Jonathan Gray, Athul Paul Jacob, Gabriele Farina, Alexander H Miller, and Noam Brown. Mastering the Game of No-Press Diplomacy via Human- Regularized Reinforcement Learning and Planning. In ICLR, 2023. ▪ Noam Brown and Tuomas Sandholm. Superhuman AI for heads-up no-limit poker: Libratus beats top professionals. Science, 2018. ▪ Noam Brown and Tuomas Sandholm. Superhuman AI for multiplayer poker. Science, 2019. ▪ Julien Perolat, Bart De Vylder, Daniel Hennes, Eugene Tarassov, Florian Strub, Vincent de Boer, Paul Muller, Jerome T Connor, Neil Burch, Thomas Anthony, et al. Mastering the game of stratego with model-free multiagent reinforcement learning. Science, 2022. ▪ Martin Zinkevich, Michael Johanson, Michael Bowling, and Carmelo Piccione. Regret minimization in games with incomplete information. In NeurIPS, 2007.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![不完全情報ゲームにおけるAIの成功例 ▪ [Brown and Sandholm, 2018]:二人プレイヤ のポーカーAI Libratusを提案 ▪ [Brown](https://files.speakerdeck.com/presentations/018a7141b8f74a04bfc87acc9d8ab8fa/slide_5.jpg){kind=link}
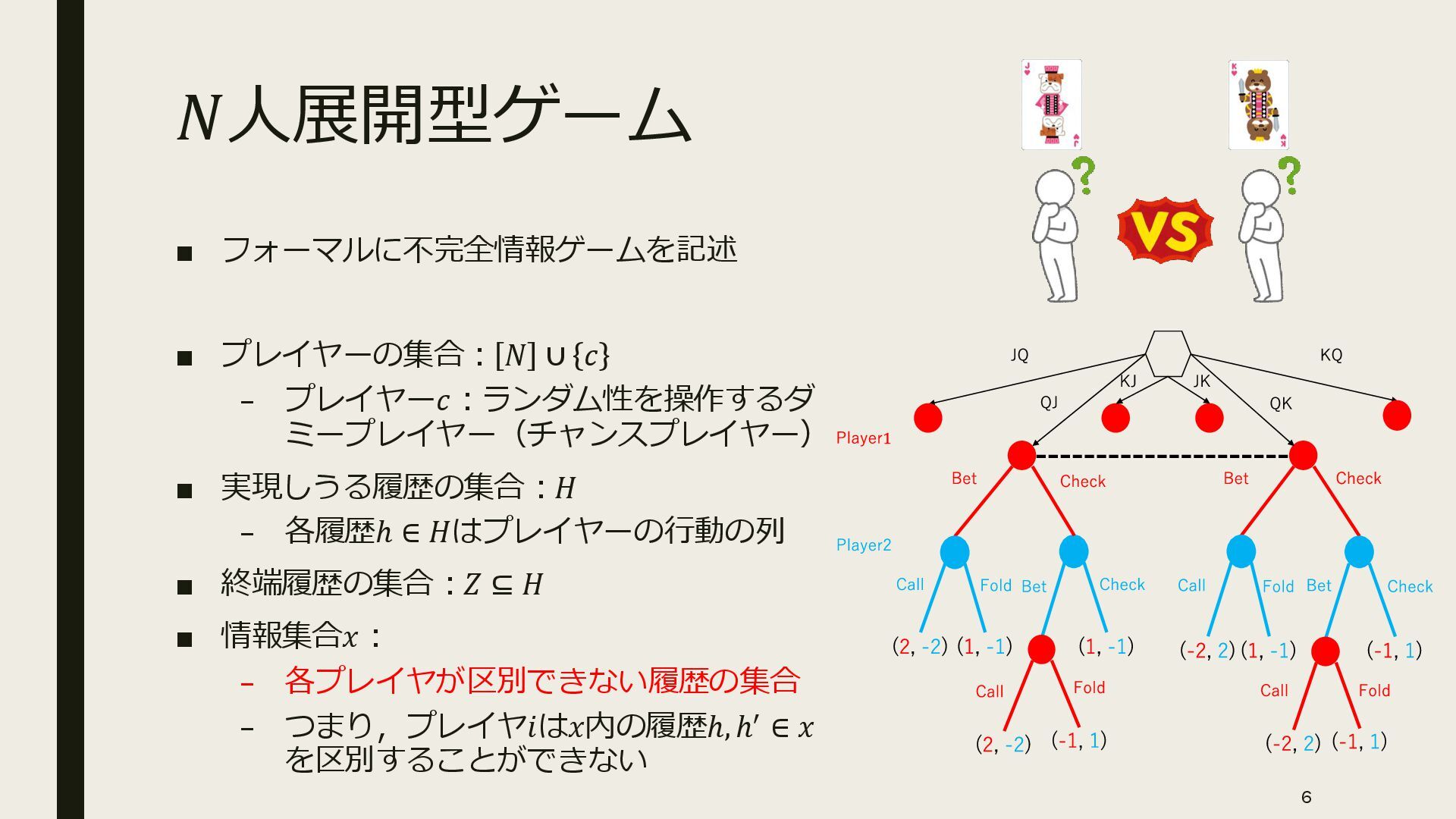{kind=link}
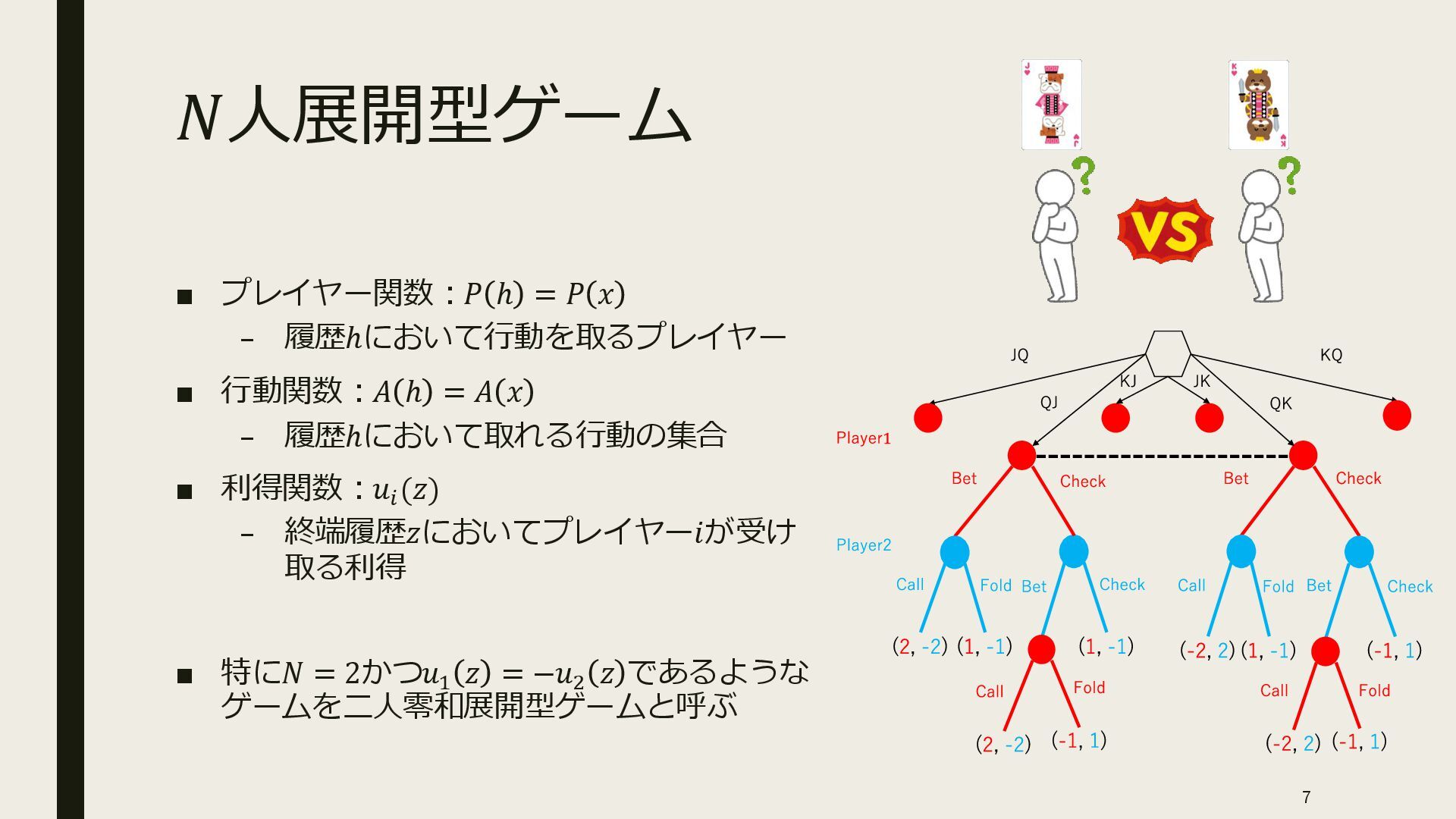{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
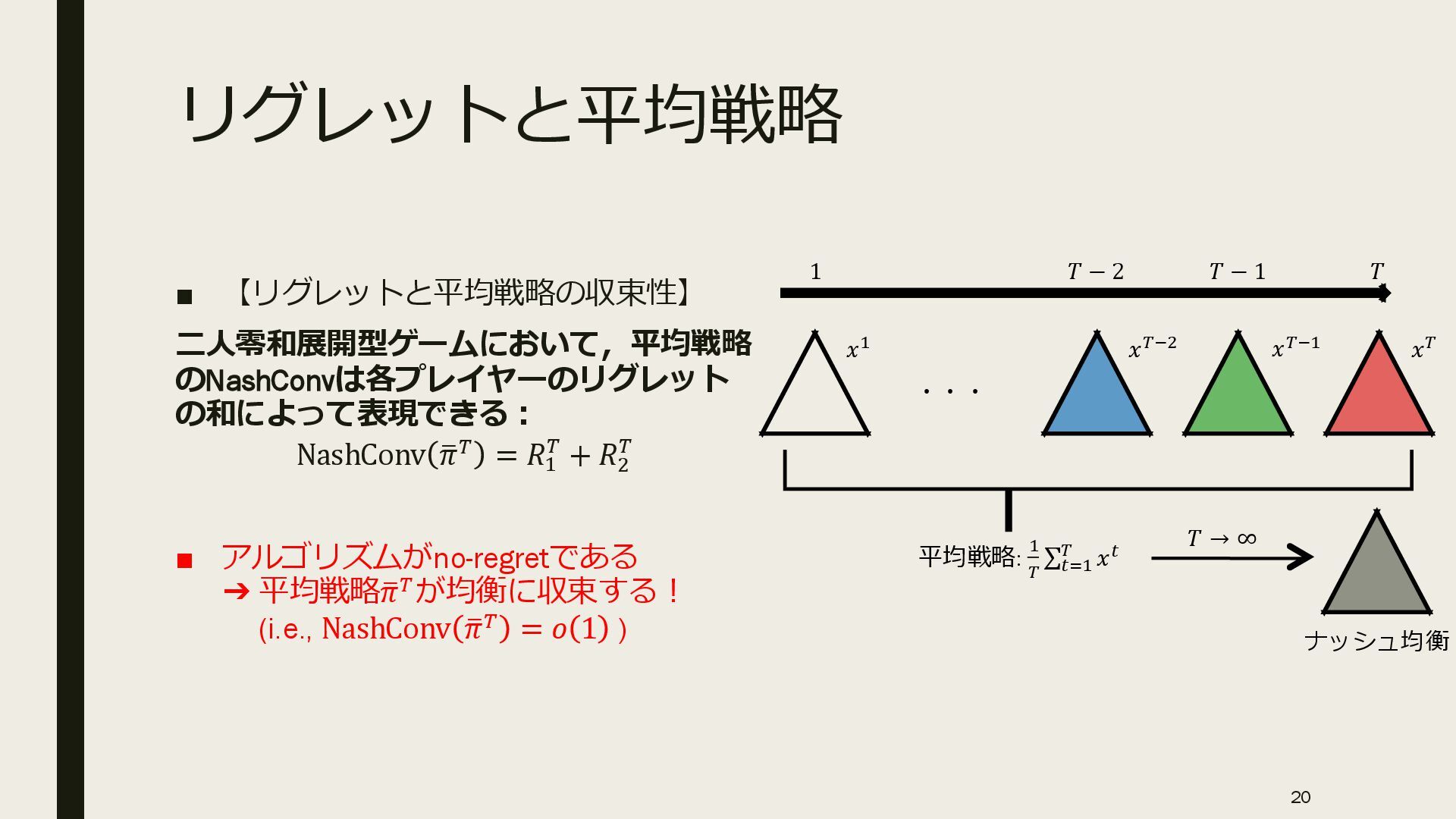{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![ICRの理論的性質 ▪ 【ICRによるリグレット上界 [Zinkevich et al., 2007]】 リグレット𝑹𝒊 𝑻はICRによって以下のように抑えられる: 𝑅𝑖](https://files.speakerdeck.com/presentations/018a7141b8f74a04bfc87acc9d8ab8fa/slide_27.jpg){kind=link}
{kind=link}
{kind=link}
![CFRの理論的性質 ▪ 【CFRのリグレット上界 [Zinkevich et al., 2007]】 反復𝒕 = 𝟏から𝑻までCFRに従って各プレイヤーの戦略を更新したとき,各プレイヤ](https://files.speakerdeck.com/presentations/018a7141b8f74a04bfc87acc9d8ab8fa/slide_30.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}