Presented by Michajlo Matijkiw at RICON East 2013
Managing a business critical Riak instance in an enterprise environment takes careful planning, coordination, and the willingness to accept that no matter how much you plan, Murphy's law will always win. At CIM we've been running Riak in production for nearly 3 years, and over those years we've seen our fair share of failures, both expected and unexpected. From disk melt downs to solar flares we've managed to recover and maintain 100% uptime with no customer impact. I'll talk about some of these failures, how we dealt with them, and how we managed to keep our clients completely unaware.
About Michajlo
Michajlo Matijkiw is a Sr Software Engineer at Comcast Interactive Media where he focuses on building the types of tools and infrastructure that make developers' lives easier. Prior to that, he was an undergraduate student at University of Pennsylvania where he split his time between soldering irons and studying task based parallelism. In his spare time he enjoys cooking, good beer, and climbing.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
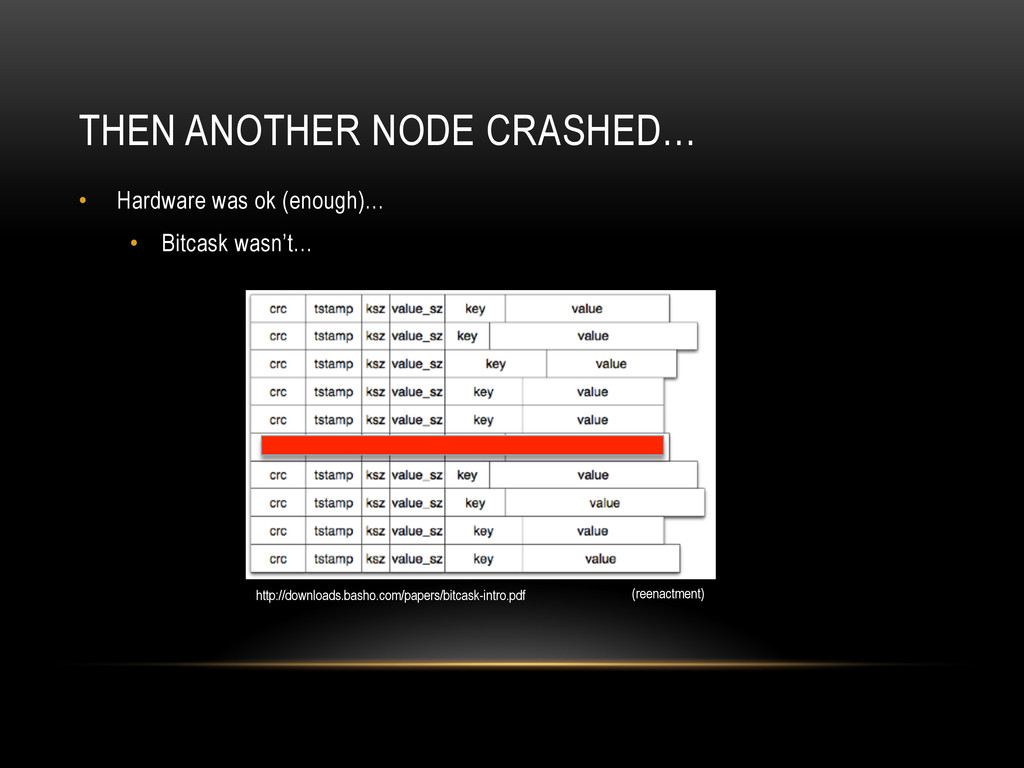{kind=link}
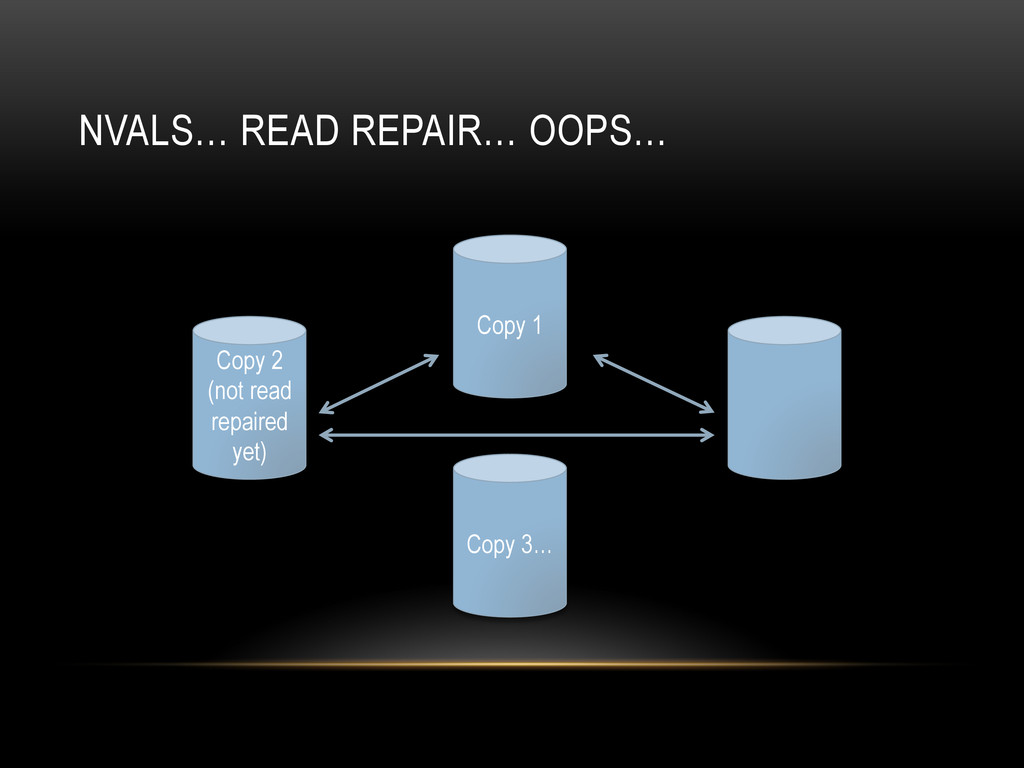{kind=link}
{kind=link}
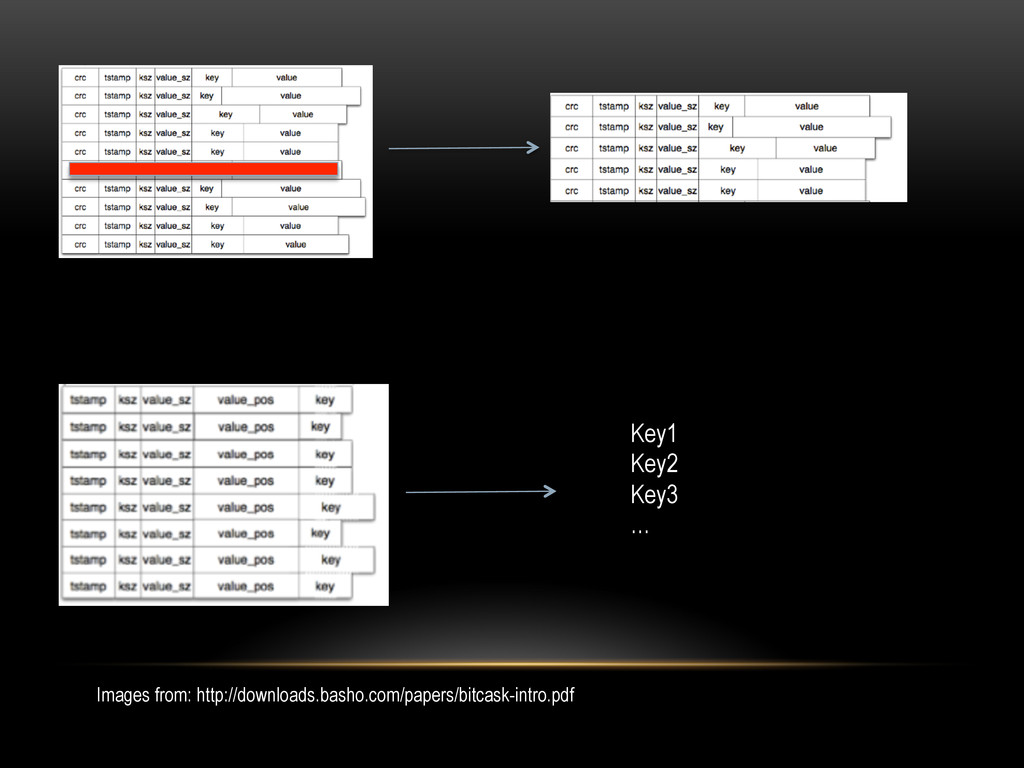{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
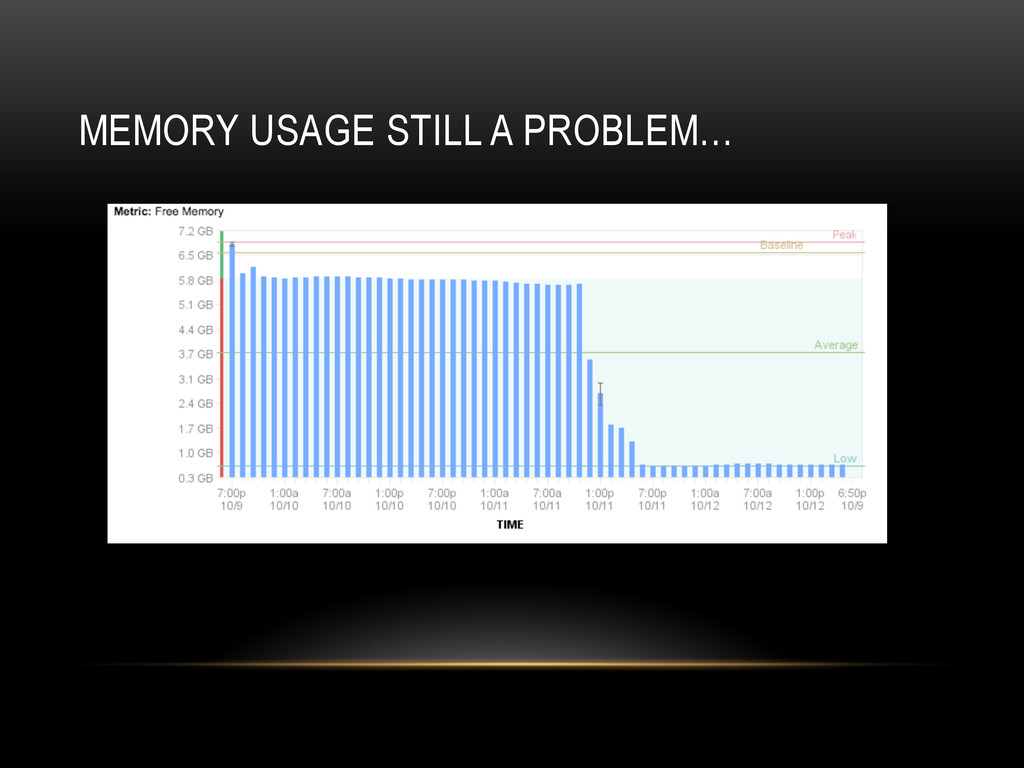{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}