近年, LLM(Large Language Model)の大規模化に伴い, 推論速度の低下, メモリ使用量の増大, および電力コストの上昇といった課題が顕在化している. これらの課題に対処するため, 実数表現を離散化し計算効率を向上させる量子化技術が注目されている. しかし, LLMの量子化において, 極低ビット量子化の実現は困難であることが報告されている. 我々はこの課題に挑戦し, 1bitの極低ビット量子化であっても標準ベンチマーク上で平均90%の性能を維持することに成功した. その成果は, 最近のプレスリリースにて報告している. 本講演では, この成果に至るまでの研究ロードマップを示すとともにLLM量子化のワークフローおよび最新動向を体系的に概観する. さらに, 我々が開発した独自技術である量子化誤差伝搬(Quantization Error Propagation: QEP)および疑似量子アニーリング(Quasi-Quantum Annealing: QQA)の設計思想とその効果を簡単に説明する. そして, 最後に1bit量子化の先にある持続可能な推論基盤への展望を提示する.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
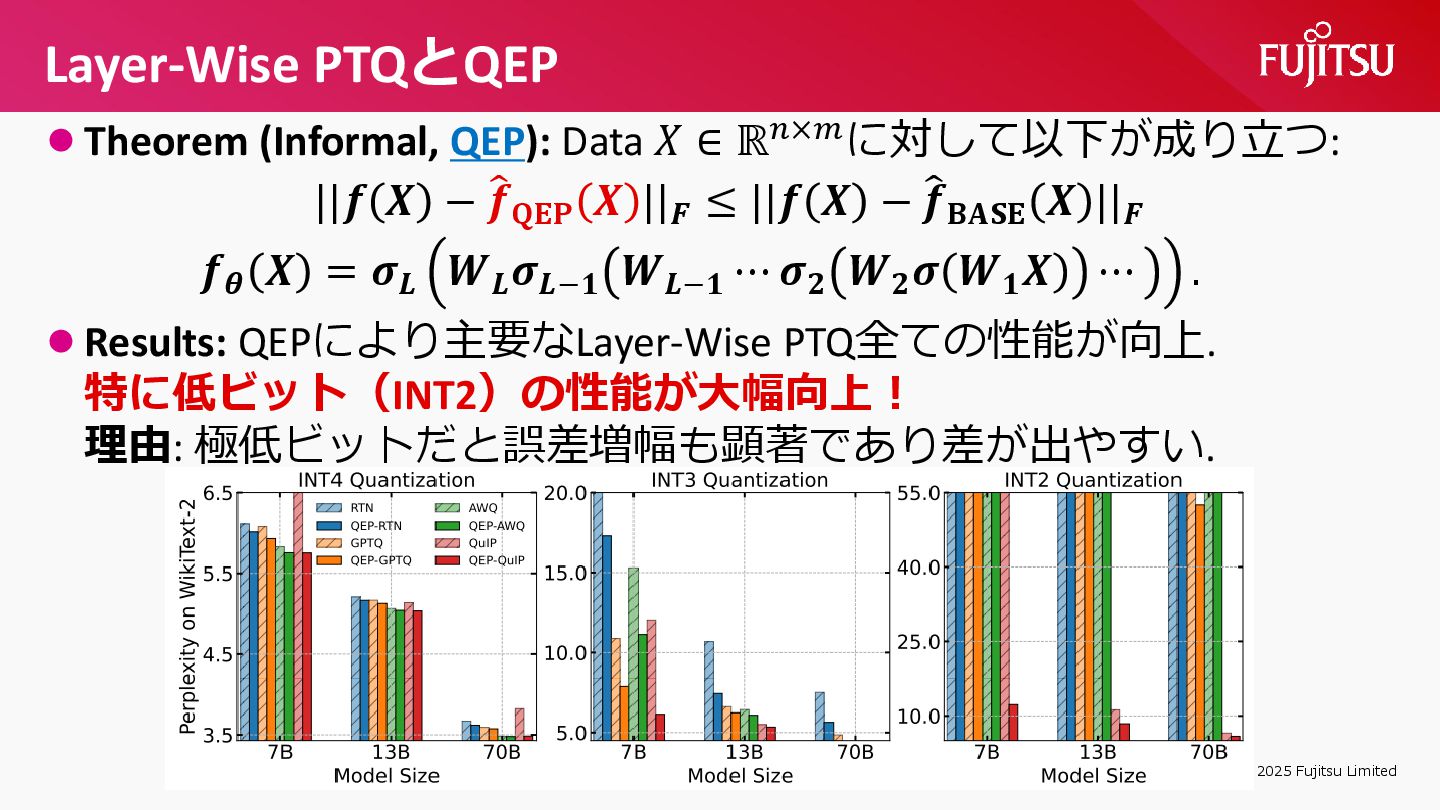{kind=link}
{kind=link}
{kind=link}
{kind=link}
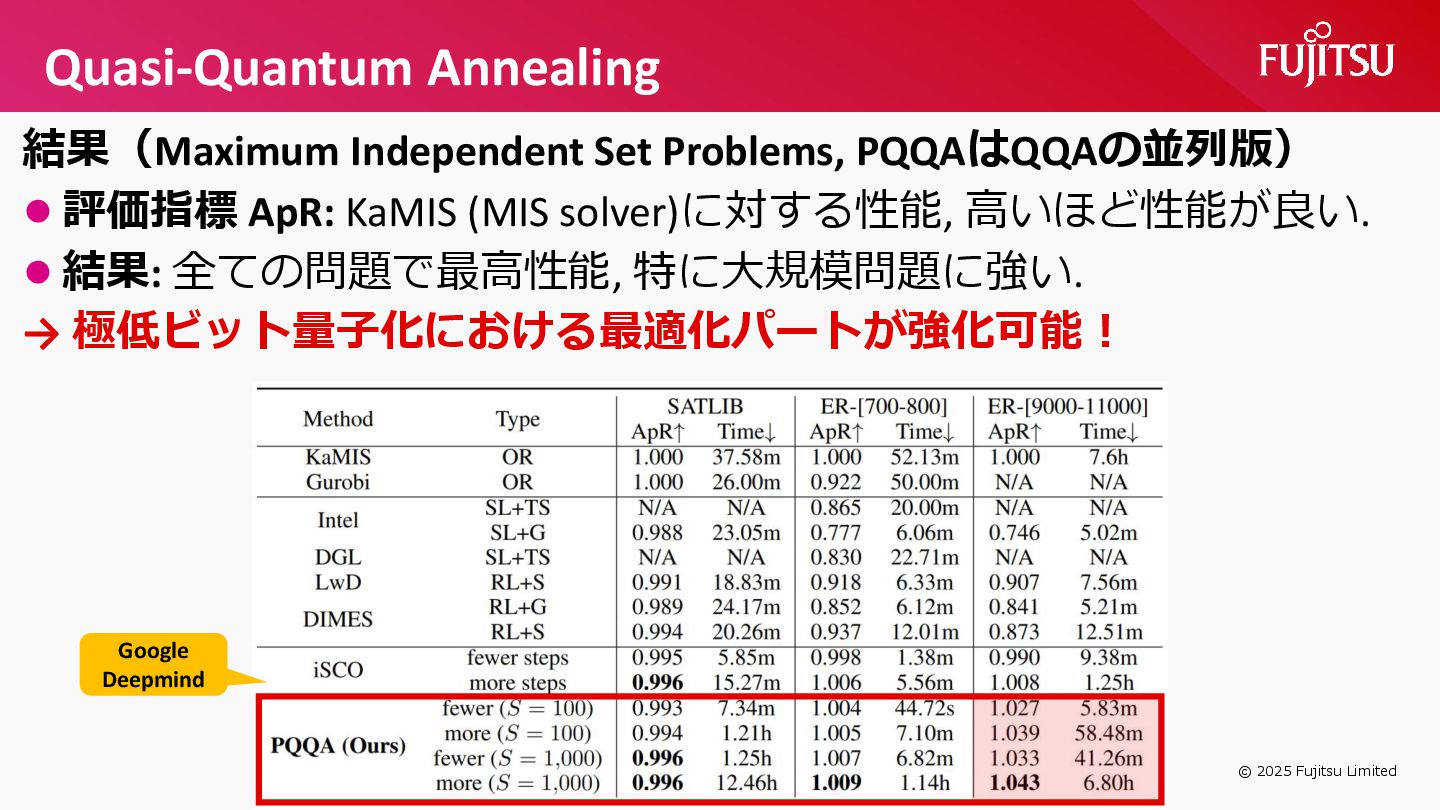{kind=link}
{kind=link}
{kind=link}
![© 2025 Fujitsu Limited 最後に インターン募集中: 1-on-1 mtg or [email protected]にメールでもOK](https://files.speakerdeck.com/presentations/49fbcb2ef355409bae427e2a8a99ddbf/slide_45.jpg){kind=link}
{kind=link}