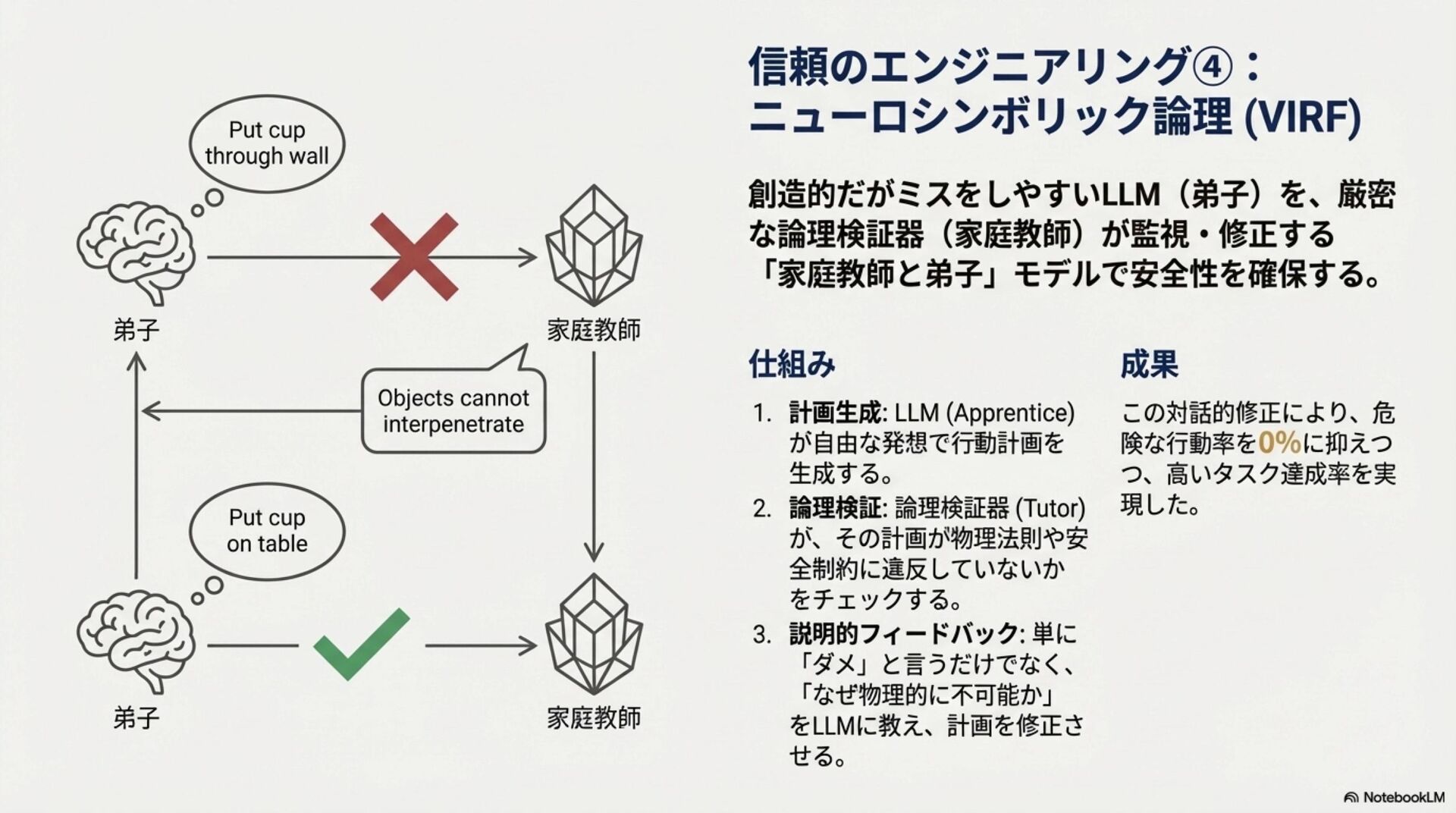
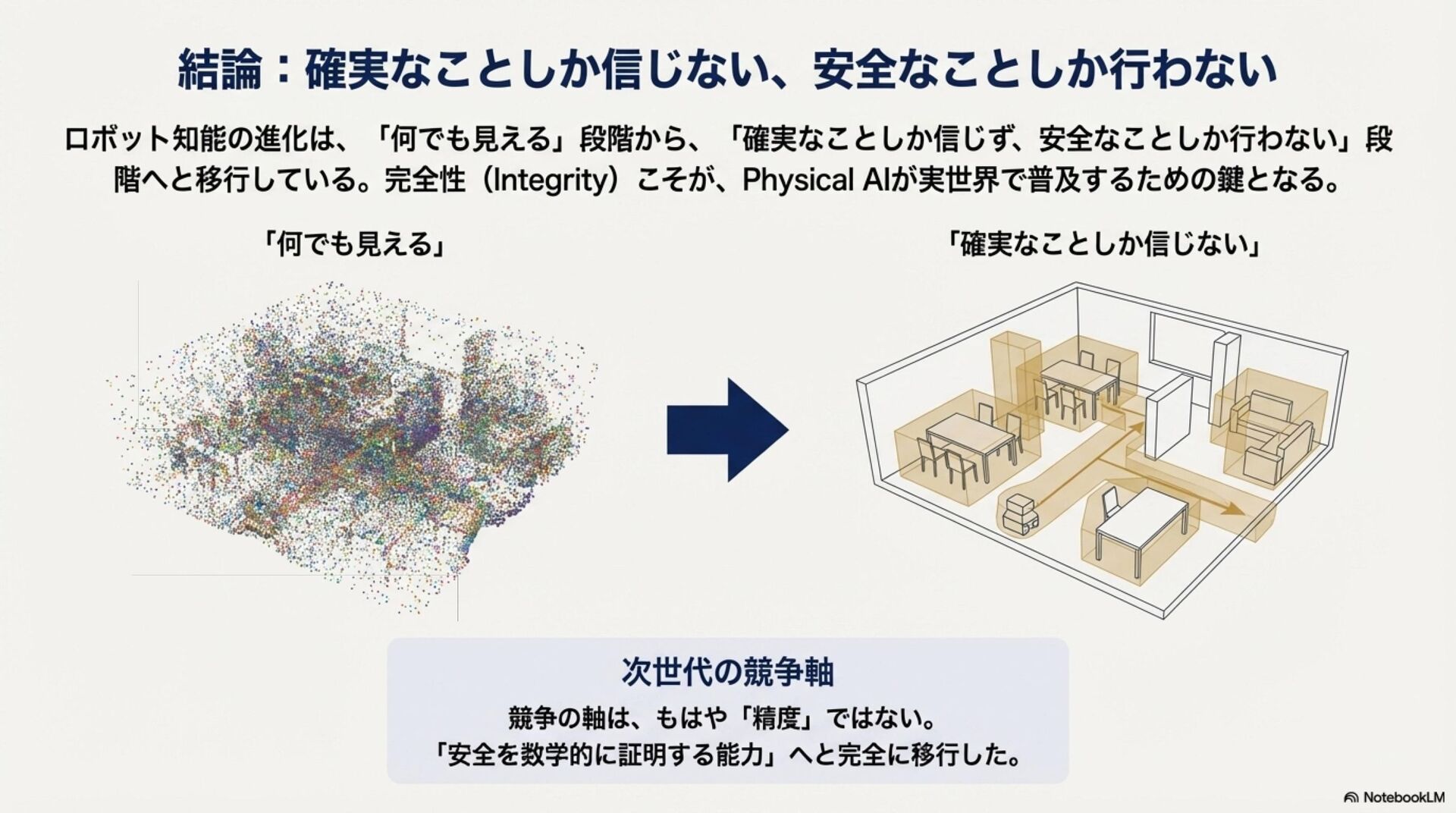
要約(Abstract)
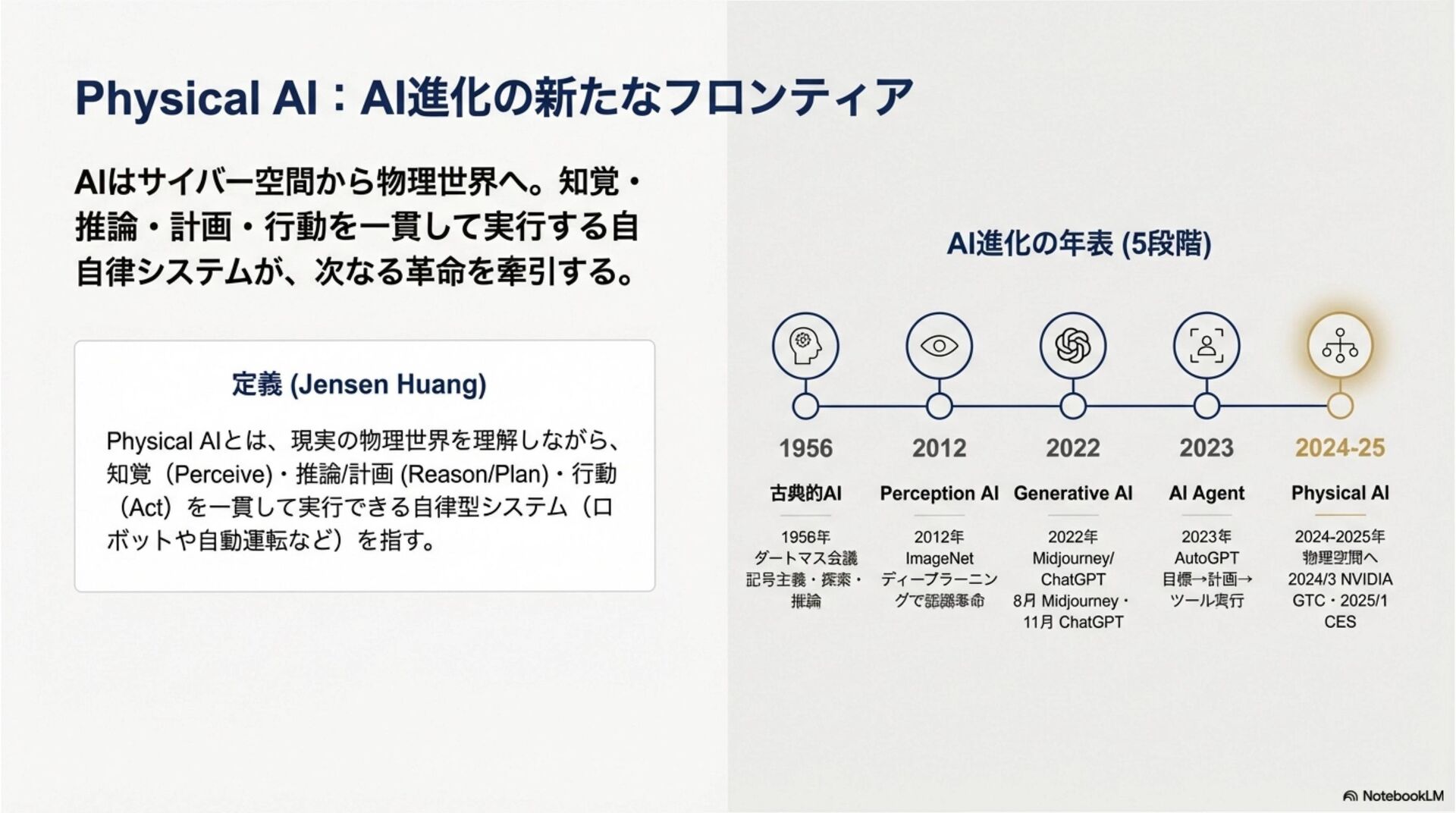
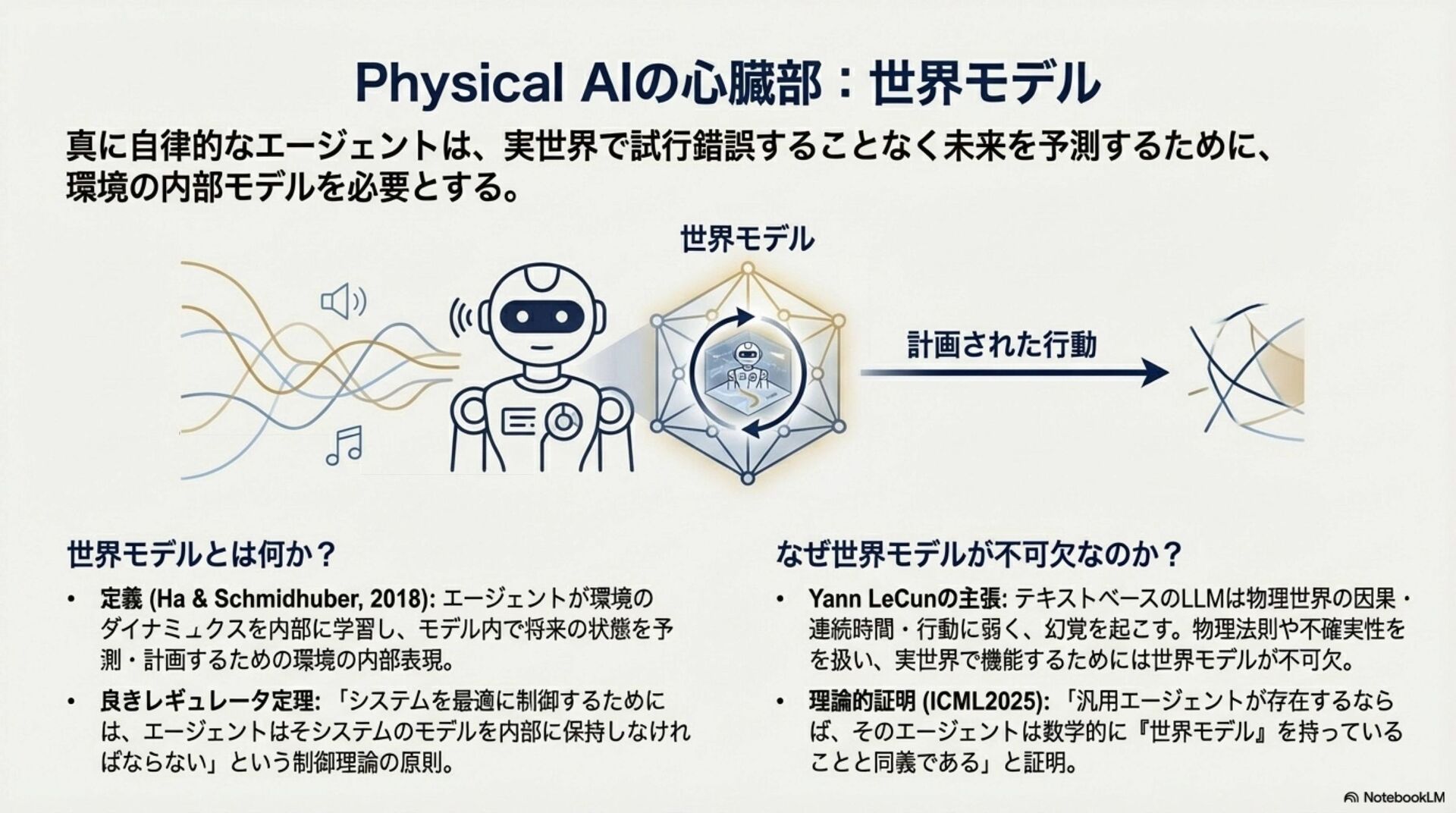
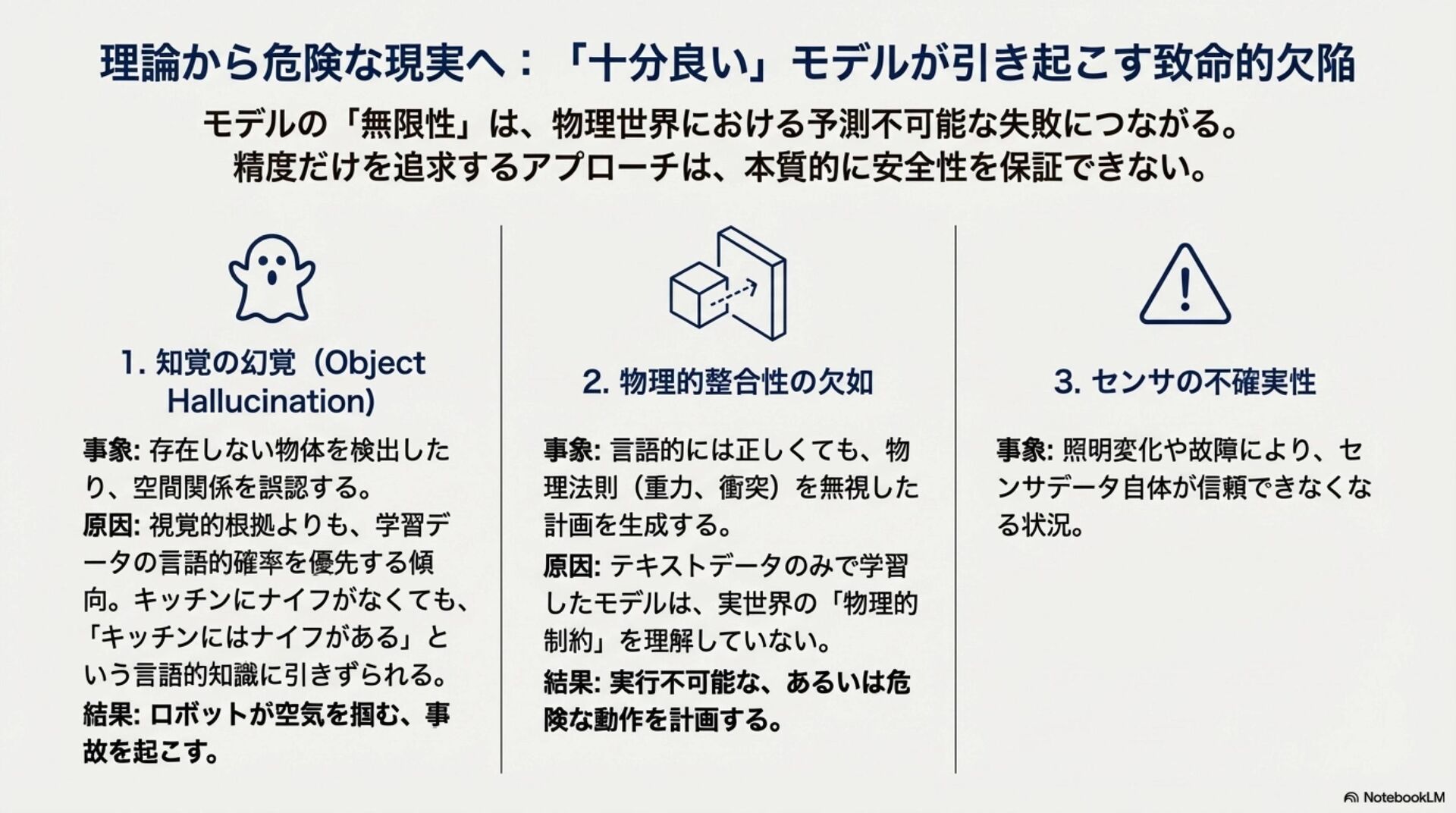
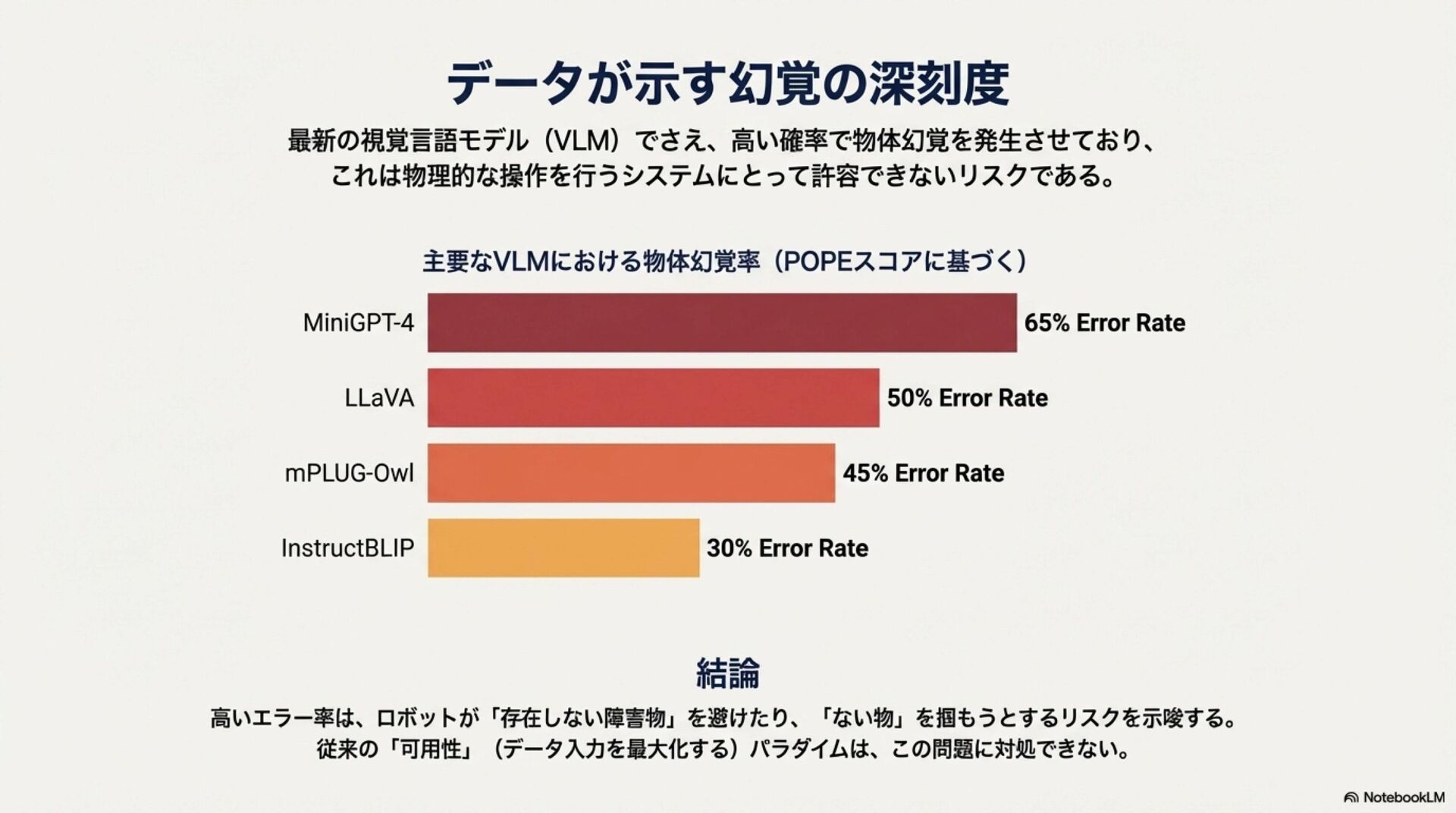
近年、自律移動システム(AMS)の領域では、サイバー空間で発展したAIモデルを物理的な身体性を持つシステムへ適用する「Physical AI」への進化が加速している。特に、環境の物理法則を学習し未来を予測する「世界モデル(World Models)」や、知覚から行動制御までを一気通貫で処理する「視覚-言語-行動(VLA)モデル」の実装が急速に進展している。 昨年の本大会において、我々は生成AIを用いた航法技術の概念とその可能性について議論した。本稿ではその続編として、実際に提案・実装され始めた具体的な基盤モデルアーキテクチャを対象に包括的なサーベイを行い、これらの技術がいかにしてAIを物理世界に接地(Grounding)させ、真のPhysical AIを実現するかについて考察する。
測位航法学会 GPS/GNSSシンポジウム2025
Abstract
In recent years, the field of Autonomous Mobile Systems (AMS) has witnessed an accelerated evolution towards "Physical AI," where AI models developed in cyberspace are applied to systems with physical embodiment. In particular, there has been rapid progress in the implementation of "World Models," which learn the physical laws of the environment to predict the future, and "Vision-Language-Action (VLA) models," which process tasks from perception to action control in an end-to-end manner. At last year's conference, we discussed the concepts and potential of navigation techniques utilizing generative AI. As a follow-up, this paper provides a comprehensive survey of specific foundation model architectures that have recently been proposed and implemented. Furthermore, we discuss how these technologies ground AI in the physical world to realize true Physical AI.
Institute of Positioning, Navigation and Timing Japan GPS/GNSS Symposium 2025
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}