Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
クラシルで実践しているフルサイクルとデータ分析でのAI活用事例 / AI Engineerin...
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
クラシル株式会社
December 16, 2025
2.1k
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
クラシルで実践しているフルサイクルとデータ分析でのAI活用事例 / AI Engineering Summit Tokyo 2025 (Kurashiru)
AI Engineering Summit Tokyo2025で発表しました、クラシル株式会社の登壇資料です。
クラシル株式会社
December 16, 2025
More Decks by クラシル株式会社
See All by クラシル株式会社
クラシル株式会社 紹介資料
delyinc
2
5.3k
クラシル株式会社 会社紹介資料
delyinc
14
490k
エンジニア向け クラシル会社説明資料 / For Engineers
delyinc
2
22k
新卒エンジニア向け クラシル会社説明資料 / New Grad Engineers
delyinc
0
5k
Kurashiru Brand Guideline
delyinc
3
9.6k
dely株式会社リテール事業概要説明資料 / Retail Business
delyinc
0
3.4k
dely Culture deck
delyinc
0
3.7k
Featured
See All Featured
The Psychology of Web Performance [Beyond Tellerrand 2023]
tammyeverts
49
3.5k
The Invisible Side of Design
smashingmag
301
52k
State of Search Keynote: SEO is Dead Long Live SEO
ryanjones
0
220
Done Done
chrislema
186
16k
jQuery: Nuts, Bolts and Bling
dougneiner
66
8.5k
Hiding What from Whom? A Critical Review of the History of Programming languages for Music
tomoyanonymous
3
920
How People are Using Generative and Agentic AI to Supercharge Their Products, Projects, Services and Value Streams Today
helenjbeal
1
230
Beyond borders and beyond the search box: How to win the global "messy middle" with AI-driven SEO
davidcarrasco
3
180
brightonSEO & MeasureFest 2025 - Christian Goodrich - Winning strategies for Black Friday CRO & PPC
cargoodrich
3
750
The #1 spot is gone: here's how to win anyway
tamaranovitovic
3
1.1k
Paper Plane (Part 1)
katiecoart
PRO
0
9.6k
Designing for Performance
lara
611
70k
Transcript
フルサイクルエンジニアリングにおけ るAI活用 hama(@dev_hamabata) / クラシル株式会社
自己紹介 hama (@dev_hamabata) クラシル株式会社 バックエンドエンジニア 担当業務 ・ クラシルリテールネットワークにおける開発 ・ 現在は特に運用改善業務に従事
技術スタック ・ Ruby on Rails / Aurora MySQL / OpenAPI
本日のアジェンダ 1. フルサイクルエンジニアリングとは? 2. PRC(Product Readiness Check)とは? 3. PRCにおけるAI活用 4.
監視対応の難しさについて 5. 例外対応をAIで楽にする 6. AWSの運用監視をAIで楽にする 7. 最後に(まとめ)
本日お話しすること クラシル社で取り組んでいるフルサイクルエンジニアリング運用の中でどのようにAIを活用 するか説明します!
フルサイクル エンジニアリングとは?
フルサイクルエンジニアリングとは? システムの設計・開発・運用・保守・改善までの全フェーズを、開発者やチームが一 貫して担当する開発手法 ・ フルスタックエンジニアはフロント、バックエンド、インフラといった技術領域を広く こなせるエンジニアを指すが、フルサイクルエンジニアは ソフトウェアライフサイクル プロセス の全領域を担当する ・
名前は似ているが、フルサイクルとフルスタックは異なるものなので注意
フルサイクルエンジニアリングとは? ・ ソフトウェア開発のライフサイクルプロセス ・ 設計 ・ 開発 ・ テスト ・
デプロイ ・ 運用・保守 ・ サポート
フルサイクルエンジニアリング実施前の弊社の課題 ・ 運用・保守が微妙 ・ 弊社では新たな大機能やサービス、基盤の立ち上げ時に少人数のスクラムチームを立て て開発を行う ・ 価値提供を迅速に行うために体制変更が激しかったりする ・ 基盤が完成した後はスクラムチームを解散して別スクラムに移動するなど
・ その基盤や機能を運用・保守するエンジニアがいなくなる ・ 障害やアラートの検知時に誰が初動対応する? ・ パフォーマンス低下したとき誰がチューニングする? -> スクラムチームと別軸でフルサイクルチームを発足
フルサイクル運用チームの構築 ・ 各サービスや基盤に対して、スクラムチームとは別の運用チームを構築 ・ チーム内では、以下のような取り組みを行う ・ メトリクスの監視 ・ コストアラートの確認 ・
例外検知時の初動対応やエスカレーション ・ PRC(Production Readiness Check)の実施 ・ 週1回の定例で報告・共有 ・ 評価制度に組み込まれており、Tierごとに責務を設計 ・ 昇格してTierが上がるとインフラ設定権限が与えられるなど裁量が増える
PRC (Product Readiness Check)
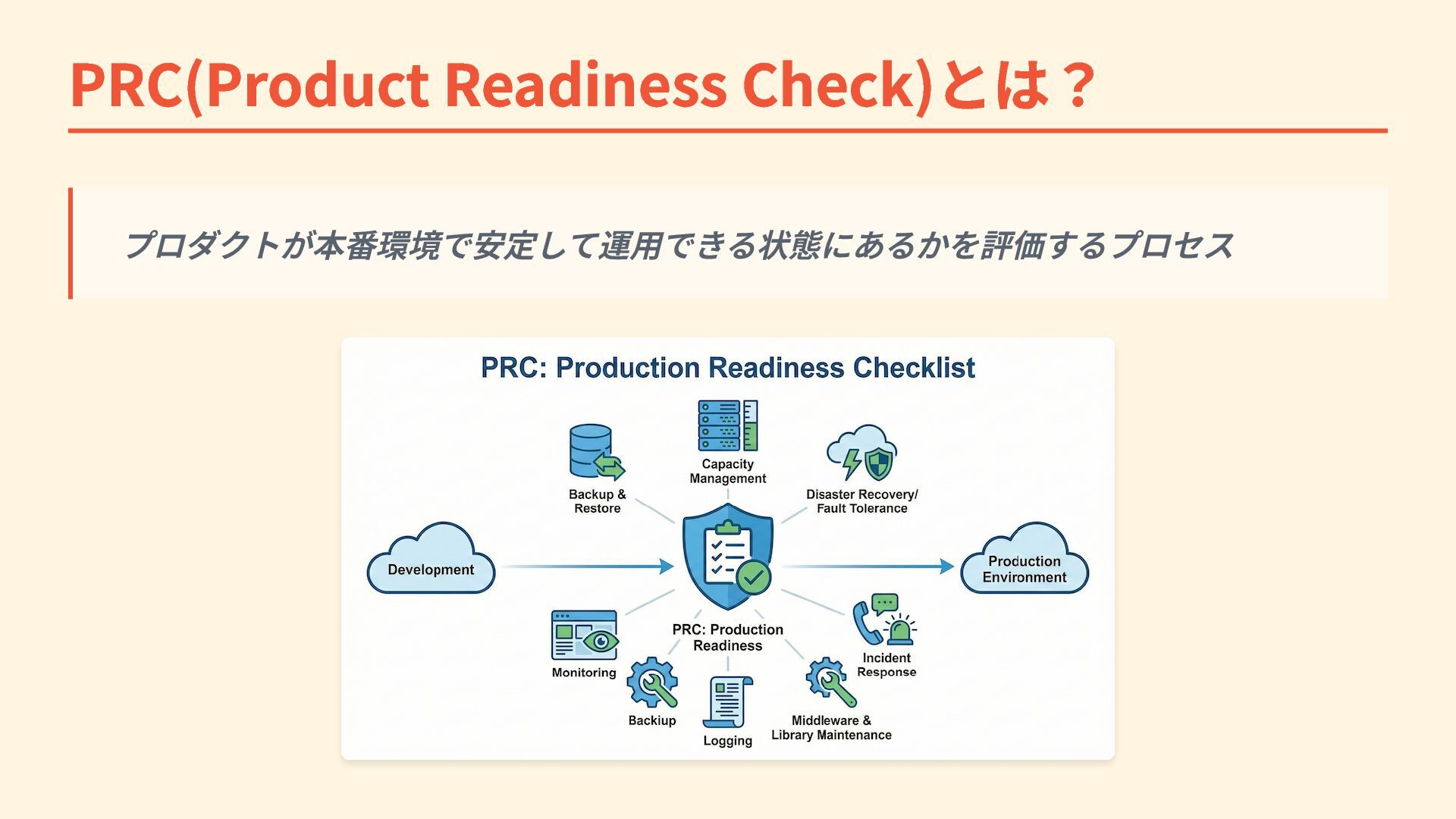
PRC(Product Readiness Check)とは? プロダクトが本番環境で安定して運用できる状態にあるかを評価するプロセス
PRC(Product Readiness Check)とは? ・ 弊社では次のような観点で評価軸を設けている(抜粋) ・ バックアップ・リストア ・ キャパシティ管理 ・
障害対策 ・ インシデント対応 ・ ログ記録 ・ ミドルウェア・ライブラリのメンテナンス方針 ・ 監視 ・ :
PRC(Product Readiness Check)とは? 各評価項目は例えばこんな感じ PRCの各項目を埋めることがそのままシステム理解に繋がっている
PRCにおけるAI活用 ・ クラシル社のAWSインフラはTerraformでコード管理されている ・ そのため、PRCで確認する項目についてはある程度コードから読み解くことができる ・ バックアップ・リストア対象は何があるか? ・ 自動スケーリングは設定されているか? ・
デプロイパイプラインがどのように定義されているか? ・ こういった情報を整理するのに Claude Codeで対話的に聞けるのは有用 ・ 助けになるMCP ・ AWS Documentation MCP Server ・ AWS Terraform MCP Server
PRCにおけるAI活用(今後の動き) ・ PRCを一度回すことで出来ているところ、出来ていないところがはっきりした ・ 安定運用の程度を可視化できた。次は改善フェーズ ・ PRC自体もTerraformのコードを管理しているリポジトリで管理しているので、改善点 をAIに相談しながら本番環境をより安定稼働する状態を目指す ・ よりAI
Readyな状態でPRCを回せるようにフォーマットを最適化
運用・監視におけるAIの導入
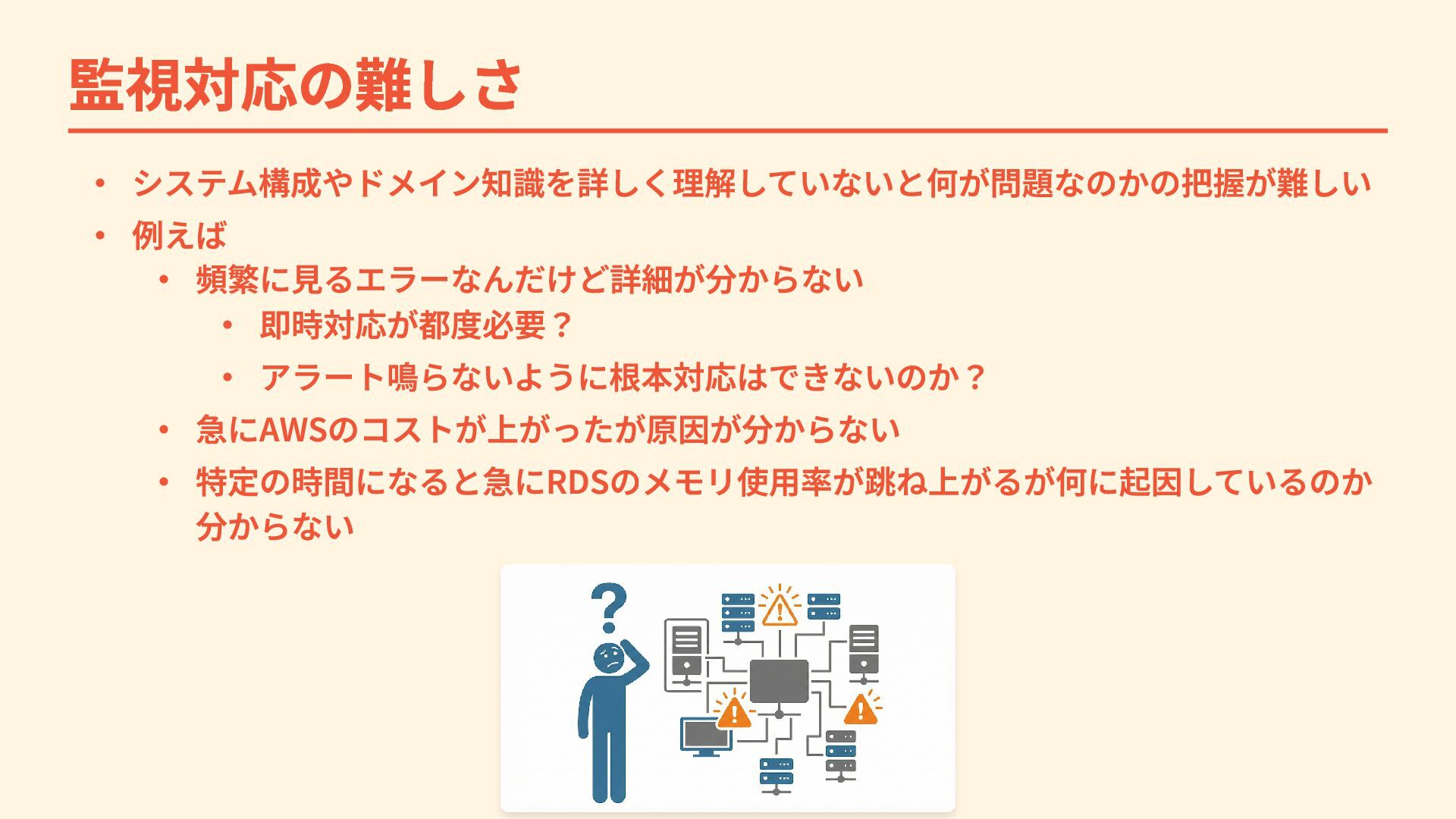
監視対応の難しさ ・ システム構成やドメイン知識を詳しく理解していないと何が問題なのかの把握が難しい ・ 例えば ・ 頻繁に見るエラーなんだけど詳細が分からない ・ 即時対応が都度必要? ・
アラート鳴らないように根本対応はできないのか? ・ 急にAWSのコストが上がったが原因が分からない ・ 特定の時間になると急にRDSのメモリ使用率が跳ね上がるが何に起因しているのか 分からない
監視対応の難しさ ・ 別のスクラムチームが触ったコードの理解度が低い ・ 機能同士の相関関係も複雑化していて分かりづらい ・ 特に筆者はAWSを使ったクラウドインフラの知識の乏しさもあり、AWS Console を眺 めたりしているだけではわからないことが多い
-> AIでなんとか楽にできないか?
例外対応をAIで楽にする ・ Sentry MCPを導入 ・ https://docs.sentry.io/product/sentry-mcp/ ・ issue URLを取得して原因調査を補佐してもらう ・
割と素直に原因を特定して解決してくれる ・ Sentryはエラーコード、スタックトレース、パラメーター等調査に必要な情報 をissue情報として保持しているのでAIが活用しやすい
例外対応をAIで楽にする(今後の動き) ・ そのままSentry issueをAIに食わせるだけでも一定の効果があるが、知見の積み上げが 難しい ・ そのエラーが来たら即時対応が必要なのか? ・ 暫定対応・恒久対応はどこまで進んでいるのか? ・
Sentry issue に情報を集約させ、適切にissueを管理する ・ Sentry issue のActivityを活用し、過去の対応時のアクションを載せていく ・ Sentry issue とGitHubのPRを紐づける
例外対応をAIで楽にする(今後の動き) ・ 一部の例外に関しては原因がバラバラなのにissueが集約されるので Issue Grouping を 活用する ・ https://docs.sentry.io/concepts/data-management/event-grouping/ ・
SentryはデフォルトだとStack Traceなどを元にしたFinger Printでissueを集約する ・ Groupingのルールは任意にカスタマイズすることができるので、独自ルールを設ける
AWSの運用監視をAIで楽にする ・ 対話形式でアラートの調査ができることを期待し、Claude CodeにてAWSの各種MCPを 導入 ・ 色々なMCPサーバーがあるがその中から使用したものを次頁でいくつか抜粋
AWSの運用監視をAIで楽にする MCP 用途 AWS Cloud Watch MCP Server メトリクス異常の調査 コスト異常時にメトリクスの傾向から原因を調査できるこ
とを期待 AWS Cost Explorer MCP Server コスト異常の原因調査 AWS CloudTrail MCP Server AWSに対する操作からメトリクス異常やコスト異常の原因 に繋がるものがないかを調査 AWS Documentation MCP Server AWSの各種サービスの最新仕様を確認
AWSの運用監視をAIで楽にする ・ CloudWatchアラートやコスト異常検出のURLなどを渡したらAIがなんとかしてくれな いか? ・ 原因をずばり特定するには至らないことが多い ・ 曖昧な指示だと調査に必要な情報が多く、セッションの圧縮が何度も繰り返されて しまい調査中のままループする ・
もっとAIに渡す情報を絞り込む事が必要
AWSの監視をAIで楽にする(今後の動き) ・ 次の打ち手として、これまでの過去の事例をNotion DB化してAIに食わせることを検討 中 ・ メトリクス異常やコスト異常のアラートが起きた経緯を記録しておく ・ その時どういった対応を取ったかも記録しておく ・
AIを使わなくとも人が読むドキュメントとして有益な情報になりそう ・ 過去事例を元に調査に必要な情報を絞り込むための対話形式のスラッシュコマンドを作 るとMCPによる調査は捗りそう
AWSの監視をAIで楽にする(今後の動き) ・ 過去事例DBを作るようなことをしなくても AWS re:Inventで発表された AWS DevOps Agent を使うとこのあたりかなり改善するかも ・
https://aws.amazon.com/jp/devops-agent/ ・ 自律性の高さが売りなようなので、どこまでを自動化してどこまでを人間がやるのか、 勘所が必要になりそう ・ 少なくともアラート等の調査工数が減らせれば大幅なコストカットにつながる ・ 調査そのものではなく、Agentの分析の質を高めることに時間を費やすという、新たな 運用の形が見えてくるかも
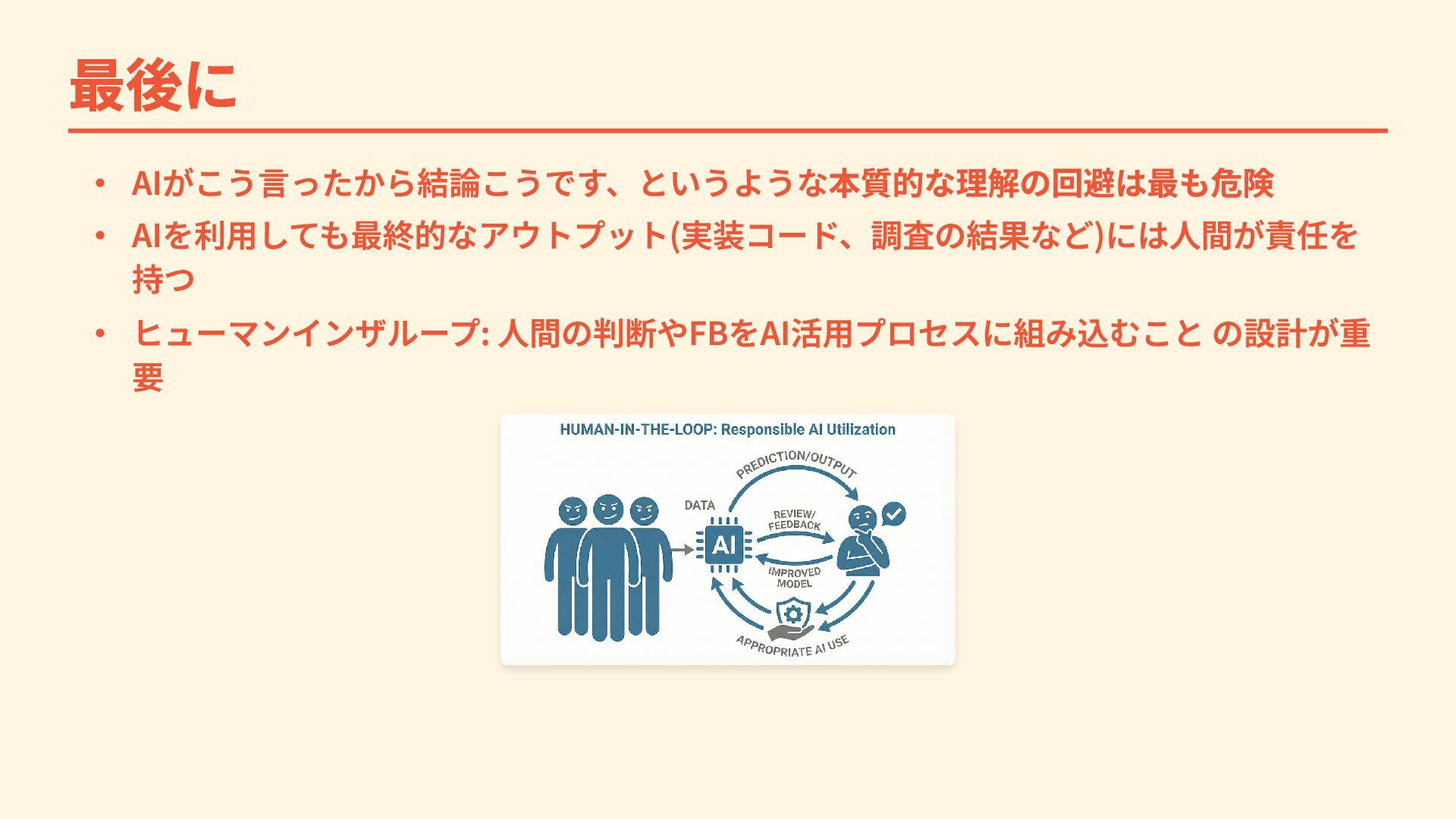
最後に ・ AIを使うと調査を楽にすることはできる ・ しかし、使いこなすためにはコンテキストをうまく伝える事が必要 ・ 前提となる情報を伝えるのに一定の理解は必要 調査にしろコーディングにしろ、AIは自らの活動を並走して助けてくれるものと考える
最後に ・ AIがこう言ったから結論こうです、というような本質的な理解の回避は最も危険 ・ AIを利用しても最終的なアウトプット(実装コード、調査の結果など)には人間が責任を 持つ ・ ヒューマンインザループ: 人間の判断やFBをAI活用プロセスに組み込むこと の設計が重
要
クラシルで実践している データ分析でのAI活用事例 harry (@gappy50) / クラシル株式会社
自己紹介 harry (@gappy50) クラシル株式会社 データエンジニア 担当業務 ・ クラシルのデータ基盤新規構築 ・ 現在は全社データ基盤の構築・運用
技術スタック ・ Snowflake / dbt / Lightdash Snowflake Data Superhero ・ 2022-2025(4年連続)
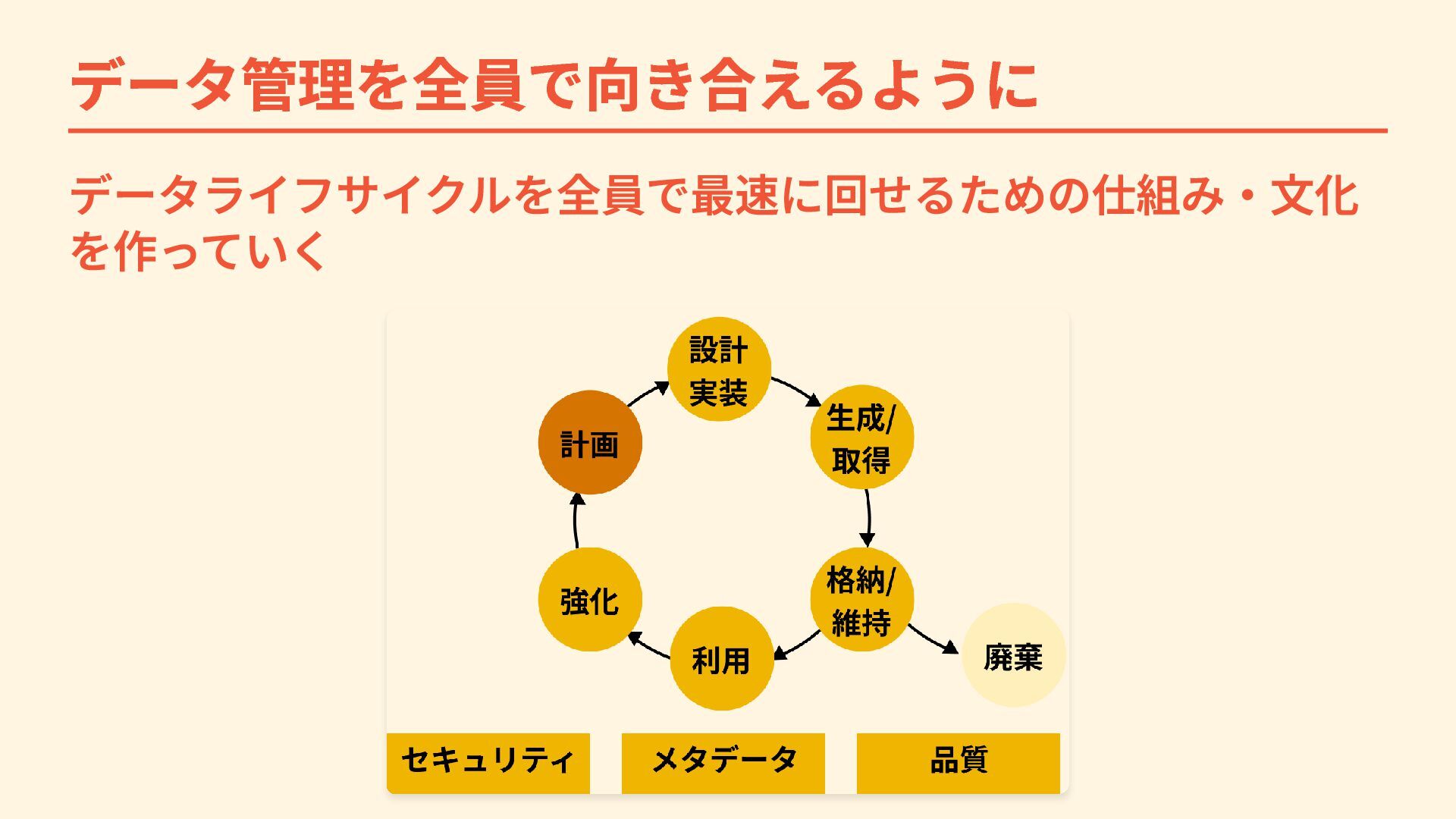
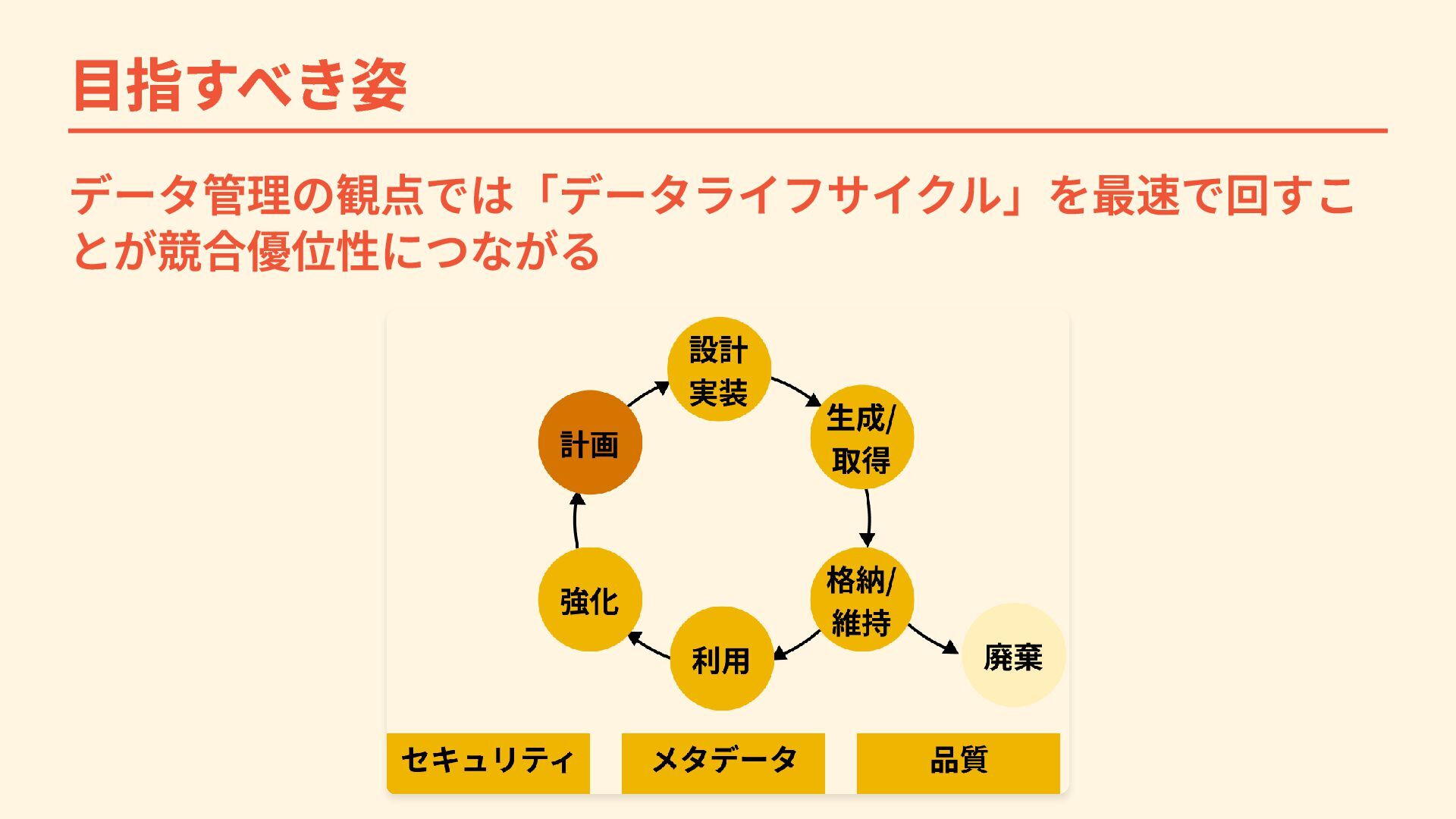
データ管理を全員で向き合えるように データライフサイクルを全員で最速に回せるための仕組み・文化 を作っていく
クラシルにおける データ利活用の根本的な問題
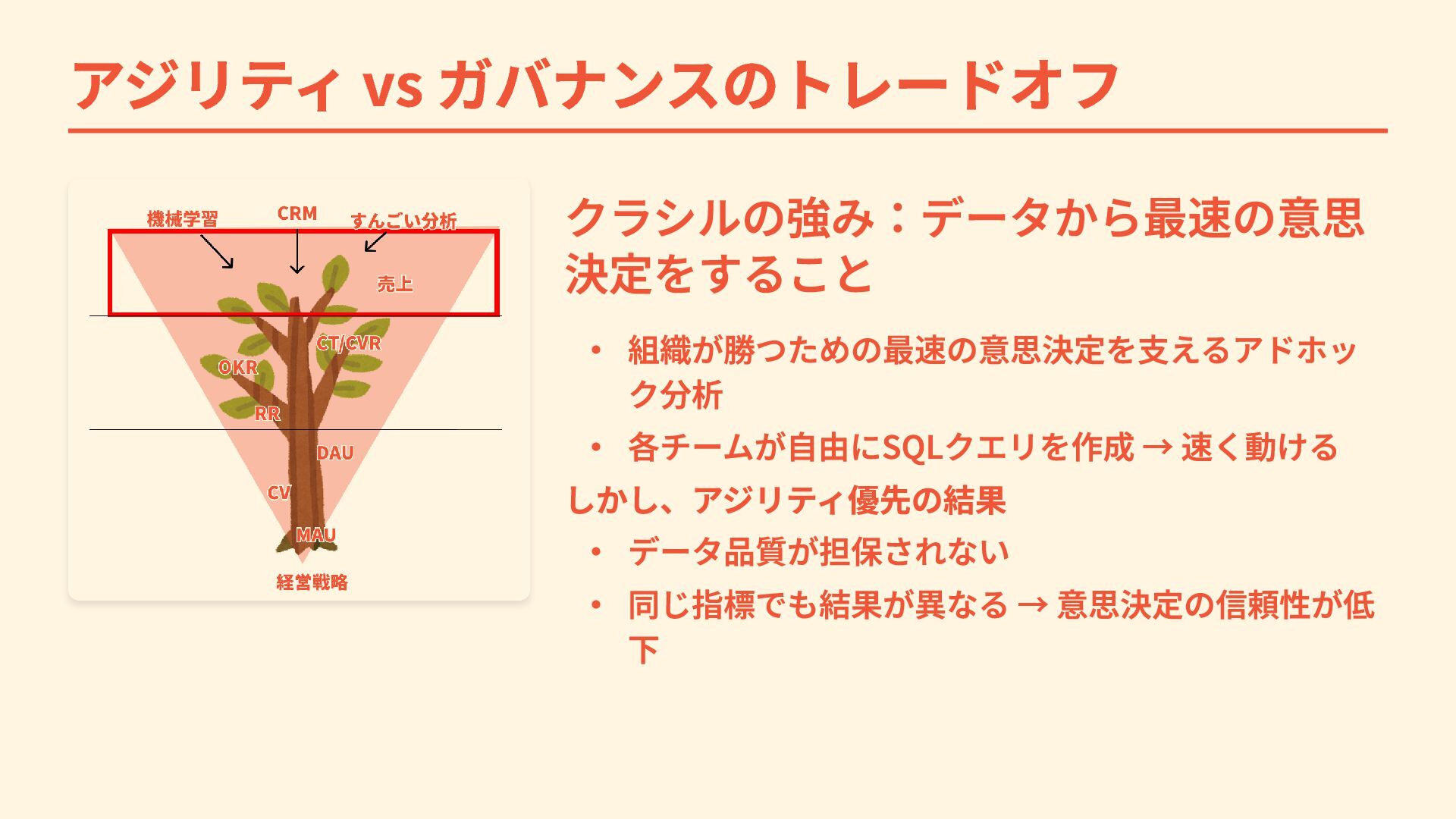
アジリティ vs ガバナンスのトレードオフ クラシルの強み:データから最速の意思 決定をすること ・ 組織が勝つための最速の意思決定を支えるアドホッ ク分析 ・ 各チームが自由にSQLクエリを作成
→ 速く動ける しかし、アジリティ優先の結果 ・ データ品質が担保されない ・ 同じ指標でも結果が異なる → 意思決定の信頼性が低 下
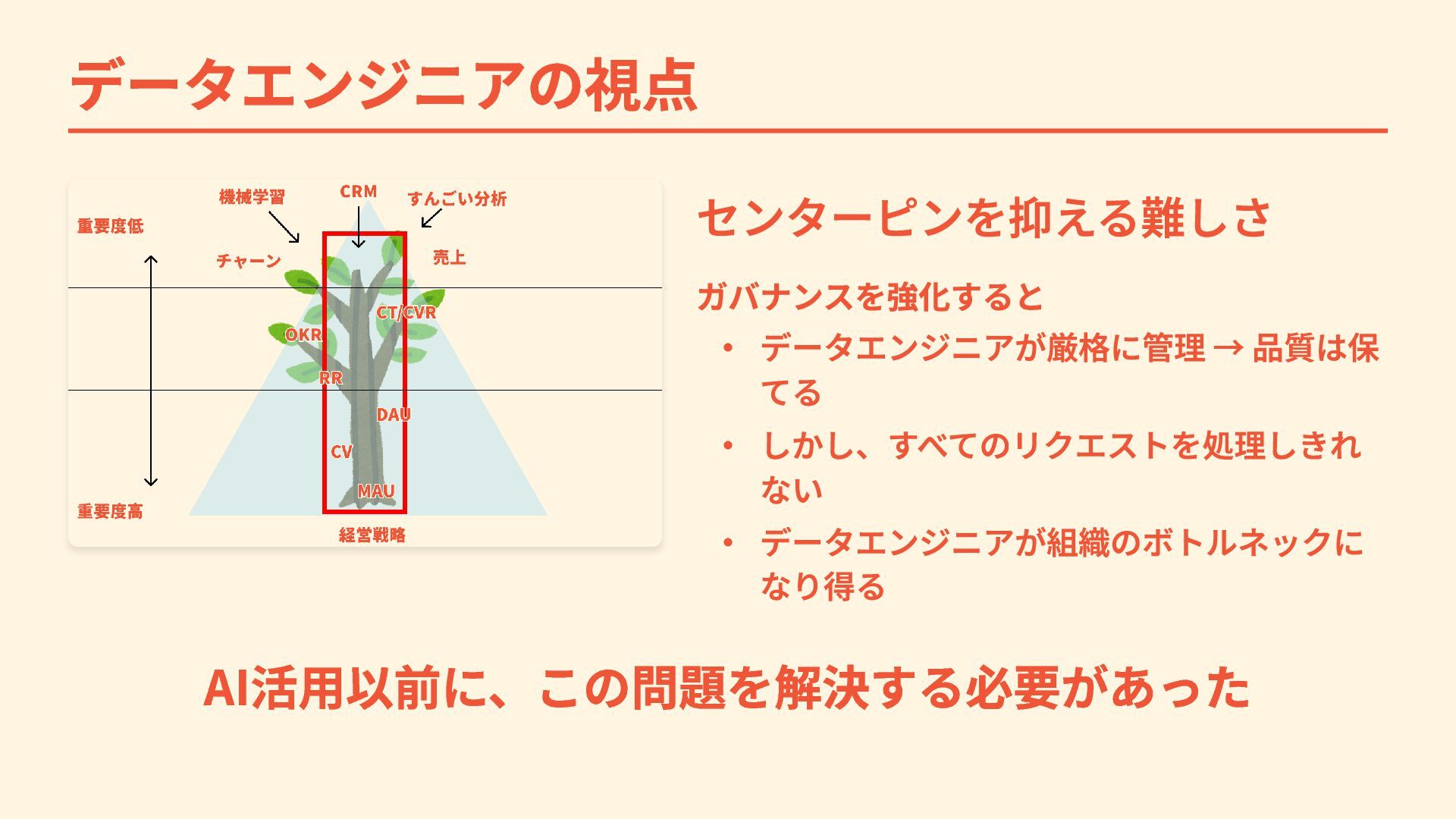
データエンジニアの視点 センターピンを抑える難しさ ガバナンスを強化すると ・ データエンジニアが厳格に管理 → 品質は保 てる ・ しかし、すべてのリクエストを処理しきれ
ない ・ データエンジニアが組織のボトルネックに なり得る AI活用以前に、この問題を解決する必要があった
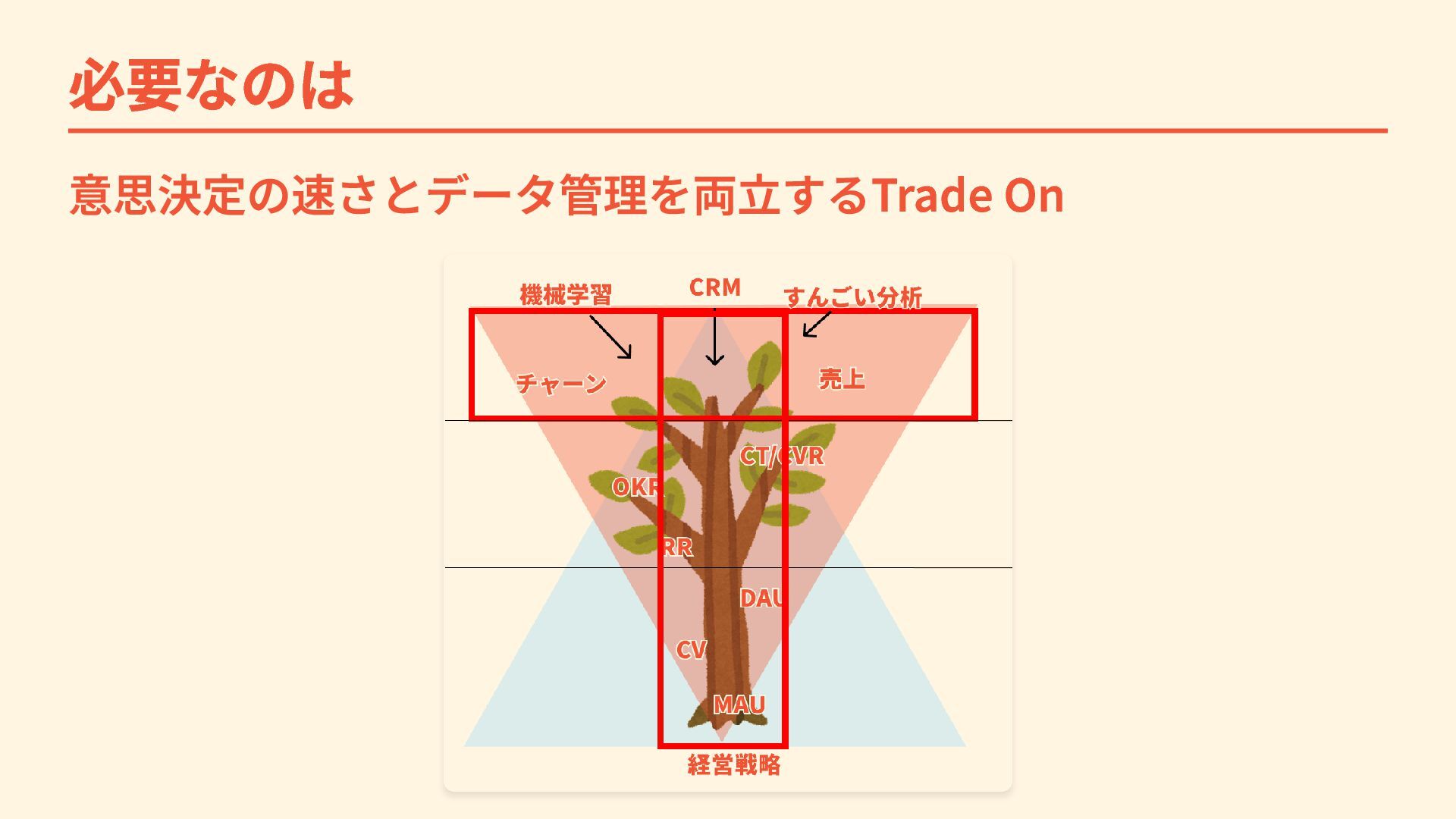
必要なのは 意思決定の速さとデータ管理を両立するTrade On
データライフサイクルを 全員で回す
目指すべき姿 データ管理の観点では「データライフサイクル」を最速で回すこ とが競合優位性につながる
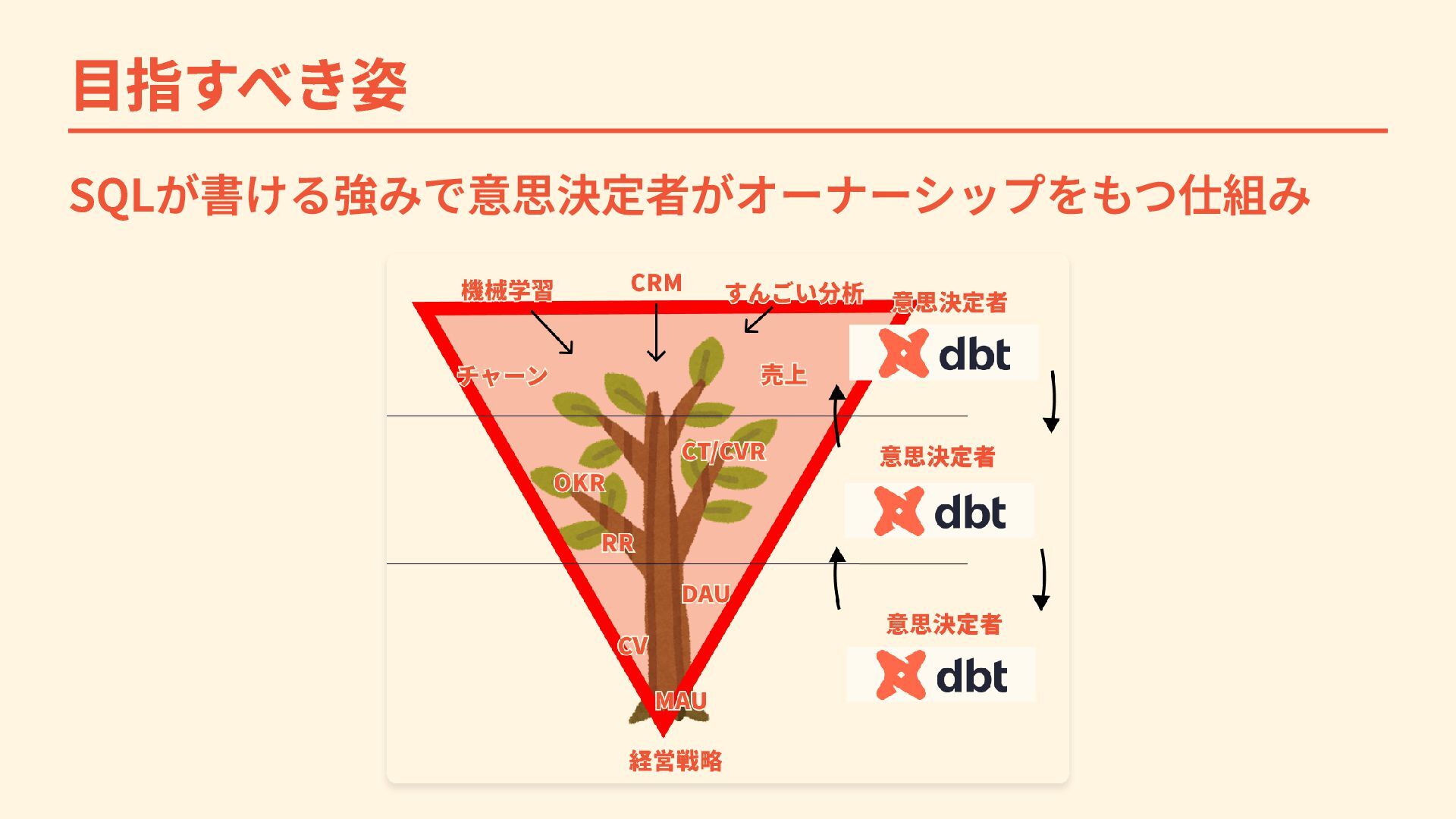
目指すべき姿 SQLが書ける強みで意思決定者がオーナーシップをもつ仕組み
解決策:3つのアプローチ
1. Lightdashでdbtを中心としたデータ管理を実現 dbtネイティブなBIツールで実現 ・ セマンティクス管理: メトリクス定義 (売上、ユーザー数など)をdbtで一元 管理 ・ セマンティクス
= ビジネス用語と データの紐付け ・ メタデータ管理: dbtのドキュメント・ テストを自動反映 ・ Write Back to dbt: アドホッククエリ をdbtモデルへ自動変換
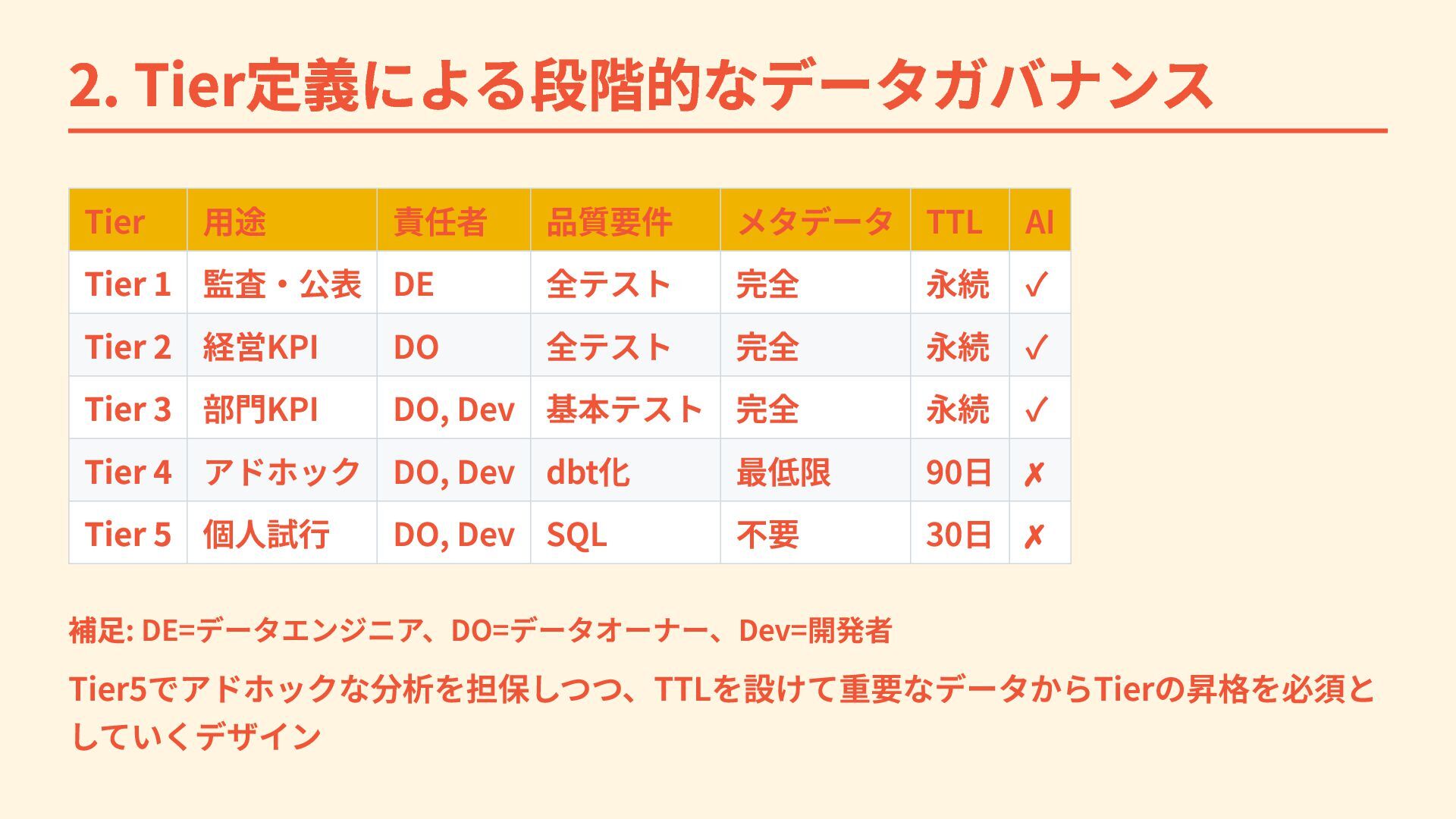
2. Tier定義による段階的なデータガバナンス Tier 用途 責任者 品質要件 メタデータ TTL AI Tier
1 監査・公表 DE 全テスト 完全 永続 ✓ Tier 2 経営KPI DO 全テスト 完全 永続 ✓ Tier 3 部門KPI DO, Dev 基本テスト 完全 永続 ✓ Tier 4 アドホック DO, Dev dbt化 最低限 90日 ✗ Tier 5 個人試行 DO, Dev SQL 不要 30日 ✗ 補足: DE=データエンジニア、DO=データオーナー、Dev=開発者 Tier5でアドホックな分析を担保しつつ、TTLを設けて重要なデータからTierの昇格を必須と していくデザイン
3. データオーナー制度の制定 データから意思決定をする人がオーナーシップをもてるように
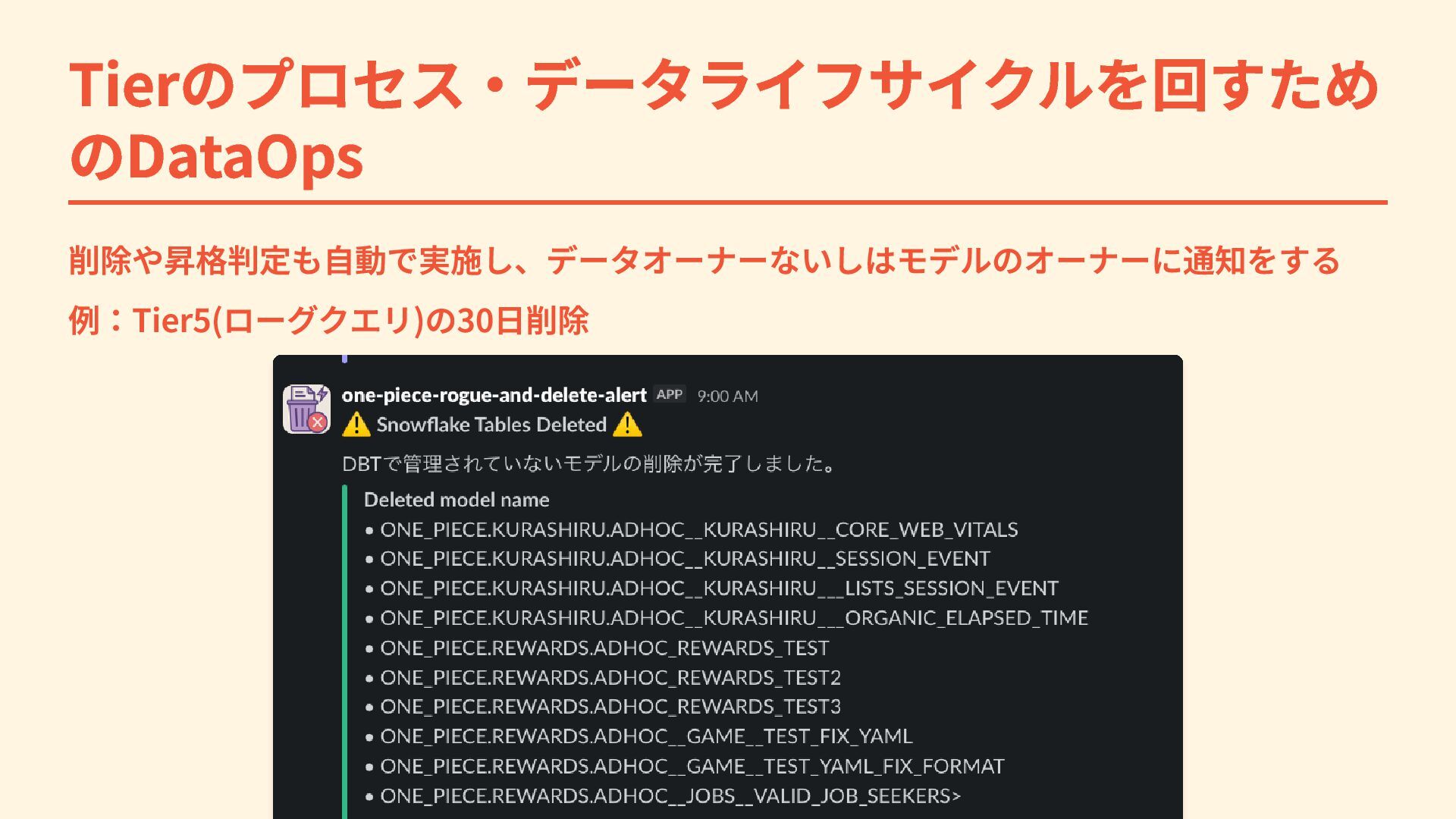
Tierのプロセス・データライフサイクルを回すため のDataOps 削除や昇格判定も自動で実施し、データオーナーないしはモデルのオーナーに通知をする 例:Tier5(ローグクエリ)の30日削除
インセンティブ設計 「品質を上げれば上げるほど、分析が楽になる」好循環 データ品質を上げる(Tier 3以上に昇格) ↓ AIエージェントで自然言語分析が可能になる! ↓ AIによって分析が楽になる、速くなる ↓ より多くのデータの品質を上げたくなるし、多くの軸で深堀りしたくなる
↓ (繰り返し) データも育てていく: 完璧を目指さず、段階的に品質を向上させる
データライフサイクルを回すことが文化に 意思決定者のデータオーナーを軸に裾野が広がる 意思決定に必要なデータのセマンティクスやメタデータが充足しBizメンバーも即時にアドホ ックな分析ができるように
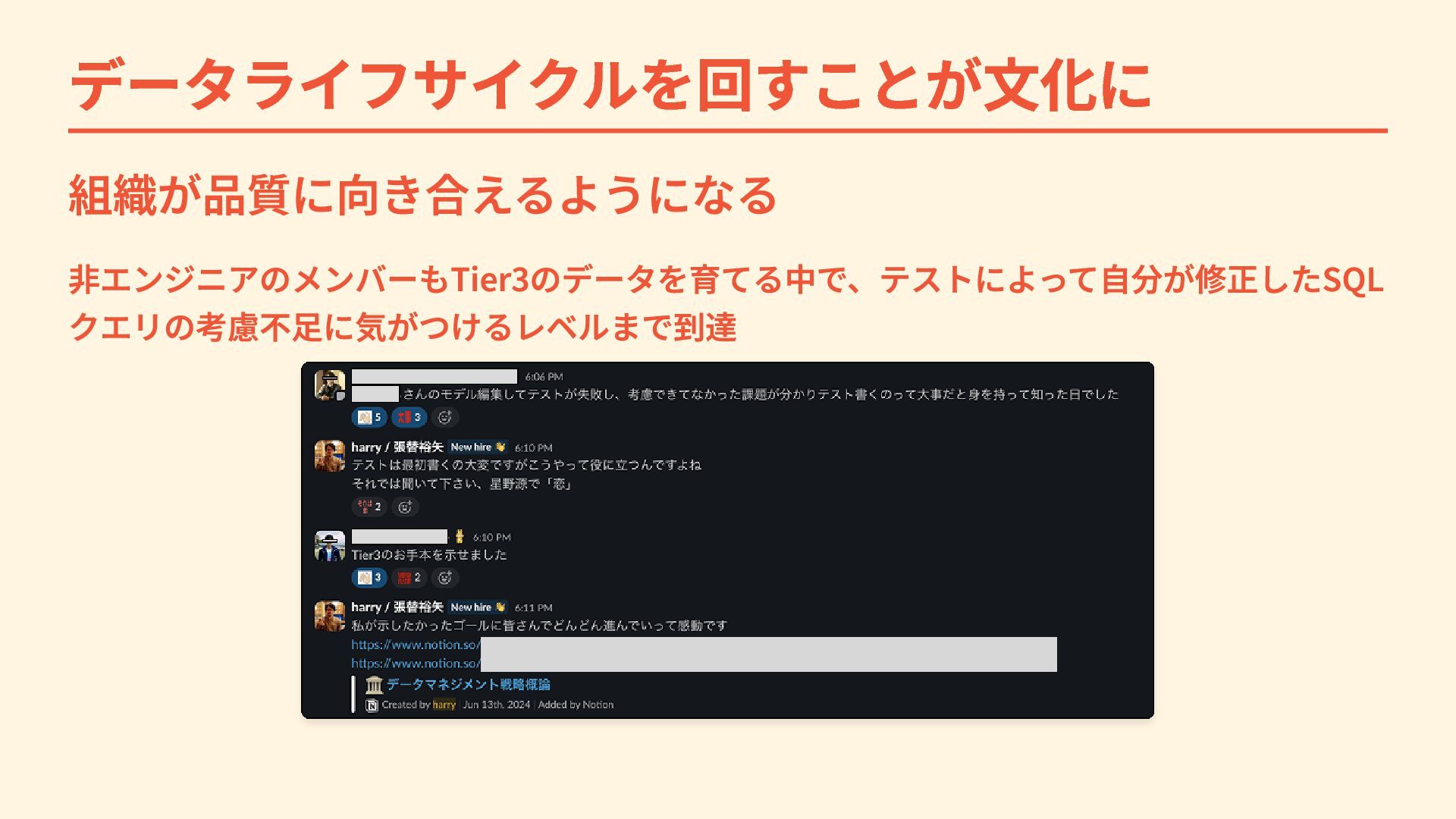
データライフサイクルを回すことが文化に 組織が品質に向き合えるようになる 非エンジニアのメンバーもTier3のデータを育てる中で、テストによって自分が修正したSQL クエリの考慮不足に気がつけるレベルまで到達
AIを活用した組織としての 取り組み
Devinによるデータパイプライン構築の自動化 自然言語の指示だけで、RDSからSnowflakeへのデータパイプライン構築を完全自動化 出典: https://zenn.dev/dely_jp/articles/ai-dataops-devin-playbook-automation
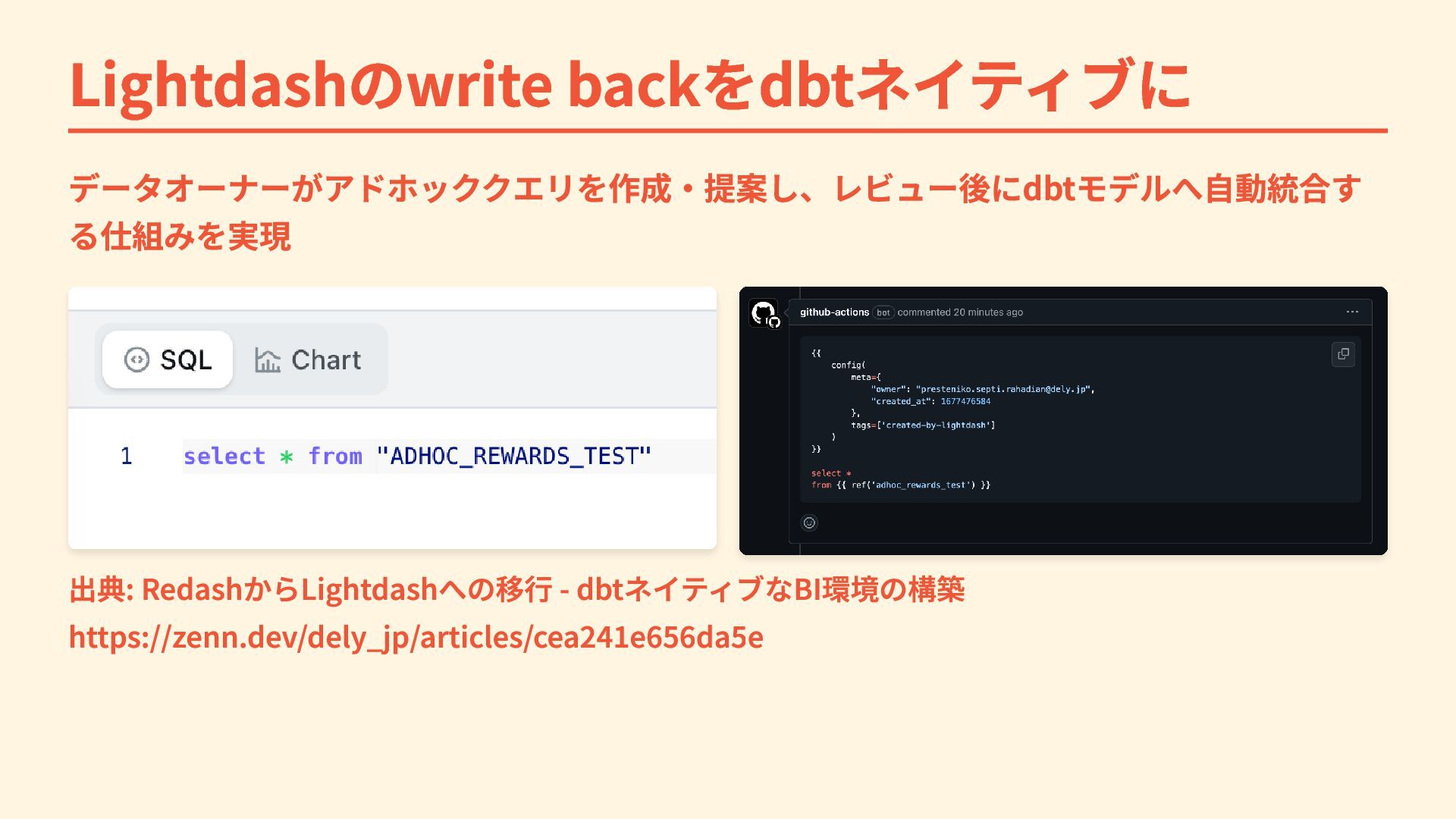
Lightdashのwrite backをdbtネイティブに データオーナーがアドホッククエリを作成・提案し、レビュー後にdbtモデルへ自動統合す る仕組みを実現 出典: RedashからLightdashへの移行 - dbtネイティブなBI環境の構築 https://zenn.dev/dely_jp/articles/cea241e656da5e
Claude Codeを活用したAdhocモデルとテスト実 装 ガードレールとコマンド機能の標準化により、専門家でなくてもスピーディーで品質の高い 分析を実現 出典: AIで加速するデータライフサイクル - Claude Codeで実現するアドホック分析の高速化
https://zenn.dev/dely_jp/articles/47c55622ec2b34
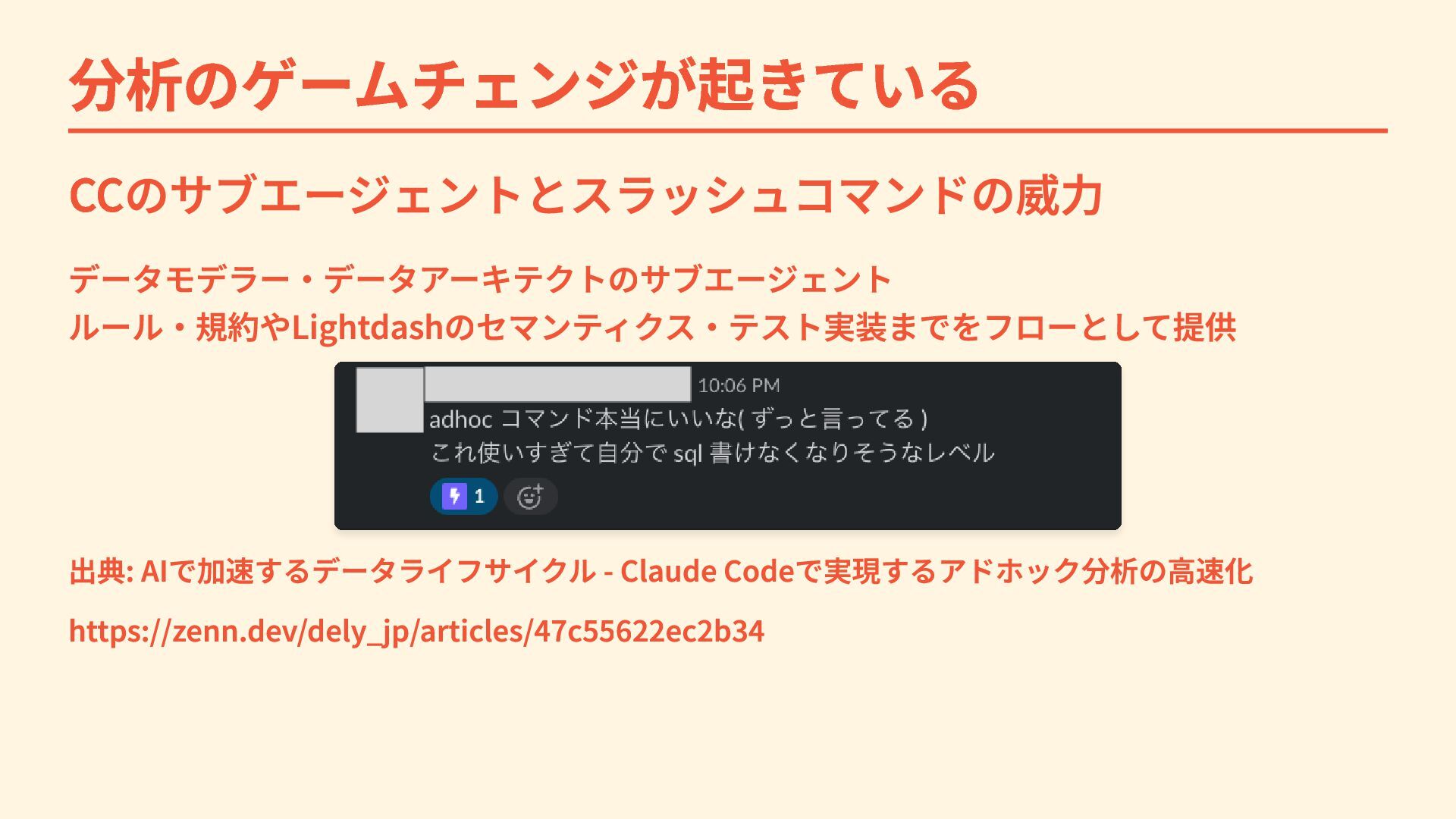
分析のゲームチェンジが起きている CCのサブエージェントとスラッシュコマンドの威力 データモデラー・データアーキテクトのサブエージェント ルール・規約やLightdashのセマンティクス・テスト実装までをフローとして提供 出典: AIで加速するデータライフサイクル - Claude Codeで実現するアドホック分析の高速化 https://zenn.dev/dely_jp/articles/47c55622ec2b34
Devinを活用したAdhocモデルとテスト実装 Devinはサーバーサイドのリポジトリも含めて横断的なコンテキストを利用できるので精度 が高いことが多い
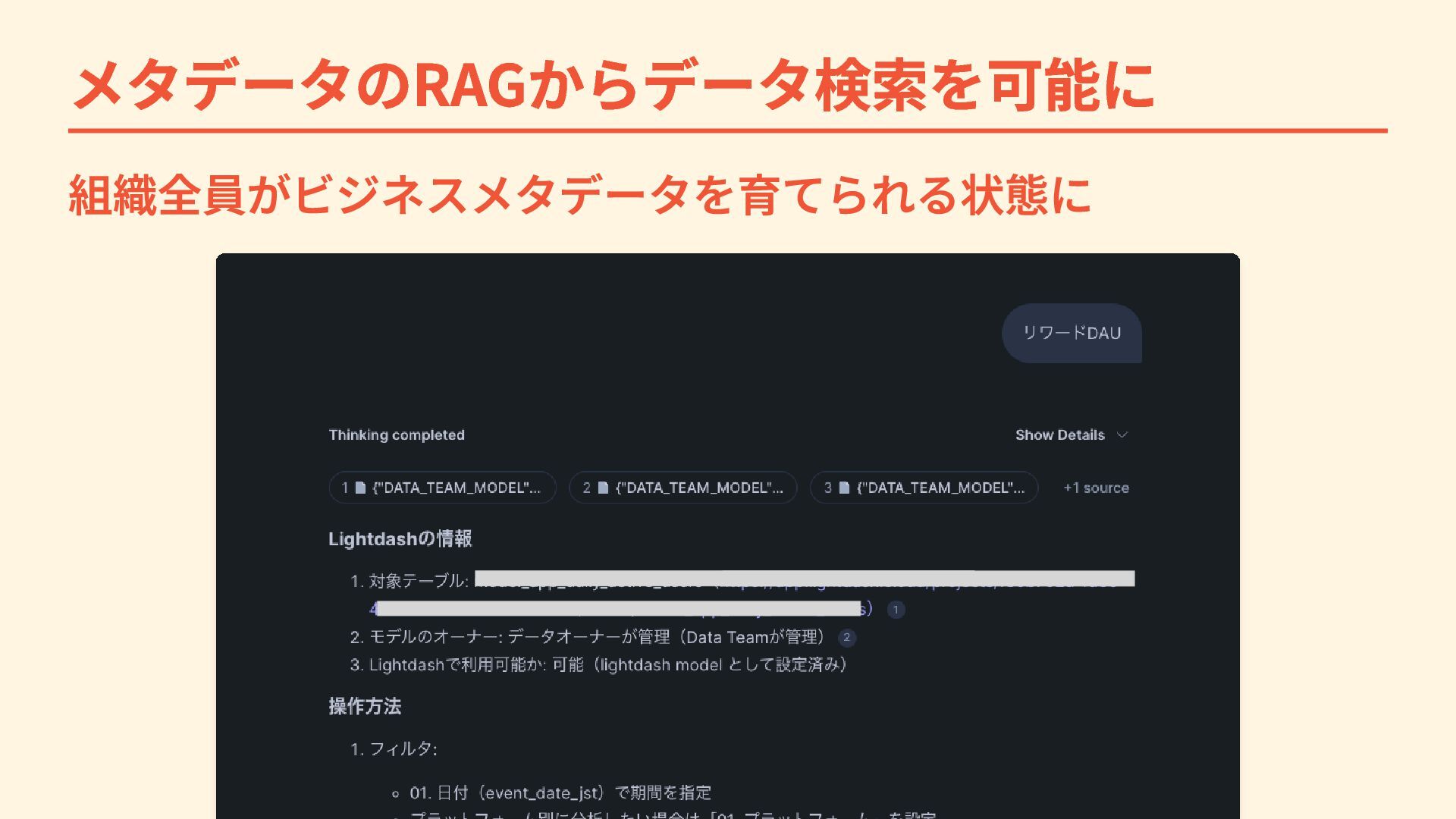
メタデータのRAGからデータ検索を可能に 組織全員がビジネスメタデータを育てられる状態に
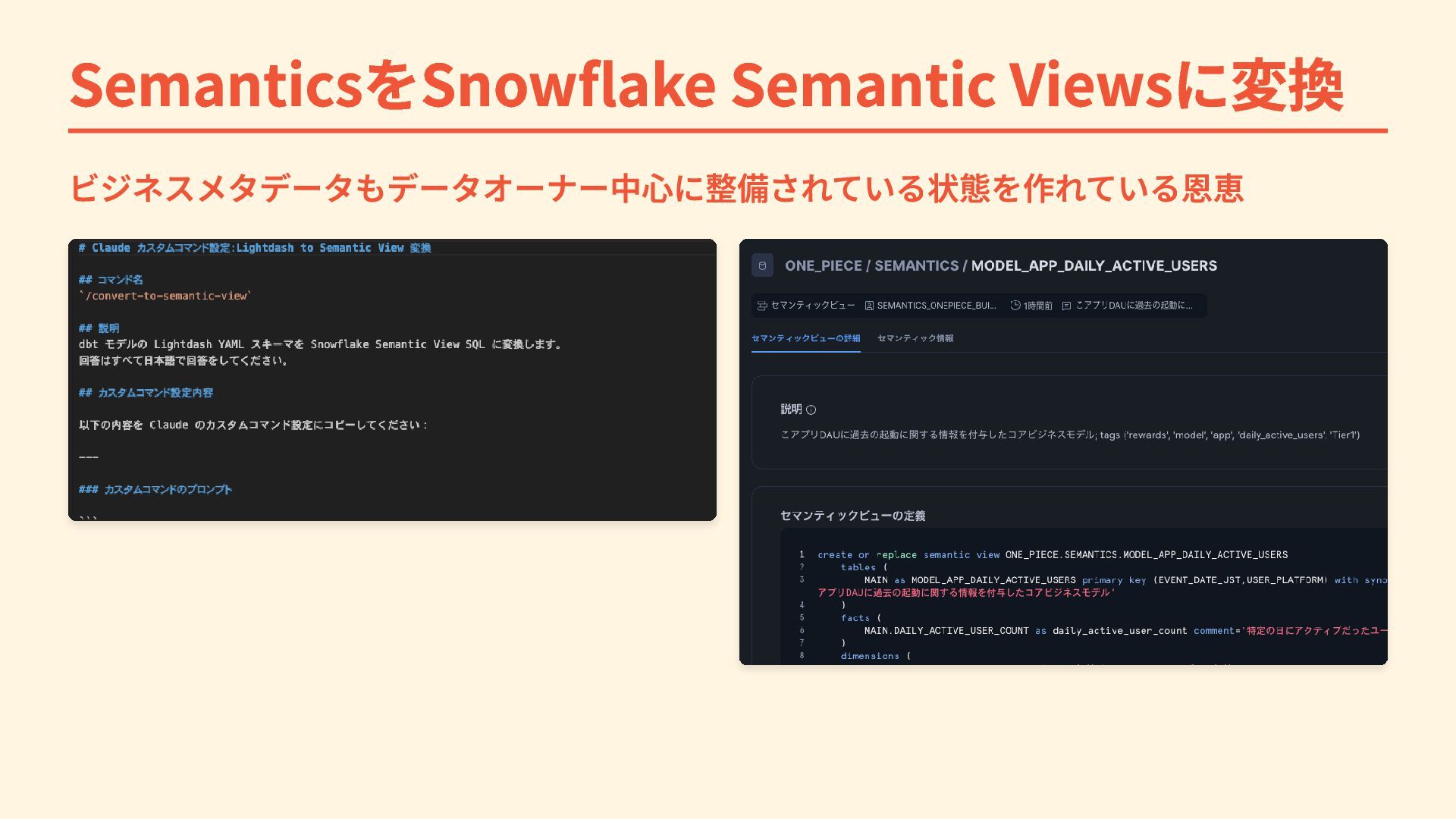
SemanticsをSnowflake Semantic Viewsに変換 ビジネスメタデータもデータオーナー中心に整備されている状態を作れている恩恵
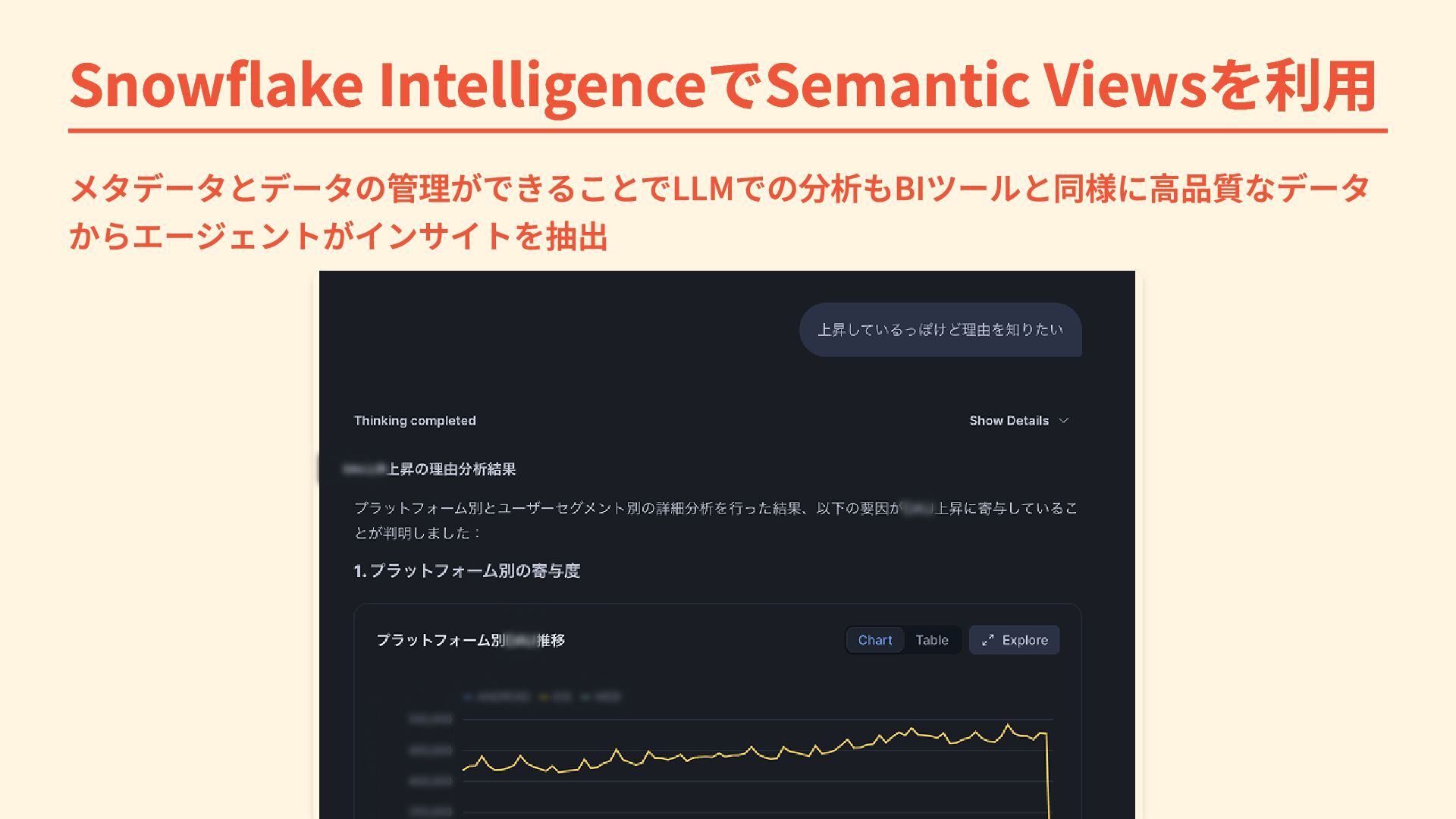
Snowflake IntelligenceでSemantic Viewsを利用 メタデータとデータの管理ができることでLLMでの分析もBIツールと同様に高品質なデータ からエージェントがインサイトを抽出
データライフサイクルを組織 全員でし続けることで いつの間にかAI Readyな データ利活用ができる状態に AI-ReadyはDataOpsを組織で最速で回している文化があれば自ずと到達できる
まとめ
まとめ ・ データライフサイクルを最速で回すための技術選定とDataOpsの実装により、データの 資産価値を高める取り組みが組織文化になりはじめた ・ データオーナーがデータの品質やビジネスメタデータを育てることで活用の裾野が 広がってきた ・ AI利活用はデータマネジメントをどう組織として実践するか ・
我々はデータエンジニアリングの民主化が組織文化になるように解く ・ いつの間にかAI Readyなデータ利活用ができる状態まで到達 ・ データのアジリティだけでなく、適切なタイミングでの品質管理などのガバナンス を両立しながら
ご清聴ありがとうございまし た!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}