Speaker : Jeffrey Lam @Confluent
Bio : Jeffrey Lam is a Staff Solutions Engineer at Confluent. He is a big data specialist with over 20 years of experience in pre-sales and enterprise architecture, having worked for global technology leaders such as Confluent, Splunk, ServiceNow, IBM, and Oracle.
In this event, we will explore how to build next-generation real-time AI applications using Kafka and Flink. Jeffrey Lam will share his expertise in this field and discuss how to continuously enrich trustworthy data streams to quickly build, deploy, secure, and scale real-time AI applications in the era of booming artificial intelligence.
Participants will gain a deep understanding of how to use Kafka and Flink as a foundation for processing real-time and batch data. You will learn how these technologies can become a core competitive advantage for companies and their wide adoption in both commercial and open-source communities. Additionally, you will gain valuable insights into building scalable and secure real-time AI applications.
{kind=link}
{kind=link}
{kind=link}
![Vectors man [0.243, 0.765, …] woman [0.293, 0.774, …] Similar](https://files.speakerdeck.com/presentations/32759e427c97480481126fc87bd1bc11/slide_3.jpg){kind=link}
{kind=link}
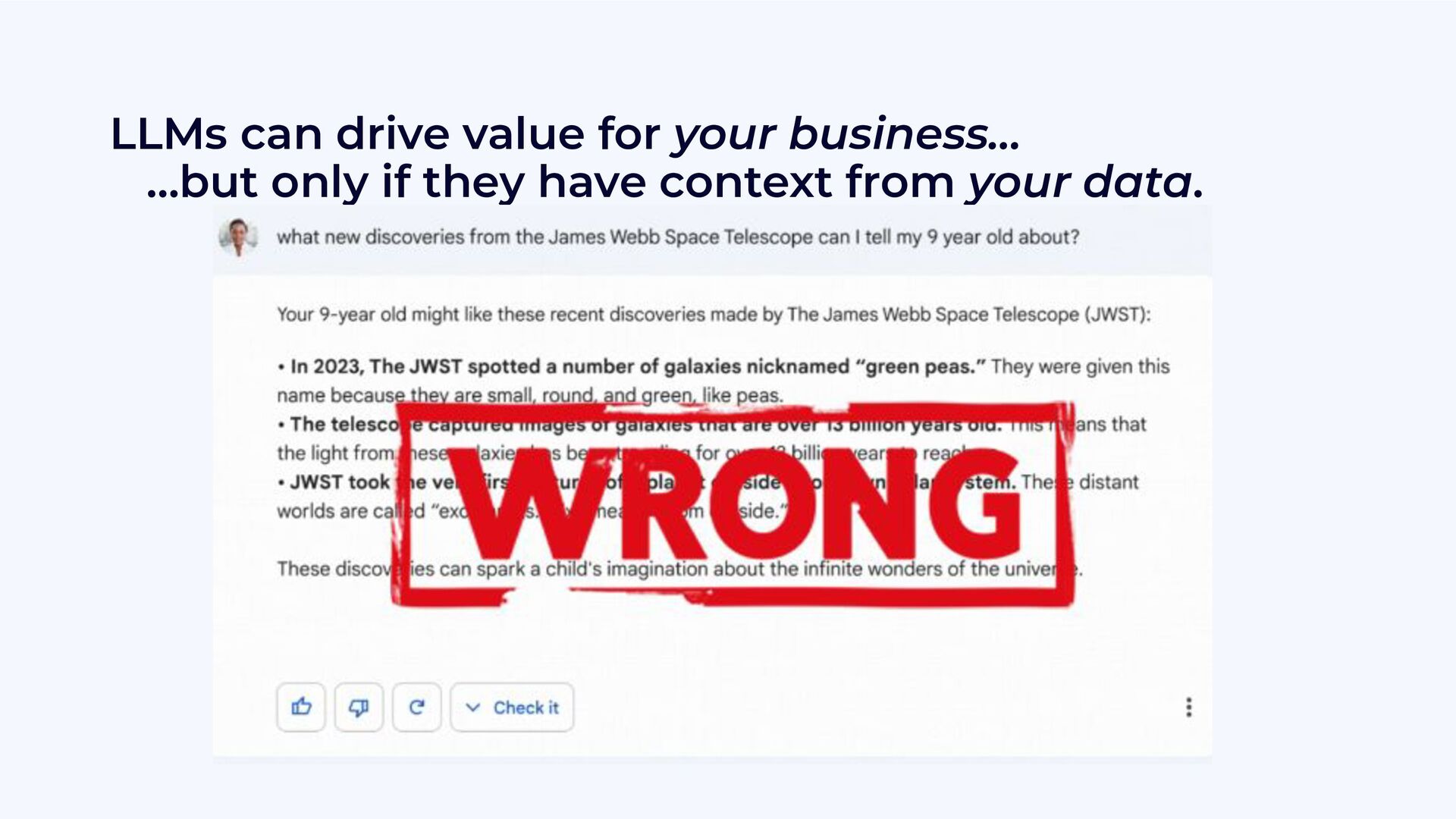{kind=link}
{kind=link}
{kind=link}
{kind=link}
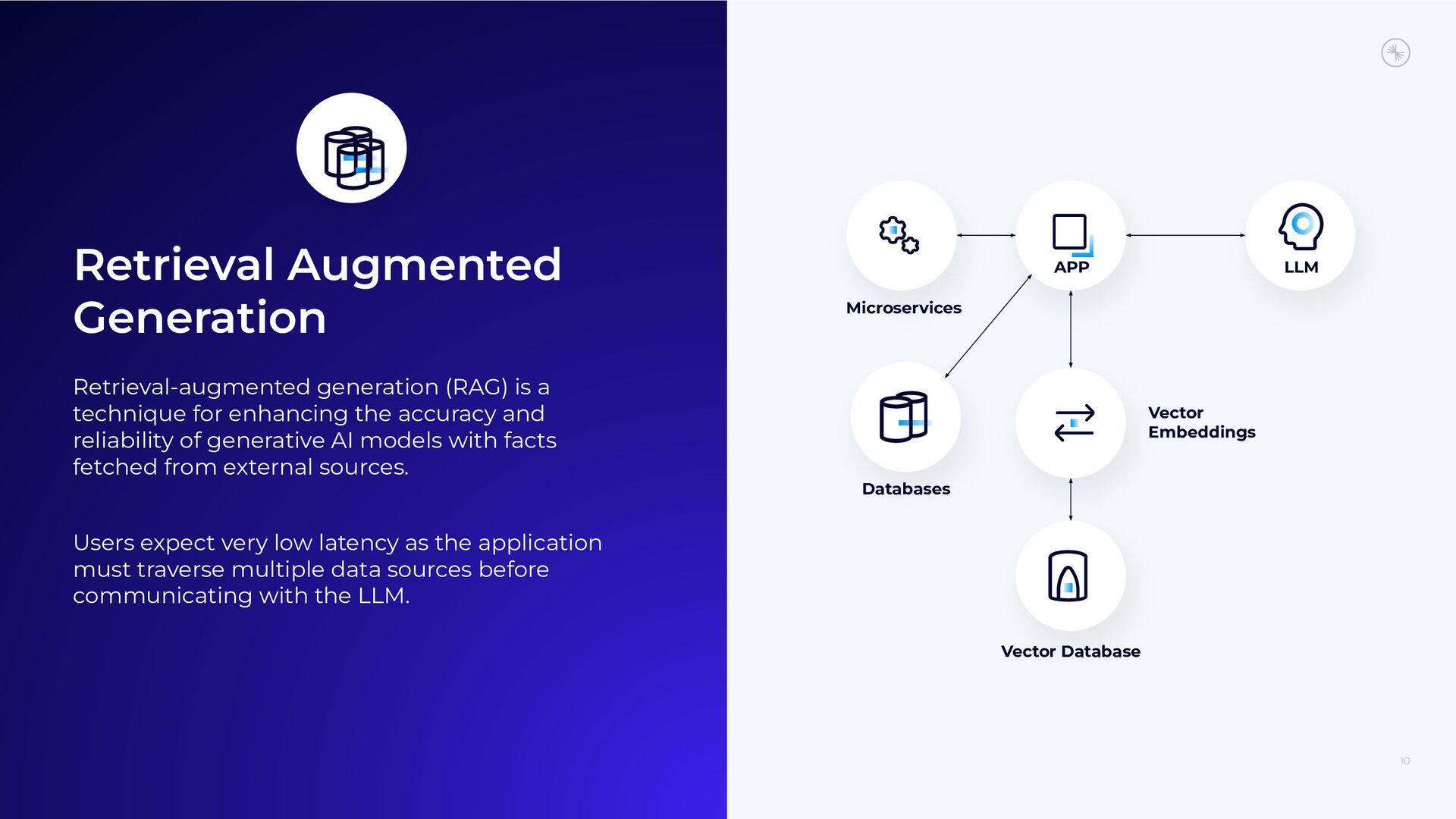{kind=link}
{kind=link}
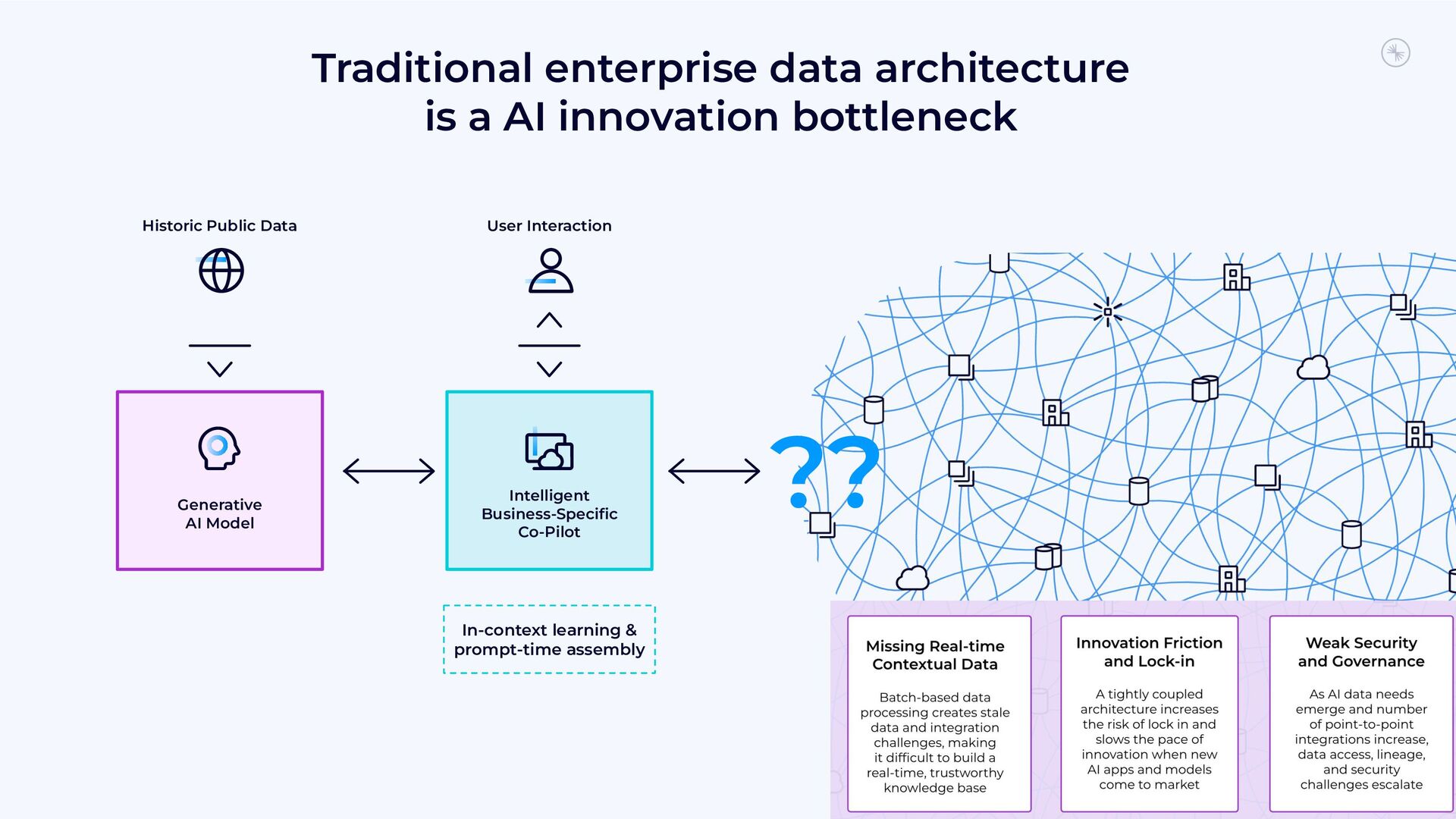{kind=link}
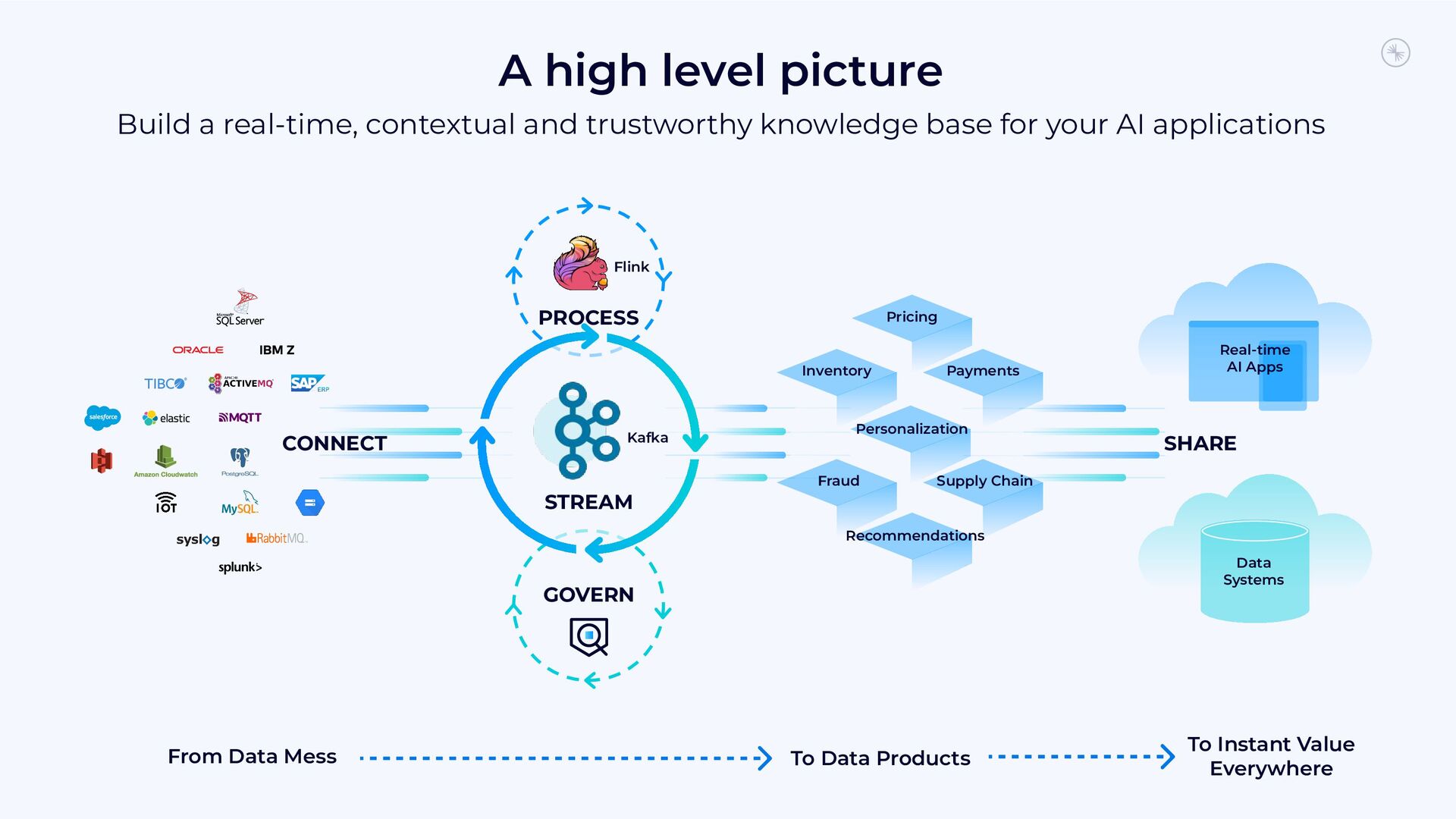{kind=link}
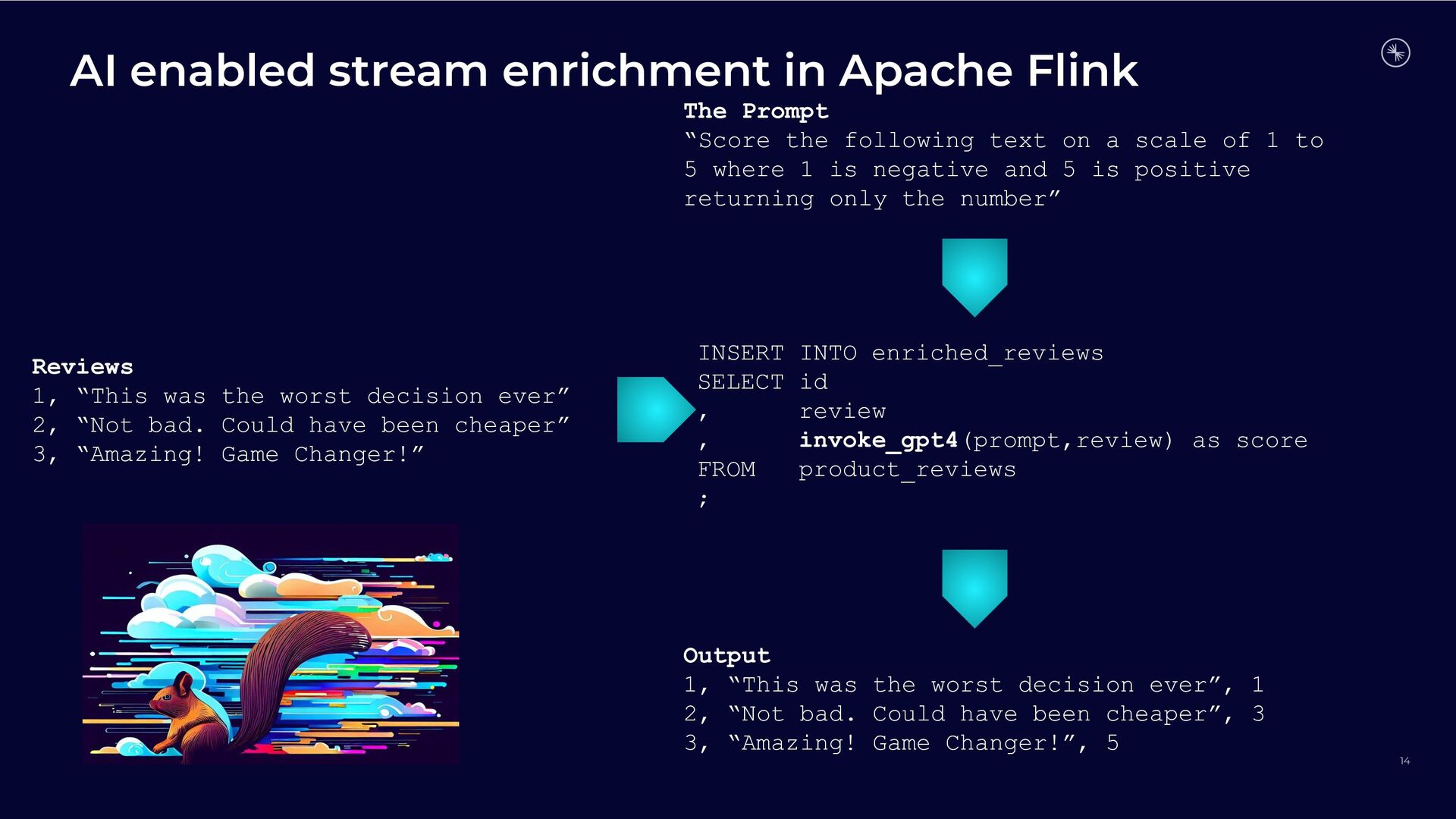{kind=link}
{kind=link}
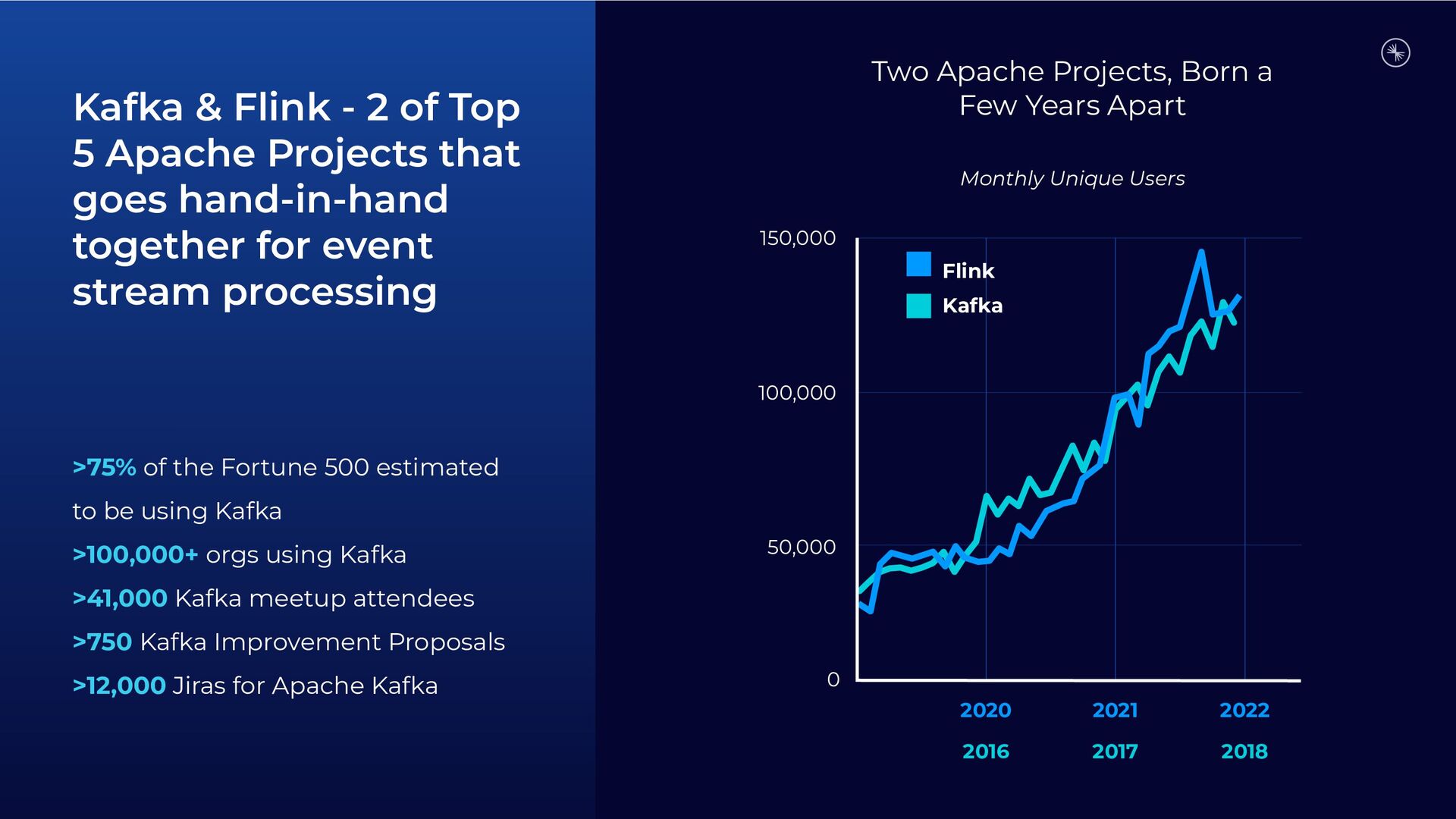{kind=link}
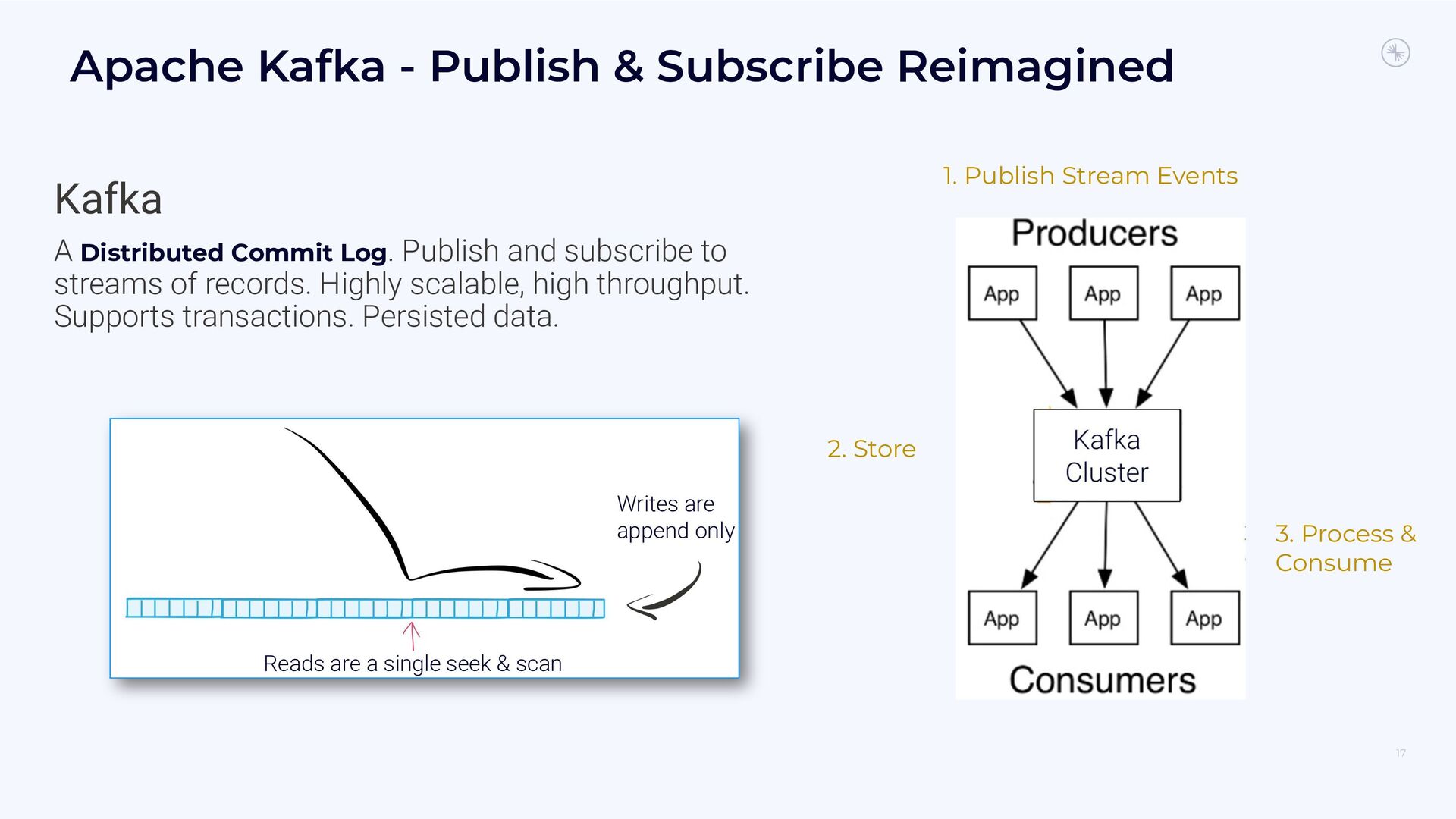{kind=link}
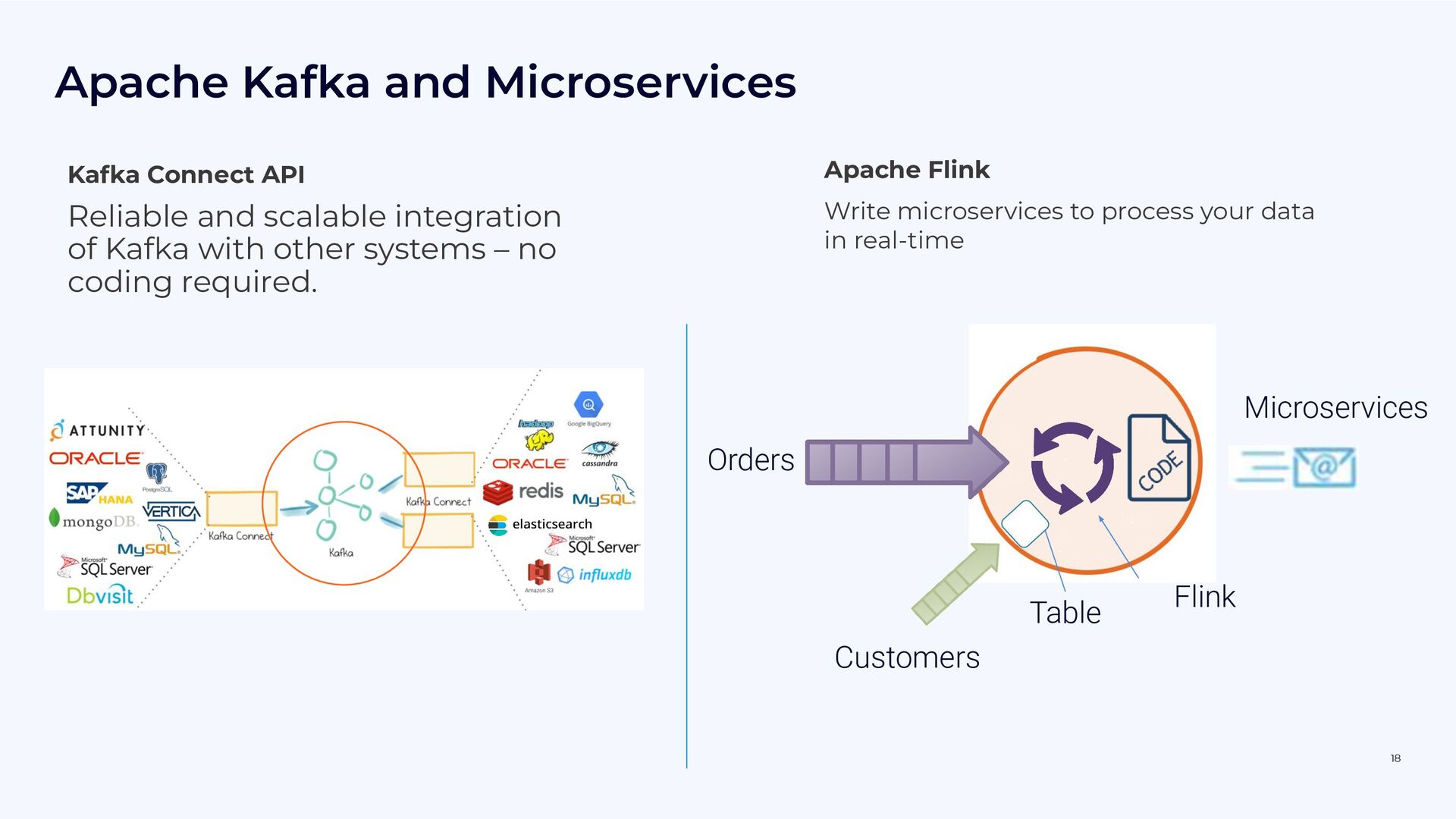{kind=link}
{kind=link}
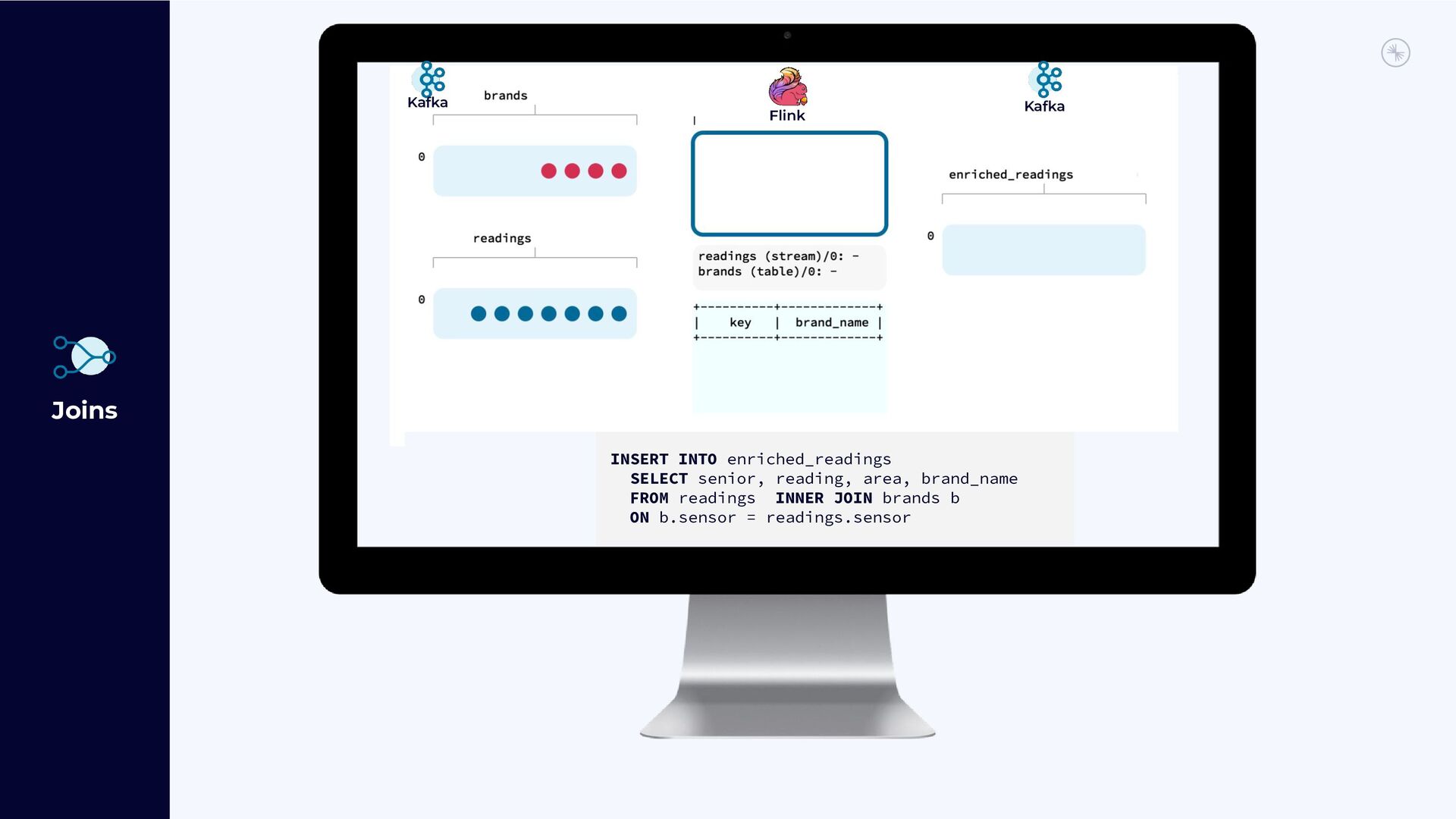{kind=link}
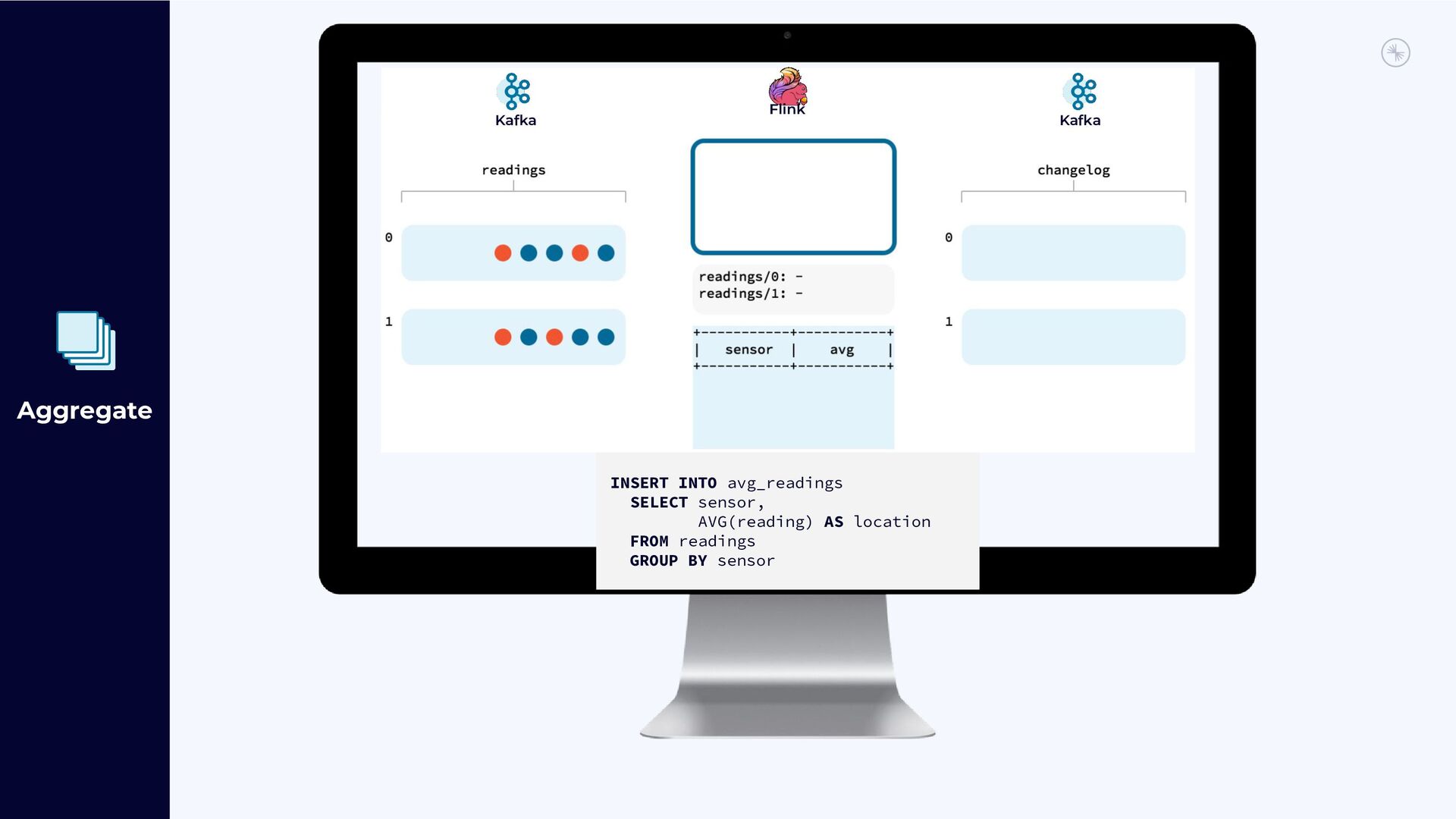{kind=link}
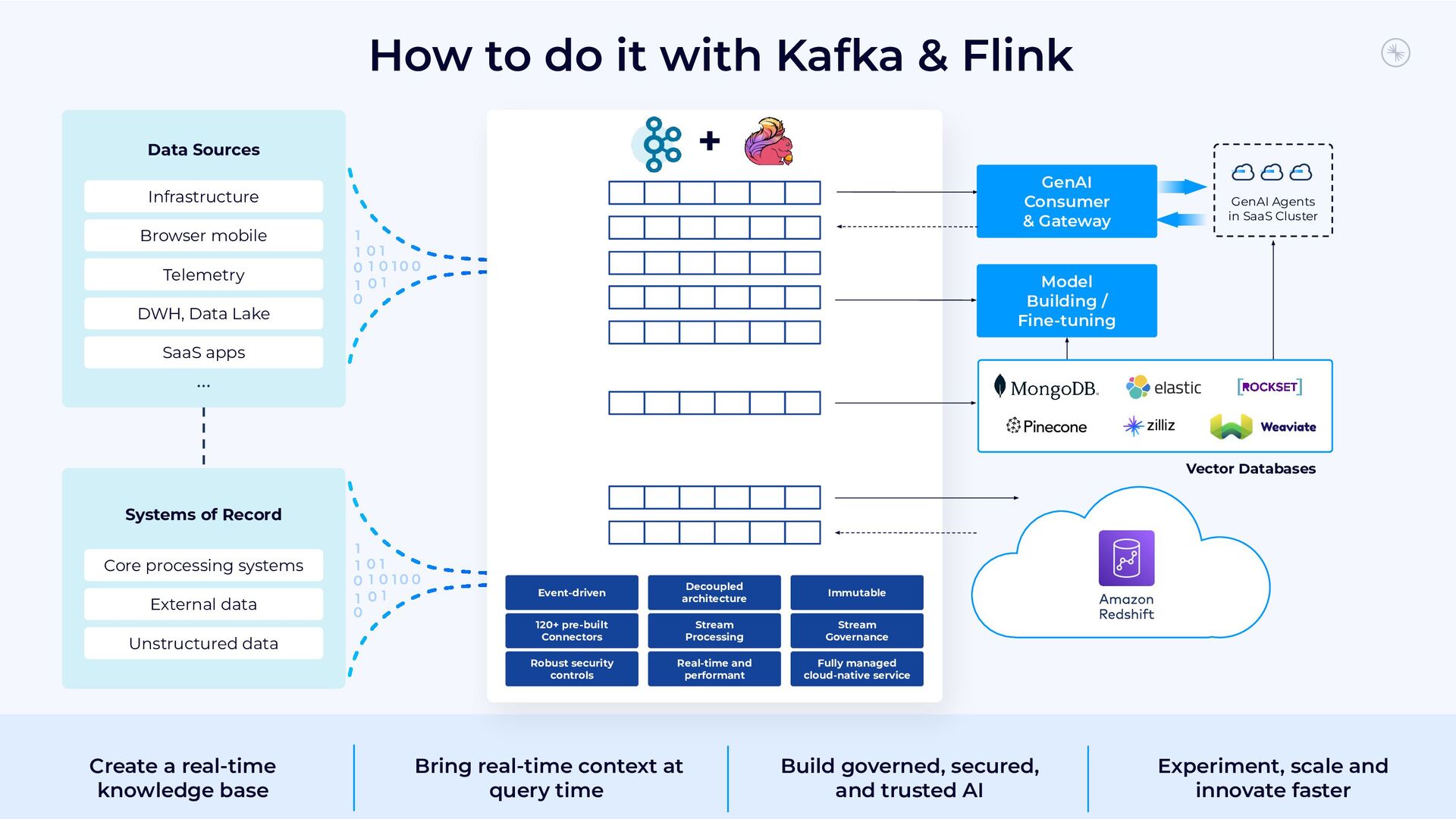{kind=link}
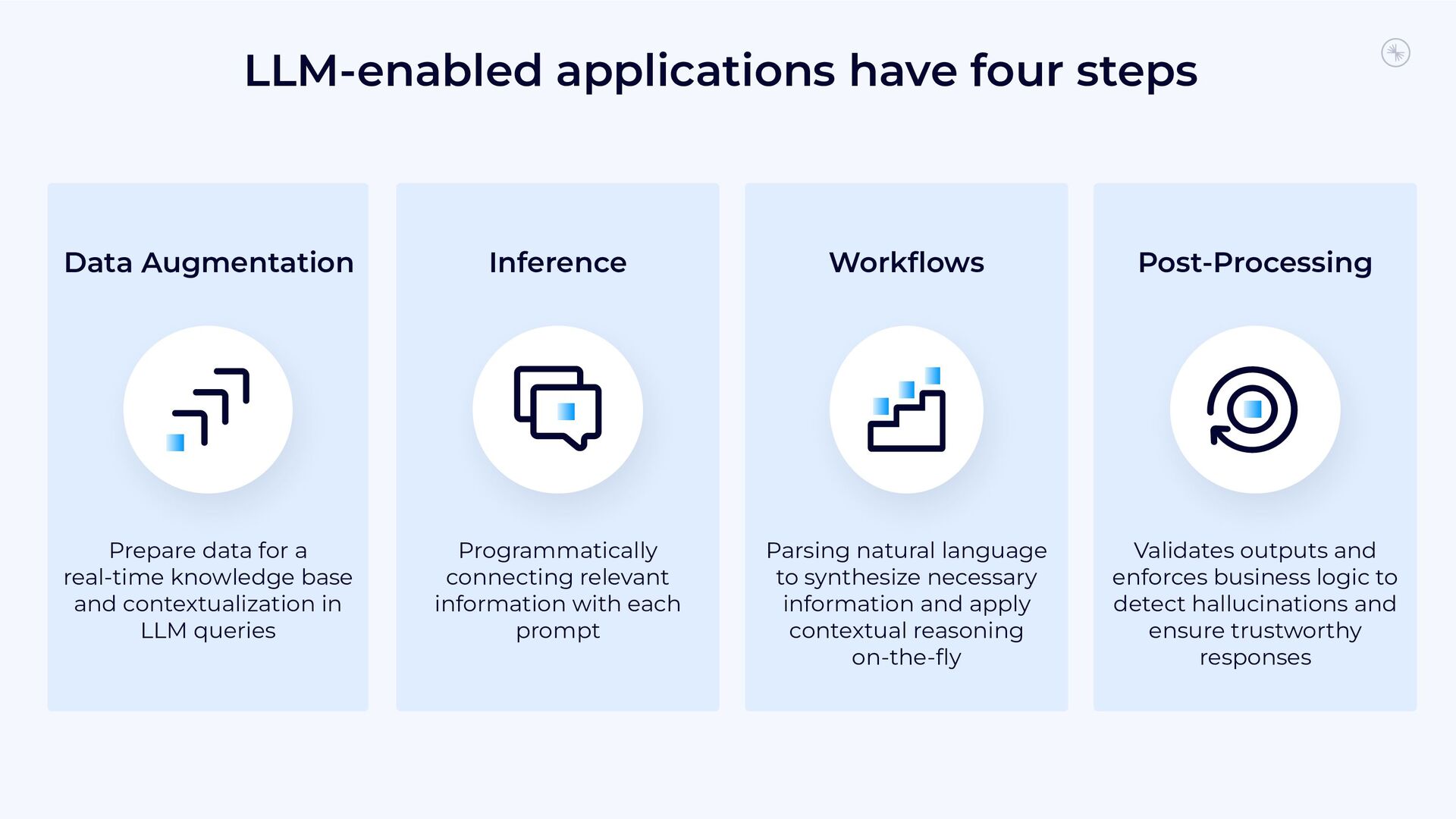{kind=link}
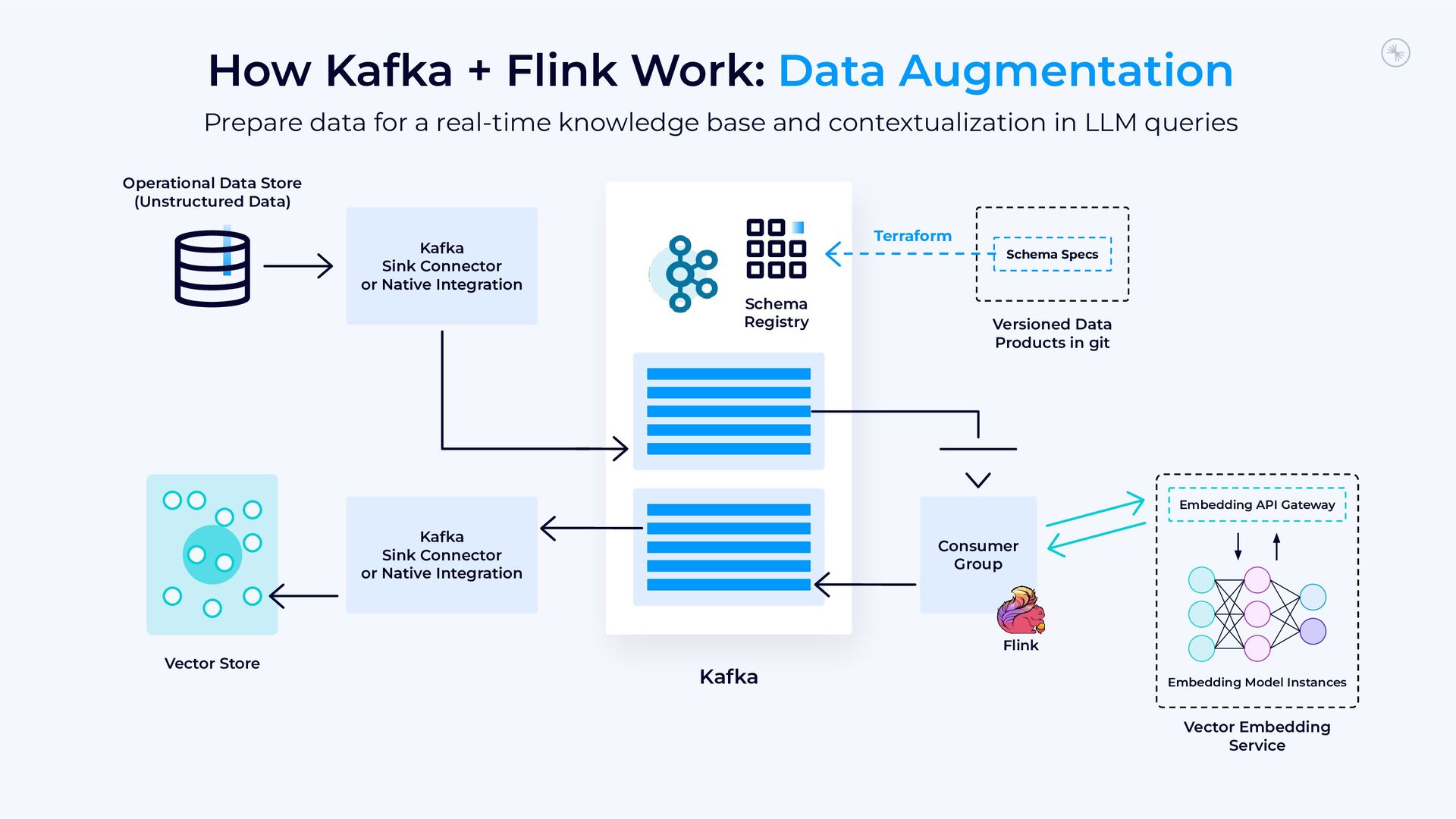{kind=link}
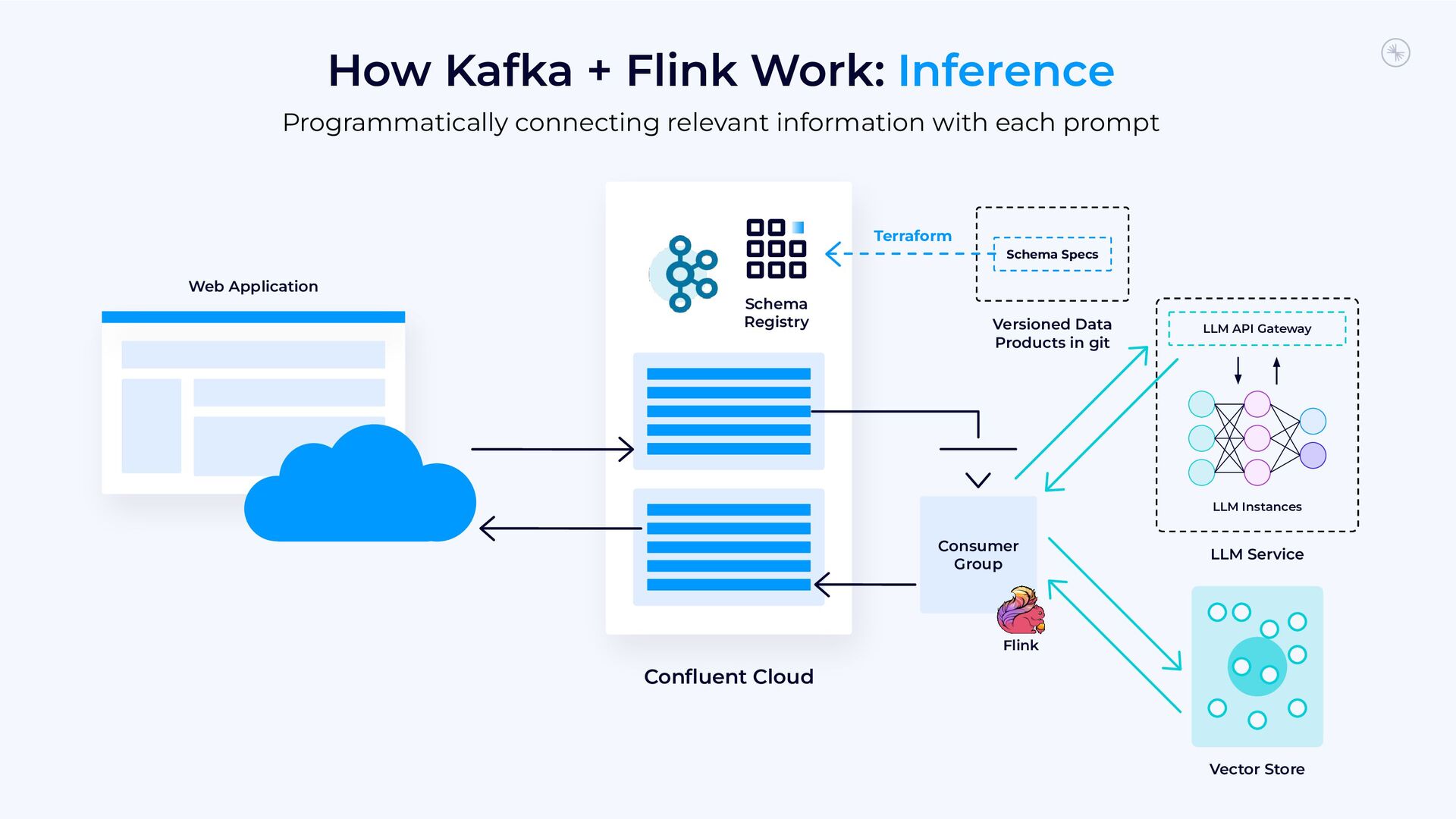{kind=link}
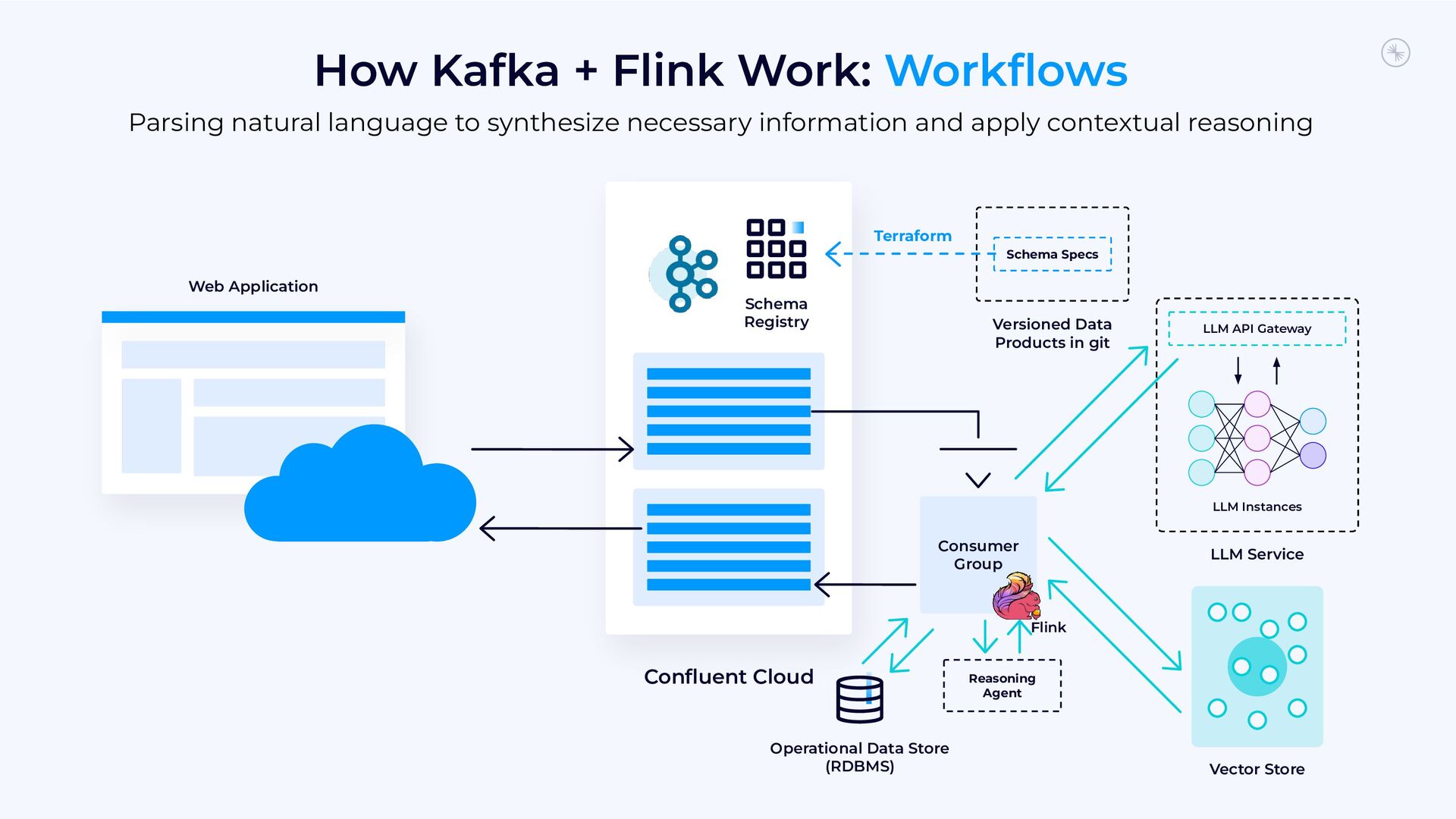{kind=link}
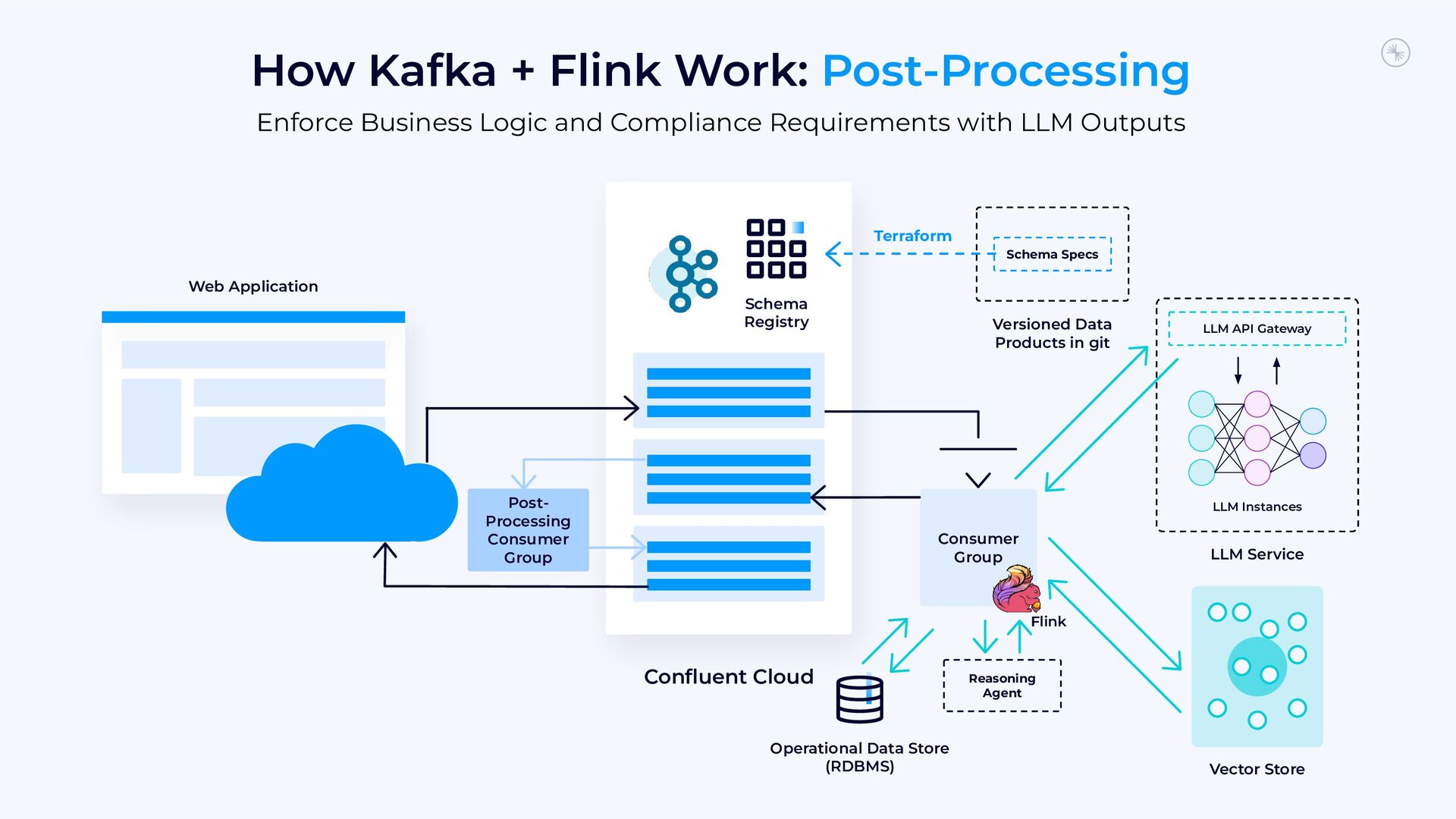{kind=link}
{kind=link}
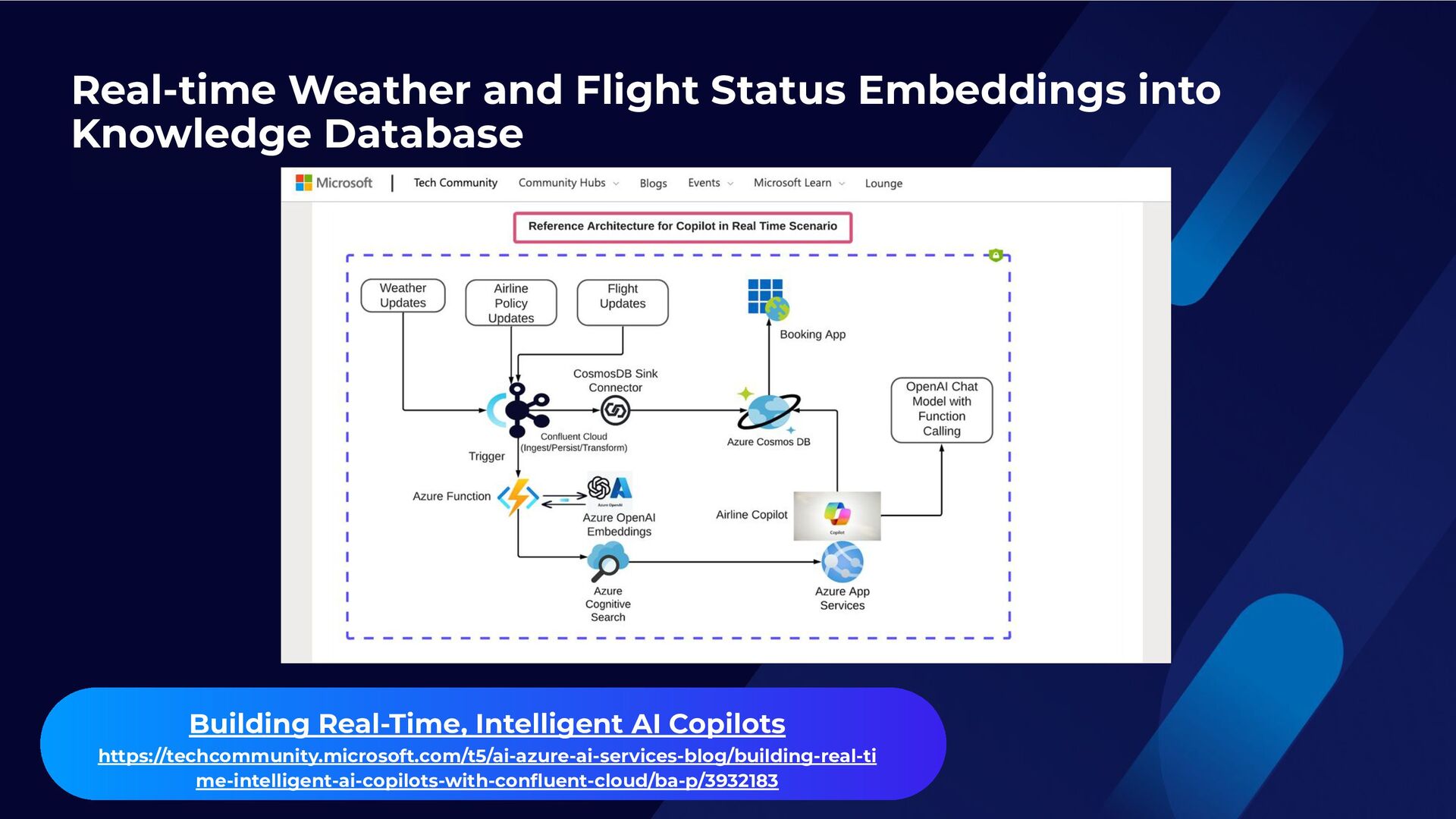{kind=link}
{kind=link}
{kind=link}
{kind=link}
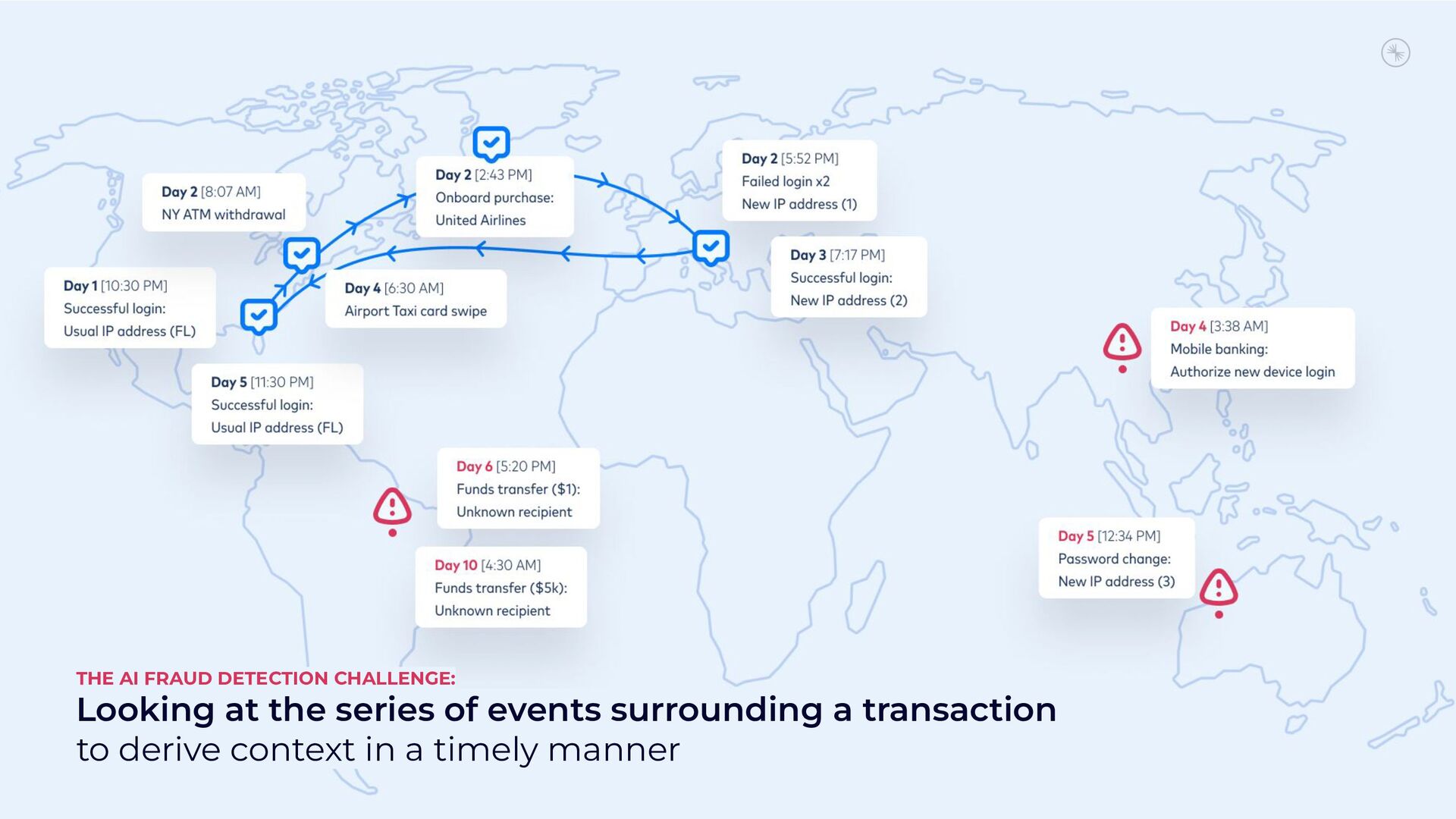{kind=link}