This talk is about two things: natural language processing (NLP) and statistical dependence. We will embark on a data science workflow using various python scientific computing tools to better understand the behavior of commenters on Reddit. To do this we'll go through an introduction to sentiment analysis in Python (mostly using NLTK) and a swift explanation of the statistics of variable dependence.
We'll couple these freshly learned methods with an excellent dataset for this domain: every public reddit comment. We'll talk a bit about handling and preprocessing data of this size and character. Then we'll compile scores for both sentiment and spelling/grammar. In the end we may just discover if angry comment are also grammatically poor comments. And the audience will walk away a few more tools in scientific computing toolbelt.
Deck as presented at PyData Amsterdam 2016
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
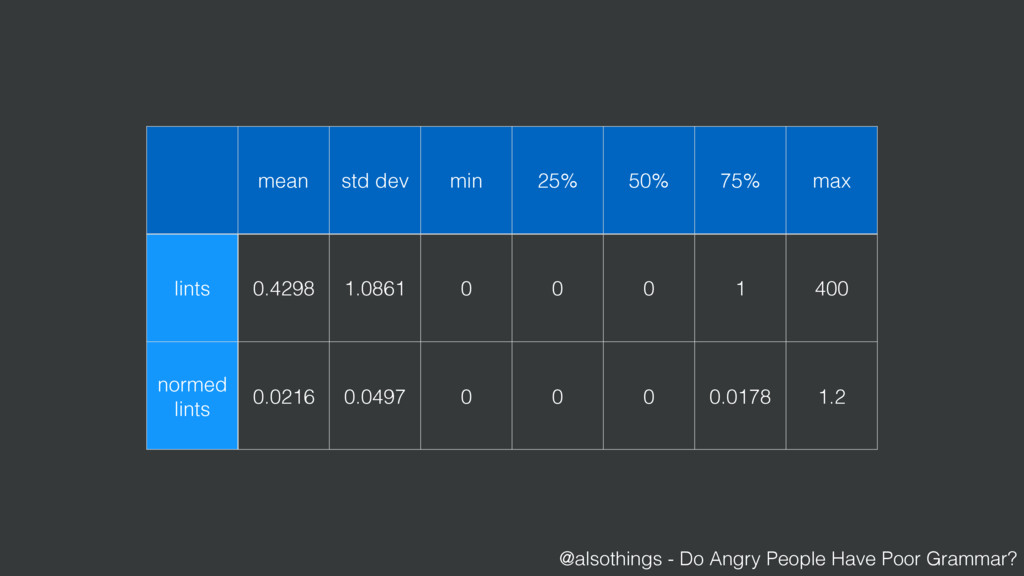{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
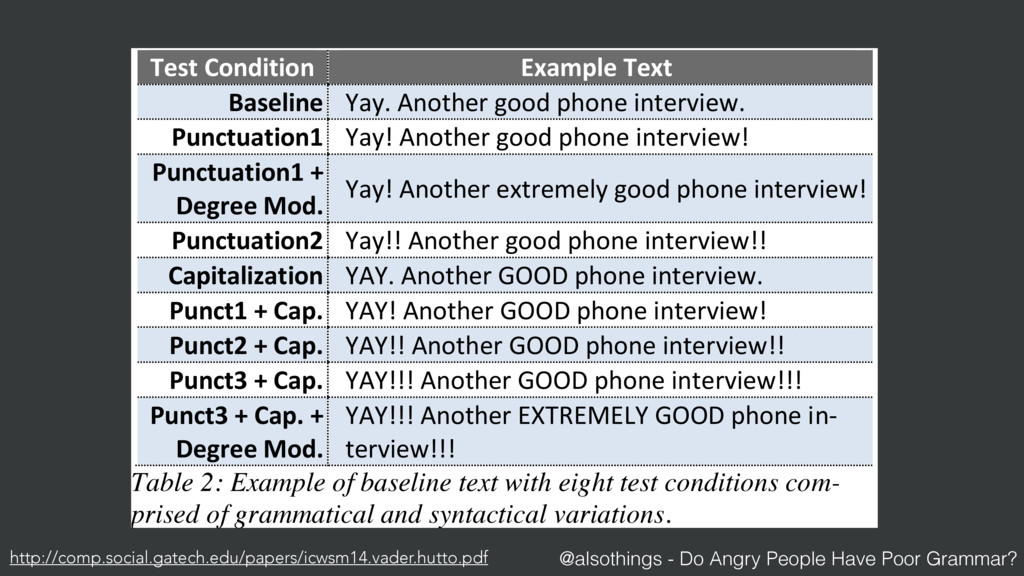{kind=link}
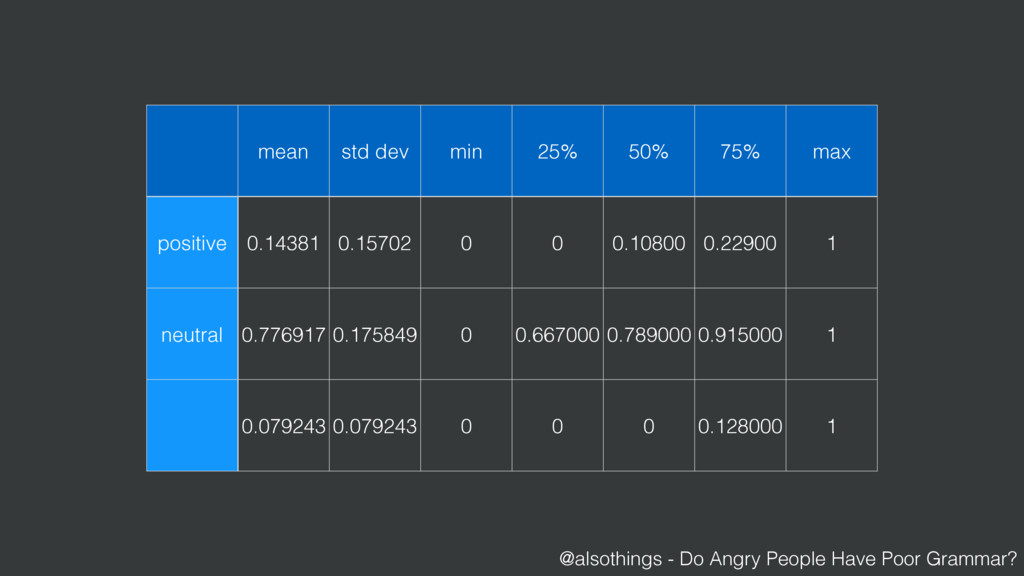{kind=link}
{kind=link}
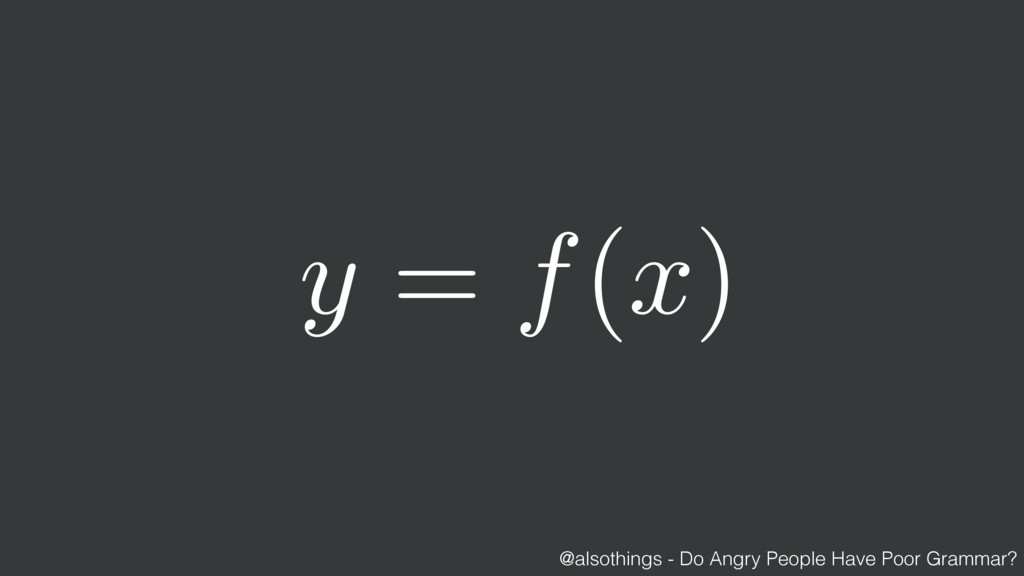{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}