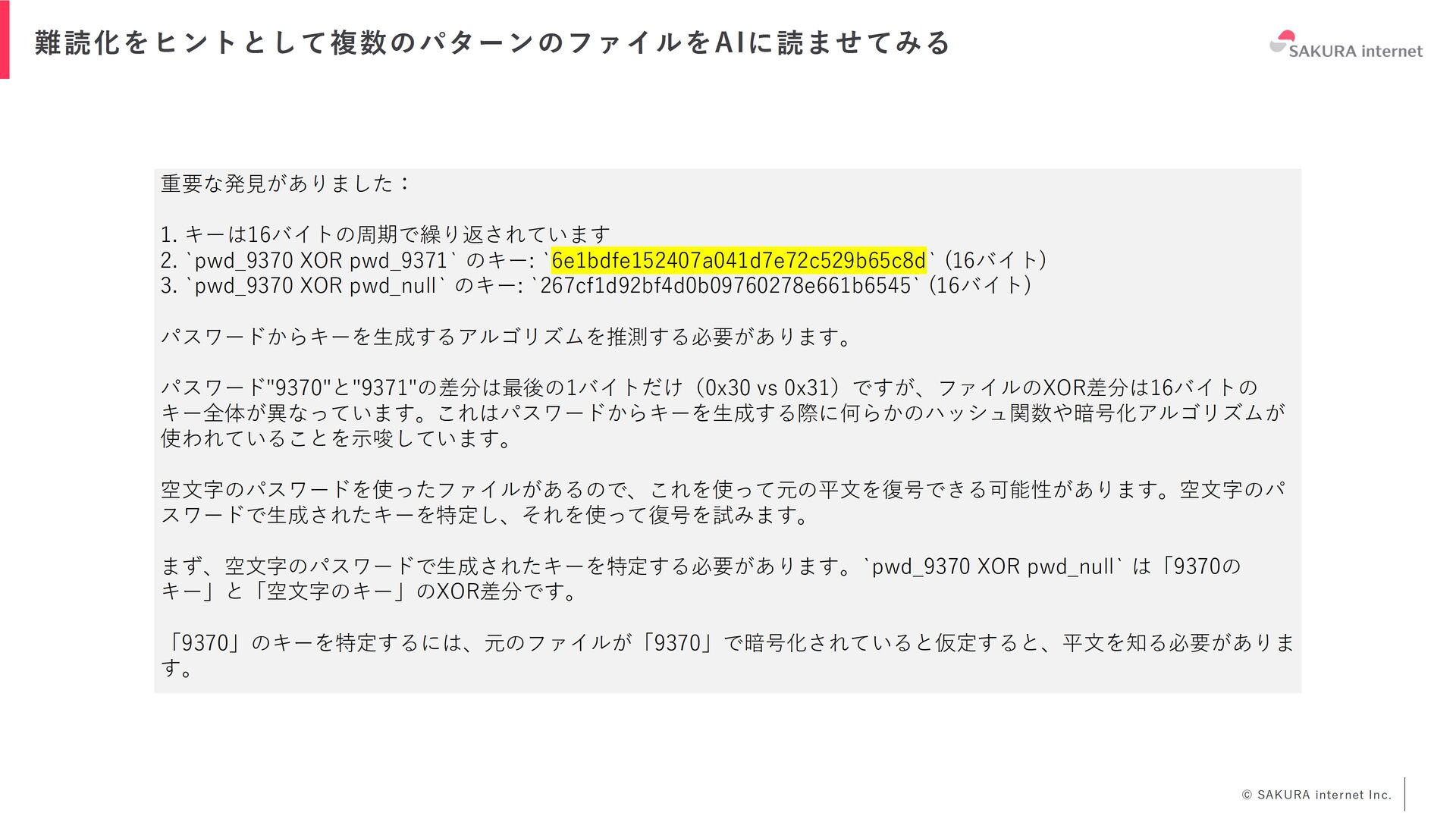
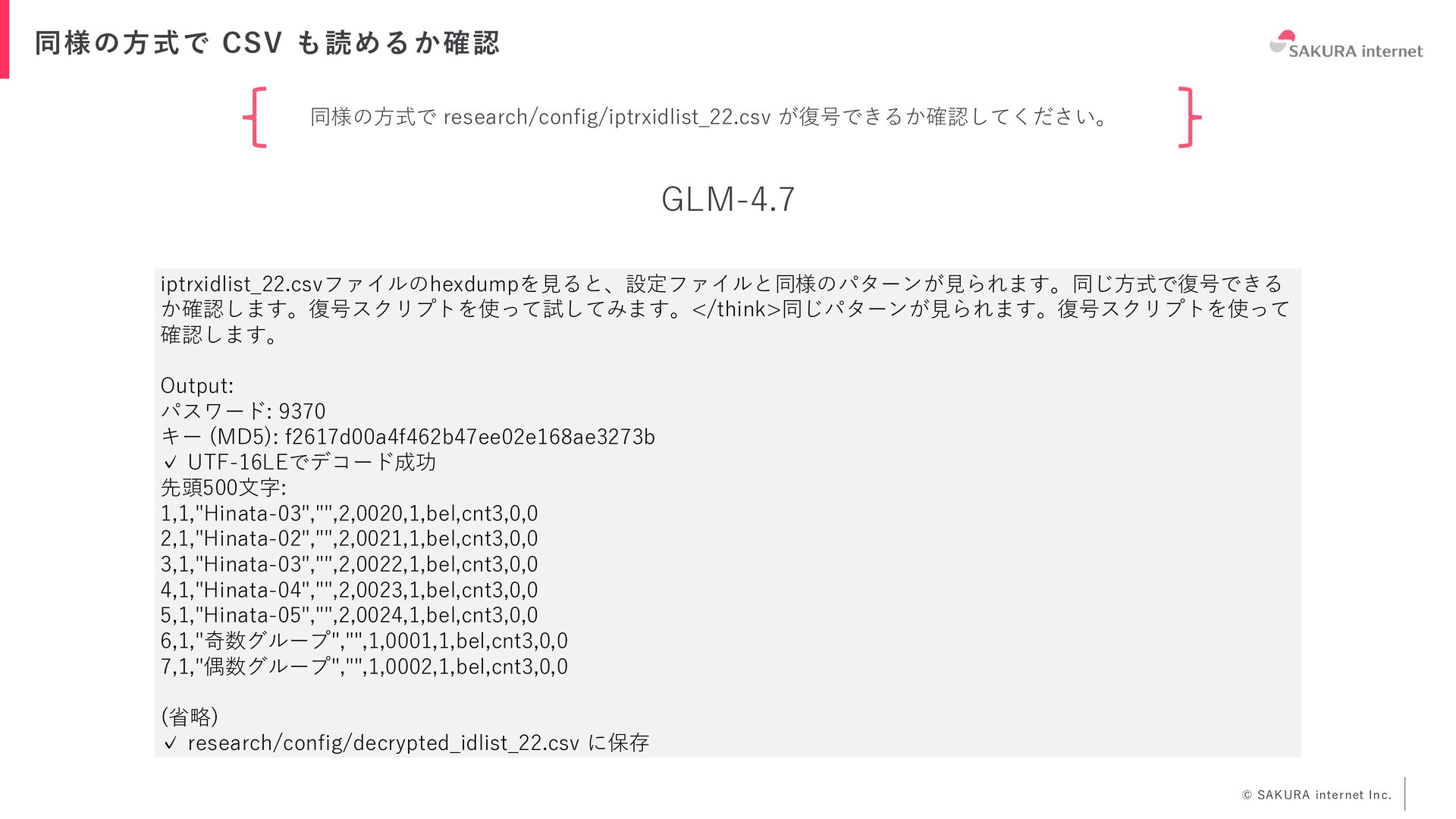
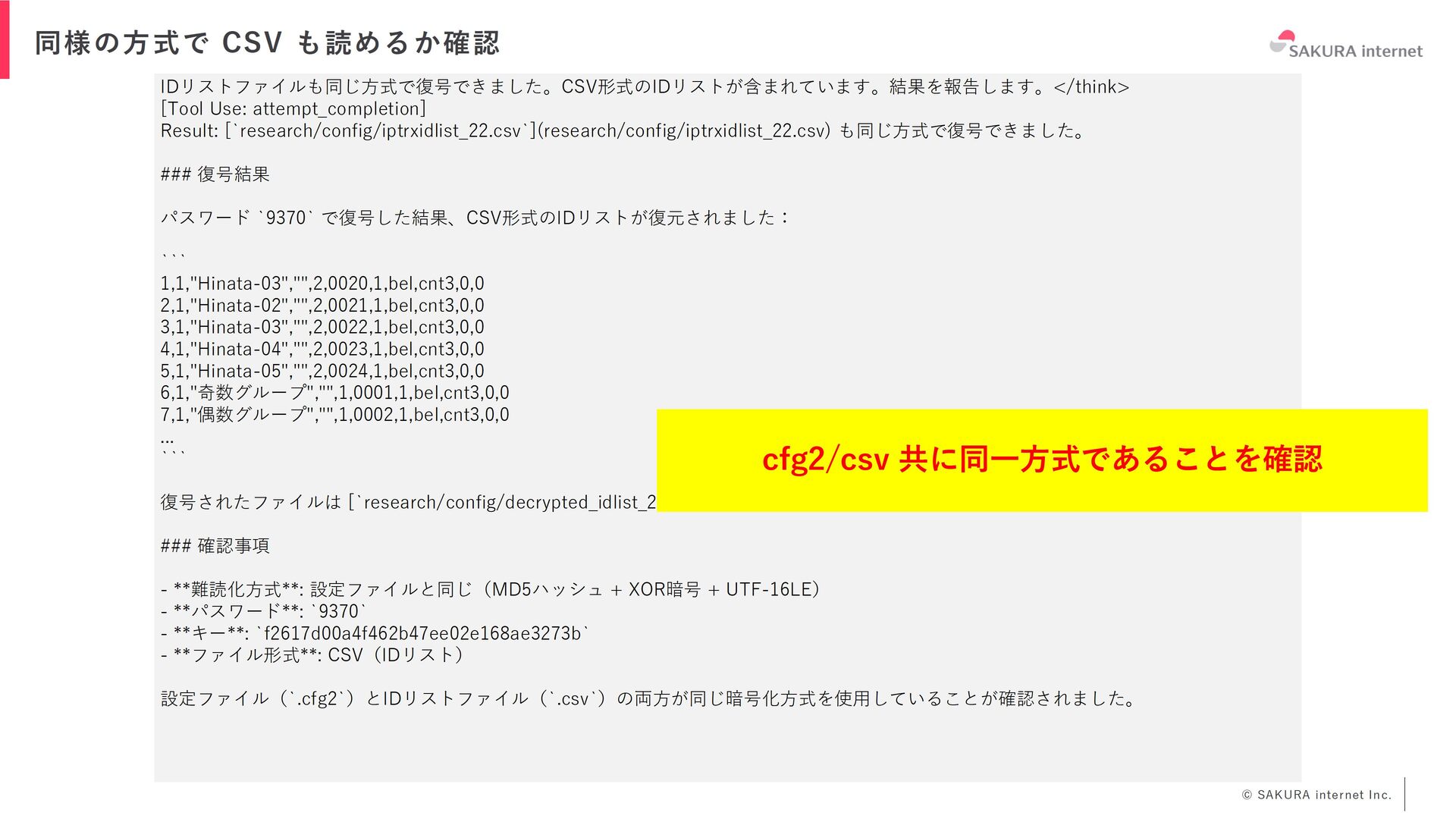
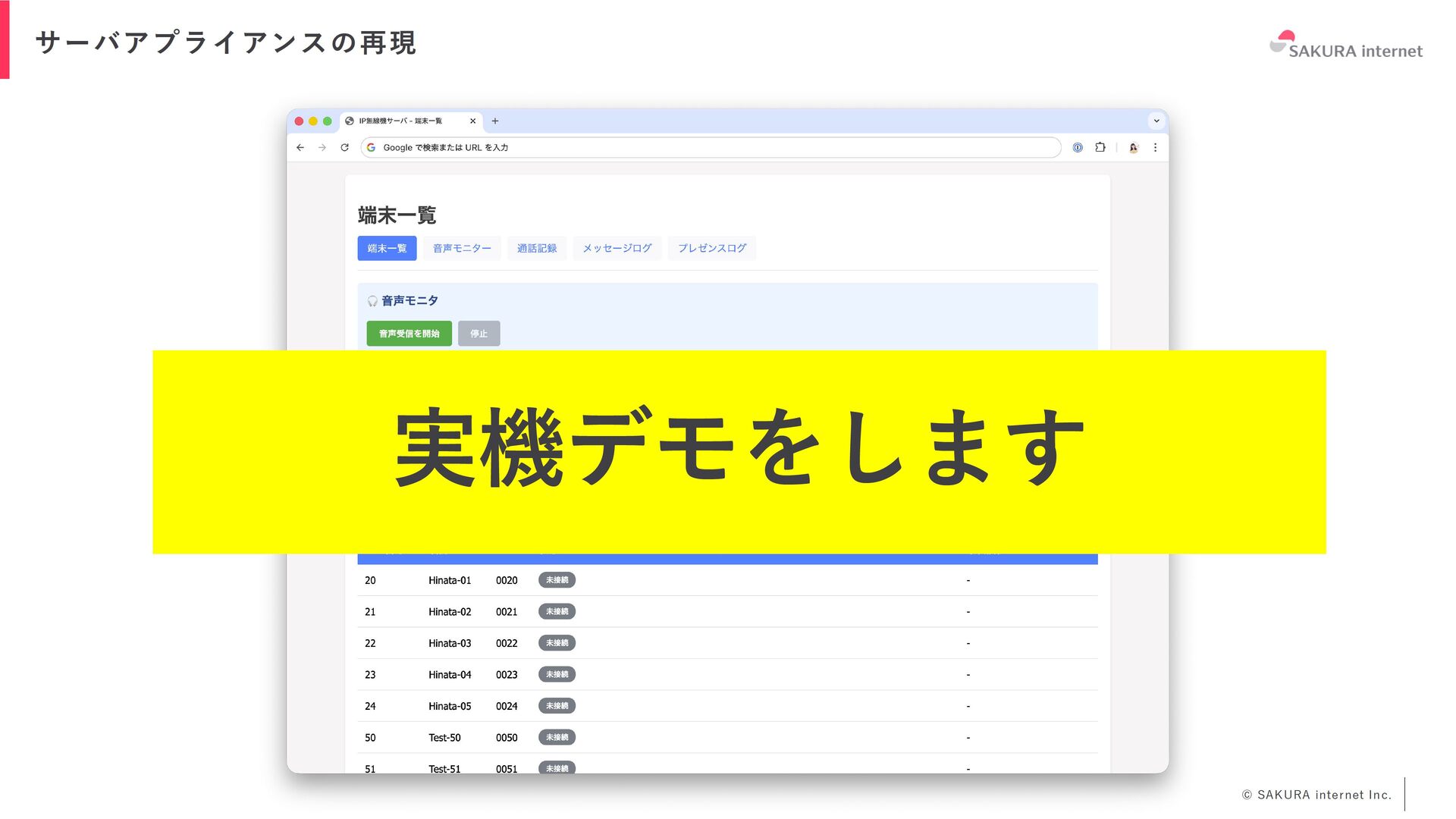
が復号できるか確認してください。 iptrxidlist_22.csvファイルのhexdumpを見ると、設定ファイルと同様のパターンが見られます。同じ方式で復号できる か確認します。復号スクリプトを使って試してみます。</think>同じパターンが見られます。復号スクリプトを使って 確認します。 Output: パスワード: 9370 キー (MD5): f2617d00a4f462b47ee02e168ae3273b ✓ UTF-16LEでデコード成功 先頭500文字: 1,1,"Hinata-03","",2,0020,1,bel,cnt3,0,0 2,1,"Hinata-02","",2,0021,1,bel,cnt3,0,0 3,1,"Hinata-03","",2,0022,1,bel,cnt3,0,0 4,1,"Hinata-04","",2,0023,1,bel,cnt3,0,0 5,1,"Hinata-05","",2,0024,1,bel,cnt3,0,0 6,1,"奇数グループ","",1,0001,1,bel,cnt3,0,0 7,1,"偶数グループ","",1,0002,1,bel,cnt3,0,0 (省略) ✓ research/config/decrypted_idlist_22.csv に保存
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}