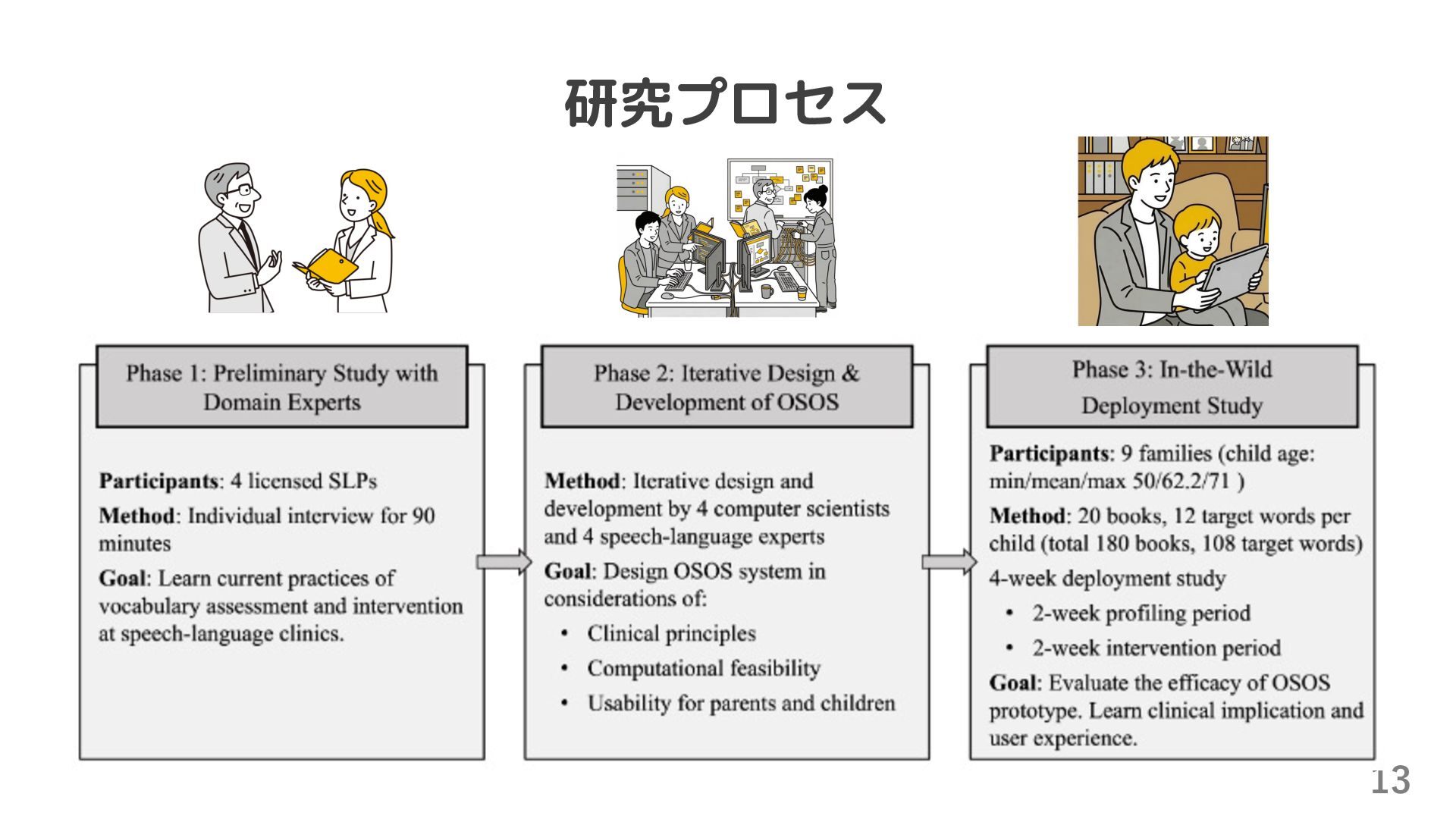
前半2週間(Stage 1):言語環境の収集期間(Profiler) l 子どもとの日常生活の中で週10時間程度を目安に録音 l 家族が持っている絵本を,タブレットで1日20分程度読み聞かせ(新奇性を減らすため) l 後半2週間(Stage 2):生成絵本の読み聞かせ期間 l 20種類の生成絵本のうち,各本を1回以上読む l 週6回以上の読み聞かせセッション(1回あたり20分程度,1回につき2冊以上) l 録音以外に収集したデータ l Stage 1・Stage2終了時:親へのアンケート(抽出語について「実は既知語」チェック) l 実験終了後:親への実験についてのアンケート,半構造化インタビュー(1.5h)
ユニーク語数は2276語(子ども発話705語,その他発話1973語) l OSOS出力の優先語を平均567語提示し,親により「実は既知語」として 平均369語が除外された l Stage 2: 読み聞かせ l 家庭あたり平均15.3分,1冊あたり平均9.2分 l 2人の子どもを除くと,読み聞かせ中の子どもの発話は4.7%(質問など) l 外れ値の2人はそれぞれ83.2%,19.8%(自分で読んだり,親と一緒に読んだり)
timingのような語は単独では説明しずらいが,物語中なら理解しやすい l 語彙習得の実感:実際に最近ターゲット語を話し始めたことを思い出すケースも l AI生成絵本の課題 l 始まりが「Once upon a time…」や「There was a girl…」になりがち l 説明しすぎる傾向にあり不自然なことも.因果関係の表現を重視する物語文法に従わせ る設計などが原因と解釈できる l キャラクターの一貫性がやや欠けていたり,最小限の要素しかないイラスト l 日常生活から,語彙だけではなく,出来事の文脈も広くストーリーに含める要望
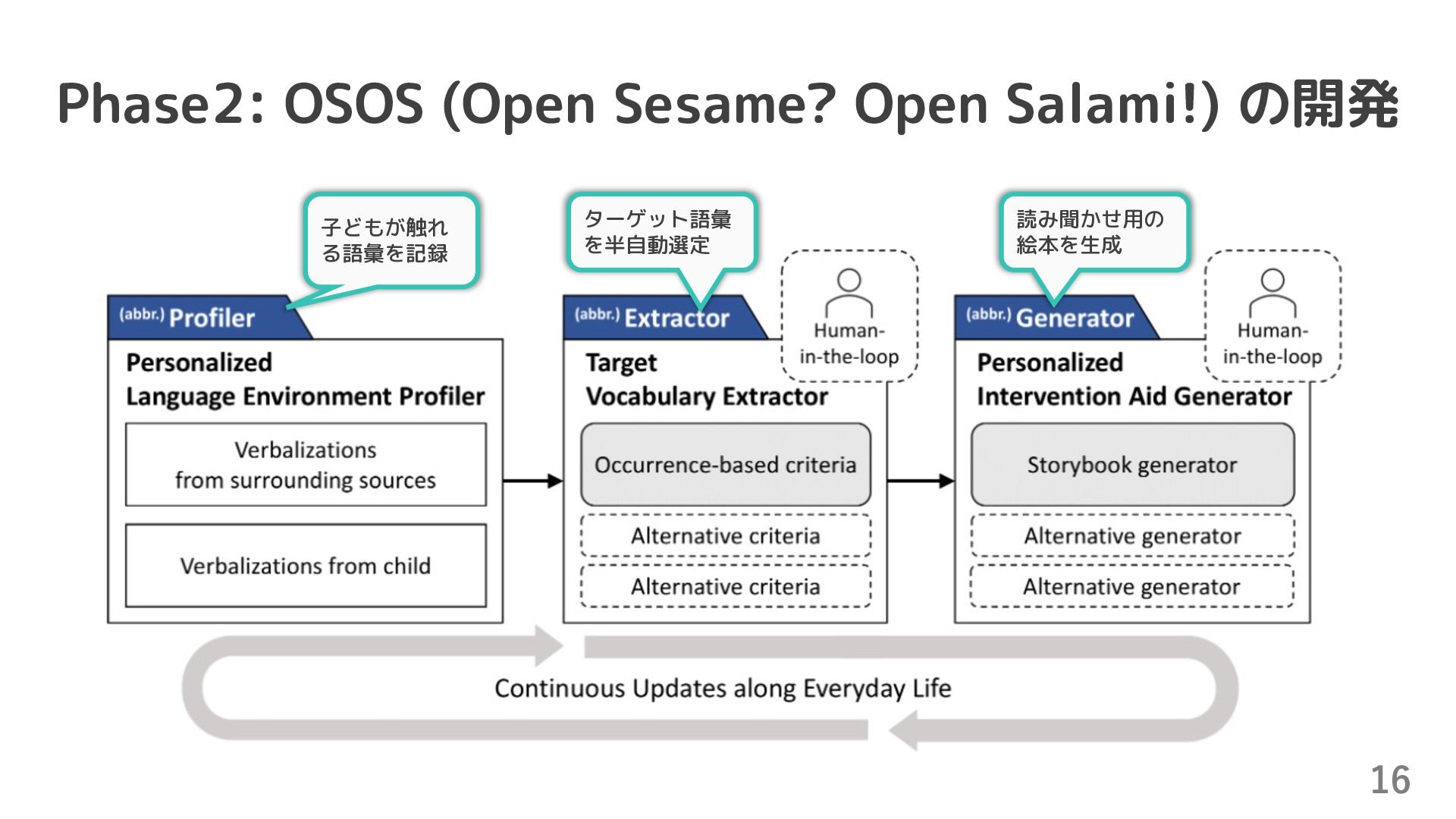
l SLPの監督下で語彙の習得が遅れている子どもへの介入も視野に l 30-million-word gapの緩和:家庭の社会経済的地位によって子どもが聞く語数が 大きく異なる(1時間あたり 2,153語 vs 616語) l 家の音声を録音することへのプライバシー懸念 l 生の音声や文字起こしは家庭内のデバイス側で処理,クラウドには抽出されたター ゲット語のみを送信する設計で軽減
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
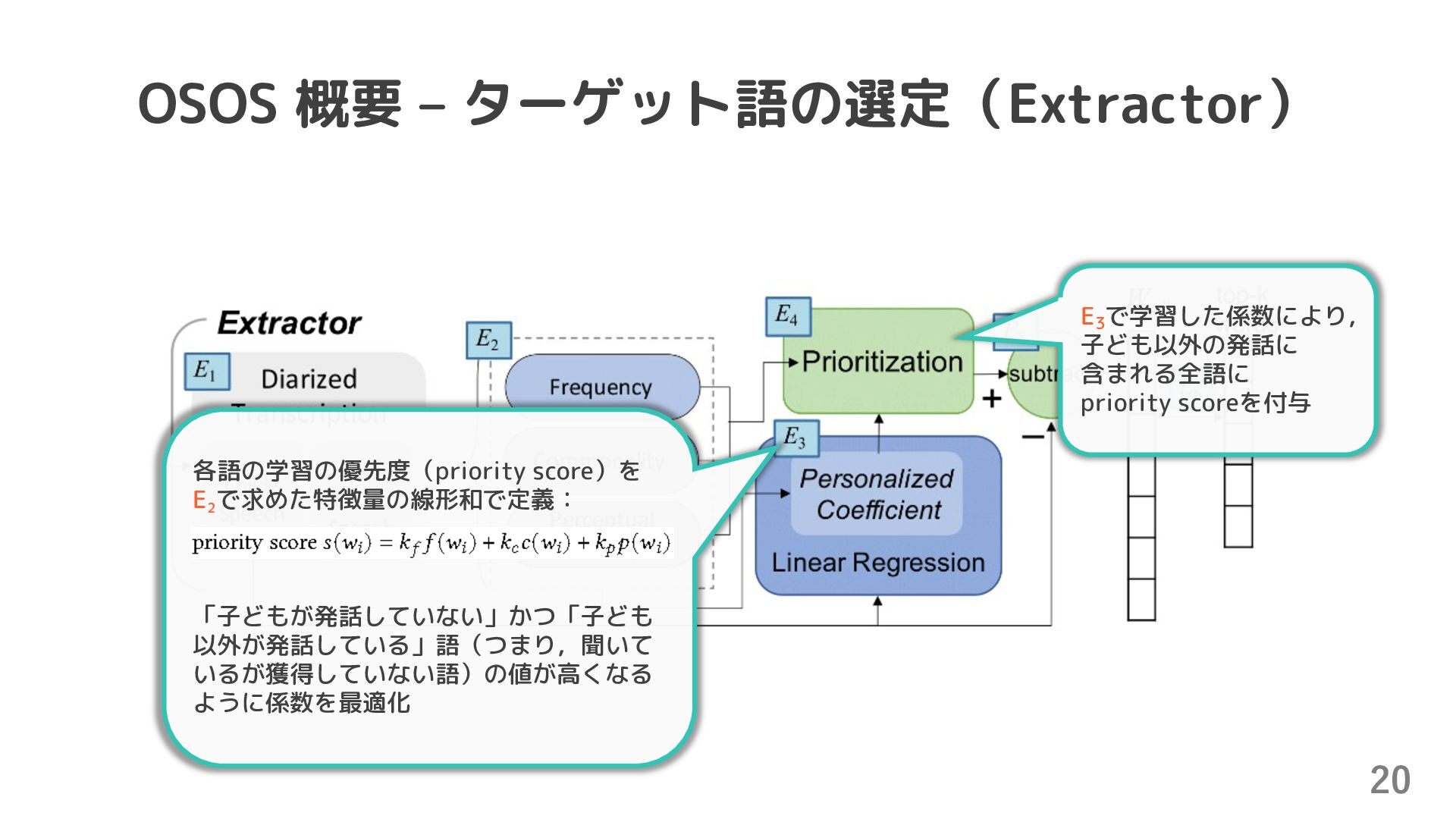{kind=link}
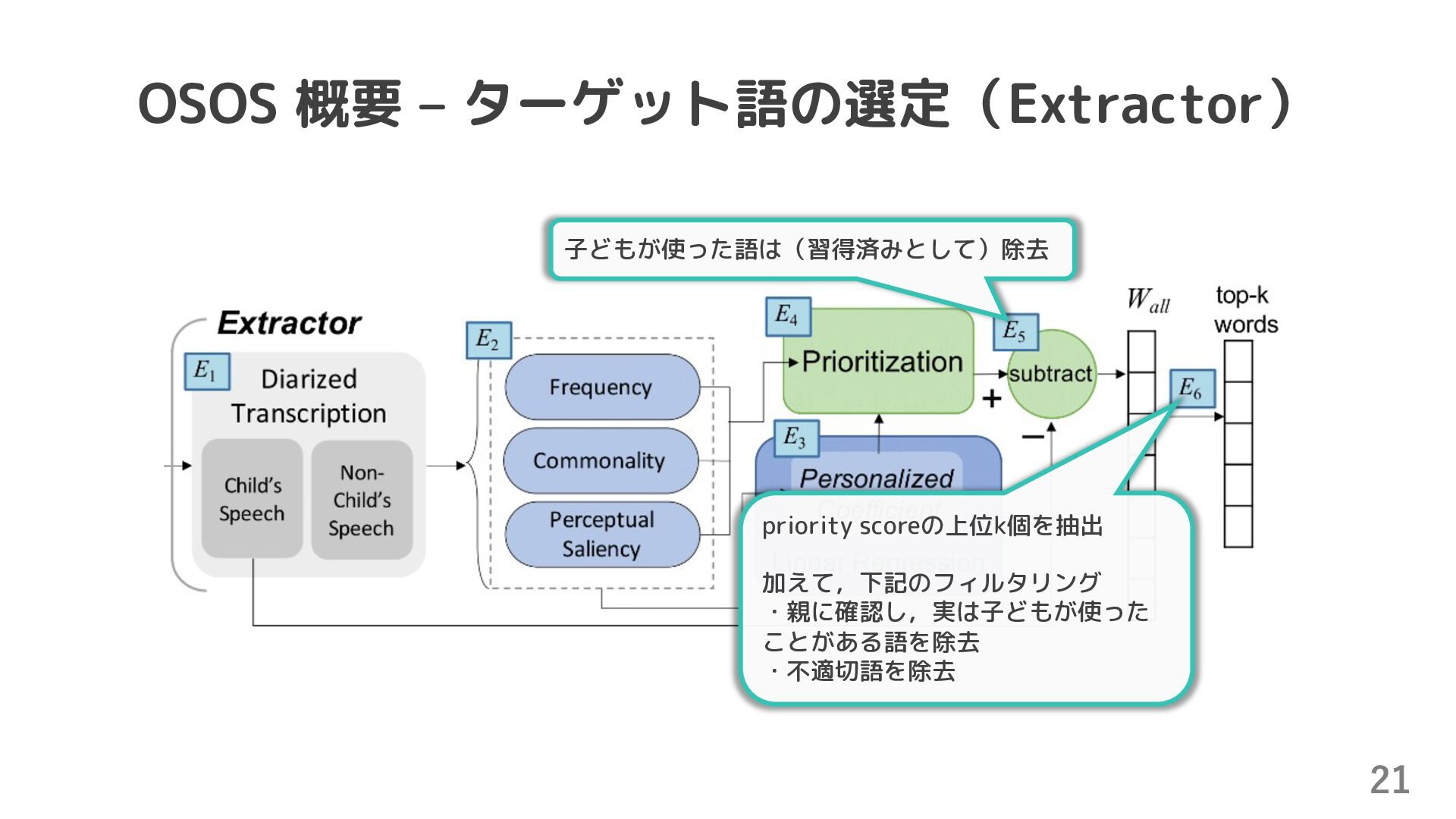{kind=link}
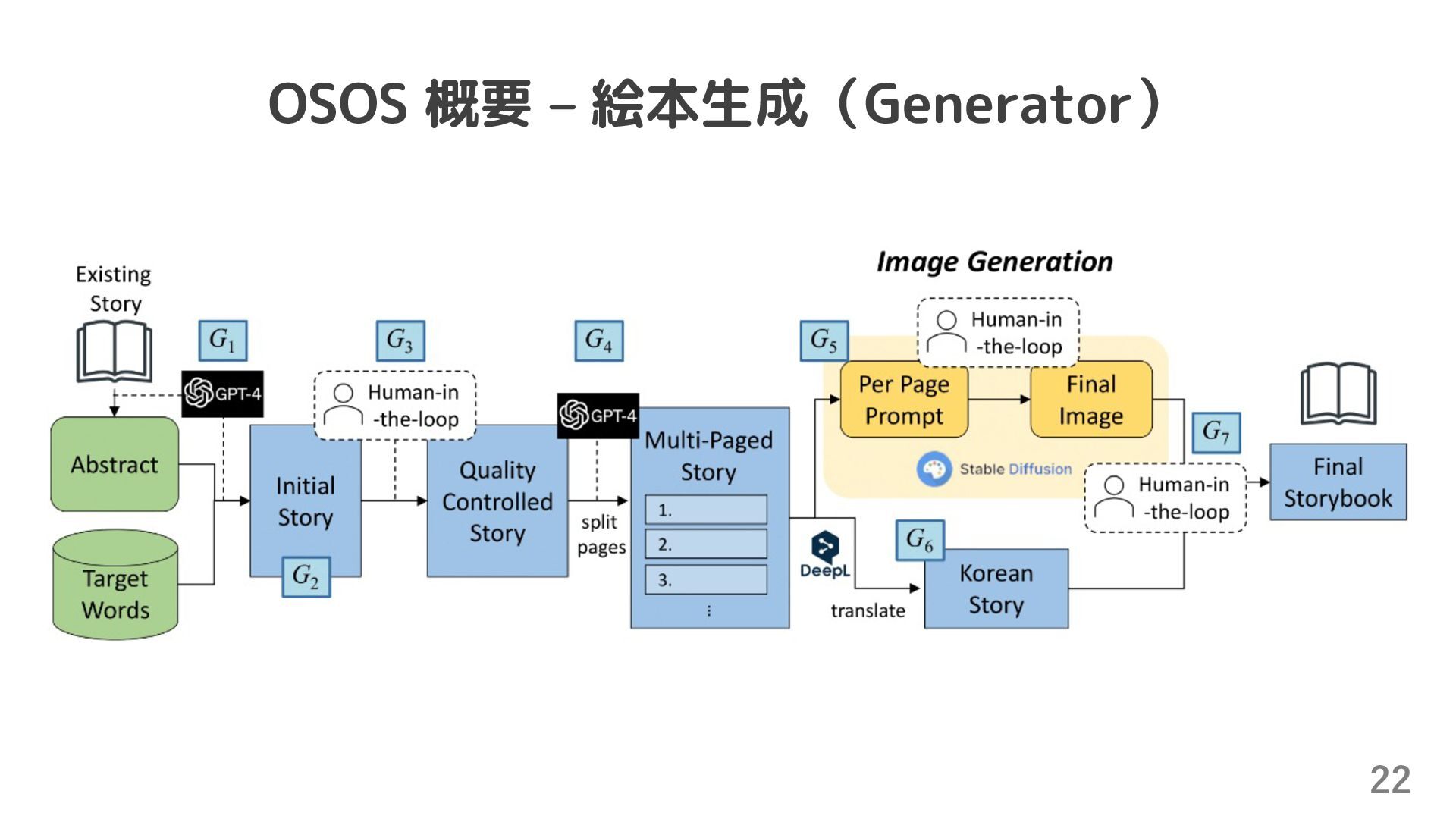{kind=link}
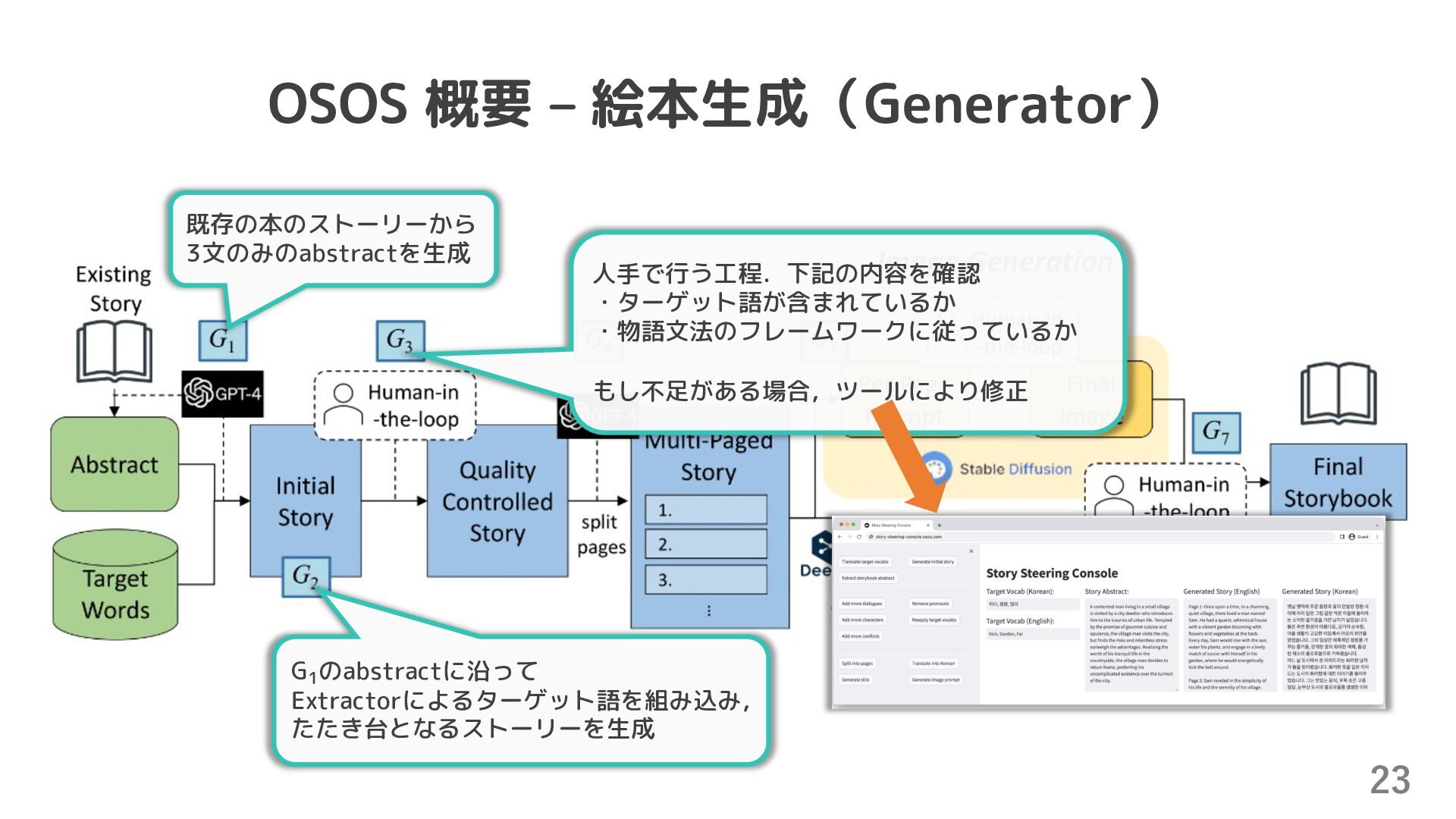{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}