In the simplest form, deploying to nomad involves creating a job.hcl file and executing a Nomad job run. While this approach can work well with a few dozen jobs, it performs less so when attempting to apply best practices to thousands of jobs across hundreds of repositories. This talk will cover different patterns to interacting with Nomad deployments at while enforcing an organization's best practices and security standards.
{kind=link}
{kind=link}
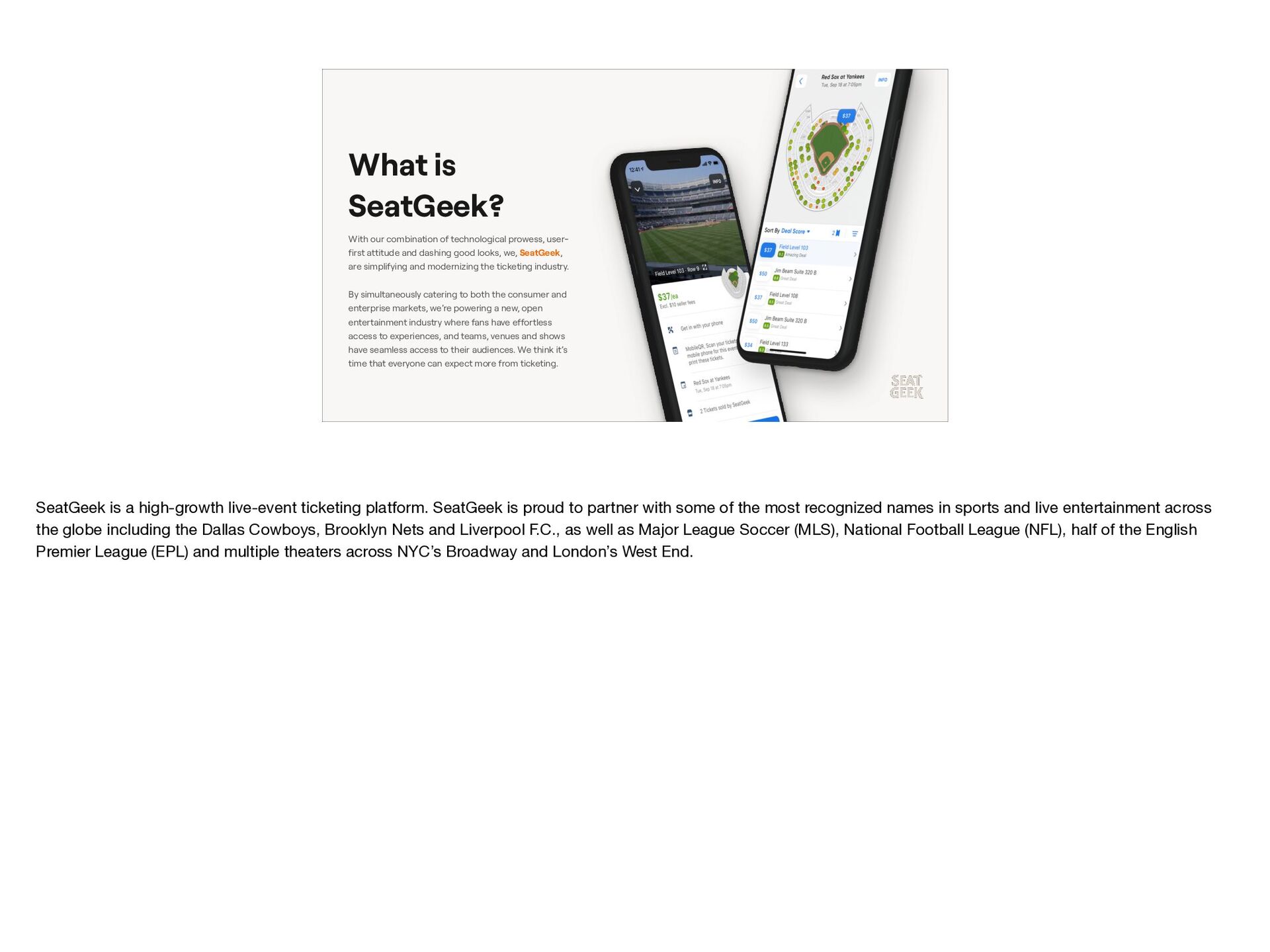{kind=link}
{kind=link}
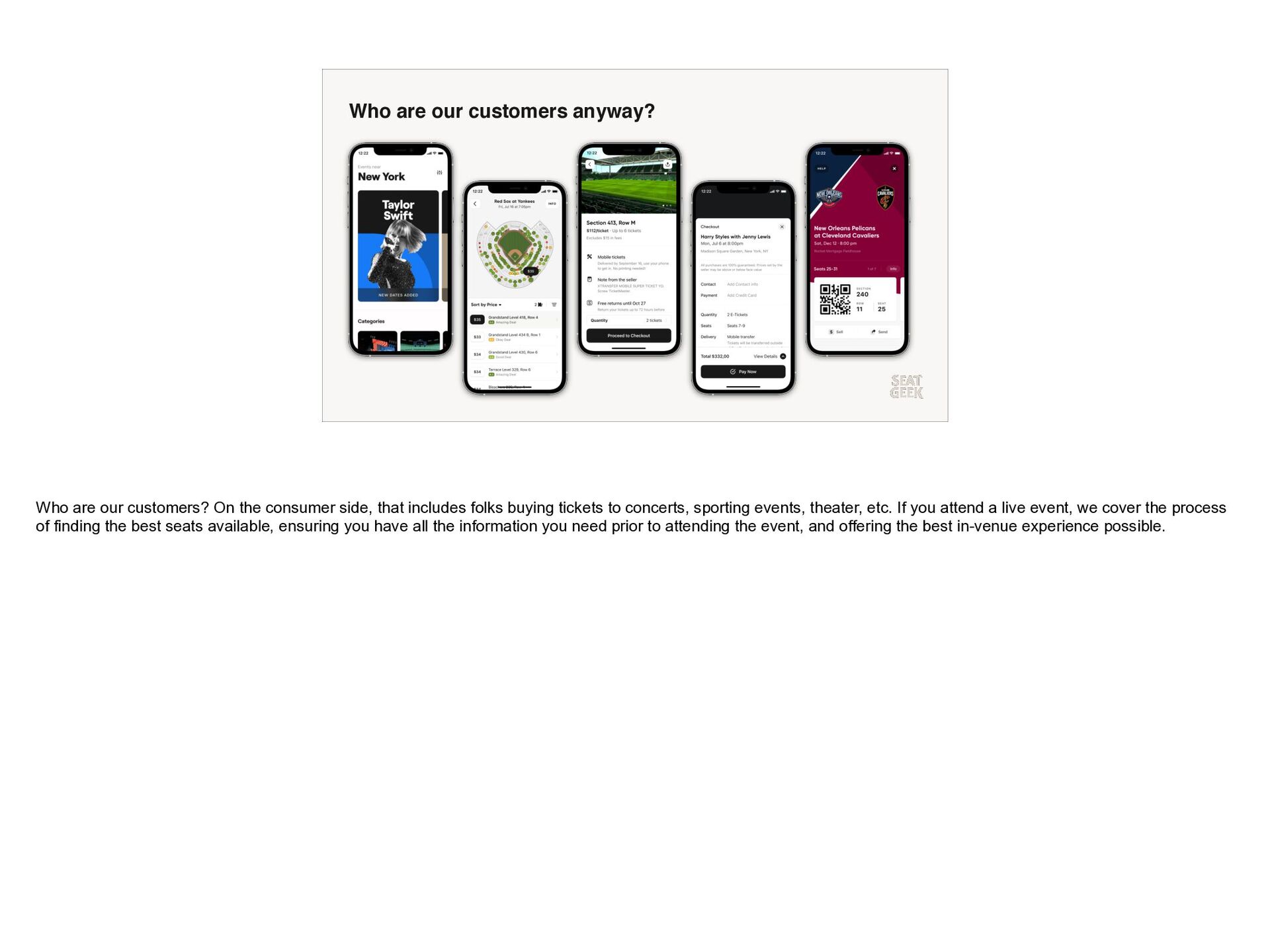{kind=link}
{kind=link}
{kind=link}
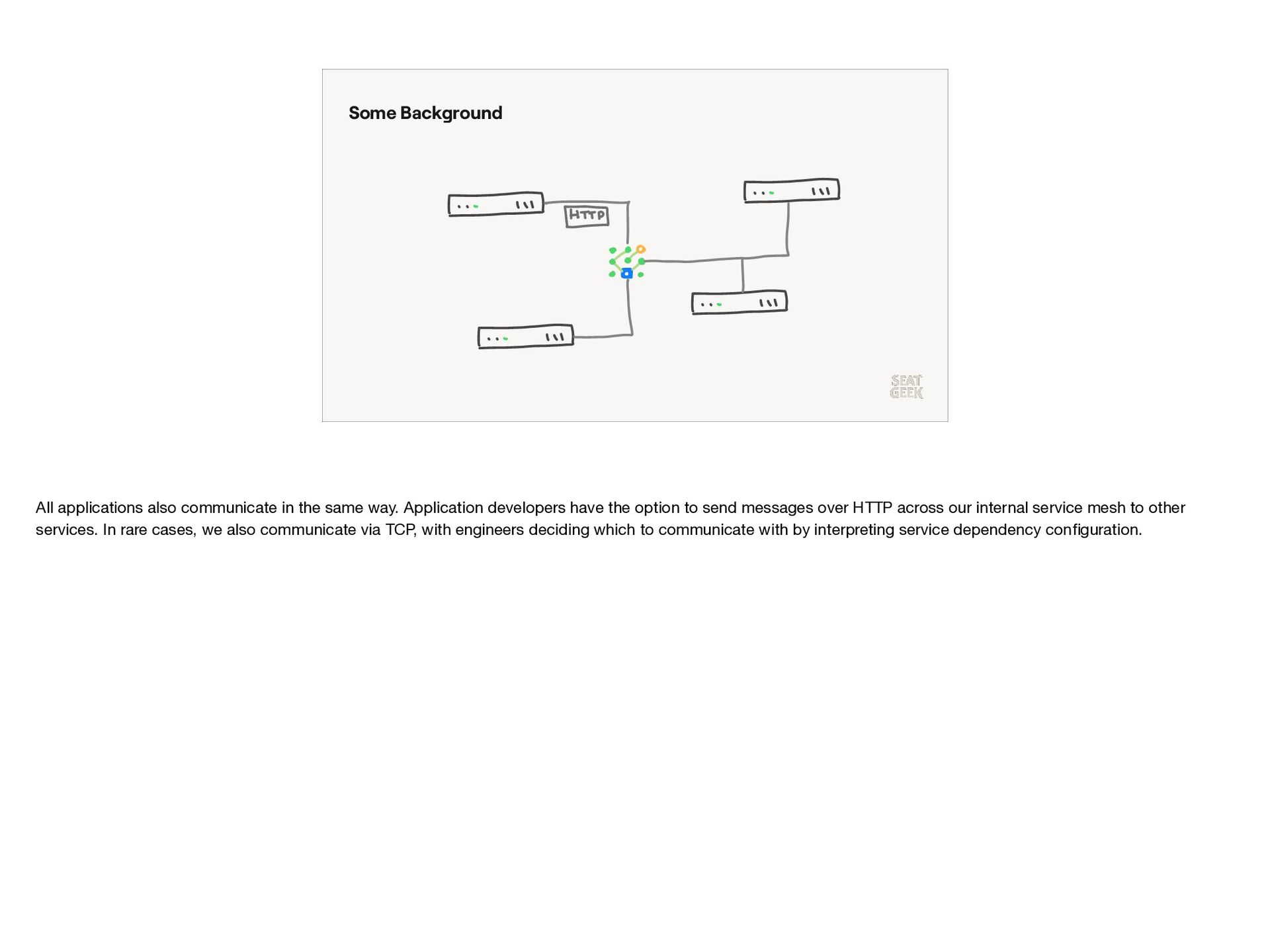{kind=link}
{kind=link}
{kind=link}
{kind=link}
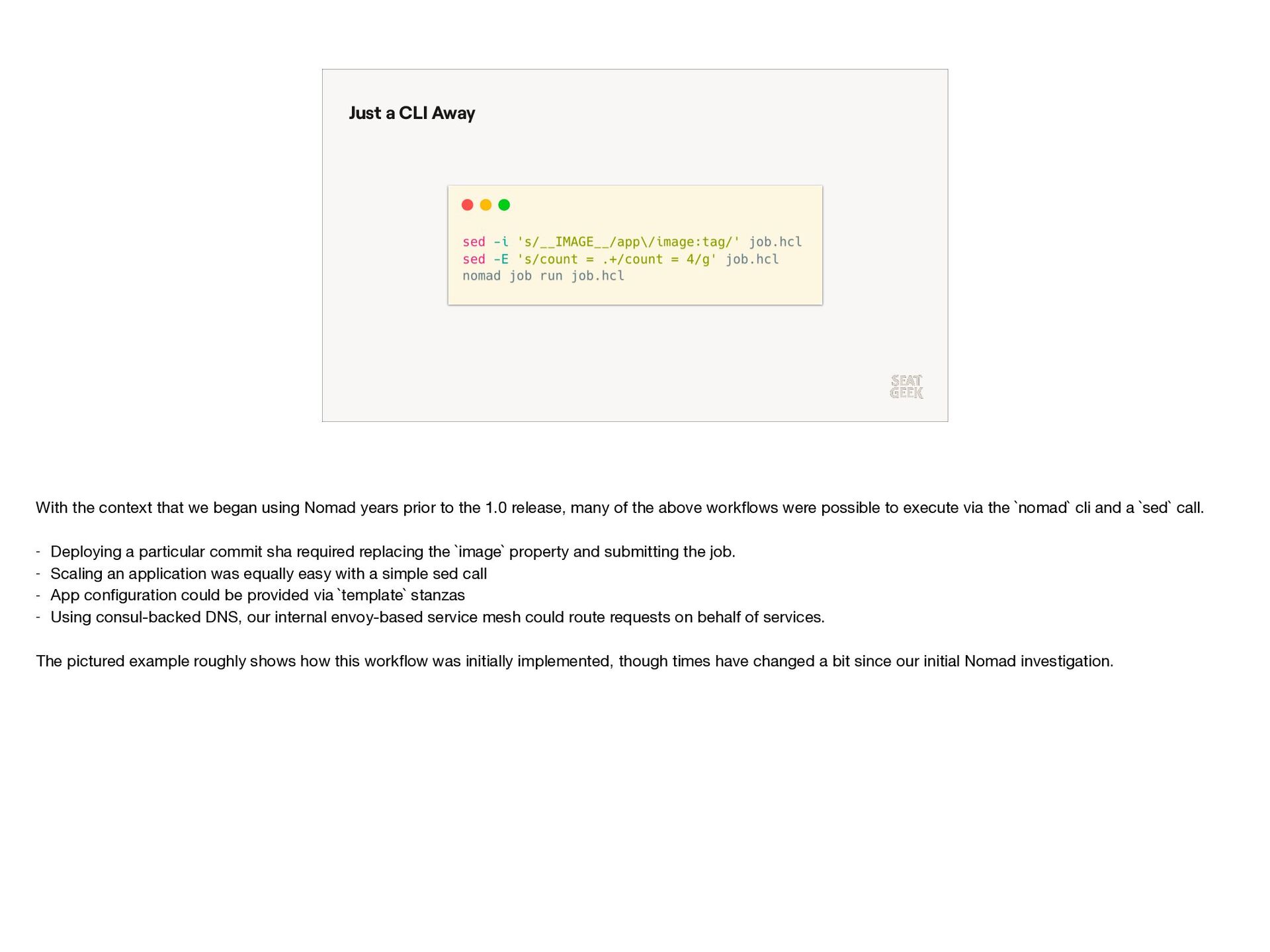{kind=link}
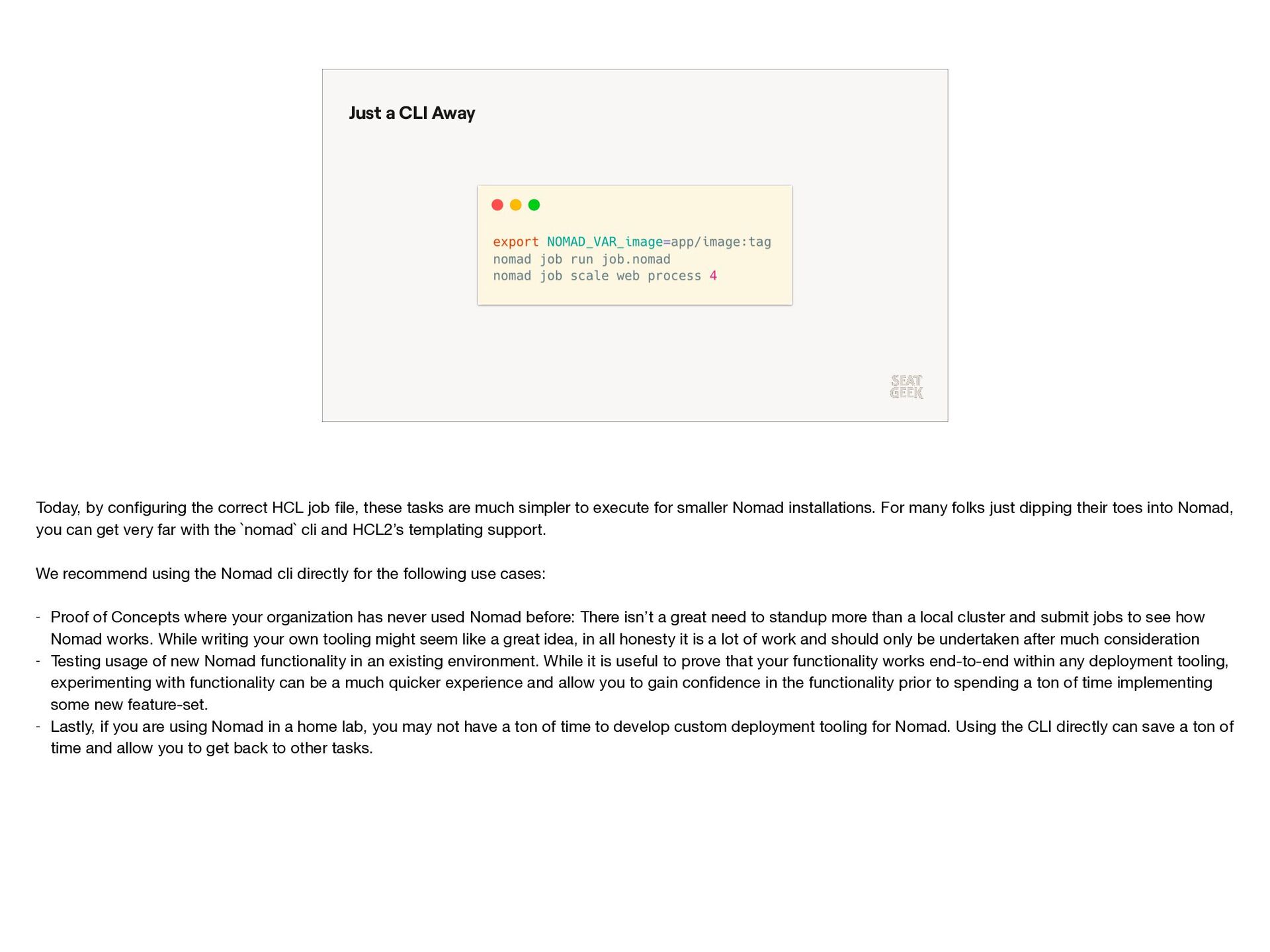{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
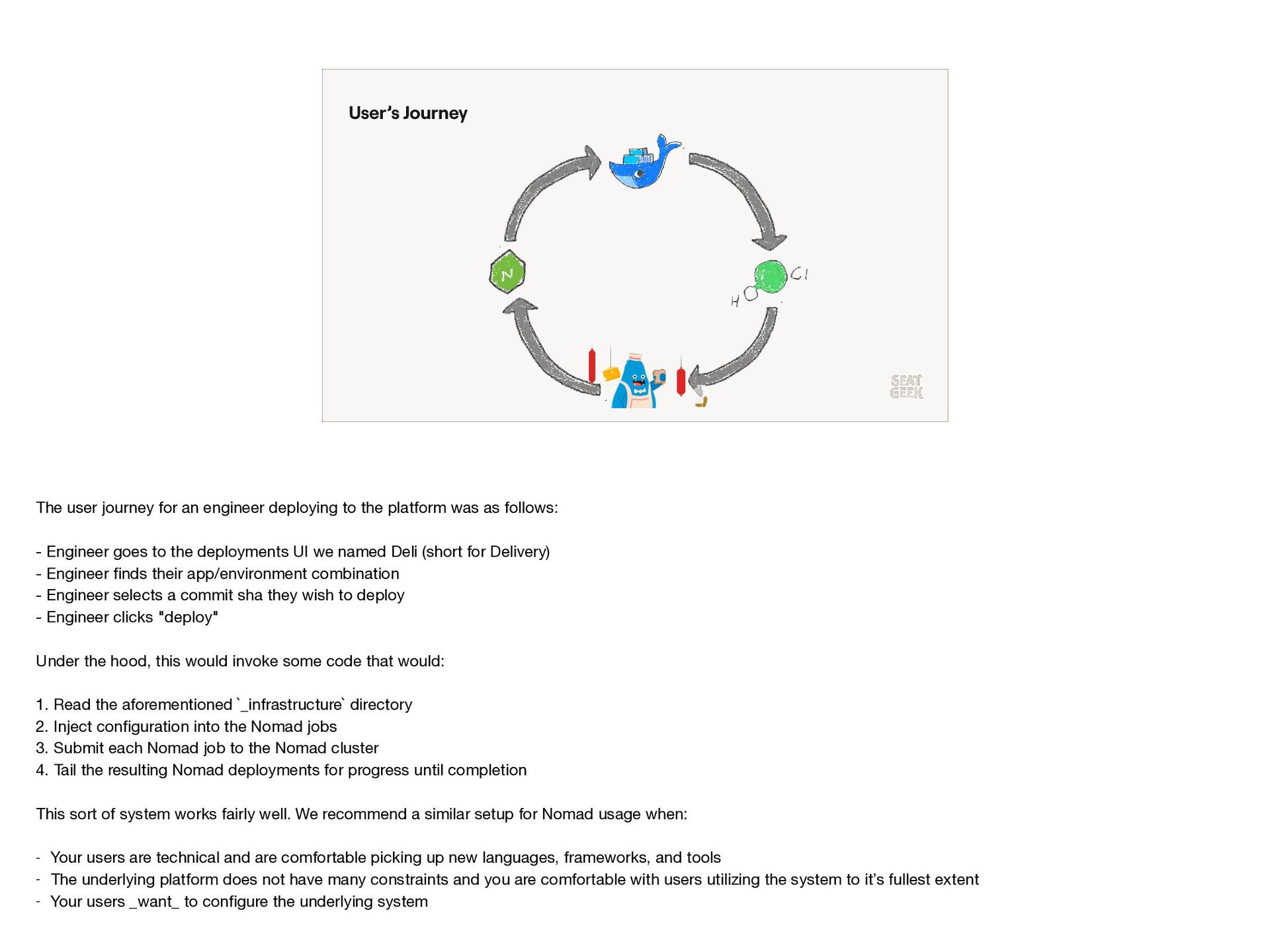{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
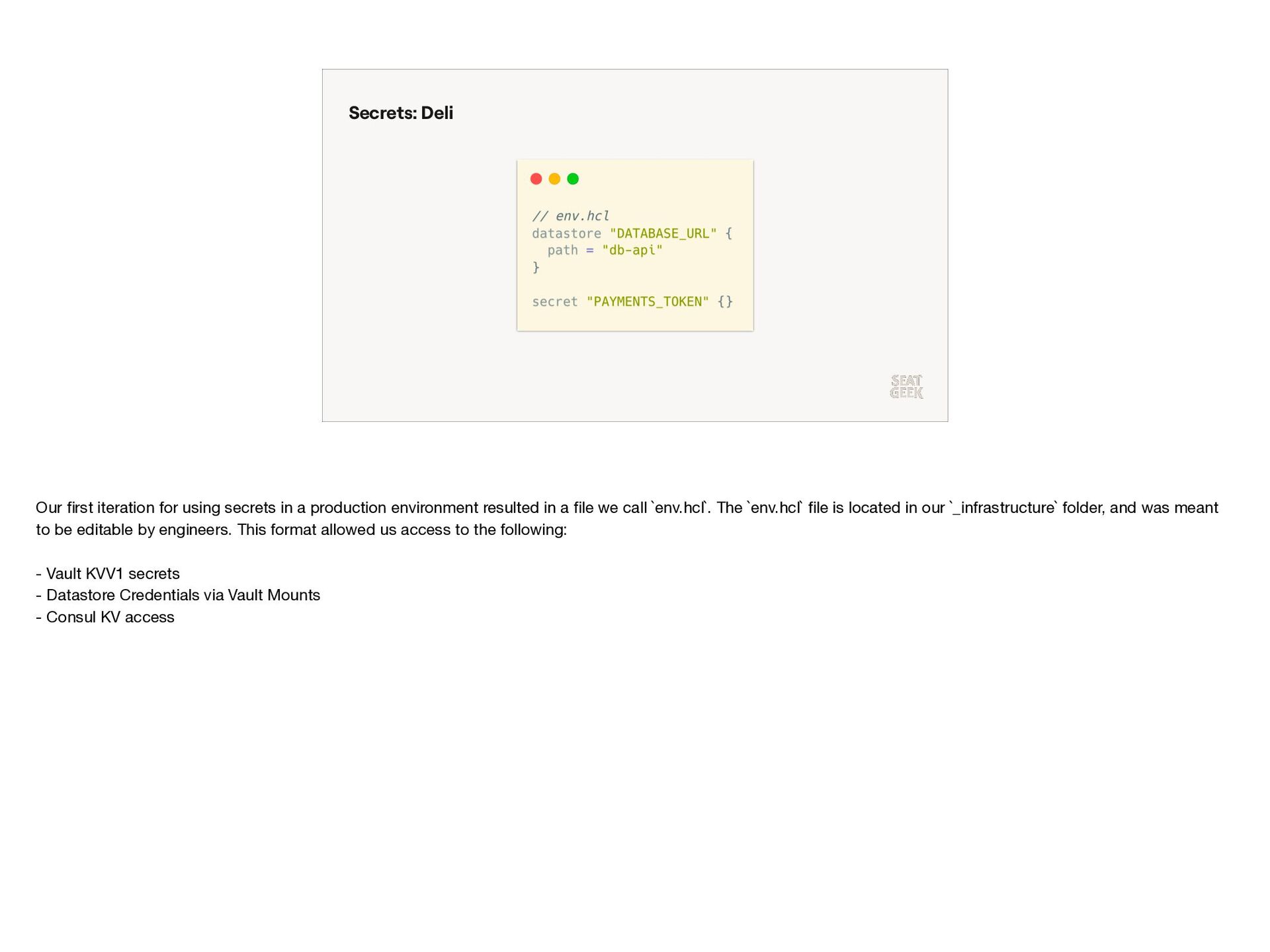{kind=link}
{kind=link}
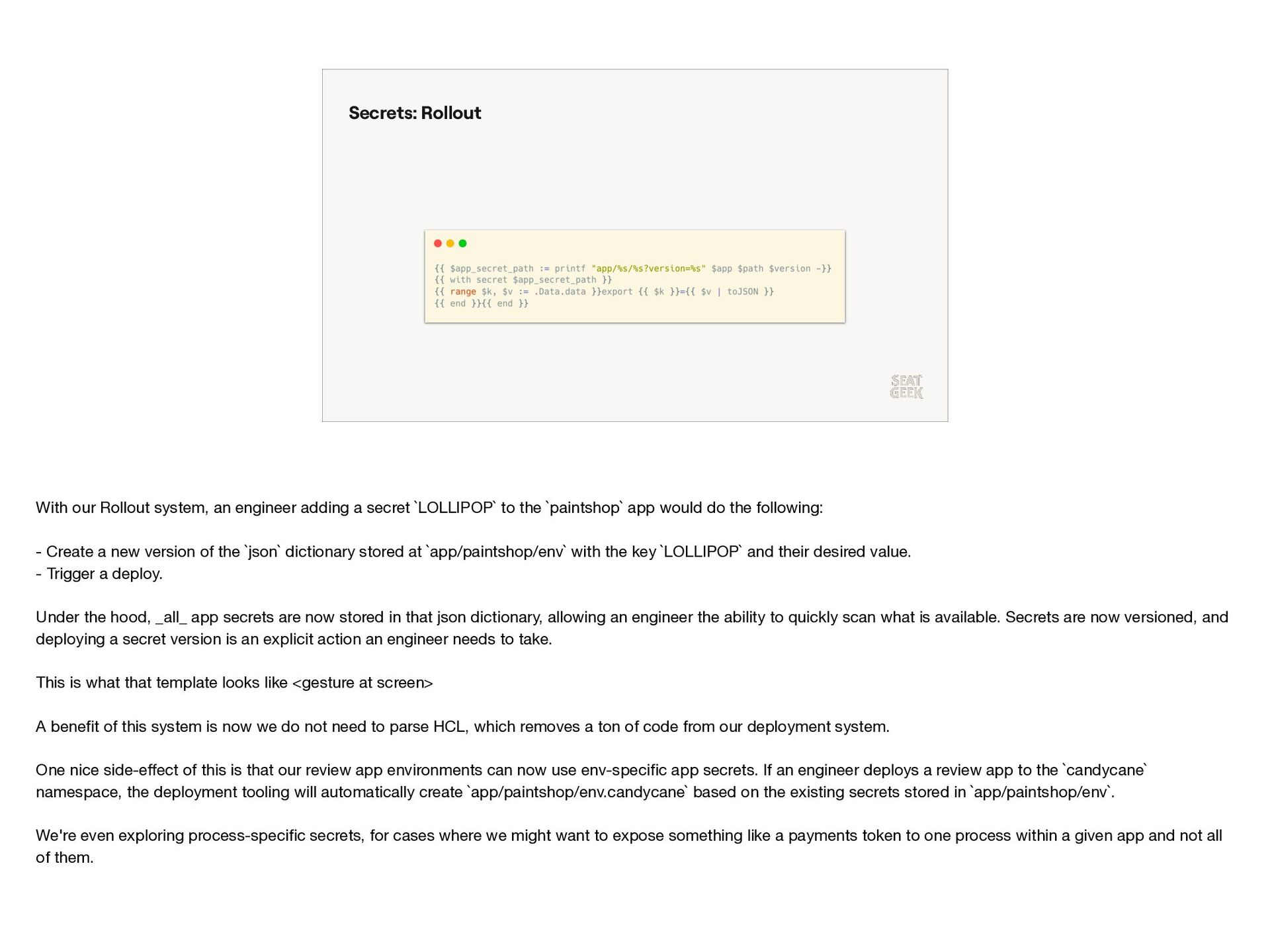{kind=link}
{kind=link}
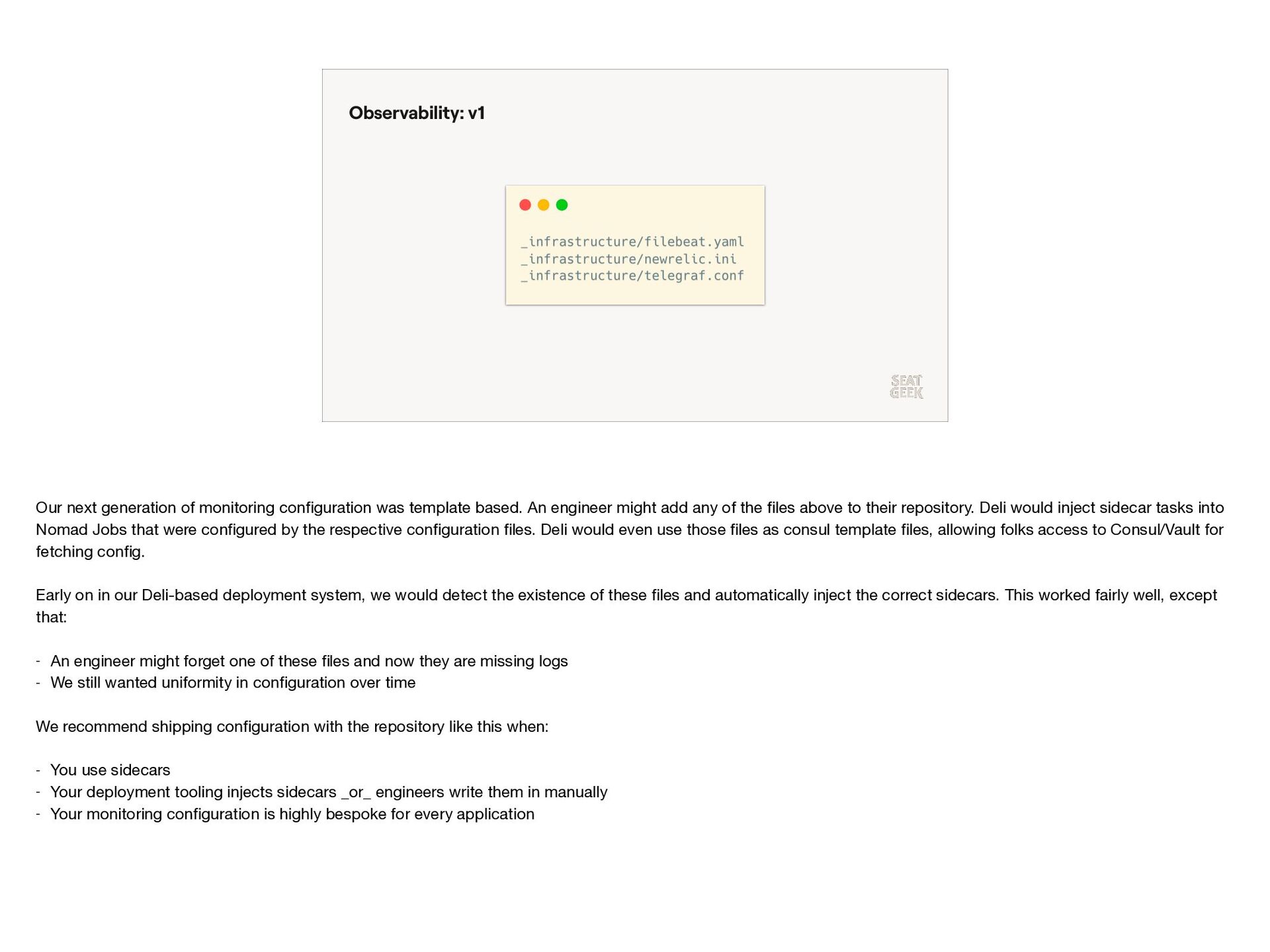{kind=link}
{kind=link}
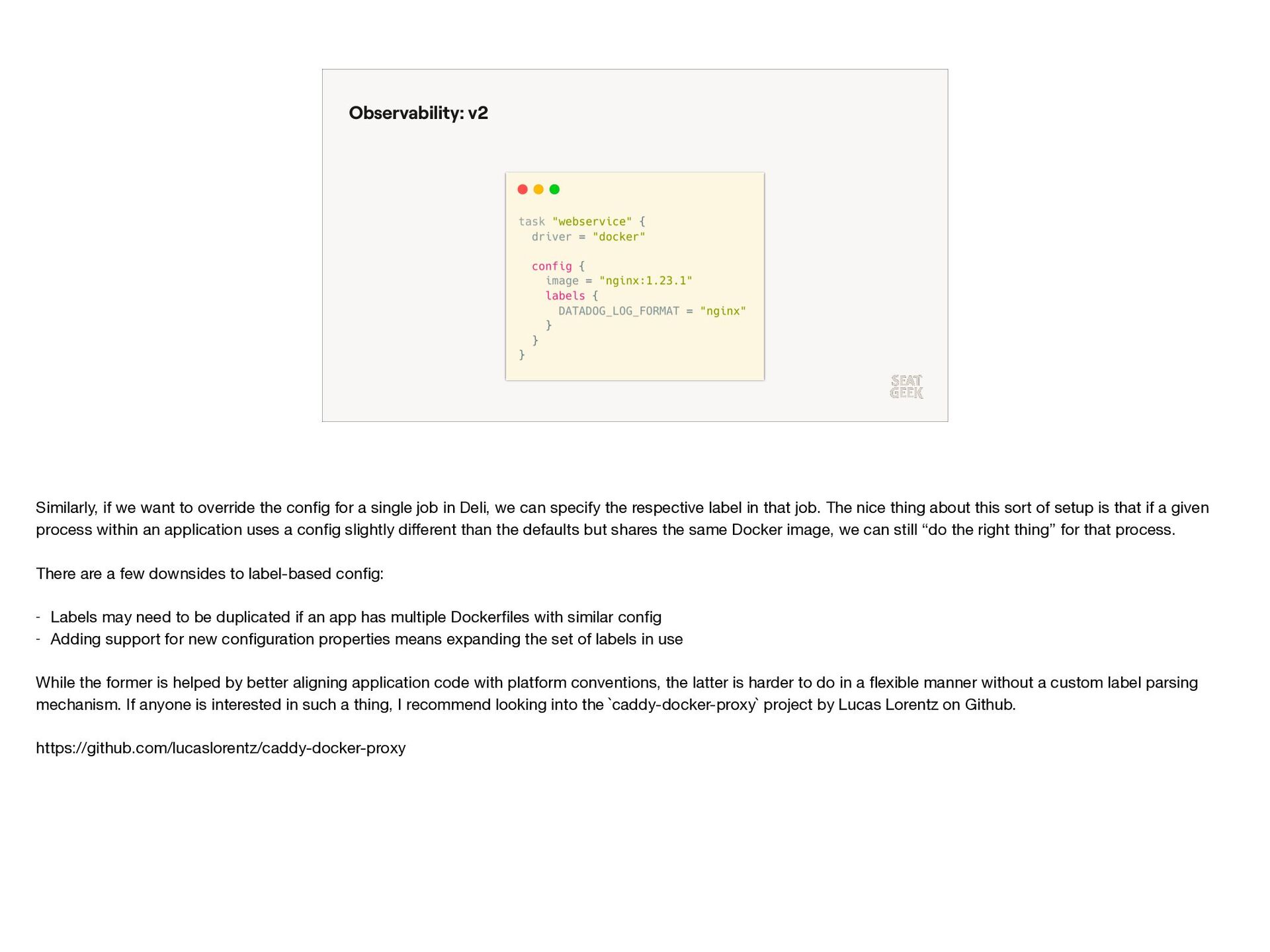{kind=link}
{kind=link}
{kind=link}
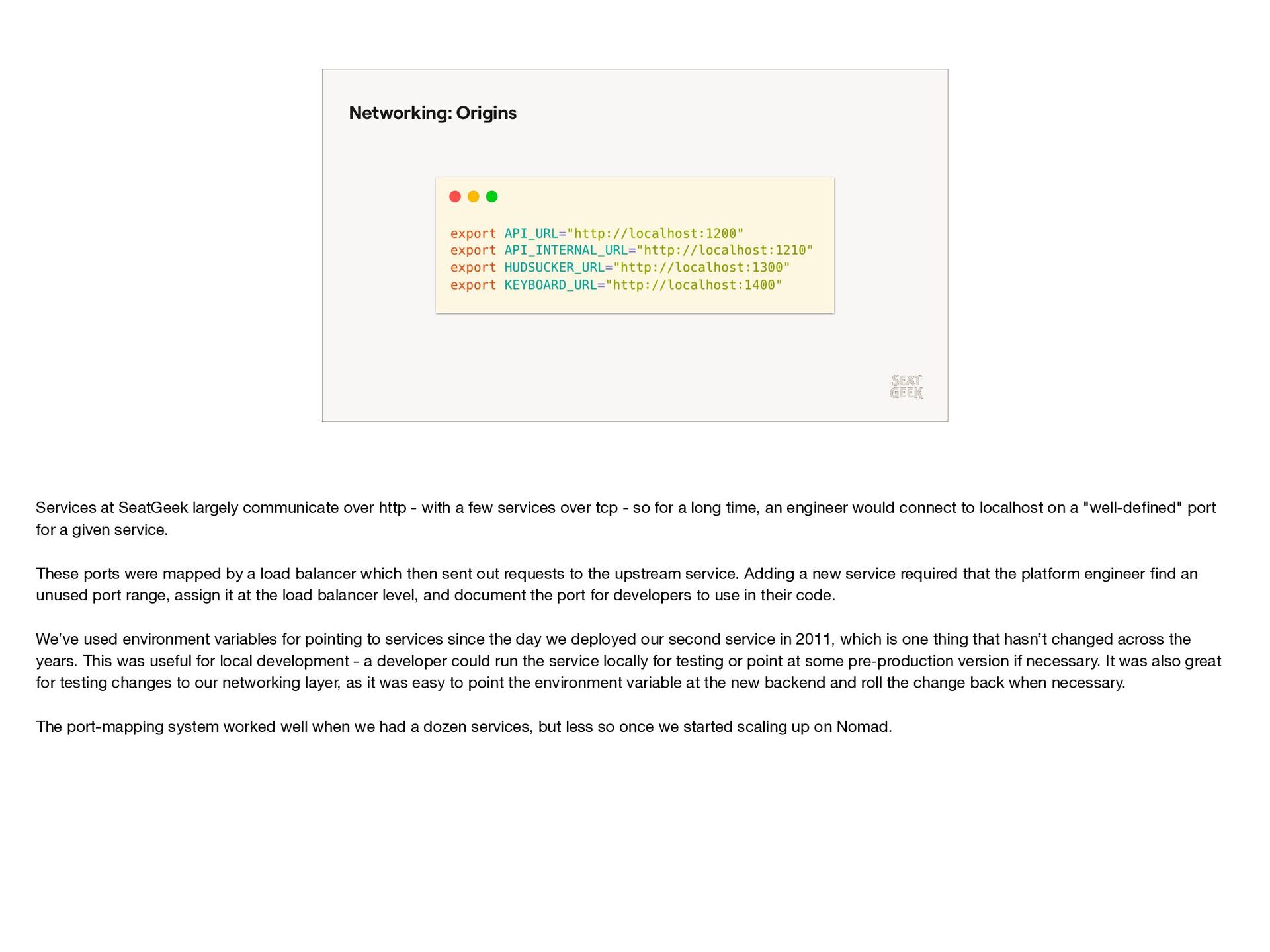{kind=link}
{kind=link}
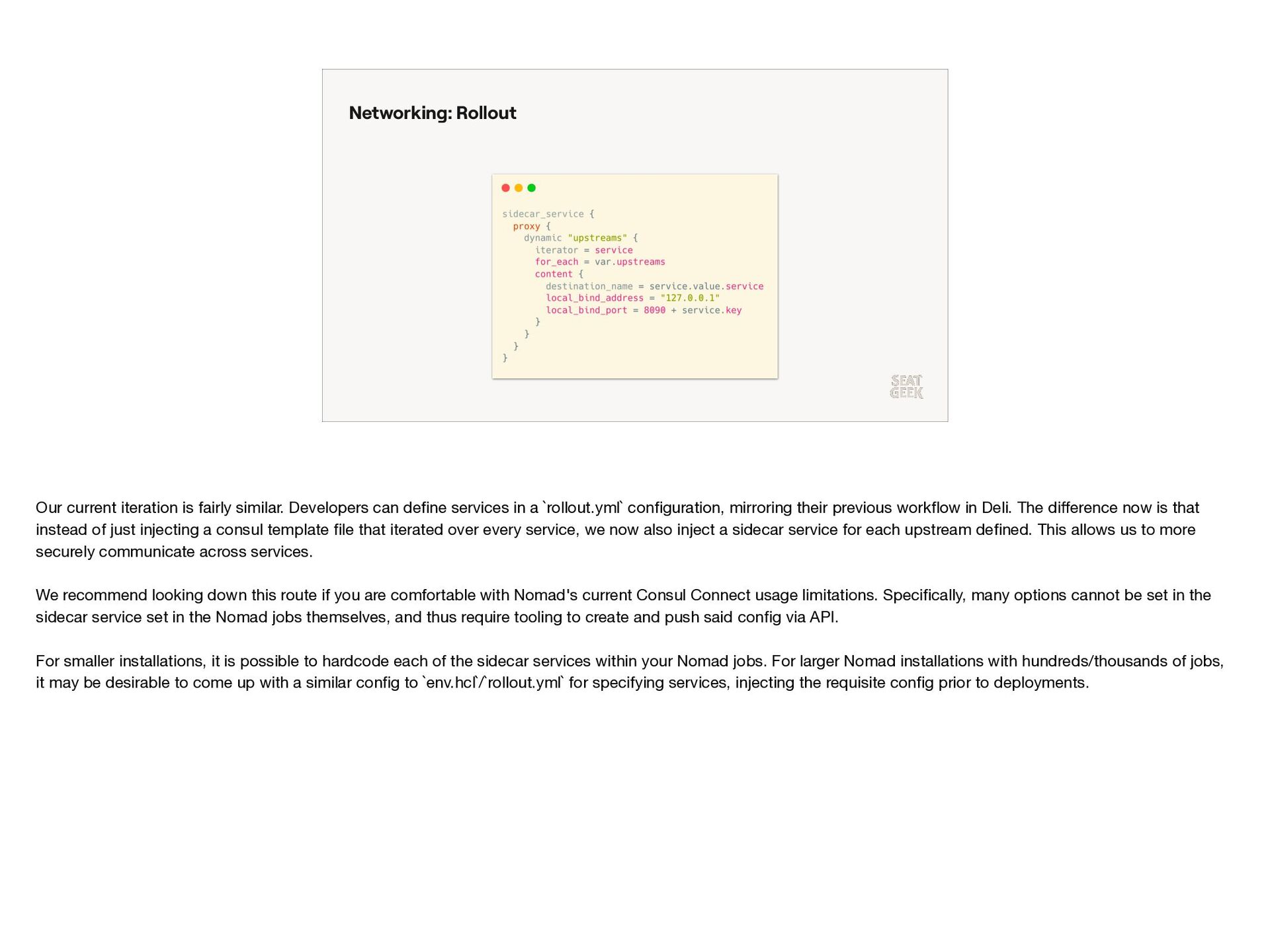{kind=link}
{kind=link}