Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
専任DEゼロからの データ基盤構築 - Databricks x IaC x AIで 進める...
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
CyberAgent
PRO
June 30, 2026
470
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
専任DEゼロからの データ基盤構築 - Databricks x IaC x AIで 進める「データの民主化」-
CyberAgent
PRO
June 30, 2026
More Decks by CyberAgent
See All by CyberAgent
”AIを使う” から ”AIに任せる” へ ─ 開発プロセスを再設計してAIを組織標準にするまで
cyberagentdevelopers
PRO
1
35
Databricks 導入から Genie 活用まで、全部やった話
cyberagentdevelopers
PRO
0
790
「エンジニア進化論」2028年の開発完全自動化、エンジニアはどう進化するか
cyberagentdevelopers
PRO
9
8.8k
NAB Show 2026 動画技術関連レポート / NAB Show 2026 Report
cyberagentdevelopers
PRO
0
300
Local LLM Meetup #1 Opening
cyberagentdevelopers
PRO
0
430
LocalLLMで機密データを匿名化したい
cyberagentdevelopers
PRO
1
440
Vibe Fine-Tuning Version 2 — RunPod SSH で安く学習してみた
cyberagentdevelopers
PRO
0
420
2026年度新卒技術研修 サイバーエージェントのデータベース 活用事例とパフォーマンス調査入門
cyberagentdevelopers
PRO
10
12k
マッチングアプリにおけるユーザー構成の変化は、事業KPIにどう影響しているのか
cyberagentdevelopers
PRO
1
230
Featured
See All Featured
Paper Plane (Part 1)
katiecoart
PRO
0
9.7k
Highjacked: Video Game Concept Design
rkendrick25
PRO
1
410
The MySQL Ecosystem @ GitHub 2015
samlambert
251
13k
Have SEOs Ruined the Internet? - User Awareness of SEO in 2025
akashhashmi
0
390
Stop Working from a Prison Cell
hatefulcrawdad
274
21k
HTML-Aware ERB: The Path to Reactive Rendering @ RubyCon 2026, Rimini, Italy
marcoroth
2
330
It's Worth the Effort
3n
188
29k
ピンチをチャンスに:未来をつくるプロダクトロードマップ #pmconf2020
aki_iinuma
128
56k
Abbi's Birthday
coloredviolet
3
8.7k
How to Align SEO within the Product Triangle To Get Buy-In & Support - #RIMC
aleyda
2
1.7k
Performance Is Good for Brains [We Love Speed 2024]
tammyeverts
12
1.7k
SEO Brein meetup: CTRL+C is not how to scale international SEO
lindahogenes
1
2.8k
Transcript
専任DEゼロからの データ基盤構築 Databricks x IaC x AIで 進める「データの民主化」 2026/06/25 CA
DATA NIGHT #10 Takuma Daicho
自己紹介 名前:大長 拓磨 (Takuma Daicho) 所属:株式会社AI Shift(2024年中途入社) 職種:インフラエンジニア 担当プロダクト:生成AIを用いたコールセンター 向けAIエージェント「AI
Worker VoiceAgent」 業務内容: GKEなどGoogle Cloud、K8S基盤の管理/運用 ArgoCD、GHAのCI/CD周りの管理/運用
話すこと/話さないこと 【話すこと】 - 専任DE不在の小規模チームによる、段階的な Databricks 移行の実体験 - 少人数でも運用が回る工夫(マネージド/メダリオン/IaC・コスト失敗談込み) - Genie
で非エンジニア(CS / Sales)に分析を開放した結果と「光と影」 【話さないこと】 - 音声対話システム固有の評価ロジックや分析基盤の詳細設計 - Spark / Databricks の内部実装・高度なチューニング - Snowflake など他社基盤との詳細な比較
Outline 目次 1. 背景:データ基盤の限界と 次期基盤への要件 2. 構築:Databricks x IaC x
AIに よる解決策 3. 活用:AI/BI Genieによるビジ ネスユーザーへのデータ民主化 4. 成果と今後の展望
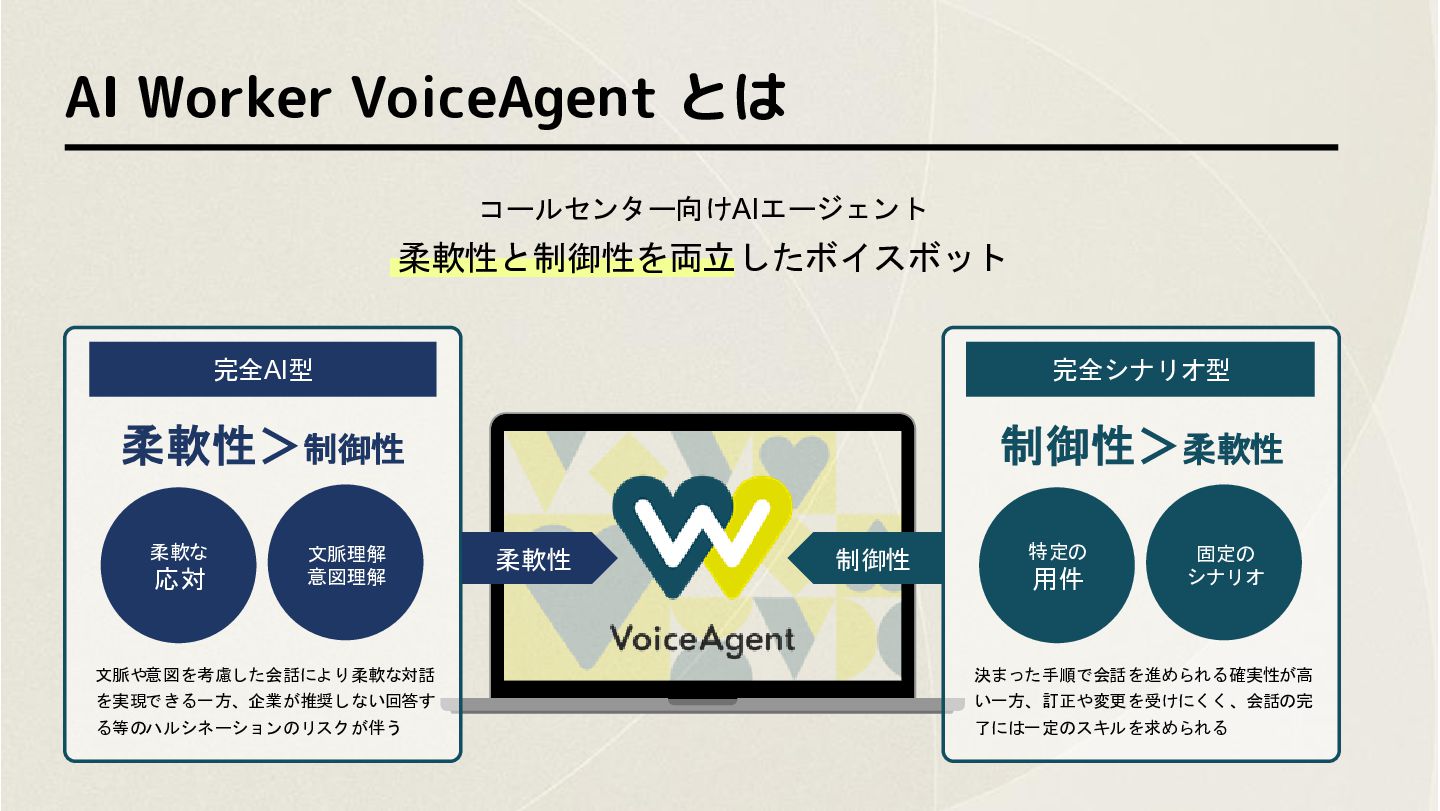
AI Worker VoiceAgent とは コールセンター向けAIエージェント 柔軟性と制御性を両立したボイスボット 文脈や意図を考慮した会話により柔軟な対話 を実現できる一方、企業が推奨しない回答す る等のハルシネーションのリスクが伴う 完全AI型
柔軟性>制御性 柔軟な 応対 文脈理解 意図理解 柔軟性 決まった手順で会話を進められる確実性が高 い一方、訂正や変更を受けにくく、会話の完 了には一定のスキルを求められる 完全シナリオ型 制御性>柔軟性 特定の 用件 固定の シナリオ 制御性
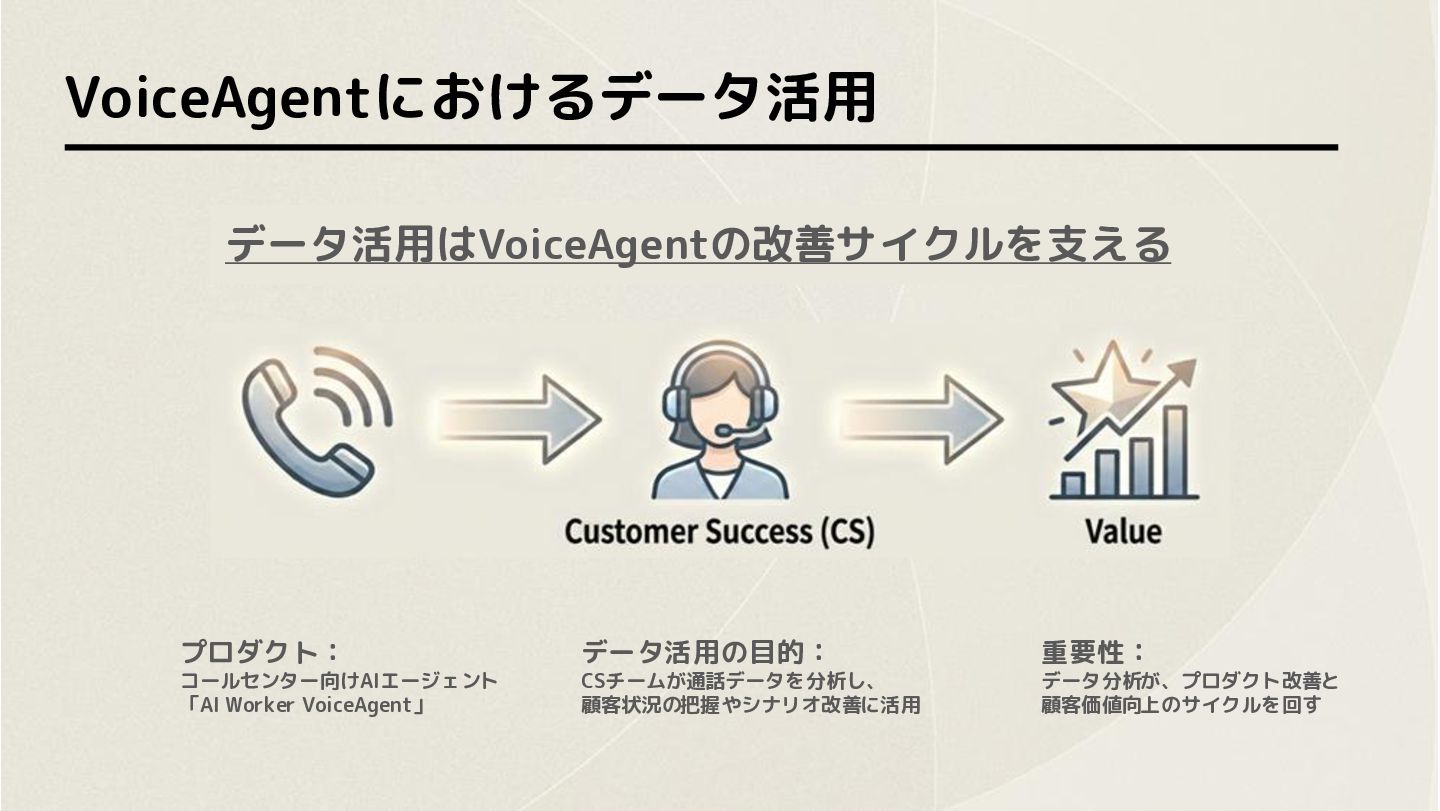
VoiceAgentにおけるデータ活用 データ活用はVoiceAgentの改善サイクルを支える プロダクト: コールセンター向けAIエージェント 「AI Worker VoiceAgent」 重要性: データ分析が、プロダクト改善と 顧客価値向上のサイクルを回す
データ活用の目的: CSチームが通話データを分析し、 顧客状況の把握やシナリオ改善に活用
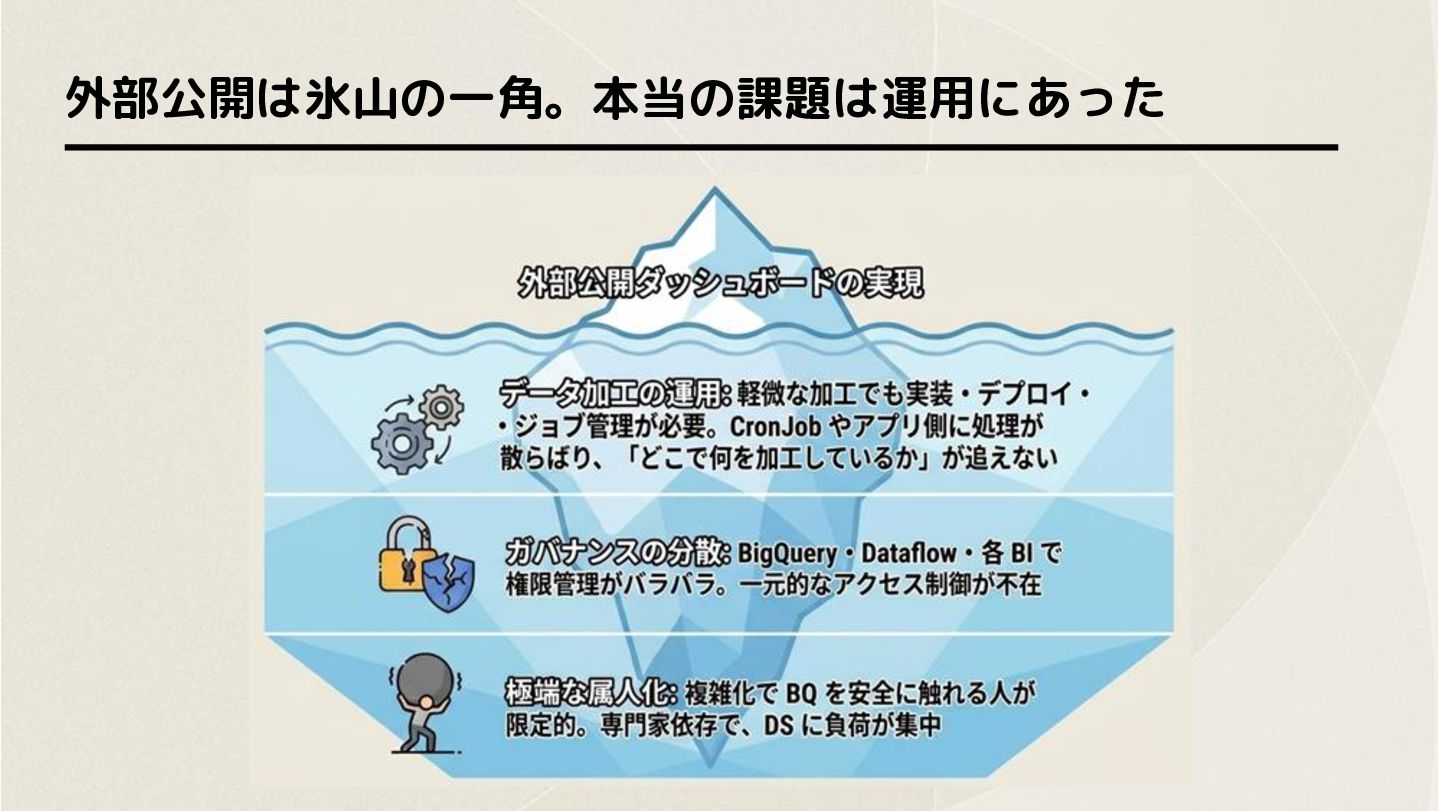
〜きっかけは顧客向けダッシュボード、本当の課題はデータ運用〜 外部公開の壁と運用課題
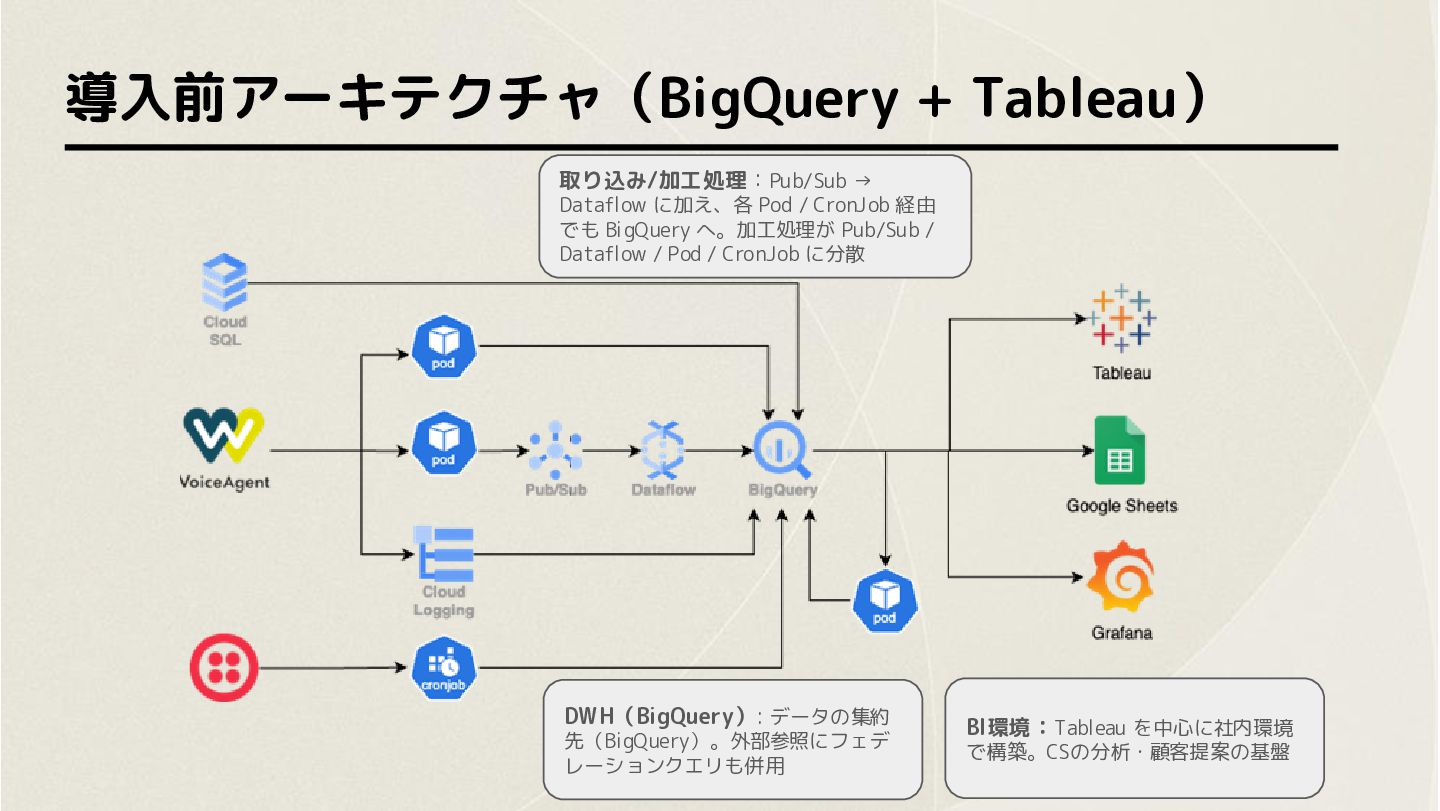
導入前アーキテクチャ(BigQuery + Tableau) 取り込み/加工処理:Pub/Sub → Dataflow に加え、各 Pod / CronJob
経由 でも BigQuery へ。加工処理が Pub/Sub / Dataflow / Pod / CronJob に分散 DWH(BigQuery): データの集約 先(BigQuery)。外部参照にフェデ レーションクエリも併用 BI環境:Tableau を中心に社内環境 で構築。CSの分析・顧客提案の基盤
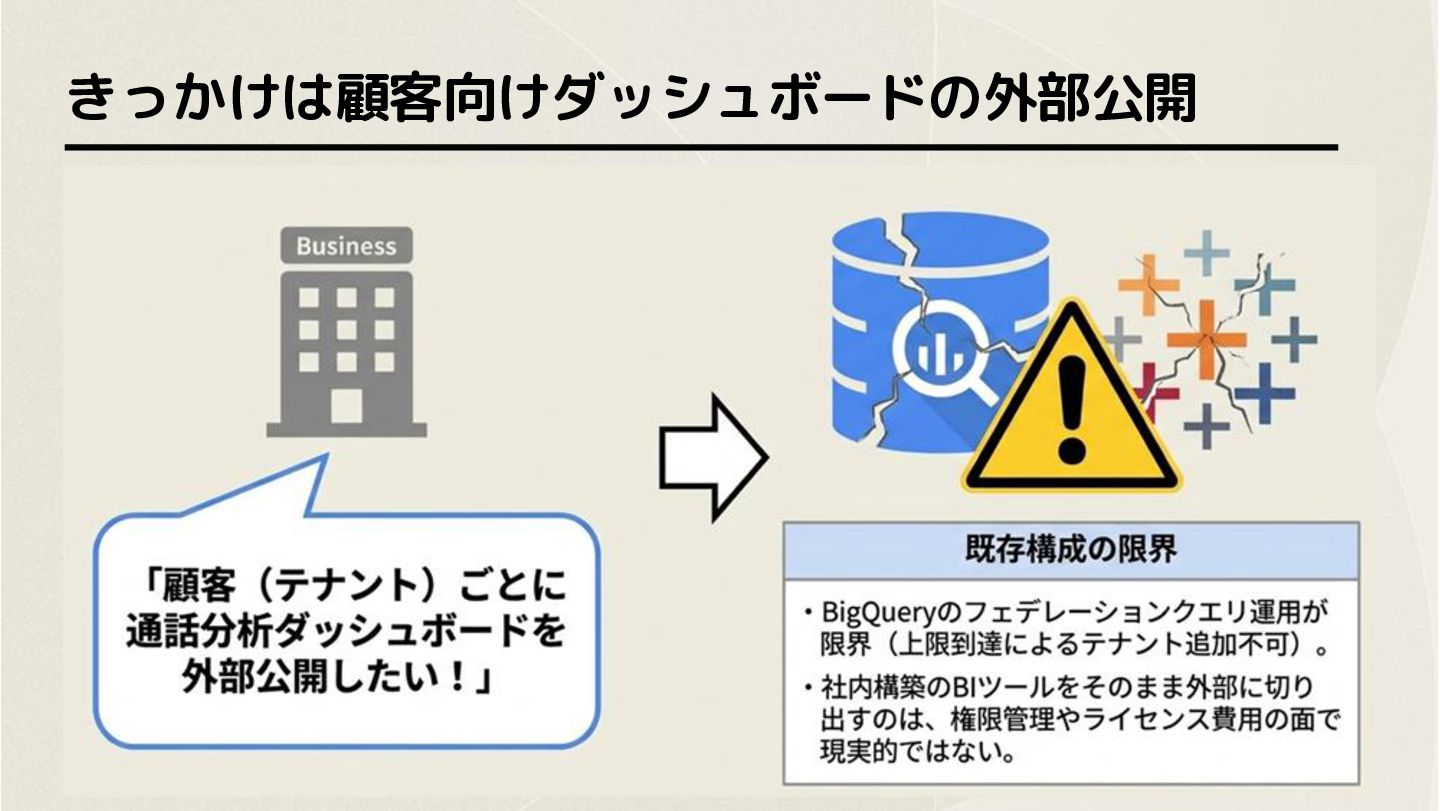
きっかけは顧客向けダッシュボードの外部公開
外部公開は氷山の一角。本当の課題は運用にあった
欲しかったのは少人数でも安全に外部公開できる基盤 これらの要件を満たせそうな基盤として、Databricksの導入検証を決定 運用負荷の低さ(マネージド) 少人数でもETLから管理まで運用しや すいこと 強固なデータガバナンス マルチテナント環境で一元的に アクセス制御・権限管理ができること 外部ダッシュボード提供の可能性 顧客向けダッシュボードを将来的に展
開できること IaC・AIとの親和性 全てのリソースをコード管理し、LLM が構成を理解・修正できること 1 3 4 2
〜マネージドの恩恵と、少人数運用のための工夫〜 検証と導入
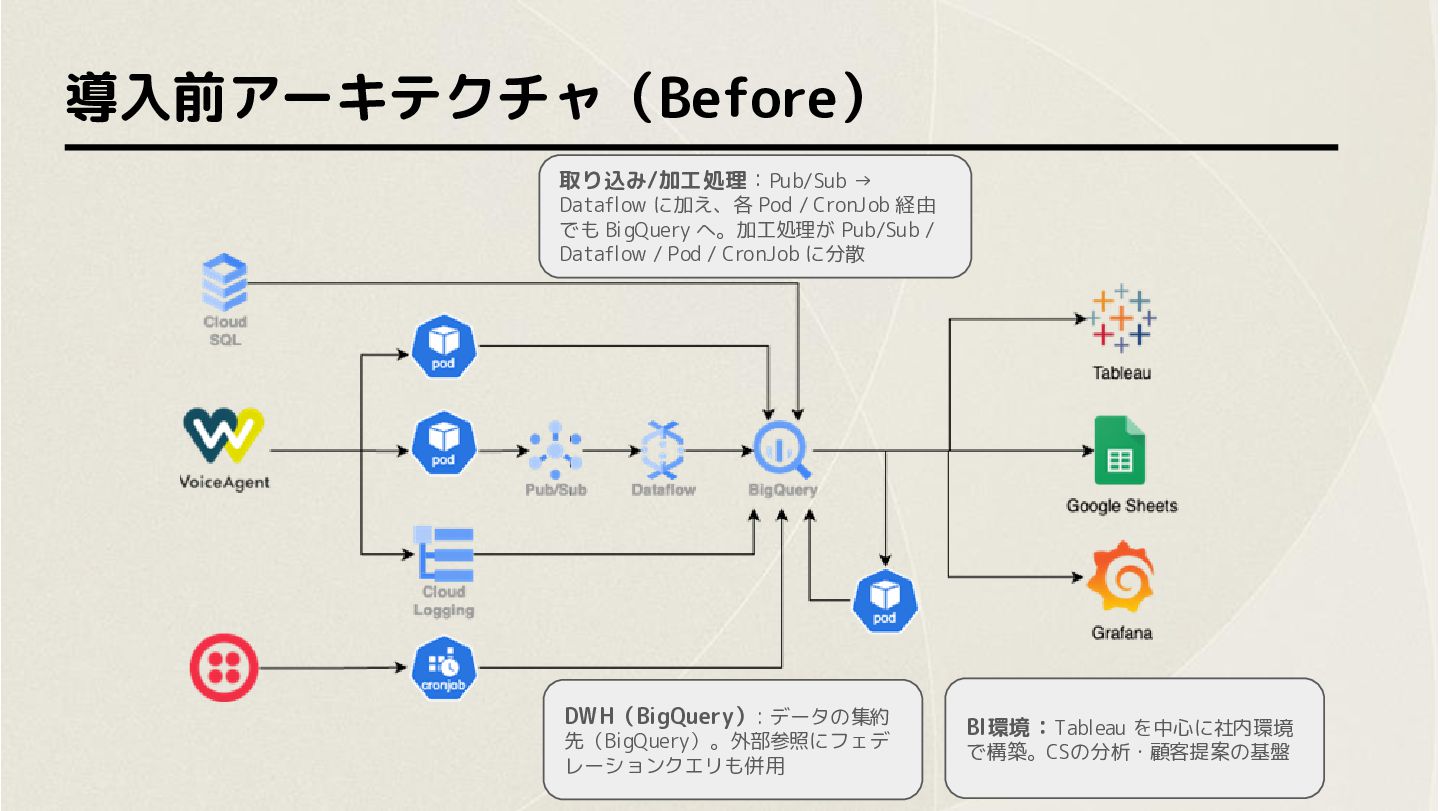
導入前アーキテクチャ(Before) 取り込み/加工処理:Pub/Sub → Dataflow に加え、各 Pod / CronJob 経由 でも
BigQuery へ。加工処理が Pub/Sub / Dataflow / Pod / CronJob に分散 DWH(BigQuery): データの集約 先(BigQuery)。外部参照にフェデ レーションクエリも併用 BI環境:Tableau を中心に社内環境 で構築。CSの分析・顧客提案の基盤
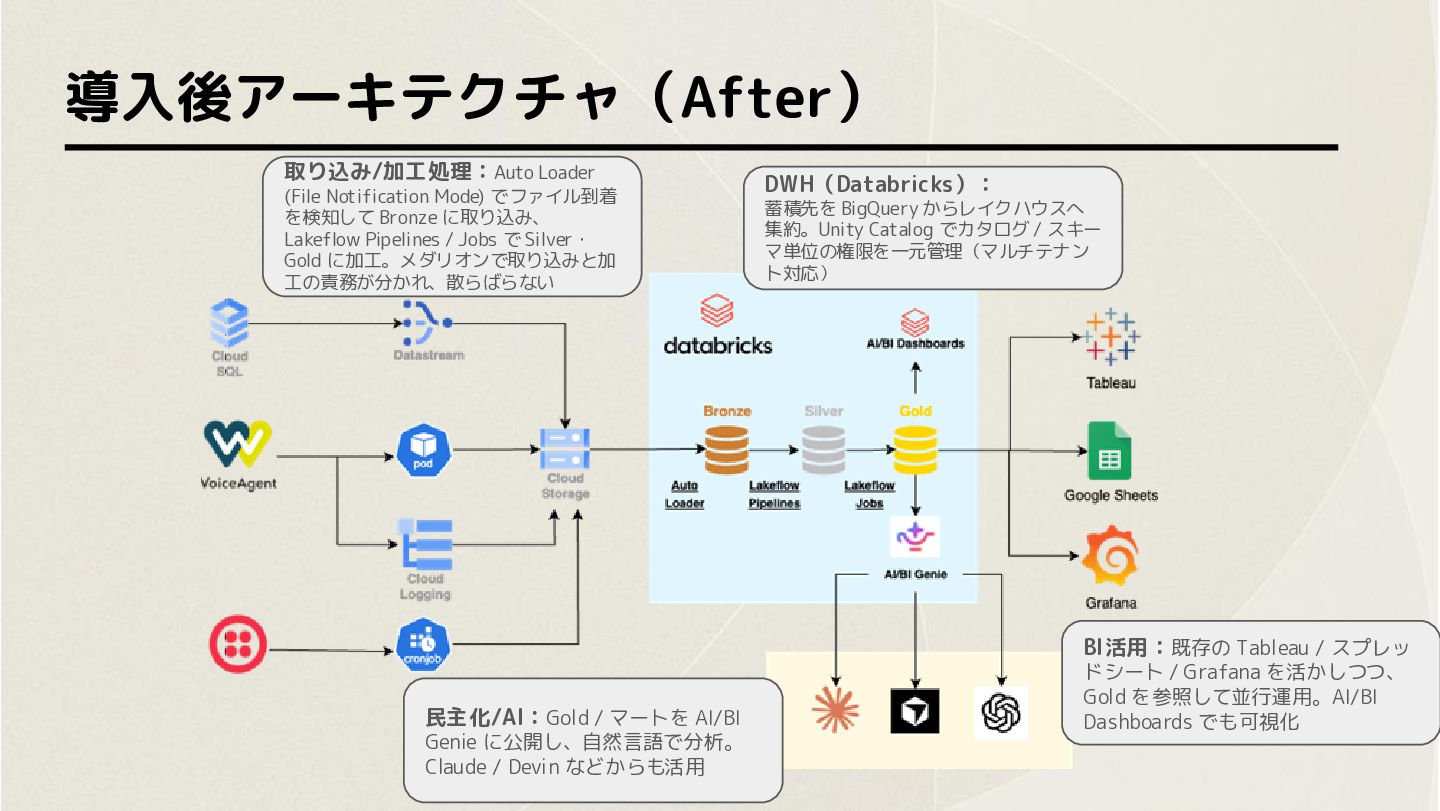
導入後アーキテクチャ(After) 取り込み/加工処理:Auto Loader (File Notification Mode) でファイル到着 を検知して Bronze に取り込み、
Lakeflow Pipelines / Jobs で Silver・ Gold に加工。メダリオンで取り込みと加 工の責務が分かれ、散らばらない DWH(Databricks): 蓄積先を BigQuery からレイクハウスへ 集約。Unity Catalog でカタログ / スキー マ単位の権限を一元管理(マルチテナン ト対応) 民主化/AI:Gold / マートを AI/BI Genie に公開し、自然言語で分析。 Claude / Devin などからも活用 BI活用:既存の Tableau / スプレッ ドシート / Grafana を活かしつつ、 Gold を参照して並行運用。AI/BI Dashboards でも可視化
工夫1:少人数運用 メダリオンアーキテクチャ、マネージドを利用しデータパイプラインを設計 - データ置き場の役割を明確にし、迷わないアーキテクチャを実現 - パイプラインが一元管理できるようになり、データ遡及なども容易に - マネージドサービス(Auto Loader, Lakeflow
Pipelines, Lakeflow Jobs)を利用 - Databricksのプラクティスに乗ることで、少人数でもパイプライン構築を進められた 運用開始後の属人化を防ぐため、すべてのリソースをIaC管理 - 全ての関連リソースをIaC(Terraform / Declarative Automation Bundles)で管理 - モノレポで管理することでナレッジの分散を防ぎ、AIとの親和性が高い構成 - CI/CDの整備し、デプロイフローを自動化
工夫2:サーバーレスのコスト設計 【検証時に発生した事件】 - ① Classic Compute を起動しっぱなしにしてしまい、何もしていないのに一晩で200ドル - ② パイプラインを分割しすぎて、月10,000ドルを超えるパイプラインが爆誕
【対策:鮮度とコストを設計する】 - コンピュートノードは全て Serverless Compute を採用 - コンピュートノードのスペック、自動停止時間を見直し(S→XXS、アイドル時間停止を早める) - 分割しすぎたパイプラインを統合、取込み処理の見直し(File Notification Mode で無駄を削減) - データ鮮度、スケジュール設計:PRD 1日2回/STG 1日1回/DEV 停止(業務ピークも回避) - 各ワークスペースに予算・コストアラートを設定し、コストダッシュボードで可視化 【結果】見直し後は 1日約$10(月約$300)で安定。鮮度とコストを設計してコントロール下に置けた サーバーレス=コスト解決ではない。鮮度とコストを意識した「設計」が要る
〜専門家に依頼する分析から、まず自分で聞いてみる分析へ〜 AI/BI Genieによるデータ民主化
AI/BI Genie とは Databricks が提供する AIエージェント型の分析アシスタント 自然言語 → SQL生成 →
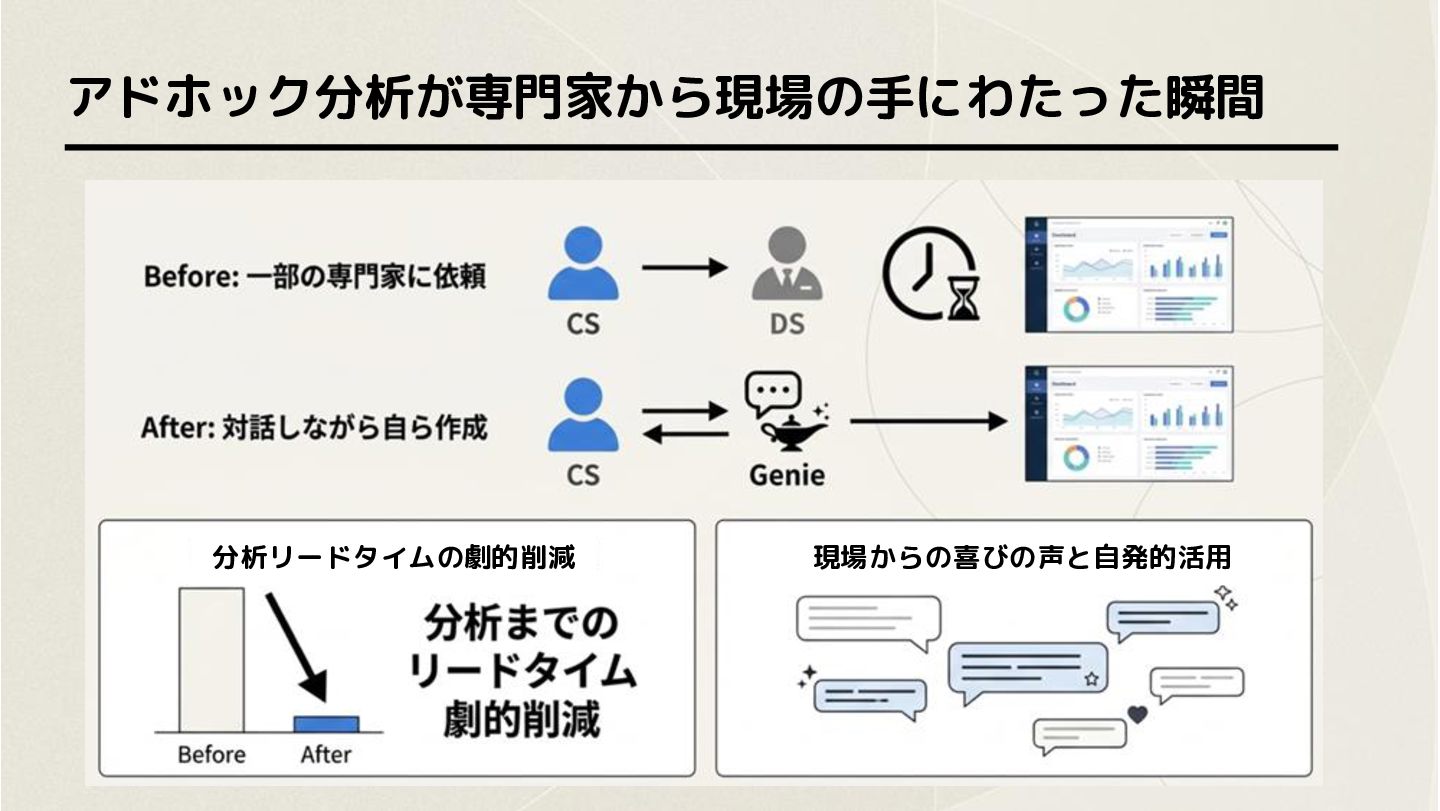
分析 / 可視化 - ① ユーザーの質問を解釈し、内部的にSQLを生成 - ② 取得したデータ集計・分析を行い、結果を返却 専門的なSQLの知識がなくても、 日常的な自然言語で高度なデータ分析や可視化を行える - ビジネスユーザーでも業務データを対話的に確認できる - アドホック分析を「専門家に依頼」から「まず自分で聞く」へ 公式MCPが提供されており、Claudeなど既存LLM、ツールとの接続も可能 - Databricks上に整理されたデータがあれば、自然言語で分析する入口を作りやすい AI/BI Genieを活用することで誰でも簡単にデータ分析ができる世界が実現できる
何でも見せない。Genie に作る「質問してよい世界」 【懸念】全テーブルをそのまま開放すると... 意図しないテーブルや似たカラムを誤用 → 結果の信頼性が下がり、問い合わせも増える可能性 【工夫】まずは2点を実施 ① 見せるマートを絞る:既存ダッシュボードで使う信頼できる データ(Gold/絞ったマート)だけを
Genie に渡す ② カラムへのコメントを徹底:テーブル・カラムに コメント+自然言語の指示文を添える(凝った調整より、まずこれが効く) まずはコメント・指示文の整備だけでも、実用に近い回答が得られた
アドホック分析が専門家から現場の手にわたった瞬間 分析リードタイムの劇的削減 現場からの喜びの声と自発的活用
〜民主化がもたらした光と影、基盤は作って終わりではない〜 導入の成果と、その先へ
導入成果 管理性向上:Unity Catalog で権限を一元管理。分散していたアクセス制御を カタログ/スキーマ単位でまとめ、マルチテナントでも統制できるようになった 運用性向上:メダリオン+マネージドで取り込み〜加工〜格納の責務が 明確になり、「どこで何を加工しているか」が追えるようになった 属人性軽減:全リソースをコード管理し、CI/CD と AI
活用で、 普段触らないメンバーでも構成を追いやすくなった データ民主化:職種に問わず Genie を通じて自分たちで分析できるように。 直近30日で324質問・4チームへ利用が拡大(月81時間の削減=試算)
民主化の「光」と「影」
まとめ Databricks x IaC x AI により、専任DE不在でもデータ基盤を構築できた - マネージド機能とメダリオン構成にのせることで迷わず構築・移行ができた -
IaCとCI/CDを一緒に整備することで、属人性を抑えた透明性の高い基盤を実現できた 副次的に導入したGenieによりデータ民主化の地盤が整った - Genieにより誰でも簡単にデータ活用ができる世界を実現できた - ビジネスメンバーが自ら分析→改善のサイクルを回せる地盤を整えられた ただし、データ基盤は作って終わりではなく、変わり続けていくもの - データ活用が進むほど、データ品質・モデリング・権限設計などより難しい課題が山積み - 音声対話システムの評価基盤や顧客向け分析基盤を育てるには、DEの力が必要
今後の展望 ▪ 短期 - 社内向けダッシュボードの拡充(既存BIからの移行) - 社内での Databricks 活用事例の拡大(活用事例の模索) -
データソース追加による活用領域の拡大(データの追加) - Genie のモニタリング・継続チューニング(信頼性向上) ▪ 中長期 - 外部向けダッシュボード提供方法の検討 - 非構造化データ・大量ログの分析基盤としての利活用推進 - AI Lab と連携し、音声データを用いた対話評価基盤の検証
None
Thank you ! 質問/フィードバックお待ちしております
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}