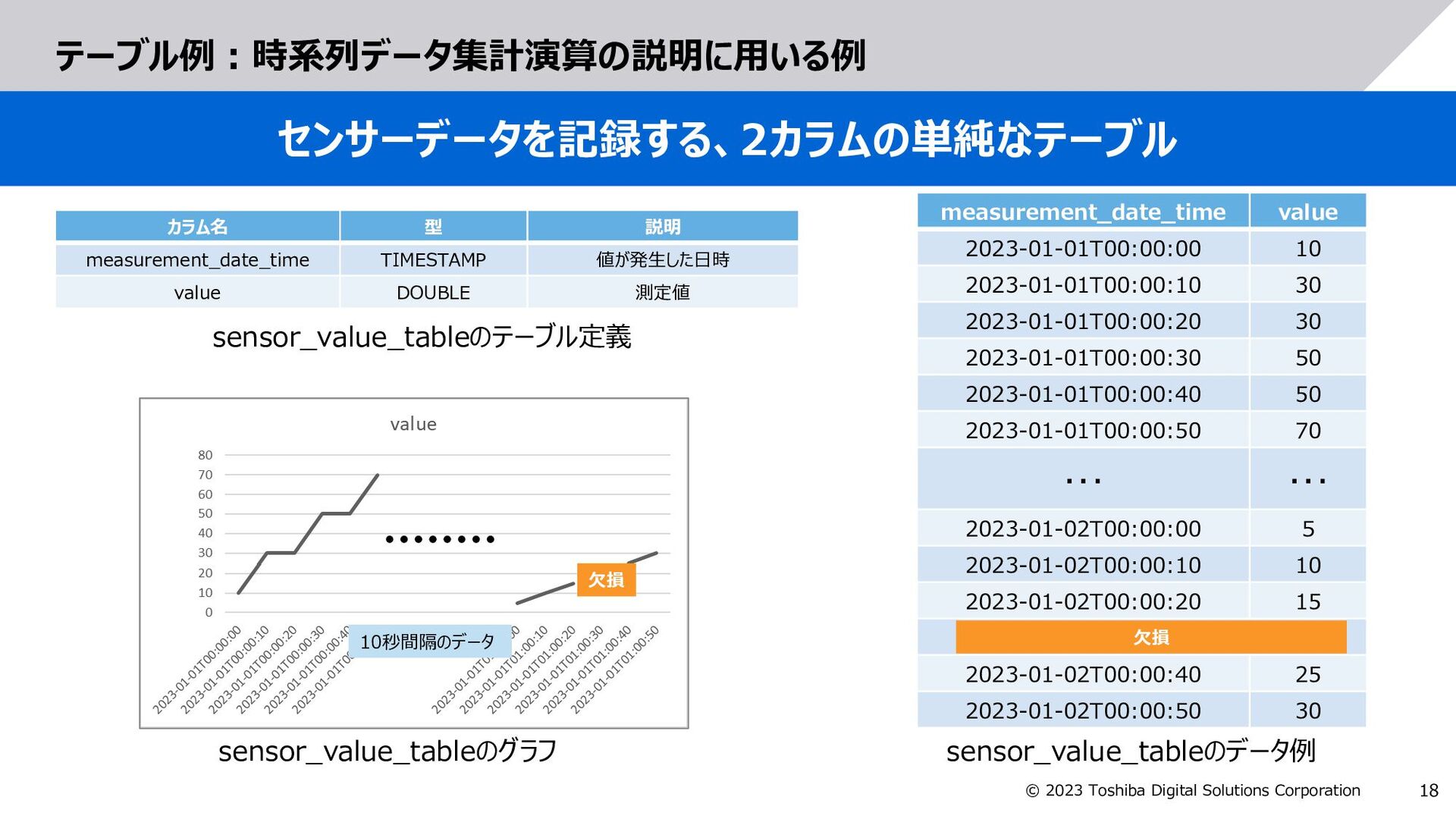
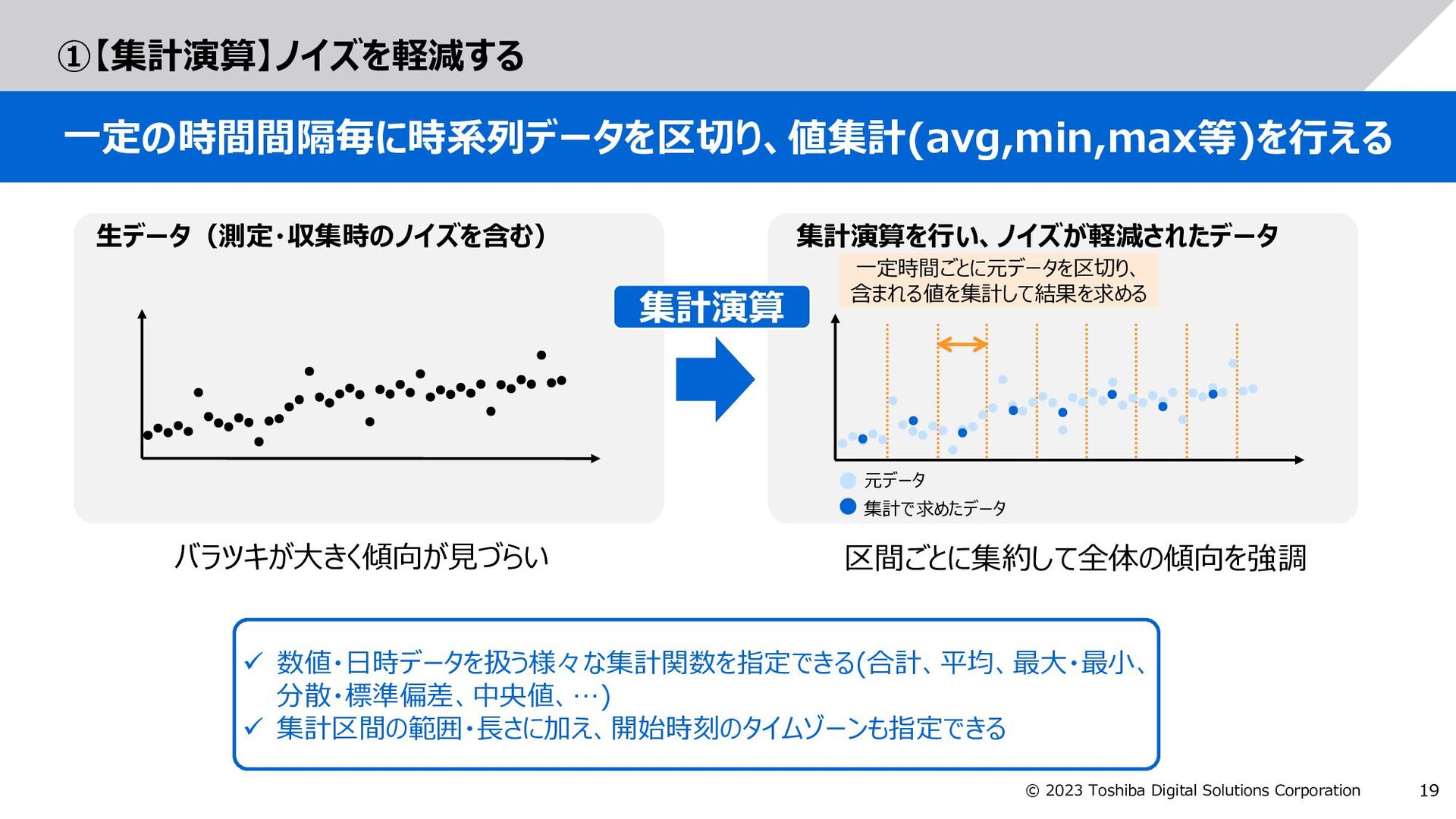
GridDBで拡張した以下の構文により、集計する日時範囲を指定 measurement_date_time value 2023-01-01T00:00:00 10 2023-01-01T00:00:10 30 2023-01-01T00:00:20 30 2023-01-01T00:00:30 50 2023-01-01T00:00:40 50 2023-01-01T00:00:50 70 measurement_date_time value 2023-01-01T00:00:00 20 2023-01-01T00:00:20 40 2023-01-01T00:00:40 60 SELECT measurement_date_time, avg(value) as value FROM sensor_value_table WHERE measurement_date_time BETWEEN TIMESTAMP('2023-01-01T:00:00:00Z') AND TIMESTAMP('2023-01-01T:00:01:00Z') GROUP BY RANGE measurement_date_time EVERY (20, SECOND) 【例】元データ(sensor_value_table)の値を、measurement_date_timeの日時を基準に 20秒間隔で区切り、それぞれの平均値を求めるSQL 20秒ごとの値に集計 GROUP BY RANGE <日時カラム> EVERY (<時区間の長さ(整数)>, <単位>) 集計演算
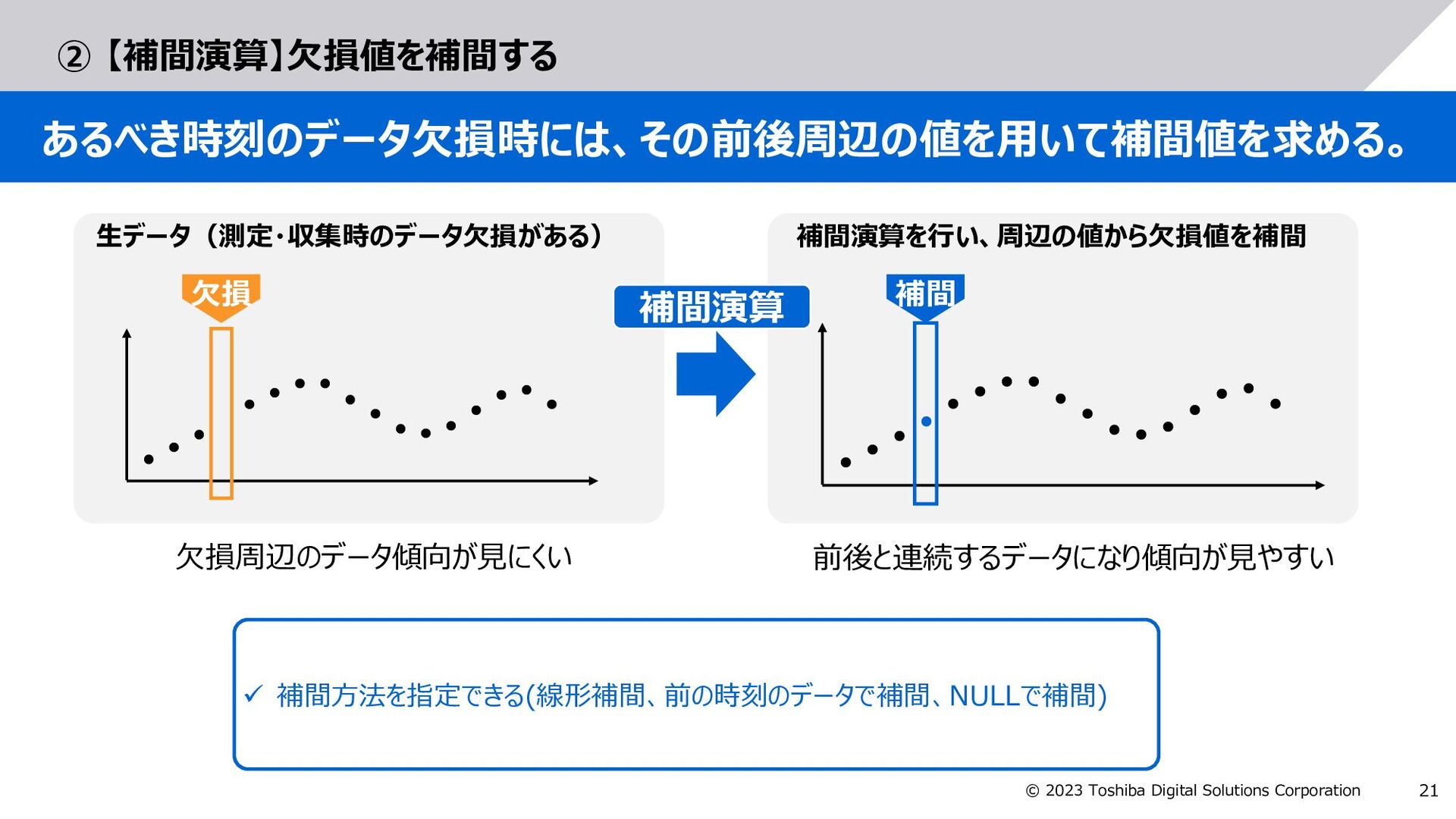
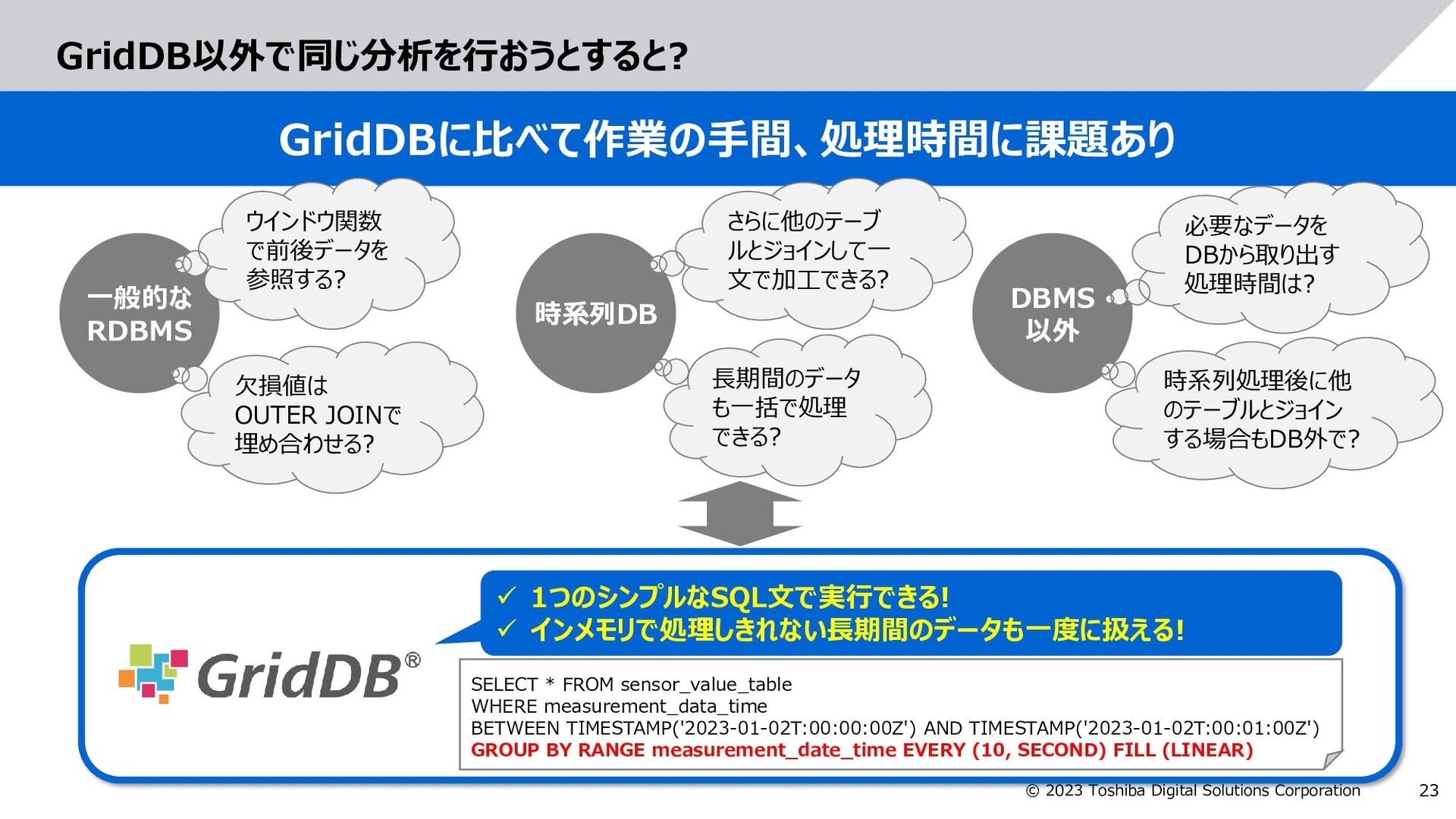
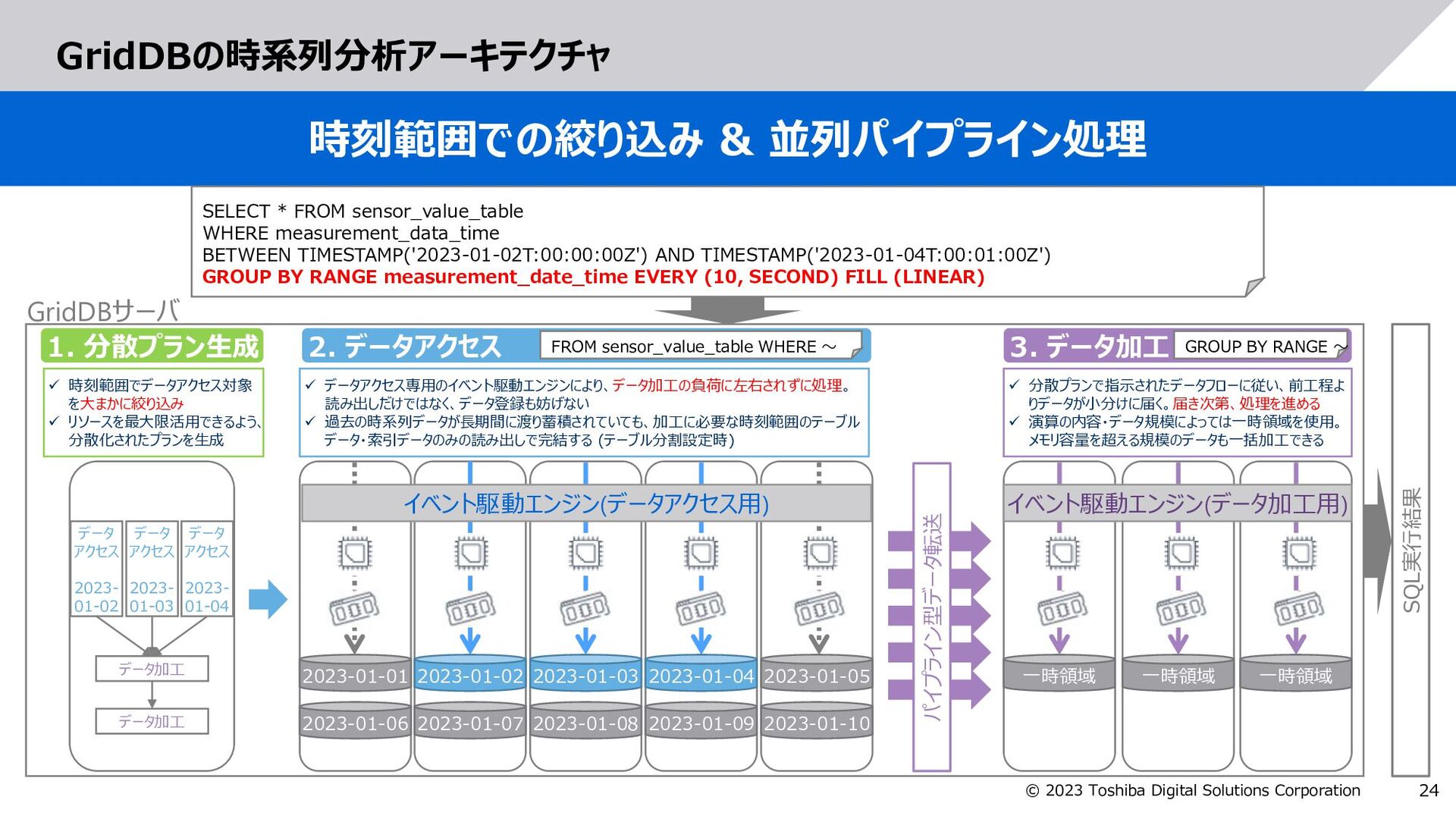
GridDBで拡張した以下の構文により、集計する日時範囲を指定 GROUP BY RANGE 日時カラム EVERY (整数,時刻単位) FILL (補間方法) measurement_date_time value 2023-01-02T00:00:00 5 2023-01-02T00:00:10 10 2023-01-02T00:00:20 15 (欠損) 2023-01-02T00:00:40 25 2023-01-02T00:00:50 30 measurement_date_time value 2023-01-02T00:00:00 5 2023-01-02T00:00:10 10 2023-01-02T00:00:20 15 2023-01-02T00:00:30 20 2023-01-02T00:00:40 25 2023-01-02T00:00:50 30 SELECT * FROM sensor_value_table WHERE measurement_data_time BETWEEN TIMESTAMP('2023-01-02T:00:00:00Z') AND TIMESTAMP('2023-01-02T:00:01:00Z') GROUP BY RANGE measurement_date_time EVERY (10, SECOND) FILL (LINEAR) 【例】元データ(sensor_value_table)の値を、measurement_date_timeの日時を基準にして、 10秒間隔の値を求め、欠損している場合は前後の値から線形補間した値を求めるSQL 補間 補間演算
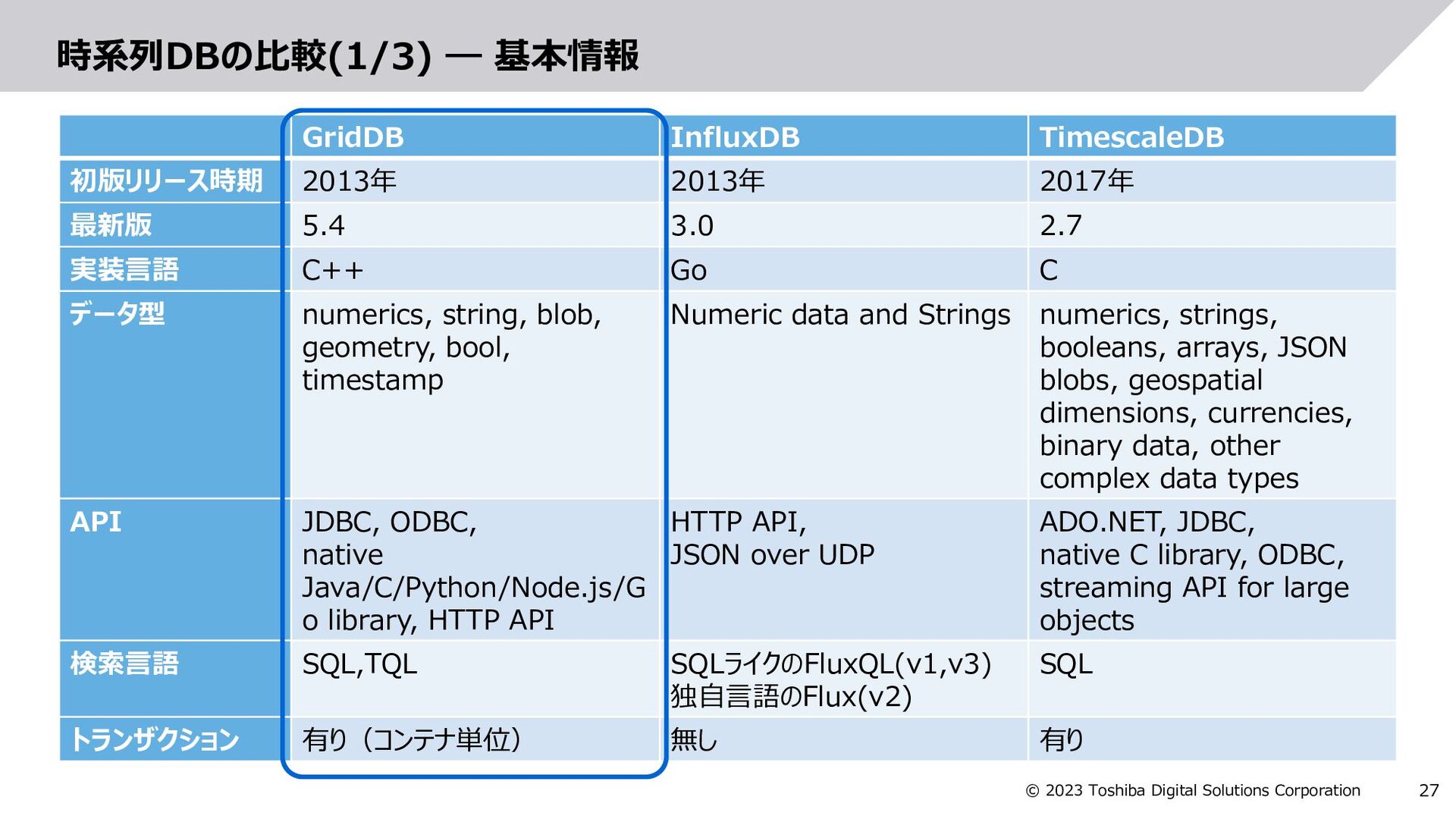
GridDB InfluxDB TimescaleDB 初版リリース時期 2013年 2013年 2017年 最新版 5.4 3.0 2.7 実装言語 C++ Go C データ型 numerics, string, blob, geometry, bool, timestamp Numeric data and Strings numerics, strings, booleans, arrays, JSON blobs, geospatial dimensions, currencies, binary data, other complex data types API JDBC, ODBC, native Java/C/Python/Node.js/G o library, HTTP API HTTP API, JSON over UDP ADO.NET, JDBC, native C library, ODBC, streaming API for large objects 検索言語 SQL,TQL SQLライクのFluxQL(v1,v3) 独自言語のFlux(v2) SQL トランザクション 有り(コンテナ単位) 無し 有り
time, avg(val) FROM table1 WHERE time >= TIMESTAMP('2023-01-01T00:00:00Z') AND time < TIMESTAMP('2023-01-01T01:00:00Z') GROUP BY RANGE (time) EVERY (1, MINUTE) (SQL拡張) SELECT time_bucket('1 minute', time) AS bucket, avg(val) row_avg FROM table1 WHERE time >= TIMESTAMPTZ '2023-01-01 00:00:00' AND time < TIMESTAMPTZ '2023-01-01 01:00:00' GROUP BY bucket • GridDB • TimescaleDB (FluxQL) SELECT mean(val) FROM table1 WHERE time >= '2023-01-01T00:00:00Z' AND time < '2023-01-01T01:00:00Z' GROUP BY TIME(1m) • InfluxDB (v1/v3) (Flux) from(bucket: "table1") |> range(start:2023-01-01T00:00:00Z, stop:2023-01-01T01:00:00Z) |> aggregateWindow(every: 1m, fn: mean) • InfluxDB (v2)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}