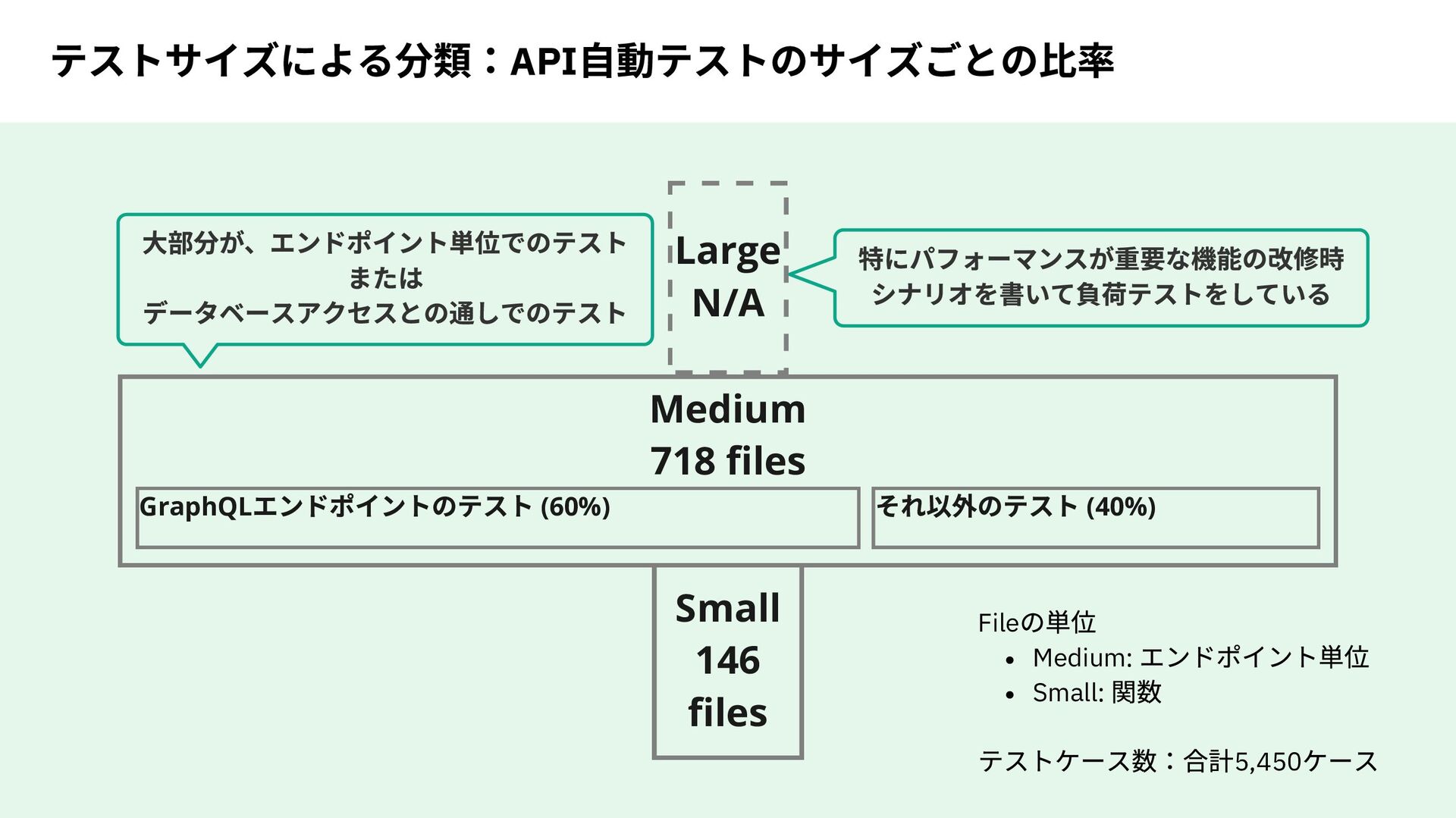
テスト中のデータベースアクセスを記録して、利用したテーブルのみ自動でtruncate するこ とでデータクリーンアップを高速化。 方法 Machine #1 Database process on Docker Test worker #1 Test worker #2 Test worker #3 Test worker #4 Test database #1 Test database #1 Test database #1 Test database #1 x N 台 参考 テストファイルの総数は864 件 (5,450 件のテストケース) GitHub Actions 上の 8 core / 32 GB Memory のマシン4 台で15 分 で実行可能
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}