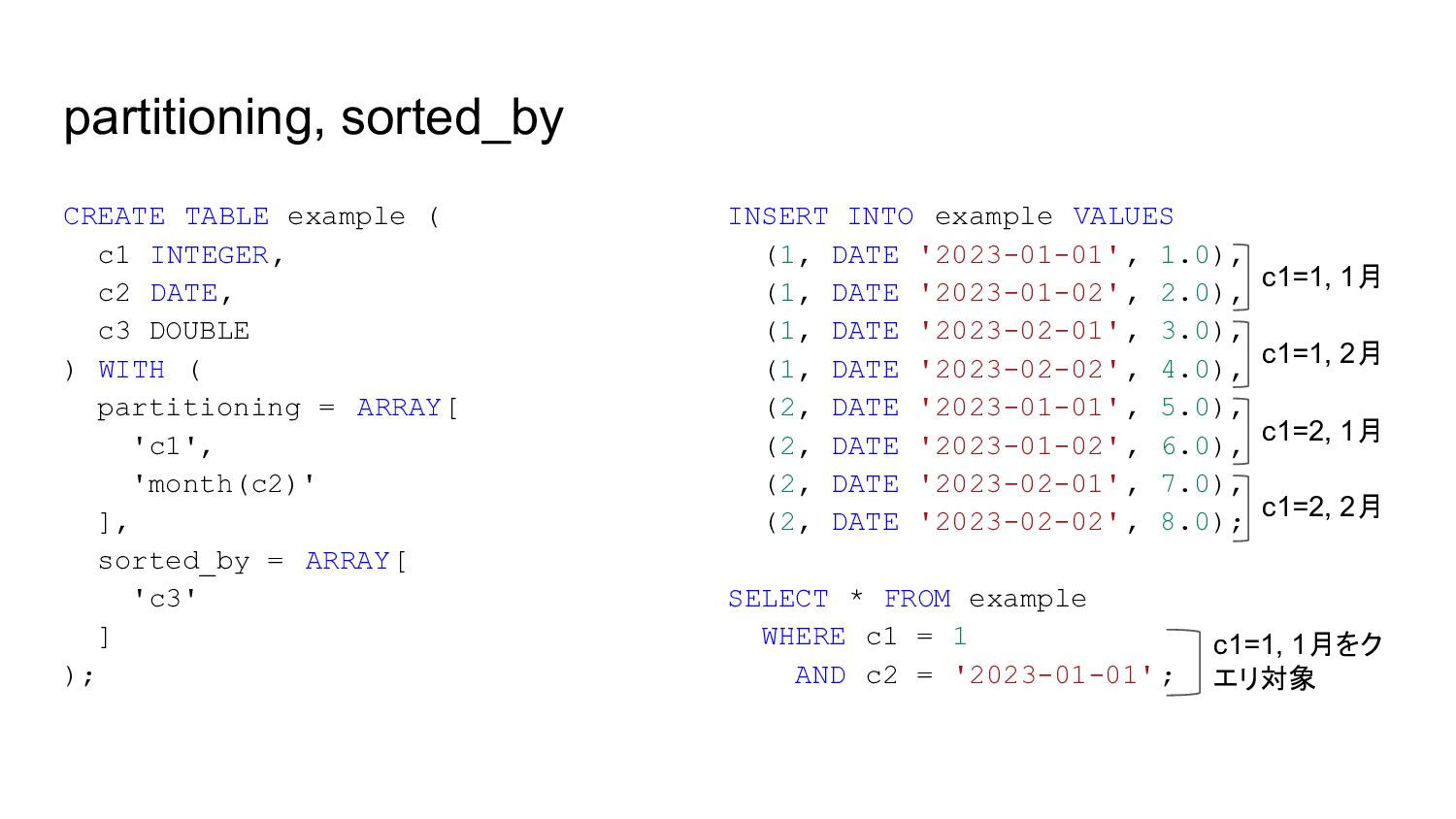
c3 DOUBLE ) WITH ( partitioning = ARRAY[ 'c1', 'month(c2)' ], sorted_by = ARRAY[ 'c3' ] ); INSERT INTO example VALUES (1, DATE '2023-01-01', 1.0), (1, DATE '2023-01-02', 2.0), (1, DATE '2023-02-01', 3.0), (1, DATE '2023-02-02', 4.0), (2, DATE '2023-01-01', 5.0), (2, DATE '2023-01-02', 6.0), (2, DATE '2023-02-01', 7.0), (2, DATE '2023-02-02', 8.0); SELECT * FROM example WHERE c1 = 1 AND c2 = '2023-01-01'; c1=1, 1月 c1=1, 2月 c1=2, 1月 c1=2, 2月 c1=1, 1月をク エリ対象
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
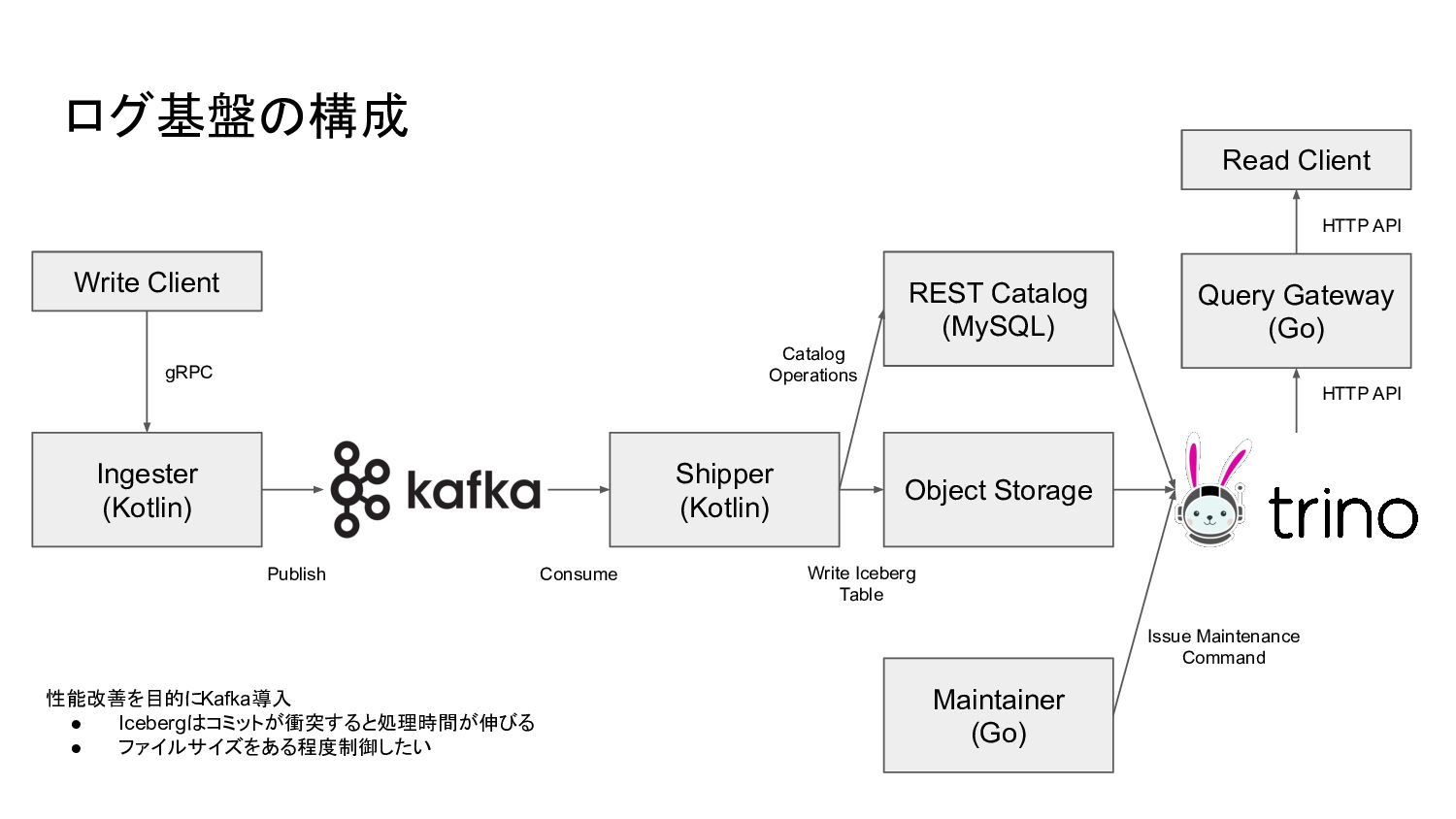{kind=link}
{kind=link}
{kind=link}