Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
DMMの検索システムをSolrからElasticCloudに移行した話
Search
小山凌太
October 30, 2025
Technology
680
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
DMMの検索システムをSolrからElasticCloudに移行した話
以下の検索技術勉強会で発表したものに、時間の都合で削ったスライドなどを追加しています。
https://search-tech.connpass.com/event/370754/
小山凌太
October 30, 2025
Other Decks in Technology
See All in Technology
どこまでAIに任せるか 〜確率論と決定論の境界決定〜
shukob
0
520
Webアプリ認証の全体像 / The Big Picture of Web App Authentication
kitano_yuichi
1
450
そのドキュメント、自動化しませんか?
yuksew
1
440
AI x 開発生産性を取り巻く予算戦略と投資対効果
i35_267
7
3.3k
Vポイント分析基盤におけるデータモデリング20年史
taromatsui_cccmkhd
4
770
データエンジニアリングとドメイン駆動設計
masuda220
PRO
14
2.6k
AIエージェントがあれば技術書なんてすぐ書けるでしょ→無理でした
watany
4
460
ソフトウェアアーキテクチャ研修【MIXI 26新卒技術研修】
mixi_engineers
PRO
2
420
AI時代におけるエンジニアの新たな役割──FDEとクオリアの探求/登壇資料(戸井田 裕貴)
hacobu
PRO
0
440
なぜ、あなたのエージェントは言うことを聞かないのか
segavvy
1
510
クラウドを使う側から、作る側へ / 大吉祥寺.pm 2026前夜祭
fujiwara3
6
1.5k
変更し続けられるシステムをどう保つか — AI時代のSSoTという設計原則
kawauso
1
1.3k
Featured
See All Featured
Why Your Marketing Sucks and What You Can Do About It - Sophie Logan
marketingsoph
0
310
DBのスキルで生き残る技術 - AI時代におけるテーブル設計の勘所
soudai
PRO
67
56k
Utilizing Notion as your number one productivity tool
mfonobong
4
460
Conquering PDFs: document understanding beyond plain text
inesmontani
PRO
4
2.9k
Building AI with AI
inesmontani
PRO
1
1.1k
Leveraging Curiosity to Care for An Aging Population
cassininazir
1
420
Stop Working from a Prison Cell
hatefulcrawdad
274
21k
Performance Is Good for Brains [We Love Speed 2024]
tammyeverts
12
1.7k
First, design no harm
axbom
PRO
2
1.2k
Navigating Algorithm Shifts & AI Overviews - #SMXNext
aleyda
1
1.5k
Intergalactic Javascript Robots from Outer Space
tanoku
273
27k
Dominate Local Search Results - an insider guide to GBP, reviews, and Local SEO
greggifford
PRO
0
210
Transcript
© DMM.com DMMの検索システムを SolrからElasticCloudに移行した話 検索基盤チーム 小山凌太 2025/10/30
© DMM.com 2 自己紹介 - 所属: - 2019/04 合同会社DMM.com 新卒
- 2019/07 検索チーム - 主にクラウドインフラ担当 - 趣味: - ライブやイベントに参加すること - 聖地巡礼 - ラーメン etc 小山 凌太 (Koyama Ryota)
© DMM.com なぜSolrからElasticCloudに移行したか
© DMM.com SolrのEKS運用がしんどすぎた
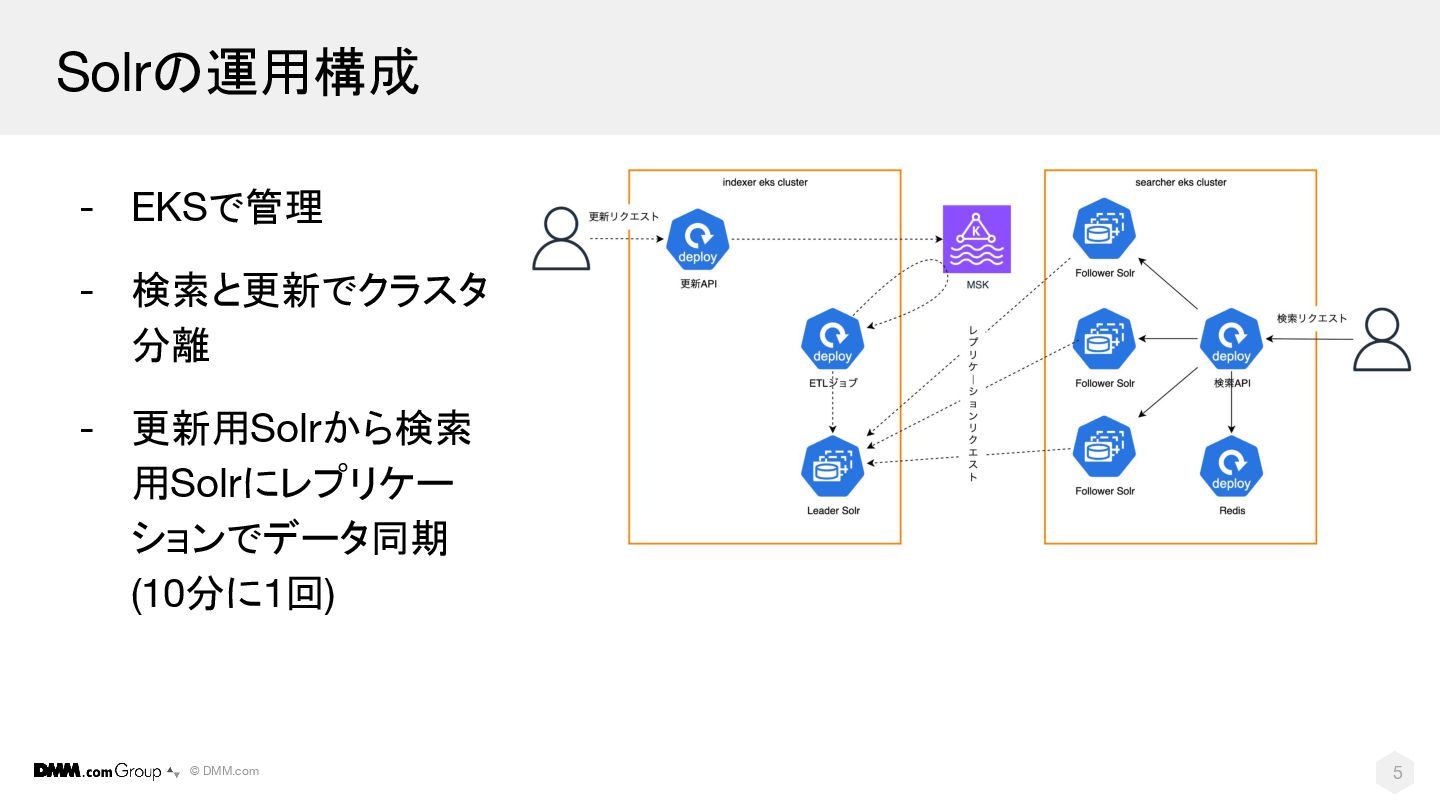
© DMM.com 5 Solrの運用構成 - EKSで管理 - 検索と更新でクラスタ 分離 -
更新用Solrから検索 用Solrにレプリケー ションでデータ同期 (10分に1回)
© DMM.com 6 SolrのEKS運用課題 - ウォームアップ による再起動コスト - Solr Pod起動時に全Indexデータをメモリに読み込む必要がある
- 1 Podあたり約10~12分程度の起動時間 → オートスケールさせられない (間に合わない) - EKSのKubernetesバージョンアップ - 3ヶ月に一度 、全クラスタ(環境数×indexer/searcher)で対応 - ノードグループをAZごとに分離しており、1AZずつローリングアップデー トしていた - 本番のsearcherクラスタでは約6時間かかっていた
© DMM.com 運用コストが高すぎて 検索改善にも手が回っていなかった
© DMM.com 8 移行方針: 絶対に満たすべき条件(Must) 移行先を検討する上での方針 - must: - 運用コストを下げられる
- 既存のSolrを用いた検索システムより性能的に劣ることがない - Solrで提供していた検索ユースケースを満たすことができる
© DMM.com 9 移行方針: できれば満たしたい条件(Should) 移行先を検討する上での方針 - must: - 運用コストを下げられる
- 既存のSolrを用いた検索システムより性能的に劣ることがない - Solrで提供していた検索ユースケースを満たすことができる - should: - 性能面でのパフォーマンス向上 - 検索改善のための豊富な機能
© DMM.com 10 選ばれたのはElasticCloudでした - 運用コストの低減: - マネージドサービス なので、EKSクラスタ運用から解放される -
豊富なドキュメント - Solrと同じLuceneライブラリ : - 機能的互換性が担保されており、移行リスクが低い - Serverlessへの期待: - 将来的な負荷ベースのオートスケール で、運用コストを更に低減 - 検索改善の未来: - 検索エンジンの機能としてベクトル検索や機械学習 など利用可能
© DMM.com 逆にElasticCloudの微妙なところは?
© DMM.com 12 ElasticCloudの懸念点 - 検索と更新のクラスタを分散できない - CCR(Cross-Cluster Replication)という機能でレプリケーション自体 はできるが...
- これはLeader側クラスタのTranslogをポーリングしてFollower側で 同じ操作を実施するもの - つまり、負荷の分散には繋がらない - ディザスタリカバリや地理的に近いポイントで検索させるための データ配置用
© DMM.com 13 移行の流れ 1. Query調査 - SolrとESでは似たような機能でも微妙な差がある - 機能ごとに結果を比較しながら調査
2. 実装 3. 本番ログを使用した機能試験 - Solrと結果を比較→差がなくなるまで繰り返す 4. 本番リクエストをミラーリングして性能試験 - 検索・更新のリクエストをミラーリングしてチューニング
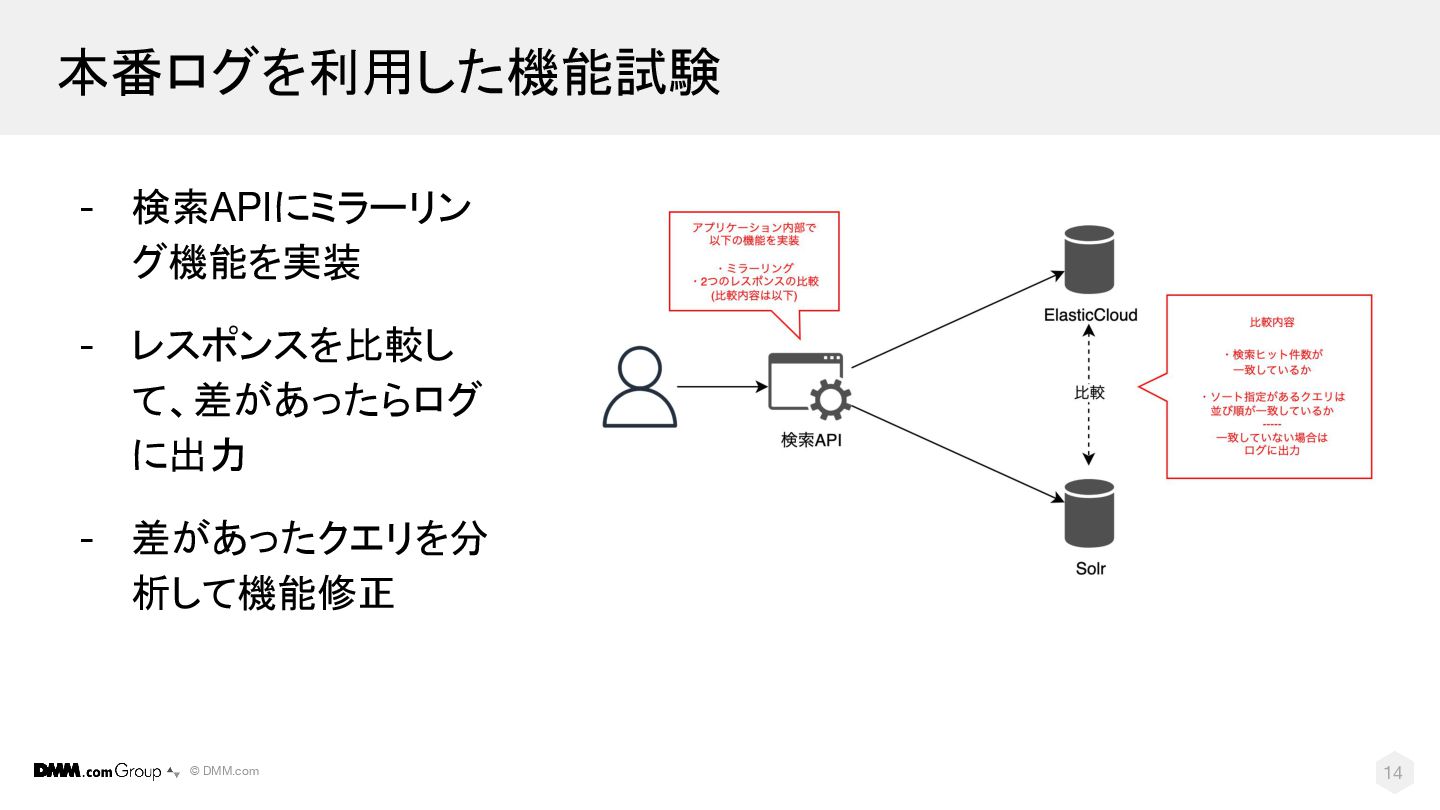
© DMM.com 14 本番ログを利用した機能試験 - 検索APIにミラーリン グ機能を実装 - レスポンスを比較し て、差があったらログ
に出力 - 差があったクエリを分 析して機能修正
© DMM.com 15 差分例1: or と and が複合した検索結果 - 例:
「アニメ or 声優 or キャラ and DVD」でヒット数に差が出た - 原因: - Solrでminimum_should_matchにあたる設定(mm)をしていなかっ た - 「アニメ or 声優 or キャラ and DVD」と「DVD」の検索結果が一緒 - 対応: - Solr側の設定ミスであり、あるべき姿はES側の結果なので、差分 を許容
© DMM.com 16 差分例2: 0トークンが空集合として扱われる - 例: 「? and ?
and アニメ」クエリでESが0件ヒット - 原因: - Solrではパース時点で「?」が除去されていたが、ESでは形態素 解析でも2gramでも空集合とみなされ、論理積を取ると0件になる - 対応: - 1文字の場合は2gramは通さず、zero_terms_queryにallを設定(こ れによって空集合ではなく全集合になる)
© DMM.com 移行してみてどうだった?
© DMM.com 18 移行して良かったこと / 移行の成果 - 移行の成果: - ESのrerank機能+terms_lookupによるスコアリングで検索改善施策
の中でも過去一の売上リフト - Solrの撤去によるEKS運用コストの削減 - EKSのアップデート工数が最大6時間→2時間に激減 - 学び: - 検索エンジンの仕組みへの理解が深まった - 例): - Luceneのスコアリングの仕組み - クエリからユーザの意図を把握する
© DMM.com 19 移行後に発生した課題 - 問題:95%ileの平均レスポンスタイムは向上したが、特定の「スロークエリ」 でSolrより性能が悪化 - 原因:オブザーバビリティの不足 -
性能試験での監視項目が全体監視に偏り 、サービス個別やIndex別、 スロークエリなど細分化された性能を見れていなかった - 対策: - プライマリシャード数のチューニング - index分離 → Deployment分離 - 1文字検索の要件見直し etc
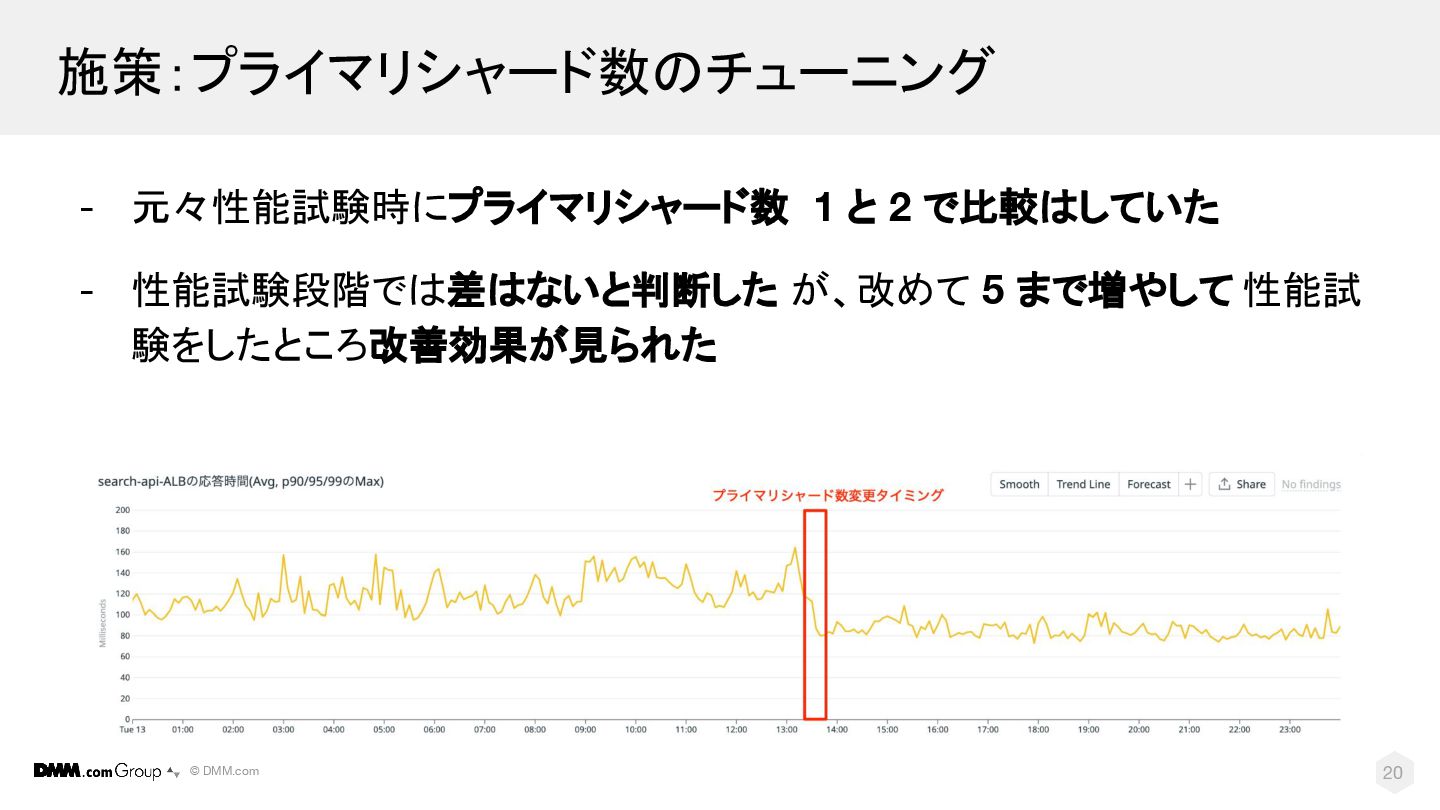
© DMM.com 20 施策:プライマリシャード数のチューニング - 元々性能試験時にプライマリシャード数 1 と 2 で比較はしていた
- 性能試験段階では差はないと判断した が、改めて 5 まで増やして 性能試 験をしたところ改善効果が見られた
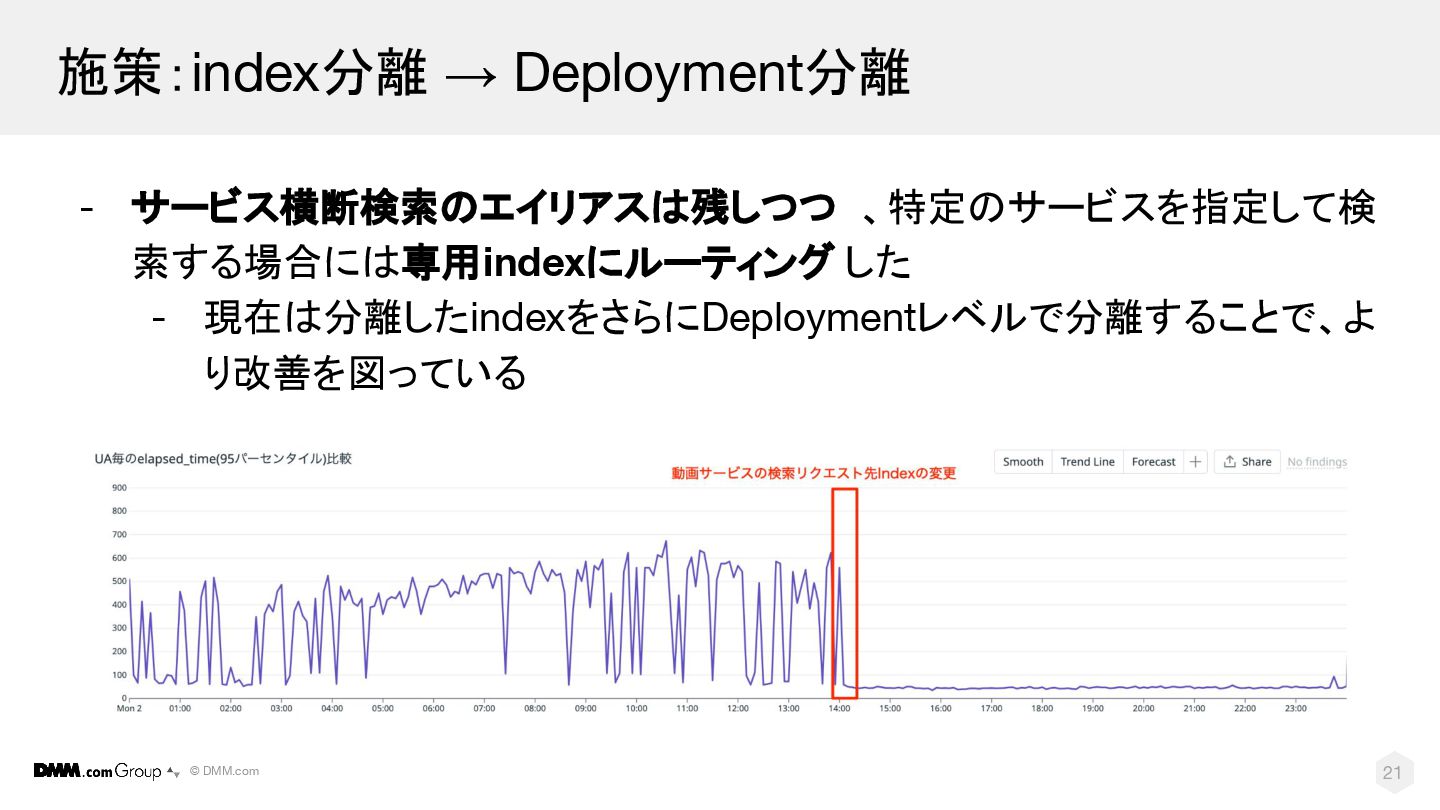
© DMM.com 21 施策:index分離 → Deployment分離 - サービス横断検索のエイリアスは残しつつ 、特定のサービスを指定して検 索する場合には専用indexにルーティング
した - 現在は分離したindexをさらにDeploymentレベルで分離することで、よ り改善を図っている
© DMM.com 22 現在の最大の課題 - reindexによる運用負荷 - 既存のETLパイプラインとの相性の悪さから工程が複雑化 - Index
Templateの変更に伴って頻繁に発生する - 一時的な対応として フィールド追加はIndex Templateの変更をし つつ、直接API経由で動いているIndexのMappingを更新するよ うにした - 性能課題 - 事業部によっては性能問題がシビアなところもあり、引き続き Deployment分離などで性能改善中
© DMM.com 23 今後の展望 - 検索APIや更新システムなどEKSに残っているシステムをGoogle Cloudに 移行する - 移行するだけでなく、システム自体も見直すことでreindexなど、既存の
課題にも対応予定 - Deployment分離による各サービスの性能改善と将来的なスキーマ最適化 - 更なる検索改善 - マッチング改善などもしていきたい
© DMM.com 24 おまけ - 今回の発表内容は以下のブログにしているので気になった方はぜひ - https://developersblog.dmm.com/entry/2025/08/04/110000 - また、ElasticCloudについてFindy
Toolsにてレビューを寄稿しています - こちらも気になった方はぜひ - https://findy-tools.io/products/elastic-cloud/1228/703
© DMM.com 25 Appendix: 0トークンが空集合として扱われる(詳細) - 事象: - 「? and
? and アニメ」クエリでESの検索結果が0件になる
© DMM.com 26 Appendix: 0トークンが空集合として扱われる(詳細) - 事象: - 「? and
? and アニメ」クエリでESの検索結果が0件になる - 調査1: - Solrクエリをデバッグ - Solrでは「アニメ」の検索結果と一致 - 「?」はパース段階で除去されていた
© DMM.com 27 Appendix: 0トークンが空集合として扱われる(詳細) - 事象: - 「? and
? and アニメ」クエリでESの検索結果が0件になる - 調査2: - ESクエリを調査 - 前提: - DMMの検索では形態素解析用のjaフィールドと2gram用のcjk フィールドがある - 「?」はjaとcjkどちらのアナライザーを通しても空になり、論理積を取る と0件になる
© DMM.com 28 Appendix: 0トークンが空集合として扱われる(詳細) - 事象: - 「? and
? and アニメ」クエリでESの検索結果が0件になる - 対応1: - zero_terms_queryにallを指定する - これにより、空集合を全集合として扱うことができる - 「? and ? and アニメ」は全集合とアニメの論理積を取り、検索結 果がアニメと一致する
© DMM.com 29 Appendix: 0トークンが空集合として扱われる(詳細) - 事象: - 「? and
? and アニメ」クエリでESの検索結果が0件になる - 新たに発生した問題: - 「夢」のような1文字のクエリで検索したときに2gramの検索が全集合に なるため、全ドキュメントを返してしまう
© DMM.com 30 Appendix: 0トークンが空集合として扱われる(詳細) - 事象: - 「? and
? and アニメ」クエリでESの検索結果が0件になる - 新たに発生した問題: - 「夢」のような1文字のクエリで検索したときに2gramの検索が全集合に なるため、全ドキュメントを返してしまう - この問題の対応 1: - 「?* and ?* and アニメ」のように1文字の場合は前方一致検索にして 2gramでも通るように変更
© DMM.com 31 Appendix: 0トークンが空集合として扱われる(詳細) - 事象: - 「? and
? and アニメ」クエリでESの検索結果が0件になる - 新たに発生した問題: - 「夢」のような1文字のクエリで検索したときに2gramの検索が全集合に なるため、全ドキュメントを返してしまう - この問題の対応1: - 「?* and ?* and アニメ」のように1文字の場合は前方一致検索にして 2gramでも通るように変更 - 更なる問題: - 前方一致検索は性能が悪く、検索がタイムアウトしまくる
© DMM.com 32 Appendix: 0トークンが空集合として扱われる(詳細) - 事象: - 「? and
? and アニメ」クエリでESの検索結果が0件になる - 最終的な解決策: - 1文字検索の場合は2gram用のcjkアナライザーを通さず、形態素解析 のみでzero_terms_queryにallを指定する - cjkを通さないので、「夢」のような1文字検索も形態素解析でそのまま 検索でき、「?」のような意味のない検索は全集合になる
© DMM.com 33 Appendix: reindexの複雑さ 1. Index Templateを変更 2. reindexを実施(ここで新しいindexも作られる)
3. 新しいindexへの更新用ETLジョブを新しく作成 4. Kafkaのキューをreindex直前まで戻す 5. 新旧indexの更新が同期されるまで待つ 6. 検索用エイリアスに紐づくindexを新しいindexに張り替える 7. 古いindexへの更新用ETLジョブを削除 8. 古いindexを削除
© DMM.com 34 Appendix: reindexの複雑さ 1. Index Templateを変更 2. reindexを実施(ここで新しいindexも作られる)
3. 新しいindexへの更新用 ETLジョブを新しく作成 4. Kafkaのキューを reindex直前まで戻す 5. 新旧indexの更新が同期されるまで待つ 6. 検索用エイリアスに紐づくindexを新しいindexに張り替える 7. 古いindexへの更新用 ETLジョブを削除 8. 古いindexを削除 ←ここで手動操作 が入る
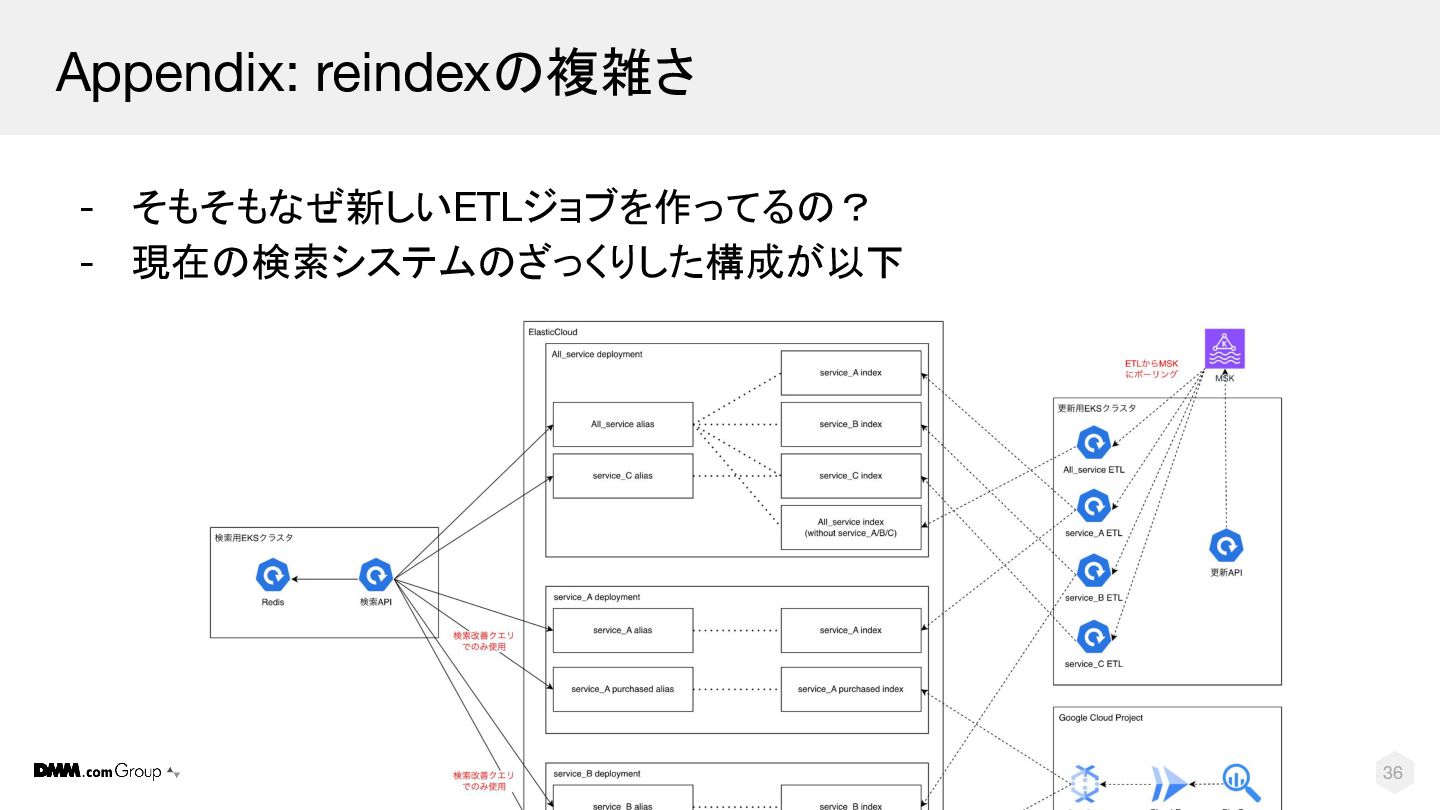
© DMM.com 35 Appendix: reindexの複雑さ - そもそもなぜ新しいETLジョブを作ってるの?
© DMM.com 36 Appendix: reindexの複雑さ - そもそもなぜ新しいETLジョブを作ってるの? - 現在の検索システムのざっくりした構成が以下
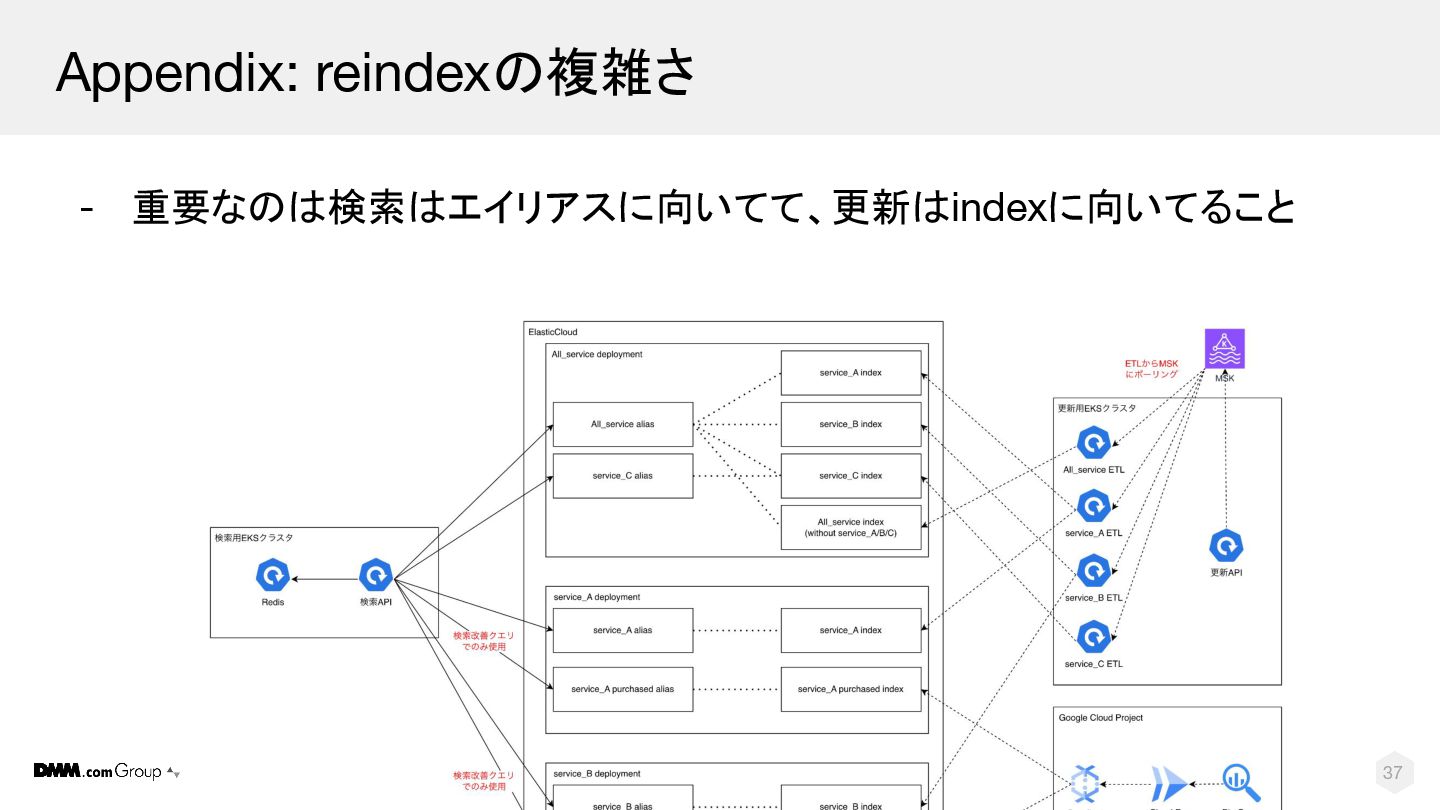
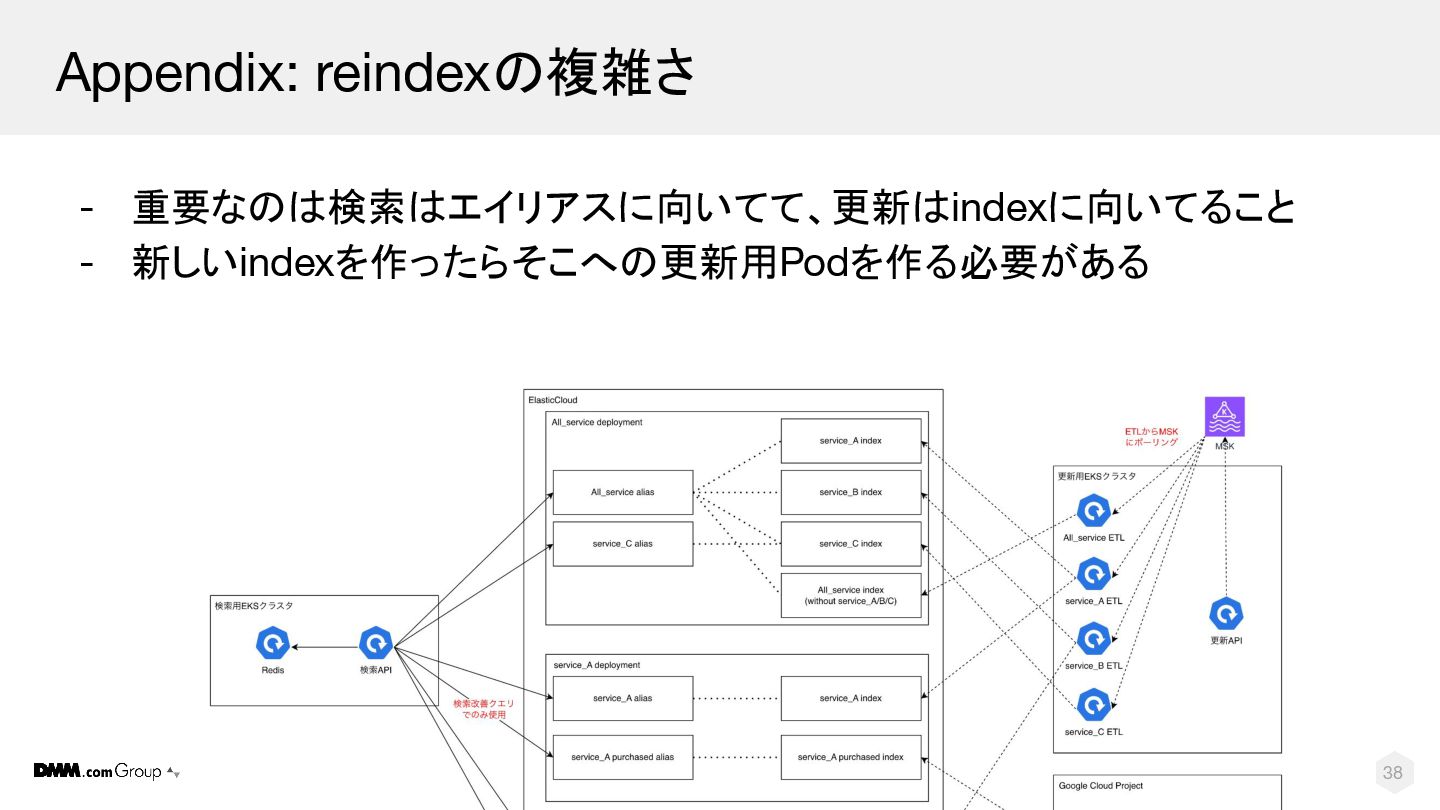
© DMM.com 37 Appendix: reindexの複雑さ - 重要なのは検索はエイリアスに向いてて、更新はindexに向いてること
© DMM.com 38 Appendix: reindexの複雑さ - 重要なのは検索はエイリアスに向いてて、更新はindexに向いてること - 新しいindexを作ったらそこへの更新用Podを作る必要がある
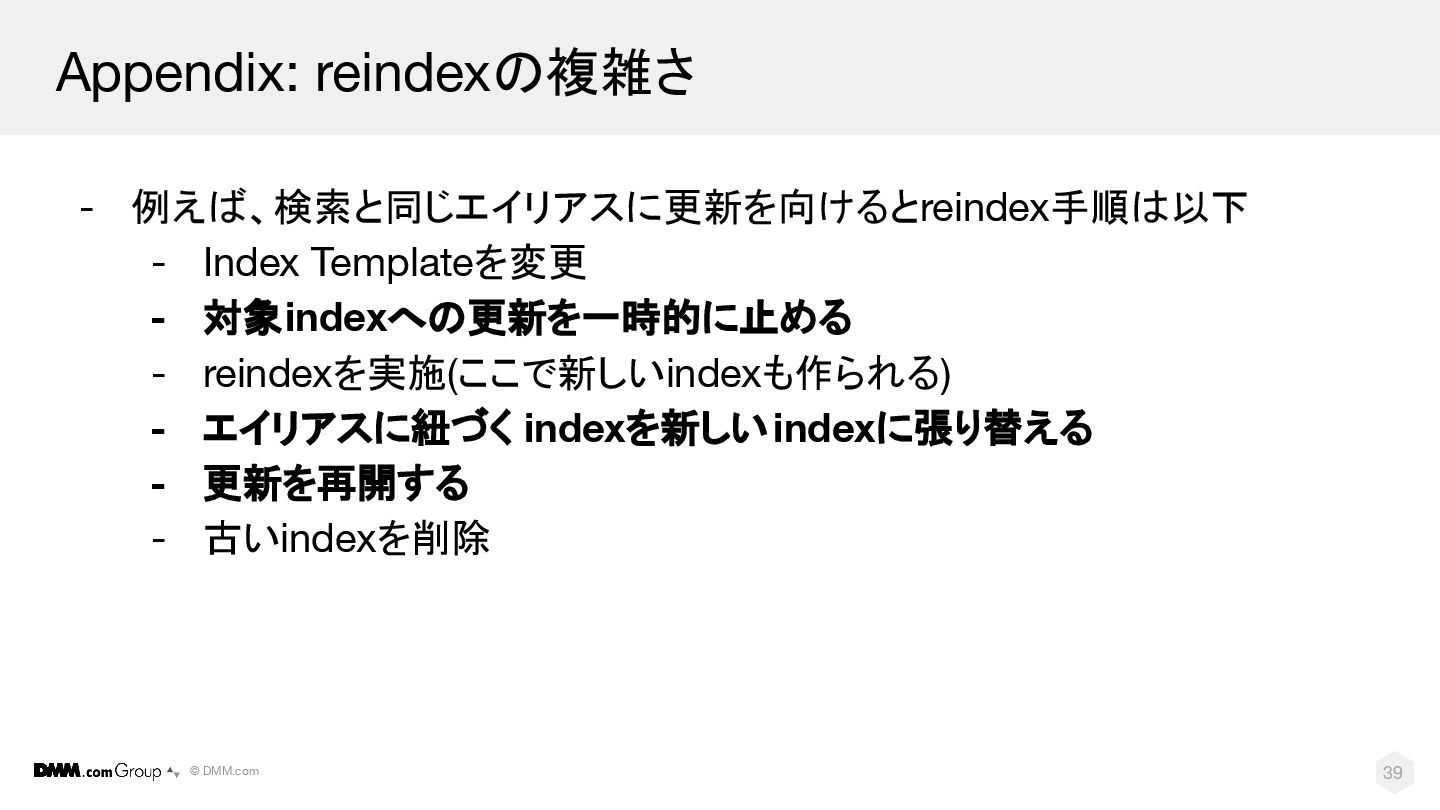
© DMM.com 39 Appendix: reindexの複雑さ - 例えば、検索と同じエイリアスに更新を向けるとreindex手順は以下 - Index Templateを変更
- 対象indexへの更新を一時的に止める - reindexを実施(ここで新しいindexも作られる) - エイリアスに紐づく indexを新しいindexに張り替える - 更新を再開する - 古いindexを削除
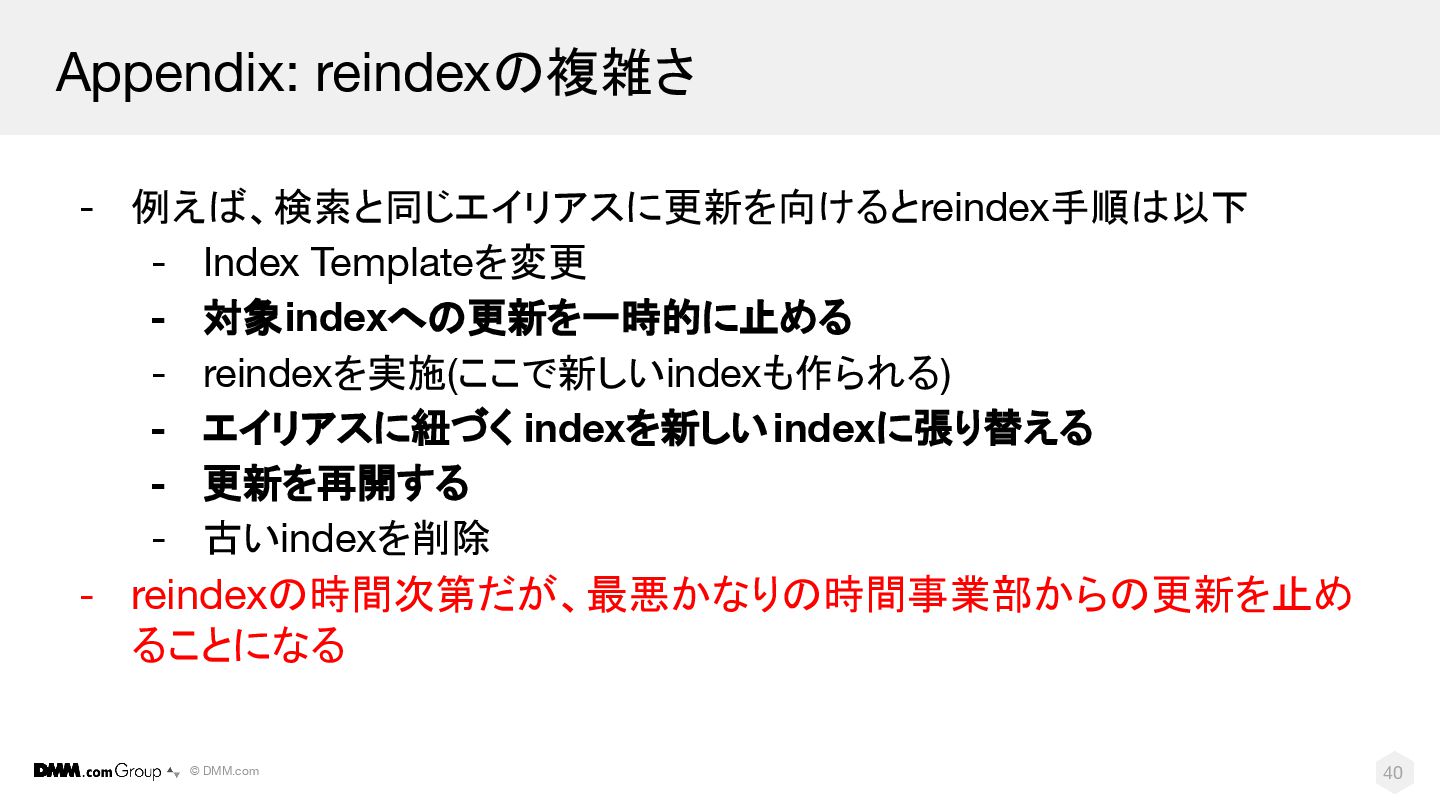
© DMM.com 40 Appendix: reindexの複雑さ - 例えば、検索と同じエイリアスに更新を向けるとreindex手順は以下 - Index Templateを変更
- 対象indexへの更新を一時的に止める - reindexを実施(ここで新しいindexも作られる) - エイリアスに紐づく indexを新しいindexに張り替える - 更新を再開する - 古いindexを削除 - reindexの時間次第だが、最悪かなりの時間事業部からの更新を止め ることになる
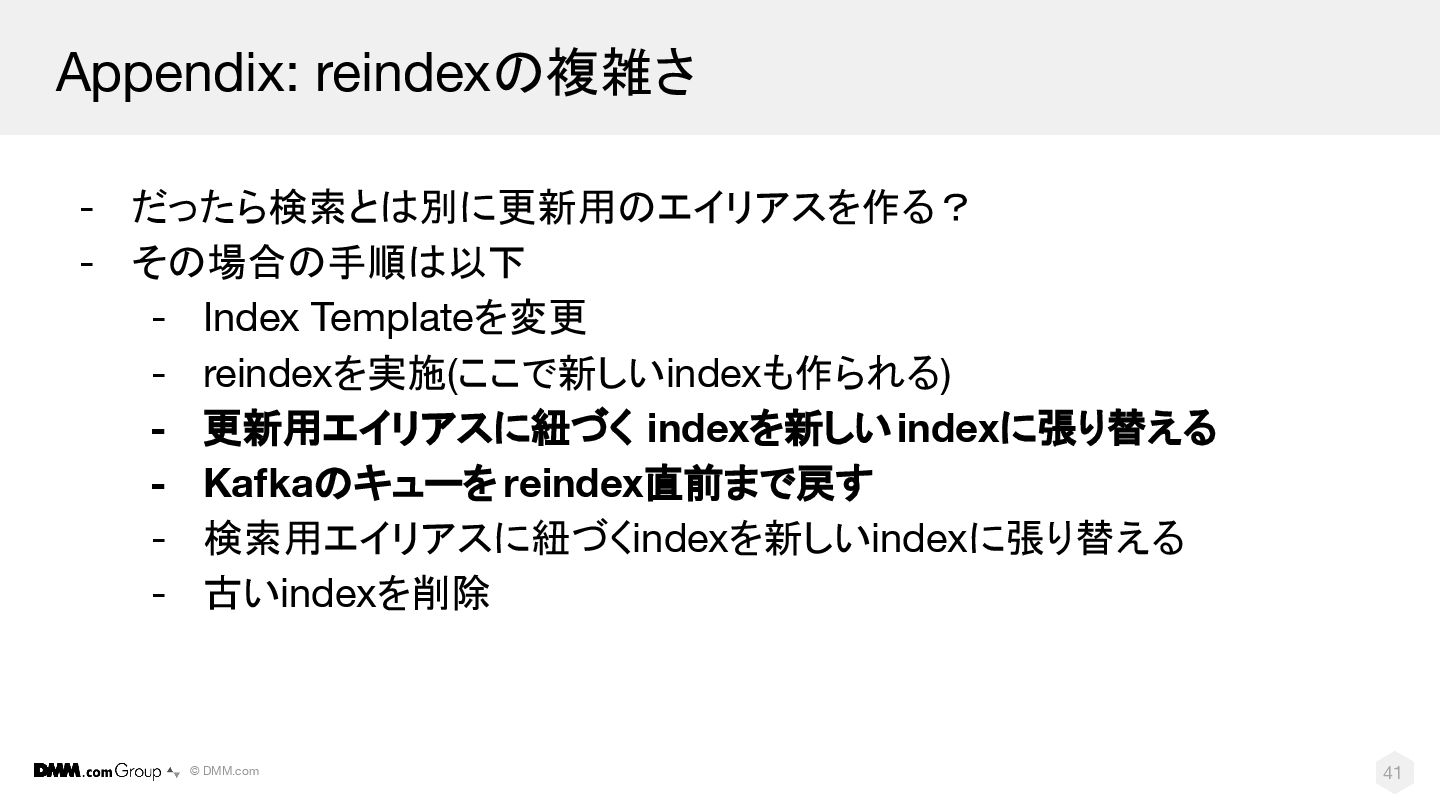
© DMM.com 41 Appendix: reindexの複雑さ - だったら検索とは別に更新用のエイリアスを作る? - その場合の手順は以下 -
Index Templateを変更 - reindexを実施(ここで新しいindexも作られる) - 更新用エイリアスに紐づく indexを新しいindexに張り替える - Kafkaのキューを reindex直前まで戻す - 検索用エイリアスに紐づくindexを新しいindexに張り替える - 古いindexを削除
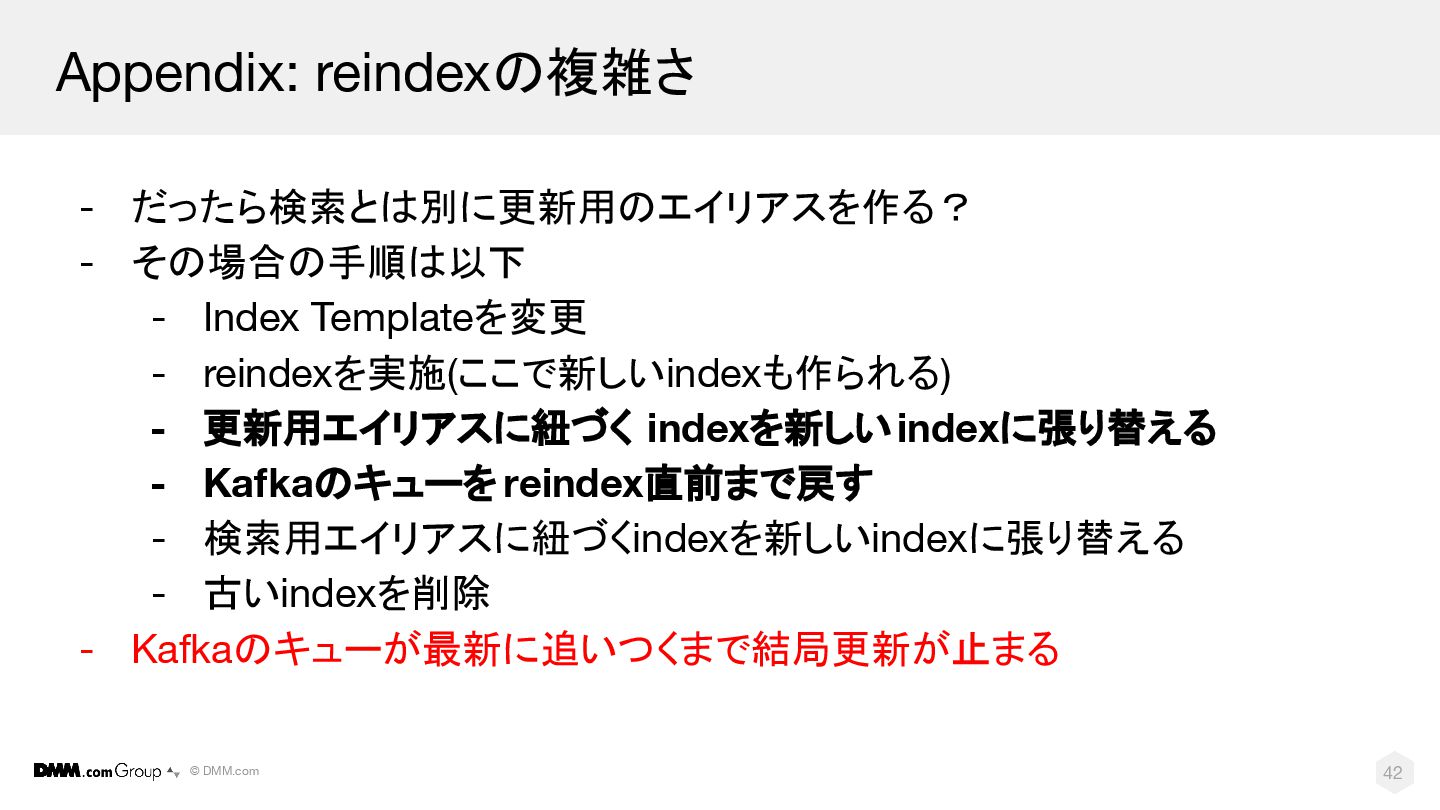
© DMM.com 42 Appendix: reindexの複雑さ - だったら検索とは別に更新用のエイリアスを作る? - その場合の手順は以下 -
Index Templateを変更 - reindexを実施(ここで新しいindexも作られる) - 更新用エイリアスに紐づく indexを新しいindexに張り替える - Kafkaのキューを reindex直前まで戻す - 検索用エイリアスに紐づくindexを新しいindexに張り替える - 古いindexを削除 - Kafkaのキューが最新に追いつくまで結局更新が止まる
© DMM.com 43 Appendix: reindexの複雑さ つまり 更新の停止が許容できる可能性もあるが、 運用コストは上がっても解決する手段が分かっているのに全ての事業部に合意 を取ることは難しい
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}