Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
LLMローカル動作方法(NvidiaGPU使用)
Search
dassimen
March 23, 2025
0
81
LLMローカル動作方法(NvidiaGPU使用)
前回はCPUのみで動作させていたLLMをNvidiaのGPUを使用して動かしてみました。
PCのファンがうるさくなることなくLLMが動いていて感動しました。
dassimen
March 23, 2025
Tweet
Share
More Decks by dassimen
See All by dassimen
LLMとは(超概要)
dassimen001
0
33
RAGとは(超概要)
dassimen001
0
26
LangChain × Ollamaで学ぶLLM & RAG超入門
dassimen001
1
120
まるでChatGTP!?
dassimen001
0
32
🎭Playwright 超入門
dassimen001
0
43
LLMローカル動作方法
dassimen001
1
64
ベクトル変換について
dassimen001
1
47
Featured
See All Featured
Scaling GitHub
holman
459
140k
"I'm Feeling Lucky" - Building Great Search Experiences for Today's Users (#IAC19)
danielanewman
228
22k
Typedesign – Prime Four
hannesfritz
42
2.7k
Dealing with People You Can't Stand - Big Design 2015
cassininazir
367
26k
Fashionably flexible responsive web design (full day workshop)
malarkey
407
66k
Performance Is Good for Brains [We Love Speed 2024]
tammyeverts
10
910
Learning to Love Humans: Emotional Interface Design
aarron
273
40k
Building a Scalable Design System with Sketch
lauravandoore
462
33k
How to Ace a Technical Interview
jacobian
276
23k
[RailsConf 2023 Opening Keynote] The Magic of Rails
eileencodes
29
9.5k
A better future with KSS
kneath
239
17k
XXLCSS - How to scale CSS and keep your sanity
sugarenia
248
1.3M
Transcript
LLMローカル動作方法 超入門 (NvidiaGPU使用) 1
使用ツール WSL2 : Windows上でLinuxを手軽に動かす環境 Docker : コンテナ実行環境 Ollama : LLMをローカルで動かすツール(https://ollama.com)
NVIDIA Container Toolkit(Dockerで使用する) 2
Ollamaとは 大規模言語モデル(LLM)をローカル環境で簡単に実行・管理する ためのオープンソースツール コマンドの感覚的にはDockerに近いイメージを持った。 元OpenAIの人が作ったそう。世界中の協力の元プロジェクトが 大きくなっている。 動かせるLLMは、リポジトリのようなホストサイトがありそこから ダウンロードする Llamaやdeepseek-R1などが使える 3
動作検証方法 1. ローカルPCで動かす 2. ローカルだけで動いてるのか確認するためにネットワークを切断す る 前提 WSL2でUbuntuディストリビューションインストール済み Dockerを動かせる環境を構築済み 今回はGPUで動作確認する(CPUのみでの動作も可能)
4
Nvida Container Toolkitの設定1 1. Ubuntu(WSL2)環境にNvidaContainerToolKitをインストール 1. NvidiaのリポジトリをUbuntuに追加 aptでインストールできるようにする 2. 以下コマンドでツールのインストール
$ sudo apt-get install -y nvidia-container-toolkit インストール詳細は以下を参照(NVIDIA公式Doc) https://docs.nvidia.com/datacenter/cloud-native/container- toolkit/latest/install-guide.html#installation “ “ 5
Nvida Container Toolkitの設定2 2. Dockerの設定をする 1. Nvidiaのツールキットを使用するように設定ファイルを更新 $ sudo nvidia-ctk
runtime configure --runtime=docker 2. Dockerの再起動 Docker Desktop for Windowsの場合はGUIから再起動する GPUをDockerで使用する詳細は以下を参照(Docker公式Doc) https://docs.docker.com/desktop/features/gpu/ “ “ 6
実行 1. まずOllamaコンテナを立ち上げる(モデルを実行するツール) $ docker run -d --gpus=all -v ollama:/root/.ollama
-p 11434:11434 --name ollama ollama/ollama 2. 好きなモデルを以下から選び実行する 今回は Llama3.2の1bパラメータ の物を選んだ。 比較的容量が1.1GBと少なめ。 DeepSeek-R1も使ったが今回は省略する。 $ docker exec -it ollama ollama run llama3.2:1b 7
実行結果 >>> 日本語で対応してください。 我々は、以下のような方法でオプションをご提供しています。 1.質問を簡単な言葉で説明する 2.長い文書の部分についての詳細な説明 3.特定の問題に答えを調べるためのシナリオを提示します。 4.関連する情報と関連している情報をご紹介します。 5.複雑な概念を簡単に理解できるように、分解したリストを提供します。 >>>
日本の首都はどこですか。 日本の首都は東京です。 Tokyo (, Tokyō) は、日本の人口の約半分の市民が住んでいる都市で、東京 metropolitan area の中心部である。 >>> が自分で入力した文章。その下がLLMの回答。 サイズが小さなモデルなので日本語での精度は少し落ちる。 精度を上げる場合は、容量の大きなモデルを使用するとよい。 ネットワークを切った状態でも問題なく動作した。 8
わかったことと今後 ローカルで手軽にLLMが動作させられることが分かった。 Docker環境でGPU連携は、簡単。 LangChainを試している最中なのでそれと連携したい。 AIを使う敷居がかなり下がっているのを感じた。 Ollamaリポジトリを見ると画面も簡単につけられそうなので試した い。 9
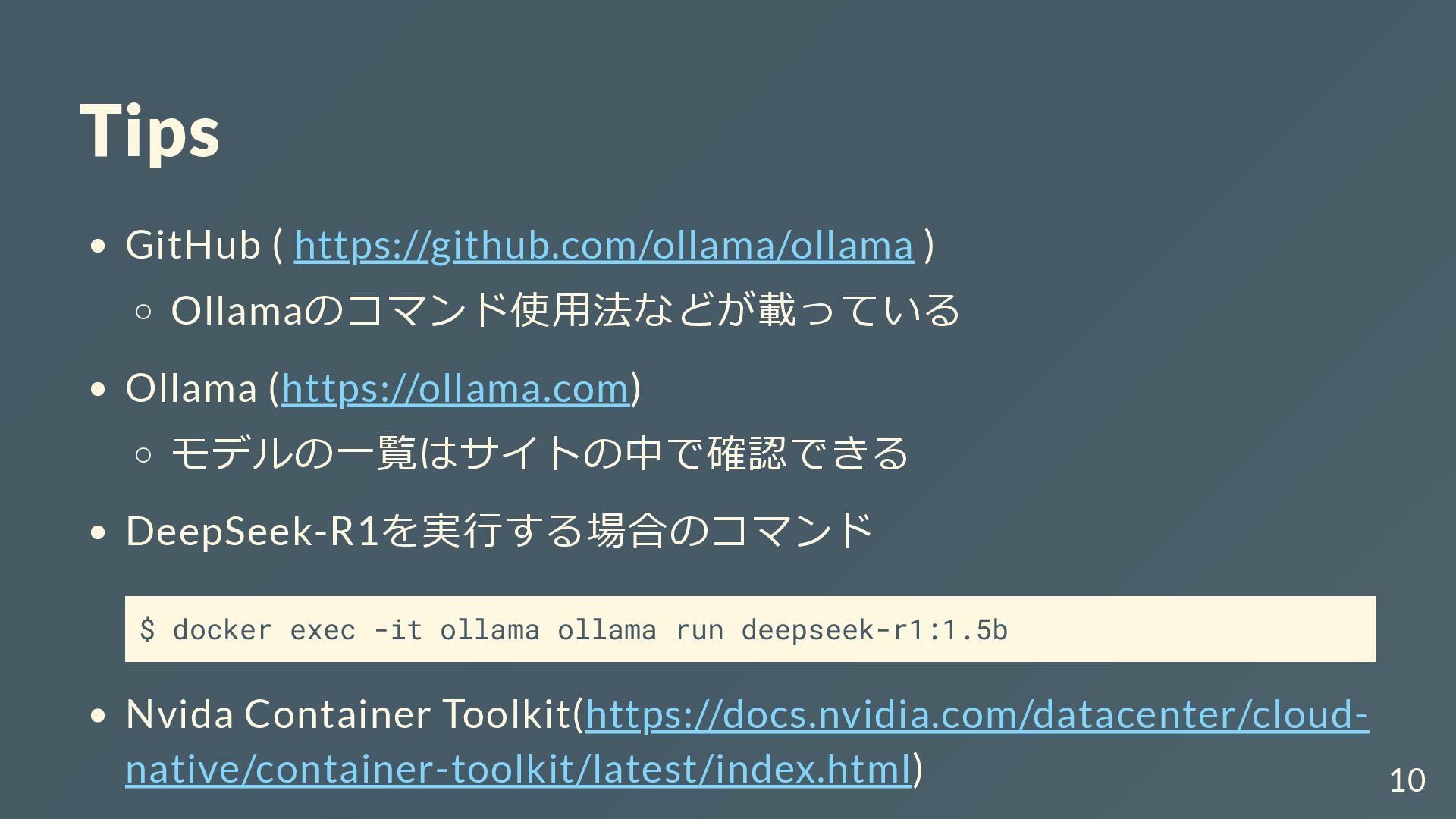
Tips GitHub ( https://github.com/ollama/ollama ) Ollamaのコマンド使用法などが載っている Ollama (https://ollama.com) モデルの一覧はサイトの中で確認できる DeepSeek-R1を実行する場合のコマンド
$ docker exec -it ollama ollama run deepseek-r1:1.5b Nvida Container Toolkit(https://docs.nvidia.com/datacenter/cloud- native/container-toolkit/latest/index.html) 10
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}