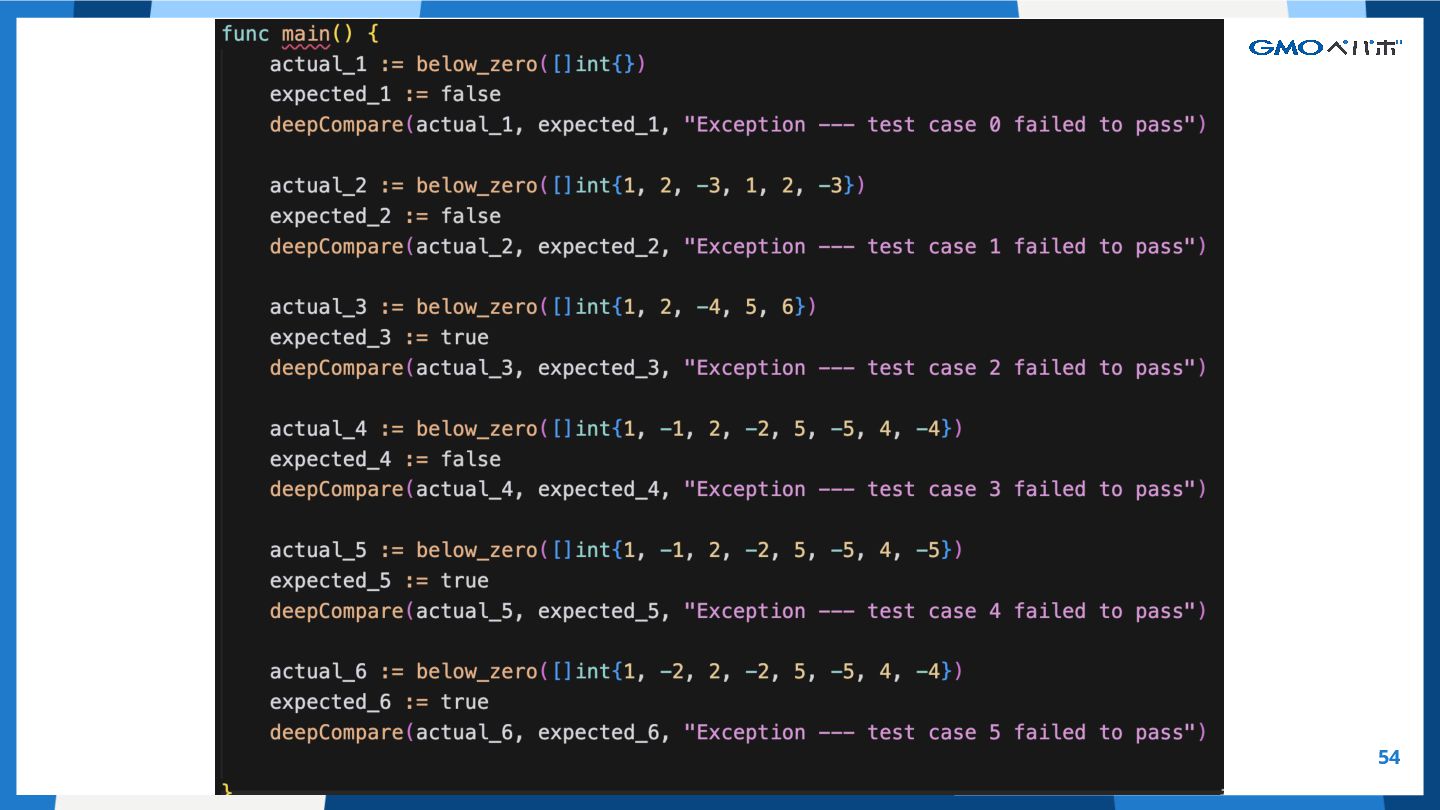
GitHub由来の解答を⽣成しないように、⼈間が⼿書き でコードを⽣成。⾔語理解、アルゴリズムなどコー ディング⾯接っぽい問題。Pythonのコード。 データセット: HumanEval Mark Chen, et.al. , Evaluating Large Language Models Trained on Code, 2021, https://arxiv.org/pdf/2107.03374, https://github.com/openai/human-eval
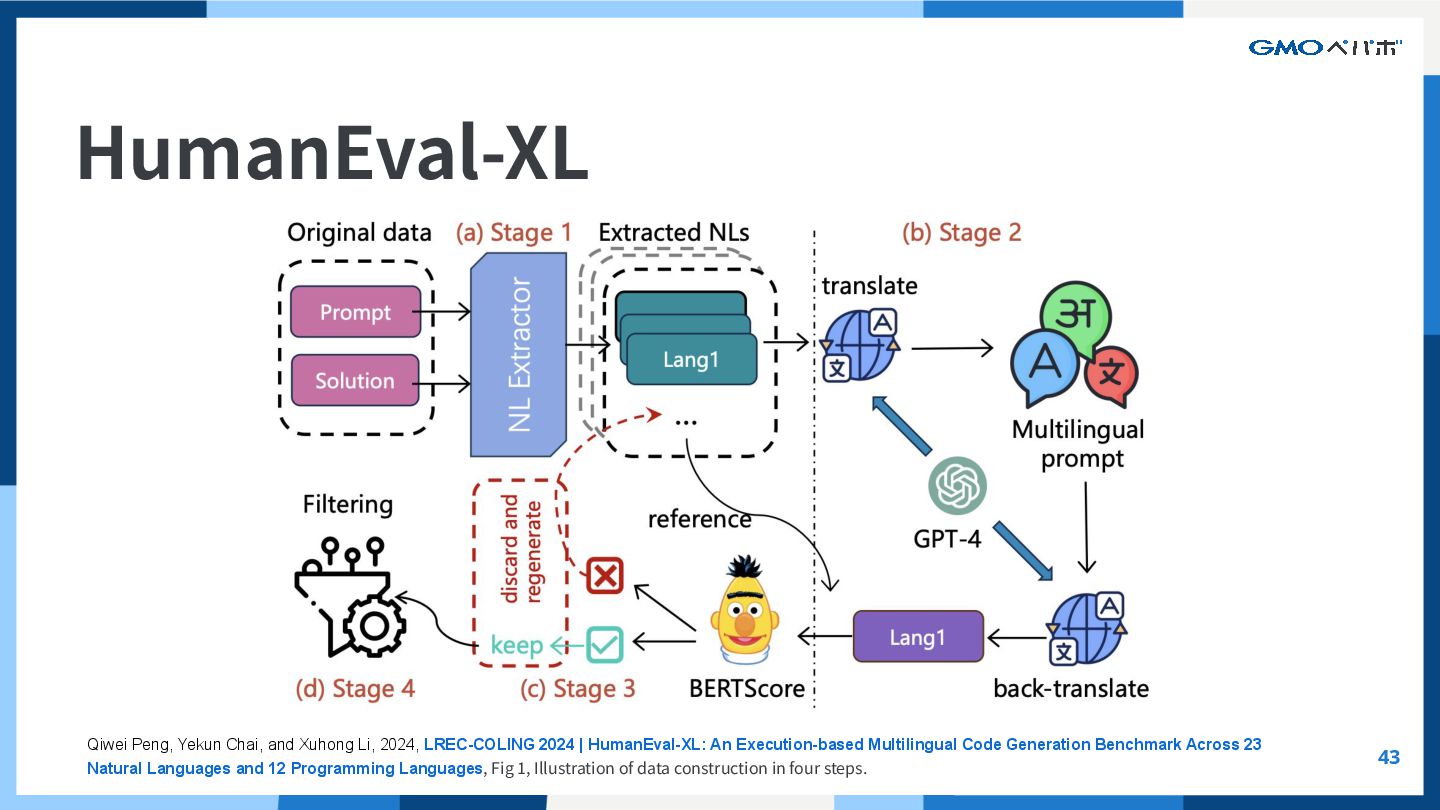
LREC-COLING 2024 | HumanEval-XL: An Execution-based Multilingual Code Generation Benchmark Across 23 Natural Languages and 12 Programming Languages, Fig 1, Illustration of data construction in four steps.
ていくシナリオのものです。多様なコード⽣成をしつつ、正しいコードが⽣成 できるかの指標 評価⽅法: pass@k について Qiwei Peng, Yekun Chai, and Xuhong Li, 2024, LREC-COLING 2024 | HumanEval-XL: An Execution-based Multilingual Code Generation Benchmark Across 23 Natural Languages and 12 Programming Languages, Fig 1, Illustration of data construction in four steps.
SWE-bench SWE-bench: Can Language Models Resolve Real-World GitHub Issues?, Carlos E. Jimenez et al. 2024, https://arxiv.org/abs/2310.06770 https://github.com/SWE-bench/SWE-bench
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
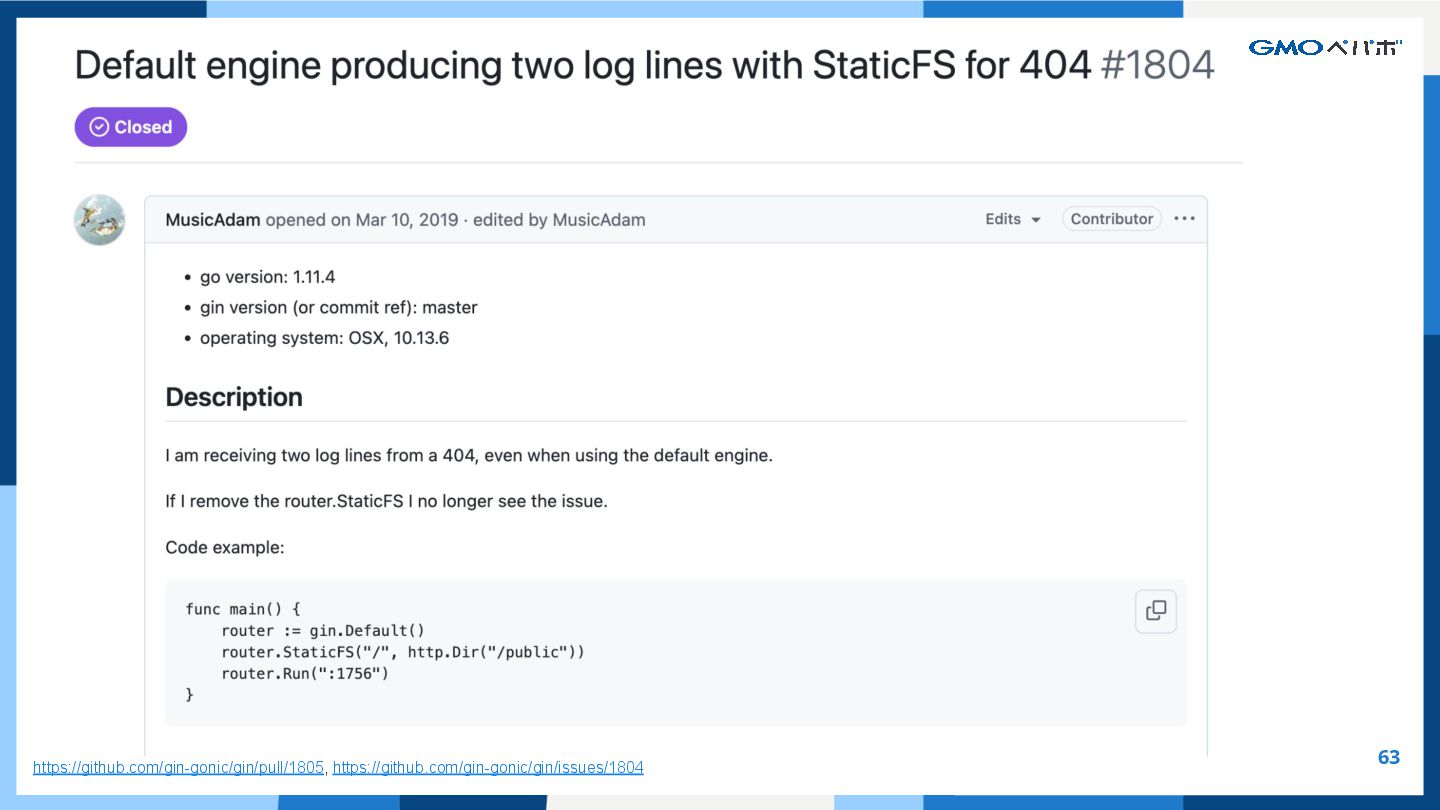{kind=link}
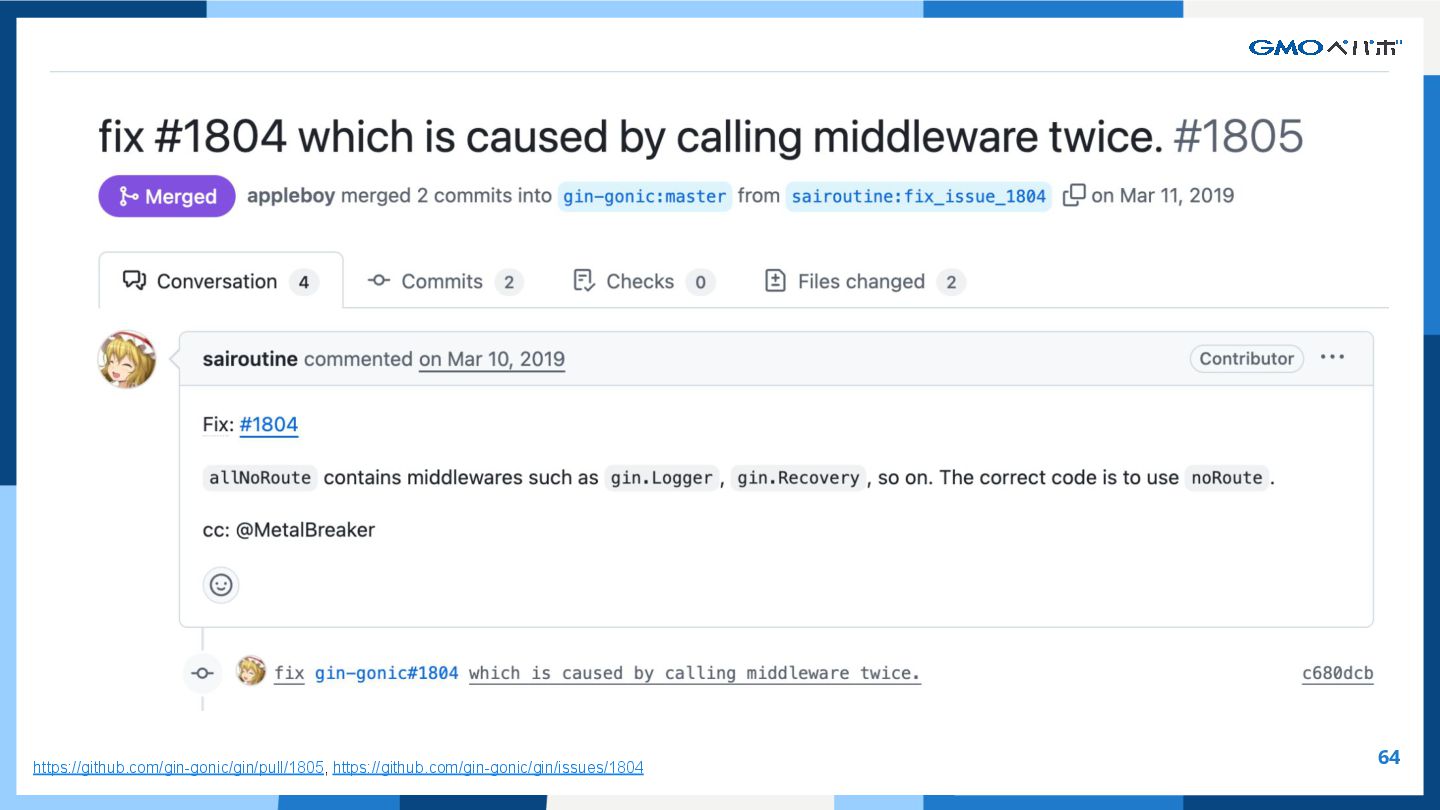{kind=link}
{kind=link}
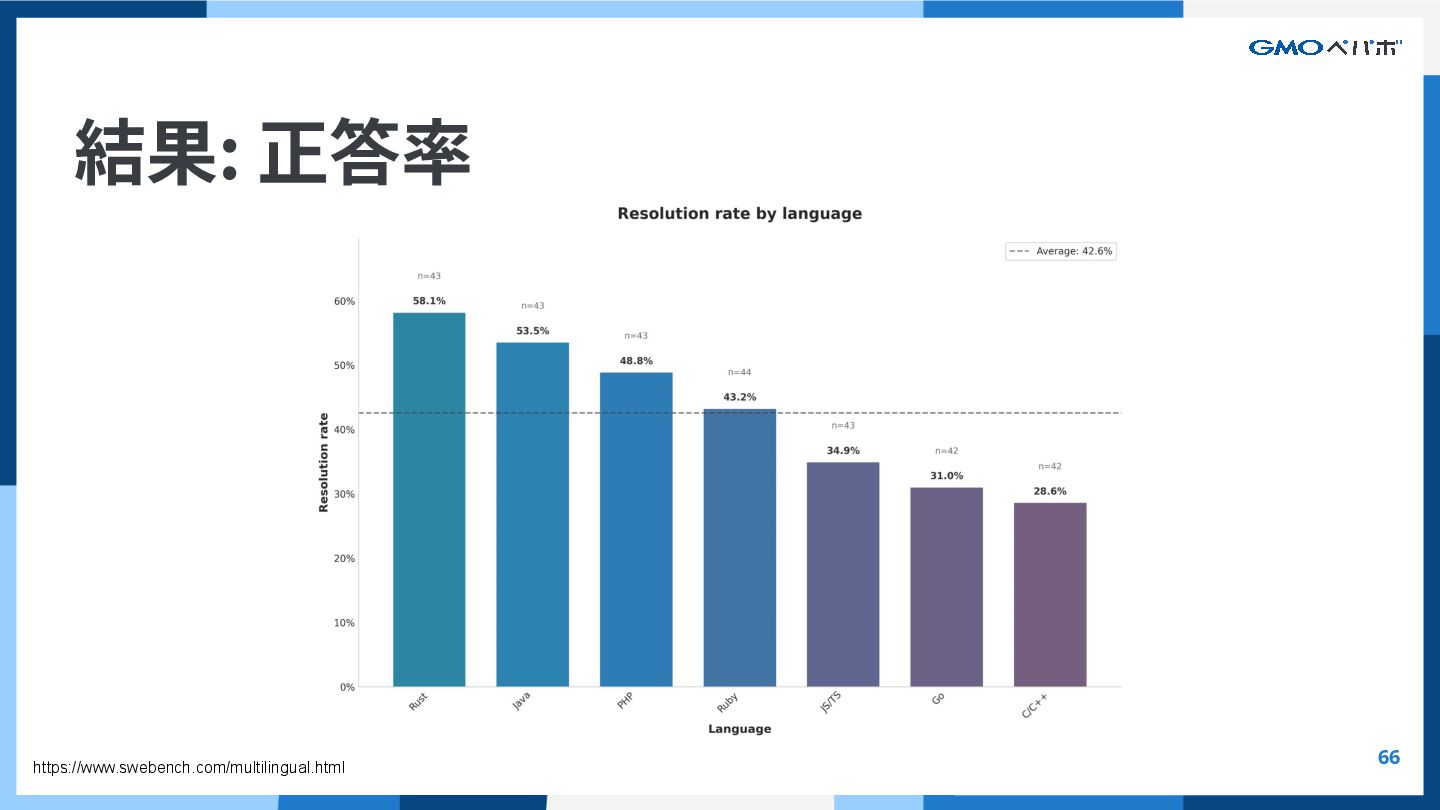{kind=link}
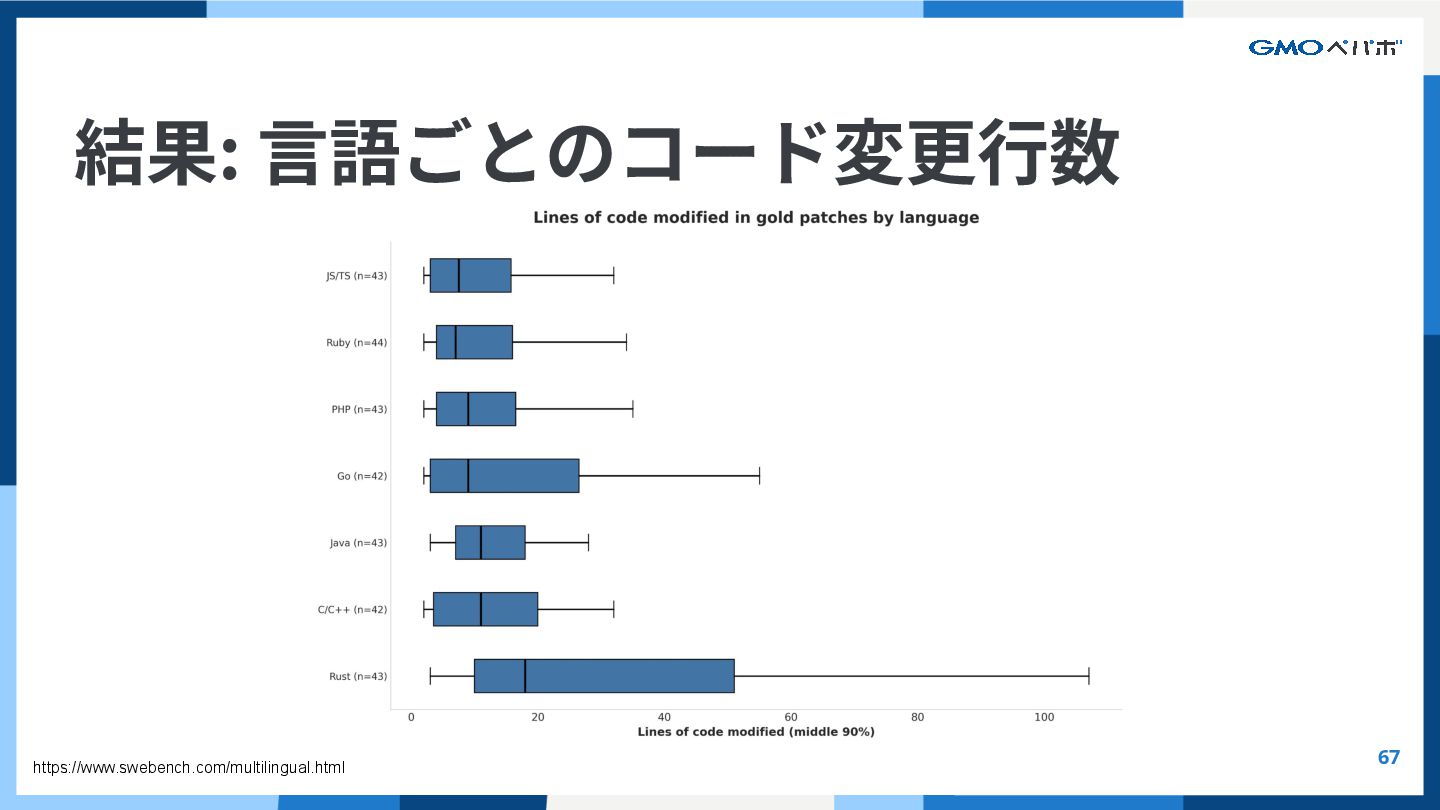{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
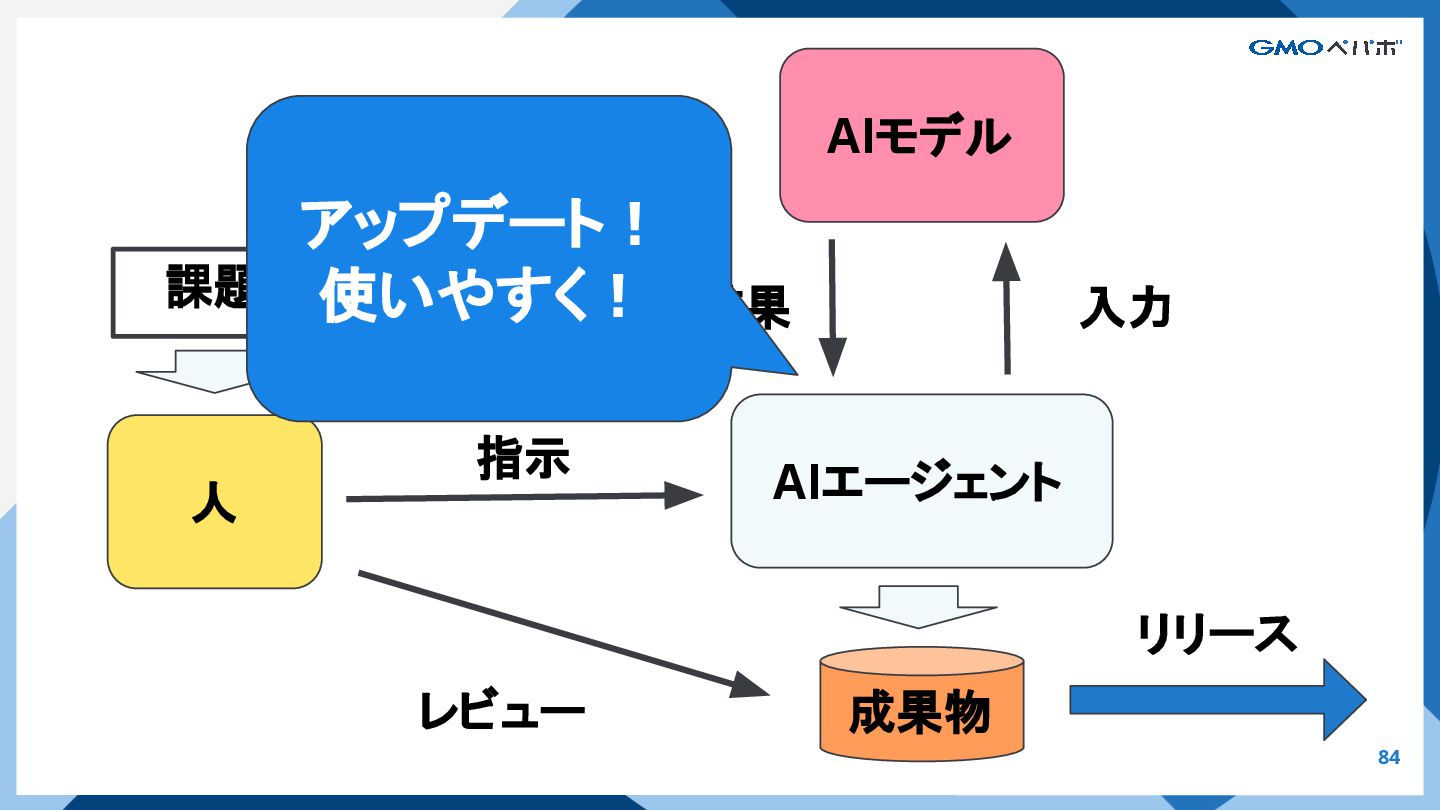{kind=link}
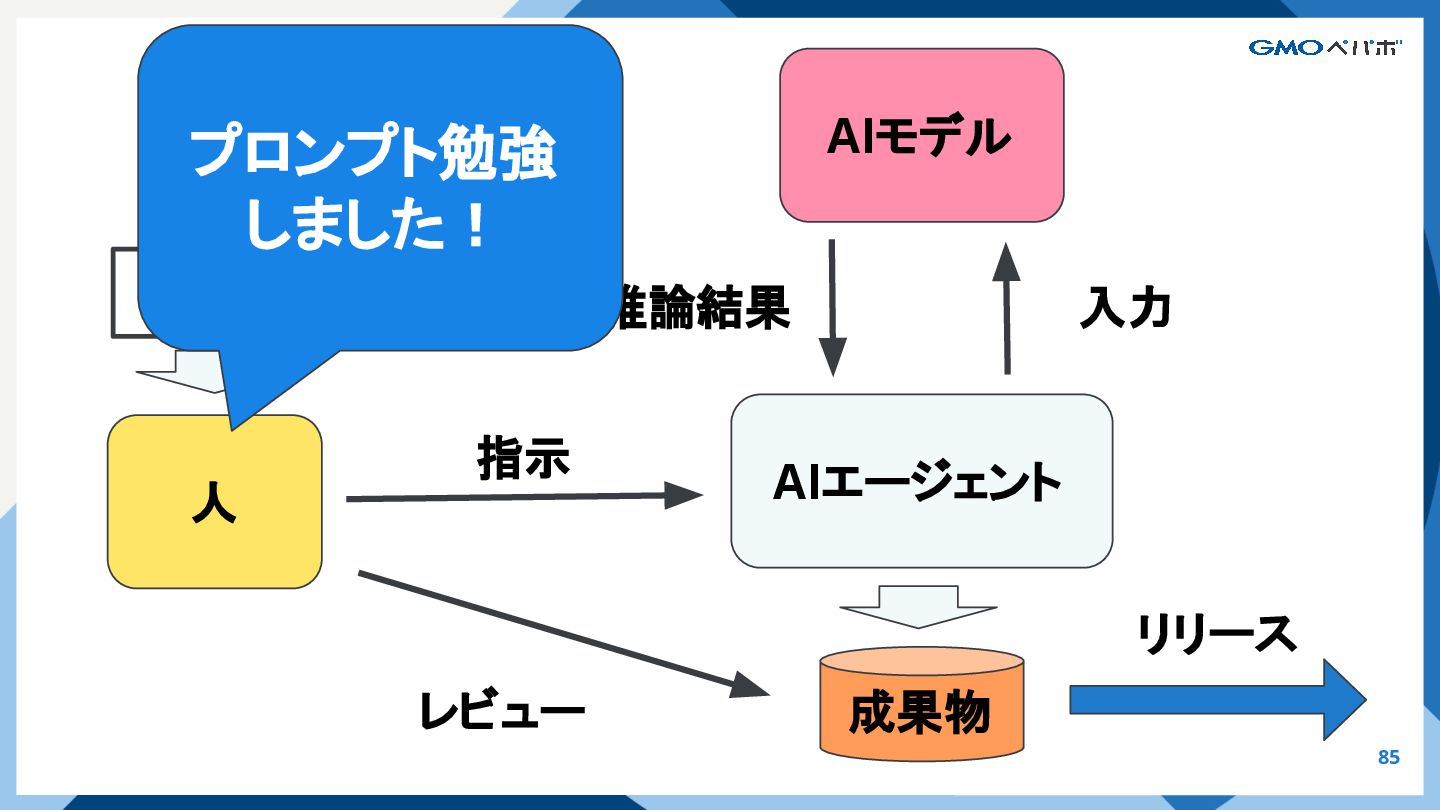{kind=link}
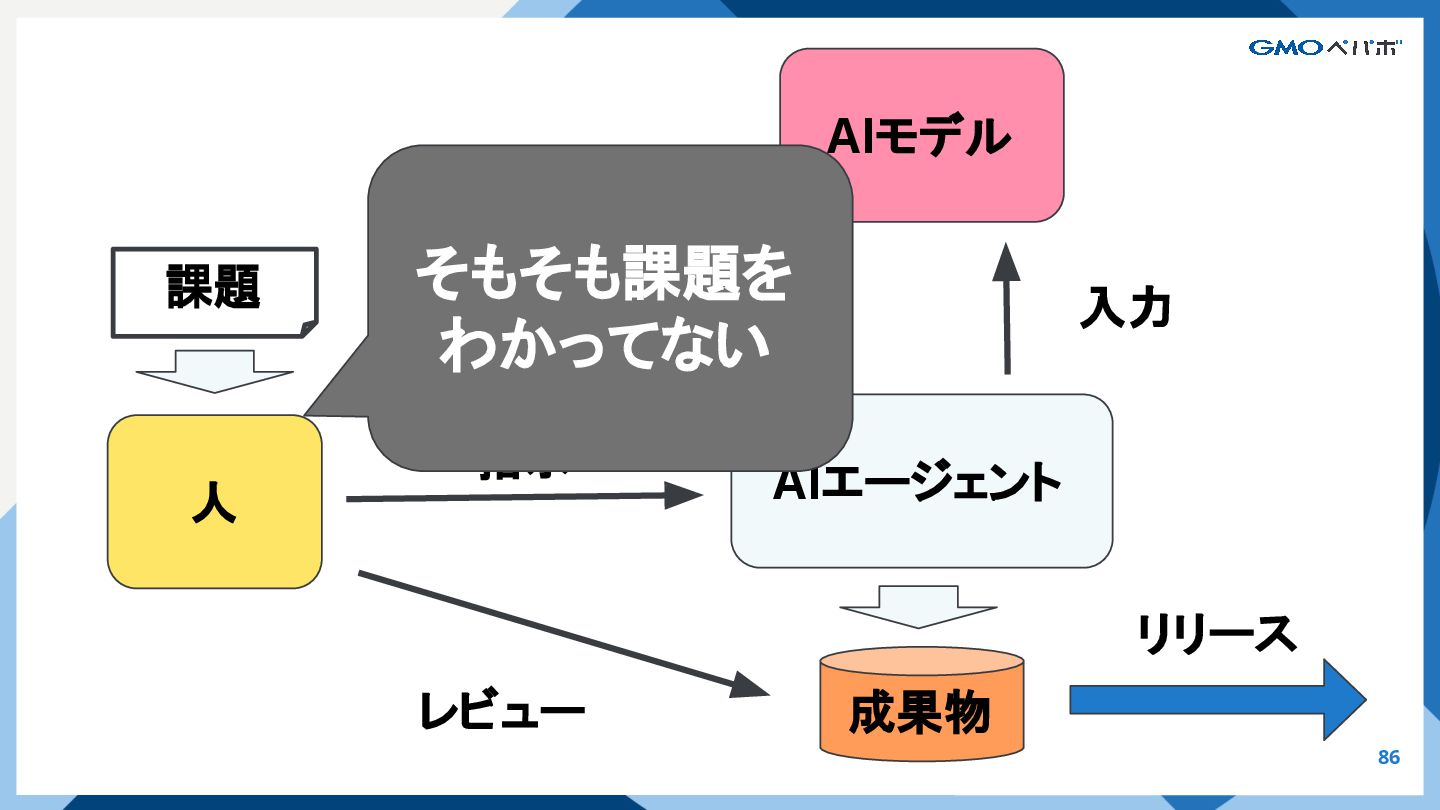{kind=link}
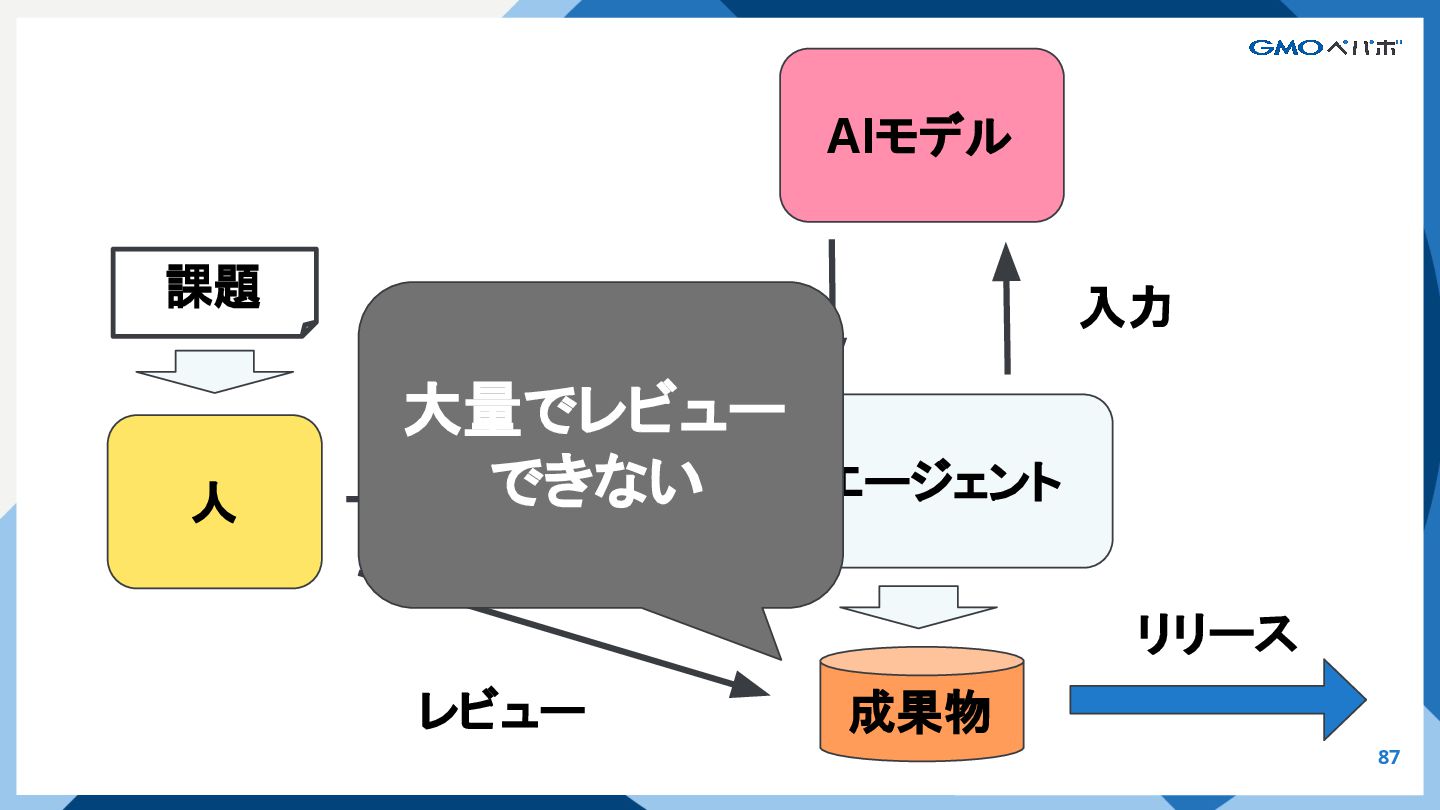{kind=link}
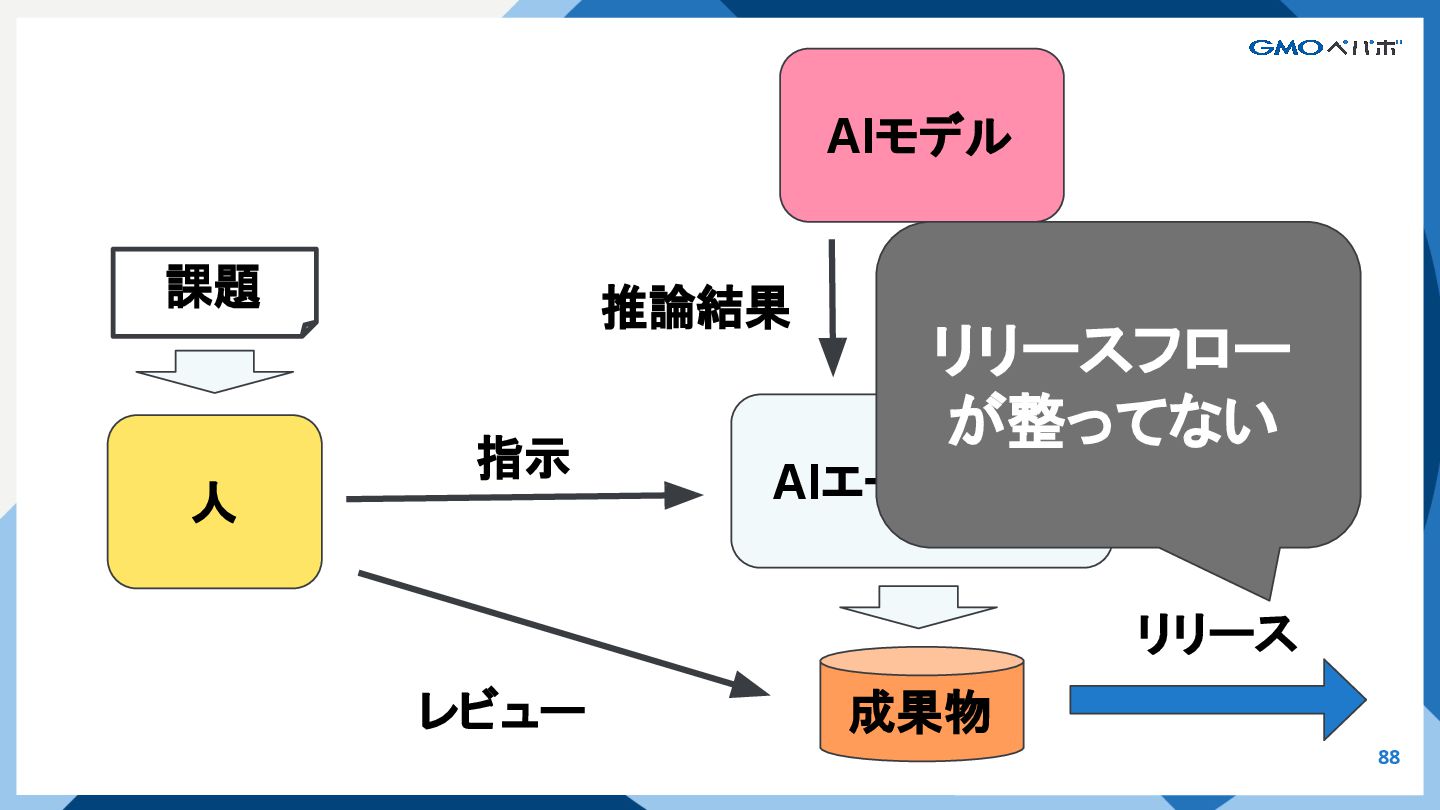{kind=link}
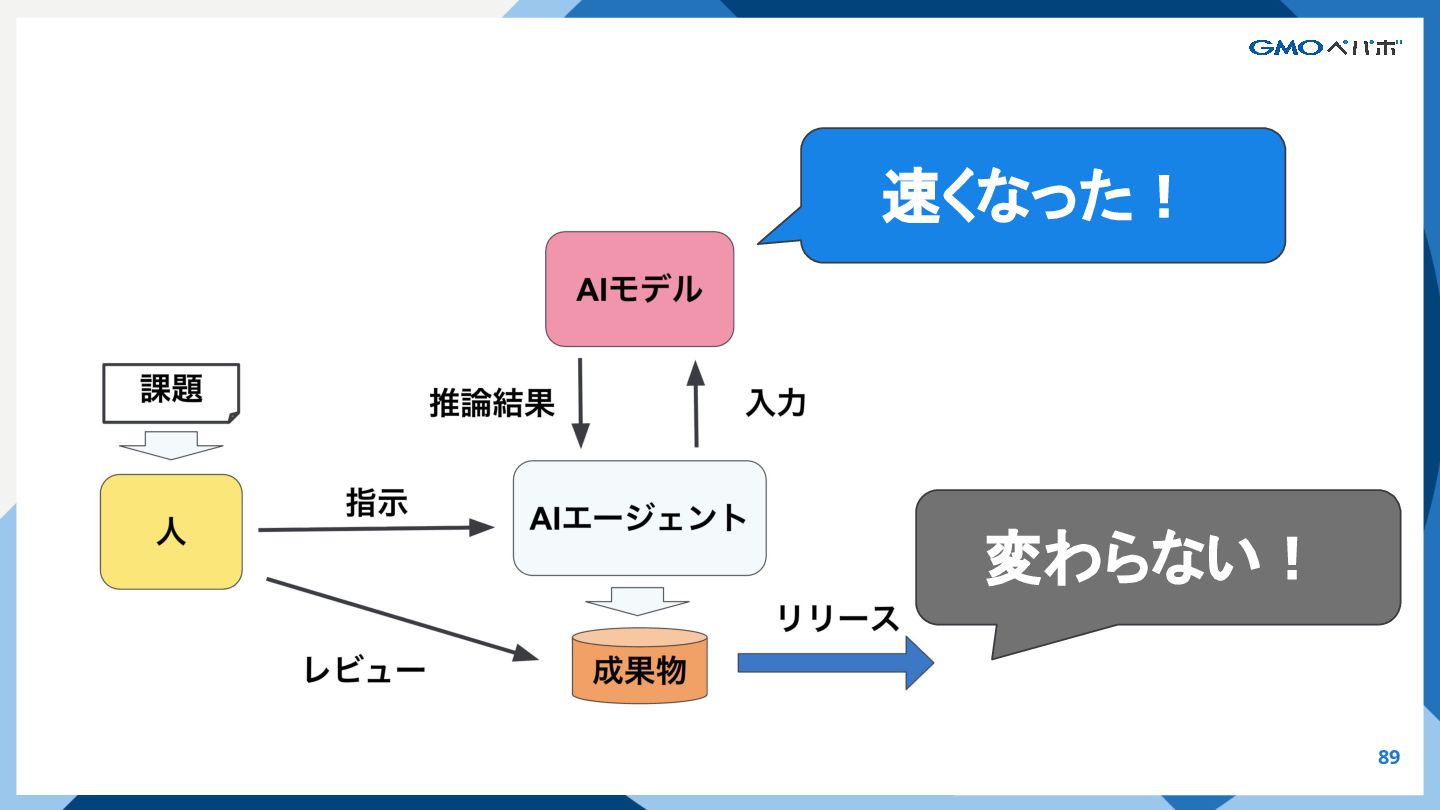{kind=link}
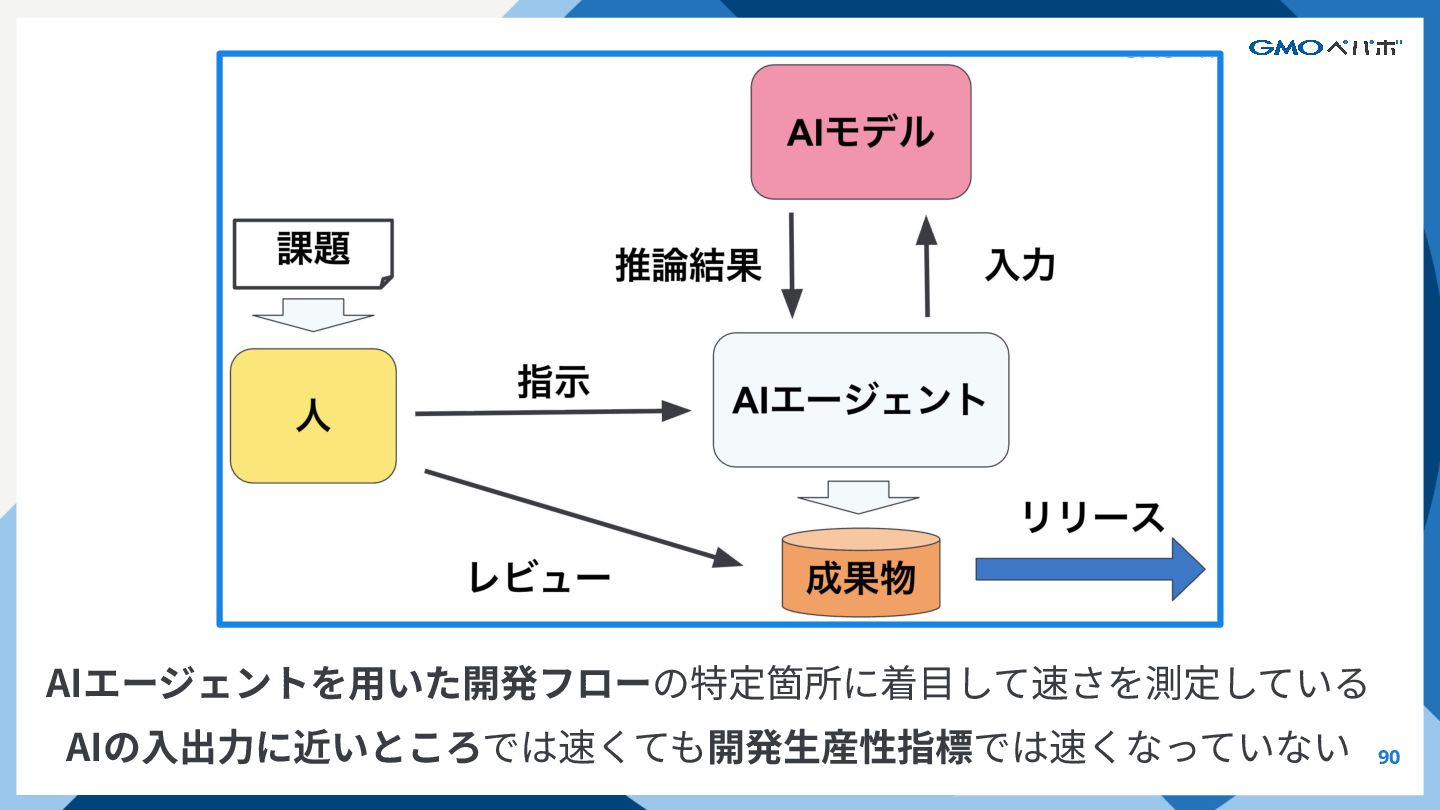{kind=link}
{kind=link}
{kind=link}
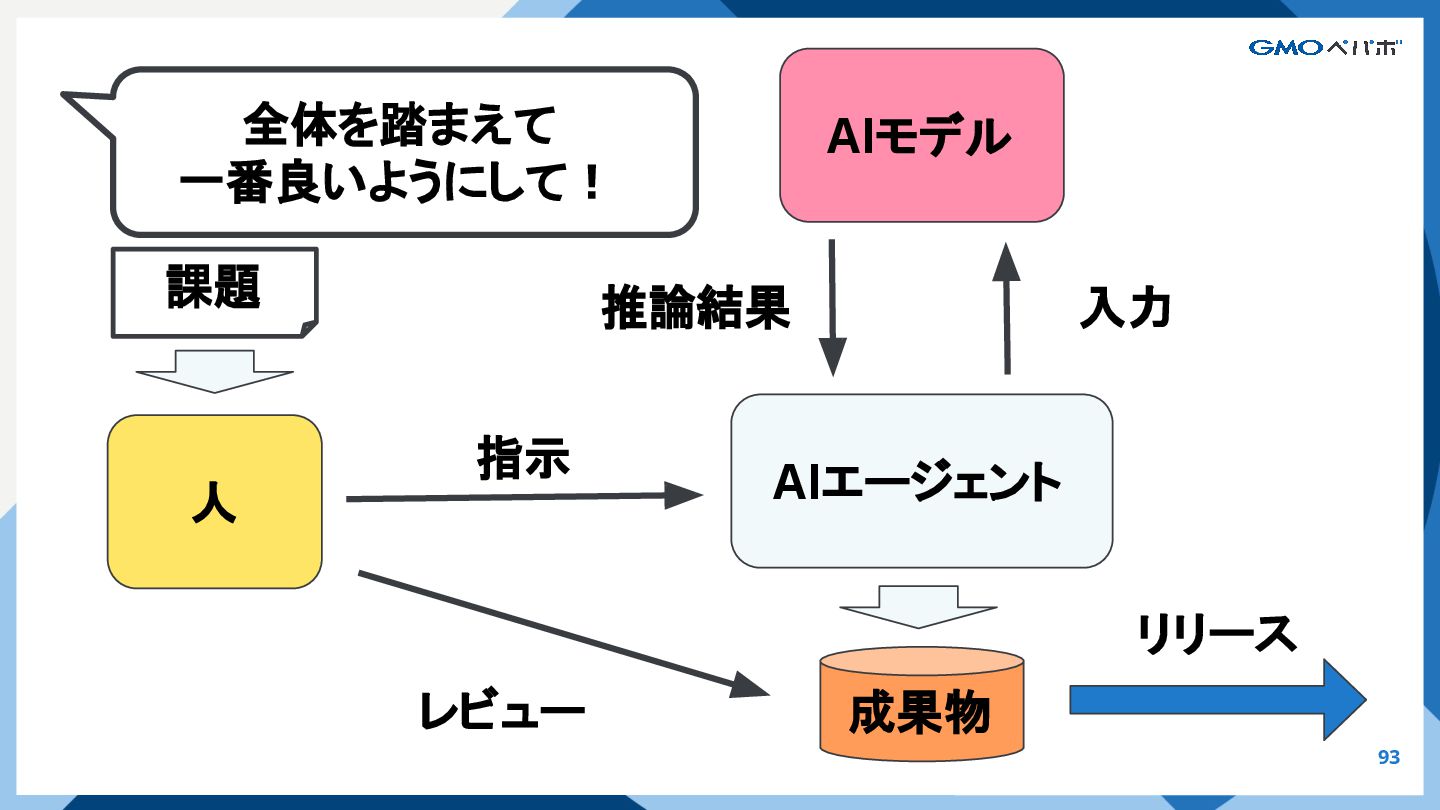{kind=link}
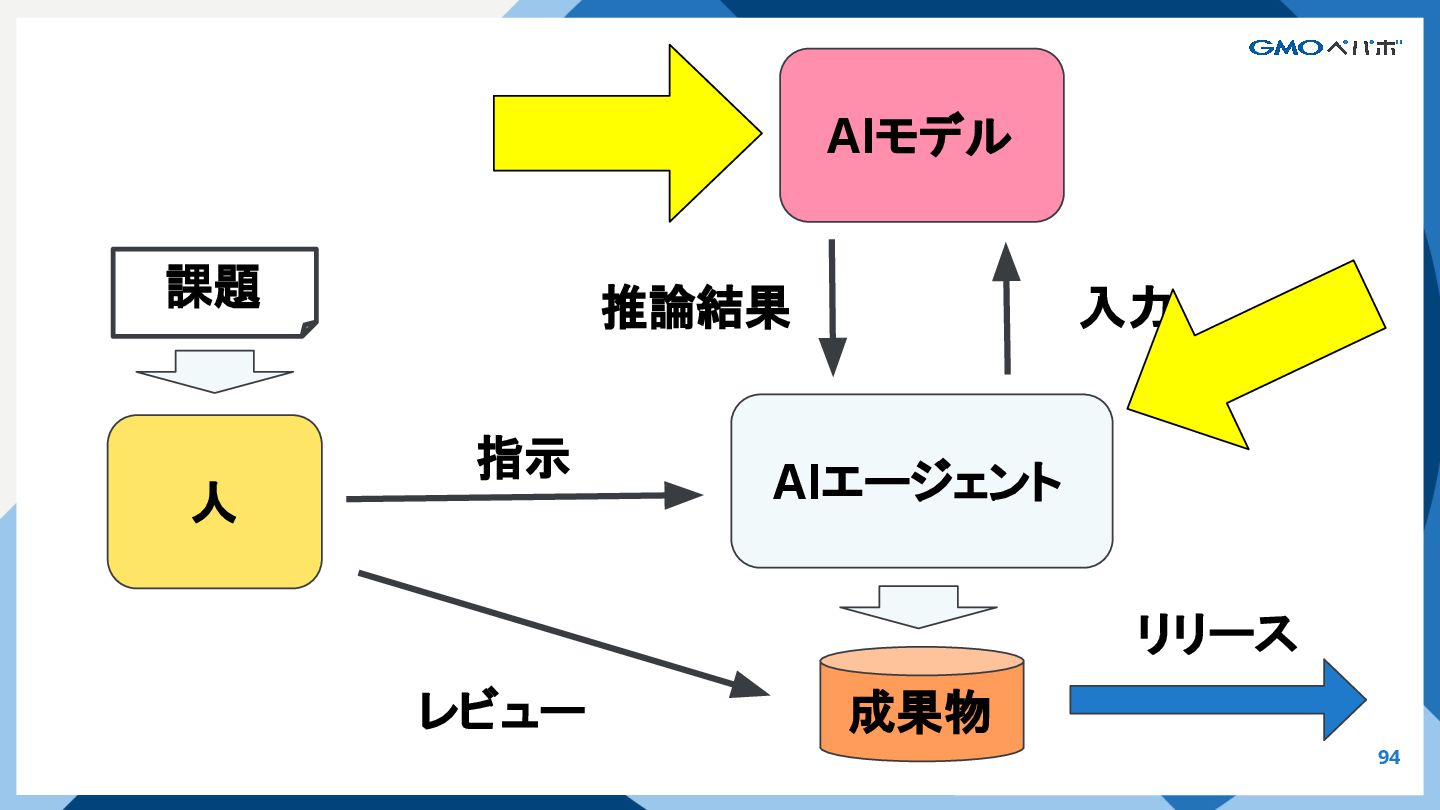{kind=link}
{kind=link}
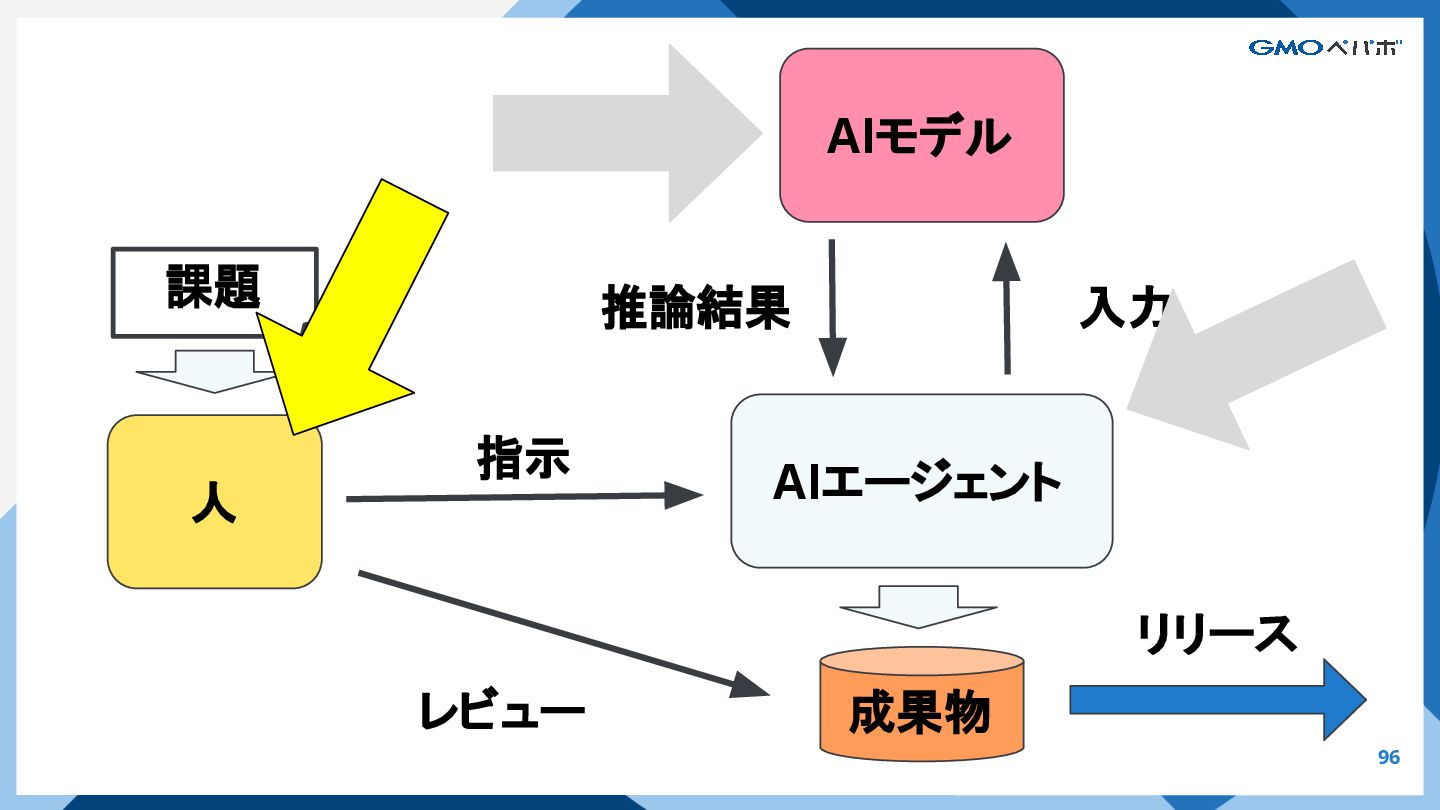{kind=link}
{kind=link}
{kind=link}
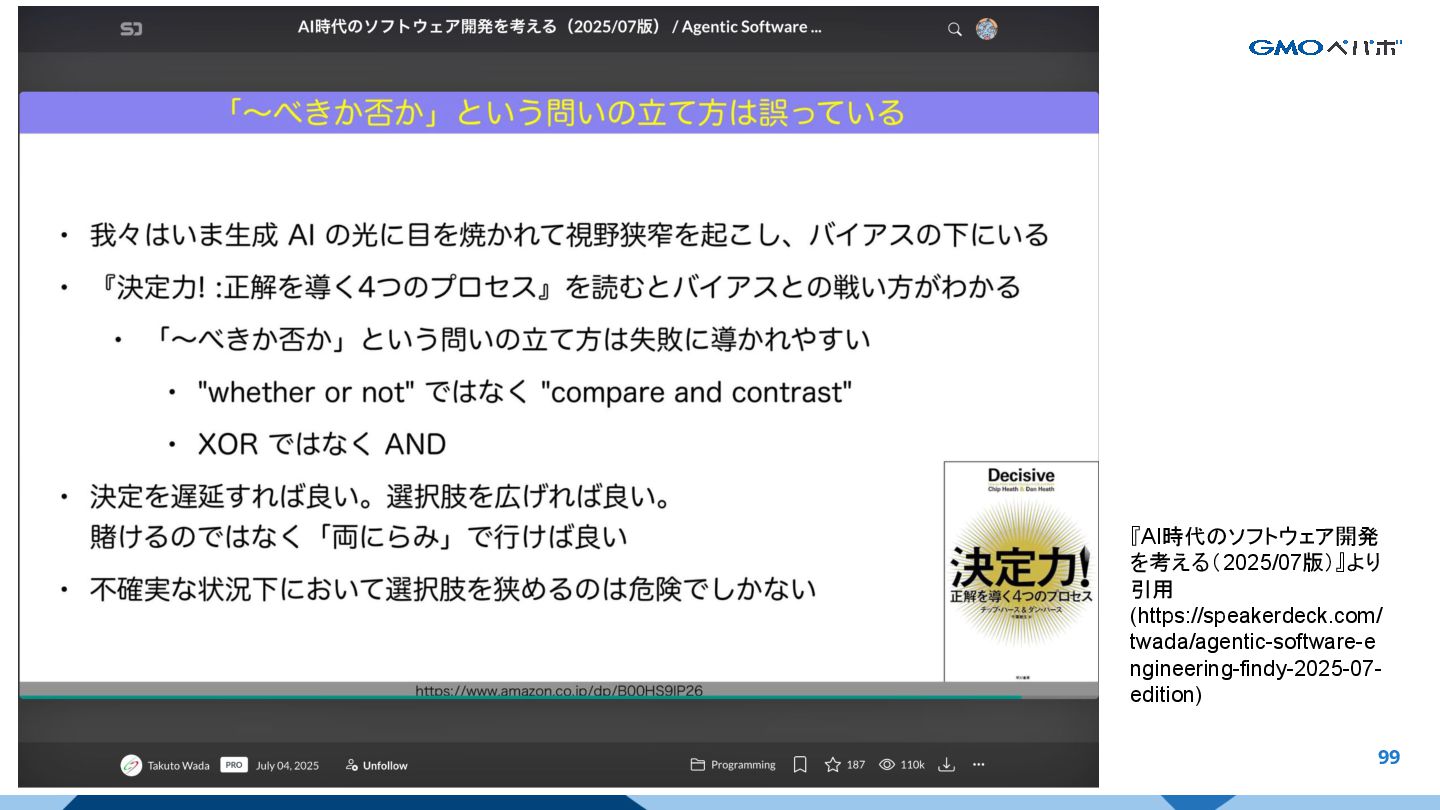{kind=link}
{kind=link}
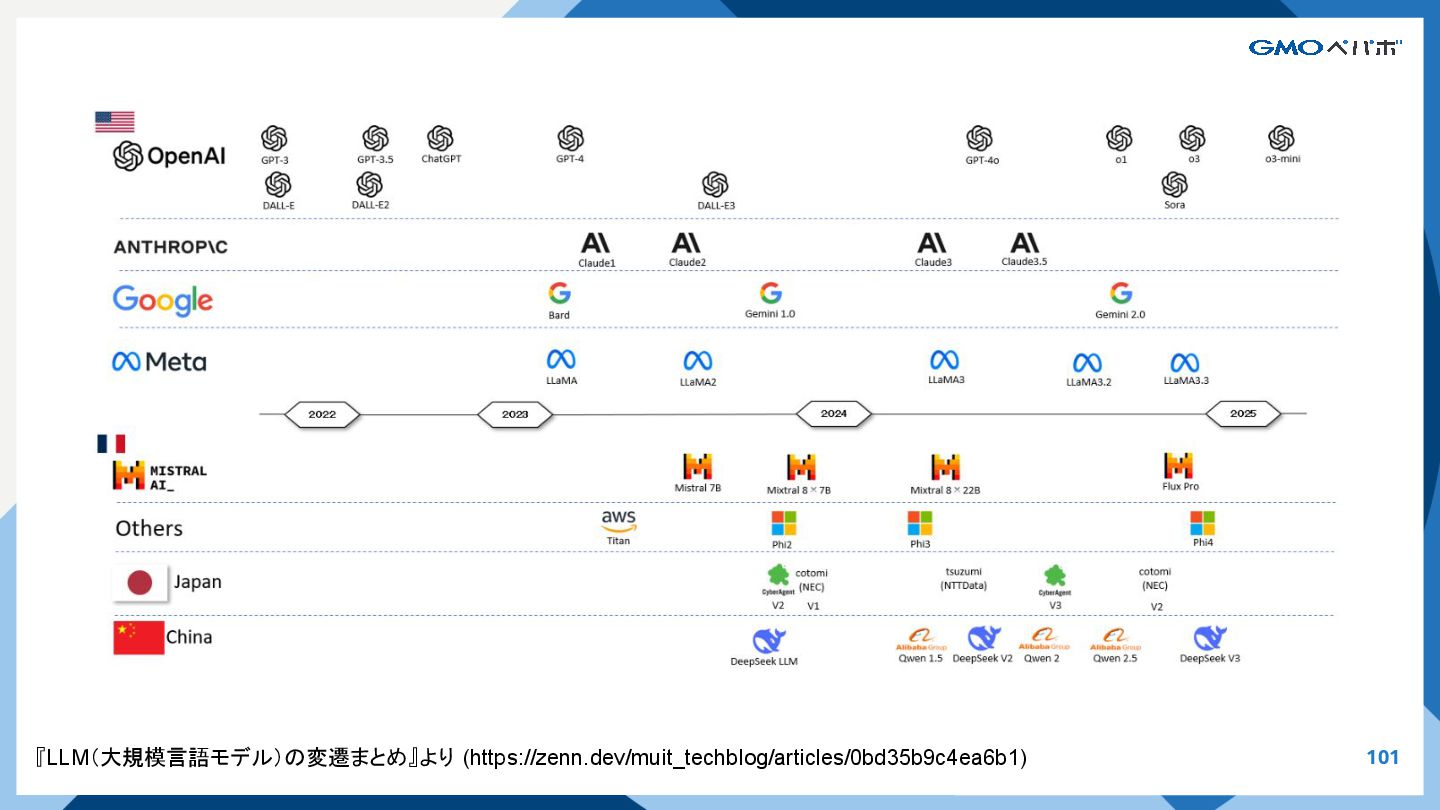{kind=link}
{kind=link}
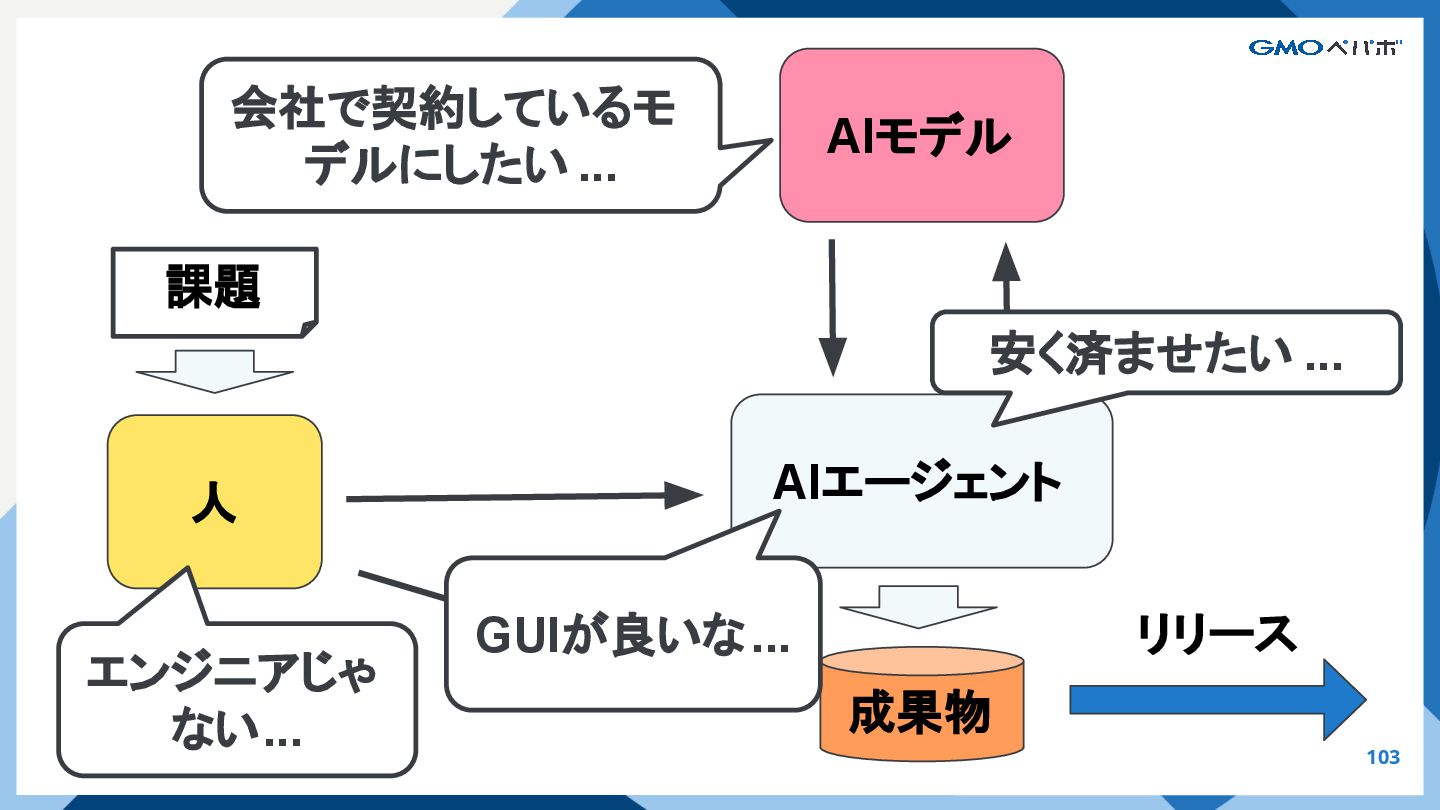{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}