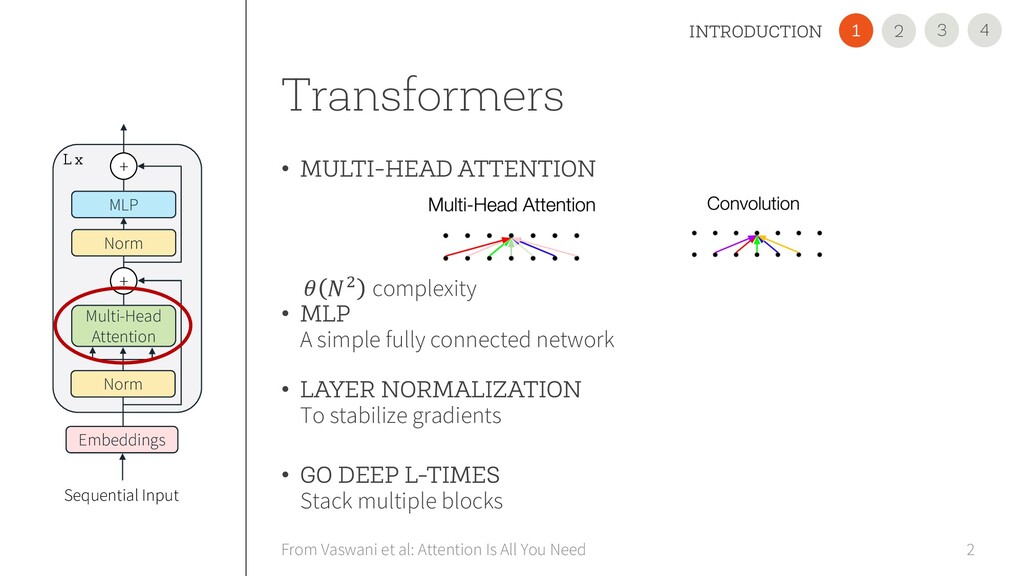
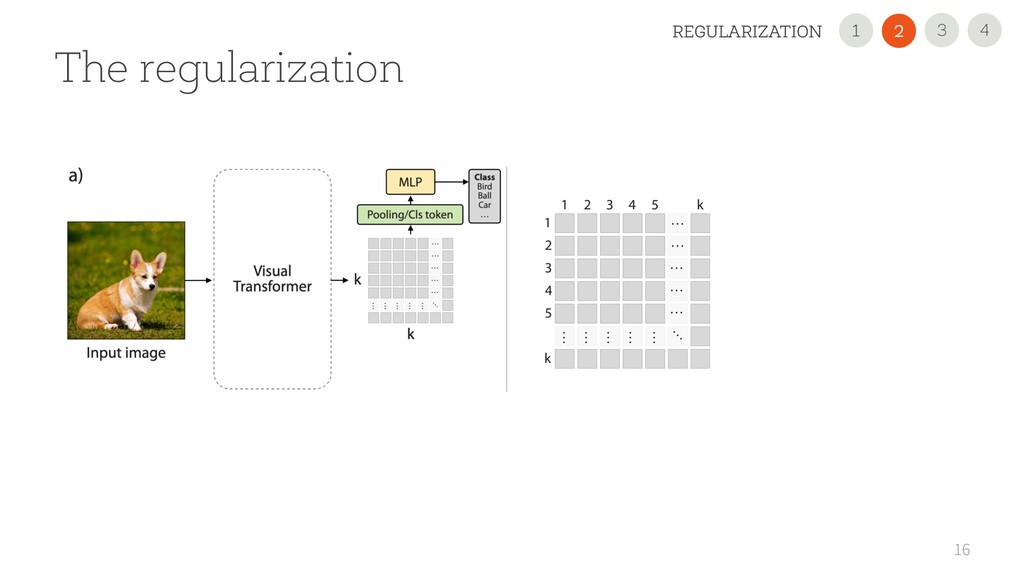
simple fully connected network • LAYER NORMALIZATION To stabilize gradients • GO DEEP L-TIMES Stack multiple blocks 2 From Vaswani et al: Attention Is All You Need 4 3 INTRODUCTION 2 1 Embeddings Multi-Head Attention MLP Norm Norm + + L x Sequential Input
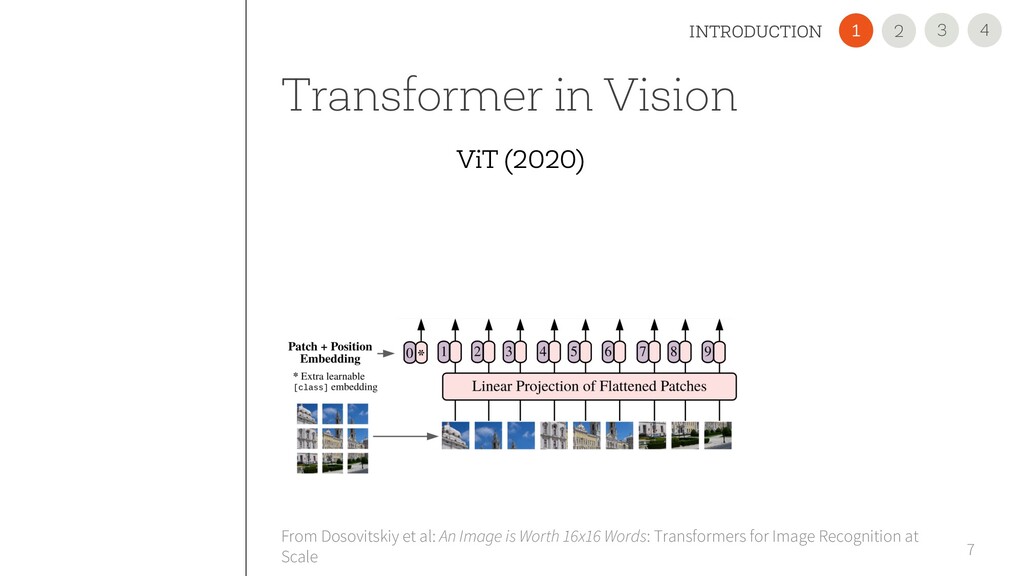
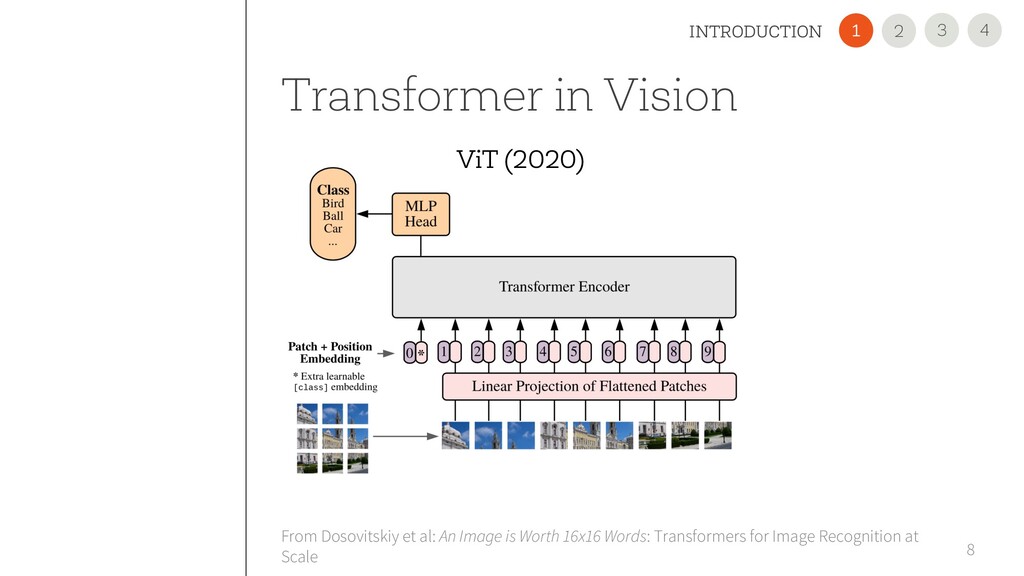
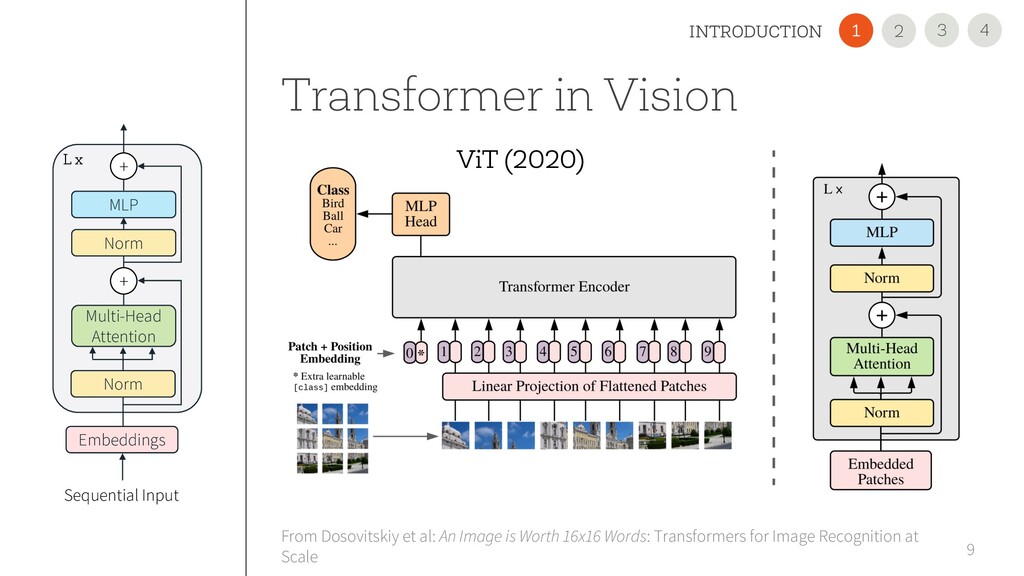
is Worth 16x16 Words: Transformers for Image Recognition at Scale Embeddings Multi-Head Attention MLP Norm Norm + + L x Sequential Input 4 3 INTRODUCTION 2 1 ViT (2020)
• ViT captures global relations in the image (global attention) • Transformers are a general-use architecture • Limit is now on the computation, not the architecture 4 3 INTRODUCTION 2 1
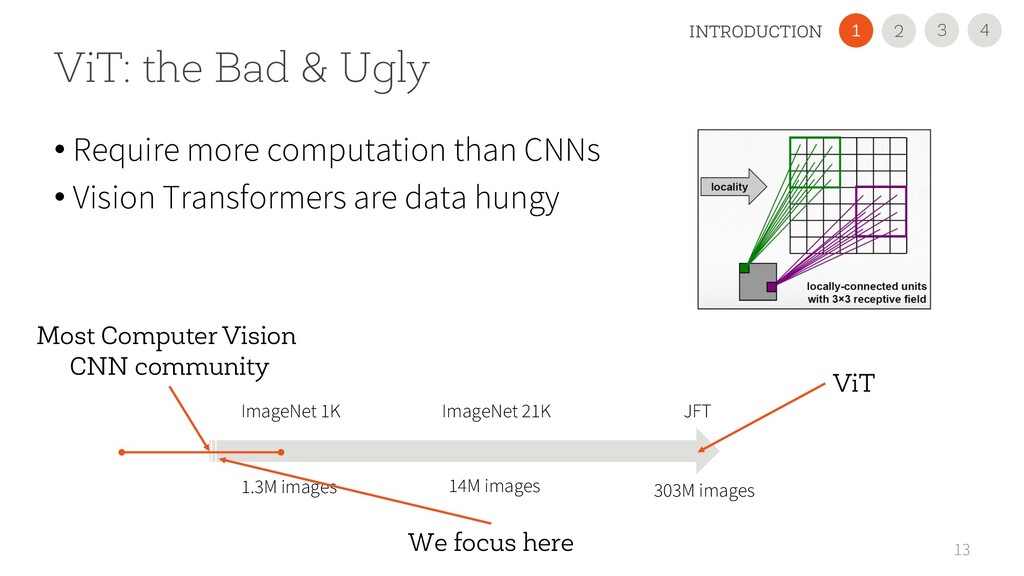
than CNNs • Vision Transformers are data hungy ImageNet 1K 1.3M images ImageNet 21K 14M images JFT 303M images ViT Most Computer Vision CNN community We focus here 4 3 INTRODUCTION 2 1
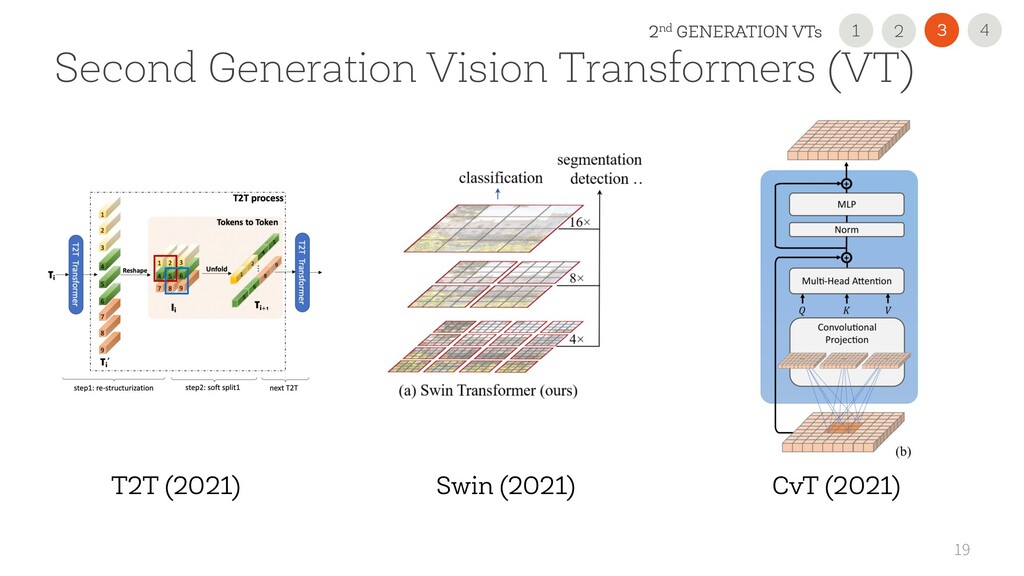
each other with the same pipeline (e.g. data augumentation) • Not tested on small datasets • Better than ResNets • Not clear what is the next Vision Transformer -> We are going to compare and use second-generation VTs 4 3 2nd GENERATION VTs 2 1
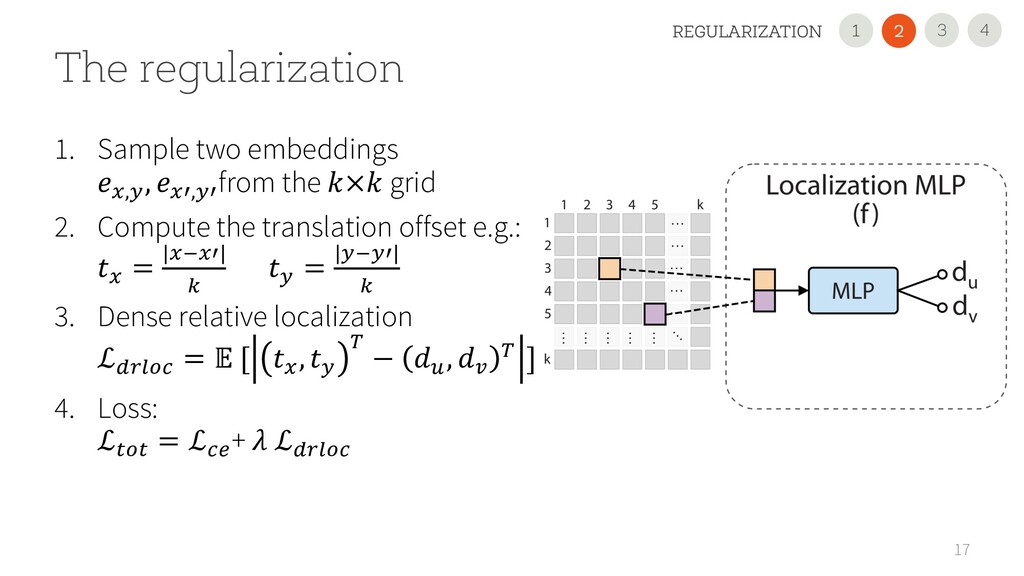
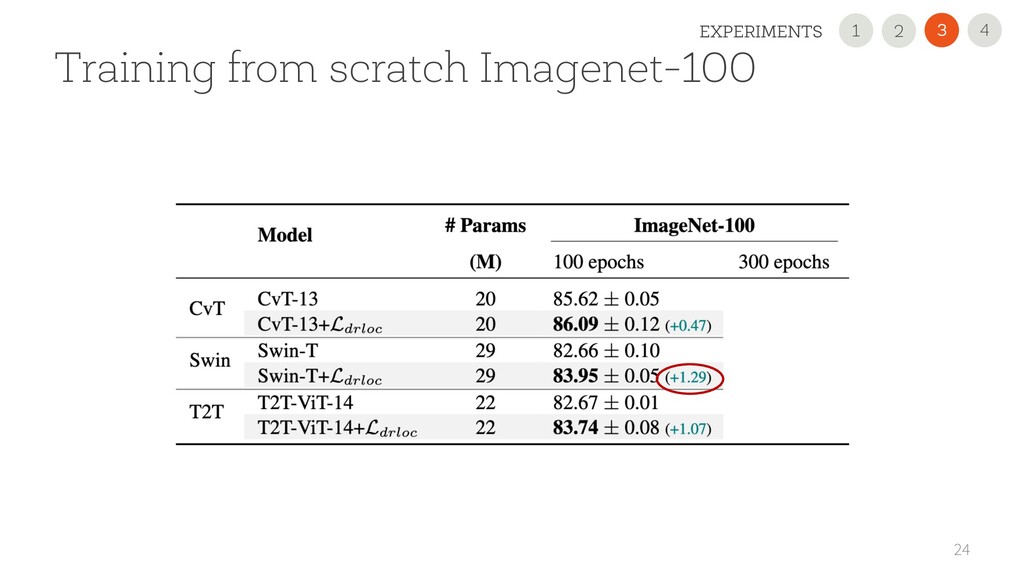
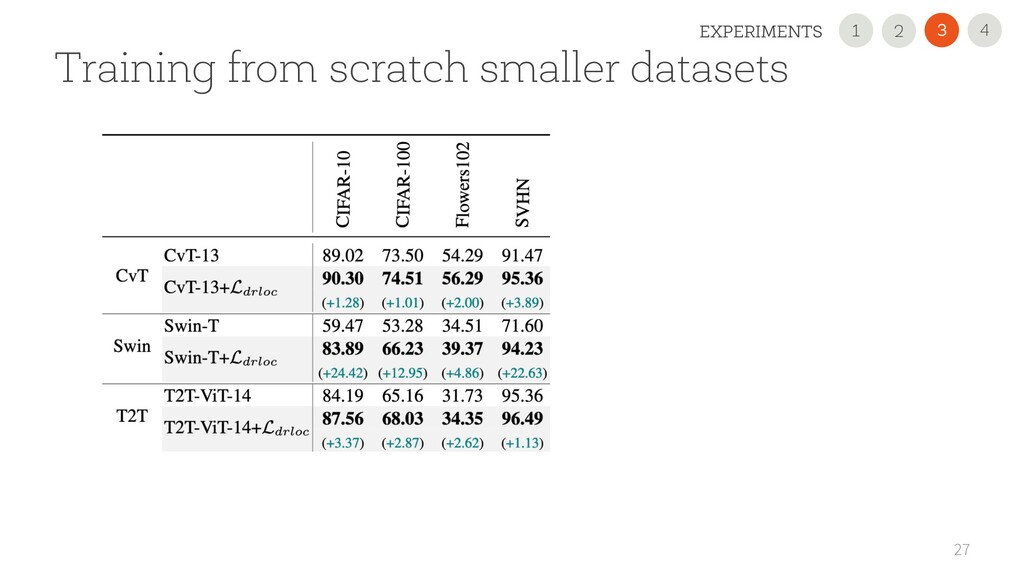
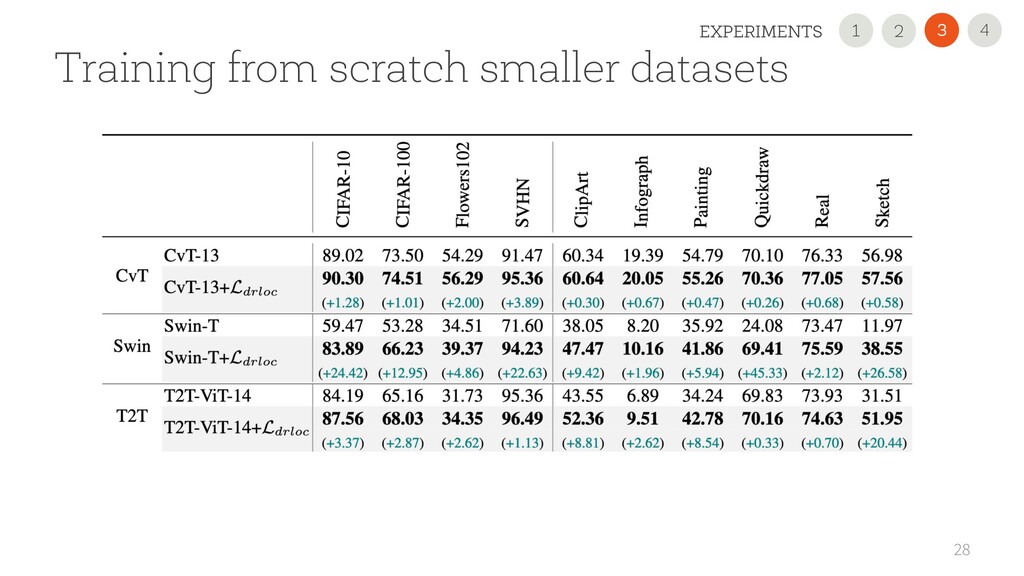
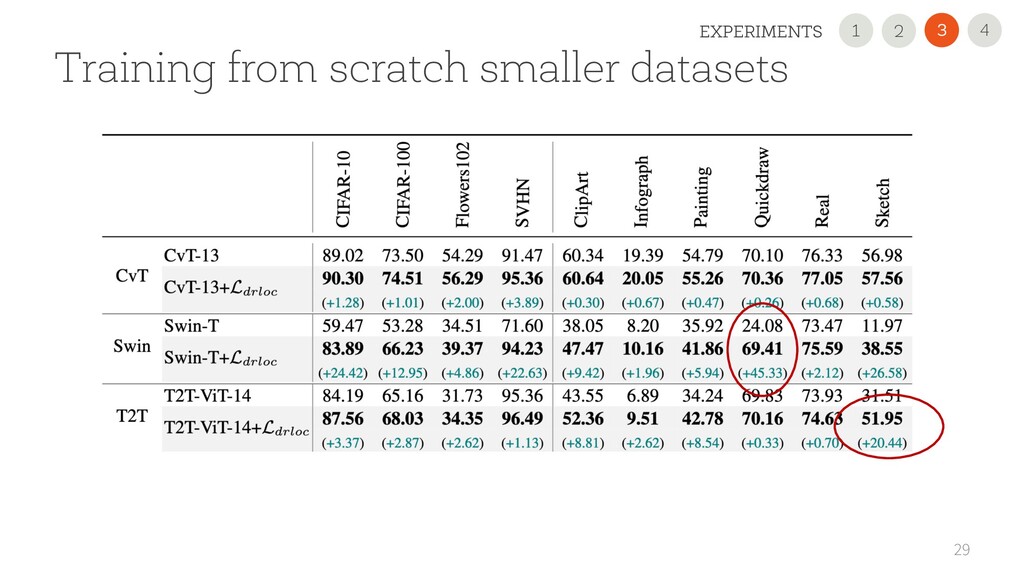
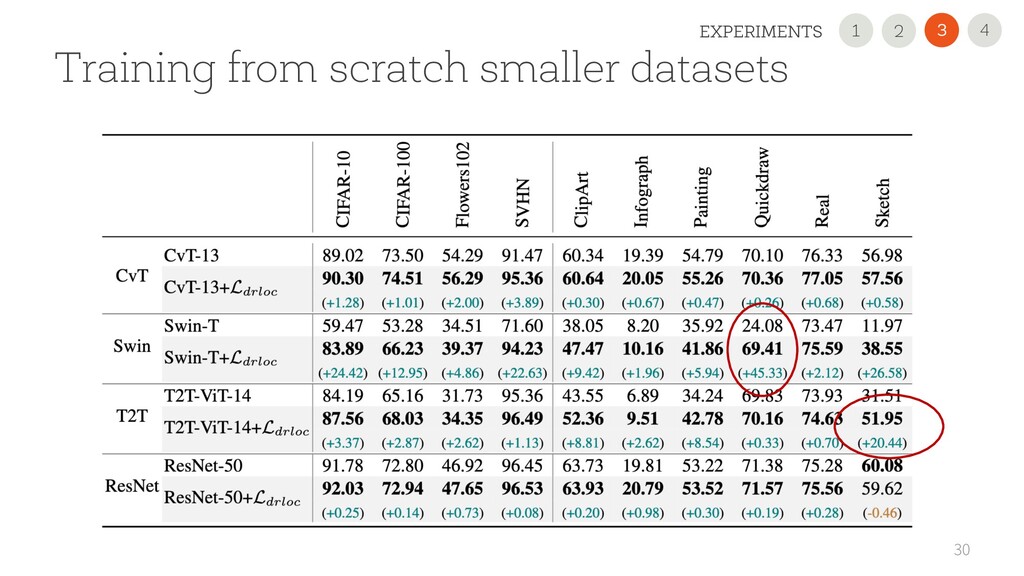
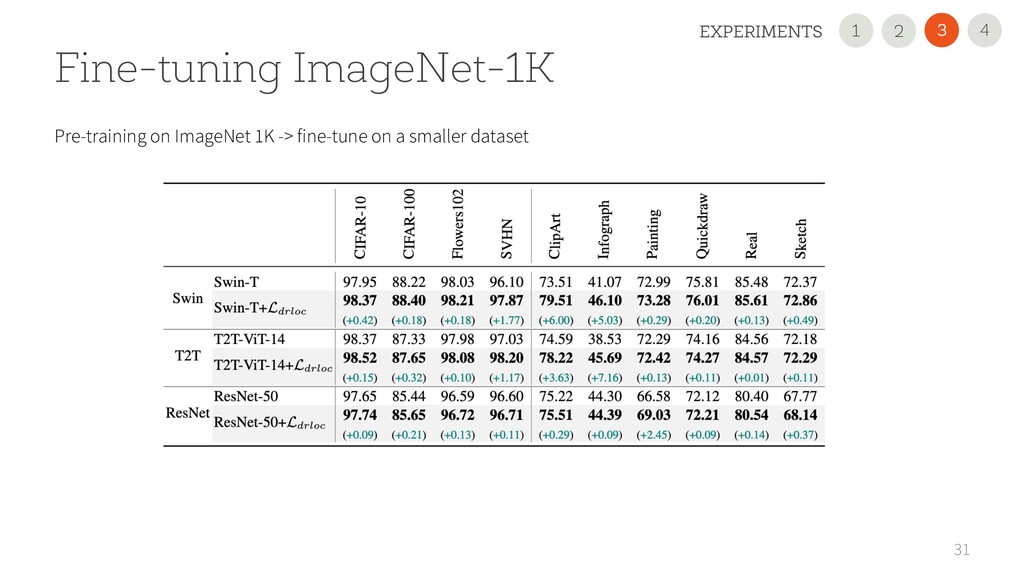
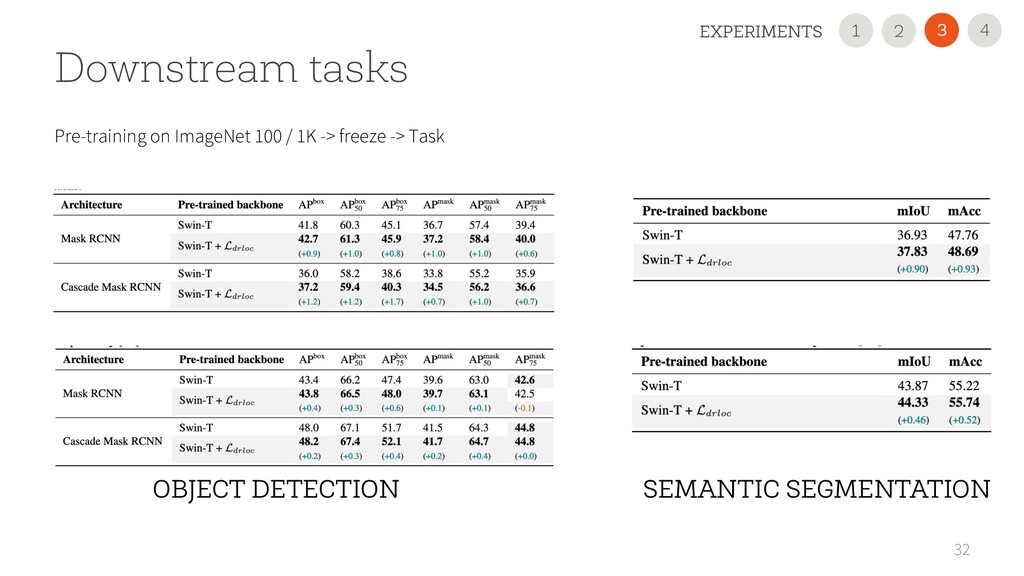
USE OUR NEW REGULARIZATION Improved the performance on all 11 datasets and all scenarios, sometimes dramatically (+45 points). It is simple and easily pluggable in any VT • USE A 2nd GENERATION VTs Performance largely varies. CvT is very promising with small datasets! • READ OUR PAPER FOR DETAILS 35 1 2 4 3 CONCLUSION 2 1 3
Bruno Lepri, and Marco De Nadai Paper: https://bit.ly/efficient-VTs Code: https://bit.ly/efficient-VTs-code Email: [email protected] COPENHAGEN – NEURIPS MEETUP
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}