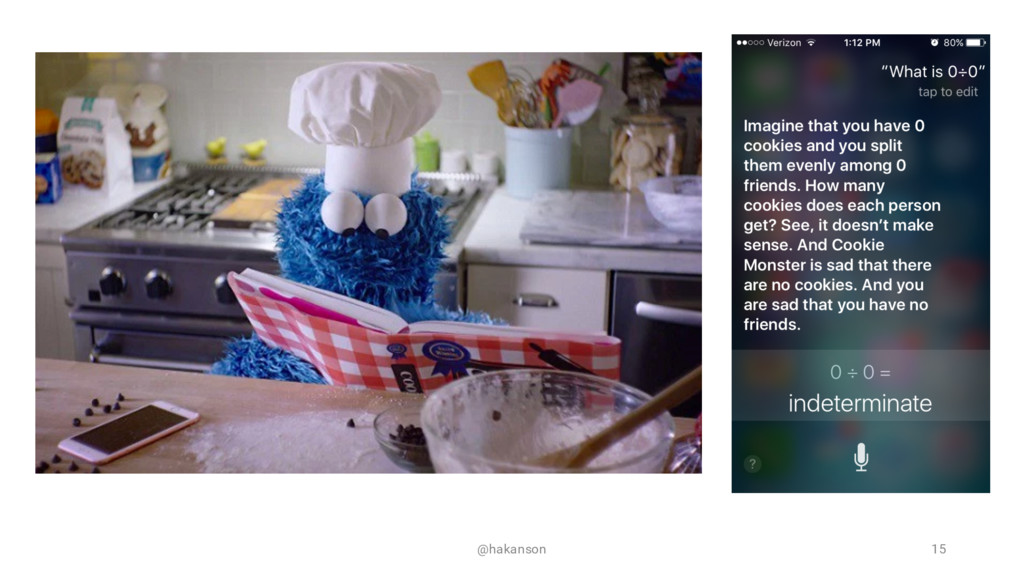
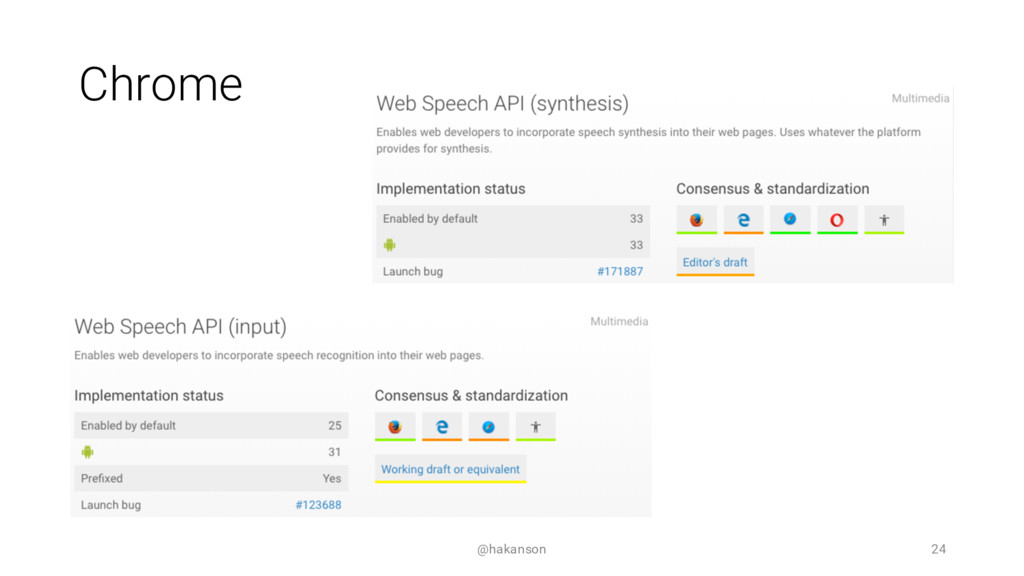
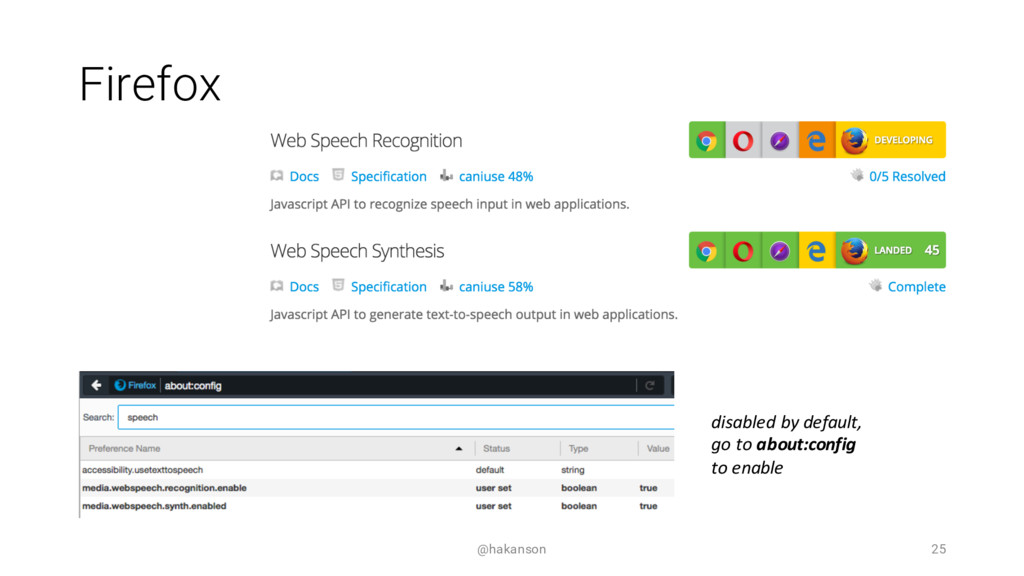
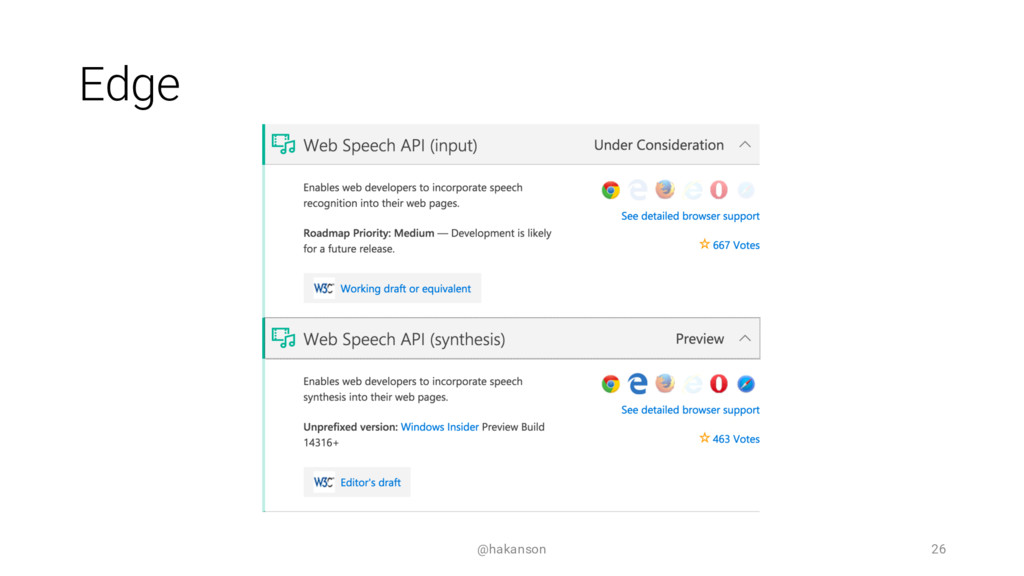
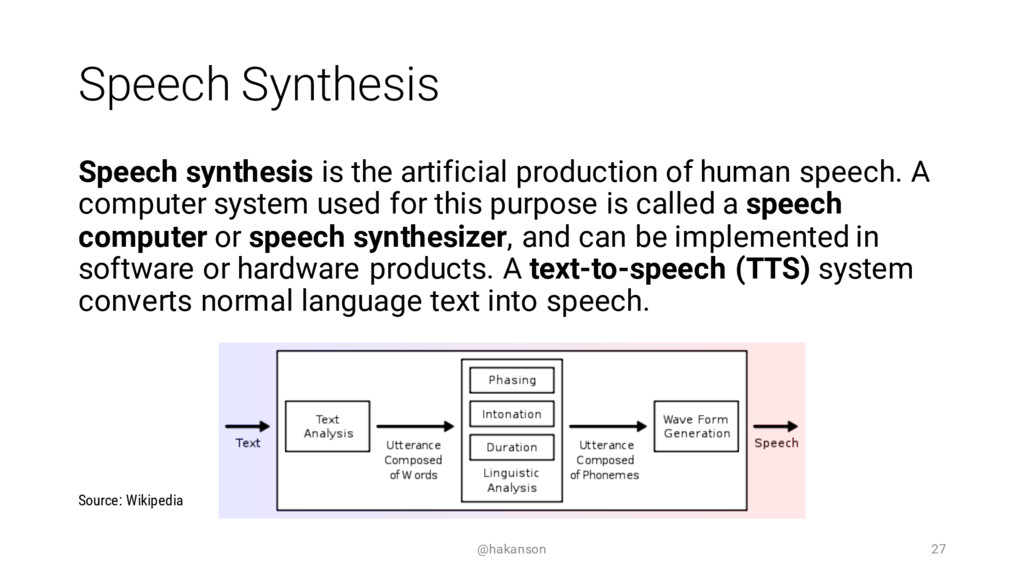
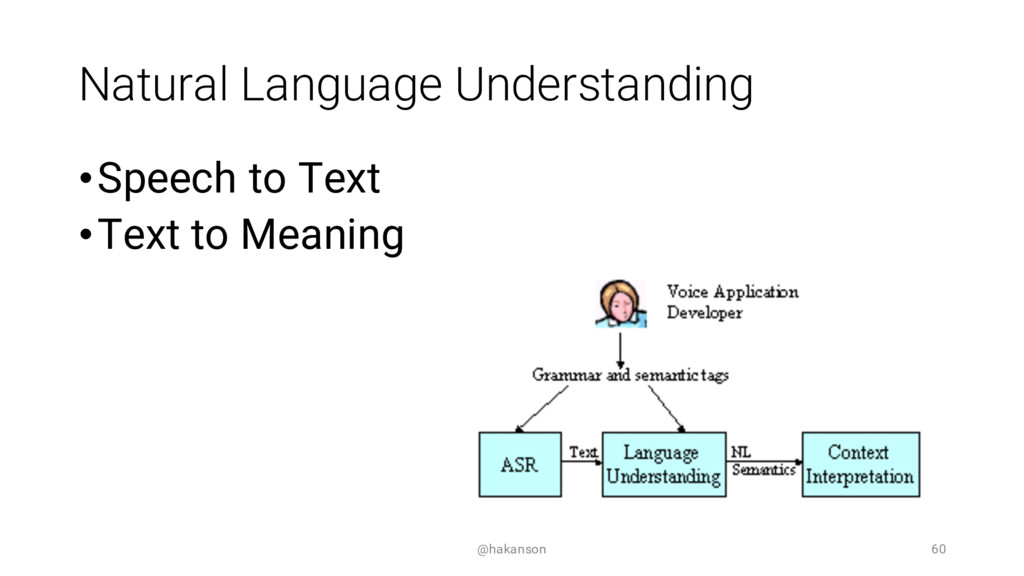
Speaking with your computing device is becoming commonplace. Most of us have used Apple's Siri, Google Now, Microsoft's Cortana, or Amazon's Alexa - but how can you speak with your web application? The Web Speech API can enable a voice interface by adding both Speech Synthesis (Text to Speech) and Speech Recognition (Speech to Text) functionality.
This session will introduce the core concepts of Speech Synthesis and Speech Recognition. We will evaluate the current browser support and review alternative options. See the JavaScript code and UX design considerations required to add a speech interface to your web application. Come hear if it's as easy as it sounds?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![JavaScript Example recognition.onresult = function(event) { var color = event.results[0][0].transcript;](https://files.speakerdeck.com/presentations/7014d160390148b2ae539fc9b5e6364f/slide_51.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}