One of the ways to get a solid understanding of operating systems is to write one, from scratch. This is what Vlad has been doing in his free time since 2016. It all started as an experiment to see what would it take to write an OS that could just “run a shell” and learn a bit of x86 hardware, kernels and bootloaders in the meanwhile. A few months later, he decided that it would be super cool if his toy-kernel could run natively i686-linux programs and that opened Pandora’s box: being binary-compatible with Linux and running non-trivial 3rd-party apps introduced plenty of unexpected challenges. Fast forward a few years, Tilck can now boot on both BIOS and UEFI machines (using its own bootloader or GRUB), run Busybox, Vim, fbDOOM, Micropython and several other console applications compiled for i686-linux with a gcc-musl toolchain.
This talk is about the story of how the Tilck kernel and its bootloader went from “Hello world” to where it is today, with focus on some of the most interesting challenges and subtle bugs its author had to go through.
Vlasdislav K. Valtchev, VmWare
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![My latest bug [1/6] I have a test (fork_oom)](https://files.speakerdeck.com/presentations/3c4bc1a0fbb64b2c92c95db9a6a60ca5/slide_7.jpg){kind=link}
![My latest bug [1/6] I have a test (fork_oom)](https://files.speakerdeck.com/presentations/3c4bc1a0fbb64b2c92c95db9a6a60ca5/slide_8.jpg){kind=link}
![My latest bug [1/6] I have a test (fork_oom)](https://files.speakerdeck.com/presentations/3c4bc1a0fbb64b2c92c95db9a6a60ca5/slide_9.jpg){kind=link}
![My latest bug [1/6] I have a test (fork_oom)](https://files.speakerdeck.com/presentations/3c4bc1a0fbb64b2c92c95db9a6a60ca5/slide_10.jpg){kind=link}
![My latest bug [2/6] Vladislav K. Valtchev (2022) That’s fine…](https://files.speakerdeck.com/presentations/3c4bc1a0fbb64b2c92c95db9a6a60ca5/slide_11.jpg){kind=link}
![My latest bug [3/6] Vladislav K. Valtchev (2022) So, I](https://files.speakerdeck.com/presentations/3c4bc1a0fbb64b2c92c95db9a6a60ca5/slide_12.jpg){kind=link}
![My latest bug [4/6] Vladislav K. Valtchev (2022) I realized](https://files.speakerdeck.com/presentations/3c4bc1a0fbb64b2c92c95db9a6a60ca5/slide_13.jpg){kind=link}
![My latest bug [5/6] Vladislav K. Valtchev (2022) Let’s look](https://files.speakerdeck.com/presentations/3c4bc1a0fbb64b2c92c95db9a6a60ca5/slide_14.jpg){kind=link}
![My latest bug [6/6] Vladislav K. Valtchev (2022) That means](https://files.speakerdeck.com/presentations/3c4bc1a0fbb64b2c92c95db9a6a60ca5/slide_15.jpg){kind=link}
![My latest bug [6/6] Vladislav K. Valtchev (2022) That means](https://files.speakerdeck.com/presentations/3c4bc1a0fbb64b2c92c95db9a6a60ca5/slide_16.jpg){kind=link}
![My latest bug [6/6] Vladislav K. Valtchev (2022) That means](https://files.speakerdeck.com/presentations/3c4bc1a0fbb64b2c92c95db9a6a60ca5/slide_17.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![The FPU code [1/2] Vladislav K. Valtchev (2022)](https://files.speakerdeck.com/presentations/3c4bc1a0fbb64b2c92c95db9a6a60ca5/slide_38.jpg){kind=link}
![The FPU code [2/2] Vladislav K. Valtchev (2022)](https://files.speakerdeck.com/presentations/3c4bc1a0fbb64b2c92c95db9a6a60ca5/slide_39.jpg){kind=link}
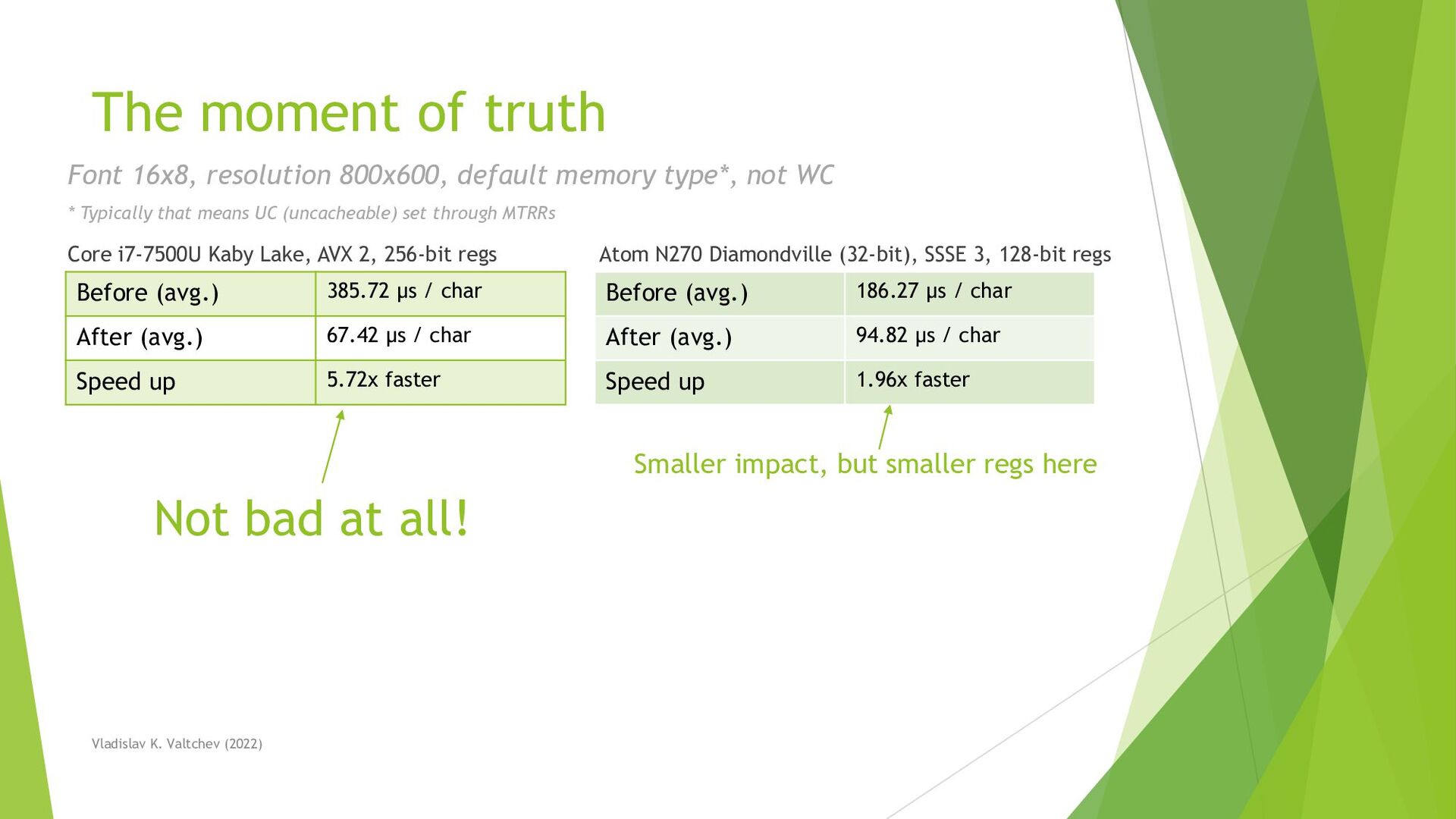{kind=link}
{kind=link}
{kind=link}
![Performance: the full picture [modern machine] Vladislav K. Valtchev (2022)](https://files.speakerdeck.com/presentations/3c4bc1a0fbb64b2c92c95db9a6a60ca5/slide_43.jpg){kind=link}
![Performance: the full picture [older machine] Vladislav K. Valtchev (2022)](https://files.speakerdeck.com/presentations/3c4bc1a0fbb64b2c92c95db9a6a60ca5/slide_44.jpg){kind=link}
![Performance on native res [modern machine] Vladislav K. Valtchev (2022)](https://files.speakerdeck.com/presentations/3c4bc1a0fbb64b2c92c95db9a6a60ca5/slide_45.jpg){kind=link}
![Performance vs Linux [modern machine] Vladislav K. Valtchev (2022) Font](https://files.speakerdeck.com/presentations/3c4bc1a0fbb64b2c92c95db9a6a60ca5/slide_46.jpg){kind=link}
![Performance vs Linux [modern machine] 9.55 μs / char](https://files.speakerdeck.com/presentations/3c4bc1a0fbb64b2c92c95db9a6a60ca5/slide_47.jpg){kind=link}
![Performance vs Linux [modern machine] 9.55 μs / char](https://files.speakerdeck.com/presentations/3c4bc1a0fbb64b2c92c95db9a6a60ca5/slide_48.jpg){kind=link}
![Performance vs Linux [modern machine] 9.55 μs / char](https://files.speakerdeck.com/presentations/3c4bc1a0fbb64b2c92c95db9a6a60ca5/slide_49.jpg){kind=link}
![Performance vs Linux [modern machine] Vladislav K. Valtchev (2022) Font](https://files.speakerdeck.com/presentations/3c4bc1a0fbb64b2c92c95db9a6a60ca5/slide_50.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
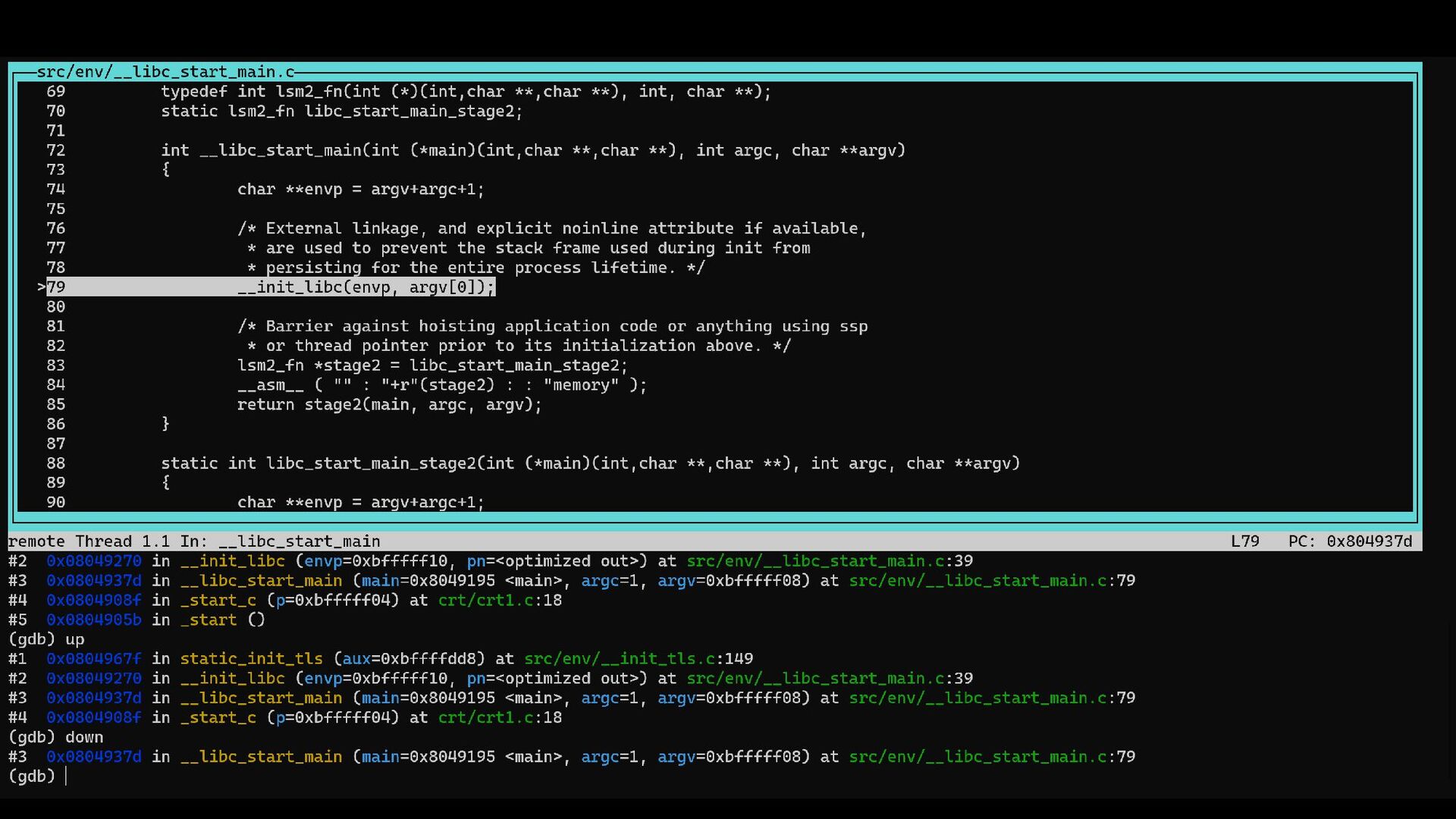{kind=link}
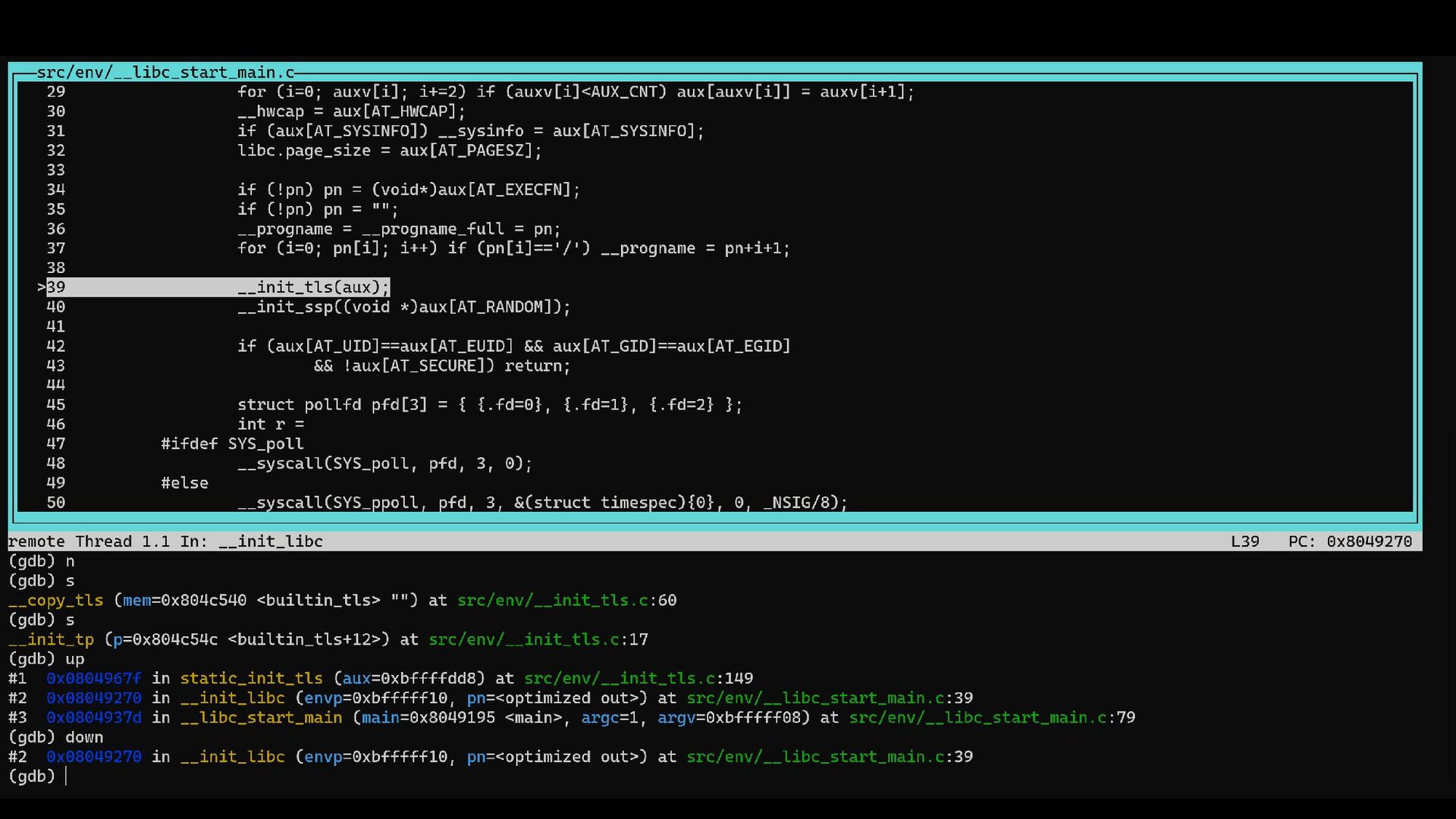{kind=link}
{kind=link}
{kind=link}
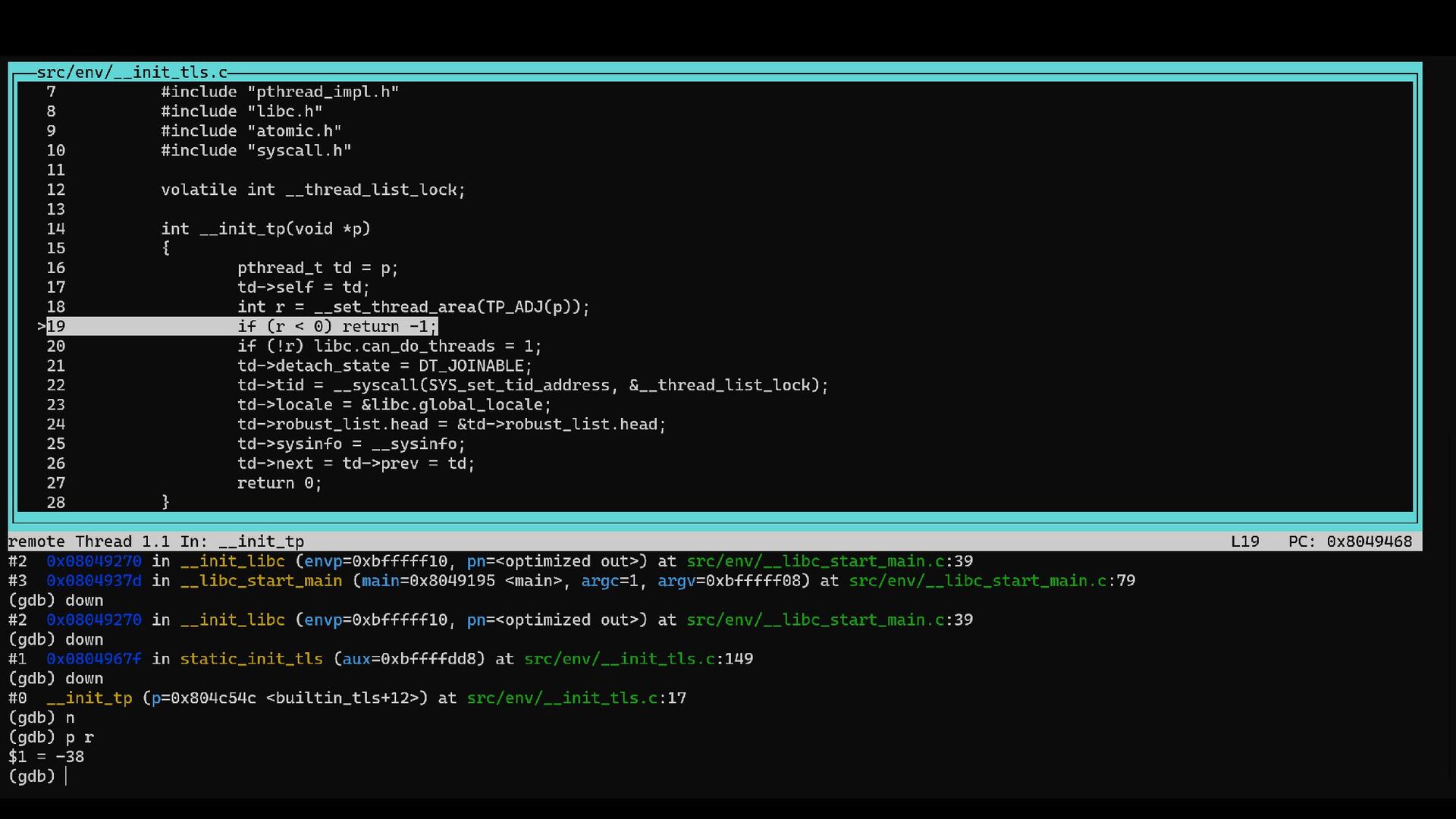{kind=link}
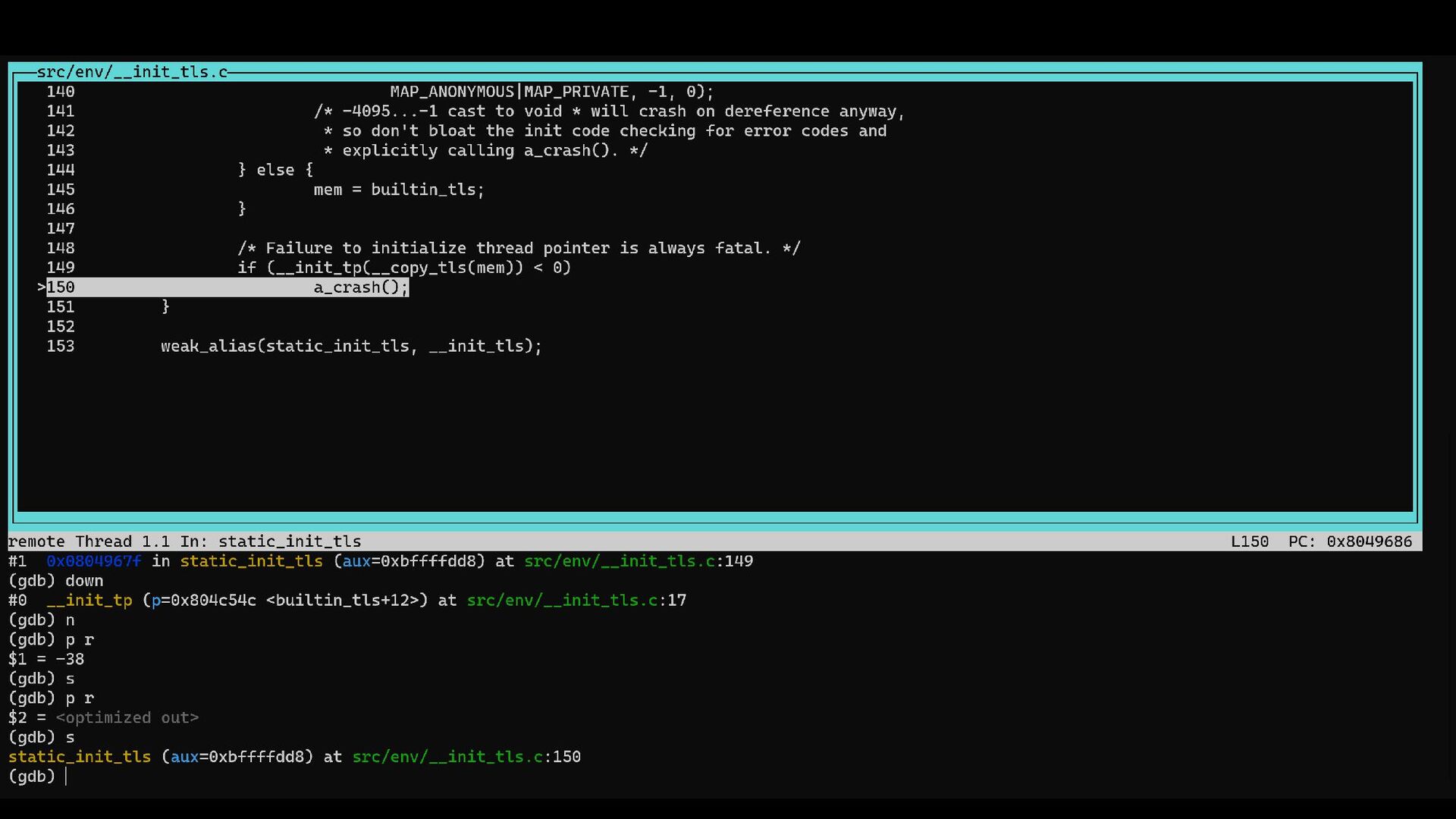{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
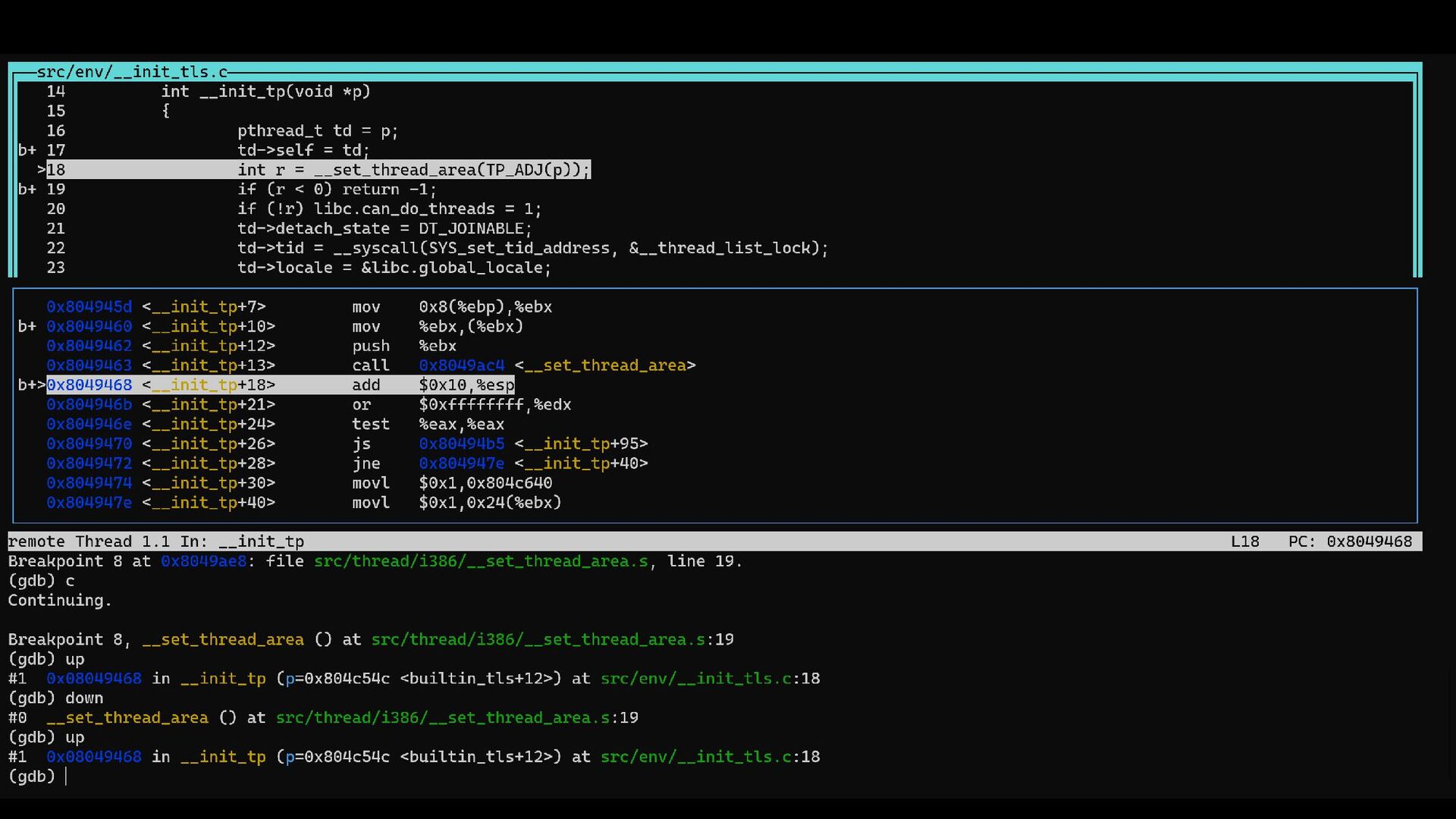{kind=link}
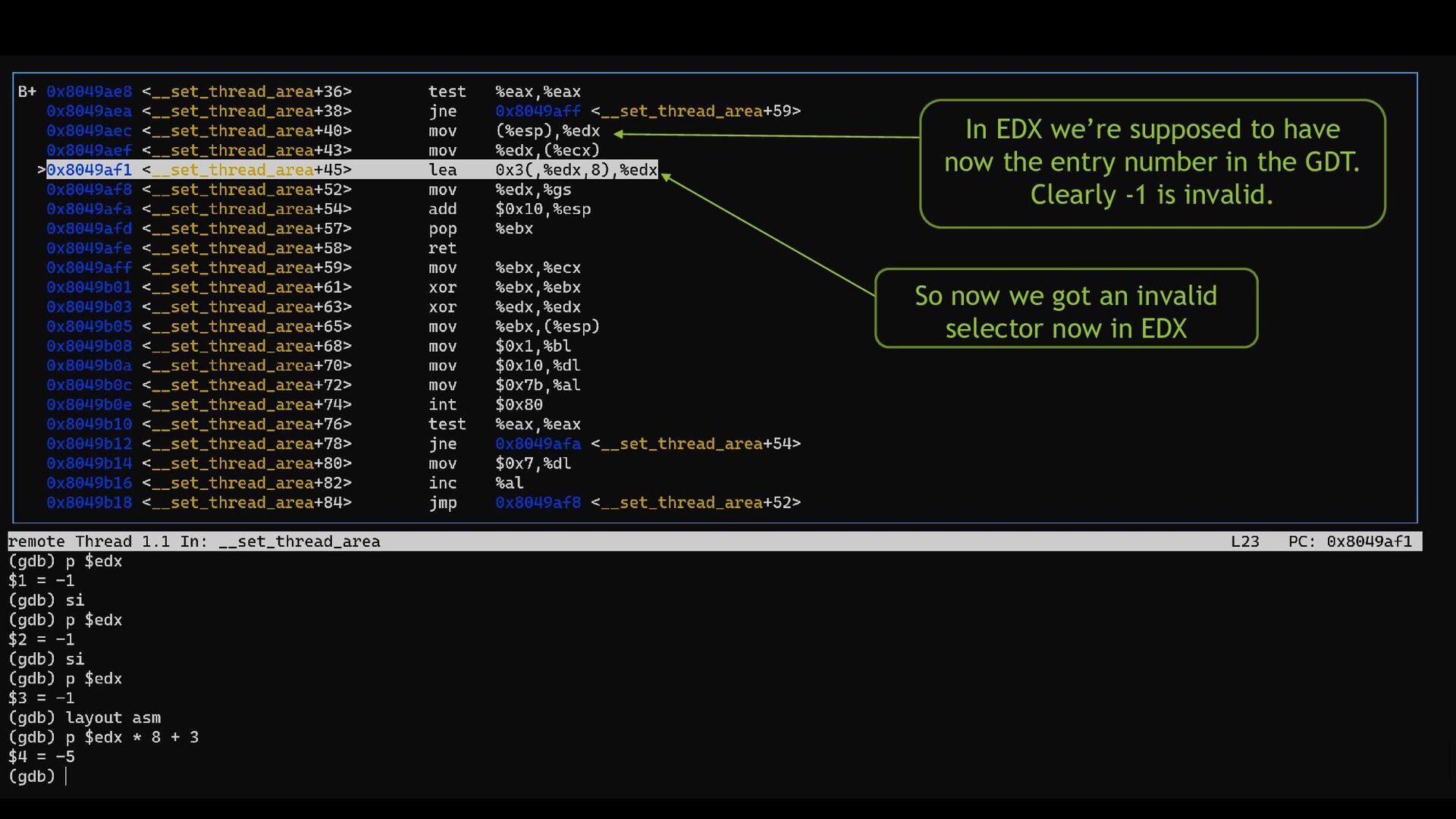{kind=link}
{kind=link}
{kind=link}
{kind=link}
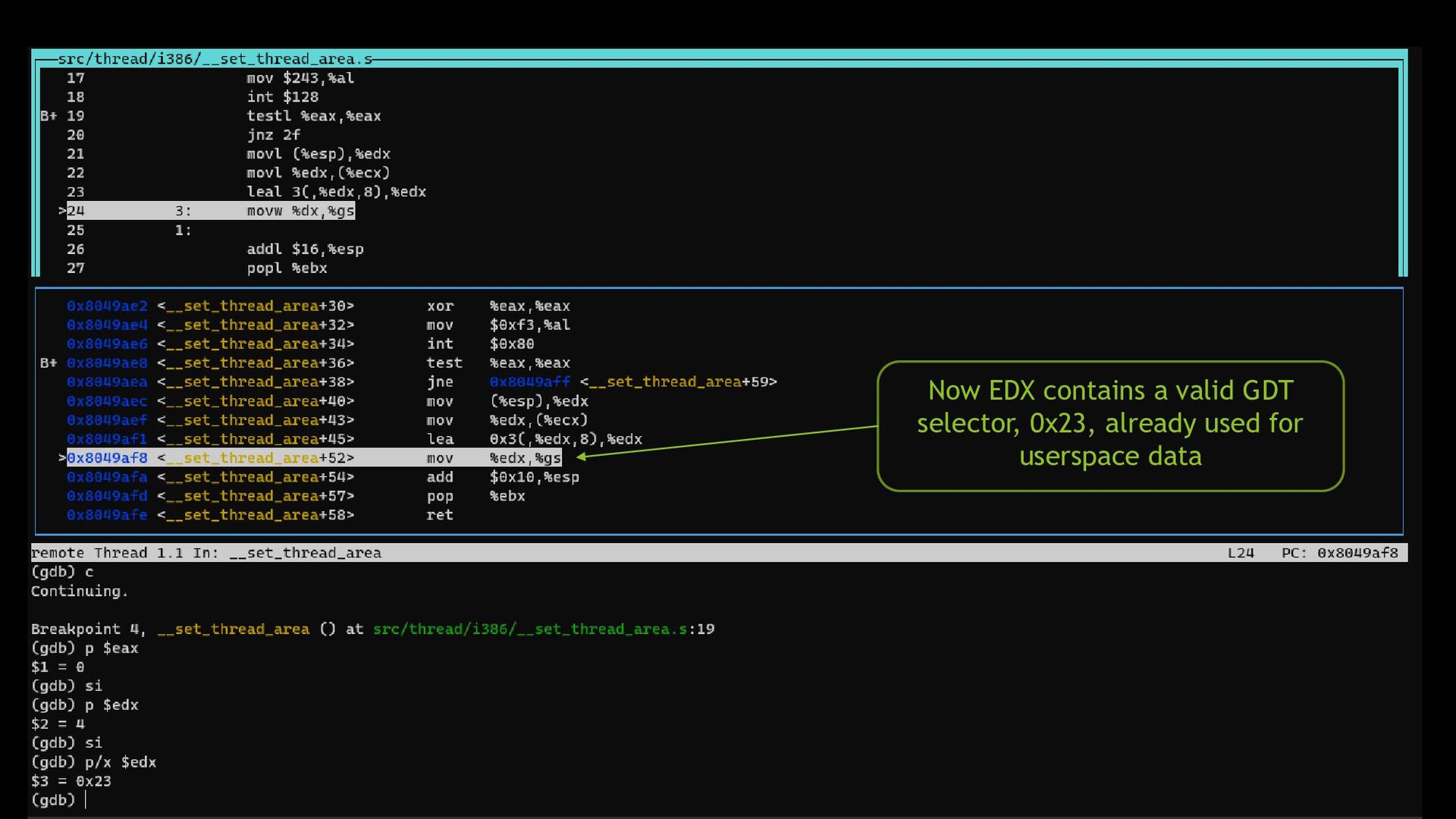{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Classic semaphore New semaphore [1/2] Vladislav K. Valtchev (2022)](https://files.speakerdeck.com/presentations/3c4bc1a0fbb64b2c92c95db9a6a60ca5/slide_85.jpg){kind=link}
![Classic semaphore New semaphore [2/2] Vladislav K. Valtchev (2022)](https://files.speakerdeck.com/presentations/3c4bc1a0fbb64b2c92c95db9a6a60ca5/slide_86.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}