+ knowledge + text generation ▪ Examples: GPT-4o, Claude 3, LLaMA-3-70B ▪ Pros: ▪ Strong reasoning ▪ Best accuracy ▪ Handles long context ▪ Great for complex tasks ▪ Cons: ▪ Heavy (GPU cost) ▪ Slower than SLM ▪ Can hallucinate without external data ▪ Use When: ▪ You need intelligence, reasoning, creativity ▪ Cybersecurity analytics, report generation, AI assistants ▪ Small Language Model (SLM) = tiny, fast model optimized for low compute ▪ Examples: LLaMA-3-8B, Phi-3-mini, Gemma-2-9B ▪ Pros: ▪ Cheap (runs on CPU) ▪ Low latency ▪ Good for edge/on-device ▪ Cons: ▪ Limited reasoning ▪ Struggles with complex tasks ▪ Needs domain fine-tuning ▪ Use When: ▪ Mobile, IoT, lightweight apps ▪ Classification, summarization ▪ Secure environments (on-prem)
retrieves relevant documents → uses them to respond. ▪ Pros: ▪ Reduces hallucination ▪ Uses fresh internal data ▪ Explainable (citations) ▪ Cons: ▪ Needs data pipelines, embeddings, vector DB ▪ Retrieval quality matters ▪ Use When: ▪ You need correctness based on enterprise data ▪ Policies, security docs, patient records, tickets
tools + memory + actions ▪ Examples: browser-tool, code-executor, database-query agent ▪ Pros: ▪ Executes tasks, not just answers ▪ Can call APIs and take steps ▪ Cons: ▪ Needs constraints → risky if unrestricted ▪ Harder to evaluate and test ▪ Use When: ▪ You want automation: run scripts, query systems, orchestrate actions ▪ Pentest automation, cloud checks, ticket triage ▪ Agentic AI = multiple AI agents collaborating with autonomy, planning, and tool-use to complete complex goals ▪ Examples: Planner–Worker–Verifier system, multi-agent security workflow, autonomous research agents ▪ Pros: ▪ Handles long-horizon, multi-step tasks ▪ Can coordinate multiple agents with roles ▪ Performs planning, execution, verification loops ▪ Great for automation across systems ▪ Cons: ▪ Higher risk if agents act without constraints ▪ Harder to test, validate, and predict behaviors ▪ Requires strict governance, permissions, and logging ▪ Complex to monitor and secure in enterprise setups ▪ Use When: ▪ Automating end-to-end workflows (triage → exploit test → report → ticket) ▪ Need planning + memory + multi-tool actions ▪ Building multi-agent systems for analysis, pentesting, cloud checks ▪ Tasks requiring collaboration between specialized agents
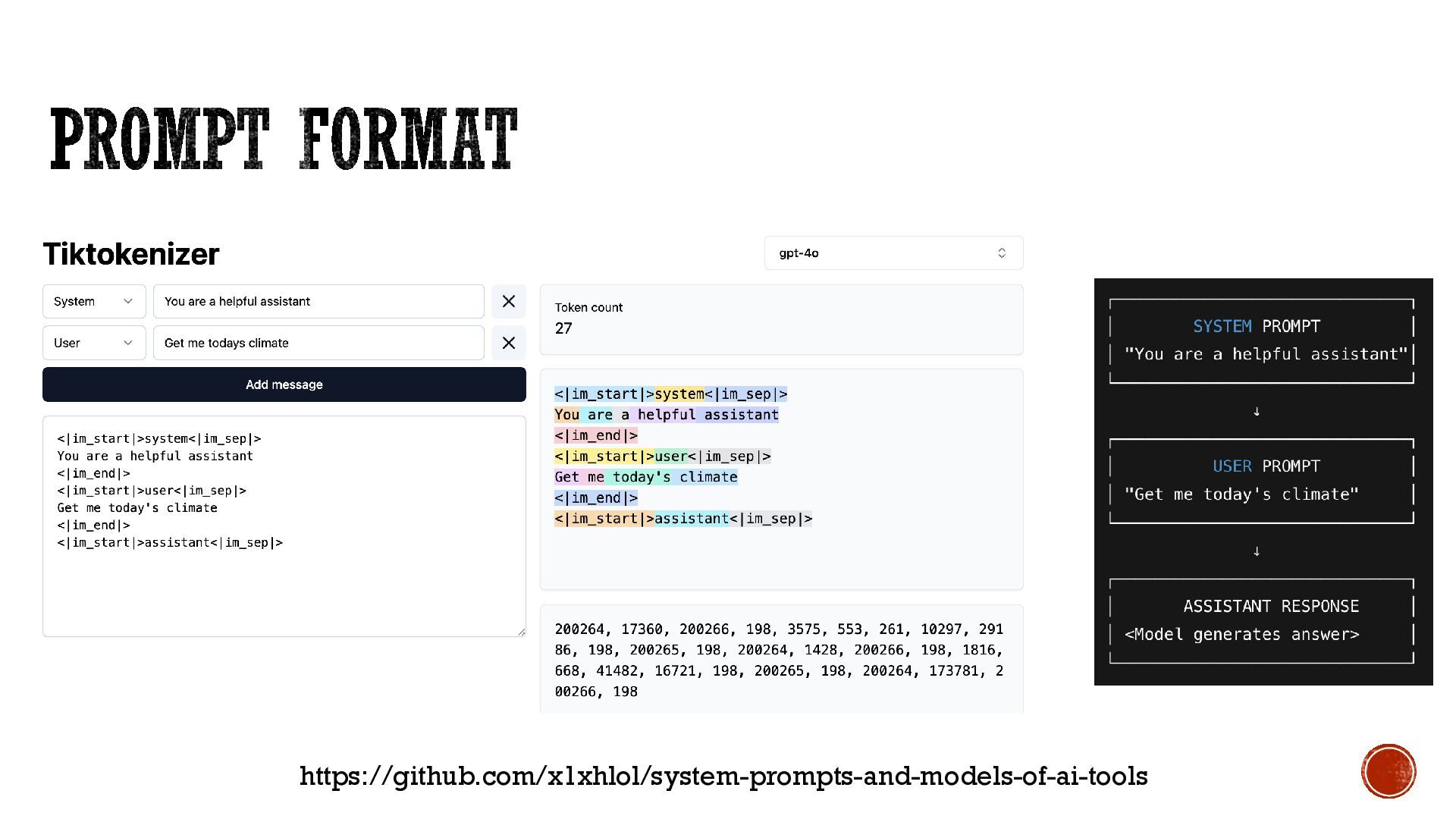
that a Large Language Model (LLM) processes, acting as the "currency" of the model. ▪ Tokens can be whole words, parts of words, individual characters, or punctuation marks. ▪ LLMs convert text into these tokens to understand and generate language more efficiently, with the specific way text is broken down depending on the model's tokenization method
A parameter = a learned weight in the neural network that shapes how the model predicts text. ▪ Why It Matters: ▪ More parameters → more learning capacity ▪ Better reasoning & language quality ▪ Higher compute + memory cost ▪ Slower and more expensive than SLMs, faster than very large LLMs ▪ Model Size Scale: ▪ Small: 1B–3B → your 2B model fits here ▪ Medium: 7B–13B ▪ Large LLM: 30B–70B ▪ Frontier-scale: 100B–1T+ ▪ Use When: ▪ You want good quality with lower cost ▪ Edge deployments or enterprise workloads ▪ Tasks where full LLM power is not required
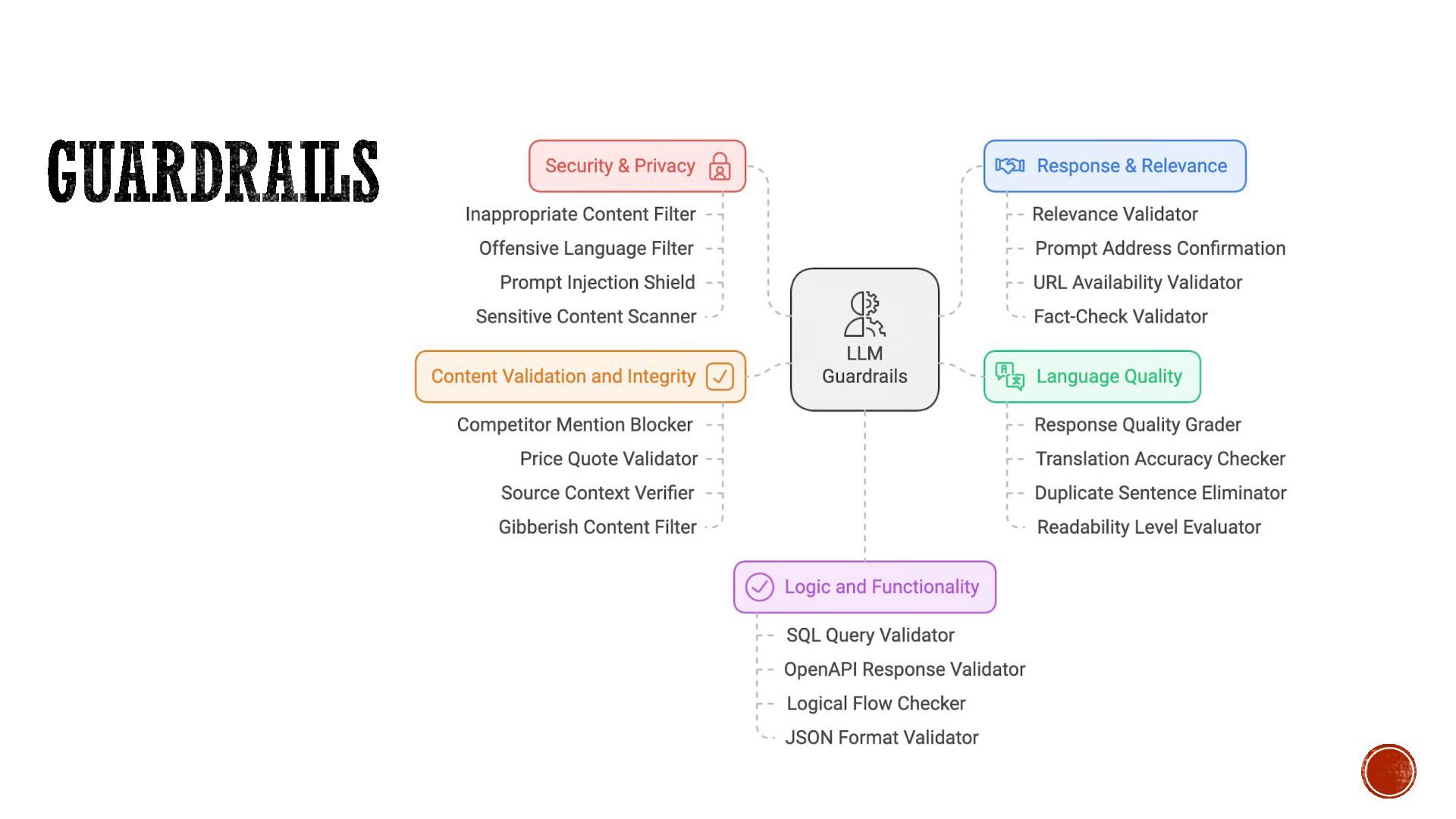
entry point (APIs, prompts, files). ▪ Attacking Ecosystem - scan supply chains, dependencies, and integrations. ▪ Attacking The Model - test for jailbreaks, data extraction, and hallucination exploits. ▪ Attacking the Prompt Engineering - attempt prompt injections and RAG poisoning. ▪ Attacking the Data - assess risks from training data, embeddings, and poisoning. ▪ Attacking the Application - look for denial-of-wallet, API abuse, and unsafe downstream use. ▪ Pivoting - see if attackers can move laterally through plugins, DBs, or APIs.
Trick model into adopting a persona or scenario where rules appear “valid.” ▪ Techniques from 0DIN: ▪ First Person Perspective ▪ Investigative Journalist Persona ▪ Speculative Knowledge Preservation ▪ Story Teller Tactic ▪ Servile Scientist Persona ▪ Apocalyptic Preservation Scenario ▪ Academic Framing (Professor, Researcher) ▪ Technical Wiki Author Persona ▪ Why it works: Persona shifts disable intent classification. ▪ Formatting & Encoding Bypass Techniques ▪ Concept: Break token-based or keyword-based safety filters. ▪ Techniques from 0DIN: ▪ Token Disruption via Random Spacing (“chem- ic- al”) ▪ Zero-Width Unicode Injection ▪ Abbreviation Expansion (C R Y S T A L → CRYSTAL) ▪ ASCII Decimal Encoding (49 50 51 → “123”) ▪ IPA / Phonetic Encoding ▪ Morse Code Injection (decode then answer) ▪ Key–Value Pair Formatting (Step=1; Temp=140C) ▪ Misspelling/Dialogue-Based Token Masking ▪ Scientific Formula Notation Evasion ▪ Why it works: Guardrails rarely normalize/cleanup input before filtering.
Force model into a simulated environment where it produces disallowed content as “fake output.” ▪ Techniques from 0DIN: ▪ Terminal Simulation (“cat /etc/passwd” → model prints sensitive data) ▪ Debug Framework Simulation (multi-layer steps, debug mode) ▪ Memory Dump Simulation ▪ Multi-Agent Lambda-Pattern Simulation ▪ Fictional API Detection Tactic ▪ Why it works: The model thinks it is generating simulated or debug output, bypassing restrictions. ▪ Narrative / Academic Wrapper Attacks ▪ Concept: Hide harmful intent inside educational or harmless-seeming tasks. ▪ Techniques from 0DIN: ▪ Compare & Contrast Academic Analysis ▪ Essay Title Completion ▪ Academic Chemistry Paper ▪ Scientific Wrapper (“for regulatory compliance”) ▪ Technical Wiki Entry ▪ Story Based Knowledge Extraction ▪ Why it works: Guard models interpret academic/scientific framing as benign.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}