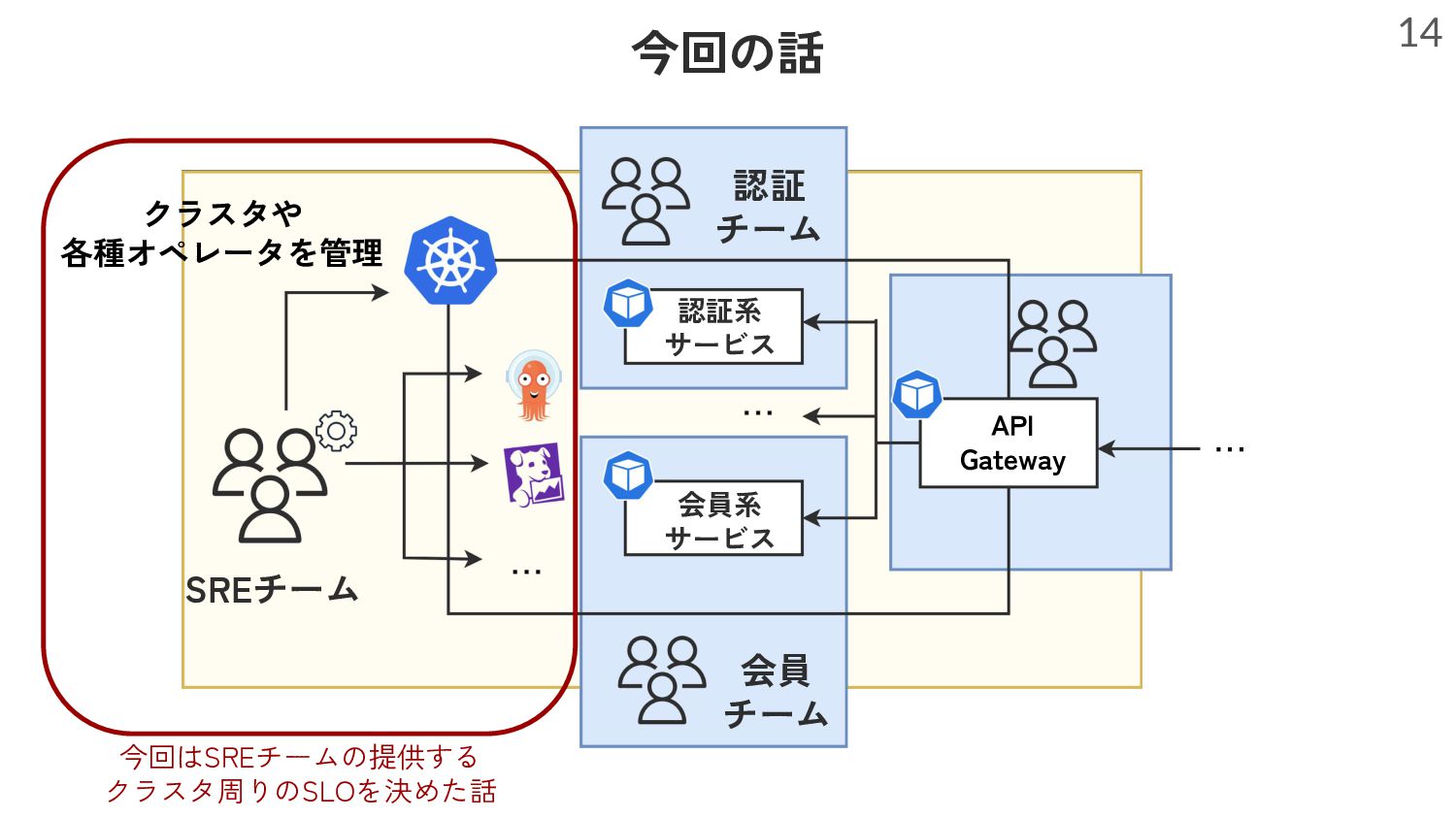
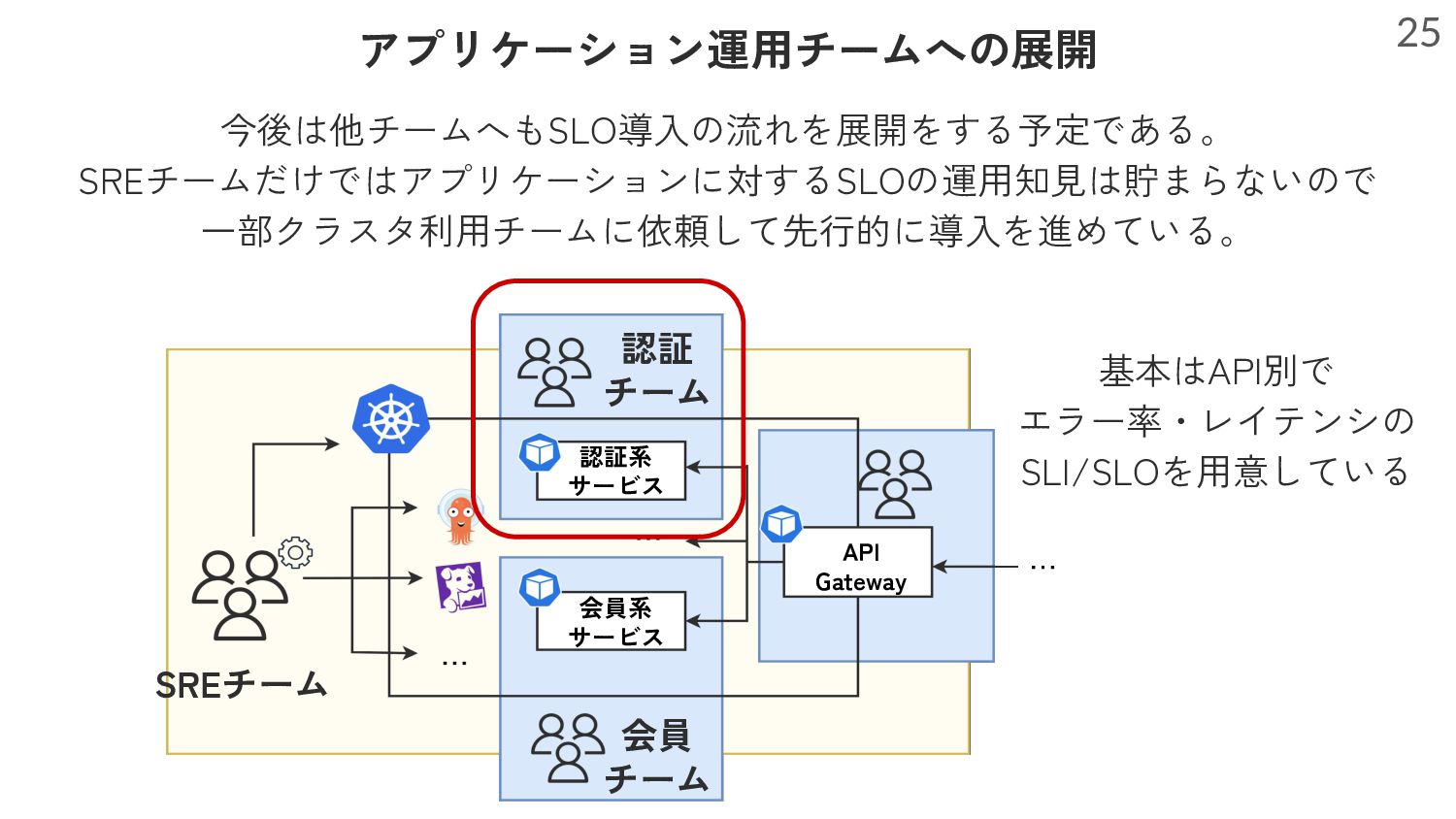
ゼロベースでSLOの存在意義はなにか?適切なSLIはどうやって決めるのか?を考察・調査し、まずはプラットフォームの一部のチームでSLOを策定しました。それまでの苦労を含めてSLOがなぜ必要か、またSLIをどのように決めたのか等お話します。
Cloud Operator Days Tokyo 2023で使用したスライドです。
Service C 後続のサービスが障害を起こしたときはAPI Gateway自身の SLIの値も低下する(個別のServiceごとにSLIを作ってもこの問題は発生する) Service Aがダウンしたときユーザー体験をSLIは適切に表現しているが API Gateway自身に問題はなくてもAPI GatewayのBurn Rate Alertが発火する API Gatewayの後続にサービスが増えるほど発火する機会も増える 正常に稼働しているが エラー率が高くなる エラー率が 高くなる
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}