S., Sanyal, S., and Kanbour, Y.: Evaluating the Diagnostic Performance of Symptom Checkers: Clinical Vignette Study, JMIR AI, Vol. 3, p. e46875 (2024) 2. Ding, Y., Zeng, Q., and Weninger, T.: ChatEL: Entity Linking with Chatbots, arXiv [cs.CL] (2024) 3. French, E. and McInnes, B. T.: An overview of biomedical entity linking throughout the years, J. Biomed. Inform., Vol. 137, No. 104252, p. 104252 (2023) 4. Li, M. and Zhang, R.: How far is Language Model from 100% Few-shot Named Entity Recognition in Med- ical Domain, arXiv [cs.CL] (2023) 5. Miller, R. A., McNeil, M. A., Challinor, S. M., Masarie, F. E., Jr, and Myers, J. D.: The INTERNIST- 1/QUICK MEDICAL REFERENCE project–status re- port, West. J. Med., Vol. 145, No. 6, pp. 816–822 (1986) 6. Wang, S., Sun, X., Li, X., Ouyang, R., Wu, F., Zhang, T., Li, J., and Wang, G.: GPT-NER: Named Entity Recognition via Large Language Models, arXiv [cs.CL] (2023) 7. Xu, L., Zhou, Q., Gong, K., Liang, X., Tang, J., and Lin, L.: End-to-End Knowledge-routed Relational Dialogue System for automatic diagnosis, Proc. Conf. AAAI Artif. Intell., Vol. 33, No. 01, pp. 7346–7353 (2019) 8. Zou, X., He, W., Huang, Y., Ouyang, Y., Zhang, Z., Wu, Y., Wu, Y., Feng, L., Wu, S., Yang, M., Chen, X., Zheng, Y., Jiang, R., and Chen, T.: AI-driven diagnostic assistance in medical inquiry: Reinforcement learning algorithm development and validation, J. Med. Internet Res., Vol. 26, p. e54616 (2024) 9. ࢁஐ߂, ࣲాେ࡞, Ӊ༟, ⁋߶ൣ, ग़༞, ٱอ խ༸, ాॡଠ, एٶᠳࢠ, ߥӳ࣏:ੜϞσϧҩྍ ς Ωετͷݻ༗දݱநग़ʹ͑Δ͔?, ݴޠॲཧֶձ࣍େ ձൃදจू (Web), Vol. 30th, pp. 11–11 (2024)
![[1O4-OS-18a-04] அલͷපྺςΩετΛରͱͨ͠ LLMʹΑΔΤϯςΟςΟϦϯΩϯάਫ਼ݕূ ʓྛ ɺଠా ຬٱɺ෩ؒ ਖ਼߂ (Ubieגࣜձࣾ) 2025-05-27 ਓೳֶձશࠃେձ](https://files.speakerdeck.com/presentations/579215aebdd14832ba9af26c6fefabcf/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
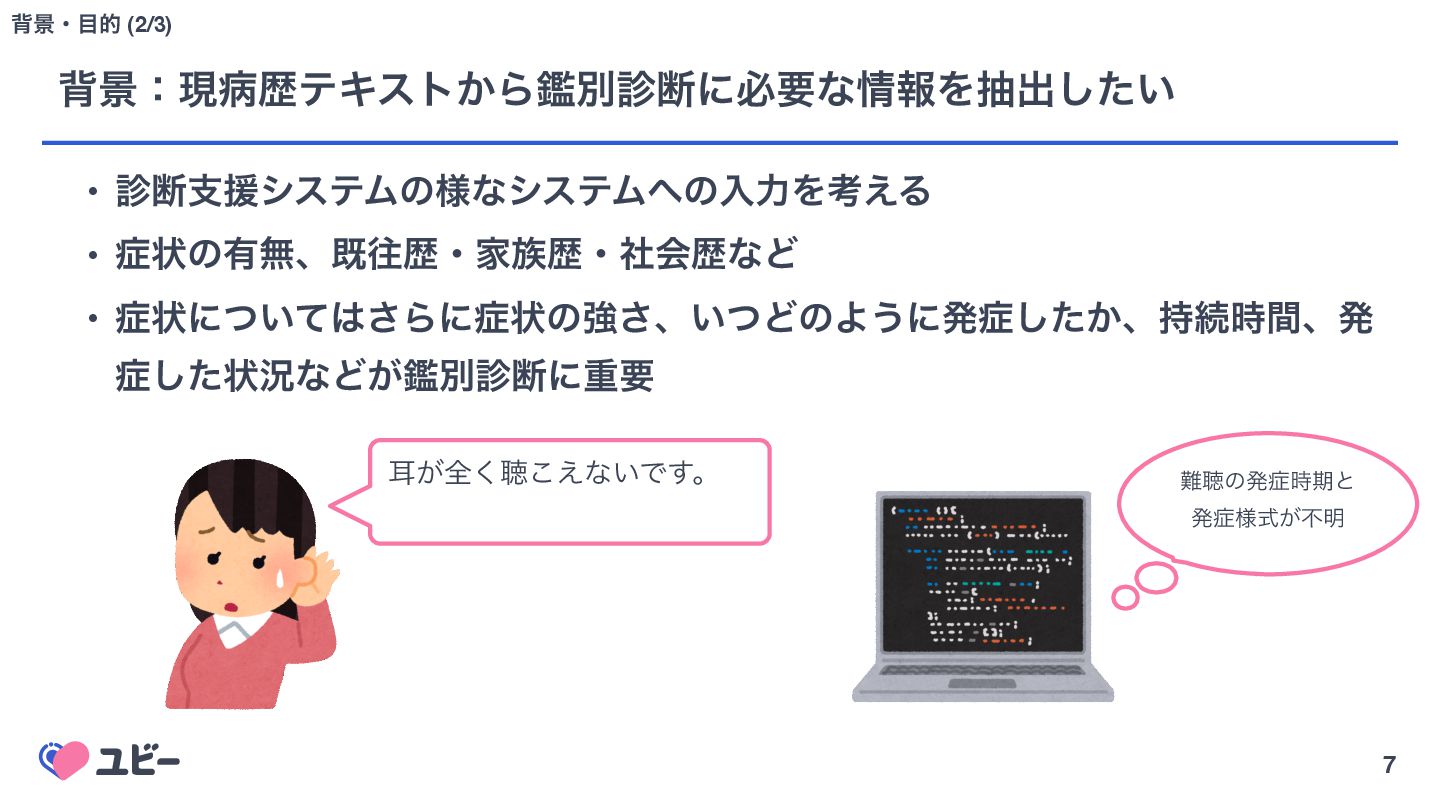{kind=link}
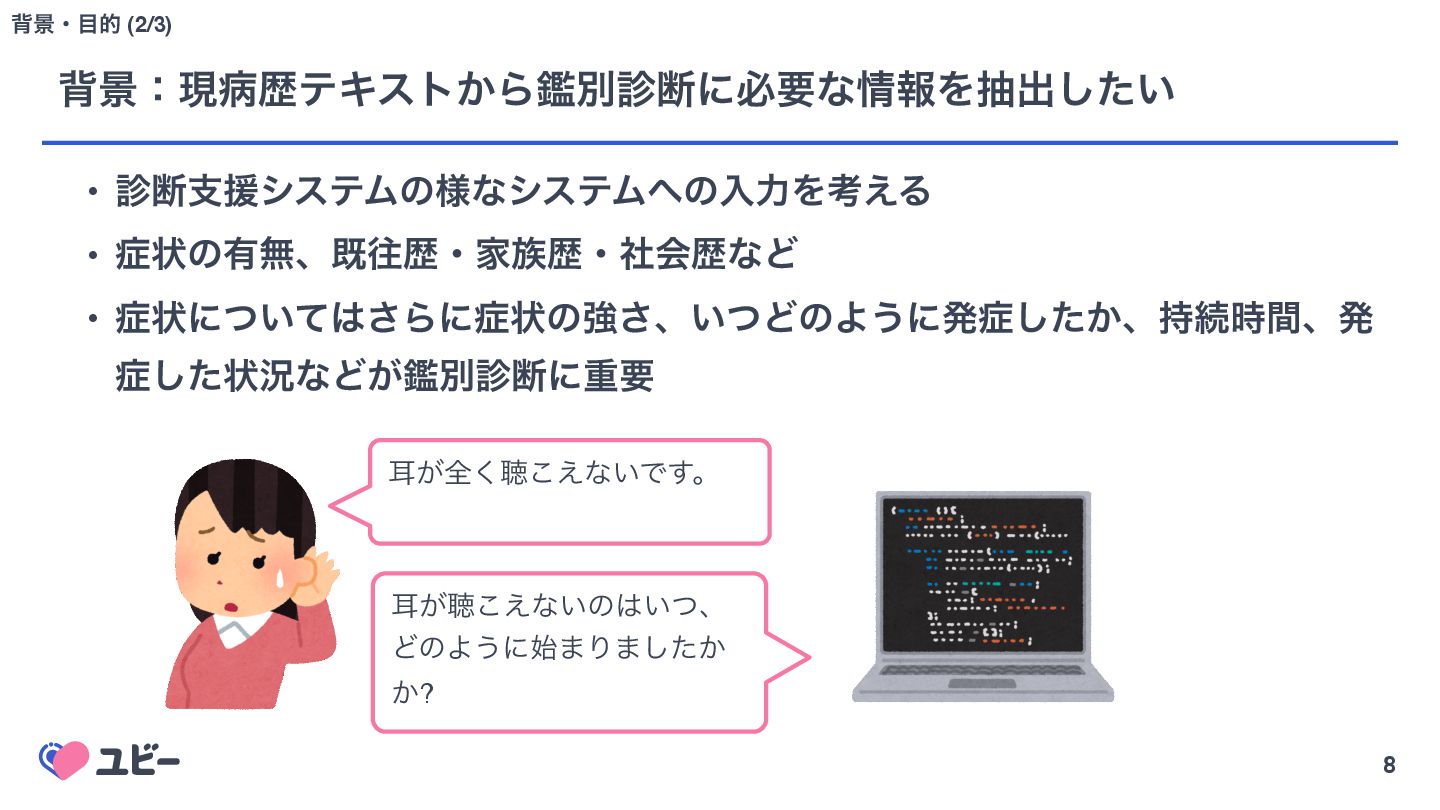{kind=link}
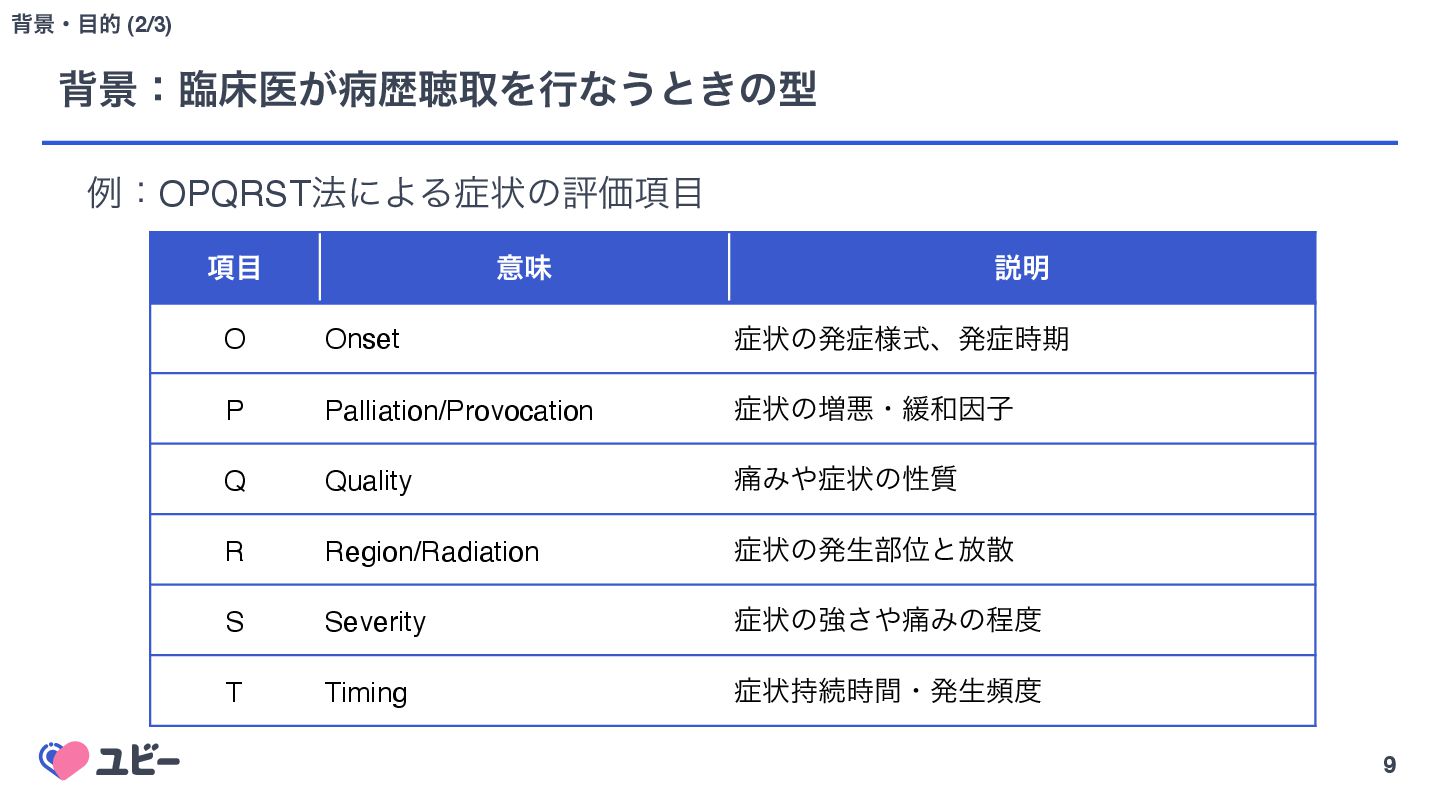{kind=link}
{kind=link}
{kind=link}
![12 ࡐྉɿݱපྺςΩετ ࡐྉɾख๏ (1/6) Avey Benchmark Vignette suite [1] ঢ়νΣοΧʔͷੑೳධՁ༻ʹ࡞ΒΕͨྫςΩετσʔληοτ](https://files.speakerdeck.com/presentations/579215aebdd14832ba9af26c6fefabcf/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
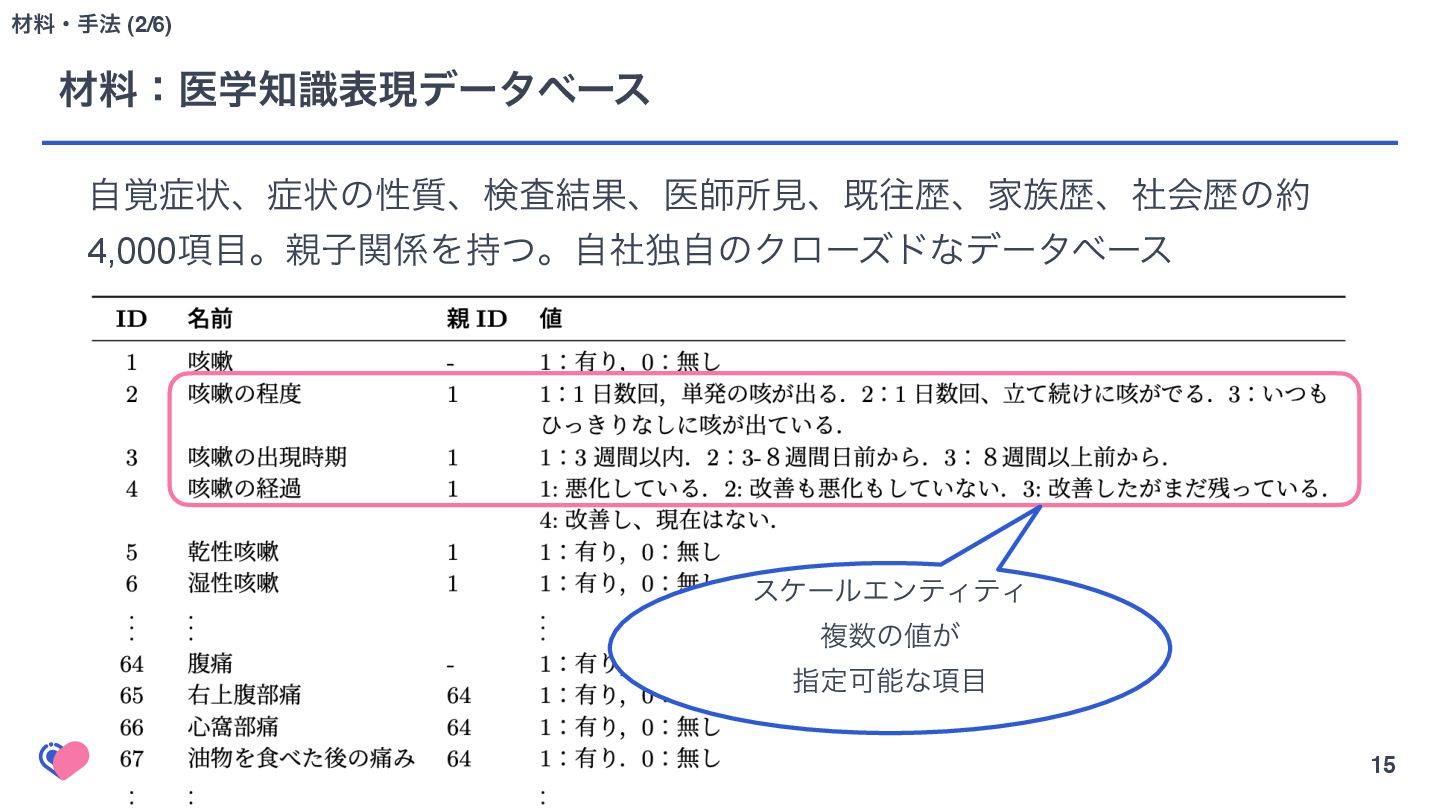{kind=link}
{kind=link}
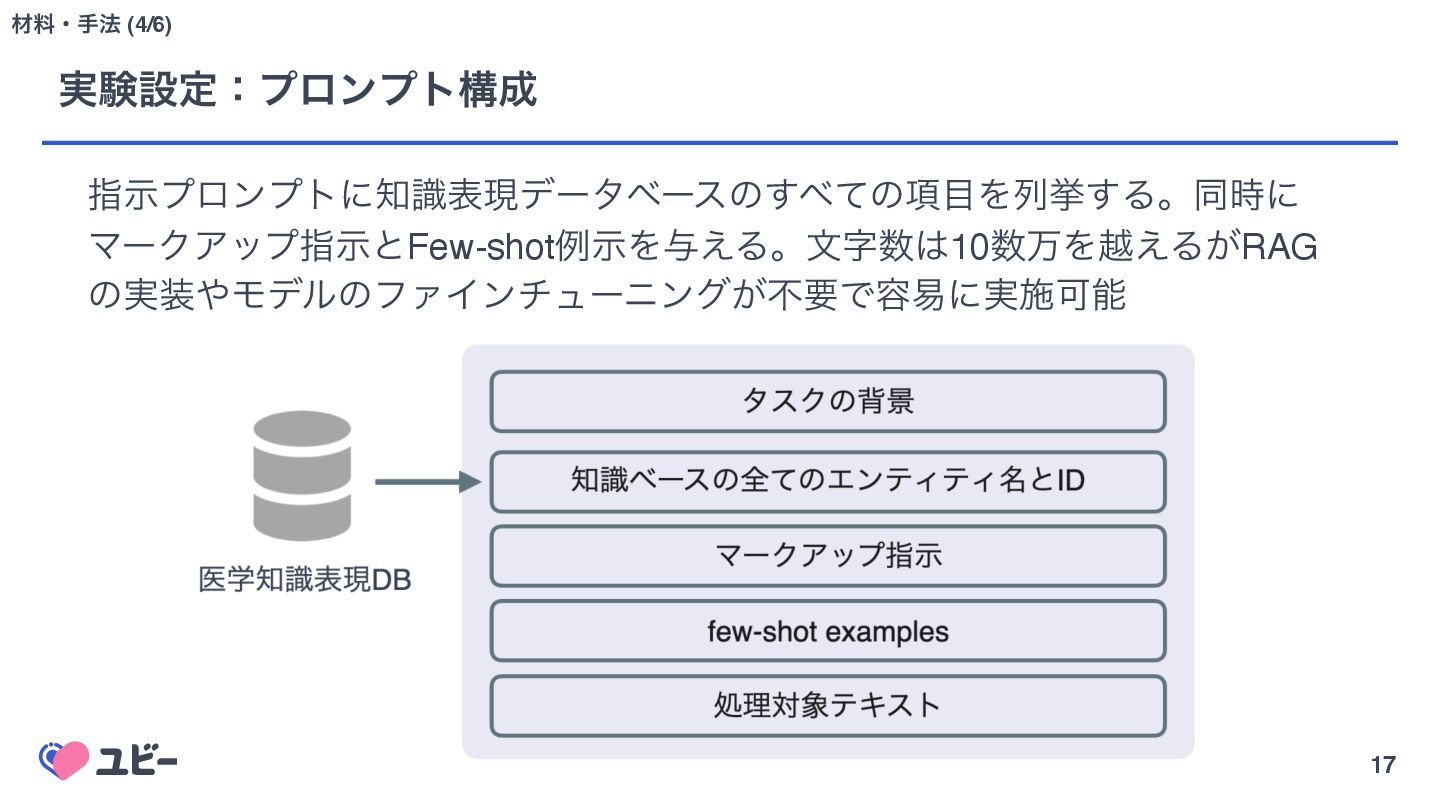{kind=link}
{kind=link}
{kind=link}
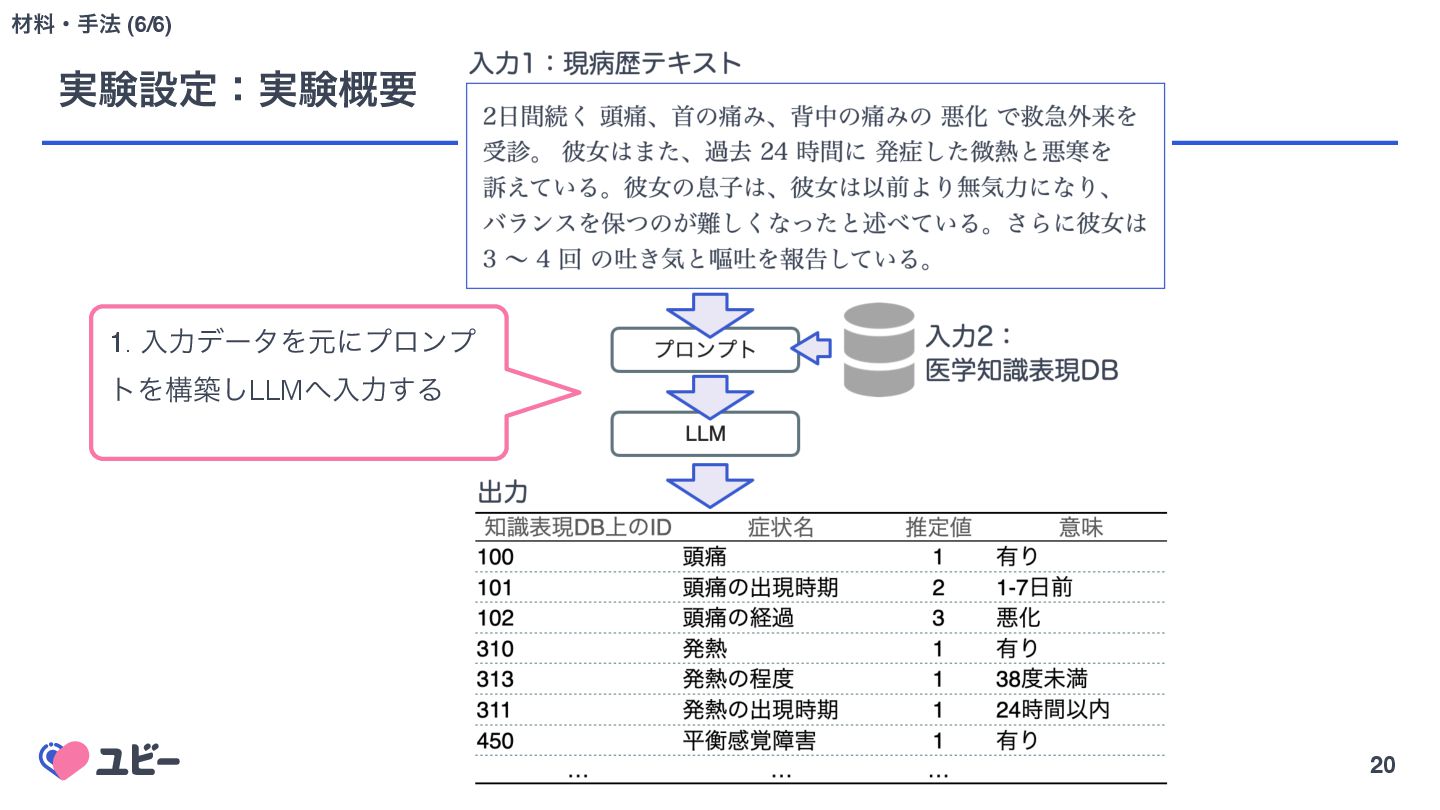{kind=link}
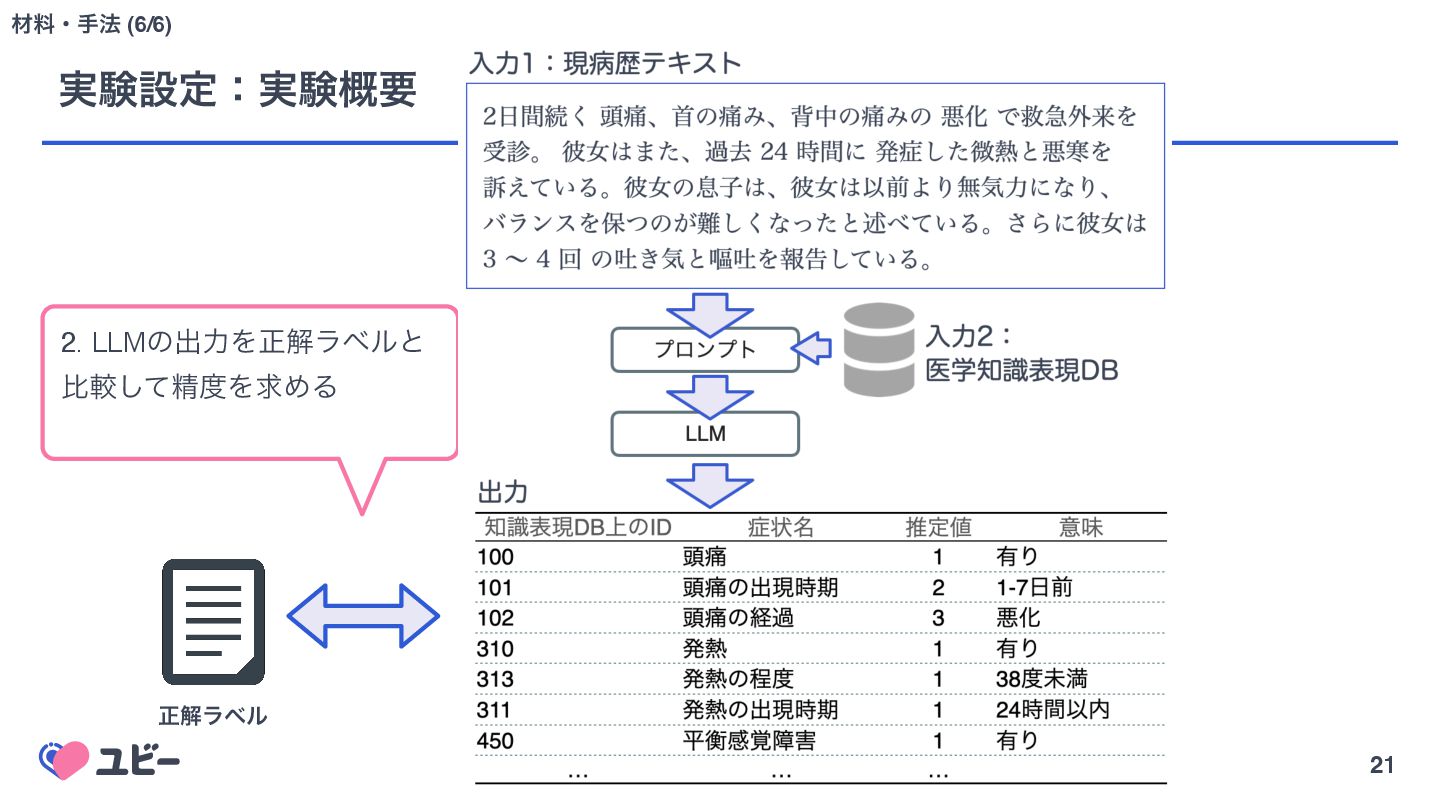{kind=link}
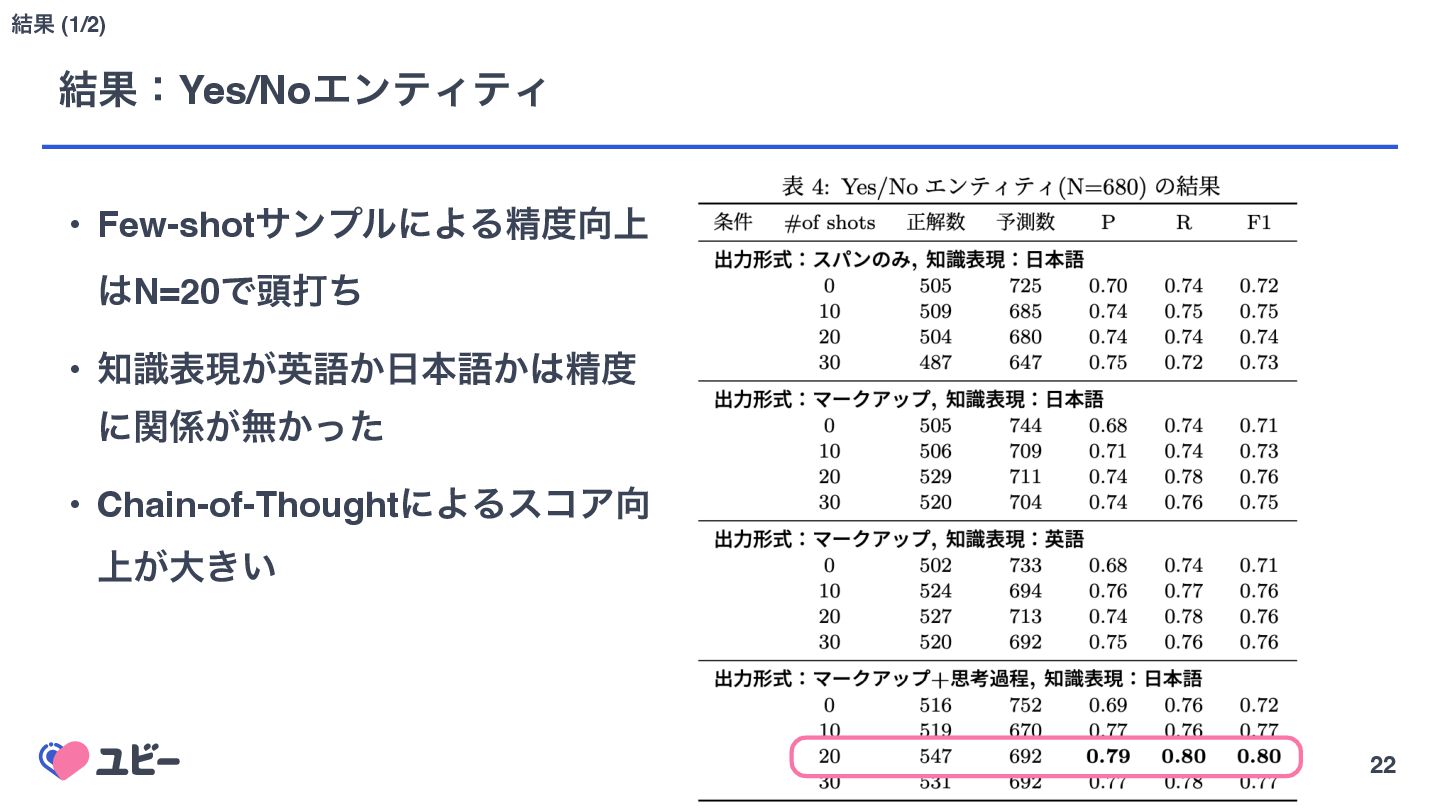{kind=link}
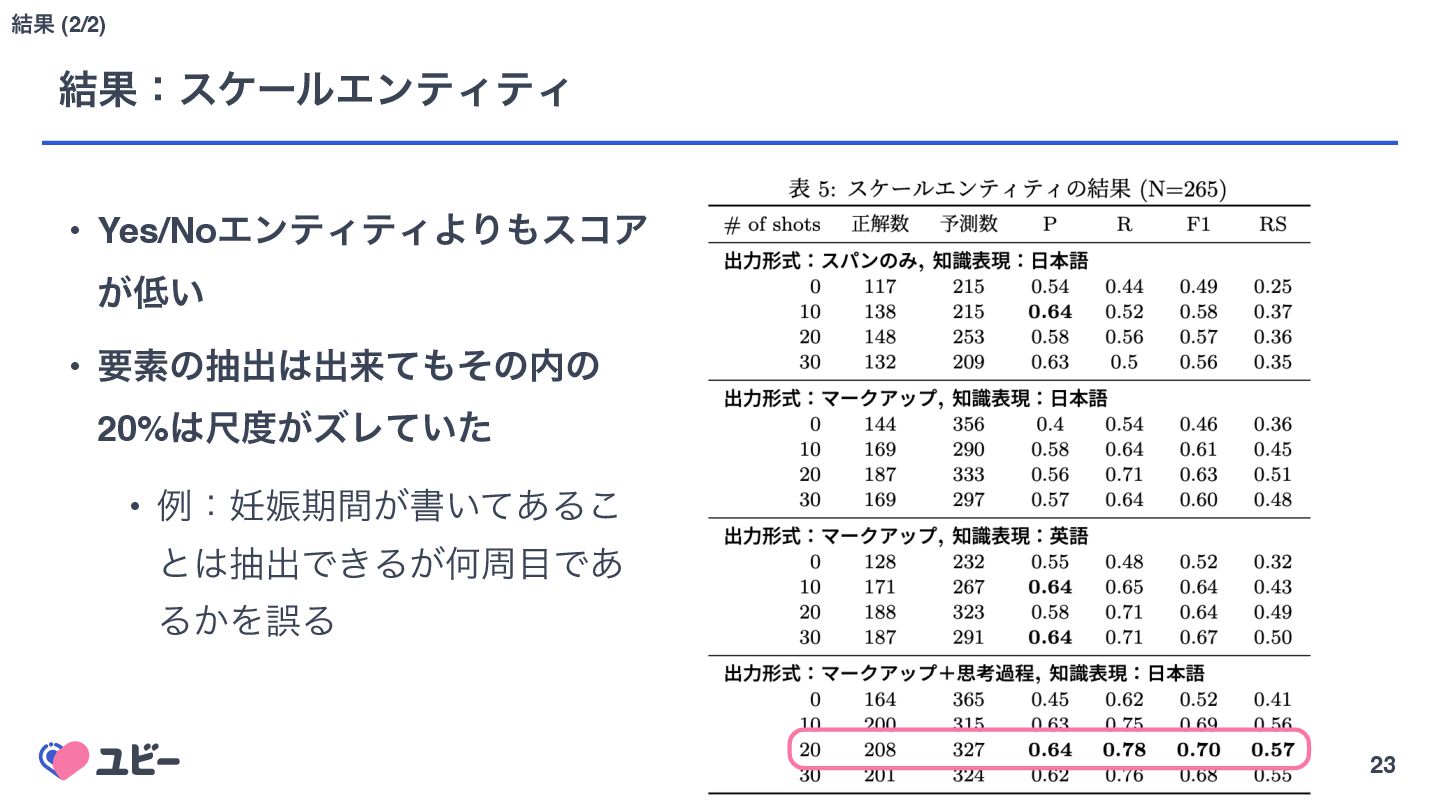{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}