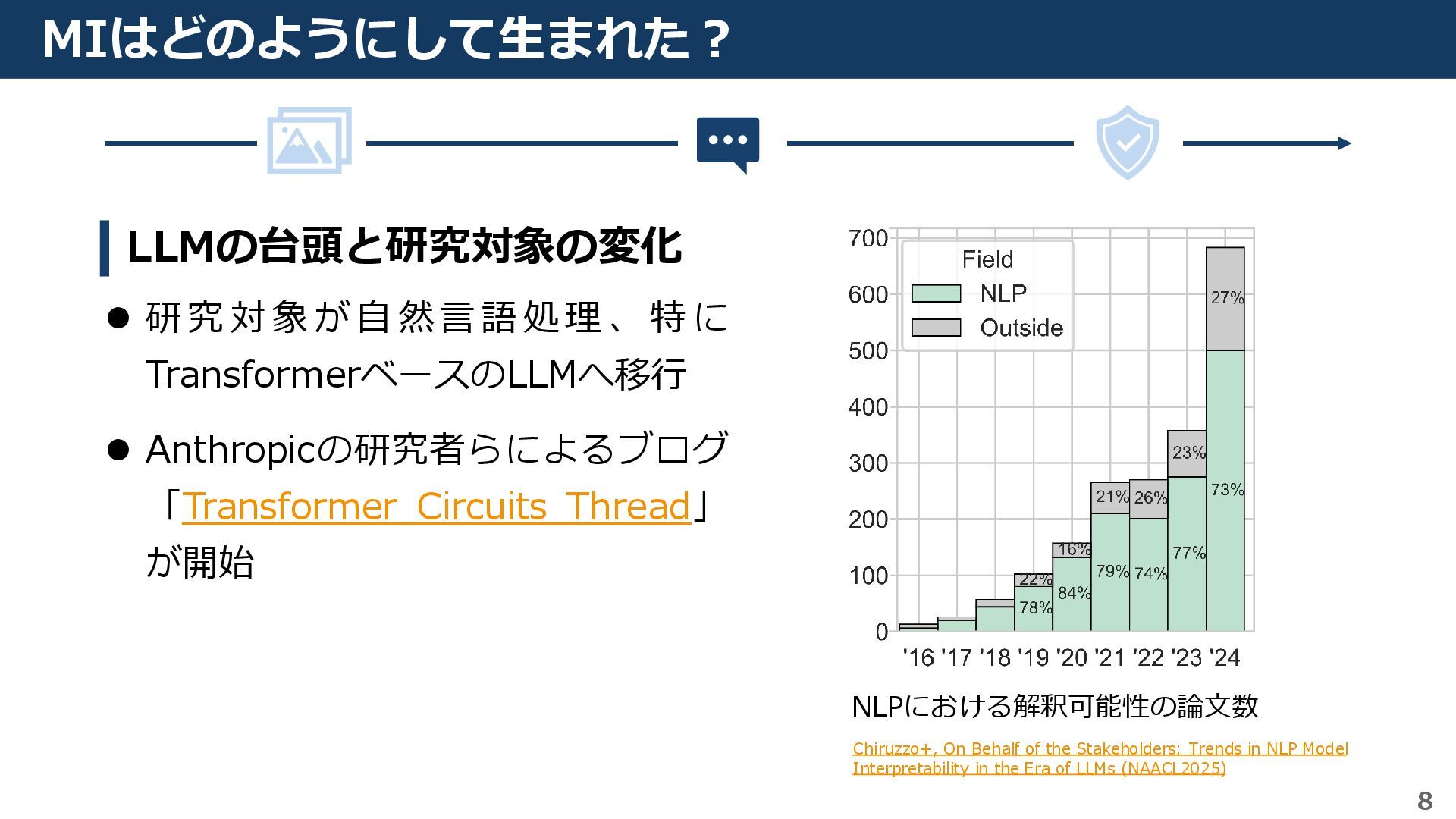
然言 語 処 理 、 特 に TransformerベースのLLMへ移行 ⚫ Anthropicの研究者らによるブログ 「Transformer Circuits Thread」 が開始 NLPにおける解釈可能性の論文数 Chiruzzo+, On Behalf of the Stakeholders: Trends in NLP Model Interpretability in the Era of LLMs (NAACL2025)
特 徴 量 は モ デ ル の 表 現 空 間 の 「方向」に対応するという仮説 ⚫ 議論の余地あり Park+, The Linear Representation Hypothesis and the Geometry of Large Language Models (NeurIPS 2023) 犬 dog
単義的で解釈可能なモデルはより頑健になる Zhang+, Beyond Interpretability: The Gains of Feature Monosemanticity on Model Robustness (ICLR 2025) 33 応用例 Gu+, Mamba: Linear-Time Sequence Modeling with Selective State Spaces (COLM 2024)
McGrath+, Acquisition of chess knowledge in AlphaZero (PNAS 2025) ⚫ 動的相互作用: ◦ Hydra Effect: モデルの一部(例:Attention Head)を無効化しても 別の部分がその機能を補完、自己修正する現象 McGrath+, The Hydra Effect: Emergent Self-repair in Language Model Computations (arXiv 2023)
Vilas+, Position: An Inner Interpretability Framework for AI Inspired by Lessons from Cognitive Neuroscience (ICML 2024) ⚫ 物理学: ◦ 物理学→MI:物理学的な視点からニューラルネットワークを解析 ◦ MI→物理学:物理現象を学習したニューラルネットワークを解析して 物理法則を発見 Kitouni+, From Neurons to Neutrons: A Case Study in Mechanistic Interpretability (ICML 2024)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
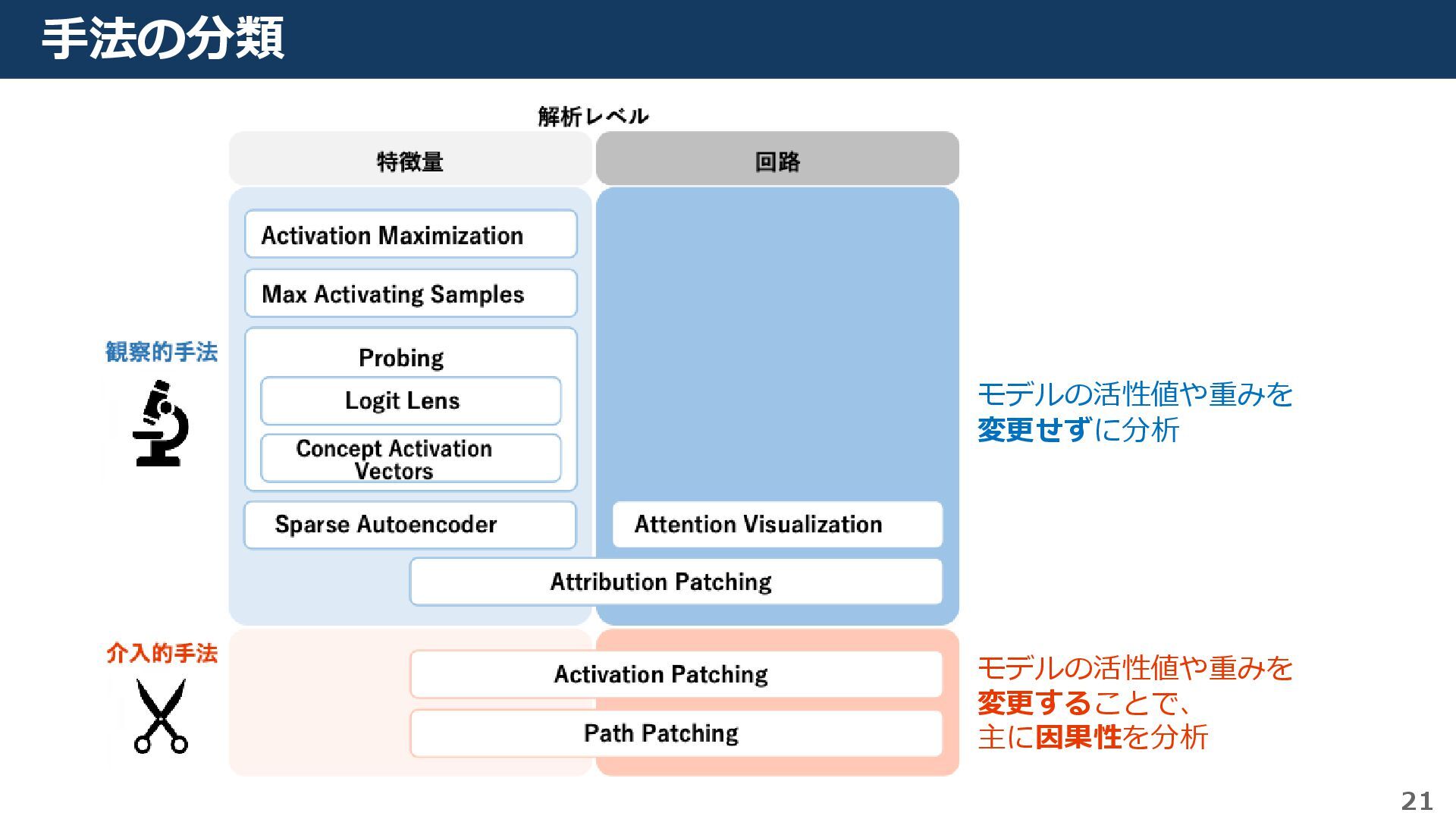{kind=link}
{kind=link}
{kind=link}
{kind=link}
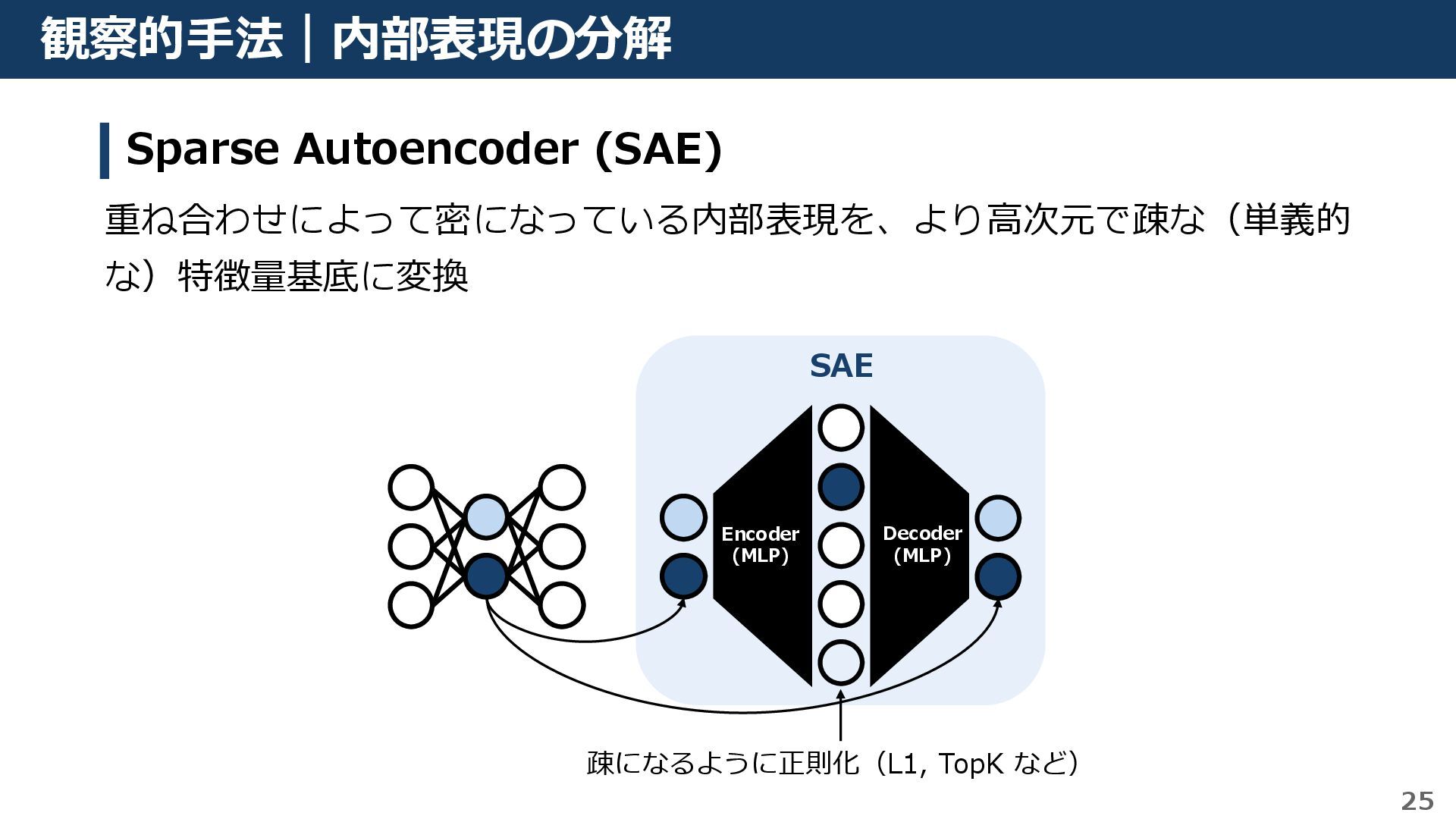{kind=link}
{kind=link}
{kind=link}
{kind=link}
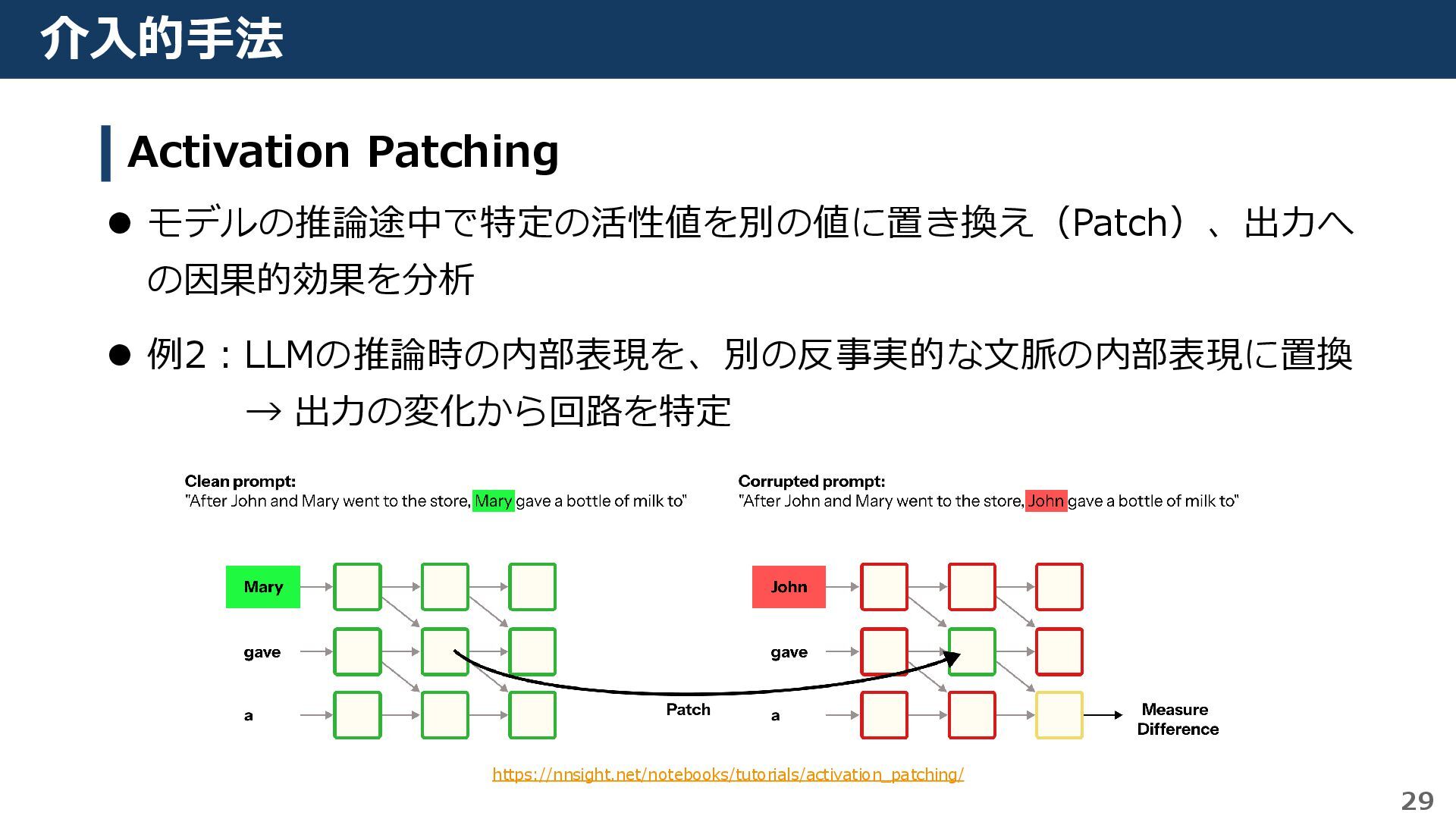{kind=link}
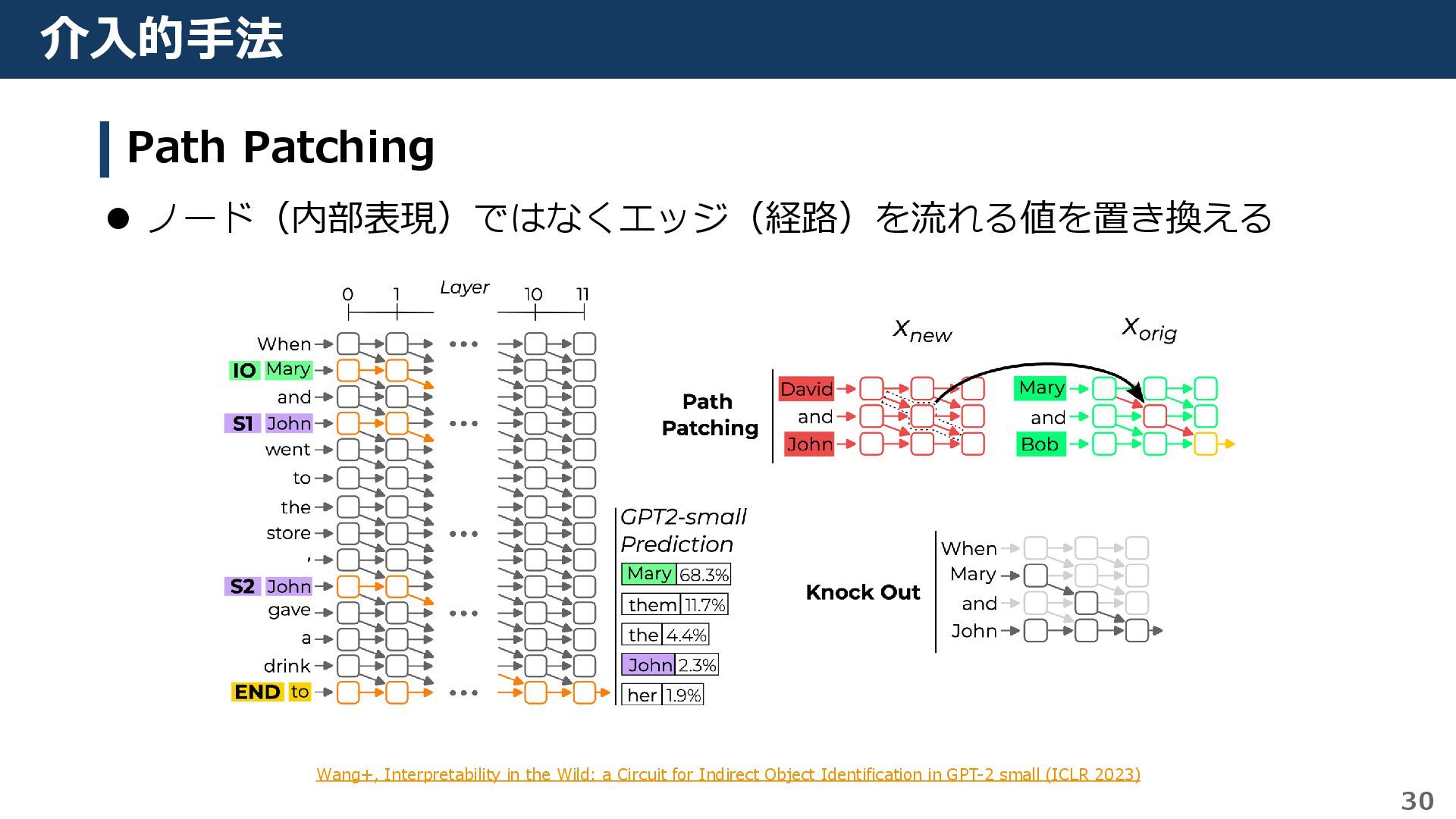{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}