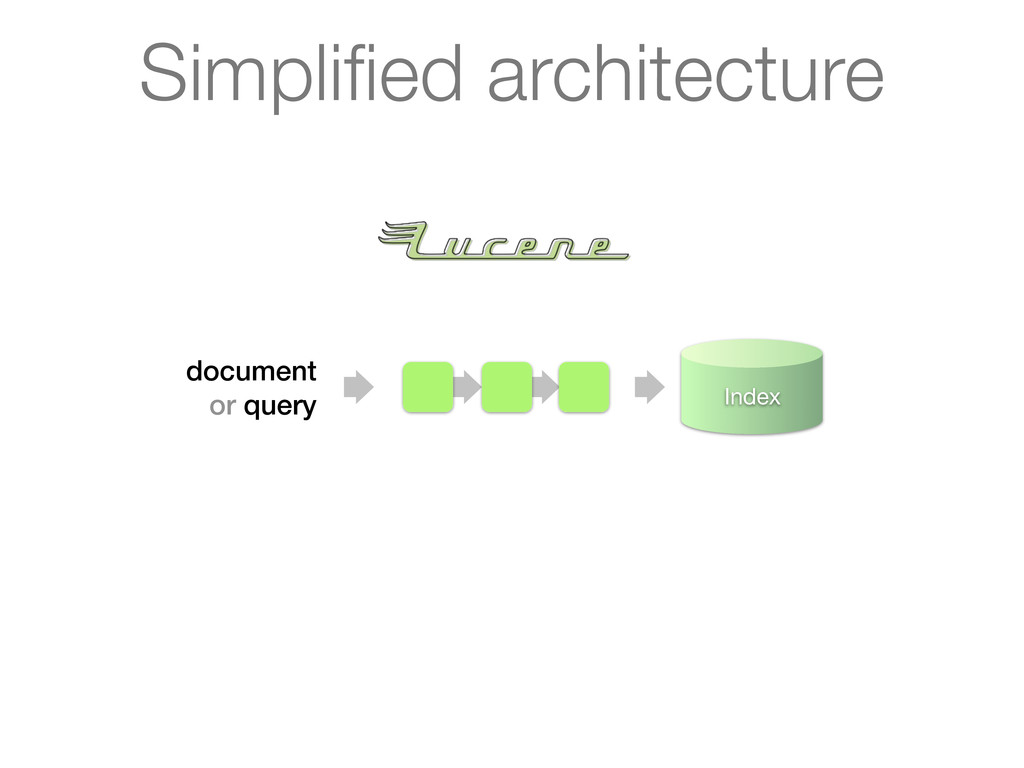
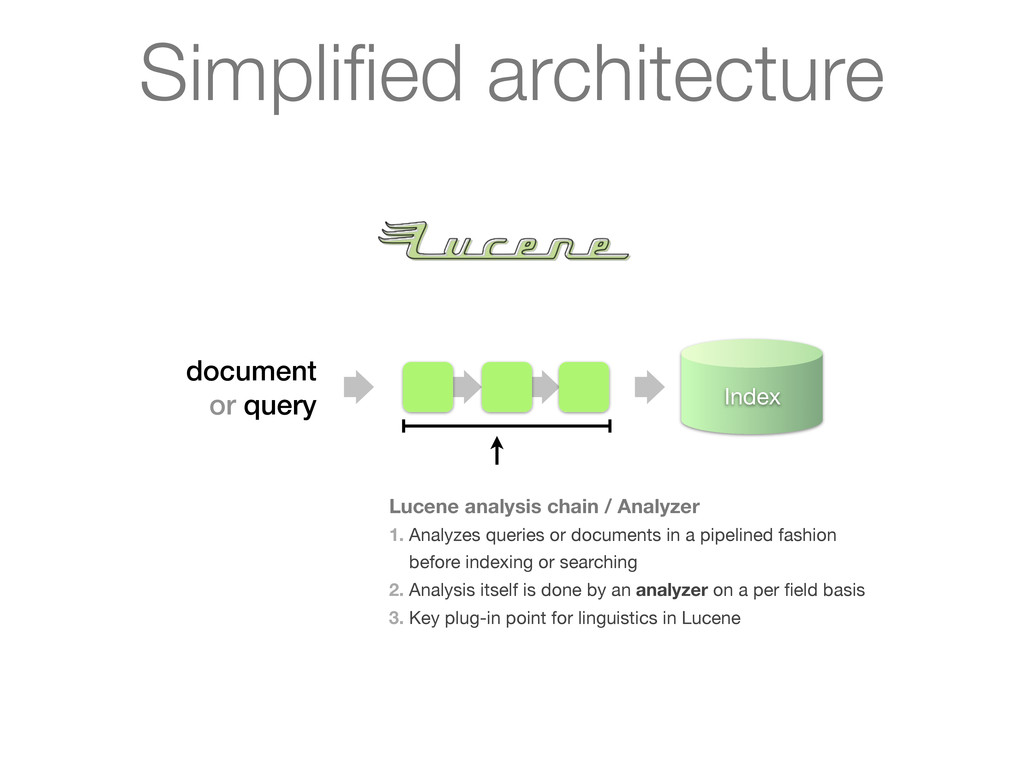
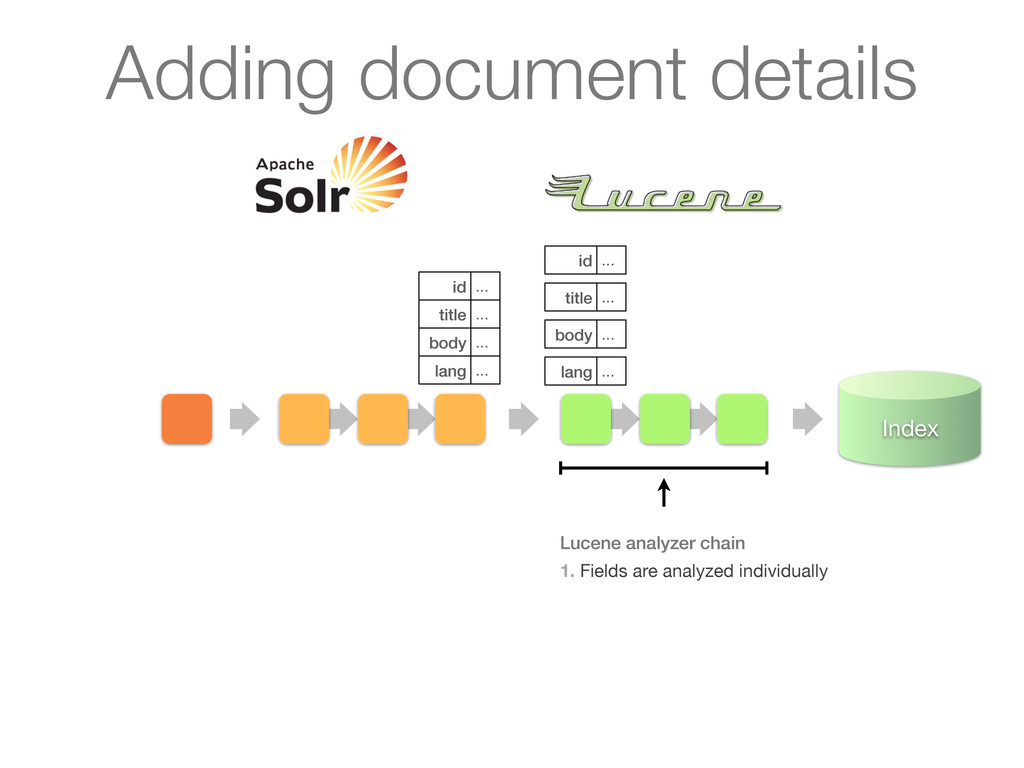
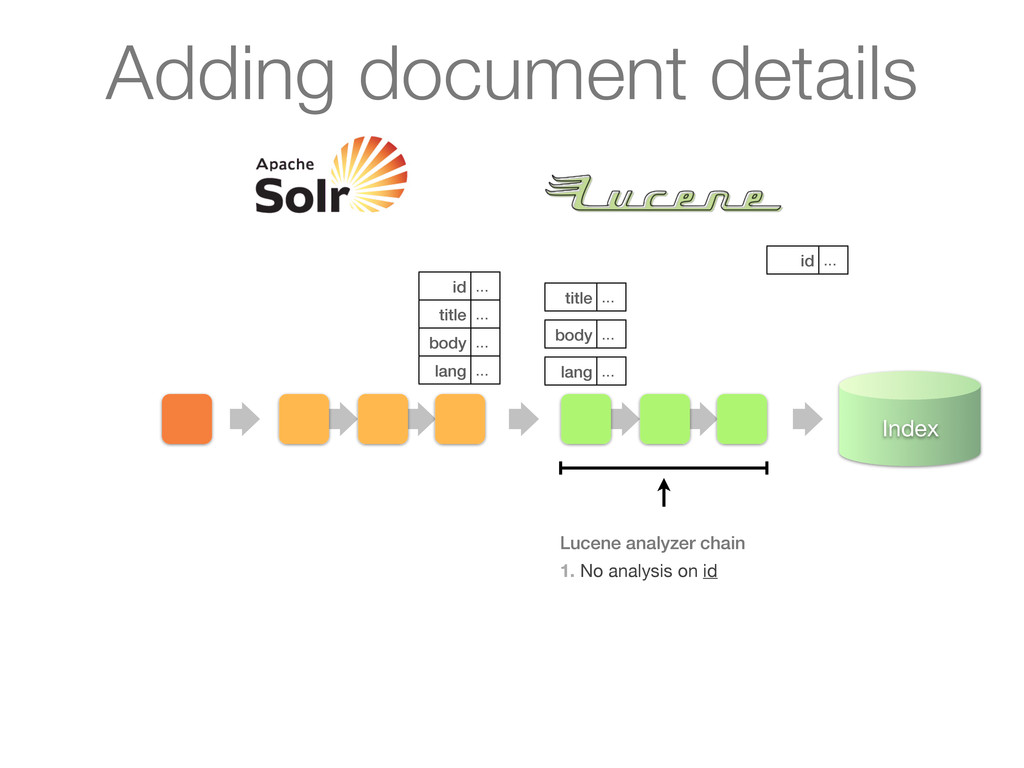
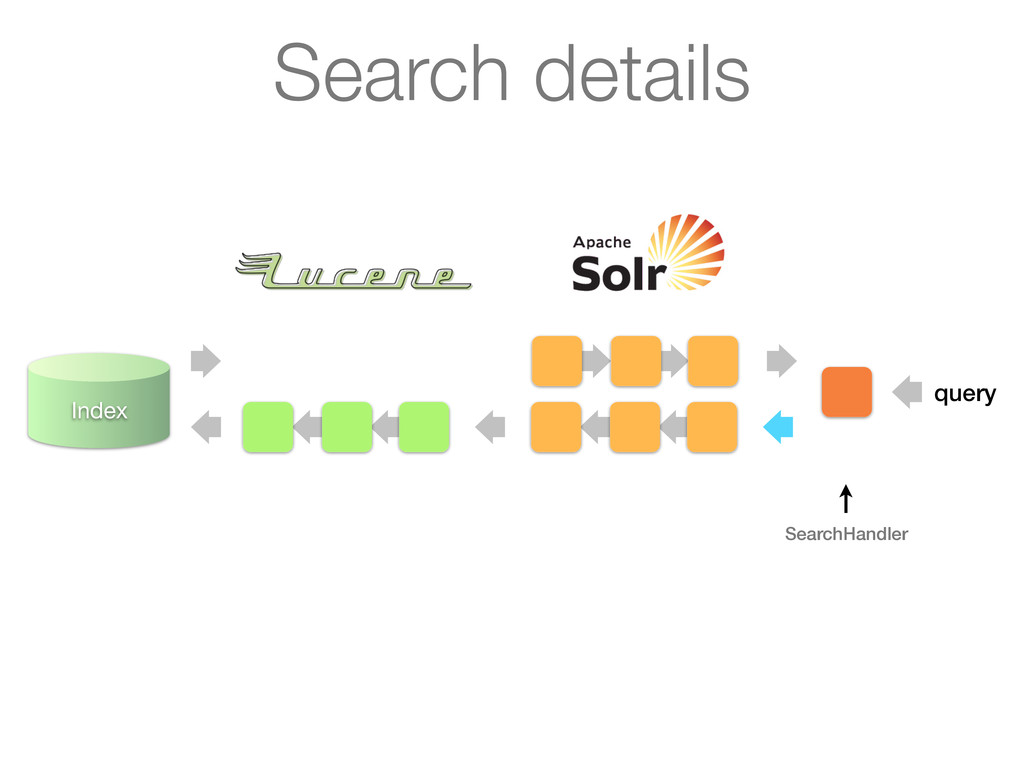
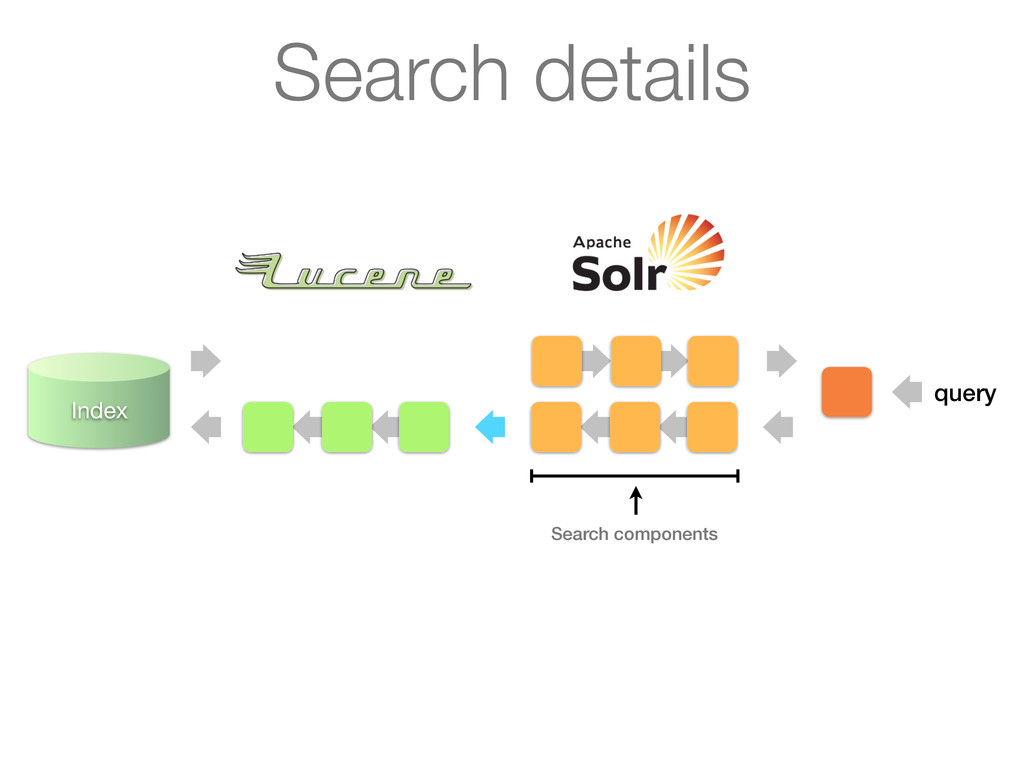
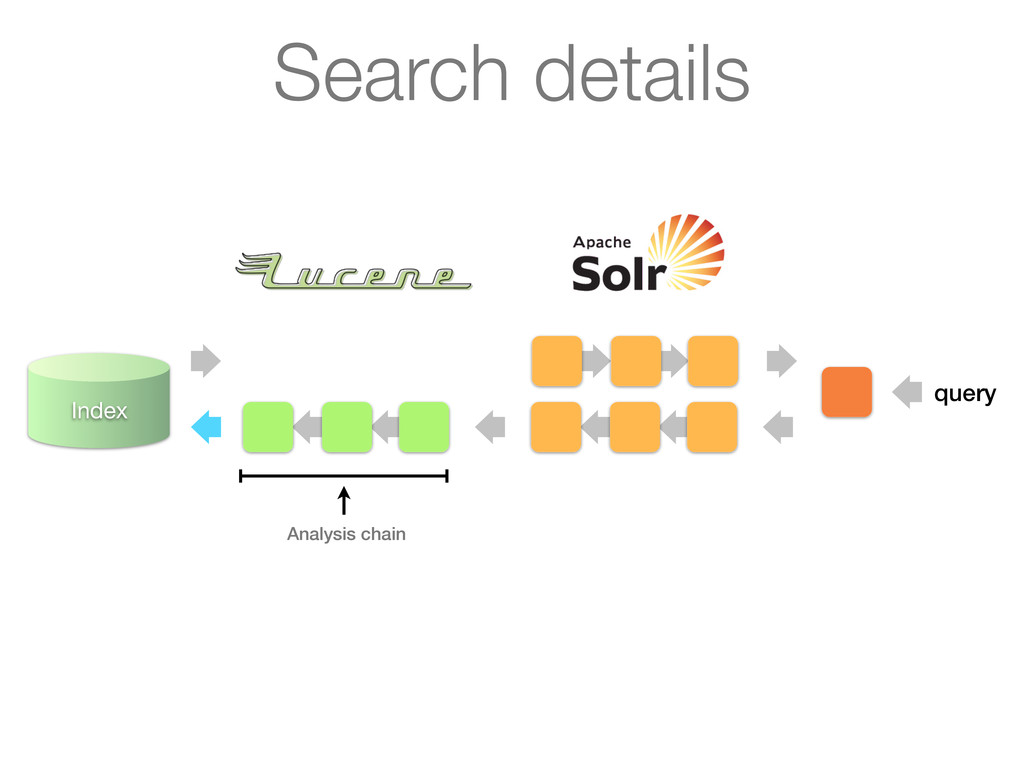
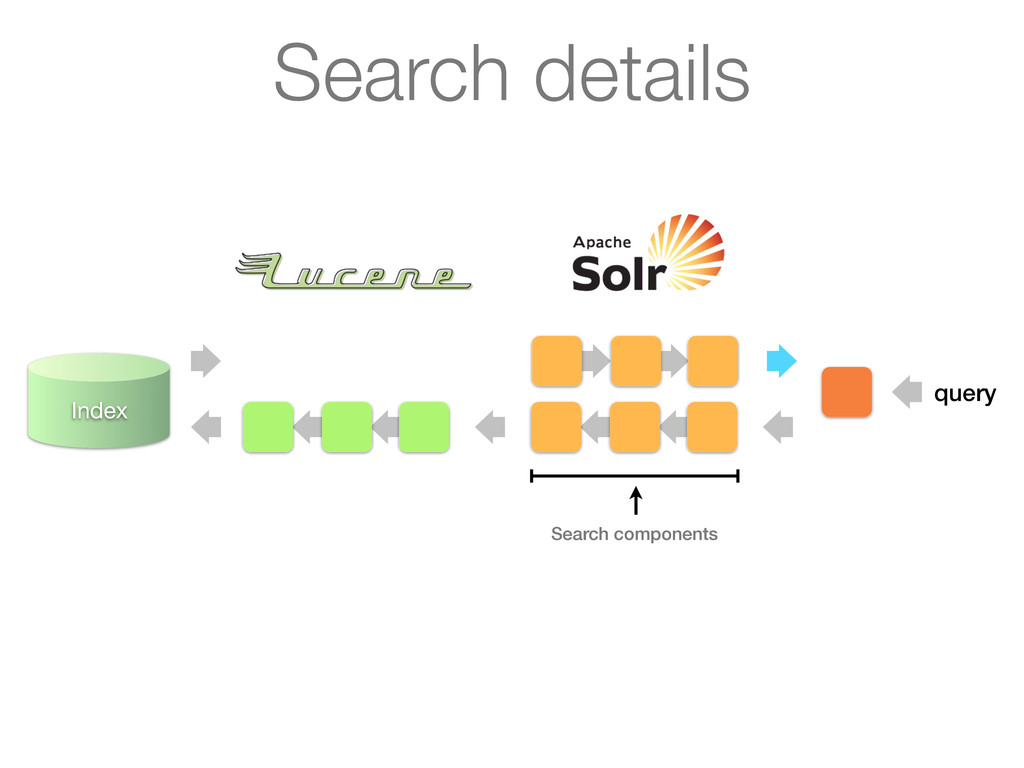
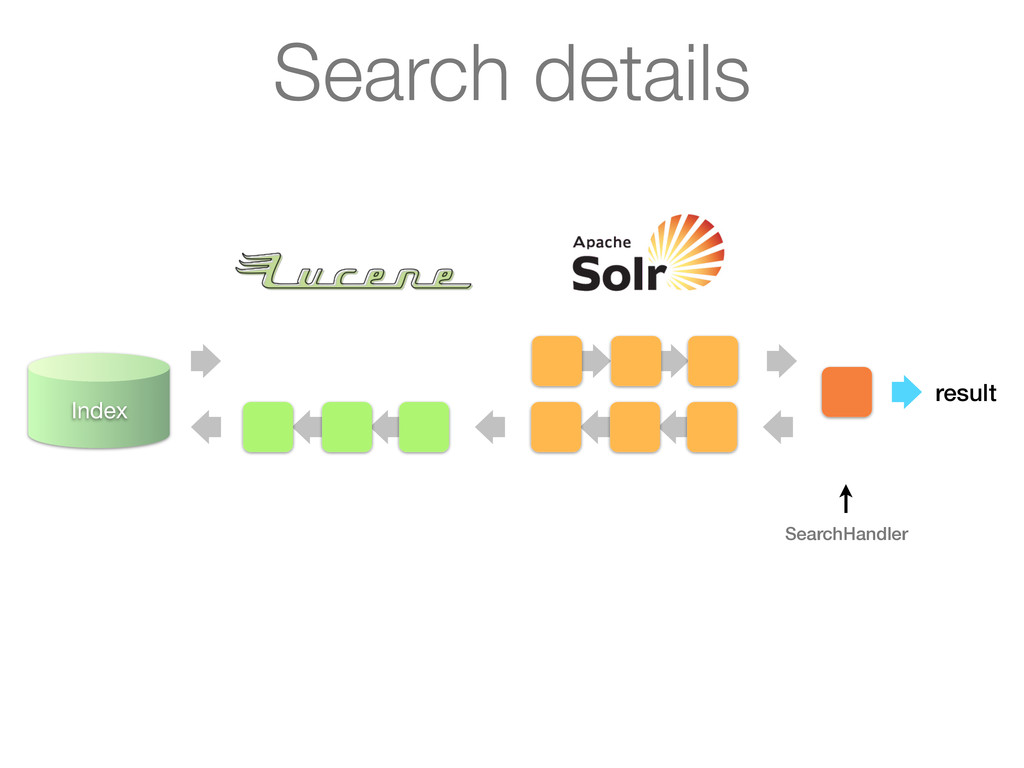
Analyzes queries or documents in a pipelined fashion before indexing or searching 2. Analysis itself is done by an analyzer on a per field basis 3. Key plug-in point for linguistics in Lucene Simplified architecture
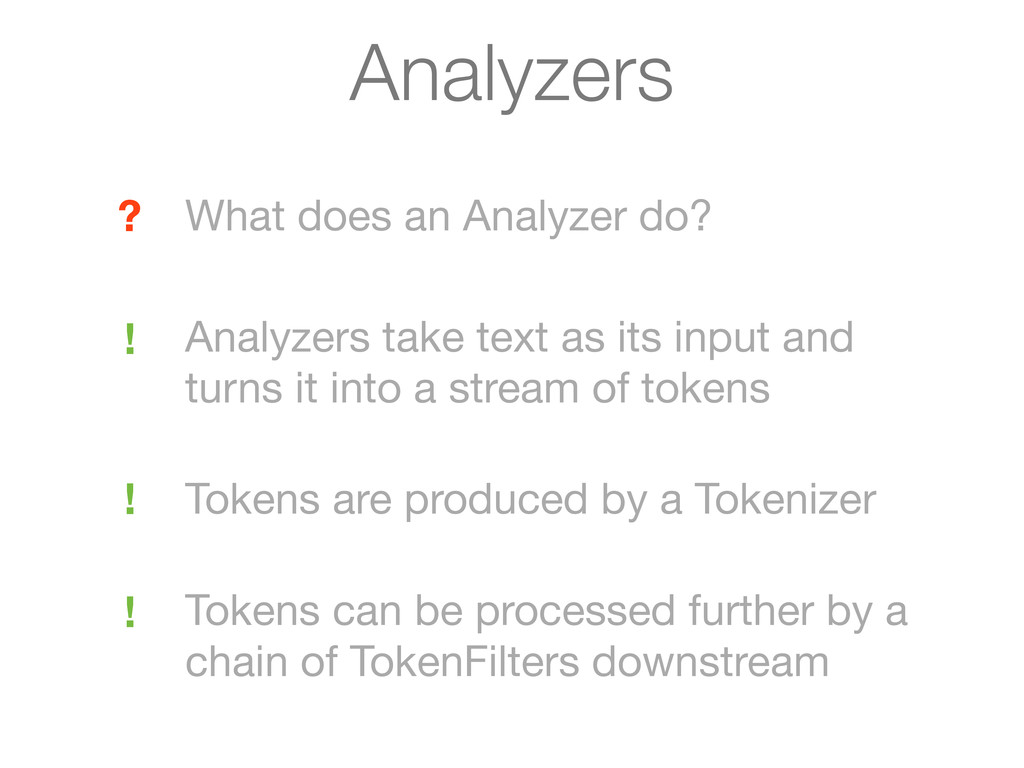
as its input and turns it into a stream of tokens Tokens are produced by a Tokenizer Tokens can be processed further by a chain of TokenFilters downstream ! ! Analyzers
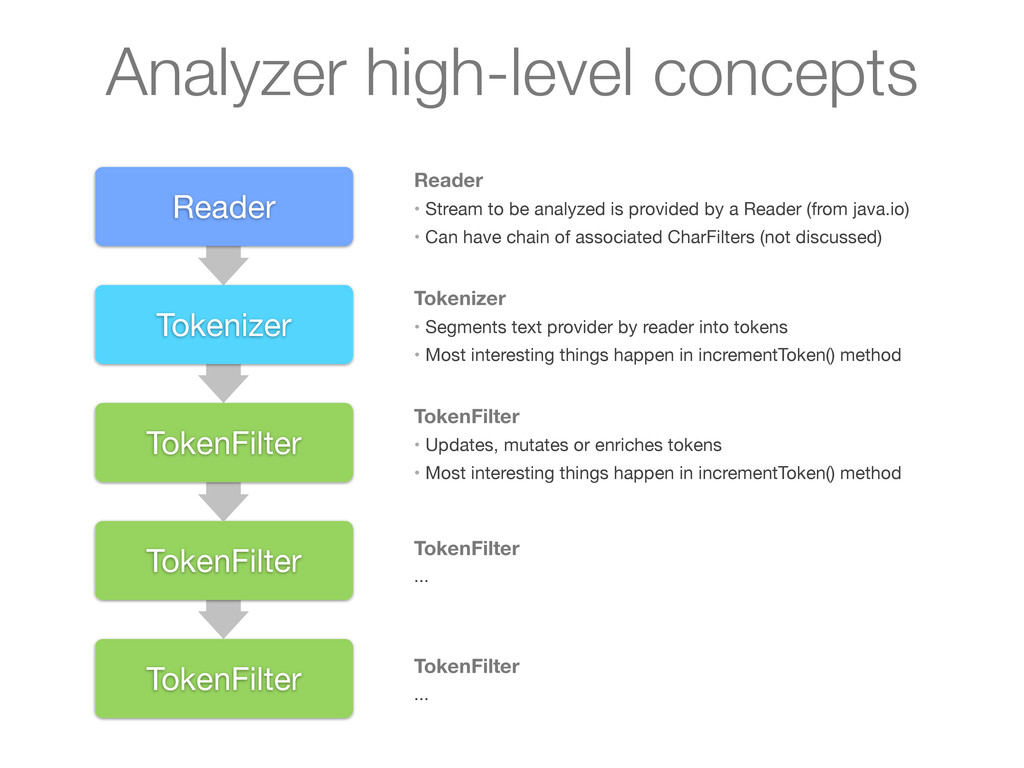
Stream to be analyzed is provided by a Reader (from java.io) • Can have chain of associated CharFilters (not discussed) Tokenizer • Segments text provider by reader into tokens • Most interesting things happen in incrementToken() method TokenFilter • Updates, mutates or enriches tokens • Most interesting things happen in incrementToken() method TokenFilter ... TokenFilter ...
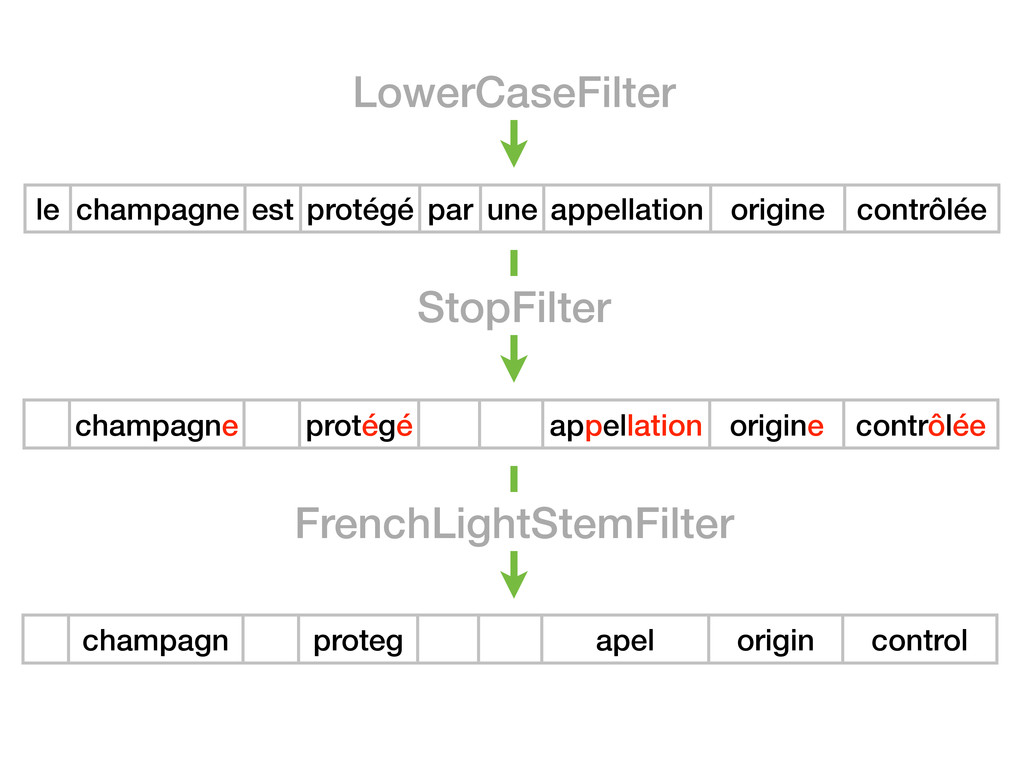
Le champagne est protégé par une appellation d'origine contrôlée ElisionFilter Le champagne est protégé par une appellation origine contrôlée FrenchAnalyzer
Le champagne est protégé par une appellation d'origine contrôlée ElisionFilter Le champagne est protégé par une appellation origine contrôlée FrenchAnalyzer LowerCaseFilter
by calling tokenStream(field, reader) • tokenStream() bundles together tokenizers and any additional filters necessary for analysis •Input is advanced by incrementToken() • Information about the token itself is provided by so-called TokenAttributes attached to the stream • Attribute for term text, offset, token type, etc. • TokenAttributes are updated on incrementToken()
tools for improving recall • Two types of synonyms • One way/mapping “sparkling wine => champagne” • Two way/equivalence “aoc, appellation d'origine contrôlée” • Can be applied index-time or query-time • Apply synonyms on one side - not both • Best practice is to apply synonyms query-side • Allows for updating synonyms without reindexing • Allows for turning synonyms on and off easily
• Analyzers are made available through a provider interface • Some analyzers available through plugins, i.e. kuromoji, smartcn, icu, etc. • Analyzers can be set up in your mapping • Analyzers can also be chosen based on a field in your document, i.e. a lang field
• Linguistic processing is defined by field types in schema.xml • Different processing can be applied on indexing and querying side if desired • A rich set of pre-defined and ready-to-use per- language field types are available • Defaults can be used as starting points for further configuration or as they are
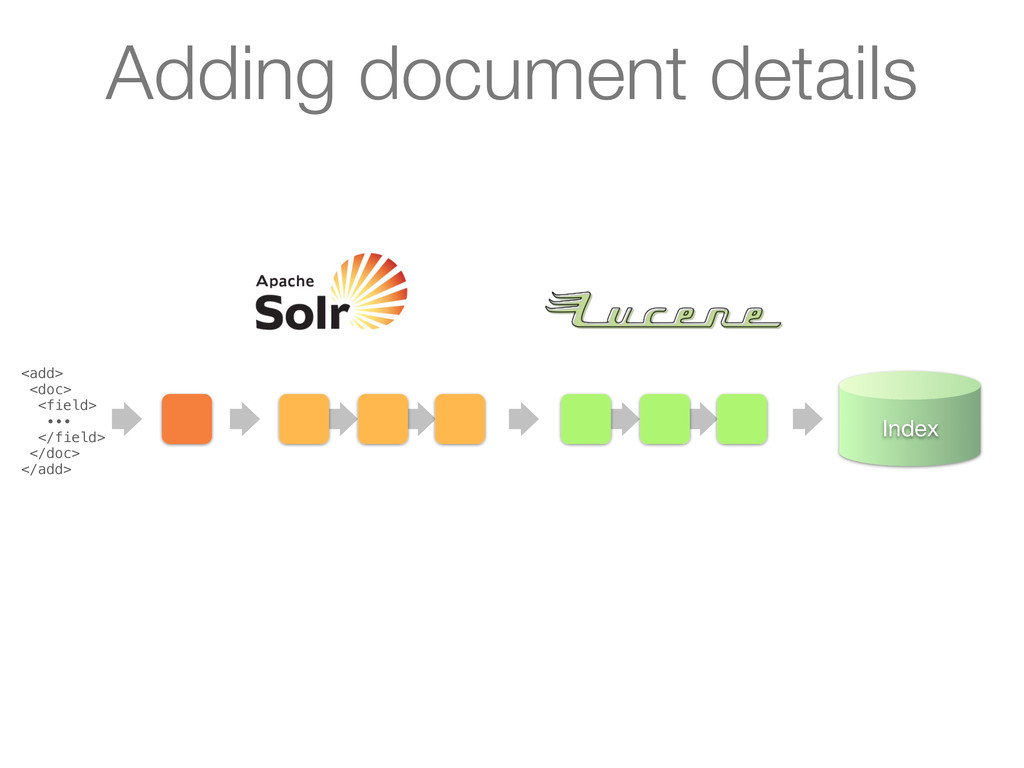
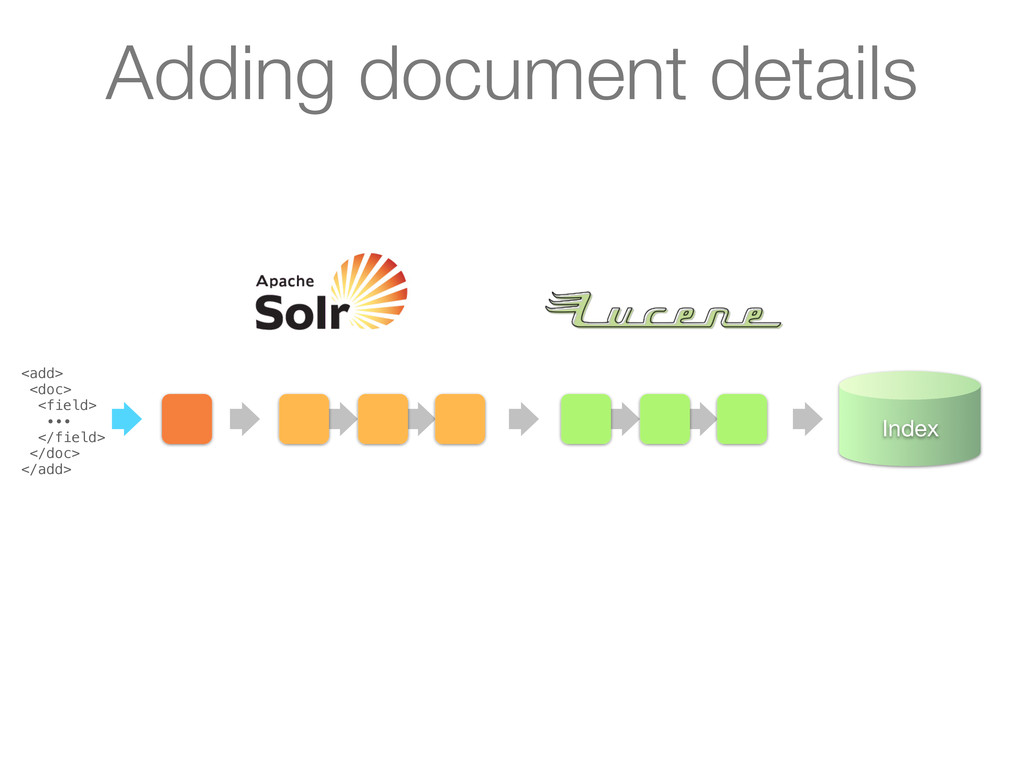
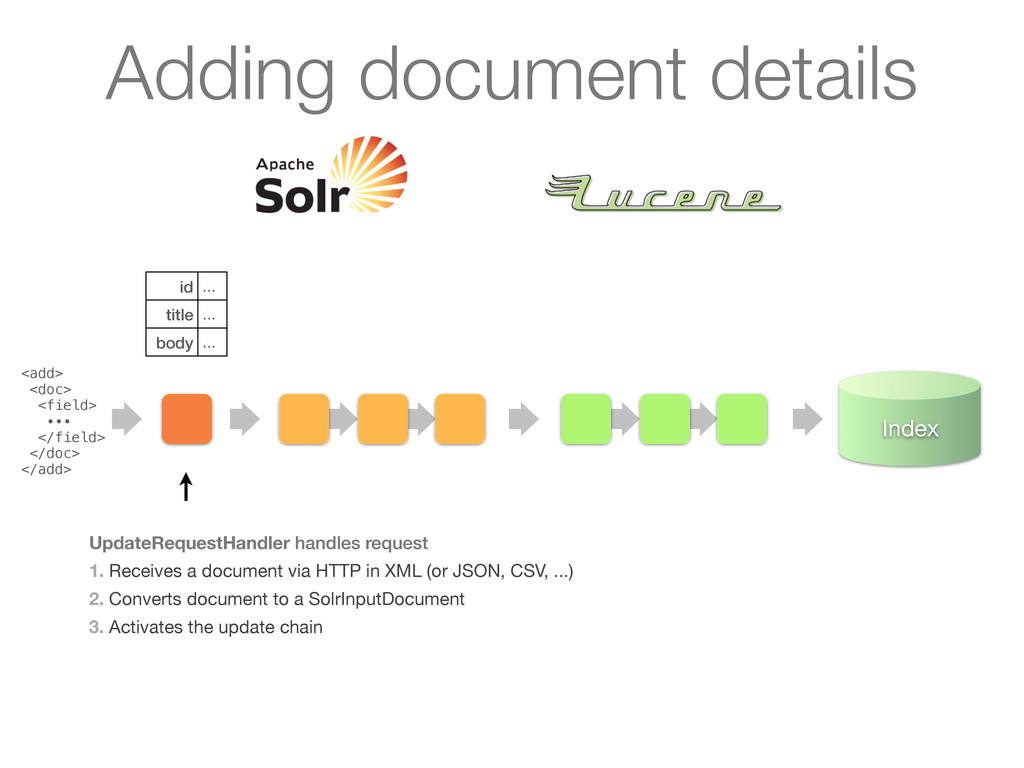
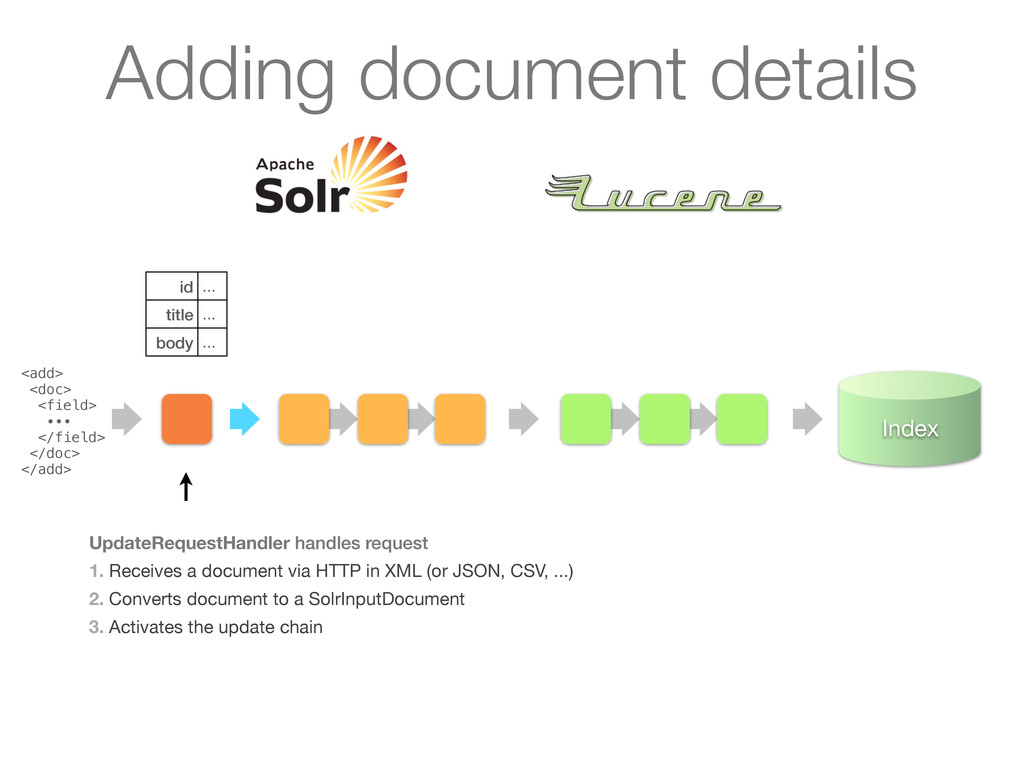
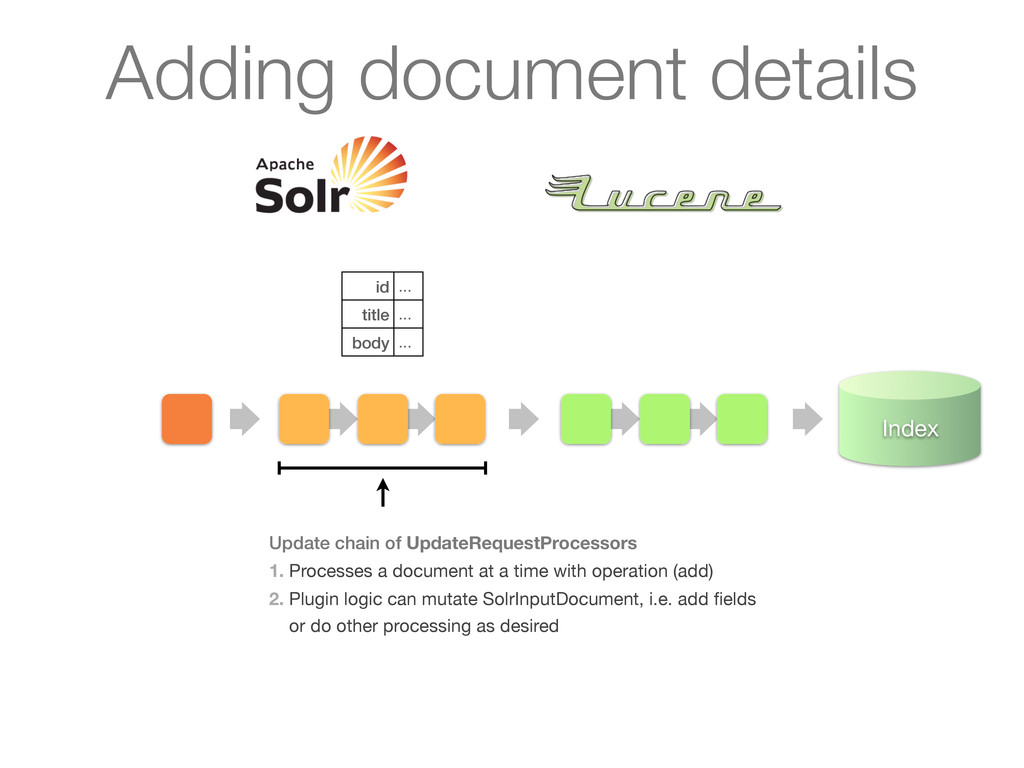
∙∙∙ </field> </doc> </add> UpdateRequestHandler handles request 1. Receives a document via HTTP in XML (or JSON, CSV, ...) 2. Converts document to a SolrInputDocument 3. Activates the update chain Adding document details
1. Receives a document via HTTP in XML (or JSON, CSV, ...) 2. Converts document to a SolrInputDocument 3. Activates the update chain <add> <doc> <field> ∙∙∙ </field> </doc> </add> Adding document details
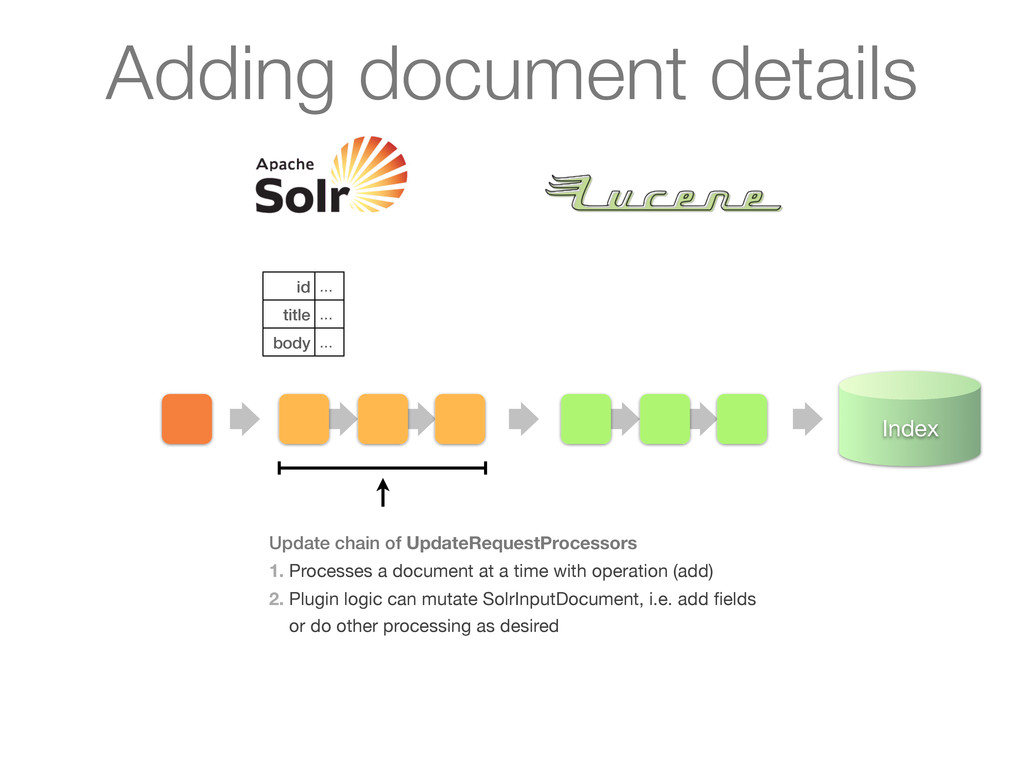
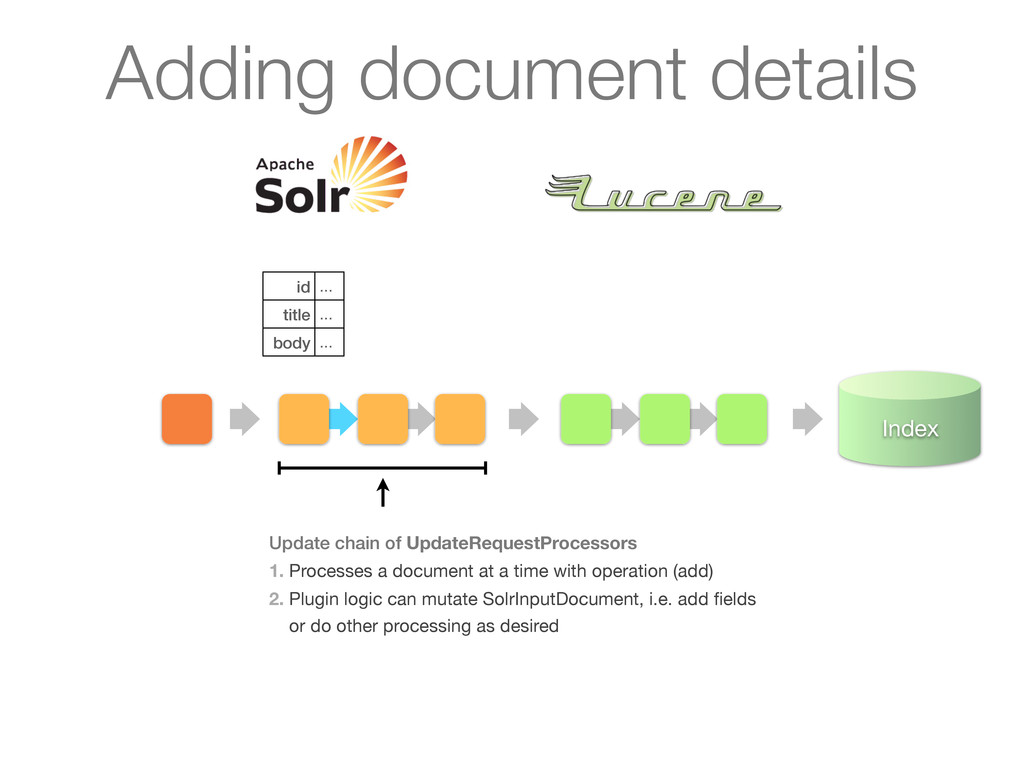
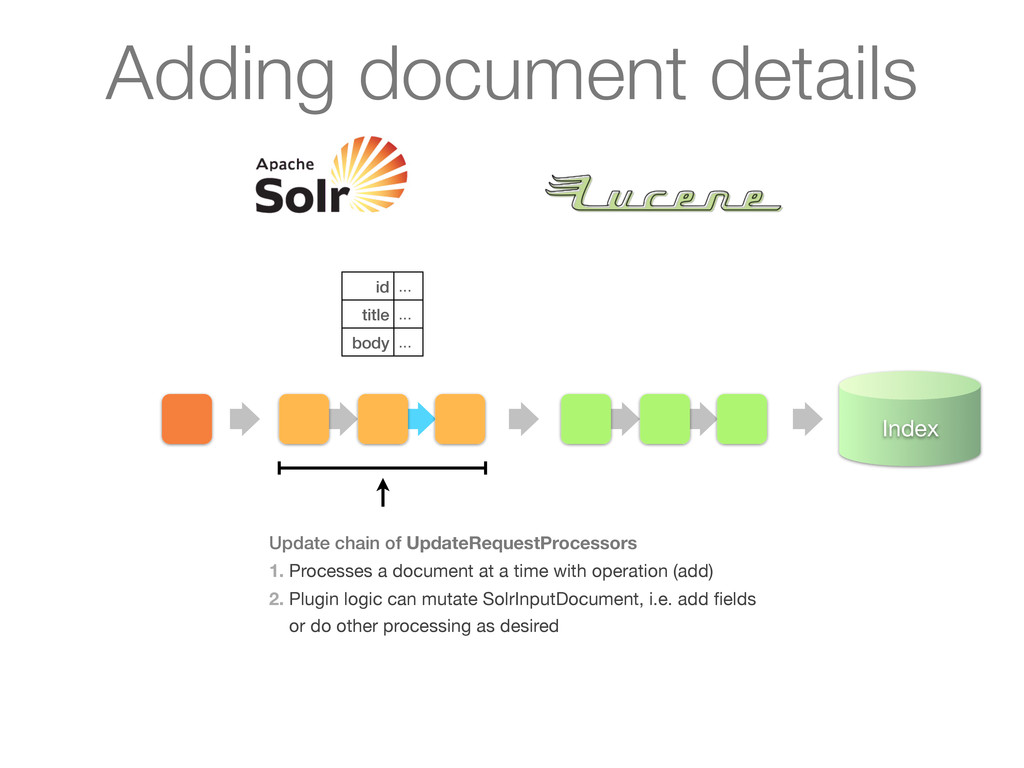
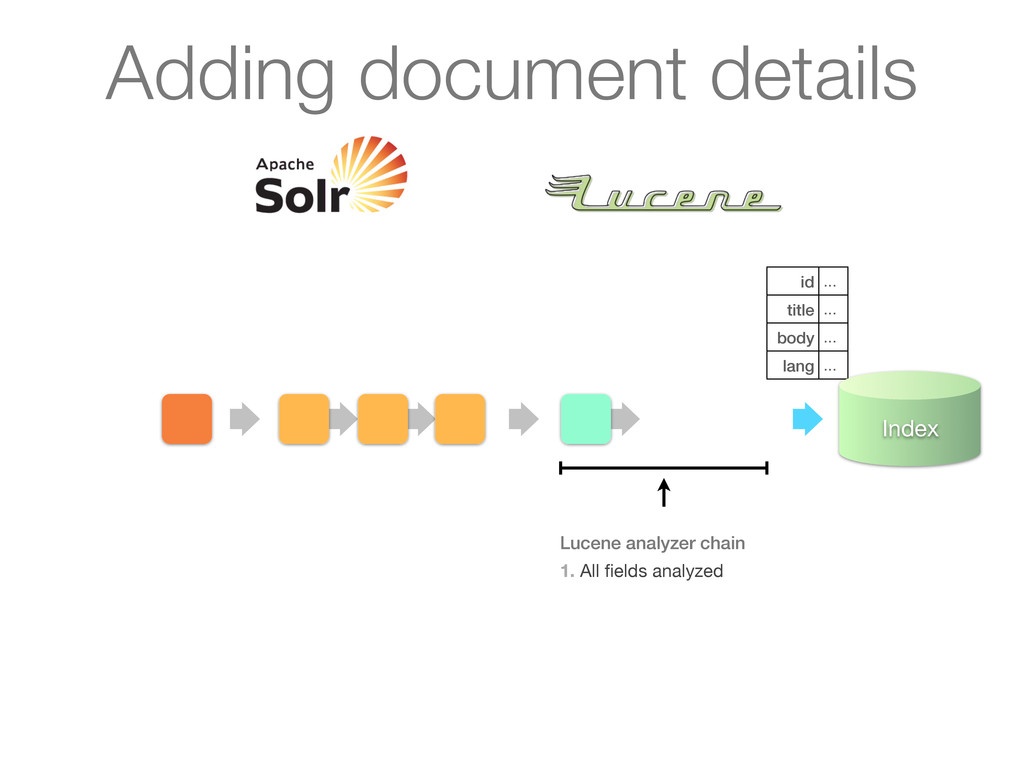
UpdateRequestProcessors 1. Processes a document at a time with operation (add) 2. Plugin logic can mutate SolrInputDocument, i.e. add fields or do other processing as desired Adding document details
UpdateRequestProcessors 1. Processes a document at a time with operation (add) 2. Plugin logic can mutate SolrInputDocument, i.e. add fields or do other processing as desired Adding document details
UpdateRequestProcessors 1. Processes a document at a time with operation (add) 2. Plugin logic can mutate SolrInputDocument, i.e. add fields or do other processing as desired Adding document details
UpdateRequestProcessors 1. Processes a document at a time with operation (add) 2. Plugin logic can mutate SolrInputDocument, i.e. add fields or do other processing as desired Adding document details
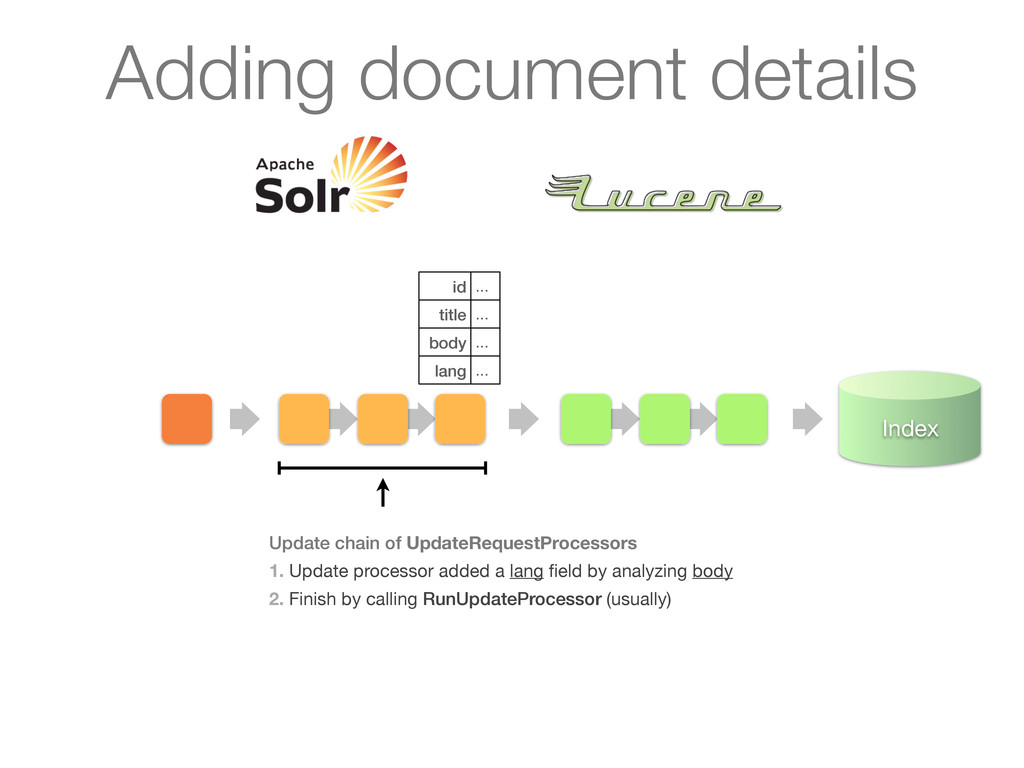
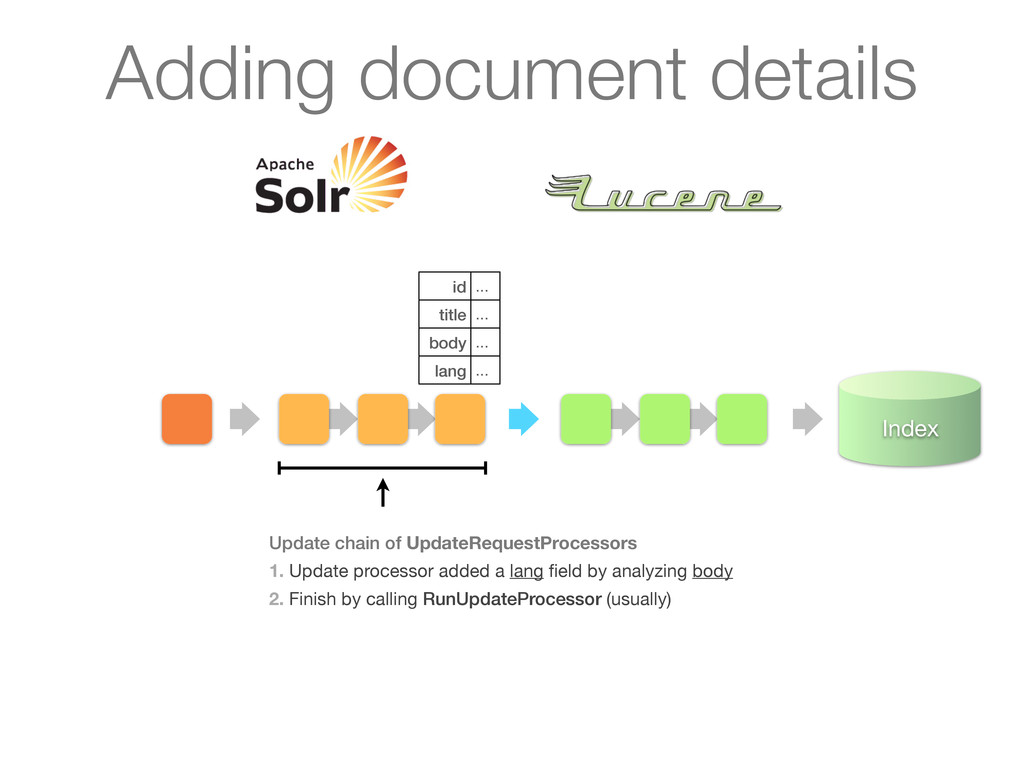
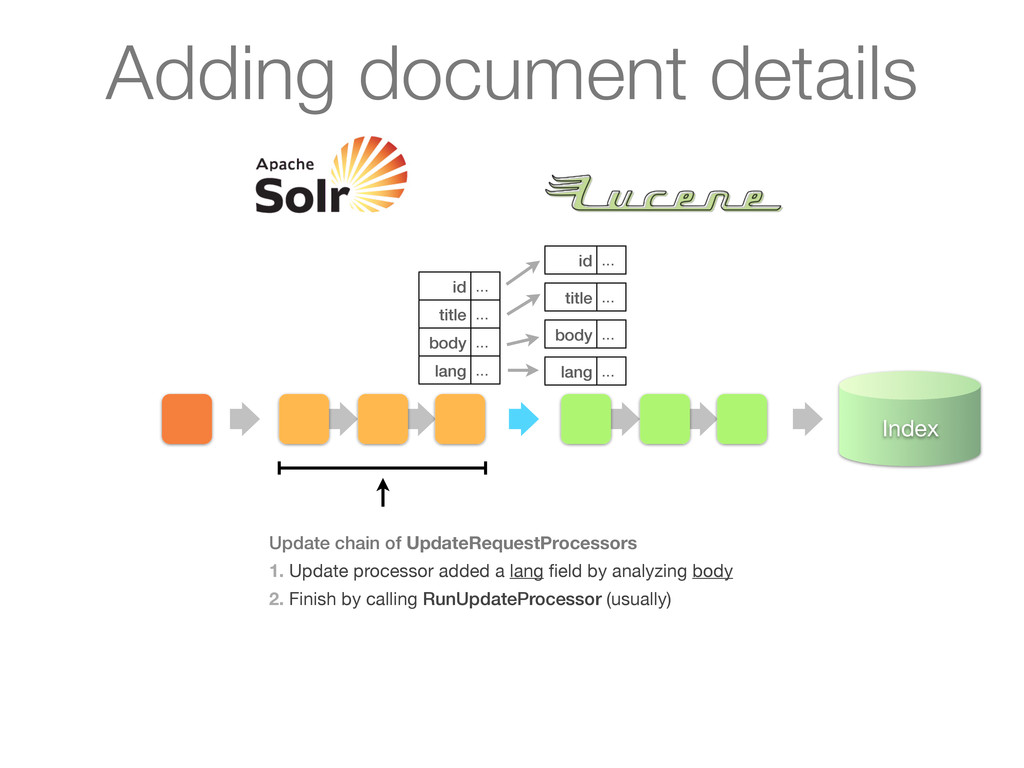
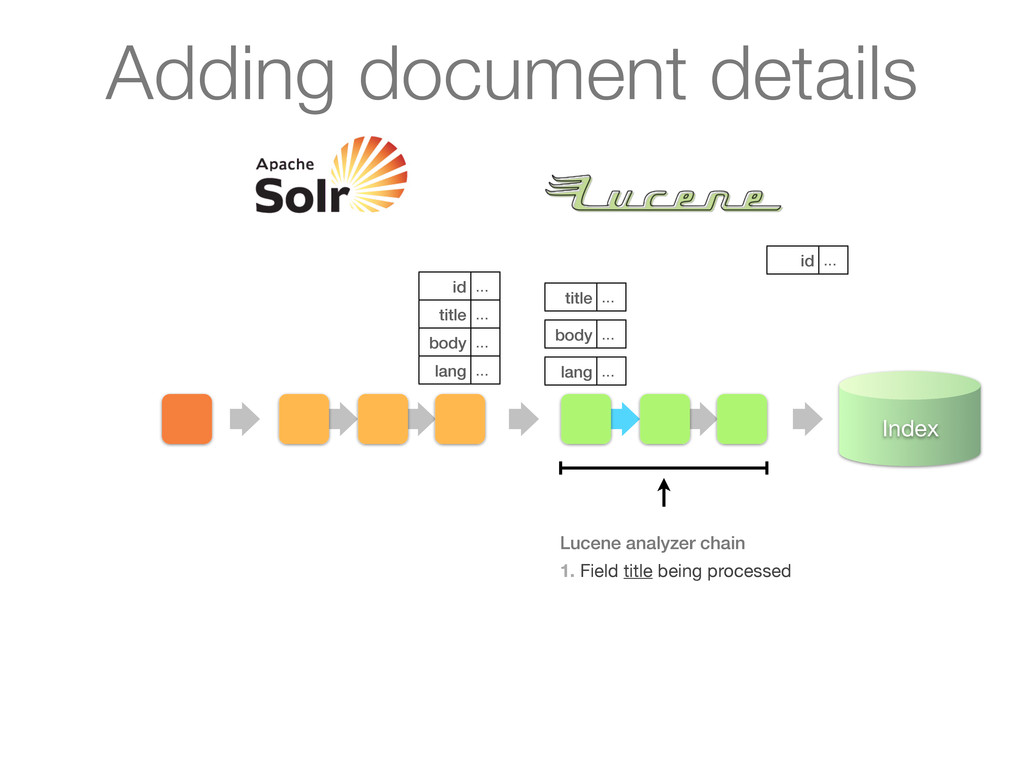
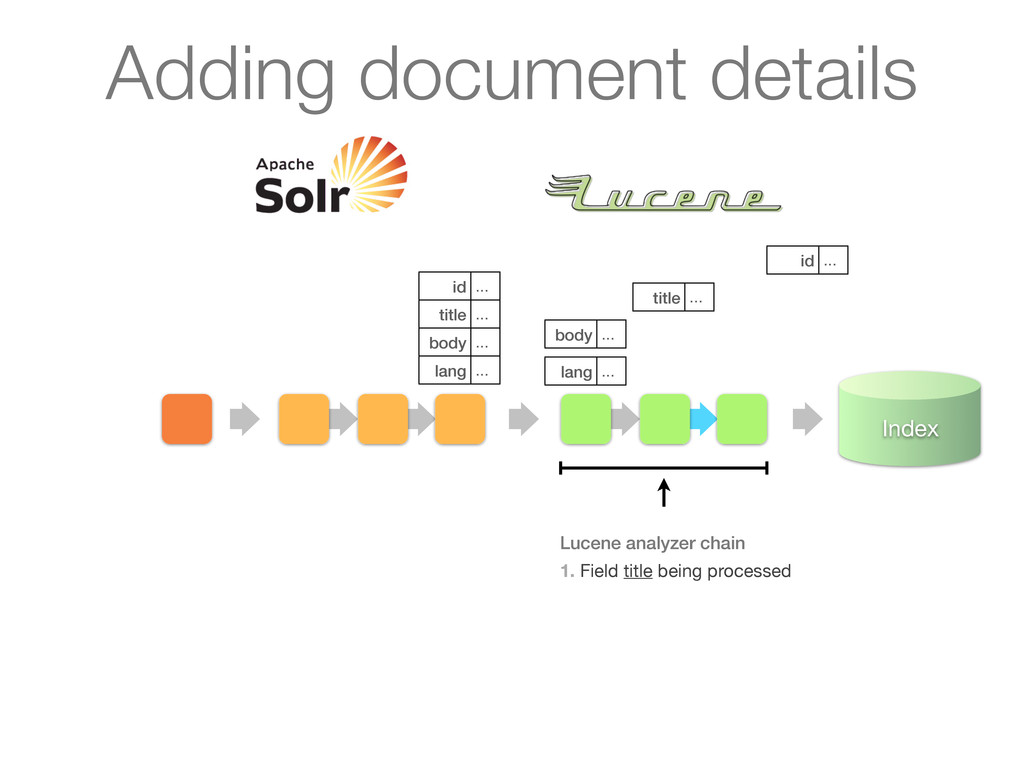
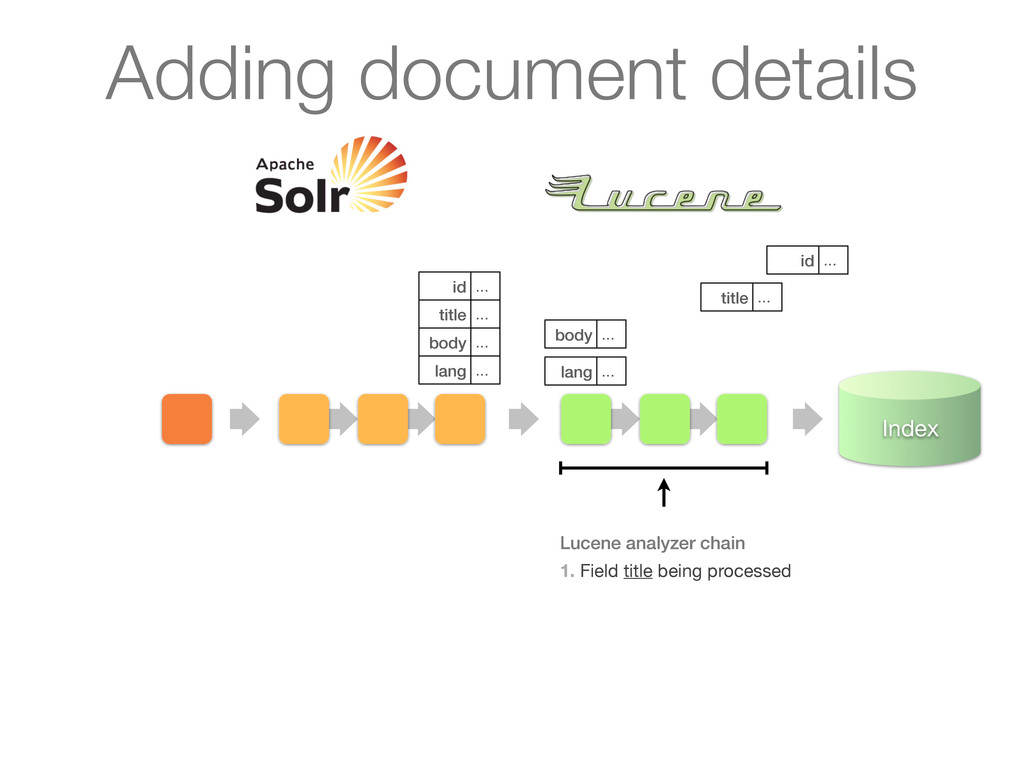
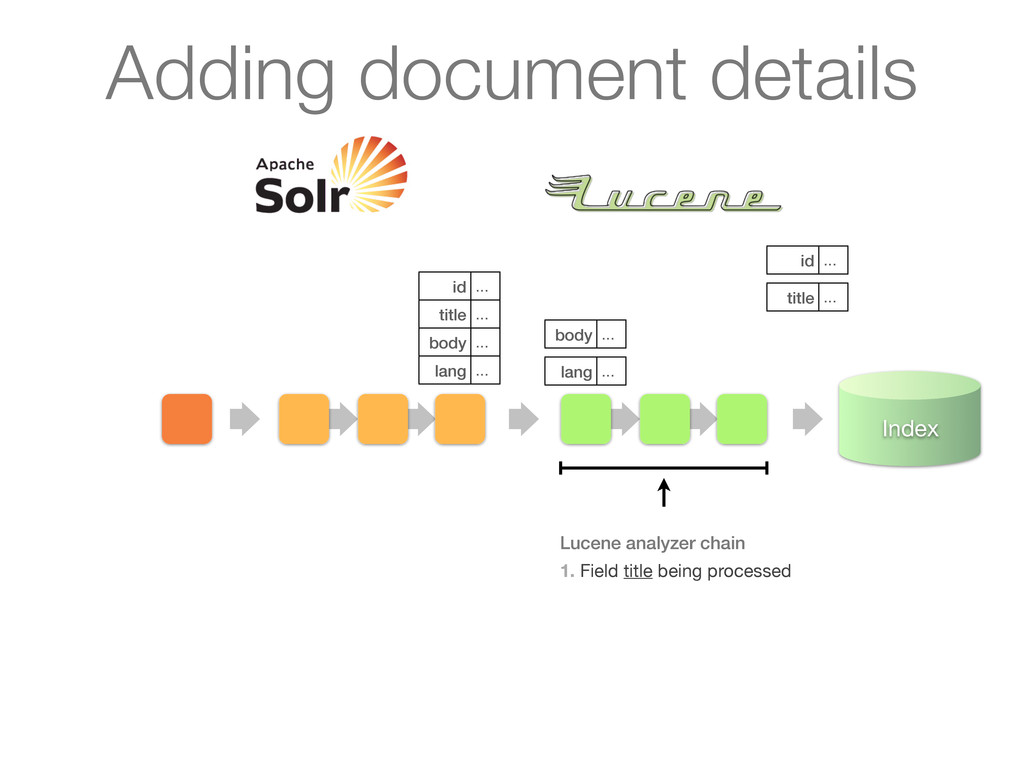
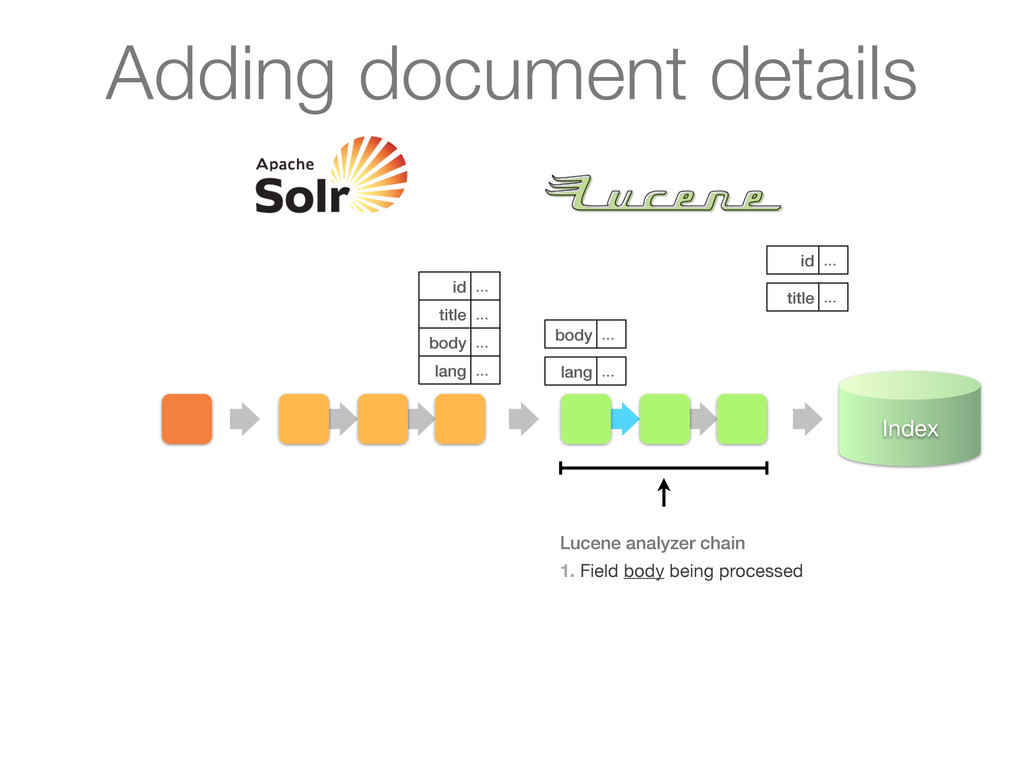
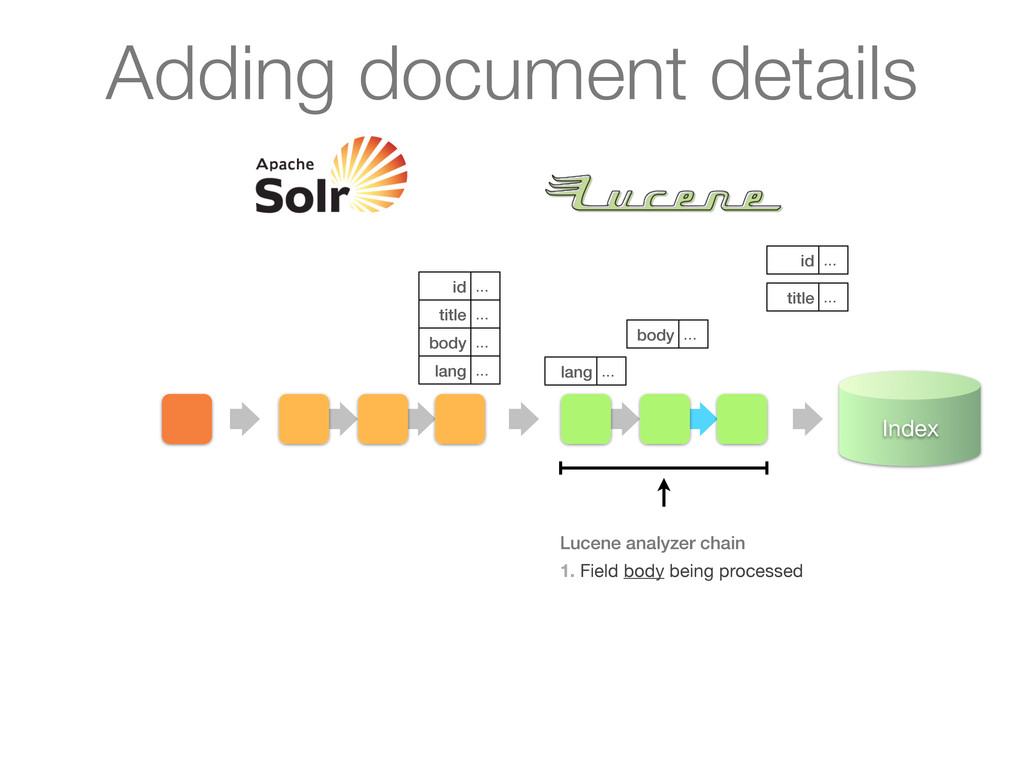
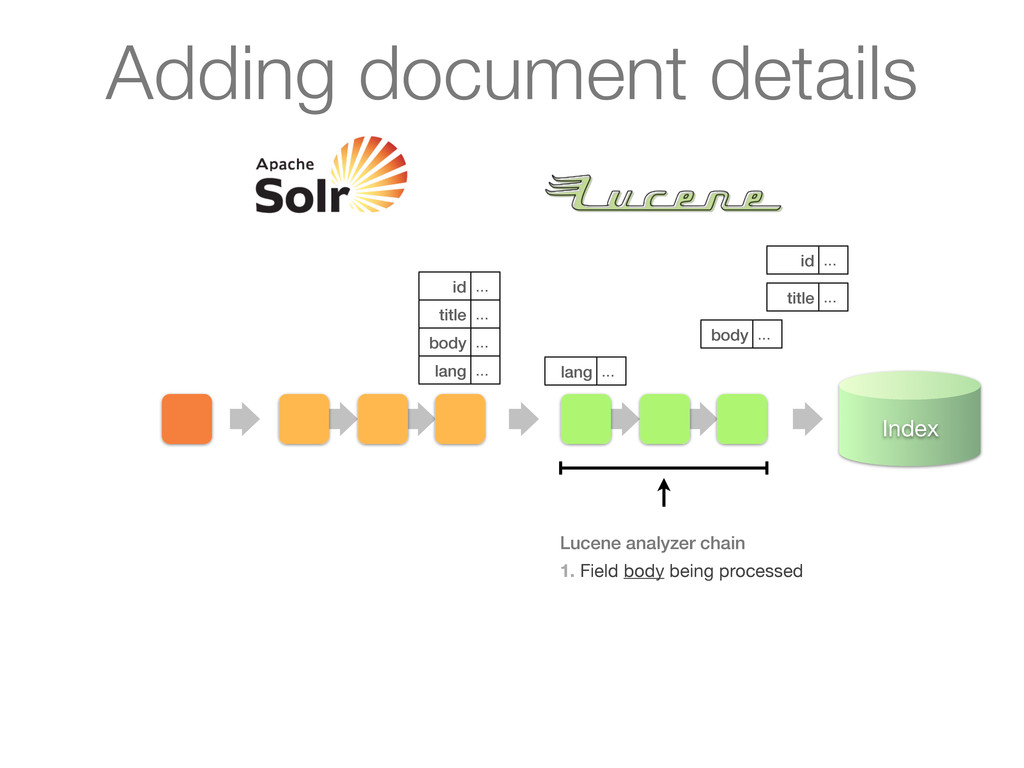
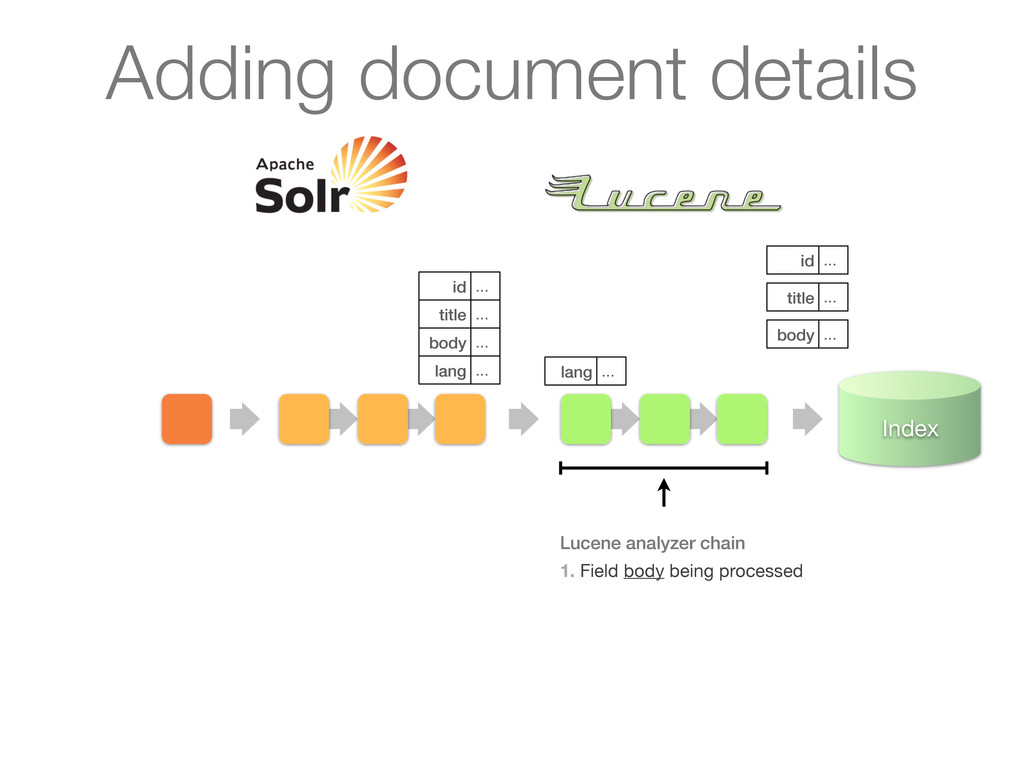
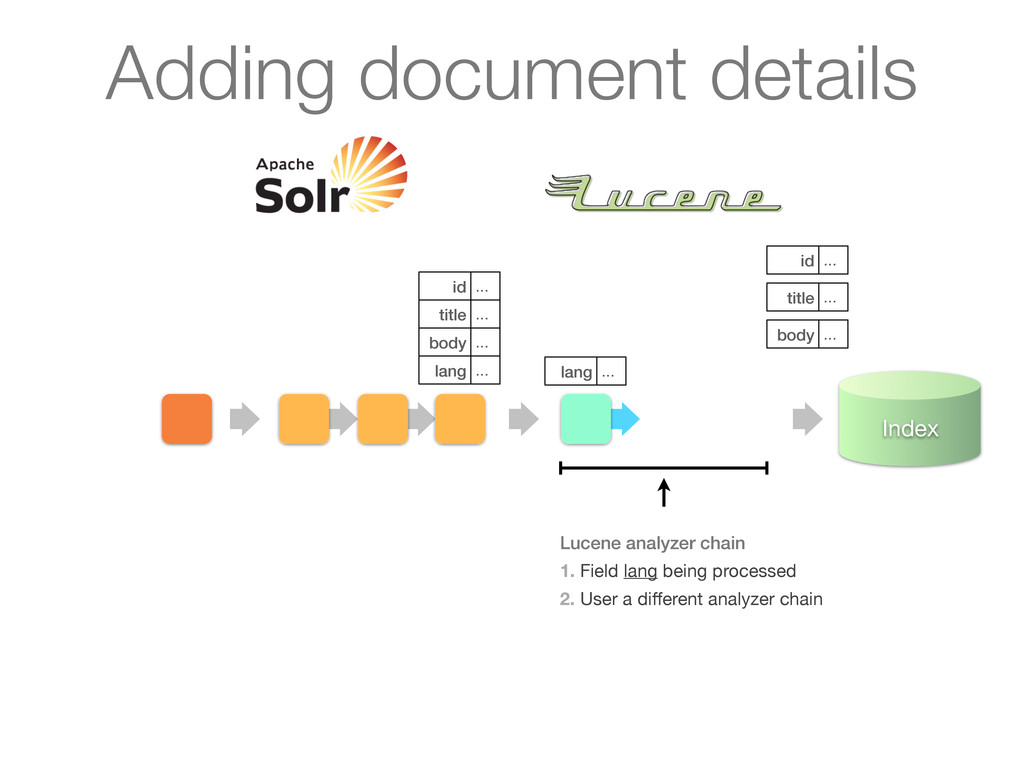
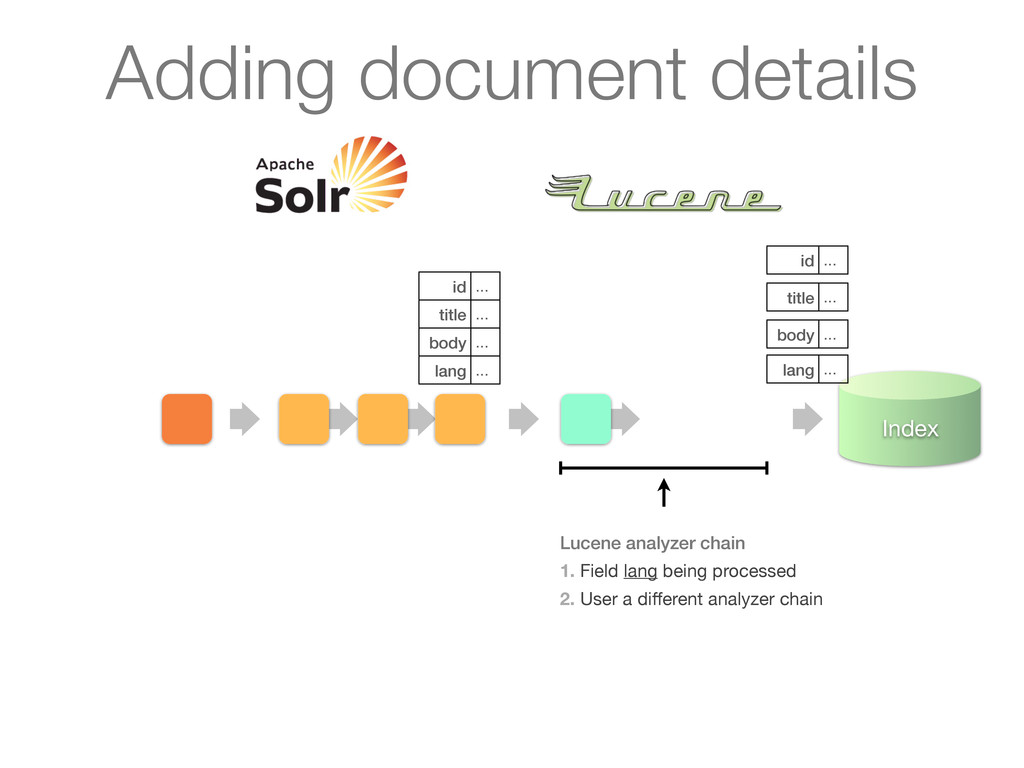
chain of UpdateRequestProcessors 1. Update processor added a lang field by analyzing body 2. Finish by calling RunUpdateProcessor (usually) Adding document details
chain of UpdateRequestProcessors 1. Update processor added a lang field by analyzing body 2. Finish by calling RunUpdateProcessor (usually) Adding document details
chain of UpdateRequestProcessors 1. Update processor added a lang field by analyzing body 2. Finish by calling RunUpdateProcessor (usually) id ... title ... body ... lang ... Adding document details
side is feasible (accuracy > 99.1%), but query side is hard because of ambiguity •How to deal with language query side? • Supply language to use in the application (best if possible) • Search all relevant language variants (OR query) • Search a fallback field using n-gramming • Boost important language or content Not knowing query term language will most likely impact negatively on overall rank
Rosette Linguistics Platform (RLP) highlights • Language and encoding identification (55 languages and 45 encodings) • Segmentation for Chinese, Japanese and Korean • De-compounding for German, Dutch, Korean, etc. • Lemmatization for a range of languages • Part-of-speech tagging for a range of language • Sentence boundary detection • Named entity extraction • Name indexing, transliteration and matching • Integrates well with Lucene/Solr
a range of common and best-practice algorithms • Very easy-to-use tools and APIs targeted towards NLP • Features and applications • Tokenization • Sentence segmentation • Part-of-speech tagging • Named entity recognition • Chunking • Licensing terms • Code itself has an Apache License 2.0 • Some models are available, but licensing terms and F-scores are unclear... • See LUCENE-2899 for OpenNLP a Lucene Analyzer (work-in-progress)
helps improve search quality •Linguistics in Lucene, ElasticSearch and Solr • A wide range of languages are supported out-of-the-box • Considerations to be made on indexing and query side • Lucene Analyzers work on a per-field level • Solr UpdateRequestProcessors work on the document level • Solr has functionality for automatically detecting language (available in ElasticSearch as a plugin) •Linguistics options also available in the eco-system
• Understand your language and its issues • Understand what users want from search • Do you have issues with recall? • Consider synonyms, stemming • Consider compound-segmentation for European languages • Consider WordDelimiterFilter, phonetic matching • Do you have issues with precision? • Consider using ANDs instead of ORs for terms • Consider improving content quality? Search fewer fields? • Is some content more important than other? • Consider boosting content with a boost query
•Get started using • git clone git://github.com/atilika/berlin-buzzwords-2013.git • less berlin-buzzwords-2013/README.md •Contact us if you have any questions • [email protected] •
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}