blazing fast search applications – don’t commit all the time – when to use stored fields vs. doc values – maybe Lucene is not the right tool • Understand index size – oh, term vectors are 1/2 of the index size! – I removed 20% of my documents and index size hasn’t changed • This is a lot of fun! Why should I learn about Lucene internals?
it helps – decide on how to index based on the queries • Trade update speed for search speed – Grep vs full-text indexing – Prefix queries vs edge n-grams – Phrase queries vs shingles • Indexing is fast – 220 GB/hour for 4K docs! – http://people.apache.org/~mikemccand/lucenebench/indexing.html Indexing
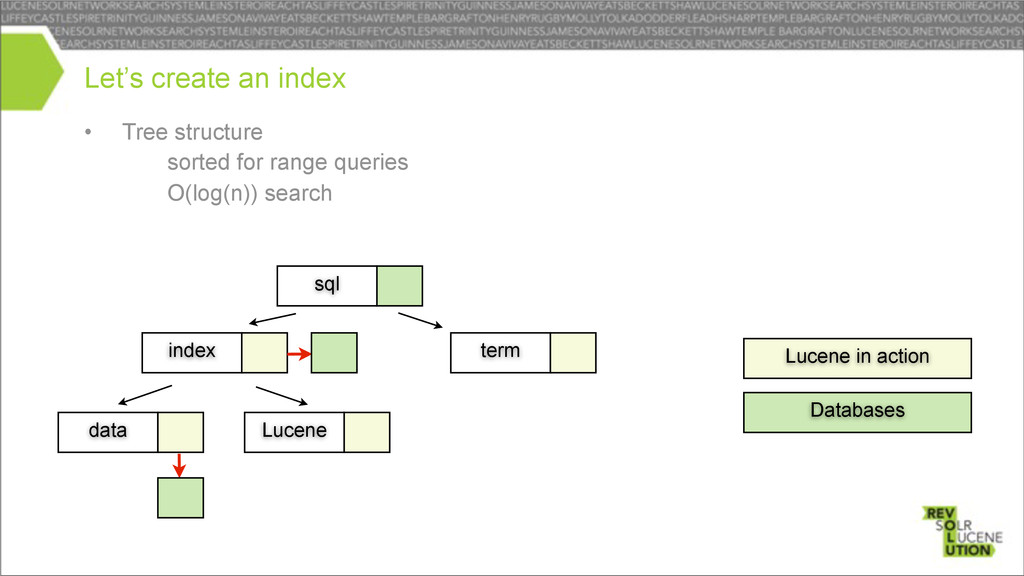
arrays – binary search Another index Lucene in action Databases 0 1 data index 0 1 0,1 0,1 0 0 Segment doc id document term ordinal terms dict postings list sql 4 1
when there are too many of them – concatenate docs, merge terms dicts and postings lists (merge sort!) Insertions? Lucene term 2 3 Lucene in action Databases 0 1 data index 0 1 0,1 0,1 0 sql 4 0 1 Lucene term 2 3 Lucene in action 0 data index 0 1 0 0 0 0 Databases 0 data index 0 1 0 0 sql 2 0
when there are too many of them – concatenate docs, merge terms dicts and postings lists (merge sort!) Insertions? Lucene term 2 3 Lucene in action Databases 0 1 data index 0 1 0,1 0,1 0 sql 4 0 1 Lucene term 2 3 Lucene in action 0 data index 0 1 0 0 0 0 Databases 1 data index 0 1 1 1 sql 2 1
are costly, bulk updates preferred – writes are sequential • Segments are never modified in place – filesystem-cache-friendly – lock-free! • Terms are deduplicated – saves space for high-freq terms • Docs are uniquely identified by an ord – useful for cross-API communication – Lucene can use several indexes in a single query • Terms are uniquely identified by an ord – important for sorting: compare longs, not strings – important for faceting (more on this later) Pros/cons
2, 20, 21, 22, 30, 40, 100 red shoe Many databases just pick the most selective index and ignore the other ones 1 2 3 4 5 6 7 8 9 Lucene’s postings lists support skipping that can be use to “leap-frog”
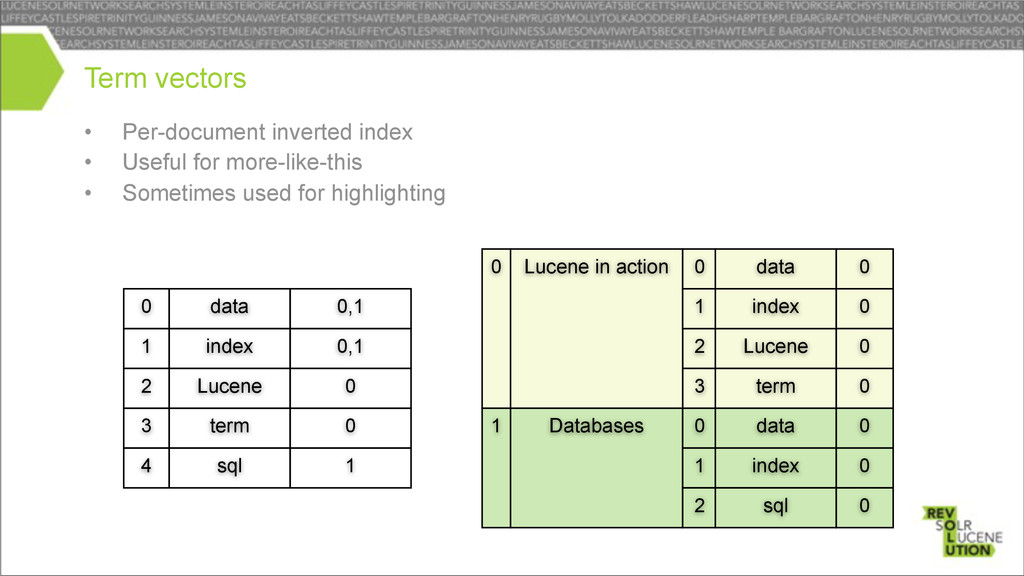
used for highlighting Term vectors Lucene term 2 3 Lucene in action 0 data index 0 1 0 0 0 0 Databases 1 data index 0 1 0 0 sql 2 0 Lucene term 2 3 data index 0 1 0,1 0,1 0 0 sql 4 1
– eg. category counts on an ecommerce website • Naive solution – hash table: value to count – O(#docs) ordinal lookups – O(#doc) value lookups • 2nd solution – hash table: ord to count – resolve values in the end – O(#docs) ordinal lookups – O(#values) value lookups Faceting Since ordinals are dense, this can be a simple array
on top of these APIs: searching, faceting, scoring, highlighting, etc. How can I use these APIs? API Useful for Method Inverted index Term -> doc ids, positions, offsets AtomicReader.fields Stored fields Summaries of search results IndexReader.document Live docs Ignoring deleted docs AtomicReader.liveDocs Term vectors More like this IndexReader.termVectors Doc values / Norms Sorting/faceting/scoring AtomicReader.get*Values
waste of space! – easy to manage thanks to immutability • Stored fields vs doc values – Optimized for different access patterns – get many field values for a few docs: stored fields – get a few field values for many docs: doc values Wrap up 0,A 1,A 2,A 0,A 0,B 0,C 1,A 1,C 2,A 2,B 2,C 1,B 0,B 1,B 2,B 0,B 1,B 2,B Stored fields Doc values At most 1 seek per doc At most 1 seek per doc per field BUT more disk / file-system cache-friendly
field or per doc • Avoid disk seeks whenever possible – disk seek on spinning disk is ~10 ms • BUT don’t ignore the filesystem cache – random access in small files is fine • Light compression helps – less I/O – smaller indexes – filesystem-cache-friendly Important rules
get the best speed for little memory – To trade memory for speed, don’t use RAMDirectory: – MemoryPostingsFormat, MemoryDocValuesFormat, etc. • Detailed file formats available in javadocs – http://lucene.apache.org/core/4_5_1/core/org/apache/lucene/codecs/package- summary.html – Codecs
FST storing terms prefixes – Gives the offset to look at in the terms dictionary – Can fast-fail if no terms have this prefix 1. Terms index l/4 u c r y/3 b/2 r a/1 br = 2 brac = 3 luc = 4 lyr = 7
– compressed based on shared prefixes, similarly to a burst trie – called the “BlockTree terms dict” • read sequentially until the term is found – 2. Terms dictionary [prefix=luc] a, freq=1, offset=101 as, freq=1, offset=149 ene, freq=9, offset=205 ky, frea=7, offset=260 rative, freq=5, offset=323 Jump here Not found Not found Found
• Encoded using modified FOR (Frame of Reference) delta – 1. delta-encode – 2. split into block of N=128 values – 3. bit packing per block – 4. if remaining docs, encode with vInt 3. Postings lists 1,3,4,6,8,20,22,26,30,31 1,2,1,2,2,12,2,4,4,1 [1,2,1,2] [2,12,2,4] 4, 1 2 bits per value 4 bits per value Example with N=4 vInt-encoded
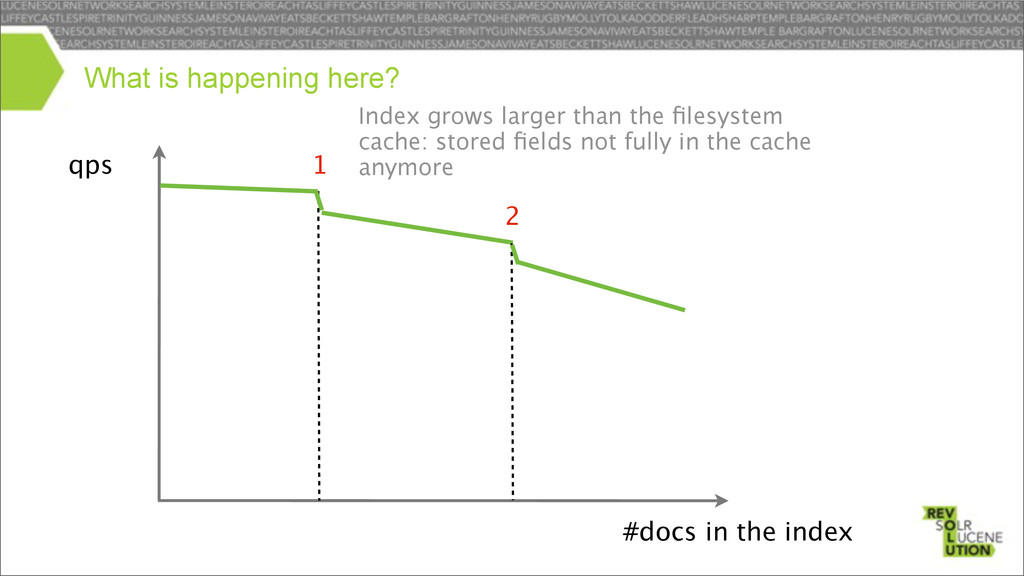
disk seek per doc for stored fields • It is common that the terms dict / postings lists fits into the file-system cache • “Pulse” optimization – For unique terms (freq=1), postings are inlined in the terms dict – Only 1 disk seek – Will always be used for your primary keys Query execution
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}