expressão regular (mas é aceito por quase todas bibliotecas regex) É difícil de entender É fácil de errar É extremamente compacta Na verdade, checa se número não é primo
SNOBOL implementou pattern matching, mas não expressões regulares Ken Thompson introduzir expressões regulares no editor QED, depois ed (Unix), e finalmente grep (abreviação do comando g/re/p do ed) Padronizado pelo POSIX Repadronizado pelo Perl e Tcl (baseado em biblioteca de Henry Spencer) Biblioteca PCRE (Philip Hazel)
ocorre em um texto Verificar se um determinado padrão não ocorre em um texto Localizar as ocorrências de um padrão Obter as ocorrências de um padrão Obter partes das ocorrências de um padrão Substituir ocorrências de um padrão por outro texto, possivelmente usando partes da ocorrência Dividir texto de acordo com um padrão
]" php.ini Acha linhas que não estejam em branco: grep –v "^$" .profile Índice de todas palavras em um texto: [w.start() for w in re.finditer(r'\b\w', text)] Todas palavras de um texto: @words = $text =~ /\w+/ Dia, mês e ano de uma data: ($d, $m, $a) = text =~ /(\d\d)/(\d\d)/(\d{4})/ Remove espaços do fim da linha: sed -p'' -e 's/ *$//‘ Divide linha em palavras e símbolos text split """\b\s*|\s*\b"""
de Gramáticas Regulares Mesmas linguagens aceitas por Autômatos Finitos Determinísticos Livres de Contexto Exemplo de linguagem não regular: Número de b depende do número de a: anbn
int state = 0; while(ch = getc()) { switch(state) { case 0: switch(ch) { case '\n': state = 1; break; default : break; } case 1: switch(ch) { case '\n': break; default : state = 0; break; } } } return state == 1;
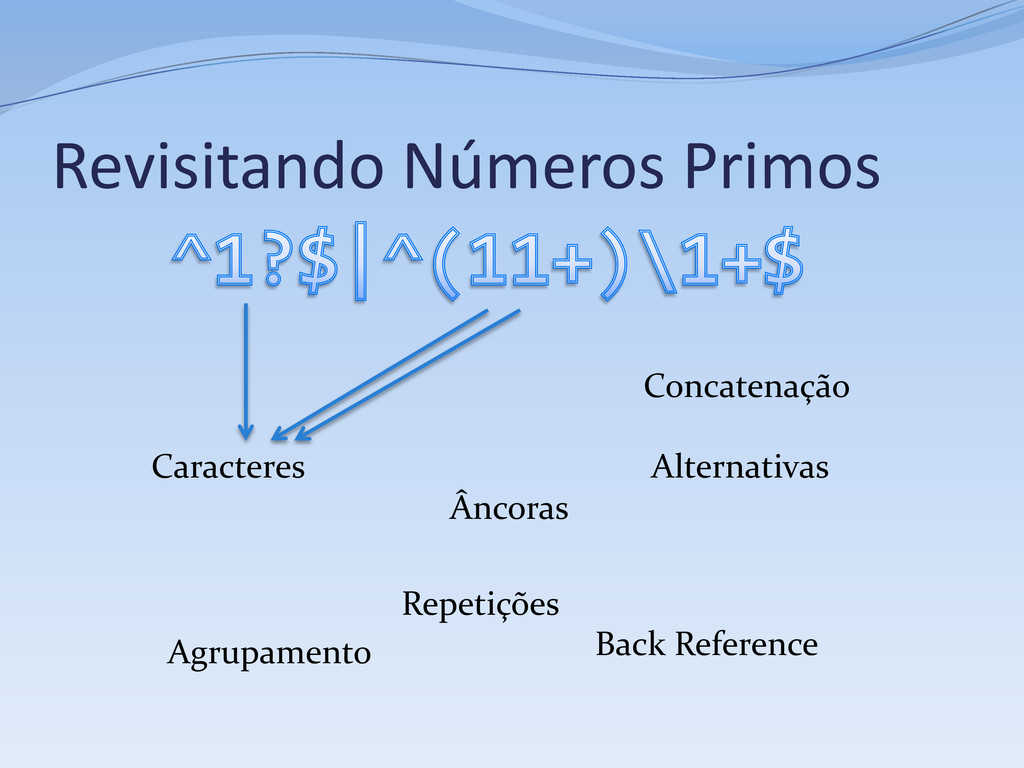
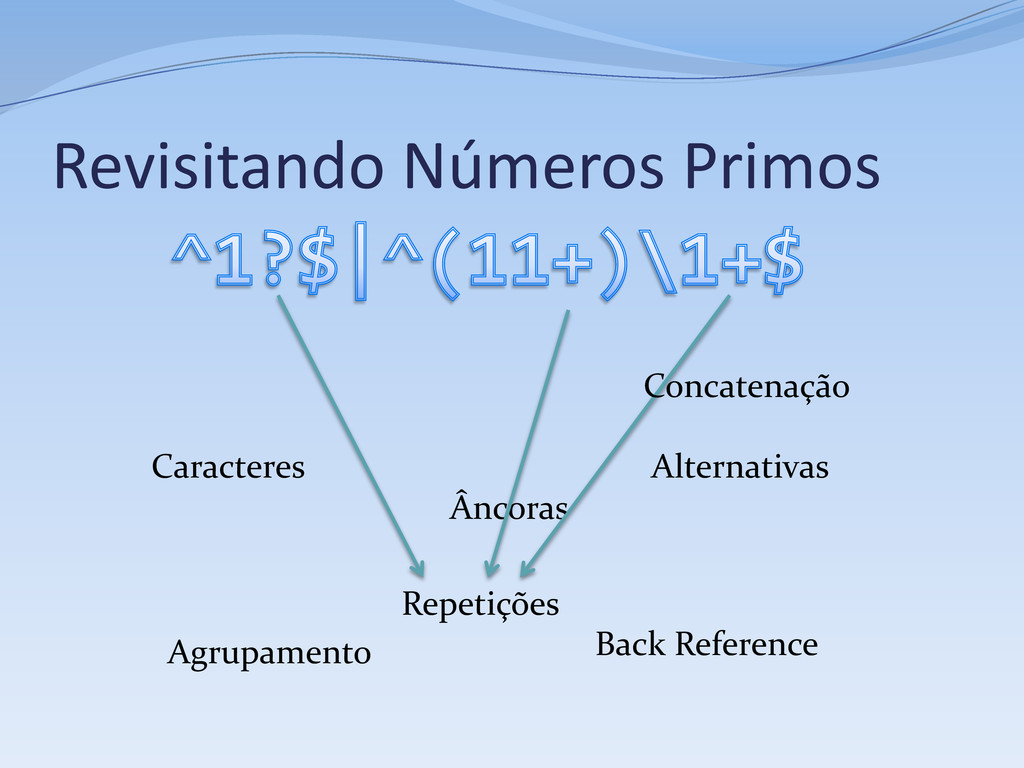
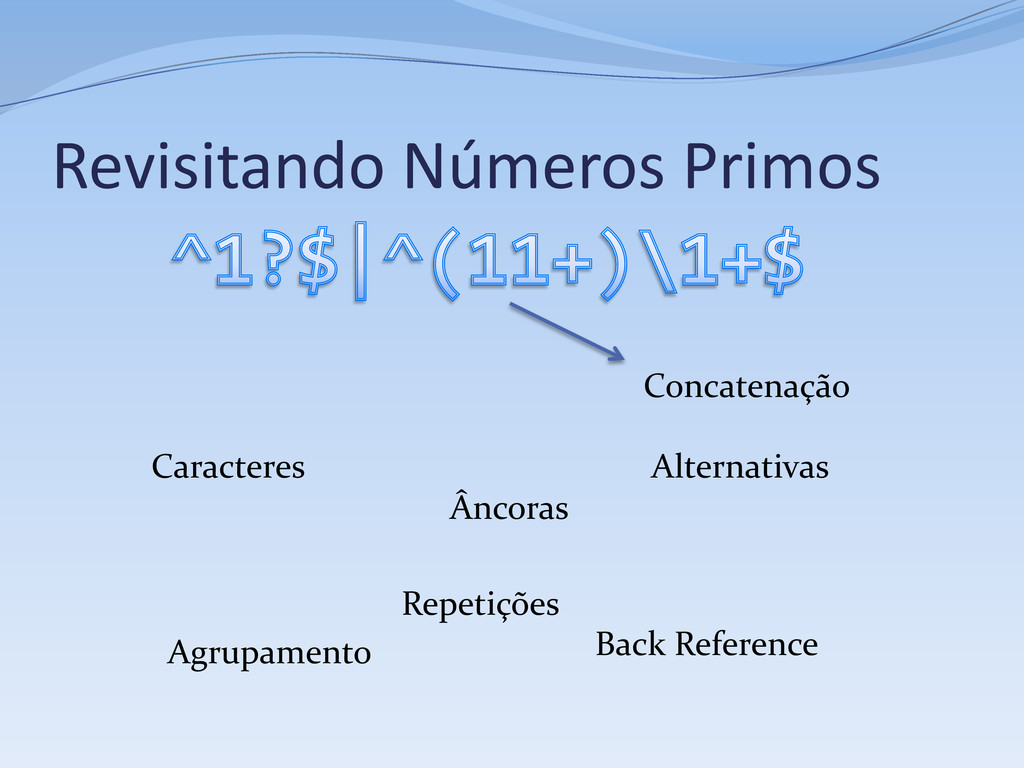
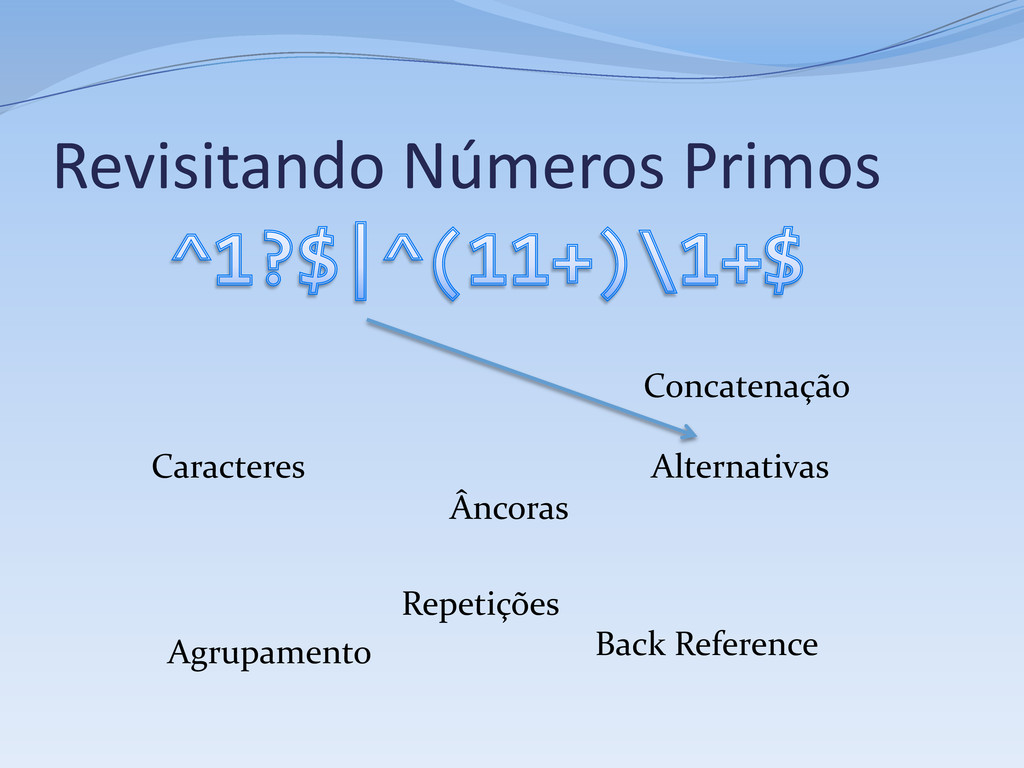
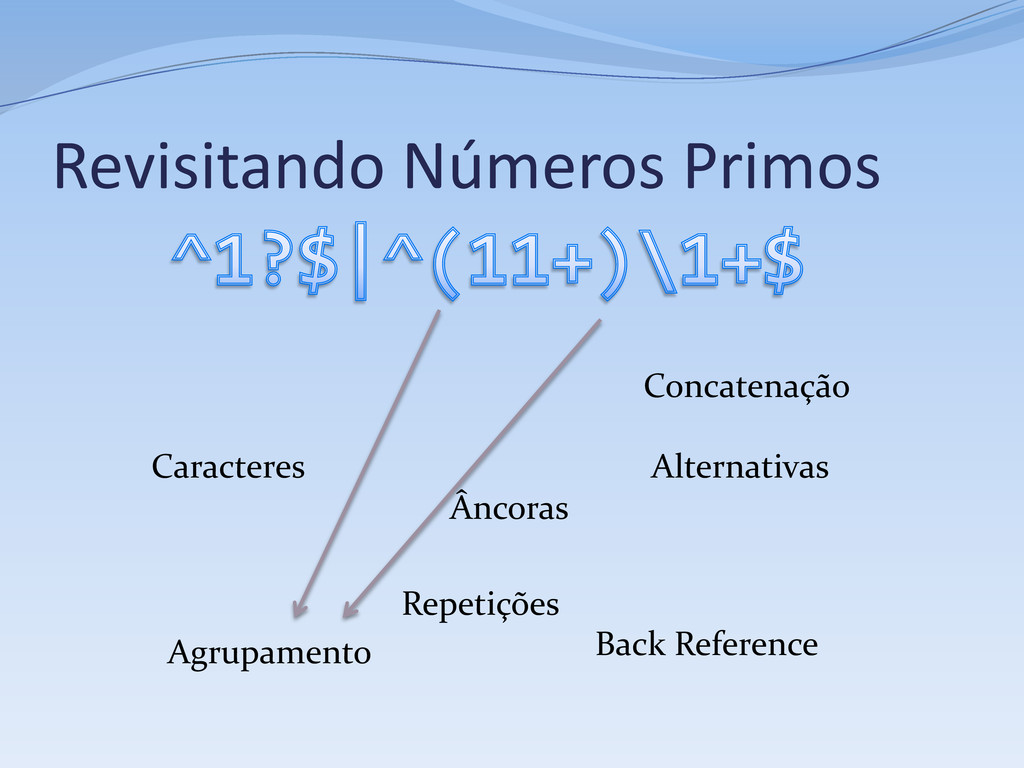
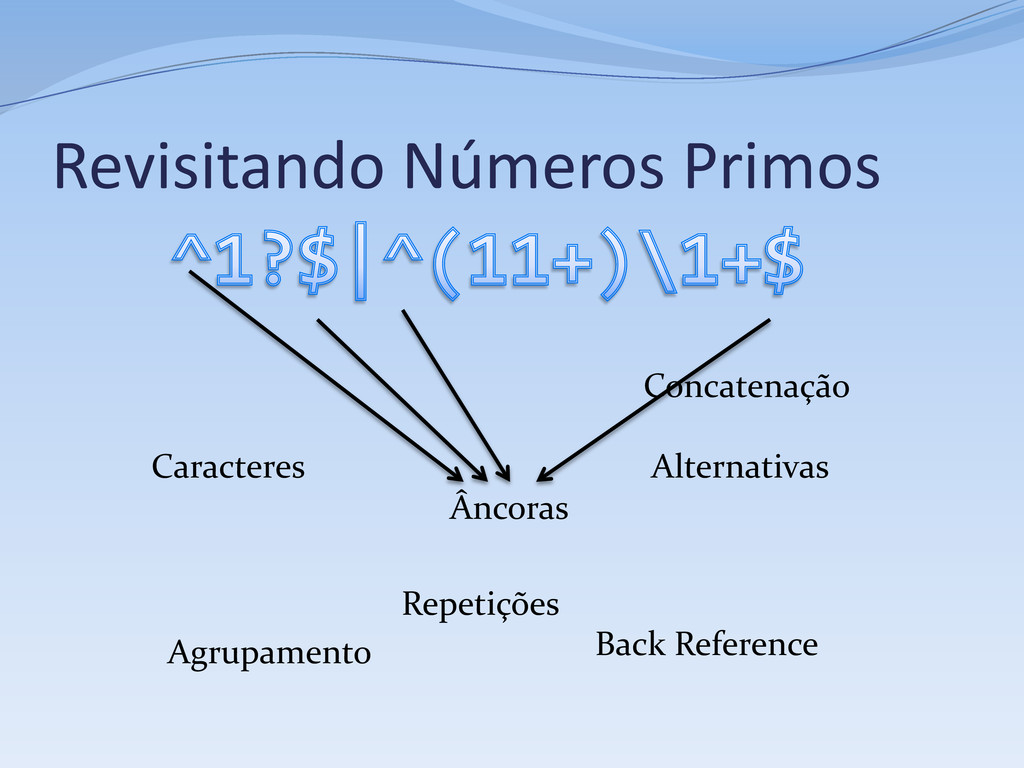
Repetição (kleene star): r* Concatenação: r1 r2 Alternativa: r1 | r2 Todas expressões regulares podem ser compostas a partir desses elementos Muitas regex não podem ser compostas só com esses elementos
string representando o regex em uma estrutura de dados otimizada para seu uso Disponível com Java, Perl, Python, Ruby Regex Just In Time recompilam a expressão todas as vezes, para diminuir a cerimônia de seu uso Disponível com Java(*), Perl, PHP, Python, Ruby (*) Somente para alguns usos
um de um conjunto: [r1 r2 -r3 ] Qualquer um não em um conjunto: [^r1 r2 ] Classes de caracteres: [[:alpha:]], \w, Negação de classes: [^[:alpha:]], \W Classes POSIX: \p{Upper}, \P{InGreek} Zero ou um: r? Um ou mais: r+ Entre n e m repetições: r{n, m}
quantidade possível de caracteres que satisfaçam a expressão Elas são greedy – gananciosas Algumas bibliotecas suportam relutância: r*? e r+? Elas retornam a menor quantidade possível de caracteres que satisfaçam a expressão Em alguns casos, a performance das repetições relutantes é muito superior
Todo o resto: ( e ) Grupos também capturam o conteúdo, e podem ser extraídos separadamente ou usados na substituição Sem captura(*): (?:r) (*) as partes de uma ocorrência correspondentes a expressões dentro de parênteses são retornadas como grupos ou subgrupos
contexto Mas esses “contextos” são válidos, pois podem ser representados como estados Âncoras: Início do texto ou de uma linha: ^ Fim do texto ou de uma linha: $ Borda de palavras: \b ou \< e \> (POSIX BRE) Look-ahead: (?=r) Look-behind: (?<=r) Negações: (?!r) e (?<!r)
para o subgrupo: (?idmsux-idmsux:r) Flags: Case insensitive: i Unix new lines: d Multiline: m “.” pega new lines: s Unicode-aware: u Comentários: x
cita o símbolo \ antes de letras tem tem significado especial POSIX Basic RE: uma zona – consulte o manual Citando um grupo de caracters: \Qgrupo de caracteres\E
1, aceita se o # tamanho da sequência não for um número primo # Primeiro caso, números menores que 2 ^ # Início da string 1? # 0 ou 1 ocorrênicas do dígito 1 $ # Fim da String | # Segundo caso, números maiores ou igual a 2 # Verifica se a string pode ser reduzida a # XX...X, onde X é uma string de tamanho fixo # com dois ou mais dígitos 1 ^ # Início da string ( # Início do primeiro subgrupo -- o “X” da questão 11+? # Sequência de dois ou mais dígitos 1 # A sequência acima é relutante por questões de performance ) # Fim da sequência \1+ # Uma ou mais (novas) ocorrências do subgrupo 1 $ # Fim da string
vezes podem ser resolvidas com regex Coisas que são regex as vezes não valem a pena serem resolvidas com regex Algumas coisas não são regex e não são resolvidas com regex Resolver com código expressões regulares simples é muito mais complicado do que as pessoas assumem Não usem regex com xml!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Autômatos Finitos Determinísticos 0 1 \n [^\n] \n [^\n] Texto](https://files.speakerdeck.com/presentations/4fe92b53adfdc0001f01f0e2/slide_12.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Classes úteis [:alnum:] \w – inclui sublinhado (não](https://files.speakerdeck.com/presentations/4fe92b53adfdc0001f01f0e2/slide_19.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![E-mail regex (?:[a-z0-9!#$%&'*+/=?^_`{|}~-]+(?:\.[a-z0- 9!#$%&'*+/=?^_`{|}~-]+)*|"(?:[\x01-\x08\x0b\x0c\x0e- \x1f\x21\x23-\x5b\x5d-\x7f]|\\[\x01-\x09\x0b\x0c\x0e- \x7f])*")@(?:(?:[a-z0-9](?:[a-z0-9-]*[a-z0-9])?\.)+[a- z0-9](?:[a-z0-9-]*[a-z0-9])?|\[(?:(?:25[0-5]|2[0-4][0- 9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0- 9]|[01]?[0-9][0-9]?|[a-z0-9-]*[a-z0-9]:(?:[\x01- \x08\x0b\x0c\x0e-\x1f\x21-\x5a\x53-\x7f]|\\[\x01-](https://files.speakerdeck.com/presentations/4fe92b53adfdc0001f01f0e2/slide_36.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}