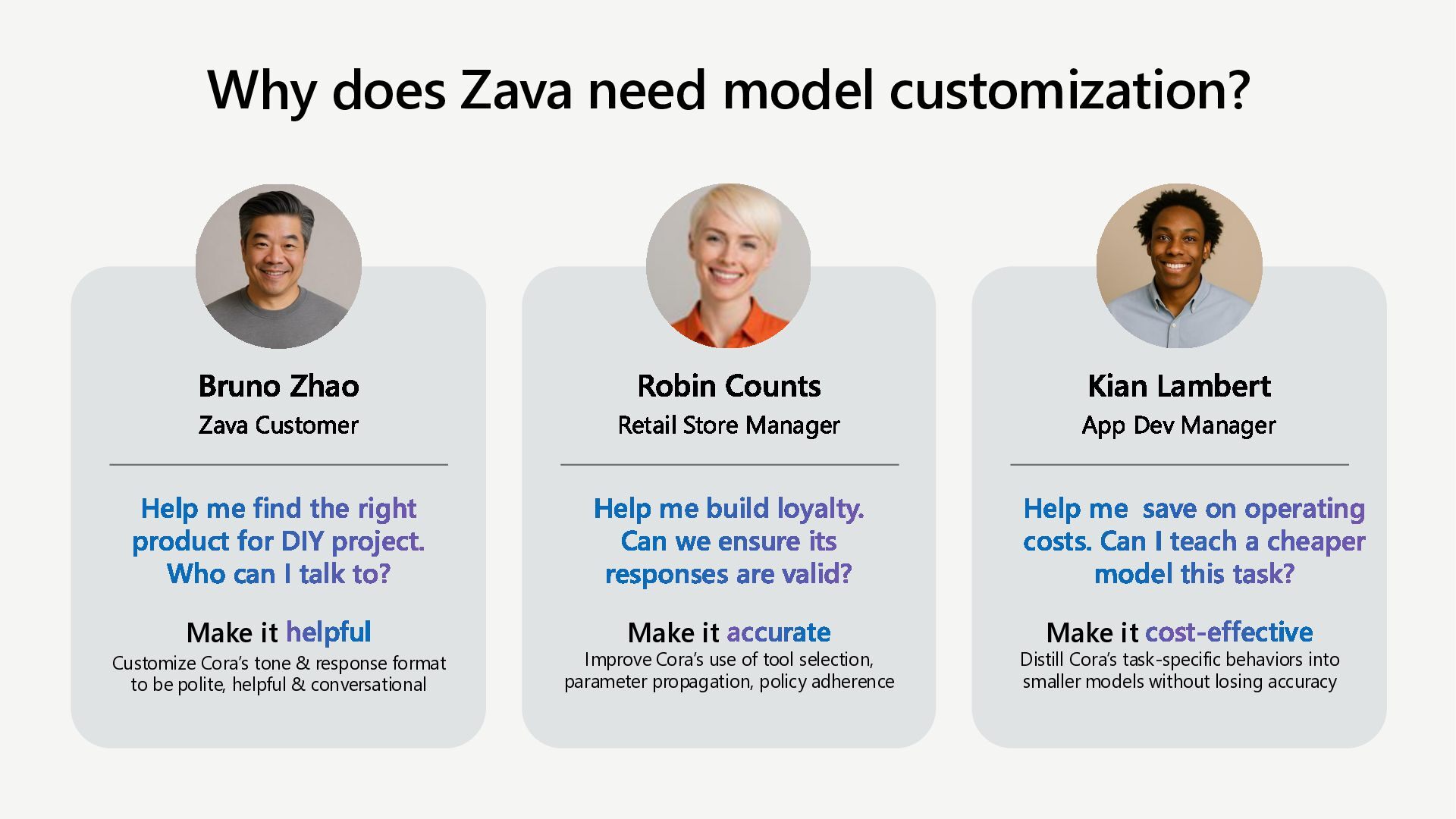
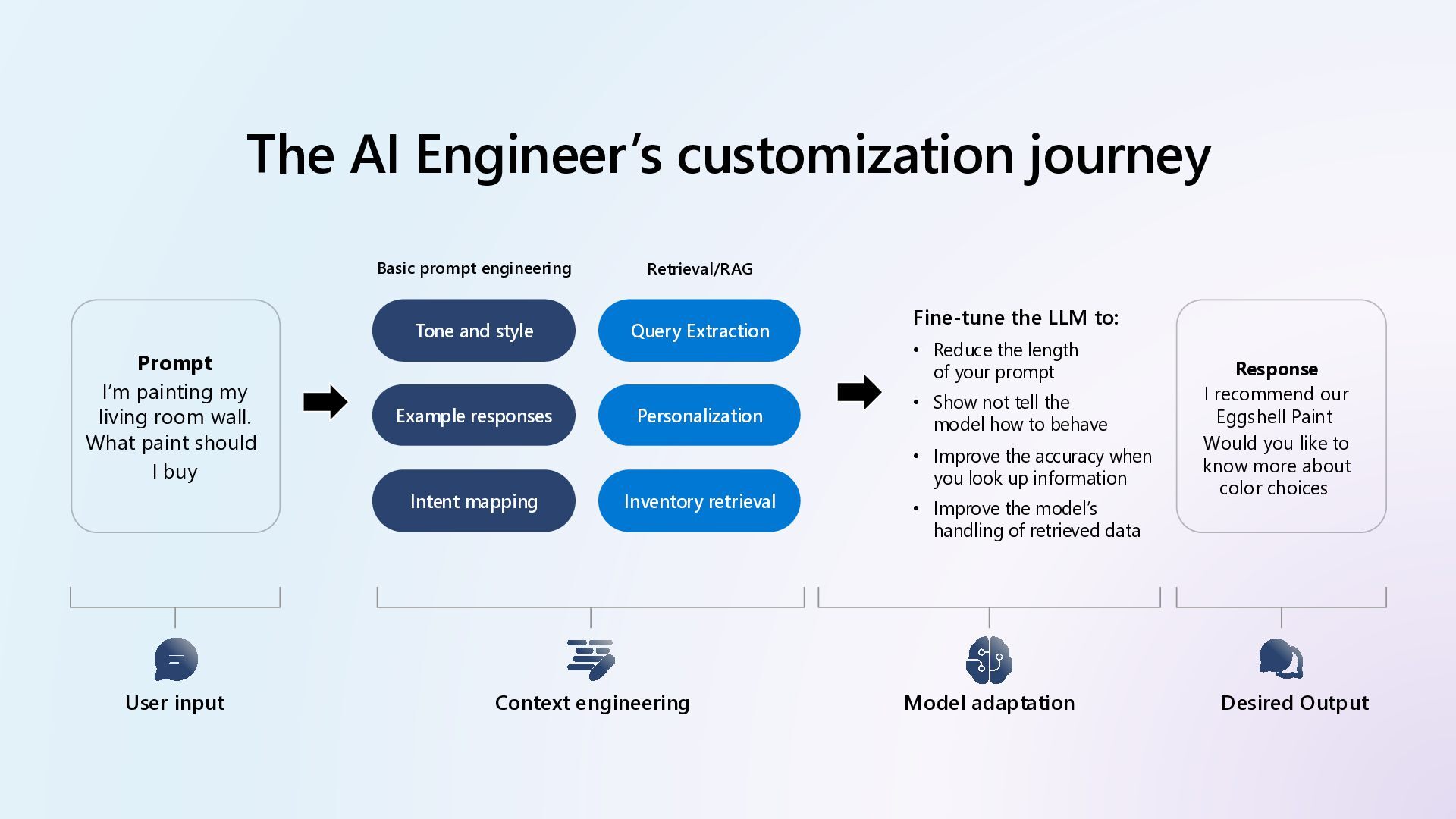
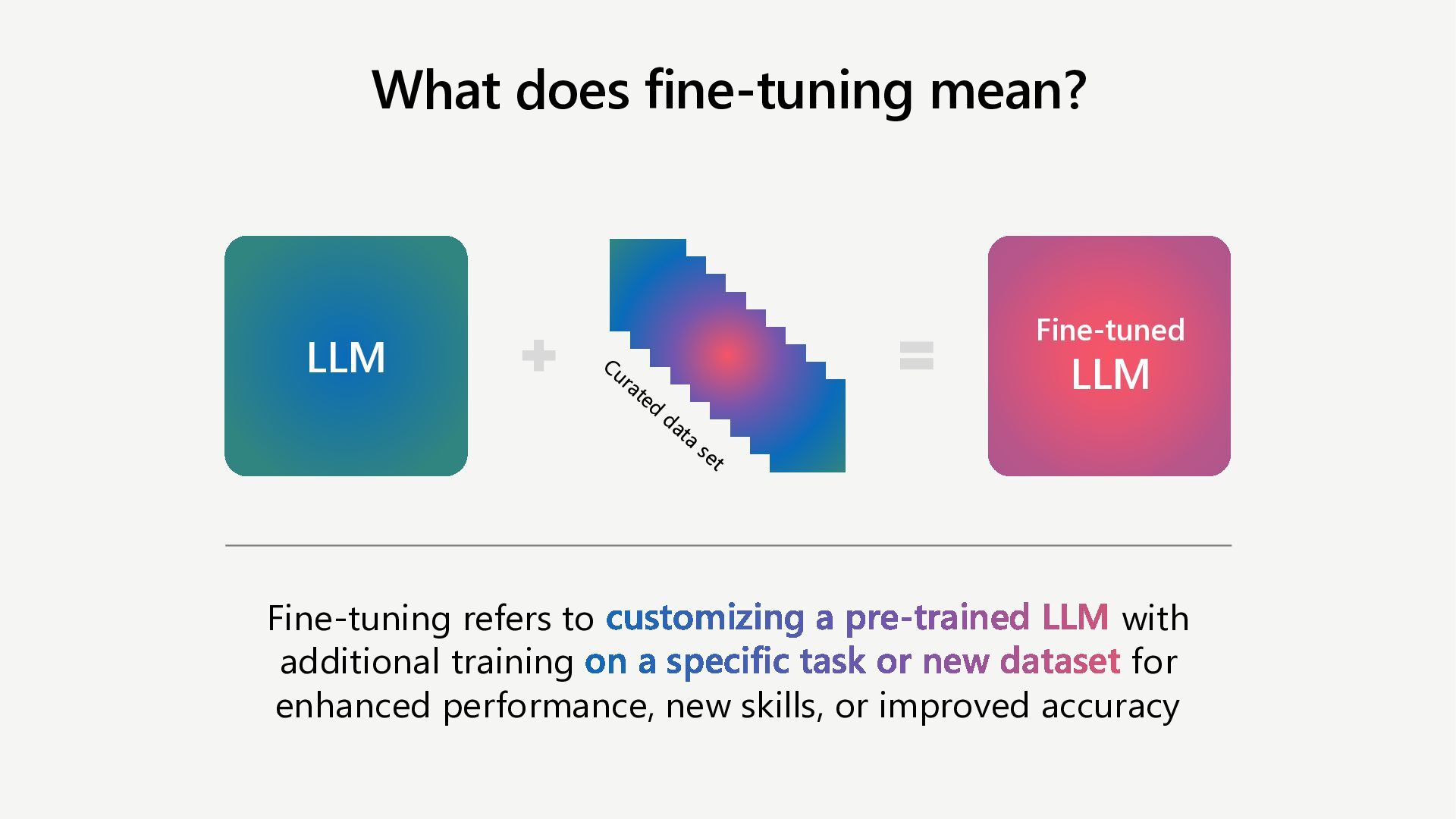
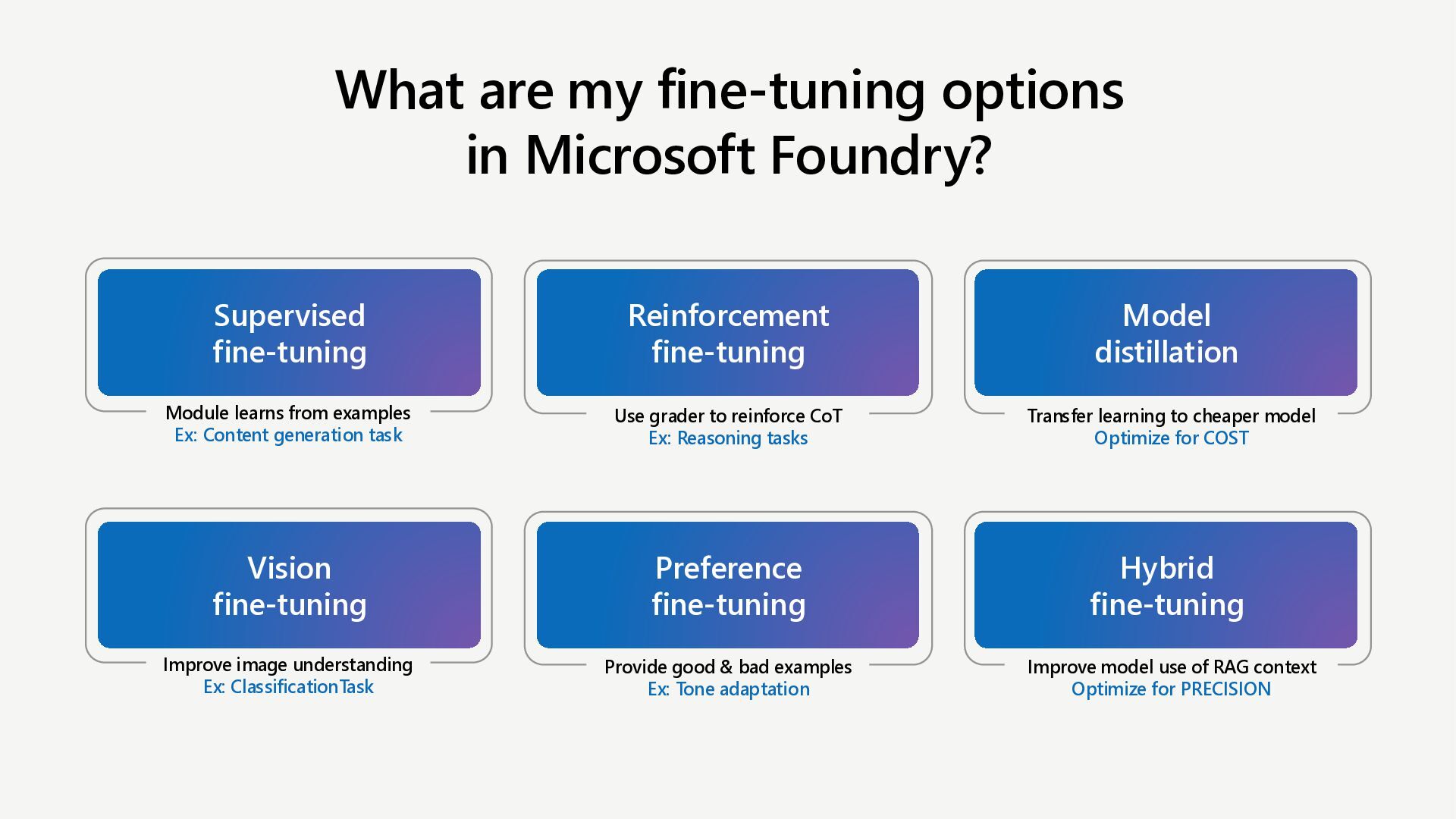
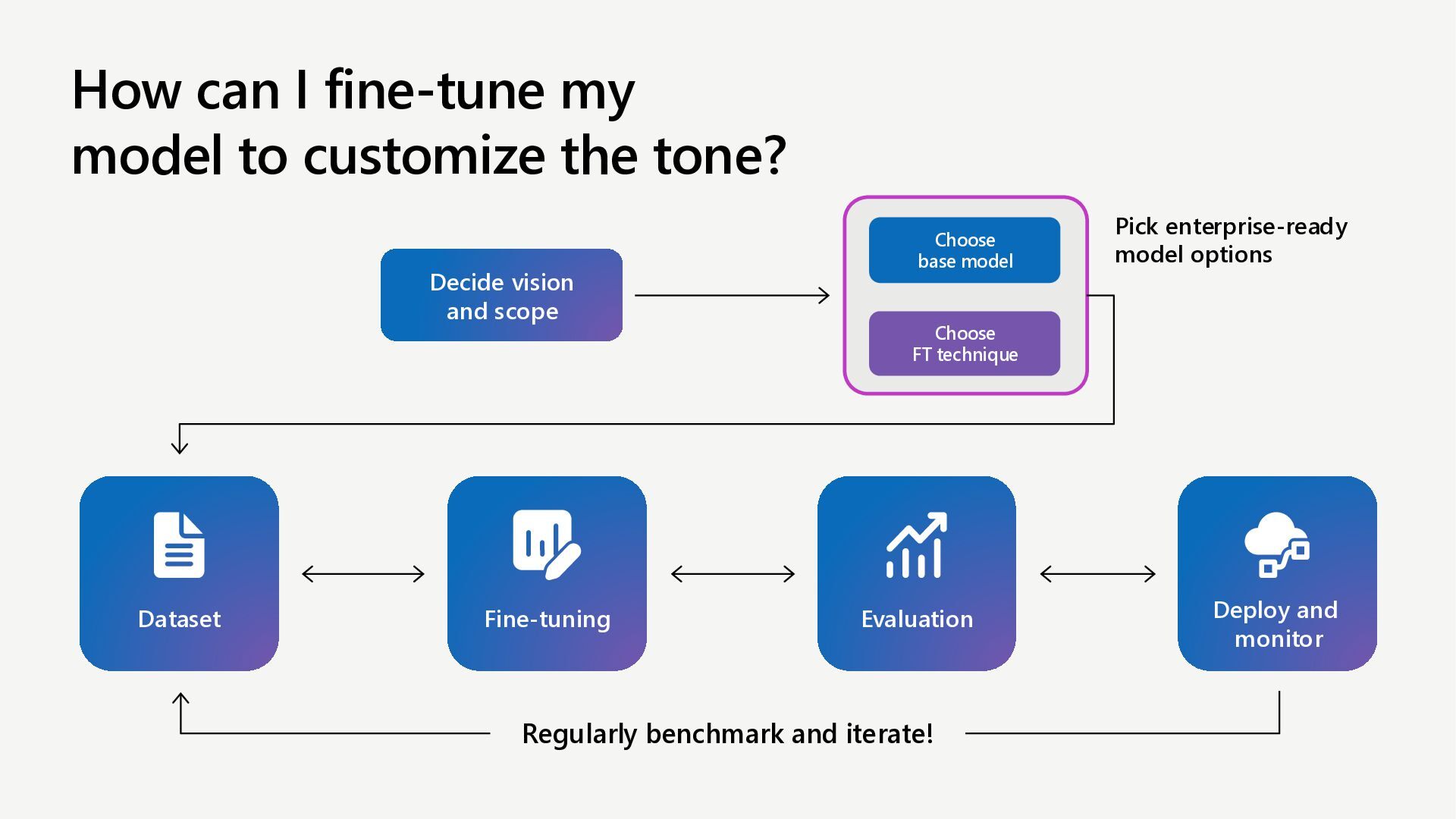
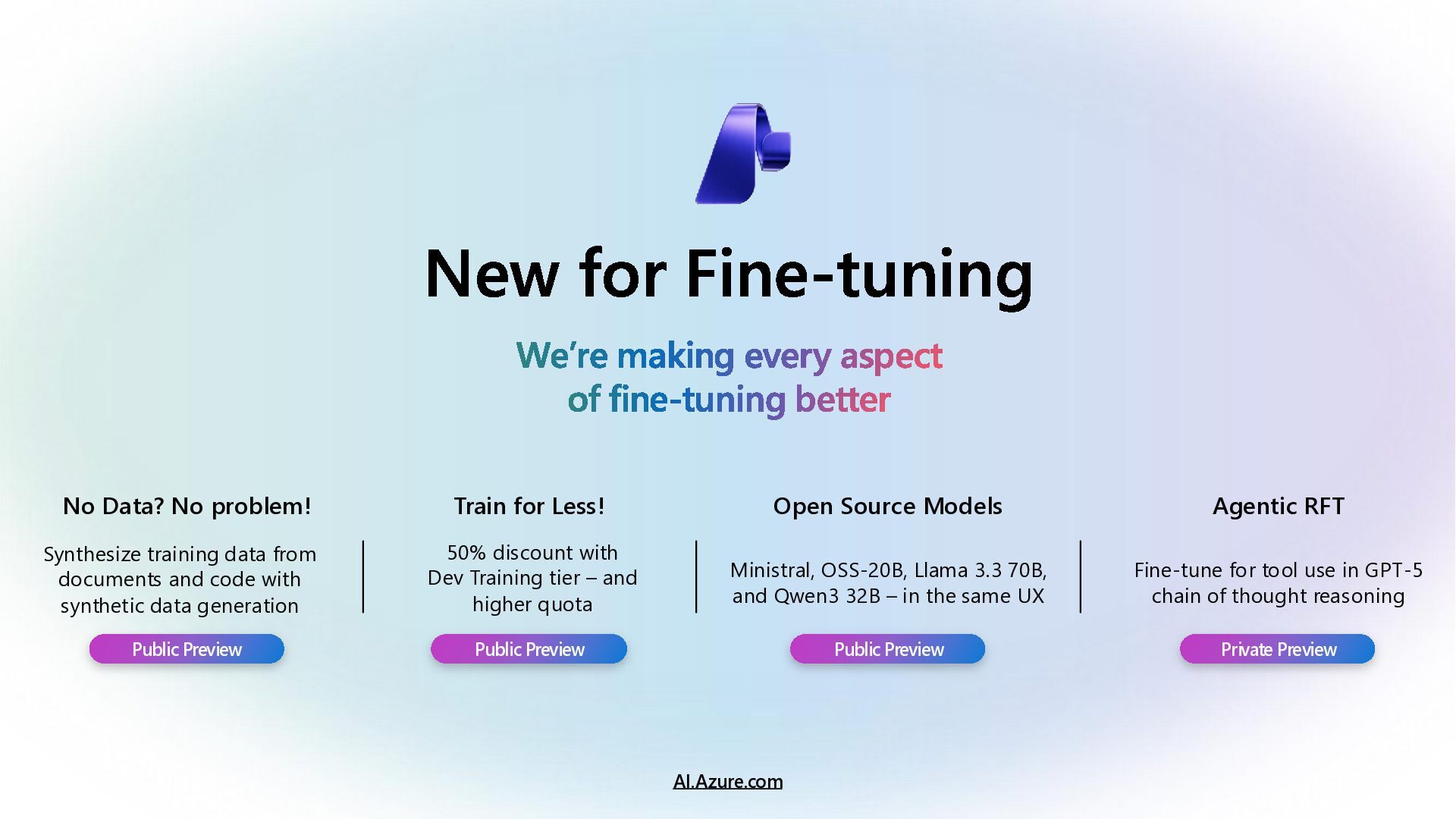
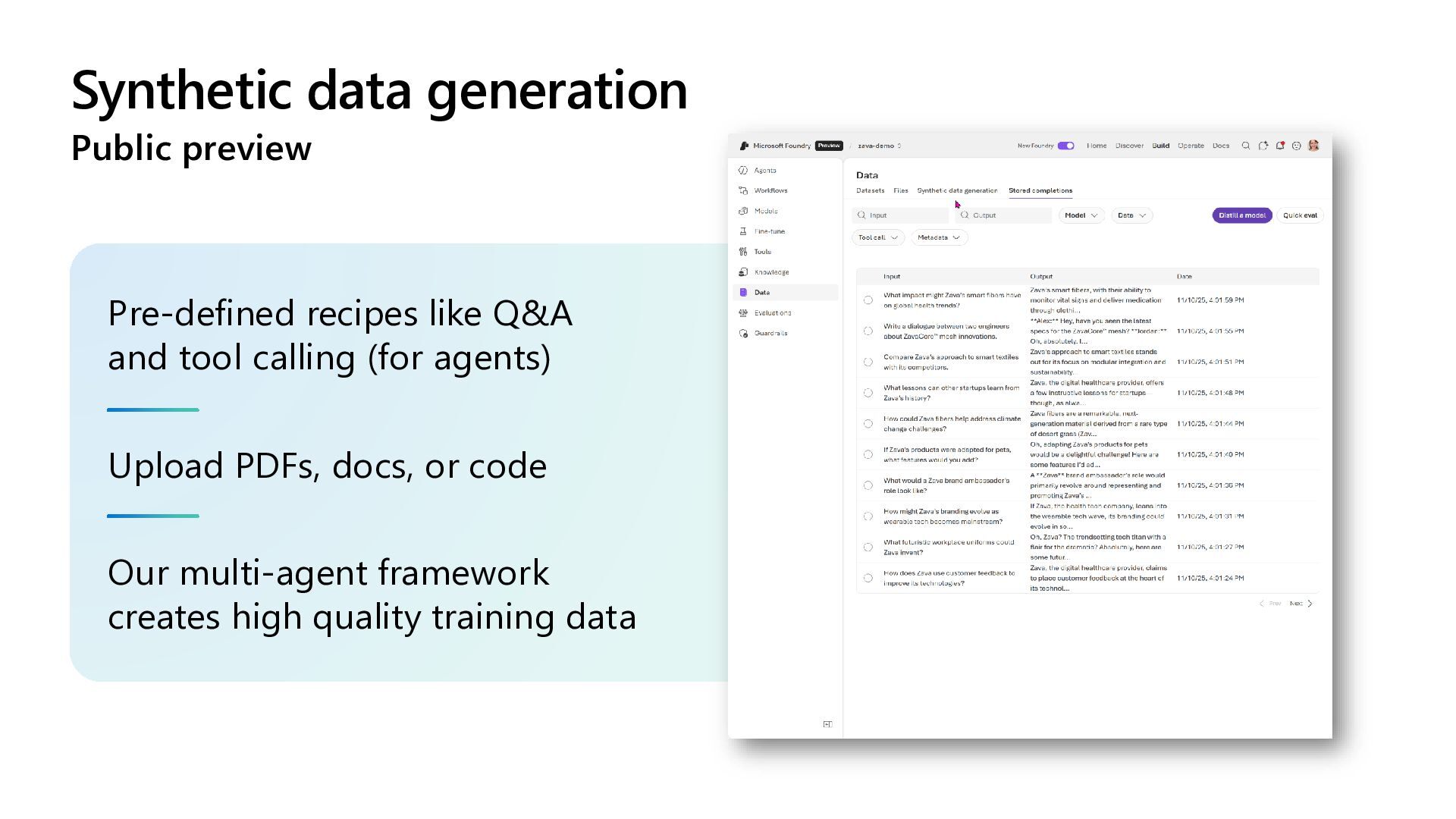
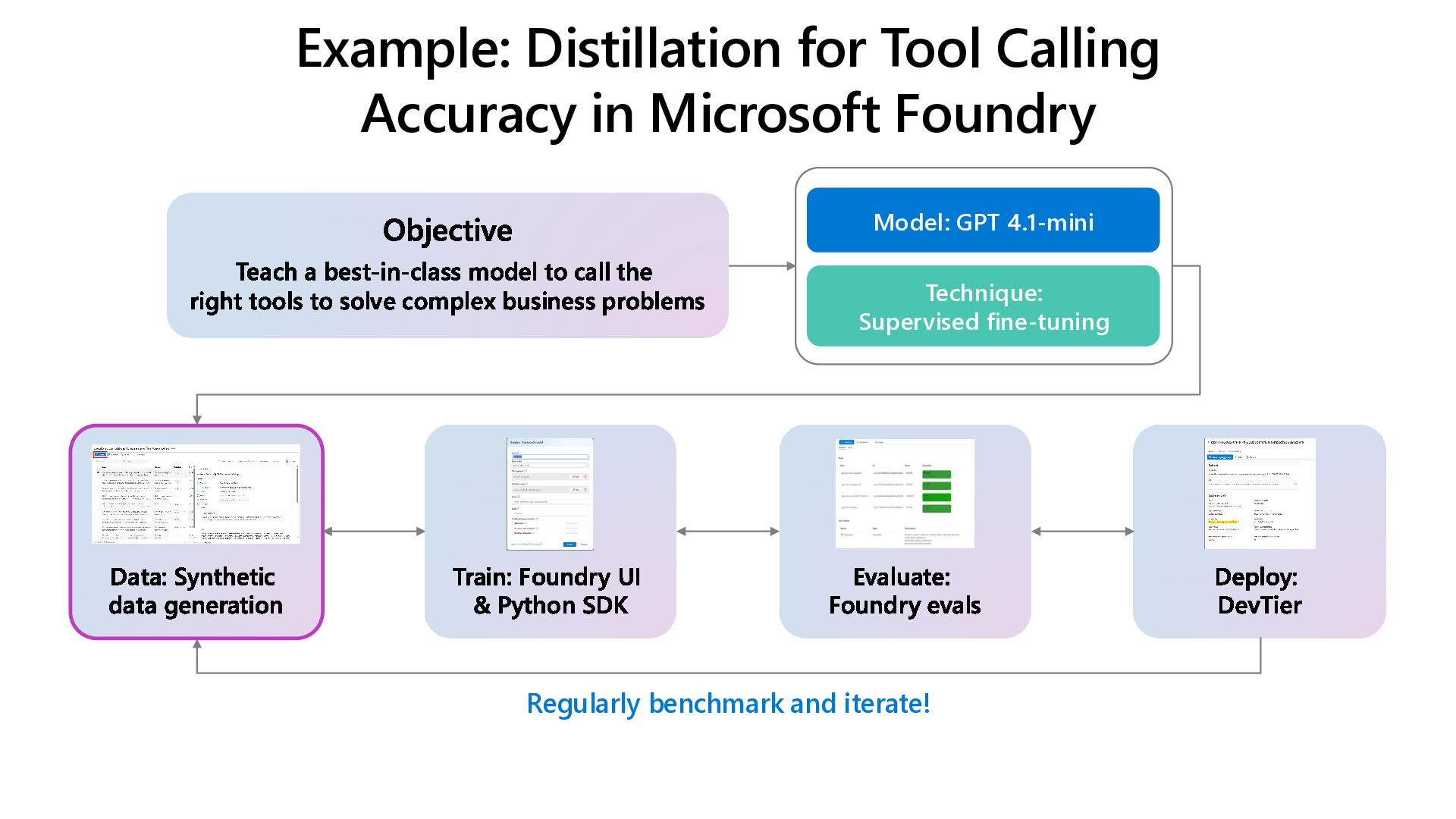
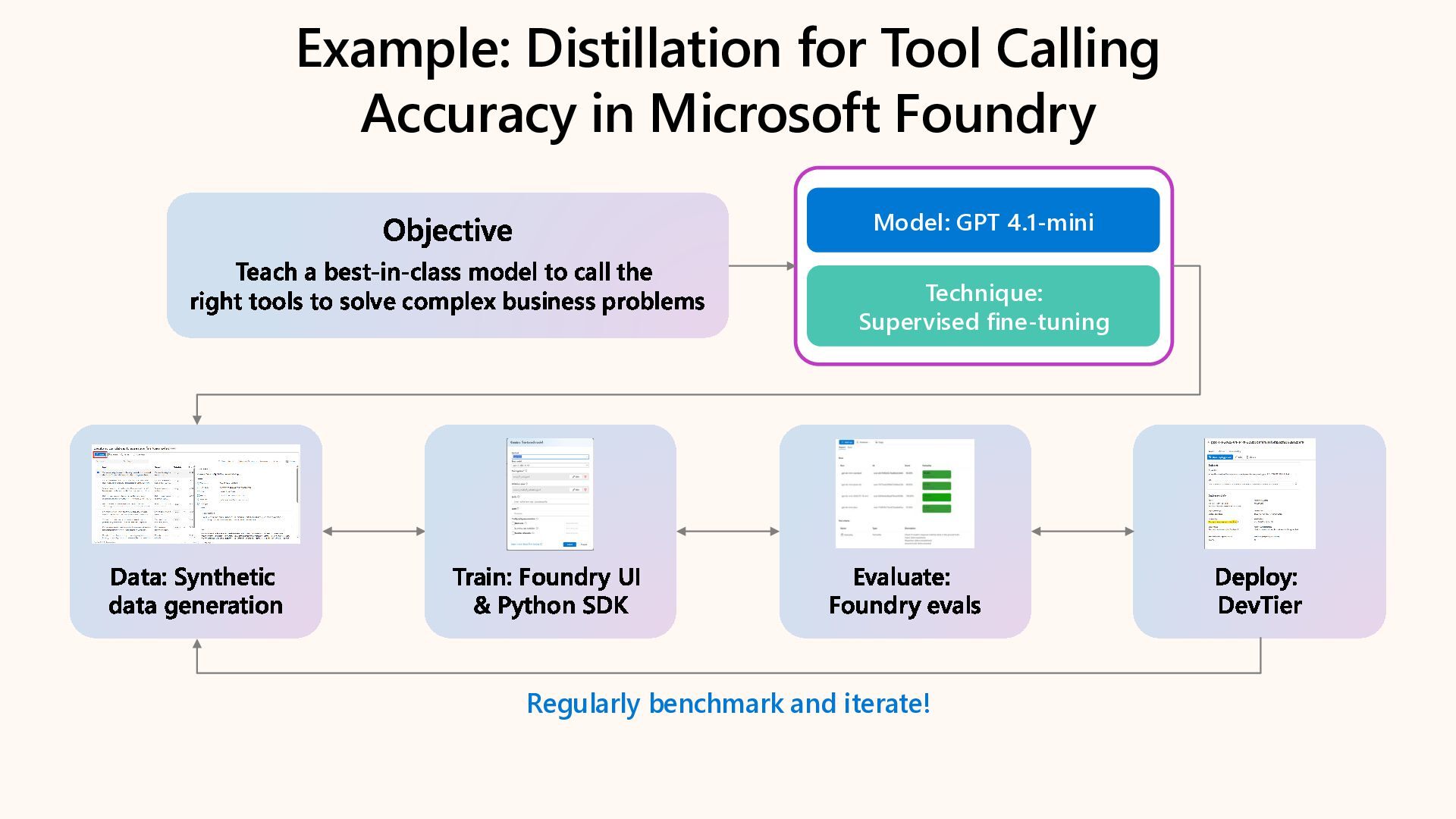
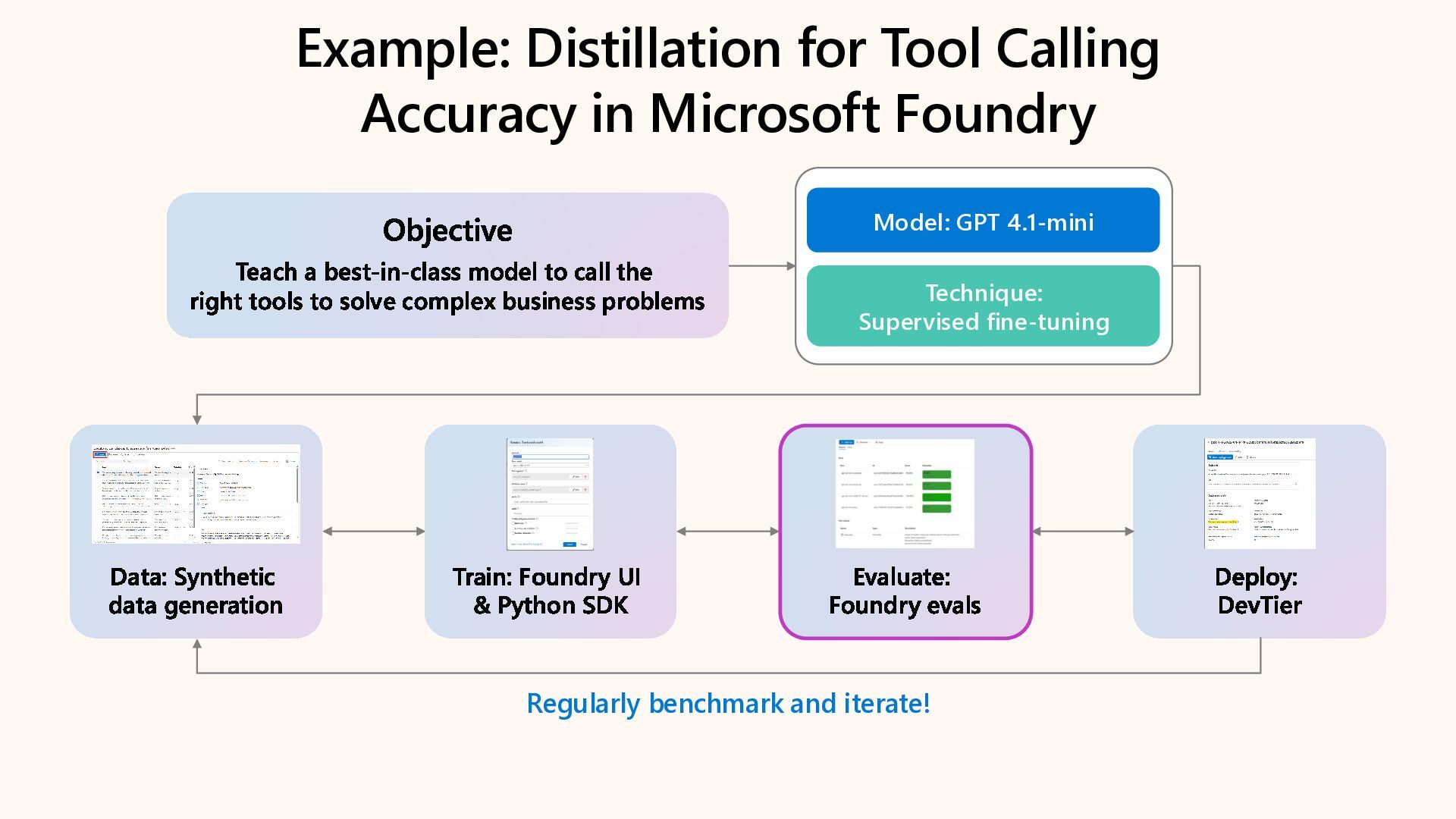
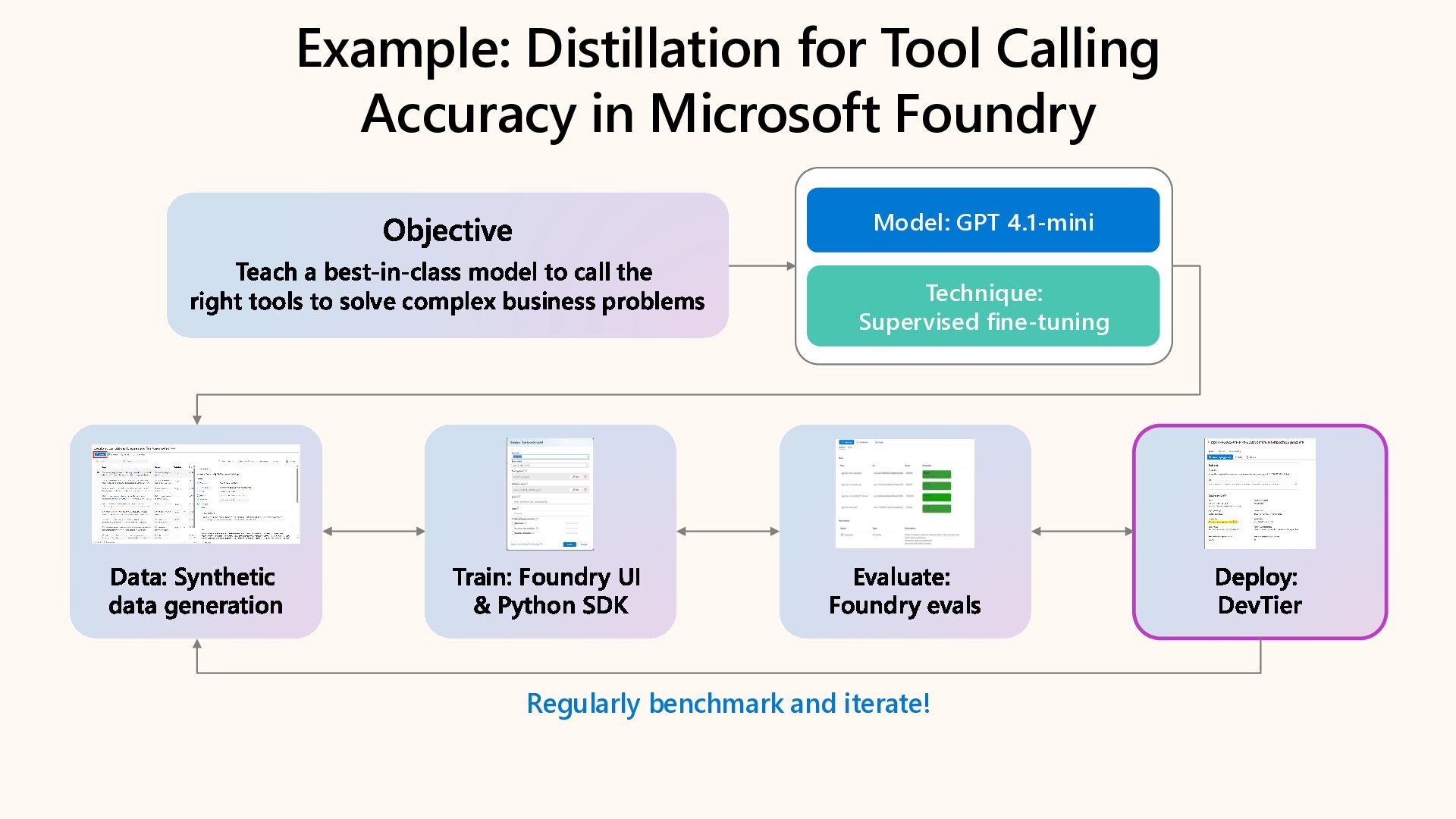
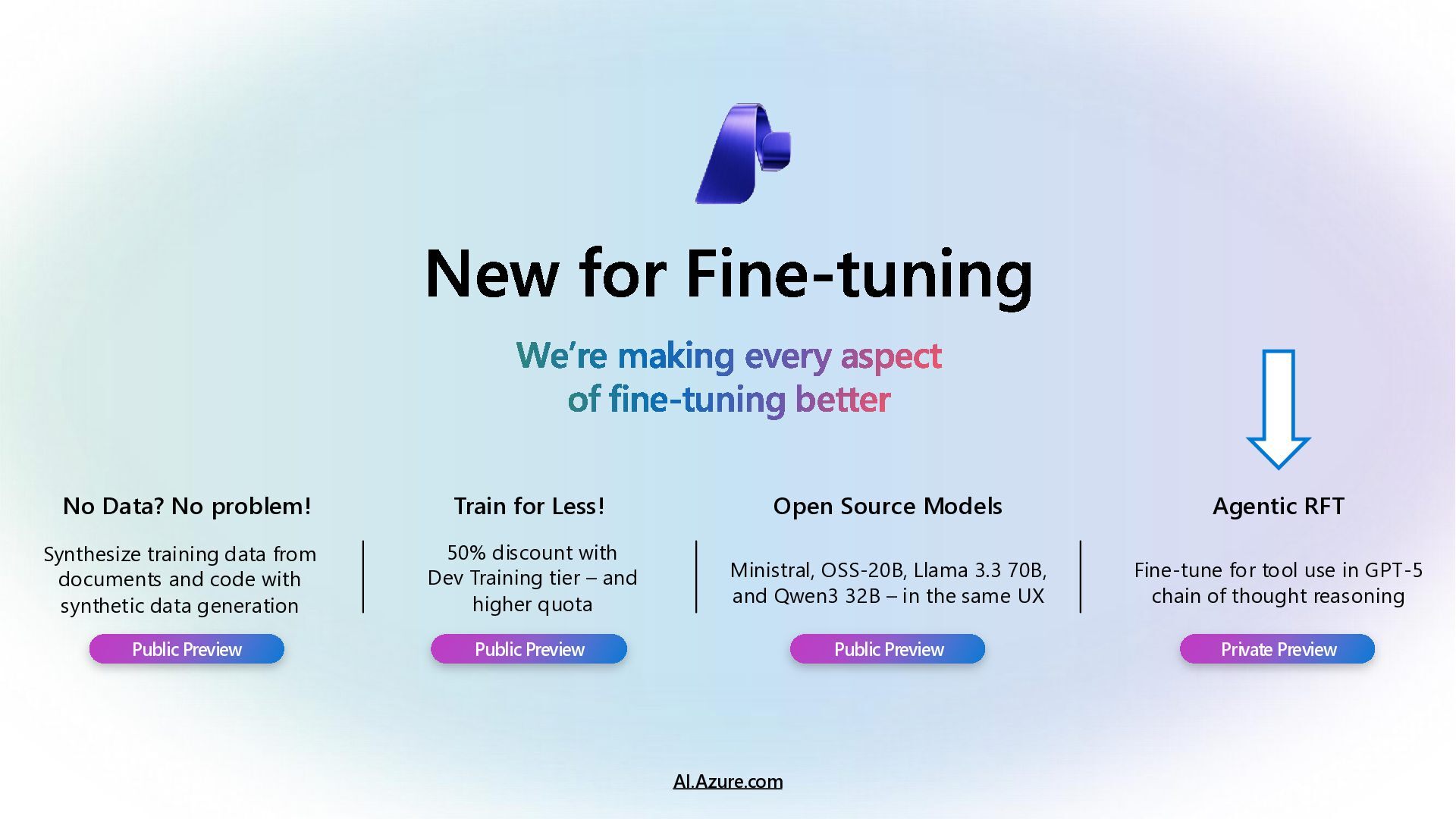
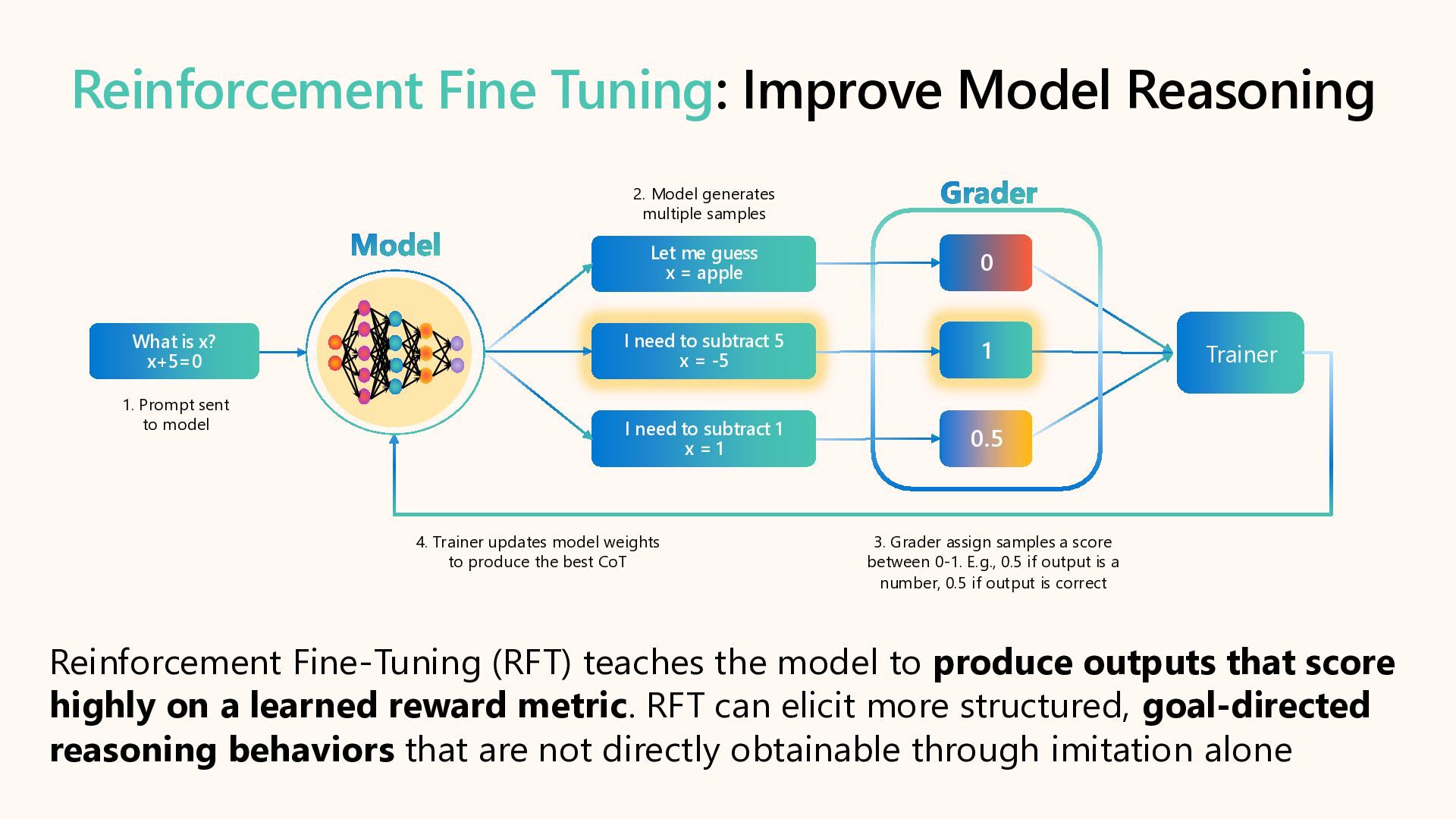
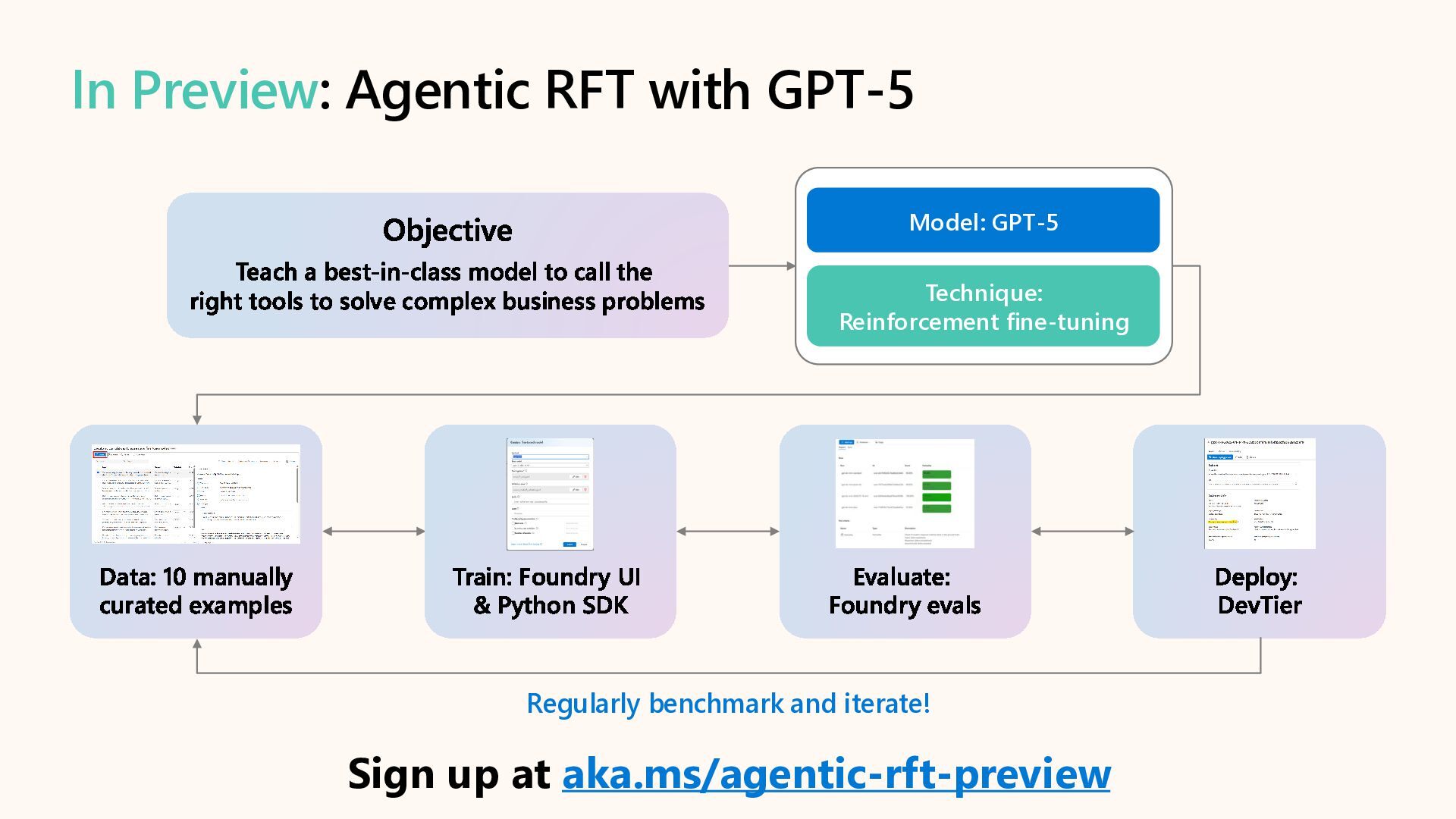
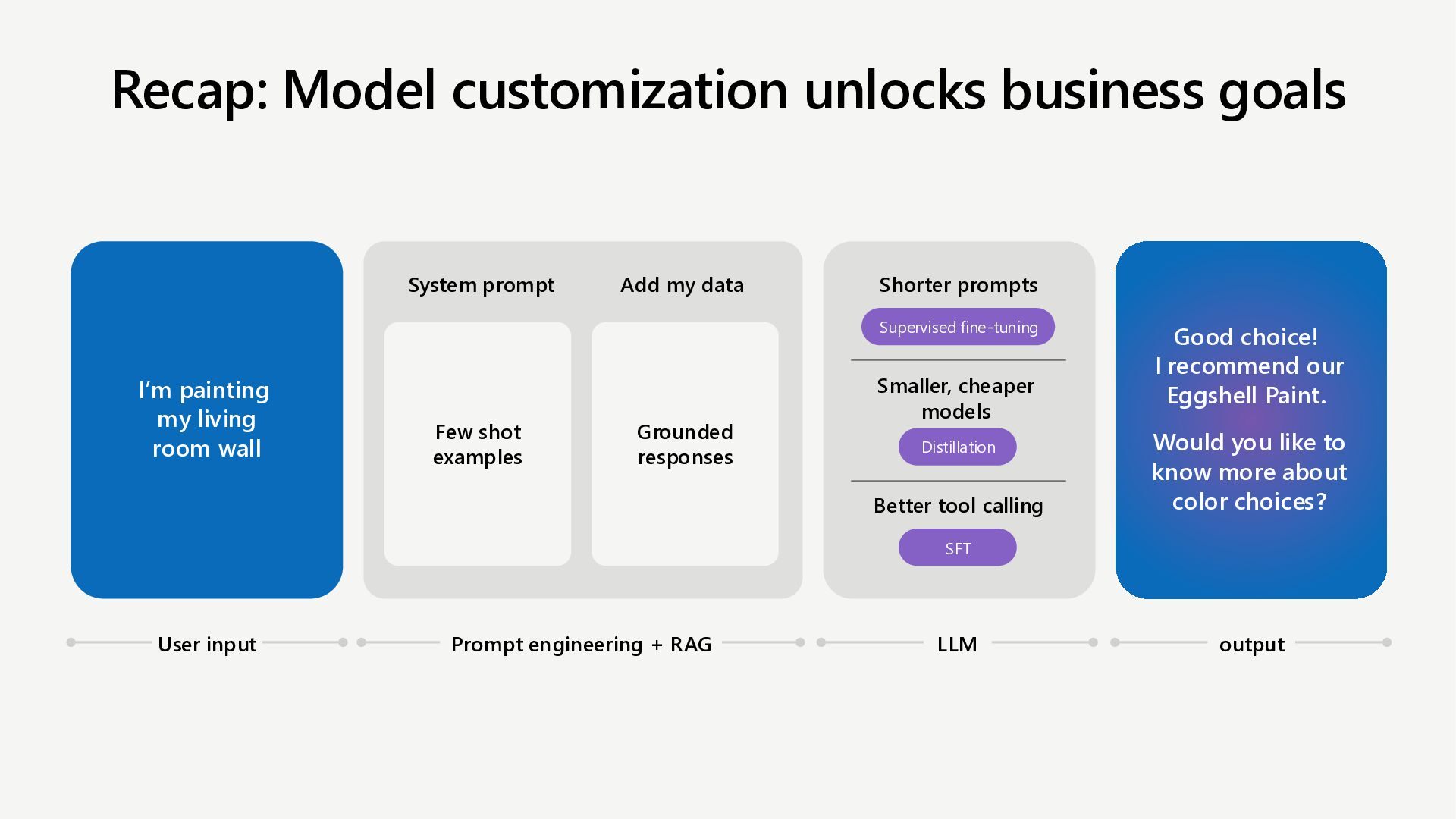
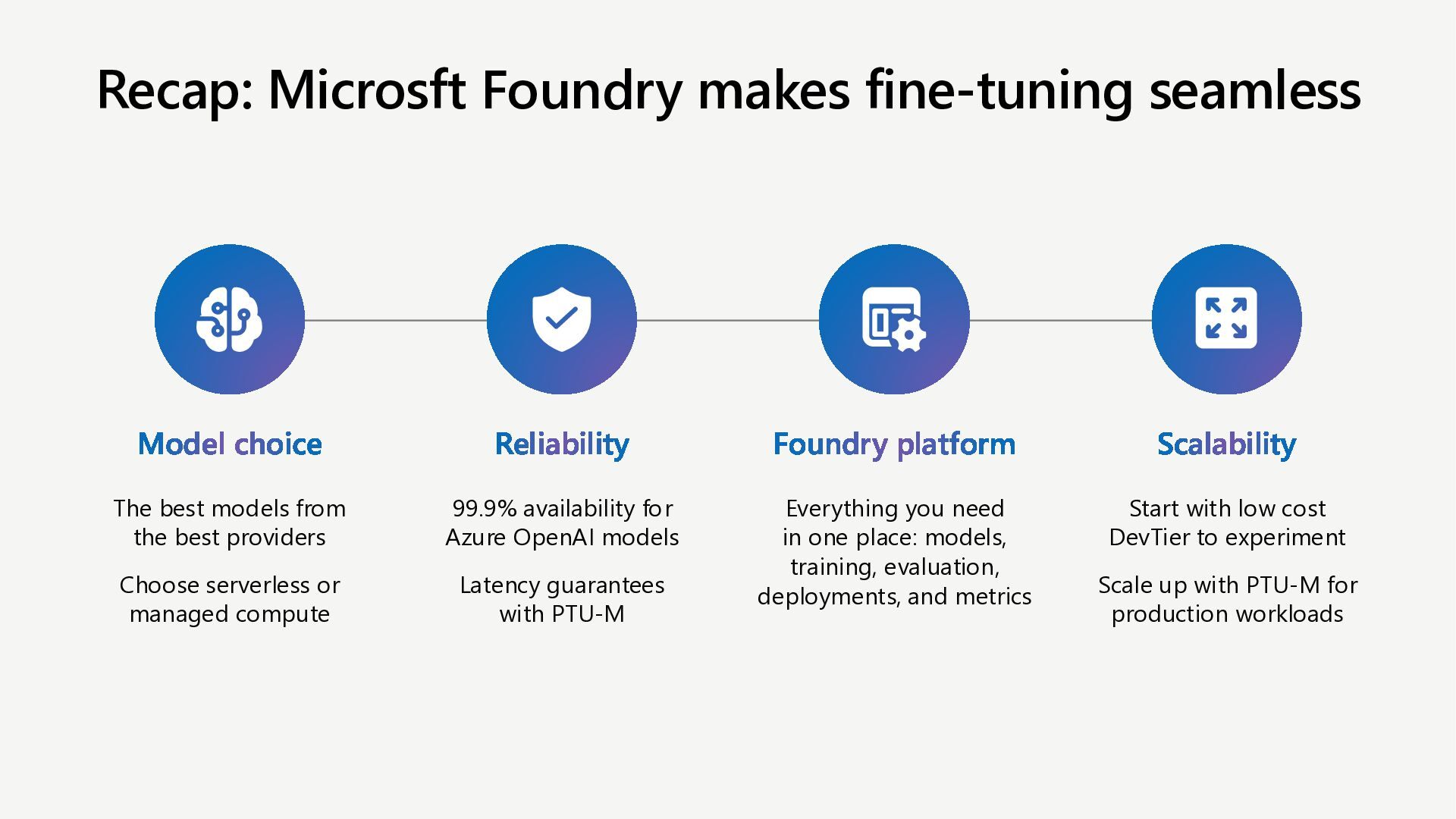
Learn how to customize AI models for a retail customer service agent using Microsoft Foundry. In this session we will discuss how you can optimize your model through options such as SFT and distillation to reduce latency and token costs and improve the tone of your models. I will also cover how you can synthetically generate your data and create a custom grader to give our model proper guidance for fine tuning. Lastly, we will talk about production, how you can deploy and evaluate your retail customer service agent.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}